
تفتح صفحة GGUF لنموذج شهير على Hugging Face فتجد خمسة عشر ملفًا تحدّق بك: Q4_0، Q4_K_S، Q4_K_M، Q5_K_M، Q6_K، Q8_0، بالإضافة إلى مجلدات منفصلة لـ GPTQ وAWQ وEXL2 بنصف دزينة من إعدادات البتات. تجري حسابًا سريعًا للملف "4-bit": 4 بت × 8 مليار معلمة ÷ 8 = 4 GB. لكن الملف يقول 4.6 GB. وبمجرد تحميله، يستخدم النموذج ذاكرة أكثر من ذلك.
أسماء الملفات ليست ضوضاء. إنها ترمّز معلومات حقيقية وقابلة للتعلم حول عرض البتات، وبيئة التشغيل التي تحمّلها، والعتاد الذي تحتاجه. تخبرك جداول تحديد الحجم التي قرأتها أن نموذج 70B يحتاج نحو 40 GB، وهذا مفيد، لكنها لا تفكّ رموز الصيغة نفسها أبدًا ولا تشرح لماذا يريد النموذج قيد التشغيل ذاكرة أكثر من الملف الموجود على القرص.
إليك الخطة إذًا: فك رموز اصطلاح تسمية GGUF (بعرض البتات الحقيقي، لا الاسمي)، وتحديد أي من الصيغ الأربع يستطيع عتادك تشغيله فعليًا، ومراعاة التكلفة الذاكرية الوحيدة غير المرئية في أي حجم ملف، وهي ذاكرة KV cache. بنهاية المقال ستستطيع قراءة مستودع نموذج وتوقّع سلوكه عند التحميل.
الخلاصة السريعة
- مستويات تكميم GGUF هي عرض بتات فعلي، وليست الرقم الدقيق في الاسم. Q4_K_M يبلغ نحو 4.89 بت لكل وزن، ولهذا فإن ملف 8B "4-bit" يقع عند نحو 4.6 GiB بدلًا من التقدير الساذج بـ4-bit.
- GGUF هو الخيار الأكثر قابلية للنقل لأن llama.cpp يستطيع تشغيله على CPU أو GPU أو إعداد هجين. أما GPTQ وAWQ وEXL2 فهي أكثر ارتباطًا بـ GPU وبيئة التشغيل، مع ارتباط EXL2 تحديدًا بسير عمل NVIDIA/CUDA.
- ذاكرة KV cache منفصلة عن أوزان النموذج، وتنمو مع طول السياق. وهذا هو السبب في أن نموذجًا يُحمَّل بسلاسة قد ينهار بسبب نفاد الذاكرة بمجرد أن تطول المحادثة.
- فوق نطاق 5-bit، عادة ما يكون فقدان الجودة صغيرًا. عند مستوى Q4، لا تزال المقايضة عملية للعديد من حالات الاستخدام المحلية. تحت 4-bit، يصبح ثمن الجودة أكثر وضوحًا بكثير. يبقى Q4_K_M خيارًا افتراضيًا شائعًا لدى المجتمع، بينما يُعد Q5_K_M وQ6_K أكثر أمانًا عندما تملك ذاكرة إضافية.
ماذا يعني Q4_K_M في اسم ملف GGUF؟

يتبع اسم تكميم GGUF النمط Q[bits]_[K]_[S/M/L]. الرقم هو عدد البتات المستهدف لكل وزن، وK تعني أنه "K-quant" يخزّن عوامل قياس لكل كتلة صغيرة من الأوزان، وحرف S أو M أو L في النهاية هو فئة الحجم/الجودة (صغيرة، متوسطة، كبيرة). ولأن K-quants تخزّن قيمة مقياس وقيمة دنيا لكل كتلة إلى جانب الأوزان، فإن عرض البتات الفعلي أعلى من الرقم الرئيسي المعلن. Q4_K_M يقع عند نحو 4.89 بت لكل وزن، لا 4.
هذه الفجوة هي الإجابة الكاملة عن سؤال "لماذا يبلغ حجم ملفي 4-bit هو 4.6 GB؟". يفترض التقدير الساذج أن كل وزن يكلف 4 بتات بالضبط. في الواقع، تنفق K-quants بتات إضافية لكل كتلة على البيانات الوصفية التي تجعل التكميم منخفض البتات دقيقًا، أي المقياس والقيمة الدنيا لكل كتلة التي تتيح لبيئة التشغيل إعادة بناء كل وزن. اضرب 4.89 بت في 8 مليار وزن فتصل إلى نحو 4.58 GiB، وهو الوزن الفعلي للملف.
