
Você abre a página GGUF de um modelo popular no Hugging Face e há quinze arquivos olhando de volta para você: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, além de pastas separadas para GPTQ, AWQ e EXL2 em meia dúzia de configurações de bits. Você faz a conta de cabeça para o arquivo "4 bits": 4 bits × 8 bilhões de parâmetros ÷ 8 = 4 GB. Mas o arquivo diz 4,6 GB. E depois de carregá-lo, o modelo usa mais memória do que isso.
Os nomes dos arquivos não são ruído. Eles codificam informações reais e aprendíveis sobre a largura de bits, o runtime que os carrega e o hardware de que precisam. As tabelas de dimensionamento que você já leu dizem que um modelo de 70B precisa de aproximadamente 40 GB, útil, mas elas nunca decodificam o formato em si nem explicam por que o modelo em execução quer mais memória do que o arquivo no disco.
Então aqui está o plano: decodificar a convenção de nomenclatura GGUF (com as larguras de bits reais, não as nominais), descobrir qual dos quatro formatos o seu hardware consegue realmente rodar, e contabilizar o único custo de memória invisível em qualquer tamanho de arquivo, o cache KV. Ao final, você conseguirá ler um repositório de modelo e prever como ele se comportará ao carregar.
TL;DR
- Os níveis de quantização GGUF são larguras de bits efetivas, não o número exato no nome. Q4_K_M é cerca de 4,89 bits por peso, e é por isso que um arquivo "4 bits" de 8B chega perto de 4,6 GiB em vez da estimativa ingênua de 4 bits.
- GGUF é a opção mais portátil porque o llama.cpp consegue rodá-lo em CPU, GPU ou uma configuração híbrida. GPTQ, AWQ e EXL2 são mais específicos de GPU e runtime, com o EXL2 especialmente atrelado a fluxos de trabalho NVIDIA/CUDA.
- O cache KV é separado dos pesos do modelo, e ele cresce com o comprimento do contexto. É por isso que um modelo que carrega perfeitamente ainda pode falhar por falta de memória quando a conversa fica longa.
- Acima da faixa de 5 bits, a perda de qualidade costuma ser pequena. Em torno de Q4, a troca ainda é prática para muitos casos de uso local. Abaixo de 4 bits, o custo de qualidade se torna bem mais perceptível. Q4_K_M continua sendo um padrão comum da comunidade, enquanto Q5_K_M e Q6_K são mais seguros quando você tem memória sobrando.
O que significa Q4_K_M em um nome de arquivo GGUF?

Um nome de quantização GGUF segue o padrão Q[bits]_[K]_[S/M/L]. O número é o alvo bits por peso, K significa que é um "K-quant" que armazena fatores de escala por pequeno bloco de pesos, e o S, M ou L final é o nível de tamanho/qualidade (small, medium, large). Como os K-quants armazenam uma escala e um valor mínimo para cada bloco junto com os pesos, a largura de bits efetiva de bits é maior do que o número no nome. Q4_K_M chega a cerca de 4,89 bits por peso, não 4.
Essa diferença é toda a resposta para a pergunta "por que meu arquivo de 4 bits tem 4,6 GB?". A estimativa ingênua presume que cada peso custa exatamente 4 bits. Na realidade, os K-quants gastam bits extras por bloco nos metadados que tornam a quantização de baixo bit precisa, a escala e o mínimo por bloco que permitem ao runtime reconstruir cada peso. Multiplique 4,89 bits por 8 bilhões de pesos e você chega perto de 4,58 GiB, que é o que o arquivo realmente pesa.
Aqui estão as larguras de bits efetivas medidas e os tamanhos de arquivo, retirados do llama.cpp quantize documentation para o Llama 3.1 8B como modelo de referência, junto com o custo de perplexidade de cada nível medido no artigo de avaliação de quantização do llama.cpp (arXiv:2601.14277) no Llama-3.1-8B-Instruct:
| Nível GGUF | BPW efetivo | ~Tamanho do arquivo (8B) | Perplexidade vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | linha de base |
*Os números de perplexidade são específicos do Llama-3.1-8B-Instruct do arXiv:2601.14277. A coluna de BPW/tamanho de arquivo e a coluna de perplexidade vêm de duas fontes diferentes medidas separadamente, então leia a tabela como uma referência prática lado a lado, e não como uma única execução de benchmark. A degradação específica de cada tarefa varia, o raciocínio matemático tende a sofrer mais do que o raciocínio de senso comum em larguras de bits baixas, mas o padrão geral se mantém: 5 bits ou mais costuma ser mais seguro, Q4 é a zona de compressão prática, e 3 bits é onde a perda de qualidade se torna muito mais difícil de ignorar.
