
Substitua GPT-5 por Claude dentro de um agent em funcionamento e, na maioria das vezes, quase nada muda. Altere a forma como ele lida com tentativas repetidas, o que você insere na janela de contexto, ou quando ele decide parar, e o agent inteiro se comporta de forma diferente. Essa diferença é o sinal: o modelo é a menor e mais substituível parte de um agent em funcionamento. A engenharia interessante está em tudo que o envolve.
Esse wrapper agora tem um nome. Os profissionais adotaram "harness" para a camada que transforma um gerador de texto em algo que executa ações ao longo do tempo em vez de rodar um script fixo. O termo se espalhou rapidamente pelo Twitter e blogs de engenharia no início de 2026, o que significa que também foi usado de forma imprecisa, com a mesma palavra fazendo trabalhos ligeiramente diferentes em cada artigo que você lê. Este artigo define com precisão: o que é um harness, do que ele é feito, como ele difere de um "framework" e de um "scaffold", e por que a maior parte da qualidade do seu agent está escondida no harness, não no modelo.
A versão curta
- Um agent harness é o software ao redor de um LLM que gerencia o loop de execução, ferramentas, memória, contexto, estado, tratamento de erros e barreiras de segurança. O modelo gera texto; o harness decide o que o modelo vê, o que ele pode fazer, quando parar e o que acontece quando algo quebra.
- Em produção, a chamada ao modelo é frequentemente a menor parte visível da superfície do sistema. Um modelo mais fraco em um harness bem construído pode superar um modelo mais forte em um descuidado, especialmente em tarefas longas e com muitas ferramentas.
- Um harness tem aproximadamente nove a onze componentes recorrentes. A maioria deles são coisas que o modelo nunca toca diretamente.
- "Harness" não é o mesmo que "framework". Um framework (LangGraph, um agents SDK) é a biblioteca com a qual você constrói; o harness é a camada em execução que essa biblioteca ajuda você a montar.
O que é um Agent Harness?
Um agent harness é a infraestrutura de software que envolve um modelo de linguagem e gerencia o loop de execução, acesso a ferramentas, memória, contexto, persistência de estado, tratamento de erros e barreiras de segurança. O modelo gera texto. O harness decide o que o modelo vê em cada turno, quais ações pode tomar, quando para e o que acontece quando uma etapa falha.
A formulação mais clara vem do LangChain, que o reduz a uma equação: Agent = Model + Harness. O modelo contribui com a inteligência. O harness é o que faz essa inteligência agir no mundo real.
"Um harness é todo o código, configuração e lógica de execução que não é o próprio modelo."
— LangChain, A anatomia de um harness de agente
Acho que o limite é mais fácil de perceber através de uma pergunta: quando seu agente faz a coisa errada, o raciocínio próprio do modelo estava errado, ou o sistema ao redor entregou ao modelo o contexto errado, as ferramentas erradas, ou nenhuma forma de se recuperar? Na maioria das vezes, em um sistema real, é o segundo. O modelo raciocinou bem sobre entradas ruins. O harness é o que controla as entradas.
Ponto-chave: O modelo gera; o harness governa. Essa divisão é o conceito inteiro.
Quais são os componentes de um harness de agente?