إليك عروض البتات الفعلية وأحجام الملفات المقاسة، مأخوذة من llama.cpp quantize documentation لنموذج Llama 3.1 8B كنموذج مرجعي، إلى جانب تكلفة الحيرة (perplexity) لكل مستوى مقاسة في ورقة تقييم تكميم llama.cpp (arXiv:2601.14277) على Llama-3.1-8B-Instruct:
| مستوى GGUF | BPW الفعلي | ~حجم الملف (8B) | الحيرة (Perplexity) مقابل F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3.4 GiB | +22% |
| Q3_K_M | 3.95 | ~3.7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4.0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4.4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4.6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5.3 GiB | +1.1% |
| Q6_K | 6.56 | ~6.1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8.0 GiB | +0.1% |
| F16 | 16.00 | ~15.0 GiB | الأساس المرجعي |
*أرقام الحيرة (perplexity) خاصة بنموذج Llama-3.1-8B-Instruct من arXiv:2601.14277. عمود BPW/حجم الملف وعمود الحيرة يأتيان من مصدرين مختلفين قيسا بشكل منفصل، لذا اقرأ الجدول كمرجع عملي جنبًا إلى جنب لا كنتيجة تشغيل معيار أداء واحد. يتفاوت التدهور بحسب المهمة، إذ يميل الاستدلال الرياضي للمعاناة أكثر من الاستدلال المنطقي البسيط عند عرض البتات المنخفض، لكن الشكل العام يظل صحيحًا: 5-bit فما فوق عادة أكثر أمانًا، وQ4 هي منطقة الضغط العملية، و3-bit هي حيث يصبح فقدان الجودة أصعب بكثير على التجاهل.
عمليًا: Q4_K_M هو الخيار الافتراضي الذي ينبغي لمعظم الناس اللجوء إليه، وQ5_K_M وQ6_K هما الخياران المائلان نحو الجودة عندما تملك ذاكرة إضافية، وأي شيء عند Q3_K_S أو أدنى هو ملاذ أخير للعتاد الذي لا يستطيع فعليًا استيعاب المزيد.
أي صيغة تكميم يجب أن تنزّلها: GGUF أم GPTQ أم AWQ أم EXL2؟

GGUF هو الأكثر قابلية للنقل من الصيغ الأربع: يعمل على CPU أو GPU أو مزيج هجين منهما عبر llama.cpp، لذا فهو الخيار الأكثر أمانًا عندما لا تكون متأكدًا مما يستطيع عتادك دعمه. أما GPTQ وAWQ وEXL2 فهي أكثر ارتباطًا بـ GPU وبيئة التشغيل. عمليًا، هي الأكثر شيوعًا على إعدادات NVIDIA/CUDA، لكن دعم GPTQ وAWQ قد يتفاوت حسب المُحمِّل وحزمة التقديم؛ فـ vLLM، على سبيل المثال، يفصل دعم التكميم بحسب العتاد والتنفيذ. إذا كنت تعمل محليًا على جهاز Mac أو بطاقة AMD أو جهاز يعتمد على CPU فقط، يبقى GGUF الإجابة الأكثر أمانًا. إذا كانت لديك GPU من NVIDIA وتريد أسرع توكنات ممكنة، تدخل الصيغ الثلاث الأخرى حيّز التطبيق.
| الصيغة | العتاد/بيئة التشغيل | السرعة (نسبية) | VRAM مقارنة بالنظراء | الأنسب لـ |
|---|---|---|---|---|
| GGUF Q4_K_M | الأوسع نطاقًا، CPU أو GPU أو هجين عبر llama.cpp | معتدلة | الأدنى | أي عتاد؛ الخيار الافتراضي المحلي |
| GPTQ 4-bit | عادة CUDA/GPU أولًا؛ يعتمد على بيئة التشغيل | سريع (ExLlama) | متوسط | GPU أولًا، أدوات قديمة |
| AWQ 4-bit | عادة CUDA/GPU أولًا؛ يعتمد على بيئة التشغيل | سريع | الأعلى | التقديم عبر vLLM/TGI، تحميل سريع |
| EXL2 ~4.9 bpw | NVIDIA/CUDA أولًا | الأسرع | منخفض-متوسط | أقصى سرعة على NVIDIA |
تحفظ حول هذا الجدول: تصنيفات السرعة وVRAM مأخوذة من معيار أداء oobabooga، والذي أُجري على عتاد من حقبة 2023/2024. تعامل مع النسبي الترتيب النسبي بوصفه ثابتًا. EXL2 مصمم للسرعة، وAWQ يقايض VRAM بتحميل سريع، ويبقى GGUF خفيفًا وقابلًا للنقل، لكن لا تقرأ الأرقام المطلقة الأصلية للتوكنات في الثانية على أنها حالية. ستُظهر GPU من عام 2026 معدل نقل خام مختلفًا جدًا؛ الترتيب النسبي هو ما يستمر.
