أكثر من 178,000 مستخدم على GitHub منحوا نجمة لملف markdown واحد. الملف ببساطة يخبر الذكاء الاصطناعي كيف يتصرف.
أربع قواعد: فكّر قبل البرمجة. البساطة أولًا. تغييرات جراحية. تنفيذ موجّه بالهدف. هذا كل شيء. لا مكتبة. لا إطار عمل. لا مثبّت. حزم Forrest Chang ملاحظات Andrej Karpathy حول أنماط فشل البرمجة لدى الـ LLM في ملف CLAUDE.md واحد، ودفعه مجتمع المطوّرين إلى ما يتجاوز 178,000 نجمة على GitHub في الأشهر التي تلت ذلك.
إذا أمعنت النظر فيما حدث هناك، فإنه يشبه إلى حد كبير ما أدركت كل مؤسسة هندسية أنها بحاجة إليه، في النهاية، بعد ما يكفي من الألم: مجموعة مشتركة من القيود على كيفية كتابة الكود. طبقة قواعد. من النوع الذي كان يقطن في قائمة تحقّق لمراجعة الكود، أو دليل نمط، أو الذاكرة المؤسسية لمهندس أقدم. وجد مجتمع برمجة الـ vibe نسخة أخف بكثير من الانضباط نفسه: اكتب القواعد في markdown ودع الوكيل يقرؤها قبل أن يكتب الكود.
هذه ليست حالة فردية. إنها نمط.
الخلاصة السريعة
- منظومة تعليمات الوكلاء (CLAUDE.md وAGENTS.md ومكتبات المهارات المشتركة ووكلاء الوصولية) تتحول إلى طبقة موزّعة لفرض الجودة في البرمجة المدعومة بالذكاء الاصطناعي.
- فجوة الجودة التي تستجيب لها حقيقية: فحص Snyk عدد 3,984 مهارة من ClawHub وskills.sh ووجد أن 1,467 منها، أي 36.82%، تحتوي على عيب أمني واحد على الأقل؛ و534 منها، أي 13.4%، تحتوي على مشكلة واحدة على الأقل بمستوى حرج.
- كانت استجابة المجتمع بناء مزيد من القواعد، لا التخلي عن النهج، وأصبحت مؤسسات من Vercel إلى OWASP إلى Linux Foundation منخرطة الآن.
فجوة الجودة حقيقية، والمجتمع يدرك ذلك

13.4% من ملفات مهارات المجتمع تحتوي على عيوب أمنية حرجة. هذا من تقرير ToxicSkills من Snyk، المنشور في فبراير 2026 بعد فحص 3,984 مهارة من ClawHub وskills.sh. كانت 36.82% تحتوي على ثغرة أمنية واحدة على الأقل. وكانت 76 منها خبيثة صراحة، مع استخدام 91% منها لحقن الموجّه (prompt injection) كآلية للتسليم.
قصة جودة كود الذكاء الاصطناعي الأوسع مشابهة. وفقًا لتحليل CodeRabbit لبيانات مراجعة الكود، يبلغ متوسط الكود المدعوم بالذكاء الاصطناعي 10.83 مشكلة لكل طلب سحب (pull request) مقابل 6.45 للكود المكتوب بشريًا، أي نحو 1.7 ضعفًا من المشكلات. وأفادت دراسة GitClear السنوية للكود بما تسمّيه "نموًا بمقدار 4 أضعاف" في استنساخ الكود: ارتفاع من 8.3% إلى 12.3% من الأسطر المتغيرة بين عامي 2021 و2024.
هذه أرقام صادرة عن جهات بائعة، لذا تعامل مع دقتها بقدر مناسب من التشكيك. ومع ذلك، فهي مفيدة من حيث الاتجاه: البرمجة المدعومة بالذكاء الاصطناعي تخلق ما يكفي من الضغط على الجودة بحيث يبني المطوّرون حواجز حماية جديدة حولها.
