
يُعدّ تحقيق تنبؤات دقيقة وموثوقة من أهم ركائز تعلم الآلة، إن لم يكن أهمها على الإطلاق. ومن أبرز الأساليب المبتكرة التي برزت لتحقيق هذا الهدف أسلوبُ التجميع التحميلي، المعروف على نطاق واسع بـ Bagging في تعلم الآلة. تتناول هذه المقالة مفهوم Bagging في تعلم الآلة، وتقارن بينه وبين Boosting، وتستعرض مثالاً عملياً على مصنِّف Bagging، وتشرح آلية عمله، وتستكشف مزاياه وعيوبه.
ما هو Bagging في تعلم الآلة؟
هاتان الصورتان هما الوحيدتان المستخدمتان في المقالات الشائعة، ويمكن الاستعانة بإحداهما أو بهما معاً (إحداهما هنا والأخرى في موضع آخر) إذا قام فريق التصميم بإنشاء نسخ خاصة بـ Cloudzy.
ما هو Bagging؟
تخيّل أنك تحاول تخمين وزن جسم ما بسؤال عدد من الأشخاص عن تقديراتهم. قد تتفاوت إجاباتهم بشكل ملحوظ، لكن بأخذ متوسط تلك التقديرات تصل إلى رقم أكثر دقة وموثوقية. هذا بالضبط ما يقوم عليه Bagging: الجمع بين مخرجات عدة نماذج للوصول إلى تنبؤ أدق وأكثر استقراراً.
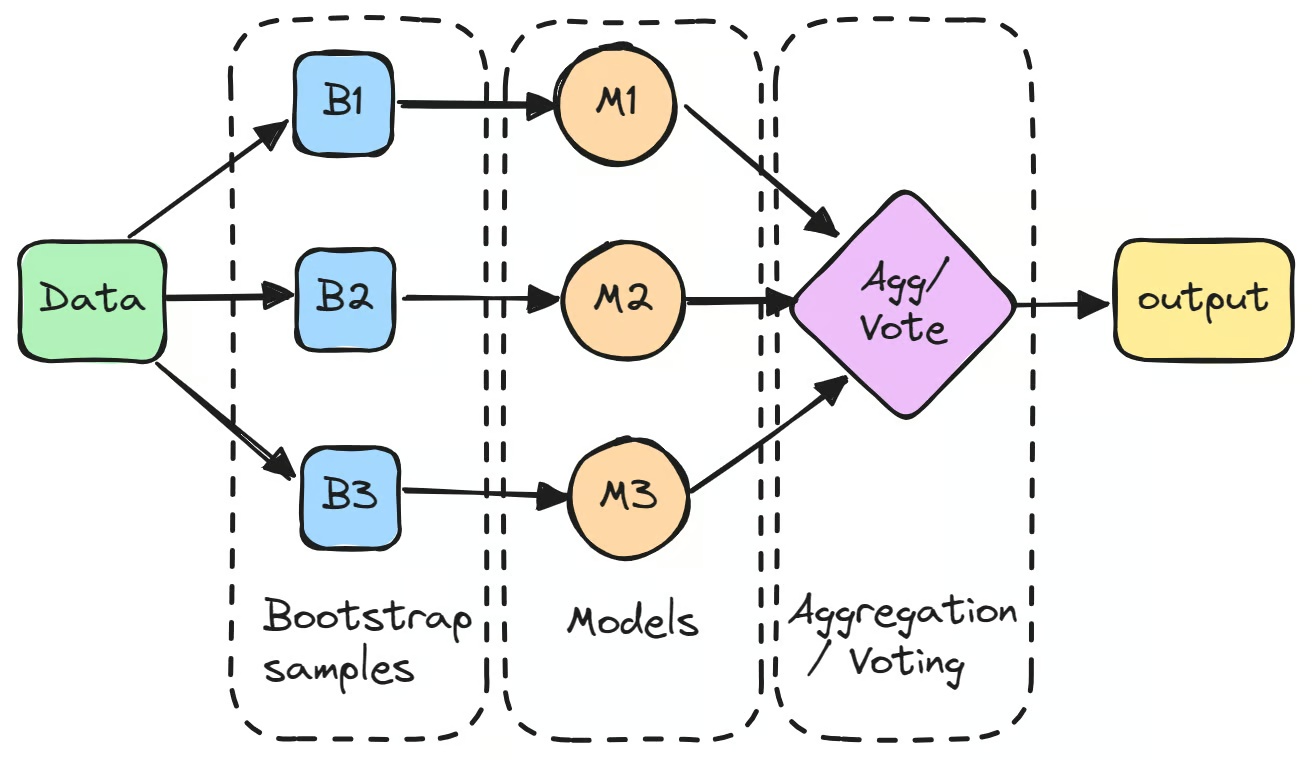
تبدأ العملية بإنشاء مجموعات فرعية متعددة من مجموعة البيانات الأصلية عبر تقنية Bootstrapping، وهي أخذ عينات عشوائية مع الإحلال. تُستخدم كل مجموعة فرعية لتدريب نموذج مستقل على حدة.