إذًا فقاعدة القرار المستخلصة من هذا: إذا كانت لديك بطاقة NVIDIA وتهتم بالسرعة قبل كل شيء، فاختر EXL2؛ وإذا كنت تريد الخيار الافتراضي المحلي الأكثر أمانًا عبر عتاد مختلف، فاختر GGUF. أما AWQ وGPTQ فيهمان بشكل أساسي عندما تدفعك حزمة تقديم معينة (vLLM أو TGI) أو أدوات قائمة نحوهما.
لماذا يستخدم LLM المحلي ذاكرة أكثر من حجم ملفه؟
حجم الملف هو فقط أوزان النموذج. أثناء التشغيل، تدفع أيضًا ثمن ذاكرة KV cache (حالة الانتباه لكل توكن في نافذة السياق لديك)، والتفعيلات (الحسابات الوسيطة لتمريرة أمامية)، والنفقات الإضافية للإطار البرمجي والتعريف. مجتمعة، تضيف العناصر غير المتعلقة بالأوزان عادة 10 إلى 20% فوق الأوزان في إعداد مستخدم واحد، ويمكن لذاكرة KV cache وحدها أن تطغى على كل شيء آخر بمجرد أن يطول السياق. قد يحتاج ملف بحجم 4.6 GB إلى أكثر من 4.6 GB من الذاكرة بكثير ليعمل.
تخيّل ذاكرة وقت التشغيل كأربعة مكونات مكدّسة فوق بعضها البعض:
- أوزان النموذج. الملف الذي نزّلته. هذا هو الجزء الوحيد المرئي قبل التحميل.
- ذاكرة KV cache. حالة الانتباه لنافذة السياق. صغيرة عند السياق القصير، وهائلة عند السياق الطويل. هذا هو القسم التالي، لأنه القسم الذي يفاجئ الناس.
- التفعيلات. الذاكرة العاملة لتمريرة أمامية. بالنسبة للاستدلال المحلي أحادي التدفق (حجم دفعة 1)، تكون صغيرة، عادة بضع مئات من الميغابايت.
- النفقات الإضافية للإطار البرمجي. البصمة الخاصة ببيئة التشغيل بالإضافة إلى سياق تعريف GPU. بالنسبة لبيئة تشغيل محلية خفيفة، يمكن أن يكون هذا صغيرًا مقارنة بأوزان النموذج وذاكرة KV cache؛ أما أطر التقديم الأثقل فقد تحجز أكثر من ذلك بكثير. حجز الذاكرة الخاص بنظام التشغيل لديك يقع خارج هذا وهو منفصل مرة أخرى.
الأوزان والنفقات الإضافية للإطار البرمجي قابلة للتنبؤ. ذاكرة KV cache هي المتغيّر الذي يحوّل نموذجًا "يتسع" إلى نموذج ينهار، لذا يستحق الأمر إجراء الحسابات الفعلية.
