
Du åbner en populær models GGUF-side på Hugging Face, og der er femten filer, der stirrer tilbage på dig: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus separate mapper til GPTQ, AWQ og EXL2 ved et halvt dusin bit-indstillinger. Du laver hovedregningen for "4-bit"-filen: 4 bit × 8 milliarder parametre ÷ 8 = 4 GB. Men filen siger 4,6 GB. Og når du først har indlæst den, bruger modellen mere hukommelse end det.
Filnavnene er ikke støj. De koder reel, forståelig information om bit-bredde, den runtime, der indlæser dem, og den hardware, de kræver. De størrelsestabeller, du har læst, fortæller dig, at en 70B-model kræver omkring 40 GB, nyttigt, men de afkoder aldrig selve formatet eller forklarer, hvorfor den kørende model vil have mere hukommelse end filen på disken.
Så her er planen: afkod GGUF-navngivningskonventionen (med de reelle bit-bredder, ikke de nominelle), find ud af, hvilket af de fire formater din hardware faktisk kan køre, og tag højde for den ene hukommelsesomkostning, der er usynlig i enhver filstørrelse, KV cachen. Ved slutningen kan du læse et modelrepo og forudsige, hvordan det vil opføre sig, når det indlæses.
TL;DR
- GGUF-kvantiseringsniveauer er effektive bit-bredder, ikke det nøjagtige tal i navnet. Q4_K_M er omkring 4,89 bit pr. vægt, hvilket er grunden til, at en "4-bit" 8B-fil lander omkring 4,6 GiB i stedet for det naive 4-bit-estimat.
- GGUF er den mest portable mulighed, fordi llama.cpp kan køre det på CPU, GPU eller en hybrid opsætning. GPTQ, AWQ og EXL2 er mere GPU- og runtime-specifikke, hvor EXL2 især er bundet til NVIDIA/CUDA-workflows.
- KV cachen er adskilt fra modellens vægte, og den vokser med context-længden. Det er grunden til, at en model, der indlæses rent, alligevel kan crashe med out-of-memory, når samtalen bliver lang.
- Over 5-bit-området er kvalitetstabet som regel lille. Omkring Q4 er afvejningen stadig praktisk for mange lokale brugsscenarier. Under 4-bit bliver kvalitetsomkostningen langt mere mærkbar. Q4_K_M er stadig et almindeligt community-standardvalg, mens Q5_K_M og Q6_K er sikrere, når du har hukommelse til overs.
Hvad betyder Q4_K_M i et GGUF-filnavn?

Et GGUF-kvantiseringsnavn følger mønsteret Q[bits]_[K]_[S/M/L]. Tallet er mål- bits pr. vægt, K betyder, at det er en "K-quant", der gemmer skaleringsfaktorer pr. lille blok af vægte, og det efterfølgende S, M eller L er størrelses-/kvalitetsniveauet (small, medium, large). Fordi K-quants gemmer en skala og en minimumsværdi for hver blok sammen med vægtene, bliver den effektive bit-bredde er højere end det tal, der står i navnet. Q4_K_M lander på omkring 4,89 bit pr. vægt, ikke 4.
Den forskel er hele svaret på spørgsmålet "hvorfor er min 4-bit-fil 4,6 GB?". Det naive estimat antager, at hver vægt koster præcis 4 bit. I virkeligheden bruger K-quants ekstra bits pr. blok på de metadata, der gør lav-bit-kvantisering præcis, skalaen og minimumsværdien pr. blok, der lader runtime rekonstruere hver vægt. Gang 4,89 bit ud over 8 milliarder vægte, og du lander nær 4,58 GiB, hvilket er, hvad filen faktisk vejer.