قد لا تُحقق هذه النماذج الفردية، التي يُشار إليها أحياناً بـ «المتعلمين الضعفاء»، أداءً استثنائياً منفردةً بسبب التباين العالي. غير أنه حين تُجمَع تنبؤاتها، سواء بأخذ المتوسط في مسائل الانحدار أو بالتصويت بالأغلبية في مسائل التصنيف، يتجاوز الناتج المجمَّع عادةً أداء أي نموذج منفرد.
من أبرز أمثلة مصنِّف Bagging خوارزمية الغابة العشوائية (Random Forest)، التي تبني مجموعة من أشجار القرار لتحسين دقة التنبؤ. تجدر الإشارة إلى أن Bagging يختلف عن Boosting في تعلم الآلة؛ إذ يعتمد Boosting على تدريب النماذج بشكل تسلسلي لتقليل التحيز، بينما يدرّب Bagging النماذج بشكل متوازٍ لتقليل التباين.
يهدف كلٌّ من Bagging وBoosting في تعلم الآلة إلى تحسين أداء النموذج، لكن كلاً منهما يستهدف جانباً مختلفاً من سلوكه.
لماذا يكون Bagging مفيداً؟
من أبرز مزايا Bagging في تعلم الآلة قدرتُه على تقليل التباين، مما يساعد النماذج على التعميم بشكل أفضل على بيانات لم تُدرَّب عليها. يبرز Bagging بوجه خاص عند التعامل مع خوارزميات حساسة للتغيرات في بيانات التدريب، كأشجار القرار.
بالحدّ من الإفراط في التخصيص (Overfitting)، يضمن Bagging نموذجاً أكثر استقراراً وموثوقية. وعند المقارنة بين Bagging وBoosting في تعلم الآلة، يركز Bagging على تقليل التباين بتدريب نماذج متعددة بشكل متوازٍ، في حين يسعى Boosting إلى تقليل التحيز بتدريب النماذج بشكل تسلسلي.
يتجلى تطبيق Bagging في تعلم الآلة في نماذج التنبؤ بالمخاطر المالية، حيث تُدرَّب أشجار قرار متعددة على مجموعات فرعية مختلفة من البيانات التاريخية للسوق. وبتجميع تنبؤاتها، يُنتج Bagging نموذجاً تنبؤياً أكثر متانة يُخفف من أثر أخطاء النماذج الفردية.
في جوهره، يستفيد Bagging في تعلم الآلة من الحكمة الجماعية لنماذج متعددة لتقديم تنبؤات أدق وأكثر موثوقية مما يمكن أن يُقدمه أي نموذج منفرد.
كيف يعمل Bagging في تعلم الآلة: خطوة بخطوة
لفهم كيفية تحسين Bagging لأداء النموذج، دعنا نستعرض العملية خطوة بخطوة.
أخذ عينات Bootstrap متعددة من مجموعة البيانات
الخطوة الأولى في Bagging في تعلم الآلة هي إنشاء مجموعات فرعية جديدة متعددة من مجموعة البيانات الأصلية باستخدام Bootstrapping. تقوم هذه التقنية على أخذ عينات عشوائية من البيانات مع الإحلال، مما يعني أن بعض نقاط البيانات قد تظهر أكثر من مرة في المجموعة الفرعية الواحدة، بينما قد لا تظهر نقاط أخرى إطلاقاً. الهدف من ذلك ضمان تدريب كل نموذج على نسخة مختلفة قليلاً من البيانات.
