
قد يبدو اختيار VPS من نوع GPU أمراً مُربكاً حين تجد نفسك أمام جداول مواصفات مليئة بالأرقام. تتراوح أعداد النوى بين ٢٬٥٦٠ و٢١٬٧٦٠، لكن ماذا يعني ذلك عملياً؟
نواة CUDA هي وحدة معالجة متوازية داخل GPU من NVIDIA تُنفّذ آلاف العمليات الحسابية في آنٍ واحد، وتُشغّل كل شيء من تدريب نماذج AI إلى التصيير ثلاثي الأبعاد. يشرح هذا الدليل آلية عملها، والفرق بينها وبين أنوية CPU وأنوية Tensor، وأعداد النوى المناسبة لاحتياجاتك دون دفع أكثر مما تحتاج.
ما هي أنوية CUDA؟

أنوية CUDA هي وحدات معالجة فردية داخل GPU من NVIDIA تُنفّذ التعليمات بشكل متوازٍ. ما هي تقنية نواة CUDA في جوهرها؟ تخيّل هذه الوحدات كعمّال صغار يتناولون أجزاء من نفس المهمة في الوقت ذاته.
أطلقت NVIDIA تقنية CUDA (Compute Unified Device Architecture) عام ٢٠٠٦ لاستثمار قوة GPU في الحوسبة العامة بعيداً عن معالجة الرسومات. وتُتيح توثيق CUDA الرسمي تفاصيل تقنية شاملة. تُجري كل وحدة عمليات حسابية أساسية على الأعداد العشرية، مما يجعلها مثالية للعمليات المتكررة.
تضم GPU الحديثة من NVIDIA آلاف هذه الوحدات في شريحة واحدة. تحتوي GPU المخصصة للمستهلكين من الجيل الأخير على أكثر من ٢١٬٠٠٠ نواة، فيما تضم GPU مراكز البيانات المبنية على بنية Hopper ما يصل إلى ١٦٬٨٩٦. تعمل هذه الوحدات معاً عبر معالجات Streaming Multiprocessors (SMs).
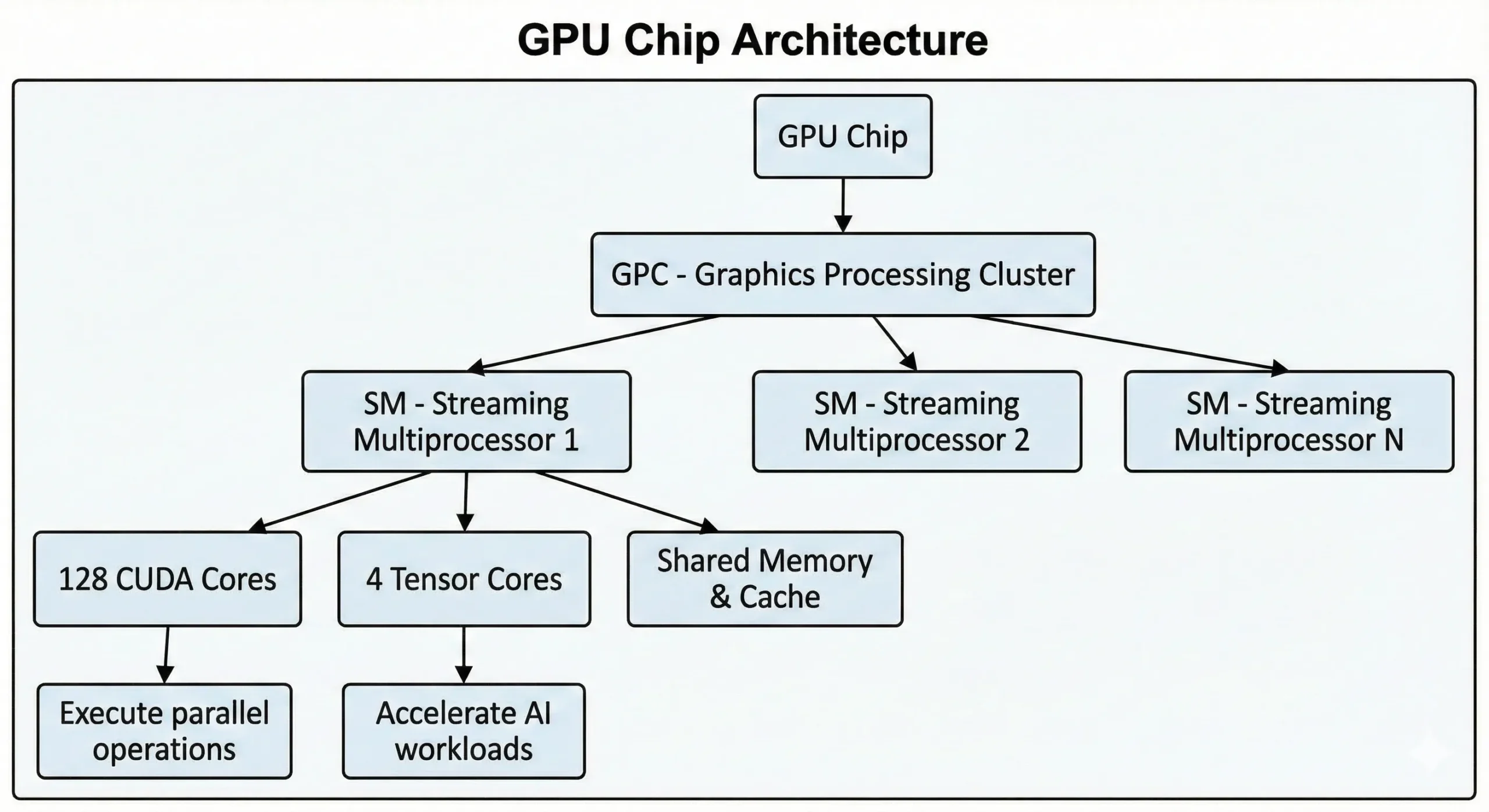
تُنفّذ الوحدات عمليات SIMT (Single Instruction, Multiple Threads) عبر أساليب الحوسبة المتوازية. تُطبَّق تعليمة واحدة على نقاط بيانات كثيرة في آنٍ واحد. عند تدريب الشبكات العصبية أو تصيير مشاهد ثلاثية الأبعاد، تجري آلاف العمليات المتشابهة في الوقت ذاته. تُقسّم هذه الوحدات العمل إلى تدفقات متزامنة وتُنفّذها معاً بدلاً من التسلسل.