Na prática: Q4_K_M é o padrão que a maioria das pessoas deveria buscar, Q5_K_M e Q6_K são as escolhas voltadas à qualidade quando você tem memória sobrando, e qualquer coisa em Q3_K_S ou abaixo é um último recurso para hardware que realmente não consegue acomodar mais.
Qual formato de quantização você deve baixar: GGUF, GPTQ, AWQ ou EXL2?

GGUF é o mais portátil dos quatro: roda em CPU, GPU ou uma combinação híbrida de ambos via llama.cpp, então é a escolha mais segura quando você não tem certeza do que seu hardware consegue suportar. GPTQ, AWQ e EXL2 são mais específicos de GPU e runtime. Na prática, são mais comuns em configurações NVIDIA/CUDA, mas o suporte a GPTQ e AWQ pode variar conforme o carregador e a stack de serviço; o vLLM, por exemplo, separa o suporte à quantização por hardware e implementação. Se você está rodando localmente em um Mac, uma placa AMD, ou uma máquina só com CPU, o GGUF ainda é a resposta mais segura. Se você tem uma GPU NVIDIA e quer os tokens mais rápidos possíveis, os outros três entram em jogo.
| Formato | Hardware/runtime | Velocidade (relativa) | VRAM comparada aos pares | Melhor para |
|---|---|---|---|---|
| GGUF Q4_K_M | O mais amplo, CPU, GPU ou híbrido via llama.cpp | Moderado | O mais baixo | Qualquer hardware; padrão local |
| GPTQ 4 bits | Geralmente com foco em CUDA/GPU; depende do runtime | Rápido (ExLlama) | Média | Focado em GPU, ferramentas legadas |
| AWQ 4 bits | Geralmente com foco em CUDA/GPU; depende do runtime | Rápido | Mais alto | Serviço vLLM/TGI, carregamento rápido |
| EXL2 ~4,9 bpw | Focado em NVIDIA/CUDA | Mais rápido | Baixo-Médio | Velocidade máxima em NVIDIA |
Uma ressalva sobre essa tabela: as classificações de velocidade e VRAM vêm do benchmark do oobabooga, que rodou em hardware da era 2023/2024. Trate a relativa ordem relativa como duradoura. O EXL2 é construído para velocidade, o AWQ troca VRAM por carregamento rápido, o GGUF permanece enxuto e portátil, mas não leia os números absolutos originais de tokens por segundo como atuais. Uma GPU de 2026 vai apresentar um throughput bruto muito diferente; é a ordem de hierarquia que se mantém.
Então a regra de decisão que se extrai disso: se você tem uma placa NVIDIA e se importa acima de tudo com velocidade, EXL2; se quer o padrão local mais seguro entre hardwares diferentes, GGUF. AWQ e GPTQ importam principalmente quando uma stack de serviço específica (vLLM, TGI) ou ferramentas já existentes te levam para lá.
Por que um LLM local usa mais memória do que seu arquivo?
O tamanho do arquivo é apenas os pesos do modelo. No runtime, você também paga pelo cache KV (o estado de atenção para cada token na sua janela de contexto), pelas ativações (a matemática intermediária de um forward pass) e pelo overhead do framework e do driver. Juntas, as partes que não são peso costumam adicionar de 10 a 20% em cima dos pesos numa configuração de usuário único, e o cache KV sozinho pode ofuscar tudo quando o contexto fica longo. Um arquivo de 4,6 GB pode precisar de bem mais do que 4,6 GB de memória para rodar.
Pense na memória de runtime como quatro componentes empilhados um sobre o outro:
- Pesos do modelo. O arquivo que você baixou. Essa é a única parte visível antes de você carregar.