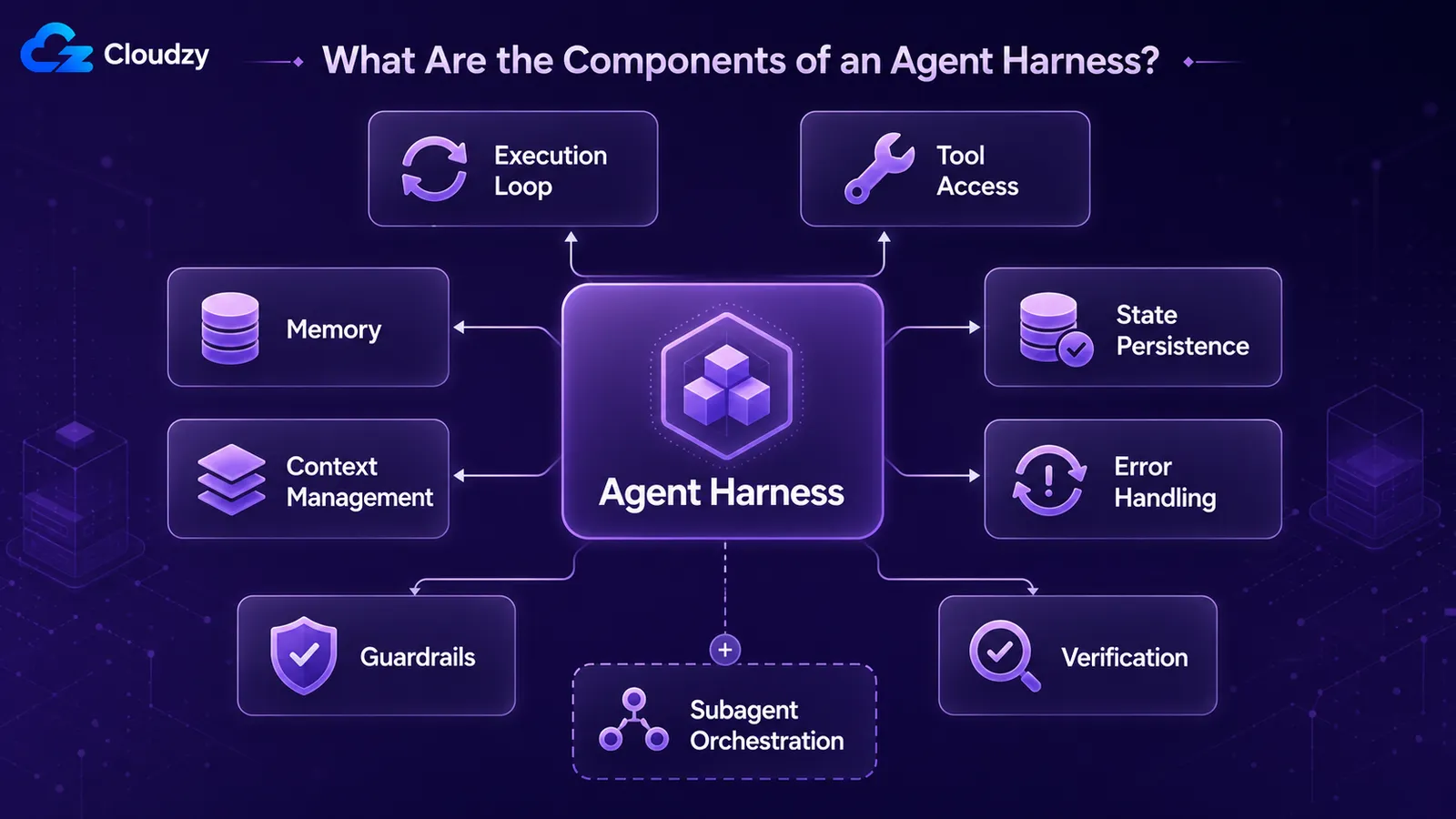
Todo harness de produção monta as mesmas partes recorrentes: um loop de execução que conduz o modelo turno a turno, acesso a ferramentas que permite que ele aja, memória entre turnos, gerenciamento de contexto para o que ele vê agora, persistência de estado para que o trabalho sobreviva entre sessões, tratamento de erros para etapas com falha e barreiras de segurança que restringem o que ele pode fazer. Os sistemas de produção adicionam loops de verificação e orquestração de subagentes.
Um inventário útil, extraído de como os profissionais descrevem sistemas reais:
- Loop de execução / controle: o que impulsiona o agente turno a turno. Chamar o modelo, ler sua saída, executar a ferramenta solicitada, devolver o resultado, repetir até a condição de parada.
- Acesso a ferramentas: as funções, APIs, execução de código e sistema de arquivos que o modelo pode acessar.
- Memória: o que o agente retém entre turnos e entre sessões.
- Gerenciamento de contexto: o que é carregado na janela do modelo a cada turno e o que é compactado quando transborda.
- Persistência de estado / checkpointing: salvar o estado do agente para que uma execução com falha ou pausada possa ser retomada.
- Tratamento de erros: tentativas, fallbacks e recuperação quando uma chamada a uma ferramenta ou ao modelo falha.
- Proteções: limites sobre o que o agente pode fazer, como ferramentas permitidas, limites de etapas e validação de saída.
- Loops de verificação: o agente (ou o harness) verifica seu próprio trabalho antes de declará-lo concluído.