أنوية CUDA مقابل أنوية CPU: ما الذي يُفرّق بينهما؟

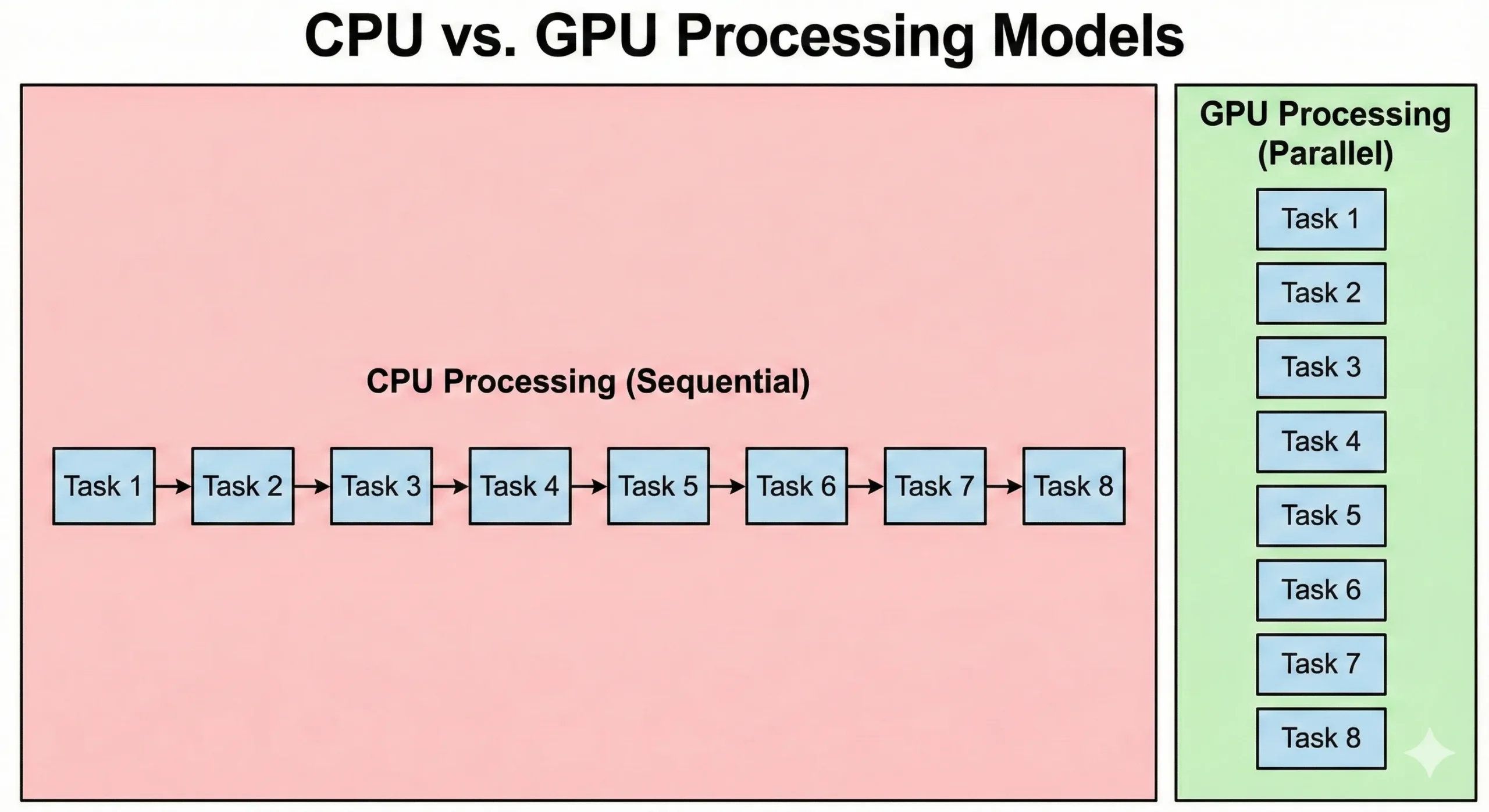
يحل CPU و GPU المشكلات بطرق مختلفة جذرياً. قد يحتوي CPU الخادم الحديث على ٨ إلى أكثر من ١٢٨ نواة تعمل بسرعات ساعة عالية. يتميز هذا النوع من المعالجات بالعمليات التسلسلية حيث تعتمد كل خطوة على نتيجة سابقتها، ويتعامل بكفاءة مع المنطق المعقد والتفريع.
يعتمد GPU نهجاً مختلفاً، إذ يضم آلاف أنوية CUDA البسيطة التي تعمل بسرعات ساعة أقل. تعوّض هذه الوحدات انخفاض السرعة بالمعالجة المتوازية. حين تعمل ١٦٬٠٠٠ نواة معاً، يتجاوز إجمالي الإنتاجية قدرة CPU التقليدي.