Her er de målte effektive bit-bredder og filstørrelser, taget fra llama.cpp quantize documentation for Llama 3.1 8B som referencemodel, sammen med perplexity-omkostningen for hvert niveau, målt i llama.cpp's kvantiseringsevalueringspapir (arXiv:2601.14277) på Llama-3.1-8B-Instruct:
| GGUF-niveau | Effektiv BPW | ~Filstørrelse (8B) | Perplexity vs. F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | baseline |
*Perplexity-tallene er specifikke for Llama-3.1-8B-Instruct fra arXiv:2601.14277. BPW/filstørrelses-kolonnen og perplexity-kolonnen stammer fra to forskellige kilder, målt separat, så læs tabellen som en praktisk side-om-side-reference snarere end én samlet benchmark-kørsel. Opgavespecifik forringelse varierer, matematisk ræsonnement har en tendens til at lide mere end commonsense-ræsonnement ved lave bit-bredder, men det overordnede billede holder: 5-bit og derover er som regel sikrere, Q4 er den praktiske komprimeringszone, og 3-bit er der, hvor kvalitetstabet bliver meget sværere at ignorere.
Praktisk set: Q4_K_M er standardvalget, de fleste bør gribe til, Q5_K_M og Q6_K er de kvalitetsorienterede valg, når du har hukommelse til overs, og alt på eller under Q3_K_S er en sidste udvej for hardware, der virkelig ikke kan rumme mere.
Hvilket kvantiseringsformat bør du downloade: GGUF, GPTQ, AWQ eller EXL2?

GGUF er den mest portable af de fire: det kører på CPU, GPU eller en hybrid af begge via llama.cpp, så det er det sikreste valg, når du ikke er sikker på, hvad din hardware kan understøtte. GPTQ, AWQ og EXL2 er mere GPU- og runtime-specifikke. I praksis er de mest almindelige på NVIDIA/CUDA-opsætninger, men GPTQ- og AWQ-understøttelse kan variere efter loader og serveringsstak; vLLM for eksempel adskiller understøttelse af kvantisering efter hardware og implementering. Hvis du kører lokalt på en Mac, et AMD-kort eller en ren CPU-boks, er GGUF stadig det sikreste svar. Hvis du har en NVIDIA-GPU og vil have de hurtigst mulige tokens, kommer de tre andre i spil.
| Format | Hardware/runtime | Hastighed (relativ) | VRAM vs. konkurrenter | Bedst til |
|---|---|---|---|---|
| GGUF Q4_K_M | Bredest, CPU, GPU eller hybrid via llama.cpp | Moderat | Lavest | Enhver hardware; lokalt standardvalg |
| GPTQ 4-bit | Som regel CUDA/GPU-først; runtime-afhængig | Hurtig (ExLlama) | Mellem | GPU-først, ældre værktøjer |
| AWQ 4-bit | Som regel CUDA/GPU-først; runtime-afhængig | Hurtig | Højeste | vLLM/TGI-servering, hurtig indlæsning |
| EXL2 ~4,9 bpw | NVIDIA/CUDA-først | Hurtigste | Lav-Mellem | Maksimal hastighed på NVIDIA |
En forbehold om den tabel: hastigheds- og VRAM-rangeringerne stammer fra oobabooga-benchmark, som kørte på hardware fra 2023/2024. Betragt den relative rækkefølge som holdbar. EXL2 er bygget til hastighed, AWQ bytter VRAM for hurtig indlæsning, GGUF forbliver slank og portabel, men læs ikke de oprindelige absolutte tokens-pr.-sekund-tal som aktuelle. En 2026-GPU vil levere meget forskellig rå throughput; det er rangordenen, der holder.
Så beslutningsreglen, der falder ud af det: hvis du har et NVIDIA-kort og bekymrer dig mest om hastighed, EXL2; hvis du vil have det sikreste lokale standardvalg på tværs af forskellig hardware, GGUF. AWQ og GPTQ betyder mest, når en bestemt serveringsstak (vLLM, TGI) eller eksisterende værktøjer skubber dig dertil.
Hvorfor bruger en lokal LLM mere hukommelse end dens fil?
Filstørrelsen er kun modellens vægte. Ved runtime betaler du også for KV cachen (attention-tilstanden for hvert token i dit context-vindue), aktiveringer (den mellemliggende matematik i et forward pass) og framework- og driver-overhead. Tilsammen lægger de ikke-vægt-relaterede dele typisk 10-20% oveni vægtene for en single-user-opsætning, og KV cachen alene kan overskygge alt, når context bliver lang. En 4,6 GB-fil kan kræve langt mere end 4,6 GB hukommelse for at køre.
