
Um dos aspectos mais importantes, se não o mais importante, do machine learning é obter previsões precisas e confiáveis. Uma abordagem inovadora para esse objetivo que ganhou destaque é Bootstrap Aggregating, mais conhecido como bagging em machine learning. Este artigo discute bagging em machine learning, compara bagging e boosting em machine learning, fornece um exemplo de classificador bagging, explora como bagging funciona e explora as vantagens e desvantagens de bagging em machine learning.
O que é Bagging em Machine Learning?
Essas duas são as únicas imagens relevantes usadas em artigos populares; uma ou ambas podem ser usadas (uma aqui e outra em outro lugar) se tivermos Design fazer versões Cloudzy delas.
O que é Bagging?
Imagine que você está tentando adivinhar o peso de um objeto pedindo estimativas a várias pessoas. Individualmente, os palpites podem variar bastante, mas ao fazer a média de todas as estimativas, você chega a um número mais confiável. É isso que o bagging faz: combina os resultados de vários modelos para produzir uma previsão mais precisa e estável.
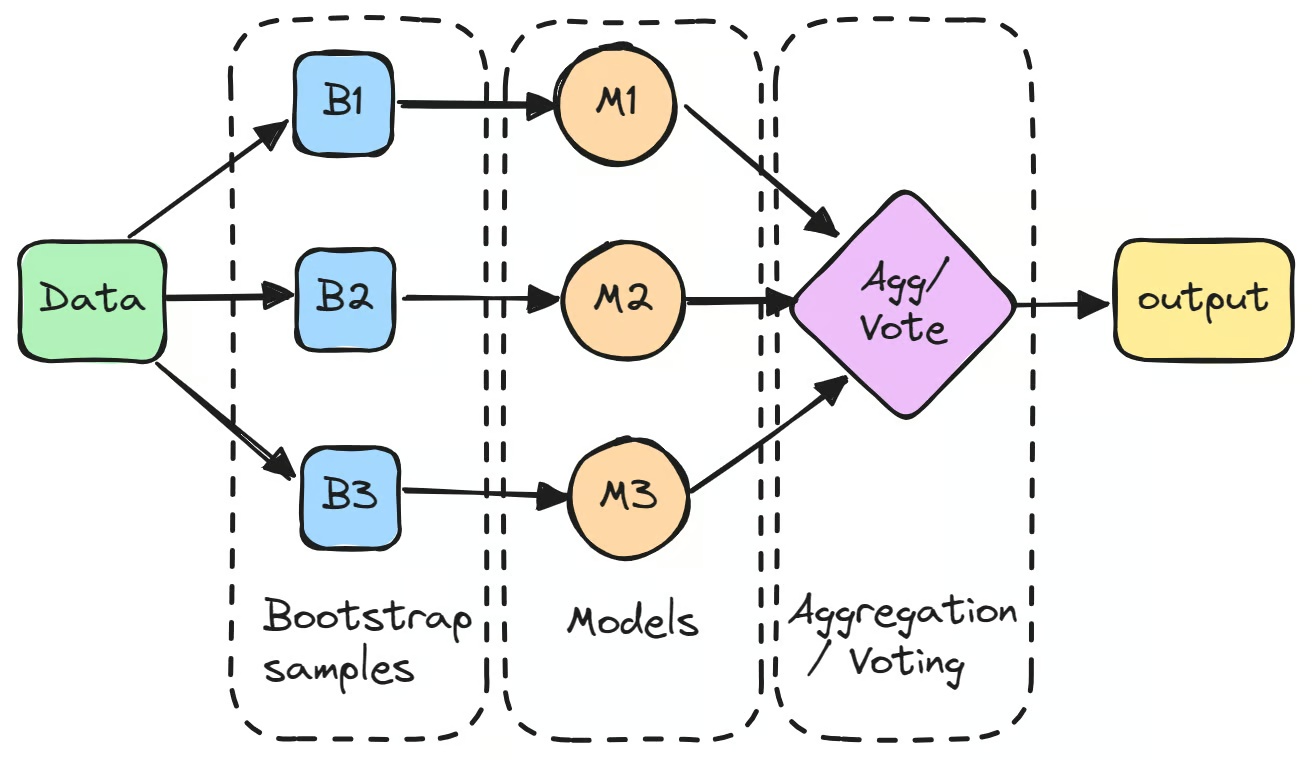
O processo começa criando múltiplos subconjuntos do dataset original através de bootstrap, que é amostragem aleatória com reposição. Cada subconjunto é usado para treinar um modelo separado de forma independente.