يُنفّذ CPU كود نظام التشغيل ومنطق التطبيقات المعقد. وبينما يُعطي GPU الأولوية للإنتاجية، تُفضي تكاليف بدء المهام والمزامنة إلى زمن استجابة أعلى. تُركّز معالجة الرسومات المتوازية على نقل البيانات؛ فرغم أن بدء التشغيل يستغرق وقتاً أطول، إلا أنها تعالج مجموعات البيانات الكبيرة أسرع من CPU.
| الميزة | أنوية CPU | نوى CUDA |
| العدد لكل شريحة | ٤ إلى ١٢٨+ نواة | ٢٬٥٦٠ إلى ٢١٬٧٦٠ نواة |
| سرعة الساعة | ٣٫٠ إلى ٥٫٥ GHz | ١٫٤ إلى ٢٫٥ GHz |
| أسلوب المعالجة | تسلسلي، تعليمات معقدة | متوازٍ، تعليمات بسيطة |
| الأنسب لـ | أنظمة التشغيل والمهام أحادية الخيط | العمليات المصفوفية ومعالجة البيانات المتوازية |
| زمن الاستجابة | منخفض (ميكروثوانٍ) | أعلى (تأخر الإطلاق) |
| البنية المعمارية | متعدد الأغراض | متخصص في الحسابات المتكررة |
تتولى تقنيتا GPU الافتراضية (vGPU) و GPU متعدد الأنظمة (MIG) إدارة تقسيم الموارد وجدولتها لتوزيع المعالجات بين عدة مستخدمين. يتيح هذا الإعداد للفرق تحقيق أقصى استفادة من الأجهزة، سواء عبر المشاركة بتقسيم الوقت أو عبر أنظمة مخصصة، وذلك حسب التهيئة المستخدمة.
يتطلب تدريب الشبكات العصبية إجراء مليارات عمليات ضرب المصفوفات. لا تنفذ GPU التي تحتوي على ١٠٬٠٠٠ وحدة هذه العمليات جميعها في آنٍ واحد، بل تدير آلاف الخيوط المتوازية المجمَّعة في ما يُعرف بـ"warps" لرفع الإنتاجية إلى أقصاها. هذه المعالجة الموازية الهائلة هي السبب الذي يجعل هذه الوحدات من الأساسيات التي لا غنى عنها لكل مطور يعمل في مجال الذكاء الاصطناعي.
CUDA Cores مقابل Tensor Cores: فهم الفرق بينهما

تضم وحدات NVIDIA GPU نوعين من الوحدات المتخصصة تعملان معاً: CUDA cores القياسية و Tensor cores. وهما ليستا تقنيتين متنافستين، بل تعالج كل منهما جانباً مختلفاً من أعباء العمل.
الوحدات القياسية معالجات متوازية متعددة الأغراض، تتولى حسابات FP32 و FP64 والعمليات الصحيحة وتحويلات الإحداثيات. وتشكّل تقنية CUDA الأساسية هذه قاعدة حوسبة GPU، إذ تشغّل كل شيء من محاكاة الفيزياء إلى المعالجة المسبقة للبيانات دون الحاجة إلى تسريع متخصص.
Tensor cores وحدات متخصصة مصممة حصراً لضرب المصفوفات ومهام الذكاء الاصطناعي. قُدِّمت مع معمارية Volta من NVIDIA عام ٢٠١٧، وتتميز بأدائها في حسابات دقة FP16 و TF32. كما يدعم الجيل الأحدث منها دقة FP8 لاستنتاج أسرع في مهام الذكاء الاصطناعي.
| الميزة | نوى CUDA | نوى Tensor |
| الغرض | الحوسبة المتوازية العامة | ضرب المصفوفات لأغراض الذكاء الاصطناعي |
| مستوى الدقة | FP32، FP64، INT8، INT32 | FP16, FP8, TF32, INT8 |
| السرعة من أجل الذكاء الاصطناعي | الأداء الأساسي (×1) | أسرع من ×2 إلى ×10 مقارنةً بـ CUDA cores |
| حالات الاستخدام | المعالجة المسبقة للبيانات، وتعلم الآلة التقليدي | تدريب التعلم العميق واستنتاجه |
| التوافر | جميع NVIDIA GPUs | سلسلة RTX 20 وما بعدها، وdatacenter GPUs |
تجمع GPUs الحديثة بين النوعين معاً. تضم RTX 5090 ما يصل إلى 21,760 وحدة معيارية إضافةً إلى 680 Tensor core من الجيل الخامس. أما H100 فتُقرن 16,896 وحدة معيارية بـ 528 Tensor core من الجيل الرابع لتسريع عمليات التعلم العميق.
عند تدريب الشبكات العصبية، تتولى Tensor cores المهام الحسابية الثقيلة خلال التمريرات الأمامية والخلفية عبر النموذج. بينما تتكفل الوحدات المعيارية بتحميل البيانات، والمعالجة المسبقة، وحسابات الخسارة، وتحديثات المحسِّن. يعمل النوعان معاً، إذ تُسرِّع Tensor cores العمليات المكثفة حسابياً.
بالنسبة لخوارزميات تعلم الآلة التقليدية كالغابات العشوائية أو Gradient Boosting، تتولى الوحدات المعيارية تنفيذ العمل، لأن هذه الخوارزميات لا تعتمد على أنماط ضرب المصفوفات التي تُسرِّعها Tensor cores. لكن بالنسبة لنماذج Transformer والشبكات العصبية الالتفافية، توفر Tensor cores تسريعاً ملحوظاً.