- Cache KV. Estado de atenção para a janela de contexto. Pequeno em contexto curto, enorme em contexto longo. Essa é a próxima seção, porque é a que surpreende as pessoas.
- Ativações. A memória de trabalho de um forward pass. Para inferência local de fluxo único (batch size 1), isso é pequeno, tipicamente algumas centenas de megabytes.
- Overhead do framework. A pegada própria do runtime mais o contexto do driver da GPU. Para um runtime local leve, isso pode ser pequeno comparado aos pesos do modelo e ao cache KV; frameworks de serviço mais pesados podem reservar muito mais. A reserva de memória do próprio sistema operacional fica fora disso e é, novamente, separada.
Os pesos e o overhead do framework são previsíveis. O cache KV é a variável que transforma um modelo que "cabe" em um modelo que trava, então vale a pena trabalhar com a matemática real.
Quanta memória o cache KV usa?
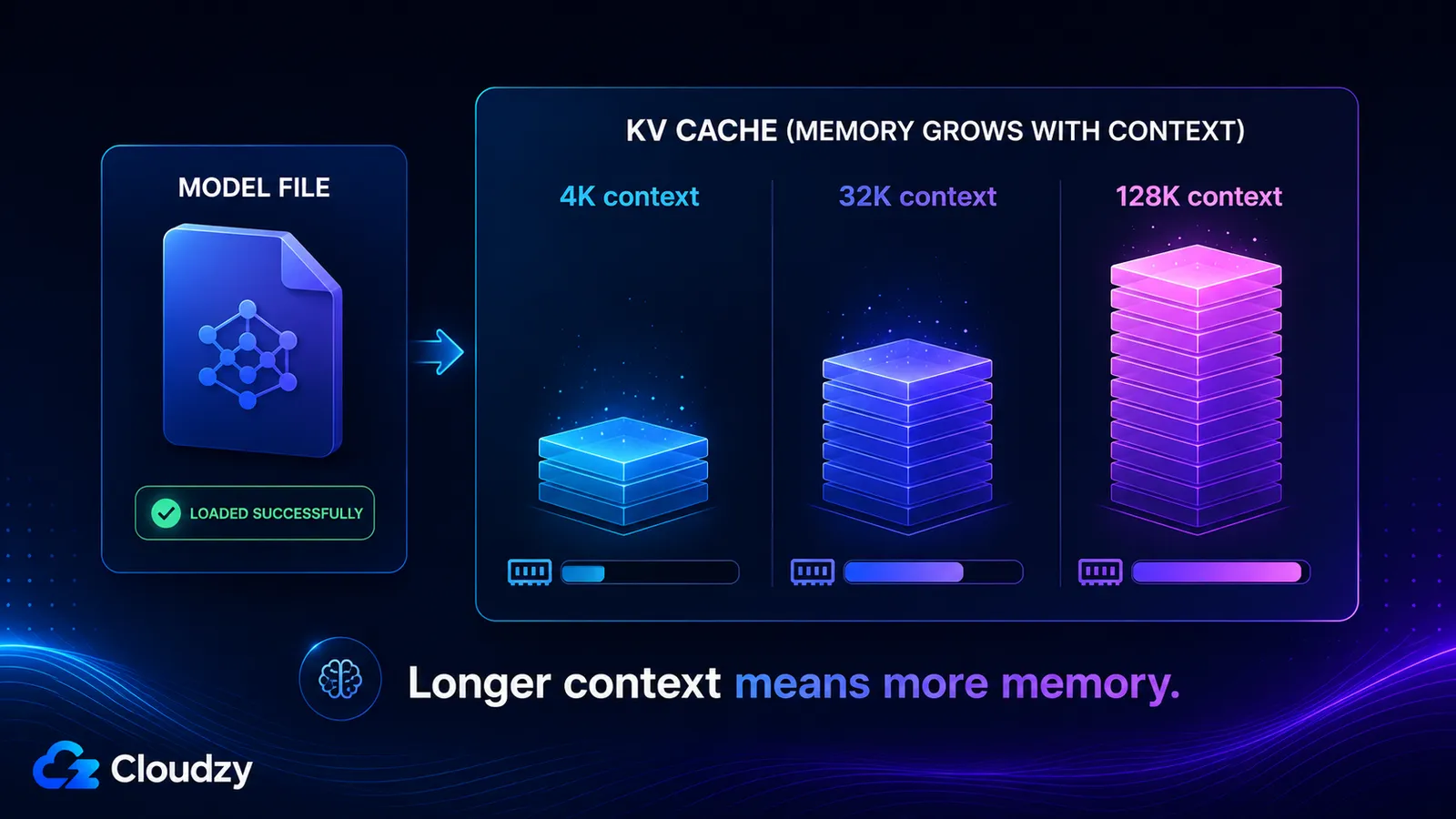
O cache KV armazena os vetores de chave e valor para cada token na sua janela de contexto, então cresce de forma aproximadamente linear com o comprimento do contexto e é completamente separado dos pesos do modelo. Seu tamanho é determinado pelo número de camadas do modelo, pelo número de cabeças KV, pela dimensão da cabeça, pelo comprimento do contexto e pela precisão do cache. Ative um contexto longo e você pode adicionar dezenas de gigabytes que um modelo que carregou bem nunca te avisou sobre.