Esses modelos individuais, frequentemente chamados de "weak learners", podem não ter um desempenho excepcional por conta própria devido à alta variância. Porém, quando suas previsões são agregadas, normalmente por média em tarefas de regressão ou votação por maioria em tarefas de classificação, o resultado combinado frequentemente supera o desempenho de qualquer modelo isolado.
Um exemplo bem conhecido de bagging é o algoritmo Random Forest, que constrói um conjunto de árvores de decisão para melhorar a performance preditiva. Dito isso, bagging não deve ser confundido com boosting em machine learning, que funciona de forma diferente: boosting treina modelos sequencialmente para reduzir viés, enquanto bagging treina modelos em paralelo para reduzir variância.
Tanto bagging quanto boosting em machine learning buscam melhorar a performance do modelo, mas visam diferentes aspectos do comportamento do modelo.
Por que o Bagging é útil?
Uma das principais vantagens do bagging em machine learning é sua capacidade de reduzir variância, ajudando modelos a generalizar melhor para dados não vistos. Bagging é particularmente benéfico ao trabalhar com algoritmos sensíveis a flutuações nos dados de treinamento, como árvores de decisão.
Ao prevenir overfitting, garante um modelo mais estável e confiável. Ao comparar bagging e boosting em machine learning, bagging se concentra em reduzir variância treinando múltiplos modelos em paralelo, enquanto boosting busca reduzir viés treinando modelos sequencialmente.
Um exemplo de bagging em machine learning pode ser visto em previsão de risco financeiro, onde múltiplas árvores de decisão são treinadas em diferentes subconjuntos de dados históricos de mercado. Ao agregar suas previsões, bagging cria um modelo de previsão mais robusto, reduzindo o impacto de erros de modelos individuais.
Em essência, bagging em machine learning aproveita a sabedoria coletiva de múltiplos modelos para entregar previsões que são mais precisas e confiáveis do que aquelas derivadas de modelos individuais isoladamente.
Como Bagging em Machine Learning Funciona: Passo a Passo
Para entender completamente como bagging melhora a performance do modelo, vamos decompor o processo passo a passo.
Colha Múltiplas Amostras de Bootstrap do Dataset
O primeiro passo em bagging em machine learning é criar múltiplos novos subconjuntos do dataset original usando bootstrap. Esta técnica envolve amostragem aleatória dos dados com reposição, então alguns pontos de dados podem aparecer múltiplas vezes no mesmo subconjunto, enquanto outros podem não aparecer nenhuma vez. Este processo é feito para garantir que cada modelo seja treinado em uma versão ligeiramente diferente dos dados.
Treine um Modelo Separado em Cada Amostra
Cada amostra de bootstrap é então usada para treinar um modelo separado, tipicamente do mesmo tipo, como árvores de decisão. Esses modelos, frequentemente chamados de "base learners" ou "weak learners", são treinados independentemente em seus respectivos subconjuntos. Um exemplo de bagging classifier é a árvore de decisão usada no algoritmo Random Forest, que forma a base de muitos modelos baseados em bagging. Enquanto cada modelo individual pode não ter um bom desempenho isolado, cada um contribui com insights únicos baseados em seus dados de treinamento específicos.
Agregue as Previsões
Depois de treinar os modelos, suas previsões são agregadas para formar a saída final.
- Para tarefas de regressão, as previsões são calculadas pela média, reduzindo a variância do modelo.
- Para tarefas de classificação, a previsão final é determinada por votação por maioria, onde a classe predita pela maioria dos modelos é selecionada. Este método fornece uma previsão mais estável comparada à saída de um único modelo.
Previsão Final
Ao combinar previsões de múltiplos modelos, bagging reduz o impacto de erros de qualquer um modelo, melhorando a precisão geral. Este processo de agregação é o que torna bagging uma técnica tão poderosa, especialmente em tarefas de machine learning onde modelos de alta variância como árvores de decisão são usados. Efetivamente suaviza inconsistências nas previsões de modelos individuais, resultando em um modelo final mais forte.
Enquanto bagging é eficaz para estabilizar previsões, algumas coisas a considerar incluem o risco de overfitting se os modelos base forem muito complexos, apesar do propósito geral de bagging ser reduzi-lo.