ما الاستخدامات التي تُغطيها CUDA Cores؟

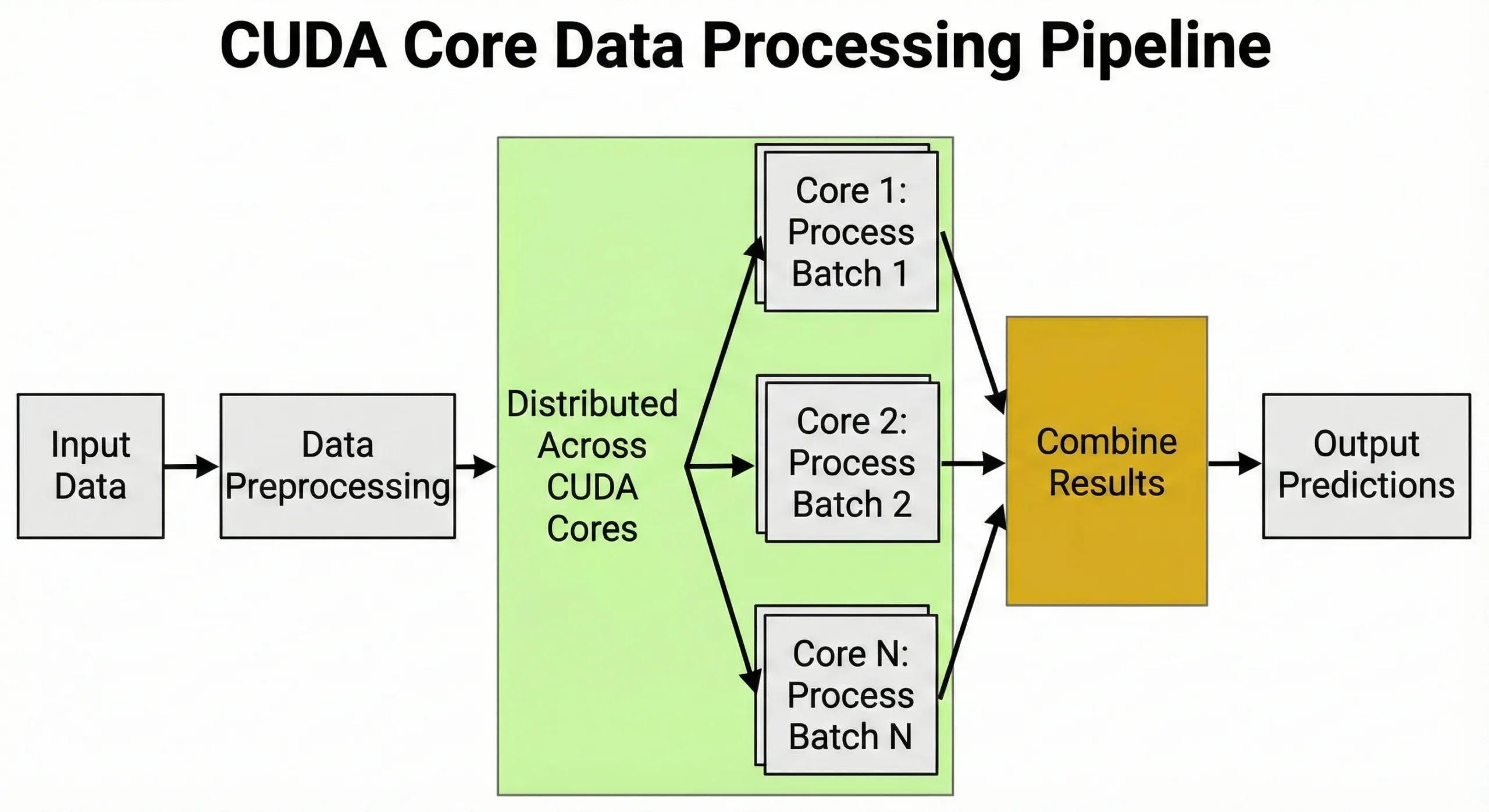
تتولى CUDA cores تنفيذ المهام التي تتطلب عمليات حسابية متطابقة بأعداد كبيرة وبشكل متوازٍ. أي عمل يشمل عمليات المصفوفات أو الحسابات العددية المتكررة يستفيد من هذه البنية.
تطبيقات الذكاء الاصطناعي وتعلم الآلة
يعتمد التعلم العميق على ضرب المصفوفات خلال مرحلتي التدريب والاستنتاج. في كل تمريرة أمامية، تستلزم عملية تدريب الشبكات العصبية ملايين عمليات الضرب والجمع عبر مصفوفات الأوزان. ويُضيف الانتشار الخلفي ملايين أخرى خلال التمريرة الخلفية.
تتولى الوحدات المعالجة المسبقة للبيانات، وتحويل الصور إلى tensors، وتسوية القيم، وتطبيق تحويلات augmentation. هذه القدرة على معالجة آلاف المهام في آنٍ واحد هي السبب الجوهري في أهمية GPUs للذكاء الاصطناعي.
خلال التدريب، تُشرف الوحدات على جدولة معدلات التعلم، وحسابات التدرجات، وتحديثات حالة المحسِّن.
بالنسبة لـ VPS في عمليات استنتاج الذكاء الاصطناعي التي تُشغِّل أنظمة التوصية أو روبوتات الدردشة، تعالج الوحدات الطلبات بشكل متزامن وتُنفِّذ مئات التنبؤات في آنٍ واحد. دليلنا حول أفضل GPU للذكاء الاصطناعي 2025 يُغطي الإعدادات المناسبة لأحجام النماذج المختلفة.