Tænk på runtime-hukommelse som fire komponenter, der er stablet oven på hinanden:
- Modelvægte. Filen, du downloadede. Det er den eneste del, der er synlig, før du indlæser.
- KV cache. Attention-tilstand for context-vinduet. Lille ved kort context, meget stor ved lang context. Det er det næste afsnit, fordi det er det, der overrasker folk.
- Aktiveringer. Arbejdshukommelsen for et forward pass. Ved single-stream lokal inferens (batch size 1) er dette lille, typisk et par hundrede megabyte.
- Framework-overhead. Runtime's egen footprint plus GPU-driver-konteksten. For en let, lokal runtime kan dette være lille sammenlignet med modelvægte og KV cache; tungere serveringsframeworks kan reservere langt mere. Dit styresystems egen hukommelsesreservation ligger uden for dette og er igen separat.
Vægtene og framework-overheaden er forudsigelige. KV cachen er den variabel, der forvandler en model, der "passer", til en model, der crasher, så det er værd at gennemgå det faktiske regnestykke.
Hvor meget hukommelse bruger KV cachen?
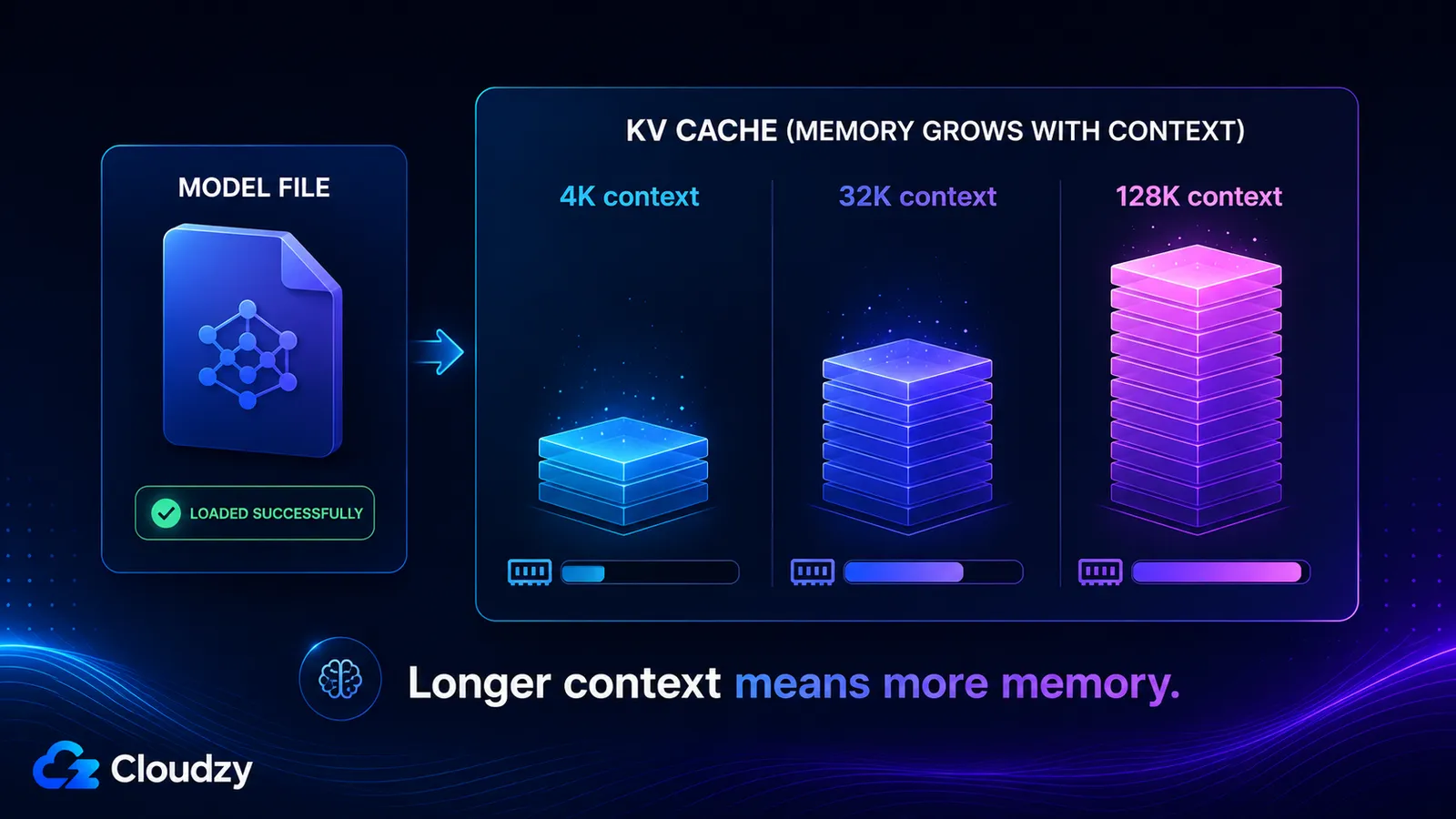
KV cachen gemmer key- og value-vektorerne for hvert token i dit context-vindue, så den vokser omtrent lineært med context-længden og er helt adskilt fra modellens vægte. Dens størrelse bestemmes af modellens antal lag, antal KV-heads, head-dimensionen, context-længden og cachens præcision. Slå en lang context til, og du kan tilføje snesevis af gigabyte, som en model, der indlæste fint, aldrig advarede dig om.