ما يهم هو ما فعله المجتمع بهذه المعلومة. لم تكن الاستجابة "ملفات المهارات خطيرة، توقّفوا عن استخدامها". بل كانت: أطلقت OWASP Agentic Skills Top 10 (AST10)، نظير منظومة المهارات لـ Web Application Security Top 10. مزيد من القواعد. مزيد من البنية. إطار أمني رسمي لمنظومة غير رسمية.
هذه استجابة هندسية كلاسيكية، حتى من مجتمع كثيرًا ما يحاول تجنّب العمليات الثقيلة.
المنظومة التي ظهرت

خلال النصف الأول من 2026، بدأ هذا يبدو أقل كحفنة من ملفات markdown المعزولة وأكثر كمنظومة متعددة الطبقات.
ابدأ بالطبقة السلوكية. ملف CLAUDE.md المستوحى من Karpathy يحزم نسخة Forrest Chang من ملاحظات Andrej Karpathy حول إخفاقات البرمجة لدى الـ LLM في ملف تعليمات واحد، وهو يقبع الآن عند أكثر من 178,000 نجمة على GitHub، أحد أكثر المستودعات حصدًا للنجوم في تاريخ GitHub، لملف مبني حول أربع قواعد بسيطة. ما هي تلك القواعد أقل إثارة للاهتمام مما تمثّله: محاولة لترميز الحكم الذي يطبّقه مهندس أقدم أثناء مراجعة الكود.
وفوق ذلك تقبع طبقة تجميع مجتمعية. تجاوزت Antigravity Awesome Skills حاجز 1,595+ مهارة وكيلية، تجمع كتيبات قابلة لإعادة الاستخدام لـ Claude Code وCursor وCodex CLI وGemini CLI وAntigravity ومساعدات برمجة أخرى بالذكاء الاصطناعي. وهي تعمل كمكتبة مشتركة سريعة الحركة للمجال: من النوع الذي قد تنتجه لجنة معايير لو أنها سارت عبر GitHub بدلًا من ملفات PDF.
ثم ظهرت أطر العمل. جعلت Vercel من vercel-labs/agent-skills مستودعًا تنظيميًا رسميًا، وهو الآن عند 28,000 نجمة. تحتوي مهارة React Best Practices وحدها على أكثر من 40 قاعدة عبر ثماني فئات مركّزة على الأداء، تشمل الشلالات (waterfalls)، وحجم الحزمة (bundle size)، والأداء على جانب الخادم، وجلب البيانات على جانب العميل، وتحسين إعادة العرض (re-render)، وأداء العرض، والتحسينات الدقيقة لـ JavaScript. وعندما تشحن الشركة التي تملك منصة نشرك قواعد جودة رسمية لوكلاء الذكاء الاصطناعي، تكون المنظومة قد تخرّجت من تجربة مجتمعية إلى بنية تحتية إنتاجية.
وفي القمة، طبقة معايير. تبرّعت OpenAI بمواصفة AGENTS.md لـ Agentic AI Foundation (AAIF) التابعة لـ Linux Foundation إلى جانب MCP (Anthropic) وGoose (Block): عابرة للأدوات، عابرة للوكلاء، على مسار المعايير. والاتجاه نحو قابلية النقل: يمنح AGENTS.md الفرق مكانًا مشتركًا للتوجيهات الخاصة بالمشروع للوكلاء، حتى وإن ظلت الأدوات الفردية تختلف في كيفية تحميل تلك التعليمات وتطبيقها.
لم تظهر هذه القطع كحزمة واحدة مخطّط لها مركزيًا. بل تقاربت لأن الطلب كان حقيقيًا.