تُدرِّب الوحدات الـ 16,896 في H100 مُدمجةً مع Tensor cores نموذجاً بسبعة مليارات معامل في أسابيع بدلاً من أشهر. يتطلب الاستنتاج الفوري لروبوتات الدردشة التي تخدم آلاف المستخدمين قدرةً مماثلة على التنفيذ المتزامن.
الحوسبة العلمية والبحث العلمي
يستخدم الباحثون هذه المعالجات في محاكاة ديناميكيات الجزيئات، ونمذجة المناخ، وتحليل الجينوم. كل عملية حسابية مستقلة بذاتها، مما يجعلها مثالية للتنفيذ المتوازي. كما تُجري المؤسسات المالية محاكاة مونت كارلو بملايين السيناريوهات في آنٍ واحد.
التصيير ثلاثي الأبعاد وإنتاج الفيديو
يعمل تتبع الأشعة على حساب مسارات الضوء عبر المشاهد ثلاثية الأبعاد بتتبع أشعة مستقلة لكل بكسل. وبينما تتولى وحدات RT المخصصة عمليات الاجتياز، تُدير الوحدات القياسية أخذ عينات النسيج والإضاءة. هذا التوزيع هو ما يحدد سرعة معالجة المشاهد التي تحتوي على ملايين الأشعة.
يتولى NVENC ترميز H.264 وH.265، فيما تُقدّم أحدث البنيات المعمارية (Ada Lovelace وHopper) دعماً على مستوى العتاد لـ AV1. أما CUDA فيُسهم في تطبيق التأثيرات والفلاتر والتحجيم وإزالة الضوضاء وتحويلات الألوان وربط مكونات خط الأنابيب. يُتيح ذلك لمحرك الترميز العمل جنباً إلى جنب مع المعالجات المتوازية لإنتاج فيديو أسرع.
يوزّع التصيير ثلاثي الأبعاد في Blender أو Maya مليارات عمليات حساب تظليل الأسطح على الوحدات المتاحة. وتستفيد أنظمة الجسيمات من هذا التوزيع إذ تحاكي آلاف الجسيمات المتفاعلة في وقت واحد. هذه الإمكانات أساسية لإنتاج المحتوى الرقمي الاحترافي رفيع المستوى.
تأثير CUDA Cores على أداء GPU

تُعطيك أعداد الوحدات فكرة تقريبية عن قدرة التنفيذ المتوازي، لكن تقييم CUDA cores يستلزم النظر إلى ما هو أبعد من الأرقام. سرعة الساعة، وعرض نطاق الذاكرة، وكفاءة البنية المعمارية، وتحسين البرمجيات، كلها عوامل محورية.
تُعطي GPU التي تضم ١٠٬٠٠٠ وحدة تعمل بسرعة 2.0 GHz نتائج مختلفة عن أخرى بالعدد ذاته تعمل بسرعة 1.5 GHz. سرعة الساعة الأعلى تعني أن كل وحدة تُنجز عمليات حسابية أكثر في الثانية. أما البنى المعمارية الأحدث فتُضمّن عملاً أكبر في كل دورة من خلال جدولة تعليمات أكثر كفاءة.
تحقق من أن الجهاز مشغول باستمرار، لكن تذكر أن nvidia-smi نسبة الاستخدام مقياس تقريبي. فهي تقيس النسبة المئوية للوقت الذي تكون فيه النواة نشطة، لا عدد الوحدات التي تعمل فعلاً.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderمثال على الناتج: 85%، 92% (الوقت النشط 85%، نشاط وحدة التحكم في الذاكرة 92%)
إذا أظهرت GPU لديك نسبة استخدام بين 60-70%، فالغالب أن لديك اختناقات في مرحلة سابقة كتحميل بيانات CPU أو أحجام دُفعات صغيرة. غير أن 100% استخدام قد تكون مضللة إذا كانت نوى البرنامج مقيدة بالذاكرة أو أحادية الخيط. للحصول على صورة دقيقة لمعدل إشغال الوحدات، استخدم أدوات تحليل الأداء مثل Nsight Systems لتتبع مقاييس "SM Efficiency" أو "SM Active".
كثيراً ما يتحول عرض نطاق الذاكرة إلى اختناق قبل الوصول إلى الحد الأقصى لقدرة المعالجة. فإذا كانت GPU تعالج البيانات أسرع مما تُمدّها به الذاكرة، تبقى الوحدات خاملة. يستخدم طراز H100 SXM5 عرض نطاق 3.35 TB/s لتغذية ١٦٬٨٩٦ وحدة. أما الإصدار PCIe فيتراجع هذا الرقم فيه إلى 2 TB/s.