Também é computacionalmente caro, então ajustar o número de base learners ou considerar métodos de ensemble mais eficientes pode ajudar, e escolher a GPU certa para ML e DL é sempre importante.
Garanta alguma diversidade de modelo entre os base learners para melhores resultados, e se você estiver trabalhando com dados desbalanceados, técnicas como SMOTE podem ser úteis antes de aplicar bagging para evitar baixa performance nas classes minoritárias.
Aplicações de Bagging
Agora que explorámos como funciona o bagging, é hora de ver onde é realmente usado na prática. O bagging ganhou espaço em várias indústrias, ajudando a melhorar a precisão e estabilidade das previsões em cenários complexos. Vejamos algumas das aplicações mais impactantes:
- Classificação e Regressão: O bagging é amplamente usado para melhorar o desempenho de classificadores e regressores, reduzindo variância e evitando overfitting. Por exemplo, Random Forests, que utiliza bagging, é eficaz em tarefas como classificação de imagens e modelagem preditiva.
- Detecção de Anomalias: Em áreas como detecção de fraude e detecção de intrusão em rede, algoritmos de bagging oferecem desempenho superior ao identificar efetivamente outliers e anomalias nos dados.
- Avaliação de Risco Financeiro: Técnicas de bagging são utilizadas na banca para aprimorar modelos de credit scoring, melhorando a precisão dos processos de aprovação de empréstimos e avaliações de risco financeiro.
- Diagnóstico Médico: Na saúde, bagging tem sido aplicado para detectar transtornos neurocognitivos como Alzheimer ao analisar conjuntos de dados de ressonância magnética, auxiliando no diagnóstico precoce e planejamento do tratamento.
- Processamento de Linguagem Natural (NLP): Bagging contribui para tarefas como classificação de texto e análise de sentimento ao agregar previsões de múltiplos modelos, resultando em compreensão de linguagem mais robusta.
Vantagens e Desvantagens do Bagging
Como qualquer técnica de machine learning, bagging tem suas próprias vantagens e desvantagens. Entendê-las ajuda a determinar quando e como usar bagging nos seus modelos.
Vantagens do Bagging:
- Reduz Variância e Overfitting: Uma das vantagens mais significativas do bagging em machine learning é sua capacidade de reduzir variância, o que ajuda a evitar overfitting. Ao treinar múltiplos modelos em diferentes subconjuntos dos dados, bagging garante que o modelo não se torne muito sensível a flutuações nos dados de treinamento, resultando em um modelo mais generalizável e estável.
- Funciona Bem com Modelos de Alta Variância: Bagging é especialmente eficaz quando usado com modelos de alta variância, como árvores de decisão. Esses modelos tendem a sofrer overfitting e ter alta variância, mas bagging atenua isso ao fazer média ou votação entre múltiplos modelos. Isso torna as previsões mais confiáveis e menos suscetíveis a ruído nos dados.
- Melhora Estabilidade e Desempenho do Modelo: Ao combinar múltiplos modelos treinados em diferentes subconjuntos dos dados, bagging frequentemente resulta em melhor desempenho geral. Ajuda a melhorar a precisão preditiva enquanto reduz a sensibilidade do modelo a pequenas mudanças no conjunto de dados, tornando o modelo mais confiável.
Desvantagens do Bagging:
- Aumenta Custo Computacional: Como bagging requer treinar múltiplos modelos, naturalmente aumenta o custo computacional. Treinar e agregar previsões de muitos modelos pode ser demorado, especialmente ao usar grandes conjuntos de dados ou modelos complexos como árvores de decisão.
- Não É Eficaz para Modelos de Baixa Variância: Enquanto bagging é altamente eficaz para modelos de alta variância, não oferece muito benefício quando aplicado a modelos de baixa variância, como regressão linear. Nesses casos, os modelos individuais já têm baixas taxas de erro, então agregar previsões faz pouco para melhorar os resultados.
- Perda de Interpretabilidade: Com a combinação de múltiplos modelos, bagging pode reduzir a interpretabilidade do modelo final. Por exemplo, em Random Forest, o processo de decisão é baseado em múltiplas árvores de decisão, dificultando rastrear o raciocínio por trás de uma previsão específica.
Quando Devo Usar Bagging?
Saber quando aplicar bagging em projetos de machine learning é fundamental para obter resultados ótimos. Essa técnica funciona bem em situações específicas, mas nem sempre é a melhor escolha para todos os problemas.