تدريب نموذج منفصل على كل عينة
تُستخدم كل عينة bootstrap لتدريب نموذج منفصل، عادةً من النوع ذاته، كأشجار القرار. تُعرف هذه النماذج غالباً بـ"المتعلمات الأساسية" أو "المتعلمات الضعيفة"، وتُدرَّب باستقلالية على مجموعاتها الفرعية. ومن أبرز أمثلة مصنفات bagging شجرة القرار المستخدمة في خوارزمية Random Forest، التي تشكّل العمود الفقري لكثير من النماذج المبنية على bagging. وبينما قد لا يُحقق كل نموذج منفرد أداءً جيداً بمفرده، يقدّم كل منها رؤى فريدة مستمدة من بيانات التدريب الخاصة به.
تجميع التنبؤات
بعد تدريب النماذج، تُجمَّع تنبؤاتها لتكوين المخرج النهائي.
- في مهام الانحدار، تُحسب متوسطات التنبؤات، مما يُقلل من تباين النموذج.
- في مهام التصنيف، يُحدَّد التنبؤ النهائي عبر التصويت بالأغلبية، إذ تُختار الفئة التي يتنبأ بها أكبر عدد من النماذج. تُقدّم هذه الطريقة تنبؤاً أكثر استقراراً مقارنةً بمخرجات النموذج المنفرد.
التنبؤ النهائي
من خلال دمج تنبؤات نماذج متعددة، يُقلل bagging من تأثير الأخطاء الصادرة عن أي نموذج واحد، مما يُحسّن الدقة الكلية. وهذه العملية التجميعية هي ما يجعل bagging أسلوباً فعّالاً، لا سيما في مهام تعلم الآلة التي تستخدم نماذج عالية التباين كأشجار القرار. إذ تُساهم بفعالية في تمهيد التفاوتات بين تنبؤات النماذج الفردية، للوصول إلى نموذج نهائي أقوى.
يُعدّ bagging فعّالاً في استقرار التنبؤات، غير أن ثمة اعتبارات ينبغي مراعاتها، منها خطر الإفراط في التخصيص إذا كانت النماذج الأساسية بالغة التعقيد، على الرغم من أن الهدف الأساسي لـ bagging هو تقليل هذا الخطر.
يُعدّ أيضاً مكلفاً حسابياً، لذا قد يُفيد ضبط عدد المتعلمات الأساسية أو اعتماد أساليب ensemble أكثر كفاءة، كما أن اختيار GPU المناسب لـ ML و DL أمر بالغ الأهمية دائماً.
احرص على تنويع النماذج بين المتعلمات الأساسية للحصول على نتائج أفضل، وإن كنت تعمل على بيانات غير متوازنة، فقد تُفيد تقنيات مثل SMOTE قبل تطبيق bagging، تفادياً لضعف الأداء على الفئات ذات التمثيل الضئيل.
تطبيقات Bagging
بعد أن استعرضنا آلية عمل bagging، حان الوقت للنظر في مجالات توظيفه الفعلي. وجد bagging طريقه إلى قطاعات متعددة، مُسهماً في رفع دقة التنبؤات واستقرارها في السيناريوهات المعقدة. إليك أبرز تطبيقاته:
- التصنيف والانحدار: يُستخدم bagging على نطاق واسع لتحسين أداء المصنفات ونماذج الانحدار عبر تقليل التباين والحد من الإفراط في التخصيص. على سبيل المثال، تعتمد Random Forests على bagging وتُحقق أداءً متميزاً في مهام كتصنيف الصور والنمذجة التنبؤية.
- اكتشاف الشذوذات: في مجالات كالكشف عن الاحتيال ورصد الاختراقات الشبكية، تُقدّم خوارزميات bagging أداءً متقدماً من خلال رصد القيم الشاذة والاستثنائية في البيانات بدقة عالية.
- تقييم المخاطر المالية: تُوظَّف تقنيات bagging في القطاع المصرفي لتطوير نماذج التصنيف الائتماني، مما يُحسّن دقة عمليات الموافقة على القروض وتقييمات المخاطر المالية.
- التشخيص الطبي: في قطاع الرعاية الصحية، طُبّق bagging للكشف عن الاضطرابات المعرفية العصبية كمرض الزهايمر عبر تحليل مجموعات بيانات MRI، مما يُسهم في التشخيص المبكر ووضع خطط العلاج.
- معالجة اللغة الطبيعية (NLP): يُسهم Bagging في مهام مثل تصنيف النصوص وتحليل المشاعر، وذلك بتجميع تنبؤات نماذج متعددة، مما يُنتج فهمًا لغويًا أكثر دقةً واتساقًا.