Formlen er kort nok til at holde i hovedet:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Det indledende 2-tal er for de to tensorer, der gemmes pr. token, én for keys, én for values. bytes_per_element er 2 for en FP16-cache. Resten er arkitekturkonstanter, du kan aflæse fra et model card.
Regn det ud for Llama 3.1 8B, som har 32 lag, 8 KV-heads og en head-dimension på 128. Ved en 4.096-token context, batch size 1, FP16-cache:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Skaler context'en op, og tallet skaleres med den, fordi hvert led undtagen context_tokens er fast:
- 4K context: ~536 MB
- 32K context: ~4,3 GB
- 128K context: ~17 GB
De sidste to er grunden til, at en model kan erklære et 128K context-vindue, indlæses uden problemer, og derefter opbruge hukommelsen i det øjeblik, du faktisk bruger det vindue. KV cachen ved fuld context er større end de kvantiserede vægte selv.
Her er den del, der overhovedet gør moderne long-context-modeller mulige: Llama 3.1 8B bruger Grouped Query Attention (GQA)bruger. Den har 32 query-heads, men kun 8 KV-heads, cachen gemmer key/value-vektorer for 8 heads, ikke 32. Kør den samme formel med 32 KV-heads (det ældre Multi-Head Attention-design, hvor KV-heads er lig query-heads), og hvert tal ovenfor ganges med 4. De 17 GB ved 128K bliver til 68 GB. GQA er den arkitektoniske grund til, at regnestykket forbliver overlevelig, efterhånden som context-vinduer er vokset.
Filstørrelsen er ikke dit hukommelsesbudget. Når vægtene eller KV cachen ikke længere kan være i den hurtige hukommelsessti, og runtime må falde tilbage til system-RAM over PCIe, forringes gennemløbet ikke blidt. Det styrtdykker, så snart du flytter data over PCIe for hvert token. Budgetter hukommelse, så vægtene og KV cachen ved din reelle context-længde begge passer, ikke kun vægtene.
Hvordan vælger du en quant til din GPU eller Mac?
Start med din hardware og runtime. Ejere af NVIDIA-GPU'er har den bredeste menu og bør overveje EXL2 for rå hastighed eller GGUF for portabilitet. Hvis du er på AMD, Apple Silicon, ren CPU-hardware eller en blandet opsætning, er GGUF via llama.cpp som regel det sikreste udgangspunkt. Derfra vælger du det højeste quant-niveau, der passer, efter du har budgetteret for KV cachen ved den context-længde, du faktisk bruger, ikke modellens maksimum.
En Apple Silicon-fælde, det er værd at kende: GPU'en får ikke al din unified memory (se vores ledsagende artikel om hvad unified memory faktisk er for det fulde billede af, hvordan den delte pulje fungerer). Self-hosting-communityet har dokumenteret en grænse på omkring 75% af den samlede unified memory, der er tilgængelig for GPU'en (dette er ikke officielt bekræftet af Apple og kan ændre sig med macOS-opdateringer). Så en "64 GB Mac" er realistisk set ~48 GB til modellen plus dens KV cache, planlæg efter det mindre tal.