كم من الذاكرة تستخدم ذاكرة KV cache؟
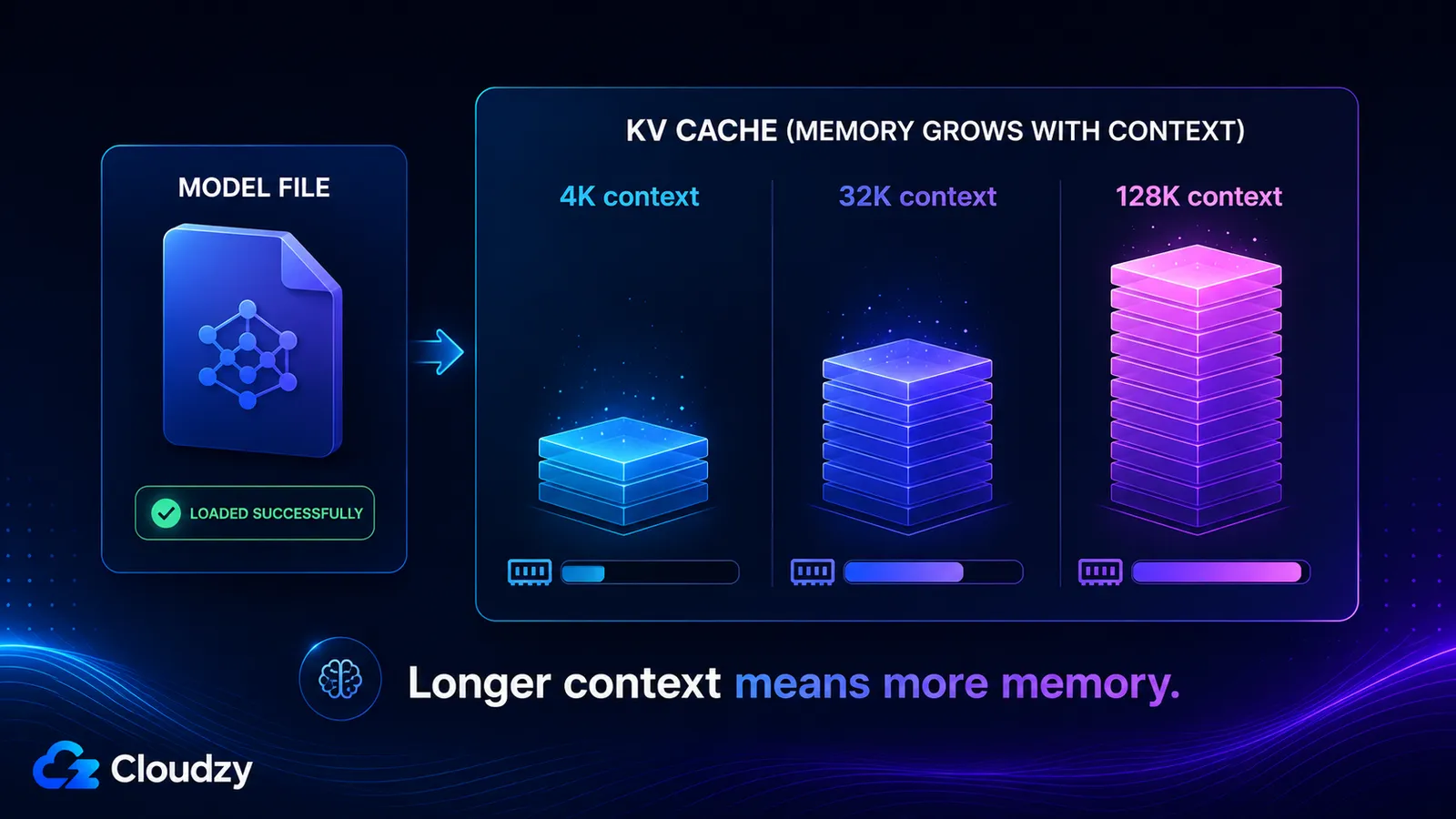
تخزّن ذاكرة KV cache متجهات المفاتيح والقيم لكل توكن في نافذة السياق لديك، لذا فهي تنمو خطيًا تقريبًا مع طول السياق وتكون منفصلة تمامًا عن أوزان النموذج. يُحدَّد حجمها بعدد طبقات النموذج، وعدد رؤوس KV، وبُعد الرأس، وطول السياق، ودقة ذاكرة التخزين المؤقت. فعّل سياقًا طويلًا ويمكنك أن تضيف عشرات الغيغابايتات التي لم يحذّرك منها نموذج كان يُحمَّل بسلاسة قط.
الصيغة قصيرة بما يكفي لحفظها:
بايتات KV cache = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
الرقم 2 في البداية يمثل التنسورين المخزنين لكل توكن، واحد للمفاتيح وواحد للقيم. bytes_per_element يساوي 2 لذاكرة تخزين مؤقت FP16. البقية ثوابت معمارية يمكنك قراءتها من بطاقة النموذج.