- Orquestração de subagentes: criar, delegar e coletar resultados de subagentes em tarefas maiores.
Nem todos estes são universais. O loop de execução, ferramentas, tratamento de contexto e tratamento de erros aparecem até em um protótipo de fim de semana. Persistência de estado, verificação e orquestração de subagentes são onde protótipos e sistemas de produção se separam. Um protótipo pode ignorá-los; um agente de produção de longa duração não pode. O texto da Anthropic sobre agentes de longa duração é um guia das partes exclusivas de produção: como um agente reconstrói seu entendimento a partir de um arquivo de progresso após a reinicialização de sua janela de contexto, e como os testes são integrados ao loop.
Para quem quer a ponte acadêmica, um recente levantamento de arquiteturas de agentes dobra a mesma maquinaria em uma tupla formal menor de componentes principais. A lista do profissional e o enquadramento da pesquisa são dois níveis de zoom na mesma estrutura: a pesquisa comprime, o inventário acima expande. Trate a contagem de nove a onze como os componentes que a maioria dos harnesses de produção compartilha, não um padrão ratificado; o campo ainda não ratificou nada.
Ponto-chave: A maioria das partes móveis de um agente reside no harness, não no modelo. O modelo é um componente entre muitos.
Por que o harness importa mais do que o modelo?
Um modelo mais fraco dentro de um harness bem projetado frequentemente supera um modelo mais forte em um mal projetado. O motivo é mecânico, não mágico: a confiabilidade end-to-end de um agente é o produto da confiabilidade de cada etapa, e a maioria dessas etapas (seleção de ferramentas, montagem de contexto, recuperação de erros) é responsabilidade do harness, não do modelo. Melhore-as e toda a cadeia se torna mais confiável, independentemente do modelo que esteja dentro.
A aritmética torna isso concreto. Suponha que cada etapa em uma tarefa de dez etapas seja bem-sucedida 99% das vezes. O sucesso end-to-end não é 99%. É 0,99 elevado à décima potência, cerca de 90%. Leve cada etapa a 99,9% e o end-to-end salta para aproximadamente 99%. A confiabilidade por etapa se acumula, e a confiabilidade por etapa é esmagadoramente uma propriedade do harness. É por isso que otimizar o tratamento de erros e o gerenciamento de contexto compensa mais do que substituir por um modelo meio ponto melhor em algum benchmark.
Há sinal de produção apontando na mesma direção. MongoDB, citando o estudo de caso da Vercel, relata que a Vercel cortou a maior parte das ferramentas do seu agente e viu sua taxa de sucesso subir acentuadamente no mesmo modelo, com um harness menor e mais limpo. Leia isso como evidência convergente, não como prova: é um caso de produção, não um experimento controlado, mas aponta na mesma direção que a aritmética composta e o trabalho de pesquisa acima.
Esta é a heurística à qual continuo voltando como engenheiro de plataforma: o contexto é o gargalo, não a capacidade bruta do modelo, e os andaimes construídos para cobrir as lacunas atuais do modelo tendem a ser absorvidos à medida que os modelos melhoram. Construa as partes duráveis do harness (o loop, o estado, a recuperação) e deixe o modelo subjacente melhorar no seu próprio ritmo.
Ponto-chave: Quando seu agente falhar, suspeite do harness antes do modelo. As probabilidades favorecem isso.
Qual é a diferença entre um harness, um scaffold e um framework?