A fórmula é curta o suficiente para guardar de cabeça:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
O 2 inicial é para os dois tensores armazenados por token, um para chaves, um para valores. bytes_per_element é 2 para um cache FP16. O resto são constantes de arquitetura que você pode ler no model card.
Faça isso para o Llama 3.1 8B, que tem 32 camadas, 8 cabeças KV e uma dimensão de cabeça de 128. Em um contexto de 4.096 tokens, batch size 1, cache FP16:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Aumente o contexto e o número aumenta junto, porque todo termo exceto context_tokens é fixo:
- Contexto de 4K: ~536 MB
- Contexto de 32K: ~4,3 GB
- Contexto de 128K: ~17 GB
Esses dois últimos são o motivo pelo qual um modelo pode declarar uma janela de contexto de 128K, carregar sem problemas, e depois esgotar a memória no momento em que você realmente usa essa janela. O cache KV em contexto completo é maior do que os próprios pesos quantizados.
Aqui está a parte que torna os modelos modernos de contexto longo possíveis: o Llama 3.1 8B usa Grouped Query Attention (GQA)usa isso. Ele tem 32 cabeças de consulta, mas apenas 8 cabeças KV, o cache armazena vetores de chave/valor para 8 cabeças, não 32. Rode a mesma fórmula com 32 cabeças KV (o design mais antigo de Multi-Head Attention, onde as cabeças KV são iguais às de consulta) e cada número acima se multiplica por 4. Aqueles 17 GB em 128K viram 68 GB. O GQA é a razão arquitetural pela qual a matemática continua sobrevivível à medida que as janelas de contexto cresceram.
O tamanho do arquivo não é o seu orçamento de memória. Quando os pesos ou o cache KV não cabem mais no caminho de memória rápida e o runtime tem que recorrer à RAM de sistema via PCIe, o throughput não degrada suavemente. Ele despenca assim que você está movendo dados pelo PCIe a cada token. Planeje a memória de modo que os pesos e o cache KV no seu comprimento de contexto real caibam, não apenas os pesos.
Como você escolhe uma quantização para sua GPU ou Mac?
Comece pelo seu hardware e runtime. Donos de GPU NVIDIA têm o menu mais amplo e devem considerar EXL2 para velocidade bruta ou GGUF para portabilidade. Se você está em AMD, Apple Silicon, hardware apenas com CPU, ou uma configuração mista, o GGUF via llama.cpp costuma ser o ponto de partida mais seguro. A partir daí, escolha o nível de quantização mais alto que caiba depois de você ter orçado o cache KV no comprimento de contexto que você realmente usa, não o máximo do modelo.
Uma armadilha do Apple Silicon que vale a pena conhecer: a GPU não recebe toda a sua memória unificada (veja nosso artigo complementar sobre o que a memória unificada realmente é para o panorama completo de como esse pool compartilhado funciona). A comunidade de auto-hospedagem tem documentado um limite de cerca de 75% da memória unificada total disponível para a GPU (isso não é confirmado oficialmente pela Apple e pode mudar com atualizações do macOS). Então um "Mac de 64 GB" é, na prática, ~48 GB para o modelo mais seu cache KV, planeje com base no número menor.