البُعد الذي لا يتحدث عنه أحد
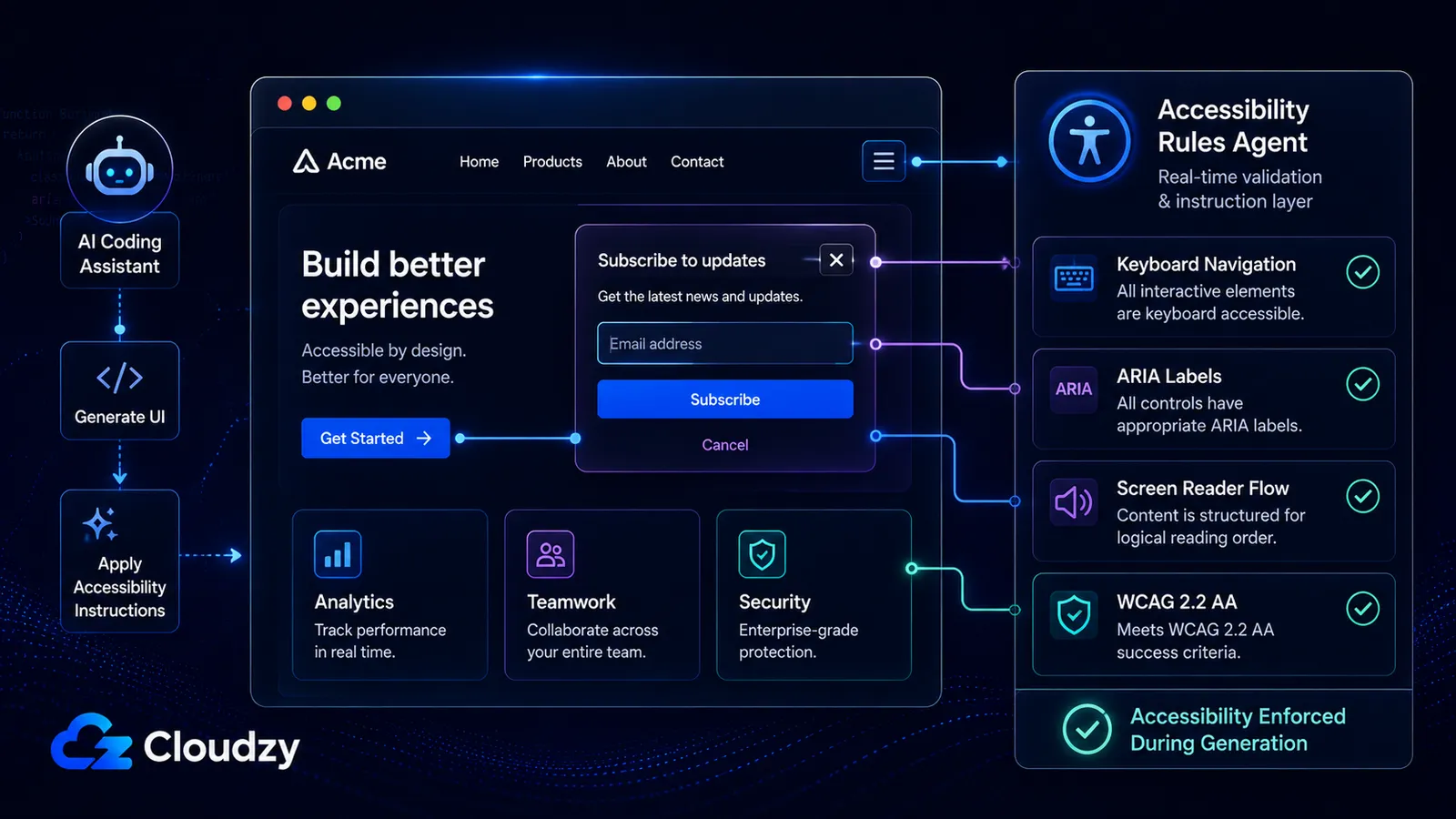
تحظى بيانات الأمان وجودة الكود بالتغطية. أما بُعد الوصولية فلا يحظى بها تقريبًا أبدًا.