مزايا Bagging وعيوبه
كأي أسلوب في تعلم الآلة، يحمل Bagging مزايا وعيوبًا خاصة به. فهم هذه الجوانب يساعدك على تحديد متى تستخدم Bagging في نماذجك وكيف توظّفه.
مزايا Bagging:
- تقليل التباين والإفراط في التخصيص: من أبرز مزايا Bagging في تعلم الآلة قدرتُه على تقليل التباين، مما يحدّ من الإفراط في التخصيص. بتدريب نماذج متعددة على مجموعات فرعية مختلفة من البيانات، يضمن Bagging ألّا يصبح النموذج حساسًا جدًا للتذبذبات في بيانات التدريب، فينتج نموذجٌ أكثر استقرارًا وأوسع تعميمًا.
- فعّالية مع النماذج ذات التباين العالي: يُبدي Bagging أداءً متميزًا مع النماذج ذات التباين العالي كأشجار القرار. هذه النماذج تميل إلى الإفراط في التخصيص وترتفع نسبة تباينها، غير أن Bagging يعالج ذلك بحساب المتوسط أو التصويت عبر نماذج متعددة، مما يجعل التنبؤات أكثر موثوقية وأقل تأثرًا بالضجيج في البيانات.
- تحسين استقرار النموذج وأدائه: بدمج نماذج متعددة مُدرَّبة على مجموعات فرعية مختلفة، يُحقق Bagging في الغالب أداءً كليًا أفضل. يرفع من دقة التنبؤ ويقلل حساسية النموذج للتغييرات الطفيفة في البيانات، مما يجعله في نهاية المطاف أكثر موثوقية.
عيوب Bagging:
- ارتفاع التكلفة الحسابية: نظرًا لأن Bagging يستلزم تدريب نماذج متعددة، فإنه يرفع التكلفة الحسابية بطبيعته. قد تستغرق عملية التدريب وتجميع التنبؤات من نماذج كثيرة وقتًا طويلًا، لا سيما عند التعامل مع مجموعات بيانات ضخمة أو نماذج معقدة كأشجار القرار.
- محدودية الفائدة مع النماذج ذات التباين المنخفض: بينما يُعدّ Bagging فعّالًا جدًا مع النماذج ذات التباين العالي، فإنه لا يُقدّم فائدة تُذكر عند تطبيقه على النماذج ذات التباين المنخفض كالانحدار الخطي. في هذه الحالات، تكون معدلات الخطأ في النماذج الفردية منخفضة أصلًا، فلا يُسهم تجميع التنبؤات في تحسين النتائج.
- فقدان قابلية التفسير: بتجميع نماذج متعددة، قد يُقلّل Bagging من قابلية تفسير النموذج النهائي. في Random Forest مثلًا، تستند عملية اتخاذ القرار إلى أشجار قرار متعددة، مما يُصعّب تتبع المنطق وراء تنبؤ بعينه.
متى أستخدم Bagging؟
تحديد متى تُطبّق Bagging في مشاريع تعلم الآلة أمرٌ محوري للوصول إلى نتائج مثلى. هذا الأسلوب يُؤدي أداءً جيدًا في سياقات محددة، لكنه ليس الخيار الأمثل دائمًا لكل مسألة.
حين يكون نموذجك عرضة للإفراط في التخصيص
من أبرز حالات استخدام Bagging أن يكون نموذجك عرضة للإفراط في التخصيص، خاصةً مع النماذج ذات التباين العالي كأشجار القرار. هذه النماذج قد تُحقق أداءً جيدًا على بيانات التدريب، لكنها كثيرًا ما تعجز عن التعميم على بيانات جديدة لارتباطها الشديد بأنماط مجموعة التدريب.
يتصدى Bagging لهذه المشكلة بتدريب نماذج متعددة على مجموعات فرعية مختلفة، ثم حساب المتوسط أو التصويت للتوصل إلى تنبؤ أكثر استقرارًا. هذا يُقلل من احتمالية الإفراط في التخصيص، ويجعل النموذج أقدر على التعامل مع بيانات جديدة لم يسبق له رؤيتها.
حين تريد تحسين الاستقرار والدقة
إن كنت تسعى إلى تحسين استقرار نموذجك ودقته دون التضحية بقابليته للتفسير بشكل كبير، فإن Bagging خيارٌ ممتاز. تجميع التنبؤات من نماذج متعددة يمنح النتيجة النهائية قوةً أكبر، وهو ما يُبرز قيمته تحديدًا في المهام التي تنطوي على بيانات صاخبة.