لنحسبها لنموذج Llama 3.1 8B، الذي يملك 32 طبقة، و8 رؤوس KV، وبُعد رأس يبلغ 128. عند سياق بطول 4,096 توكن، وحجم دفعة 1، وذاكرة تخزين مؤقت FP16:
2 × 32 × 8 × 128 × 4096 × 2 بايت ≈ 536 MB
زد حجم السياق وسيزداد الرقم معه، لأن كل الحدود باستثناء context_tokens ثابتة:
- سياق 4K: ~536 MB
- سياق 32K: ~4.3 GB
- سياق 128K: ~17 GB
هذان الرقمان الأخيران هما سبب أن نموذجًا قد يعلن عن نافذة سياق بحجم 128K، ويُحمَّل بسلاسة، ثم يستنفد الذاكرة بمجرد أن تستخدم فعليًا تلك النافذة. ذاكرة KV cache عند السياق الكامل أكبر من الأوزان المكمَّمة نفسها.
إليك الجزء الذي يجعل نماذج السياق الطويل الحديثة ممكنة من الأساس: يستخدم Llama 3.1 8B Grouped Query Attention (GQA)يملك 32 رأس استعلام لكن 8 رؤوس KV فقط، وتخزّن ذاكرة التخزين المؤقت متجهات المفاتيح/القيم لـ 8 رؤوس، لا 32. طبّق نفس الصيغة مع 32 رأس KV (تصميم Multi-Head Attention القديم، حيث تساوي رؤوس KV رؤوس الاستعلام) وسيتضاعف كل رقم أعلاه 4 مرات. تصبح تلك الـ 17 GB عند 128K هي 68 GB. GQA هو السبب المعماري الذي يبقي الحسابات قابلة للتحمل مع نمو نوافذ السياق.
حجم الملف ليس ميزانيتك من الذاكرة. عندما لا تعود الأوزان أو ذاكرة KV cache تتسع في مسار الذاكرة السريع وتضطر بيئة التشغيل إلى الرجوع إلى RAM النظام عبر PCIe، لا يتدهور معدل النقل بلطف. بل ينهار فجأة بمجرد أن تنقل بيانات عبر PCIe في كل توكن. خصّص ميزانية الذاكرة بحيث تتسع الأوزان وذاكرة KV cache عند طول السياق الحقيقي لديك معًا، لا الأوزان فقط.
كيف تختار تكميمًا لـ GPU أو Mac الخاص بك؟
ابدأ من عتادك وبيئة التشغيل لديك. يملك أصحاب GPU من NVIDIA أوسع قائمة خيارات وينبغي أن يوازنوا بين EXL2 من أجل السرعة الخام أو GGUF من أجل قابلية النقل. إذا كنت تستخدم AMD أو Apple Silicon أو عتادًا يعتمد على CPU فقط أو إعدادًا مختلطًا، فإن GGUF عبر llama.cpp هو عادة نقطة البداية الأكثر أمانًا. من هناك، اختر أعلى مستوى تكميم يتسع بعد أن خصصت ميزانية لذاكرة KV cache عند طول السياق الذي تستخدمه فعليًا، لا الحد الأقصى للنموذج.
فخ واحد من Apple Silicon يستحق المعرفة: لا يحصل GPU على كامل الذاكرة الموحدة لديك (انظر مقالنا الشقيق حول ما هي الذاكرة الموحدة فعليًا للحصول على الصورة الكاملة لكيفية عمل ذلك المجمع المشترك). قام مجتمع الاستضافة الذاتية self-hosting وثّق حدًا أقصى يبلغ نحو 75% من إجمالي الذاكرة الموحدة المتاحة لـ GPU وثّقه (لم تؤكد Apple هذا رسميًا وقد يتغير مع تحديثات macOS). لذا فإن "Mac بسعة 64 GB" هو واقعيًا نحو 48 GB للنموذج بالإضافة إلى ذاكرة KV cache الخاصة به، خطّط بناءً على الرقم الأصغر.
يتعلق هذا المقال بقراءة الصيغة وتوقّع سلوكها في وقت التشغيل: فك رموز اسم التكميم، واختيار الصيغة التي يدعمها عتادك، وتخصيص ميزانية لذاكرة KV cache بمعزل عن الأوزان. أما مطابقة نموذج معين بمقدار معين من الذاكرة، أي جدول البحث عن حجم مقابل ذاكرة، فهي مسألة ذات صلة لكنها منفصلة سنتناولها في مقال شقيق مستقبلي.