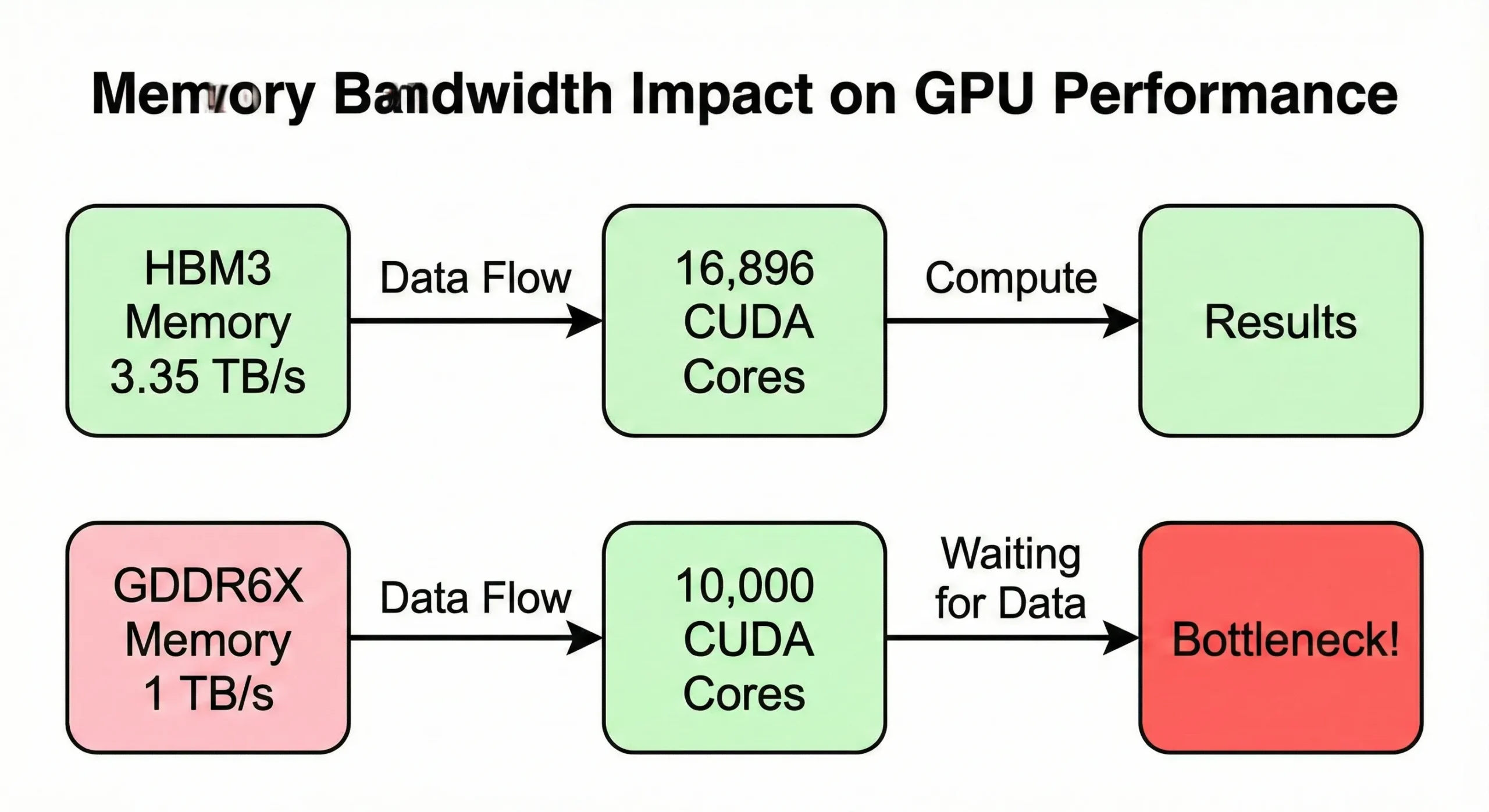
تُظهر GPU للمستخدمين العاديين بأعداد وحدات مماثلة لكن عرض نطاق أقل (نحو 1 TB/s) سرعة أدنى في العالم الحقيقي على العمليات كثيفة الذاكرة.
تحدد سعة VRAM حجم المهام التي يمكنك تشغيلها. سواء كانت أوزان FP16 لنموذج 70B، فإن التدريب الكامل يتطلب ذاكرة أكبر. يجب أن تحسب حساب التدرجات وحالات المُحسِّن، إذ كثيراً ما تُضاعف هذه الحالات حجم البصمة ثلاث مرات ما لم تستخدم استراتيجيات الإزاحة.
يستهدف A100 80GB الاستدلال عالي الإنتاجية والضبط الدقيق. في المقابل، يمكن لـ RTX 4090 بسعة 24GB، الذي يُستشهد به كثيراً لنماذج 7B، أن يُشغّل بشكل مفاجئ نماذج بأكثر من 30B معامل إذا استخدمت تقنيات تكميم حديثة كـ INT4. لكن نفاد VRAM يُجبرك على نقل البيانات بين CPU وGPU، مما يُدمر الإنتاجية.
يحدد تحسين البرمجيات ما إذا كان كودك يستغل جميع تلك الوحدات فعلاً. فالنوى المكتوبة بصورة رديئة قد تُشغّل جزءاً صغيراً فقط من الموارد المتاحة. مكتبات كـ cuDNN للتعلم العميق وRAPIDS لعلم البيانات مُضبَّطة بعناية لتعظيم الاستخدام.
المزيد من CUDA Cores لا يعني دائماً أداءً أفضل

شراء GPU بأعلى عدد نوى قد يبدو منطقياً، لكنك ستهدر المال إذا تجاوزت الوحدات قدرة مكونات النظام الأخرى، أو كانت مهمتك لا تستفيد من زيادة عدد النوى.
عرض النطاق الترددي للذاكرة هو أول عائق. وحدات RTX 5090 البالغة ٢١٬٧٦٠ تعتمد على عرض نطاق ترددي للذاكرة يبلغ ١٬٧٩٢ GB/s. أما طرازات GPU الأقدم ذات الوحدات الأقل، فقد تتمتع بنسبة عرض نطاق ترددي أعلى لكل وحدة.
اختلافات البنية مهمة. GPU أحدث بـ ١٤٬٠٠٠ وحدة عند ٢٫٢ GHz يتفوق على GPU أقدم بـ ١٦٬٠٠٠ وحدة عند ١٫٨ GHz، بفضل تحسينات التعليمات لكل دورة ساعة. وكودك يحتاج إلى تحسين متوازٍ حقيقي ليستفيد من ٢٠٬٠٠٠ وحدة بفاعلية.