Community-Access/accessibility-agents بدأ في 21 فبراير 2026 بستة وكلاء. واعتبارًا من يونيو 2026: 79 وكيلًا متخصصًا عبر ثمانية فرق، و18 مهارة وصولية قابلة لإعادة الاستخدام، واستهداف WCAG 2.2 AA، ودعم عبر خمس منصات: Claude Code وGitHub Copilot وGemini CLI وCodex CLI وخادم MCP يمكنه خدمة العملاء المتوافقين مع MCP.
ما هو هذا المشروع، بعبارات بسيطة: مجتمع من المطوّرين قرر أن أدوات البرمجة بالذكاء الاصطناعي تولّد كودًا غير قابل للوصول افتراضيًا (تتخطّى قواعد ARIA، وتتجاهل التنقّل بلوحة المفاتيح، وتنتج نوافذ منبثقة (modals) تحبس قارئات الشاشة) وبنى 79 وكيلًا متخصصًا لفرض القواعد التي يستمر الذكاء الاصطناعي في نسيانها.
هذا أمر لافت أن يحدث. لطالما قصّر مهندسو الواجهات الأمامية تاريخيًا في الوصولية. فهي أول ما يُحذف تحت ضغط المواعيد النهائية. مشروع accessibility-agents هو مبرمجو الـ vibe يكتبون القواعد التي كانوا سيحتاجون لولاها إلى مهندس أقدم لفرضها، ويفعلون ذلك علنًا، مجانًا، عبر خمسة تكاملات مدعومة.
في قراءتي، المشروع دقيق على نحو غير معتاد بالنسبة لجهد وصولية تطوّعي، خصوصًا لأنه يحوّل الوصولية من شاغل QA متأخر إلى تعليمات وكلاء قابلة لإعادة الاستخدام تعمل أثناء توليد الكود.
لماذا كان هذا حتميًا
الحجة القائلة إن "ملفات المهارات مجرد READMEs للذكاء الاصطناعي" منصفة إذا كنت تنظر إلى أي ملف منفرد. لكنها تكفّ عن الصمود حين تنظر إلى OWASP وهي تطلق إطارًا أمنيًا للمنظومة، أو Vercel وهي تشحن مكتبة جودة رسمية، أو مشروع وصولية تطوّعي ينمو إلى 79 وكيلًا متخصصًا.
إليك ما يحدث فعلًا: فرض الجودة لا يختفي عندما تزيل العملية. بل يعود في صورة مختلفة، لأن غياب الجودة يُنتج الألم بسرعة، والشخص الأقرب إلى ذلك الألم يصلحه عند المصدر.
الانضباط الهندسي التقليدي (مراجعة الكود، وأدلة النمط، وبوابات QA، وحوكمة البنية المعمارية) موجود ليلتقط ما يتخطّاه المطوّرون الأفراد تحت ضغط الوقت. وهو يعمل عندما يكون لديك فريق وعملية. أما مبرمجو الـ vibe فكثيرًا ما لا يملكون أيًّا منهما، بحكم التصميم. لذا رمّزوا المراجعة مسبقًا في تعليمات الوكيل.
CLAUDE.md هو مراجعة كود مرمّزة مسبقًا. Awesome Skills هو دليل نمط موزّع. AGENTS.md هو معيار حوكمة. تغيّرت الكلمات. ولم تتغير الوظيفة.
ما هو مثير للاهتمام ليس أن القيود عادت، فذلك كان حتميًا. ما هو مثير للاهتمام أنها عادت أسرع مما عادت في المرة الأولى، وبشكل أكثر علنية، وبمستوى جودة يُحرج بعض المؤسسات الهندسية ذات العمليات الناضجة.
لم يُعِد مجتمع برمجة الـ vibe اختراع الانضباط الهندسي على مضض، تحت ضغط من الإدارة. بل بناه لأنهم اصطدموا بجدار وكانت أدوات إصلاحه على بُعد ملف markdown.