سواء كنت تعمل على مسائل التصنيف أو مهام الانحدار، يمكن للـ bagging أن يُنتج نتائج أكثر اتساقاً، ويرفع الدقة مع الحفاظ على الكفاءة.
عندما تتوفر لديك موارد حسابية كافية
من العوامل المهمة الأخرى عند تقييم استخدام الـ bagging هو توفر الموارد الحسابية. إذ يستلزم الـ bagging تدريب نماذج متعددة في آنٍ واحد، مما يرفع التكلفة الحسابية بشكل ملحوظ، خاصةً مع مجموعات البيانات الكبيرة أو النماذج المعقدة.
إذا كانت لديك القدرة الحسابية اللازمة، فإن فوائد الـ bagging تفوق تكاليفه بمراحل. أما إذا كانت الموارد محدودة، فقد يكون من المناسب النظر في تقنيات بديلة أو تقليل عدد النماذج في المجموعة.
عندما تعمل مع نماذج عالية التباين
يبرز الـ bagging بشكل خاص عند التعامل مع نماذج عالية التباين وحساسة للتذبذبات في بيانات التدريب. أشجار القرار مثلاً تُستخدم كثيراً مع الـ bagging في صورة Random Forests، نظراً لتفاوت أدائها الكبير تبعاً لبيانات التدريب.
بتدريب نماذج متعددة على مجموعات فرعية مختلفة من البيانات ودمج توقعاتها، يُخفف الـ bagging من حدة التباين، مما يُنتج نموذجاً أكثر موثوقية.
عندما تحتاج إلى مُصنِّف متين
إذا كنت تعمل على مسائل التصنيف وتحتاج إلى مُصنِّف متين، فإن الـ bagging يُحسّن استقرار توقعاتك بشكل ملموس. فعلى سبيل المثال، يُقدم الـ Random Forest، الذي يُعدّ نموذجاً تطبيقياً للـ bagging، توقعات أدق بفضل تجميع نتائج أشجار القرار الفردية.
يُؤدي هذا الأسلوب أداءً جيداً حين تكون النماذج الفردية ضعيفة، غير أن قوتها المجتمعة تُنتج نموذجاً كلياً قوياً.
علاوةً على ذلك، إذا كنت تبحث عن منصة مناسبة لتطبيق تقنيات الـ bagging بكفاءة، فإن أدوات مثل Databricks وSnowflake توفر منصة تحليلات موحدة تُفيد كثيراً في إدارة مجموعات البيانات الكبيرة وتشغيل أساليب التعلم التجميعي كالـ bagging.
إذا كنت تفضل نهجاً أقل تقنية في تعلم الآلة، أدوات الذكاء الاصطناعي بدون كود قد تكون خياراً مناسباً. فرغم أنها لا تركز مباشرةً على تقنيات متقدمة كالـ bagging، تتيح كثير من هذه المنصات للمستخدمين تجربة أساليب التعلم التجميعي، بما فيها الـ bagging، دون الحاجة إلى مهارات برمجية واسعة.
يُتيح لك ذلك تطبيق تقنيات أكثر تطوراً والحصول على توقعات دقيقة، مع التركيز على أداء النموذج بدلاً من الكود البرمجي.
أفكار ختامية
الـ bagging في تعلم الآلة تقنية فعّالة ترفع أداء النماذج بتقليل التباين وتحسين الاستقرار. بتجميع توقعات نماذج متعددة مدرَّبة على مجموعات فرعية مختلفة من البيانات، يُساعد الـ bagging على إنتاج نتائج أدق وأكثر موثوقية. وهو فعّال بشكل خاص مع النماذج عالية التباين كأشجار القرار، إذ يحدّ من الإفراط في التخصيص ويجعل النموذج أكثر قدرة على التعميم على بيانات جديدة.
رغم المزايا الكبيرة للـ bagging، كتقليل الإفراط في التخصيص وتحسين الدقة، إلا أنه ينطوي على بعض المقايضات. فهو يرفع التكلفة الحسابية بسبب تدريب نماذج متعددة، وقد يُقلل من قابلية التفسير. ومع ذلك، تجعل قدرته على تحسين الأداء منه تقنية قيّمة في التعلم التجميعي، إلى جانب أساليب أخرى كالـ boosting والـ stacking.
هل استخدمت الـ bagging في مشاريع تعلم الآلة؟ أخبرنا عن تجربتك وكيف أفادتك!