لماذا تهم CUDA Cores عند اختيار GPU VPS

اختيار تكوين CUDA core المناسب لـ GPU الخاص بـ VPS يحميك من إنفاق المال على موارد لا تستخدمها أو الوقوع في اختناقات في منتصف المشروع.
ذاكرة ٨٠ GB في H100 تكفي لتشغيل الاستنتاج على نماذج بـ ٧٠ مليار معامل باستخدام الكمية الرباعية ٤-bit. لكن للتدريب الكامل، حتى ٨٠ GB غالباً لا تكفي لنموذج بـ ٣٤ مليار معامل حين تحسب متطلبات التدرجات وحالات المحسِّن. في تدريب FP16، تتوسع بصمة الذاكرة بشكل ملحوظ، وغالباً ما يستلزم ذلك التجزئة عبر عدة GPU.
عمليات الاستنتاج التي تخدم تنبؤات آنية تحتاج وحدات أقل، لكنها تستفيد من زمن استجابة منخفض. أما أعمال التطوير والنمذجة الأولية فتؤدَّى بكفاءة على GPU متوسطة المستوى لاختبار الخوارزميات وتصحيح الكود.
RTX 4060 Ti بـ ٤٬٣٥٢ وحدة تتيح لك الاختبار دون دفع مقابل أجهزة مبالغ في قوتها. حين تتحقق من صحة نهجك، انتقل إلى GPU مخصصة للإنتاج لإجراء دورات التدريب الكاملة.
الإصدار وأعمال الفيديو تستفيد من زيادة الوحدات حتى حد معين. محرك Cycles في Blender يستغل جميع الموارد المتاحة بكفاءة. GPU بـ ٨٬٠٠٠ إلى ١٠٬٠٠٠ وحدة يصدر المشاهد بسرعة أعلى ٢ إلى ٣ مرات مقارنة بواحدة بـ ٤٬٠٠٠ وحدة.
في Cloudzy، نوفر خطط GPU VPS استضافة عالية الأداء مصممة للأعباء الثقيلة. اختر RTX 5090 أو RTX 4090 للإصدار السريع والاستنتاج الاقتصادي بالذكاء الاصطناعي، أو ارتقِ إلى A100 لأعباء التعلم العميق الضخمة. جميع الخطط تعمل على شبكة ٤٠ Gbps مع سياسات تحترم الخصوصية وخيارات دفع بالعملات الرقمية، فتحصل على قوة حقيقية بلا تعقيدات بيروقراطية.
سواء كنت تدرّب نماذج ذكاء اصطناعي، أو تصدر مشاهد ثلاثية الأبعاد، أو تشغّل محاكاة علمية، أنت من يحدد عدد النوى الذي يناسب احتياجاتك.
التكلفة عامل أساسي. A100 بـ ٦٬٩١٢ وحدة أرخص بكثير من H100 بـ ١٦٬٨٩٦ وحدة. في كثير من الحالات، يمنحك A100 اثنان نسبة سعر إلى سرعة أفضل من H100 واحدة. نقطة التعادل تعتمد على مدى قابلية كودك للتوسع عبر عدة GPU.
كيف تختار العدد المناسب من CUDA Cores
طابق متطلباتك مع خصائص عبء العمل الفعلي، بدلاً من السعي وراء أعلى الأرقام المتاحة في السوق.
ابدأ بتحليل عملك الحالي. إن كنت تدرّب النماذج على أجهزة محلية أو نسخ سحابية، راجع مقاييس استخدام GPU. إذا أظهرت GPU الحالية استخداماً ثابتاً بين ٦٠ و٧٠٪، فأنت لم تبلغ الحد الأقصى للوحدات بعد.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")هذا الاختبار البسيط يكشف ما إذا كانت نوى GPU تحقق الإنتاجية المتوقعة. قارن نتائجك بالمعايير المنشورة لطراز GPU الخاص بك.
الترقية لن تجدي نفعاً هنا. عليك أولاً معالجة الاختناقات كالذاكرة وعرض النطاق الترددي وتوقفات CPU. بعد ذلك، قدّر متطلبات الذاكرة باحتساب حجم النموذج بالبايت مضافاً إليه ذاكرة التنشيط.
أضف حجم الدُّفعة مضروباً في مخرجات الطبقات، واحسب حالات المحسِّن. يجب أن يتناسب هذا الإجمالي مع VRAM. حين تعرف الذاكرة المطلوبة، تحقق من GPU التي تستوفي هذا الحد.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)خذ الجدول الزمني بعين الاعتبار. إن كنت تحتاج نتائج في غضون ساعات، ادفع مقابل وحدات أكثر. دورات التدريب التي يمكن أن تستغرق أياماً تؤدَّى بكفاءة على GPU أصغر مع أوقات إكمال أطول بالنسبة ذاتها.
التكلفة في الساعة مضروبة في عدد الساعات المطلوبة تعطيك التكلفة الإجمالية، وقد يجعل ذلك GPU الأبطأ أرخص في المجمل. اختبر كفاءة التوسع باستخدام أطر العمل المتعددة التي توفر أدوات قياس أداء تُظهر تغيرات الإنتاجية.