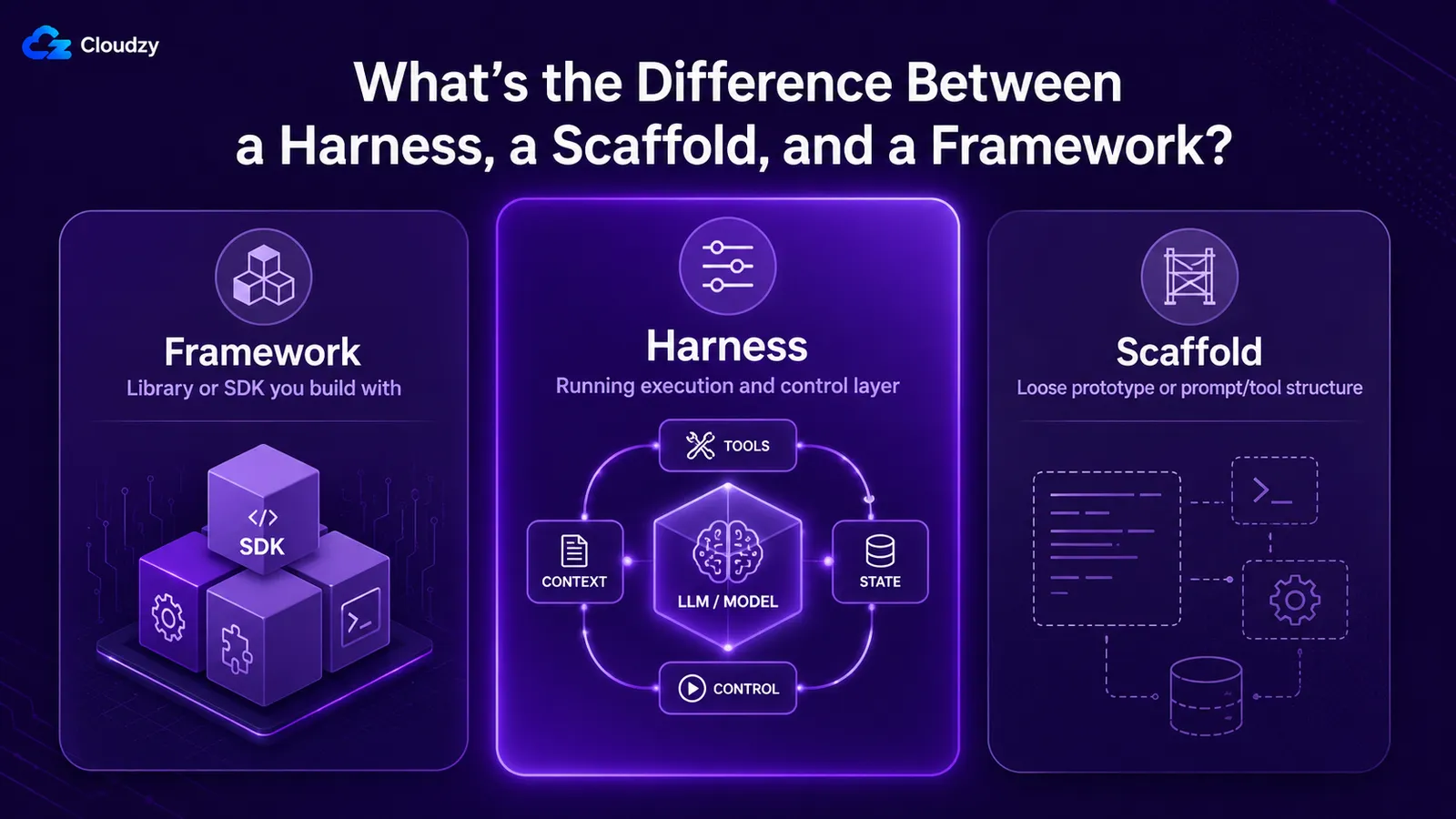
Esses três são usados de forma intercambiável, e não deveriam ser. A framework é a biblioteca ou SDK com que você constrói, como LangGraph ou um agents SDK. Um harness é a camada de execução e governança em execução ao redor do modelo, que um framework ajuda a montar. Um scaffold é o mais flexível dos três: às vezes quase sinônimo de harness, às vezes a versão protótipo de um, às vezes especificamente a camada de prompt e descrição de ferramentas.
O vocabulário está genuinamente indefinido, e o mais claro a fazer é mapear os usos em vez de legislar um. O da HuggingFace Glossário de Agentes diz isso diretamente:
"Muitos desses termos ainda não têm definições universalmente aceitas, e diferentes frameworks usam a mesma palavra de maneiras diferentes."