Quando Seu Modelo Está Propenso a Overfitting
Um dos principais casos de uso para bagging é quando seu modelo está propenso a overfitting, especialmente com modelos de alta variância como árvores de decisão. Esses modelos podem funcionar bem com dados de treinamento, mas frequentemente falham ao generalizar para dados não vistos, pois se ajustam demais aos padrões específicos do conjunto de treinamento.
Bagging ajuda a combater isso treinando múltiplos modelos em subconjuntos diferentes dos dados e usando média ou votação para criar uma previsão mais estável. Isso reduz a probabilidade de overfitting, tornando o modelo melhor em lidar com dados novos e não vistos.
Quando Você Quer Melhorar Estabilidade e Precisão
Se você está buscando melhorar a estabilidade e precisão do seu modelo sem comprometer muito a interpretabilidade, bagging é uma excelente escolha. A agregação de previsões de múltiplos modelos torna o resultado final mais poderoso, o que é especialmente útil em tarefas que envolvem dados ruidosos.
Seja em problemas de classificação ou tarefas de regressão, bagging pode ajudar a produzir resultados mais consistentes, aumentando a precisão mantendo a eficiência.
Quando Você Tem Recursos Computacionais Suficientes
Outro fator importante ao decidir usar bagging é a disponibilidade de recursos computacionais. Como bagging requer treinar múltiplos modelos simultaneamente, o custo computacional pode se tornar significativo, especialmente com conjuntos de dados grandes ou modelos complexos.
Se você tem acesso à potência computacional necessária, os benefícios de bagging superam amplamente os custos. No entanto, se seus recursos são limitados, você pode considerar técnicas alternativas ou reduzir o número de modelos no seu ensemble.
Quando Você Está Trabalhando com Modelos de Alta Variância
Bagging é particularmente útil ao trabalhar com modelos que têm alta variância e são sensíveis às flutuações nos dados de treinamento. Árvores de decisão, por exemplo, são frequentemente usadas com bagging na forma de Random Forests porque seu desempenho tende a variar muito dependendo dos dados de treinamento.
Ao treinar múltiplos modelos em subconjuntos de dados diferentes e combinar suas previsões, bagging suaviza a variância, resultando em um modelo mais confiável.
Quando Você Precisa de um Classificador Robusto
Se você está trabalhando em problemas de classificação e precisa de um classificador robusto, bagging pode melhorar significativamente a estabilidade de suas previsões. Por exemplo, uma Random Forest, que é um exemplo de classificador de bagging, pode fornecer uma previsão mais precisa agregando os resultados de muitas árvores de decisão individuais.
Essa abordagem funciona bem quando modelos individuais podem ser fracos, mas seu poder combinado resulta em um modelo geral forte.
Além disso, se você está procurando a plataforma certa para implementar técnicas de bagging de forma eficiente, ferramentas como Databricks e Snowflake fornecem uma plataforma de análise unificada que pode ser muito útil para gerenciar grandes conjuntos de dados e executar métodos de ensemble como bagging.
Se você está procurando uma abordagem menos técnica para machine learning, ferramentas de IA sem código também pode ser uma opção. Embora não se concentrem diretamente em técnicas avançadas como bagging, muitas plataformas sem código permitem que usuários experimentem com métodos de ensemble learning, incluindo bagging, sem necessidade de habilidades de programação extensivas.
Isso permite que você aplique técnicas mais sofisticadas e ainda obtenha previsões precisas enquanto se concentra no desempenho do modelo em vez do código subjacente.
Considerações finais
Bagging em machine learning é uma técnica poderosa que melhora o desempenho do modelo reduzindo a variância e melhorando a estabilidade. Ao agregar as previsões de múltiplos modelos treinados em subconjuntos diferentes de dados, bagging ajuda a criar resultados mais precisos e confiáveis. É especialmente eficaz para modelos de alta variância como árvores de decisão, onde ajuda a evitar overfitting e garante que o modelo generalize melhor para dados não vistos.
Embora bagging tenha vantagens significativas, como reduzir overfitting e melhorar precisão, ele tem alguns trade-offs. Aumenta o custo computacional devido ao treinamento de múltiplos modelos e pode reduzir a interpretabilidade. Apesar dessas desvantagens, sua capacidade de melhorar o desempenho o torna uma técnica valiosa em ensemble learning, junto com outros métodos como boosting e stacking.
Você já usou bagging em projetos de machine learning? Nos conte sua experiência e como funcionou para você!