إذا كان مضاعفة الوحدات لا يمنحك سوى تسريع ١٫٥ مرة، فالوحدات الإضافية لا تستحق تكلفتها. ابحث عن نقاط التوازن المثلى حيث تبلغ نسبة السعر إلى السرعة ذروتها.
| نوع عبء العمل | الأنوية الموصى بها | مثال GPUs | ملاحظات |
| تطوير النماذج وتصحيح الأخطاء | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | تكرار سريع وتكاليف أقل |
| تدريب الذكاء الاصطناعي على نطاق صغير (أقل من 7B معامل) | 6,000-10,000 | RTX 4090, L40S | مناسب للأفراد والشركات الصغيرة |
| تدريب الذكاء الاصطناعي على نطاق واسع (من 7B إلى 70B معامل) | 14,000+ | A100, H100 | يتطلب GPUs خاصة بمراكز البيانات |
| الاستدلال الفوري (إنتاجية عالية) | 10,000-16,000 | RTX 5080, L40 | توازن بين التكلفة والأداء |
| التصيير ثلاثي الأبعاد وترميز الفيديو | 8,000-12,000 | RTX 4080, RTX 4090 | يتوسع مع تزايد التعقيد |
| الحوسبة العلمية و HPC | 10,000+ | A100, H100 | يتطلب دعم FP64 |
VPS GPUs الأكثر شيوعاً وعدد أنويتها CUDA

تستهدف فئات GPU المختلفة شرائح مستخدمين متباينة. ما المقصود بـ GPUaaS؟ إنها GPU-as-a-Service، حيث تتيح مزودات كـ Cloudzy وصولاً عند الطلب إلى وحدات NVIDIA GPU القوية هذه، دون الحاجة إلى شراء الأجهزة المادية أو صيانتها بنفسك.
| طراز GPU | نوى CUDA | VRAM | عرض نطاق الذاكرة | البنية المعمارية | الأنسب لـ |
| RTX 5090 | 21,760 | 32GB GDDR7 | ١٬٧٩٢ GB/s | Blackwell | محطة عمل متطورة، تصيير بدقة 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | ١٬٠٠٨ غيغابايت/ثانية | أدا لوفليس | ذكاء اصطناعي متقدم، تصيير بدقة 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | ٣٬٣٥٠ غيغابايت/ثانية | Hopper | تدريب نماذج الذكاء الاصطناعي على نطاق واسع |
| H100 PCIe | 14,592 | 80GB HBM2e | ٢٬٠٠٠ غيغابايت/ثانية | Hopper | ذكاء اصطناعي للمؤسسات، فعّال من حيث التكلفة في مراكز البيانات |
| A100 | 6,912 | 40/80 غيغابايت HBM2e | ١٬٥٥٥–٢٬٠٣٩ غيغابايت/ثانية | Ampere | ذكاء اصطناعي متوسط المستوى، موثوقية مُجرَّبة |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | أدا لوفليس | الألعاب وتطبيقات الذكاء الاصطناعي المتوسطة |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | أدا لوفليس | مركز بيانات متعدد الأحمال |
بطاقات RTX الاستهلاكية (4070 و4080 و4090 و5080 و5090) مُصمَّمة في الأصل للمبدعين والألعاب، لكنها تؤدي أداءً جيداً في تطوير الذكاء الاصطناعي. توفر سرعة GPU مفردة عالية بأسعار أقل من بطاقات مراكز البيانات.
كثيراً ما يوفر مزودو VPS هذه البطاقات للمستخدمين ذوي الميزانيات المحدودة. أما بطاقات مراكز البيانات (A100 وH100 وL40) فتُعطي الأولوية للموثوقية وذاكرة ECC وتوسيع نطاق GPU المتعدد، وهي مُصمَّمة للتشغيل على مدار الساعة مع دعم الميزات المتقدمة.
تتيح لك تقنية Multi-Instance GPU (MIG) تقسيم GPU واحدة إلى نسخ معزولة متعددة. يظل A100 خياراً رائجاً رغم ظهور بدائل أحدث، بفضل مواصفاته المتوازنة.
يجعل التوازن بين نوى NVIDIA والذاكرة والسعر من هذه البطاقة الخيار الأمثل لمعظم عمليات الذكاء الاصطناعي في بيئات الإنتاج. يوفر H100 وحدات أكثر بمقدار ٢٫٤ ضعف، لكن تكلفته أعلى بفارق ملحوظ.
الخاتمة
محركات المعالجة المتوازية هي ما يجعل الذكاء الاصطناعي الحديث والتصيير والحوسبة العلمية ممكنة. فهم آلية عملها وتفاعلها مع الذاكرة وسرعات الساعة والبرمجيات يساعدك على اختيار تكوينات GPU VPS المناسبة.
يُفيد وجود وحدات أكثر حين يتوزع عملك بفعالية على المعالجة المتوازية، وحين تواكب مكوناتٌ كعرض نطاق الذاكرة هذا الحمل. لكن السعي الأعمى نحو أعلى عدد للنوى يُهدر المال إذا كانت عوامل الاختناق لديك تقع في مكان آخر.
ابدأ بتحليل عملياتك الفعلية، وحدد أين يتركز استهلاك الوقت، ثم طابق مواصفات GPU مع تلك المتطلبات دون شراء طاقة زائدة لا تحتاجها.
لمعظم أعمال تطوير الذكاء الاصطناعي، يمثل نطاق ٦٬٠٠٠-١٠٬٠٠٠ وحدة نقطة التوازن بين التكلفة والأداء. أما العمليات الإنتاجية التي تُدرِّب نماذج كبيرة أو تُشغِّل استنتاجًا بإنتاجية عالية، فتستفيد من GPU بـ ١٤٬٠٠٠+ وحدة كـ H100.
يتوسع التصيير وعمل الفيديو بكفاءة مع الوحدات حتى نحو ١٦٬٠٠٠، وبعد ذلك يصبح عرض نطاق الذاكرة هو العامل المحدود.