الأسئلة الشائعة
ماذا يدخل في ملف CLAUDE.md؟
قيود سلوكية للذكاء الاصطناعي: ما يجب تجنّبه، وما يجب إعطاؤه الأولوية، والقواعد المعمارية، والإشارات الأمنية الحمراء، والاصطلاحات الخاصة بالمشروع. يتجاوز الاستخدام المركّز على الجودة اختصارات سير العمل: قواعد مثل "لا تُزِل أبدًا معالجة الأخطاء لتمرير الاختبارات" تقبع إلى جانب "استخدم دائمًا TypeScript". للاطلاع على أمثلة حقيقية ومختبَرة، ابدأ بـ تجميع مجتمع Awesome Skills. agent-skills من Vercel هو مرجع قوي آخر.
ما هو AGENTS.md وكيف يختلف عن CLAUDE.md؟
AGENTS.md هو معيار عالمي للتوجيهات الخاصة بالمشروع للوكلاء، أصدرته OpenAI وأسهمت به في Agentic AI Foundation التابعة لـ Linux Foundation في ديسمبر 2025. أما CLAUDE.md فهو ملف توجيه المشروع الخاص بـ Claude Code. يتداخلان في الغرض، لكنهما ليسا تنسيقين متطابقين في كل أداة. الخلاصة العملية هي أن الفرق يمكنها بشكل متزايد كتابة تعليمات الوكلاء مرة واحدة وتكييفها عبر أدوات مثل Codex وCursor وCopilot وGemini CLI وClaude Code.
هل ملفات المهارات آمنة للاستخدام؟
ينبغي قراءة المهارات المستمدّة من المجتمع قبل استيرادها. تقرير ToxicSkills من Snyk وجدت أن 36% من مهارات المجتمع المفحوصة تحتوي على عيب أمني واحد على الأقل، و13.4% تحتوي على عيوب بمستوى حرج، مع حقن الموجّه (prompt injection) كآلية الهجوم الأساسية. OWASP Agentic Skills Top 10 هو الإطار المرجعي لفهم سطح الهجوم. تحمل ملفات المهارات من المستودعات الرسمية أو مشاريع المصدر المفتوح الراسخة مخاطر سلسلة توريد أقل عمومًا من المساهمات المجتمعية المجهولة، لكن ما زال ينبغي مراجعتها قبل الاستيراد.
ما هو OWASP Agentic Skills Top 10 (AST10)؟
إطار أمن من OWASP لعام 2026 لمنظومة المهارات، نظير OWASP Web Application Security Top 10 لكنه يعالج تحديدًا سطح الهجوم الذي تخلقه ملفات تعليمات وكلاء الذكاء الاصطناعي. يغطّي المخاطر الأمنية العشرة الأكثر حرجًا عبر منصات تشمل Claude Code وCursor/Codex وVS Code. الإطار قيد التطوير النشط اعتبارًا من 2026، مع إصدار v1.0 مخطّط له في الربع الرابع من 2026.
هل أحتاج إلى ملفات مهارات إذا كنت أبني مشروعًا شخصيًا؟
فقط إذا أردت سلوكًا متسقًا من الذكاء الاصطناعي. من دون قيود، تُحسّن أدوات البرمجة بالذكاء الاصطناعي لإنجاز المهمة، لا لجودة الكود، وهو ما يعمل جيدًا إلى أن يُنتج منطقًا مكررًا، أو معالجة أخطاء غائبة، أو مكوّنات UI غير قابلة للوصول. العبء منخفض: ملف واحد لكل مشروع، تتم صيانته كلما اكتشفت ما يستمر الذكاء الاصطناعي في إخطائه. القواعد المستوحاة من Karpathy نقطة بداية معقولة؛ ومكتبات مهارات المجتمع تتيح لك سحب قواعد خاصة بالمجال (الأمان، الوصولية، اصطلاحات اللغة) من دون كتابتها من الصفر.