Denne artikel handler om at læse formatet og forudsige dets runtime-adfærd: afkod quant-navnet, vælg det format, din hardware understøtter, og budgetter KV cachen separat fra vægtene. At matche en bestemt model til en bestemt mængde hukommelse, opslagstabellen fra størrelse til hukommelse, er et beslægtet, men separat spørgsmål, vi dækker i en kommende ledsagende artikel.
Læs repo'et
Du kan nu se på en modelside og læse den i stedet for at gætte. Afkod quant-navnet til dens effektive bit-bredde, anerkend at GGUF er det bredeste lokale format, mens GPTQ, AWQ og EXL2 er mere runtime-specifikke, og husk, at filstørrelsen kun er gulvet, KV cachen lægges oveni og vokser med din context. Åbn filerne for den model, du vil have, vælg det format, din hardware kan køre, vælg det højeste quant-niveau, der passer, efter du har efterladt plads til KV cachen ved din reelle context-længde, og du vil undgå det out-of-memory-crash, der startede hele dette spørgsmål.
Ofte stillede spørgsmål
Hvad betyder Q4_K_M?
Q4_K_M er et GGUF-kvantiseringsniveau: omkring 4 bit pr. vægt (Q4), med K-quant per-blok-skalering (K), ved det medium størrelses-/kvalitetsniveau (M). Dens effektive bit-bredde er omkring 4,89 bit pr. vægt, ikke præcis 4, fordi K-quants gemmer en skala og en minimumsværdi for hver blok af vægte. Det er derfor, en "4-bit" 8B-modelfil er omkring 4,6 GB frem for 3,5 GB.
Reducerer kvantisering LLM-kvaliteten?
Ja, men omkostningen afhænger meget af, hvor langt du presser det. På Llama-3.1-8B-Instruct, målt i arXiv:2601.14277, stiger perplexity kun omkring 0,4% ved Q6_K og forbliver nær 1% gennem Q5-båndet. Falder du til Q4, er stigningen stadig beskeden (nogle få procent); under Q3_K_M stiger den stejlt og når +22% ved Q3_K_S. Til de fleste formål er Q4_K_M og opefter reelt tabsfri; den stejle straf ligger ved 3 bit og derunder.
Hvad er forskellen mellem GGUF, GPTQ, AWQ og EXL2?
GGUF (kørt af llama.cpp) er det portable format, det virker på CPU, GPU eller en hybrid opsætning på tværs af en bred vifte af hardware. GPTQ, AWQ og EXL2 er mere GPU- og runtime-specifikke. Ved 4-bit kan alle fire lande i et smalt kvalitetsbånd, så den praktiske forskel er hardware, loader-understøttelse, hastighed og VRAM-brug: EXL2 er det hastighedsfokuserede NVIDIA/CUDA-valg, AWQ er almindeligt i serveringsstakke, GPTQ passer til ældre GPU-værktøjer og modelrepos, og GGUF forbliver den mest portable lokale mulighed.
Hvorfor bruger min lokale LLM mere hukommelse end filen?
Filstørrelsen er kun modellens vægte. Ved runtime betaler du også for KV cachen (attention-tilstand for hvert token i context-vinduet), aktiveringer og framework plus driver-overhead. KV cachen er den sædvanlige synder, når forskellen er stor, fordi den vokser med context-længden og allokeres separat fra vægtene, en model, hvis fil er nogle få gigabyte, kan kræve langt mere hukommelse, når du sætter en lang context.
Hvordan påvirker context-længde hukommelsesforbruget?
KV cachen vokser omtrent lineært med context-længden, så en fordobling af din context omtrent fordobler cachen. For Llama 3.1 8B er cachen omkring 536 MB ved 4K tokens, ~4,3 GB ved 32K og ~17 GB ved 128K (FP16, single stream). Den vækst er helt adskilt fra modellens vægte, hvilket er grunden til, at det at erklære et langt context-vindue kan skubbe en model ud i out-of-memory, selv om den indlæste fint.