Este artigo trata de ler o formato e prever seu comportamento em runtime: decodificar o nome da quantização, escolher o formato que seu hardware suporta, e orçar o cache KV separadamente dos pesos. Combinar um modelo específico com uma quantidade específica de memória, a tabela de referência de tamanho para memória, é uma questão relacionada, mas separada, que abordaremos em um futuro artigo complementar.
Leia o repositório
Agora você pode olhar para a página de um modelo e lê-la em vez de adivinhar. Decodifique o nome da quantização para sua largura de bits efetiva, reconheça que o GGUF é o formato local mais amplo, enquanto GPTQ, AWQ e EXL2 são mais específicos de runtime, e lembre-se de que o tamanho do arquivo é apenas o piso, o cache KV se empilha em cima e cresce com seu contexto. Abra os arquivos do modelo que você quer, escolha o formato que seu hardware consegue rodar, escolha o nível de quantização mais alto que caiba depois de deixar espaço para o cache KV no seu comprimento de contexto real, e você evitará o travamento por falta de memória que deu origem a toda essa questão.
Perguntas frequentes
O que significa Q4_K_M?
Q4_K_M é um nível de quantização GGUF: aproximadamente 4 bits por peso (Q4), usando escalonamento K-quant por bloco (K), no nível médio de tamanho/qualidade (M). Sua efetiva largura de bits é de cerca de 4,89 bits por peso, não exatamente 4, porque os K-quants armazenam uma escala e um valor mínimo para cada bloco de pesos. É por isso que o arquivo de um modelo "4 bits" de 8B fica em torno de 4,6 GB em vez de 3,5 GB.
A quantização reduz a qualidade do LLM?
Sim, mas o custo depende muito de quão longe você leva isso. No Llama-3.1-8B-Instruct medido no arXiv:2601.14277, a perplexidade aumenta apenas cerca de 0,4% em Q6_K e permanece perto de 1% ao longo da faixa Q5. Caindo para Q4, o aumento ainda é modesto (alguns pontos percentuais); abaixo de Q3_K_M ela sobe abruptamente, chegando a +22% em Q3_K_S. Para a maioria dos usos, Q4_K_M e acima é efetivamente sem perdas; a penalidade acentuada fica em 3 bits e abaixo.
Qual é a diferença entre GGUF, GPTQ, AWQ e EXL2?
GGUF (rodado pelo llama.cpp) é o formato portátil, funciona em CPU, GPU ou uma configuração híbrida em uma ampla gama de hardware. GPTQ, AWQ e EXL2 são mais específicos de GPU e runtime. Em 4 bits, os quatro podem cair numa faixa estreita de qualidade, então a diferença prática está no hardware, no suporte de carregadores, na velocidade e no uso de VRAM: o EXL2 é a escolha focada em velocidade para NVIDIA/CUDA, o AWQ é comum em stacks de serviço, o GPTQ se encaixa em ferramentas de GPU e repositórios de modelo mais antigos, e o GGUF continua sendo a opção local mais portátil.
Por que meu LLM local usa mais memória do que o arquivo?
O tamanho do arquivo é apenas os pesos do modelo. No runtime, você também paga pelo cache KV (estado de atenção para cada token na janela de contexto), pelas ativações, e pelo overhead do framework mais o driver. O cache KV costuma ser o culpado quando a diferença é grande, porque ele cresce com o comprimento do contexto e é alocado separadamente dos pesos, um modelo cujo arquivo tem alguns gigabytes pode precisar de muito mais memória assim que você define um contexto longo.
Como o comprimento do contexto afeta o uso de memória?
O cache KV cresce de forma aproximadamente linear com o comprimento do contexto, então dobrar seu contexto aproximadamente dobra o cache. Para o Llama 3.1 8B, o cache é de cerca de 536 MB em 4K tokens, ~4,3 GB em 32K, e ~17 GB em 128K (FP16, fluxo único). Esse crescimento é totalmente separado dos pesos do modelo, e é por isso que declarar uma janela de contexto longa pode levar um modelo à falta de memória mesmo que ele tenha carregado bem.