اقرأ المستودع
يمكنك الآن النظر إلى صفحة نموذج وقراءتها بدلًا من التخمين. فكّ رموز اسم التكميم إلى عرض بتاته الفعلي، وأدرك أن GGUF هي الصيغة المحلية الأوسع بينما GPTQ وAWQ وEXL2 أكثر ارتباطًا ببيئة التشغيل، وتذكّر أن حجم الملف هو الحد الأدنى فقط، إذ تتكدّس ذاكرة KV cache فوقه وتنمو مع سياقك. افتح ملفات النموذج الذي تريده، واختر الصيغة التي يستطيع عتادك تشغيلها، واختر أعلى مستوى تكميم يتسع بعد أن تركت هامشًا لذاكرة KV cache عند طول السياق الحقيقي لديك، وستتجنب انهيار نفاد الذاكرة الذي بدأ هذا السؤال كله.
الأسئلة الشائعة
ماذا يعني Q4_K_M؟
Q4_K_M هو مستوى تكميم GGUF: نحو 4 بتات لكل وزن (Q4)، باستخدام معايرة K-quant لكل كتلة (K)، عند فئة الحجم/الجودة المتوسطة (M). الفعلي عرض البتات الفعلي هو نحو 4.89 بت لكل وزن، وليس 4 بالضبط، لأن K-quants تخزّن قيمة مقياس وقيمة دنيا لكل كتلة من الأوزان. لهذا السبب يبلغ حجم ملف نموذج 8B "4-bit" نحو 4.6 GB بدلًا من 3.5 GB.
هل يقلل التكميم من جودة LLM؟
نعم، لكن التكلفة تعتمد بشدة على المدى الذي تدفع فيه التكميم. على نموذج Llama-3.1-8B-Instruct المقاس في arXiv:2601.14277، ترتفع الحيرة (perplexity) بنحو 0.4% فقط عند Q6_K وتبقى قرب 1% عبر نطاق Q5. انزل إلى Q4 وتبقى الزيادة متواضعة (بضع نقاط مئوية)؛ أما تحت Q3_K_M فترتفع بشدة، لتصل إلى +22% عند Q3_K_S. لمعظم الاستخدامات، يكون Q4_K_M وما فوقه خاليًا من الفقدان فعليًا؛ العقوبة الحادة تقع عند 3-bit وما دونه.
ما الفرق بين GGUF وGPTQ وAWQ وEXL2؟
GGUF (يشغّله llama.cpp) هو الصيغة القابلة للنقل، ويعمل على CPU أو GPU أو إعداد هجين عبر مجموعة واسعة من العتاد. أما GPTQ وAWQ وEXL2 فهي أكثر ارتباطًا بـ GPU وبيئة التشغيل. عند 4-bit، يمكن أن تقع الصيغ الأربع جميعها ضمن نطاق جودة ضيق، لذا فإن الفرق العملي يكمن في العتاد ودعم المُحمِّل والسرعة واستخدام VRAM: EXL2 هو الخيار المرَكِّز على السرعة لـ NVIDIA/CUDA، وAWQ شائع في حزم التقديم، ويناسب GPTQ أدوات GPU ومستودعات النماذج الأقدم، ويبقى GGUF الخيار المحلي الأكثر قابلية للنقل.
لماذا يستخدم LLM المحلي لدي ذاكرة أكثر من الملف؟
حجم الملف هو فقط أوزان النموذج. أثناء التشغيل، تدفع أيضًا ثمن ذاكرة KV cache (حالة الانتباه لكل توكن في نافذة السياق)، والتفعيلات، والنفقات الإضافية للإطار البرمجي بالإضافة إلى التعريف. ذاكرة KV cache هي عادة السبب عندما تكون الفجوة كبيرة، لأنها تنمو مع طول السياق وتُخصَّص بمعزل عن الأوزان، فنموذج حجم ملفه بضعة غيغابايتات قد يحتاج ذاكرة أكبر بكثير بمجرد أن تحدد سياقًا طويلًا.
كيف يؤثر طول السياق على استخدام الذاكرة؟
تنمو ذاكرة KV cache خطيًا تقريبًا مع طول السياق، لذا فإن مضاعفة سياقك تضاعف ذاكرة التخزين المؤقت تقريبًا. بالنسبة لنموذج Llama 3.1 8B، تبلغ ذاكرة التخزين المؤقت نحو 536 MB عند 4K توكن، و~4.3 GB عند 32K، و~17 GB عند 128K (FP16، تدفق واحد). هذا النمو منفصل تمامًا عن أوزان النموذج، وهذا هو سبب أن الإعلان عن نافذة سياق طويلة قد يدفع نموذجًا إلى نفاد الذاكرة رغم أنه حُمِّل بسلاسة.