— HuggingFace, Glossário de Agentes
| Termo | O que se refere | Relação |
|---|---|---|
| Framework | A biblioteca ou SDK com que você constrói (LangGraph, um SDK de agentes) | Uma ferramenta para montar um harness |
| Harness | A camada em execução ao redor do modelo: loop, ferramentas, contexto, estado, guardrails | O que você entrega e executa |
| Scaffold | Usado de forma ampla: quase sinônimo de harness, ou a versão em nível de protótipo / camada de prompt | Sobrepõe-se ao harness; menos preciso |
| Loop | O ciclo de execução dentro do harness | Um componente do harness |
A conclusão prática para raciocinar sobre o seu próprio sistema: quando alguém diz "framework", pergunte se eles querem dizer a biblioteca ou a coisa em execução. Quando alguém diz "scaffold", pergunte se eles querem dizer o harness inteiro ou apenas a camada de prompt-e-ferramenta. A desambiguação é o valor aqui, não uma reivindicação à palavra final.
Como o LangGraph Implementa o Padrão Harness?
LangGraph é uma implementação Python de código aberto popular do padrão harness. Ele modela a execução do agente como um grafo dirigido de nós e arestas, com estado tipado fluindo entre eles e cada transição que pode ser checkpointada. Se os componentes abstratos acima parecem escorregadios, o LangGraph é um lugar para vê-los tomar forma concreta em uma ferramenta real.
O mapeamento é próximo de um para um. Os nós e as arestas são o loop de execução: cada nó faz trabalho, cada aresta decide para onde o controle vai a seguir. O objeto de estado tipado passado entre nós é o componente context-and-state tornado explícito. O checkpointing (LangGraph persiste o estado através de savers como sua implementação baseada em Postgres) é o componente de persistência de estado. Um limite de etapas configurável é um guardrail de condição de parada, impedindo que um agente com comportamento inadequado fique em loop para sempre. Os mesmos componentes, nomeados e conectados por uma biblioteca específica.
Se você quiser executar um agente LangGraph em seu próprio servidor, o tempo todo, essa é uma questão de deployment em vez de conceitual. Veja nosso guia de Linux VPS para esse caminho. Aqui, LangGraph é apenas o exemplo trabalhado: prova de que "loop de execução", "persistência de estado" e "guardrail" não são abstrações, são coisas que você pode apontar em código real.
Perguntas frequentes
O que é um Agent Harness?
Um agent harness é o software em torno de um modelo de linguagem que o transforma em um agente. Ele gerencia o loop de execução, acesso a ferramentas, memória, contexto, persistência de estado, tratamento de erros e guardrails. O modelo gera texto; o harness decide o que o modelo vê, o que ele pode fazer, quando parar e o que acontece quando algo falha.
Um harness de agente é o mesmo que um framework de agente?
Não. Um framework é a biblioteca ou SDK com o qual você constrói, como LangGraph ou um agents SDK. O harness é a camada de execução e governança em execução ao redor do modelo (o loop, ferramentas, contexto, estado e guardrails) que um framework ajuda você a montar. Você usa um framework para construir um harness.
Quais componentes todo agent harness possui?
A maioria dos harnesses compartilha um núcleo recorrente: um loop de execução, acesso a ferramentas, memória, gerenciamento de contexto, persistência de estado, tratamento de erros e guardrails. Harnesses de produção adicionam loops de verificação e orquestração de subagentes. Protótipos podem pular as partes exclusivas de produção, mas o loop, ferramentas, tratamento de contexto e tratamento de erros aparecem quase em todo lugar.
O que significa "O LLM é a menor parte do seu sistema de agente"?
Significa que a maior parte do comportamento e da confiabilidade de um agente vem do harness, não do modelo. A confiabilidade de ponta a ponta é o produto da taxa de sucesso de cada etapa, e a maioria das etapas são trabalho de harness. A MongoDB, citando o estudo de caso da Vercel, relata um salto na taxa de sucesso apenas por mudanças no harness, no mesmo modelo. Isso é evidência de que corrigir o harness supera corrigir o modelo.
Onde Vive a Qualidade do Seu Agente
O harness é onde vive a maior parte da qualidade de um agente, e agora você tem o vocabulário para localizar problemas em seu próprio sistema. Você pode definir um harness, nomear seus componentes, distingui-lo de um framework e um scaffold, e raciocinar sobre se uma determinada falha é um problema do modelo ou um problema do harness.
Então, na próxima vez que seu agente se comportar mal, audite primeiro a camada harness: o contexto que você está fornecendo, as ferramentas que você expôs, as condições de parada que você definiu, a forma como ele se recupera de um passo com falha. Busque um modelo maior somente após essa camada ser verificada. Na maioria das vezes, não será necessário.


