
Apri la pagina GGUF di un modello popolare su Hugging Face e ci sono quindici file che ti fissano: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, più cartelle separate per GPTQ, AWQ ed EXL2 con una mezza dozzina di impostazioni di bit. Fai il calcolo a spanne per il file "a 4 bit": 4 bit × 8 miliardi di parametri ÷ 8 = 4 GB. Ma il file dice 4,6 GB. E una volta caricato, il modello usa più memoria di quella.
I nomi dei file non sono rumore. Codificano informazioni reali, interpretabili, sulla larghezza in bit, sul runtime che li carica e sull'hardware necessario. Le tabelle di dimensionamento che hai letto ti dicono che un modello da 70B necessita di circa 40 GB, utile, ma non decodificano mai il formato in sé né spiegano perché il modello in esecuzione richieda più memoria del file su disco.
Ecco quindi il piano: decodificare la convenzione di denominazione GGUF (con le larghezze in bit reali, non quelle nominali), capire quale dei quattro formati il tuo hardware può effettivamente eseguire, e considerare l'unico costo di memoria invisibile in ogni dimensione di file, la cache KV. Alla fine sarai in grado di leggere un repository di modelli e prevedere come si comporterà al caricamento.
TL;DR
- I livelli di quantizzazione GGUF sono larghezze in bit effettive, non il numero esatto nel nome. Q4_K_M è circa 4,89 bit per peso, motivo per cui un file "a 4 bit" da 8B si attesta intorno ai 4,6 GiB invece della stima ingenua a 4 bit.
- GGUF è l'opzione più portabile perché llama.cpp può eseguirlo su CPU, GPU o in configurazione ibrida. GPTQ, AWQ ed EXL2 sono più specifici per GPU e runtime, con EXL2 particolarmente legato ai flussi di lavoro NVIDIA/CUDA.
- La cache KV è separata dai pesi del modello e cresce con la lunghezza del contesto. È il motivo per cui un modello che si carica perfettamente può comunque andare in crash per esaurimento della memoria una volta che la conversazione si allunga.
- Sopra l'intervallo a 5 bit, la perdita di qualità è di solito piccola. Intorno a Q4, il compromesso resta praticabile per molti casi d'uso locali. Sotto i 4 bit, il costo in termini di qualità diventa molto più evidente. Q4_K_M rimane un default comune nella comunità, mentre Q5_K_M e Q6_K sono più sicuri quando hai memoria da parte.
Cosa significa Q4_K_M in un nome di file GGUF?

Un nome di quantizzazione GGUF segue lo schema Q[bit]_[K]_[S/M/L]. Il numero è il obiettivo di bit per peso, K significa che è un "K-quant" che memorizza fattori di scala per ogni piccolo blocco di pesi, e la S, M o L finale indica il livello di dimensione/qualità (small, medium, large). Poiché i K-quant memorizzano una scala e un valore minimo per ogni blocco insieme ai pesi, la larghezza in bit effettiva effettiva è superiore al numero indicato nel nome. Q4_K_M si attesta a circa 4,89 bit per peso, non 4.
Quella differenza è tutta la risposta alla domanda "perché il mio file a 4 bit è di 4,6 GB?". La stima ingenua presume che ogni peso costi esattamente 4 bit. In realtà, i K-quant spendono bit extra per blocco sui metadati che rendono accurata la quantizzazione a basso numero di bit, la scala e il minimo per blocco che permettono al runtime di ricostruire ogni peso. Moltiplica 4,89 bit per 8 miliardi di pesi e arrivi a circa 4,58 GiB, che è ciò che il file effettivamente pesa.
Ecco le larghezze in bit effettive misurate e le dimensioni dei file, tratte dal llama.cpp quantize documentation per Llama 3.1 8B come modello di riferimento, insieme al costo di perplexity di ogni livello misurato nel paper di valutazione della quantizzazione di llama.cpp (arXiv:2601.14277) su Llama-3.1-8B-Instruct:
| Livello GGUF | BPW effettivo | ~Dimensione file (8B) | Perplexity vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | riferimento |
*I numeri di perplexity si riferiscono nello specifico a Llama-3.1-8B-Instruct da arXiv:2601.14277. La colonna BPW/dimensione file e la colonna perplexity provengono da due fonti diverse misurate separatamente, quindi leggi la tabella come un riferimento pratico affiancato piuttosto che come un'unica esecuzione di benchmark. Il degrado specifico per compito varia, il ragionamento matematico tende a soffrire più del ragionamento di buon senso a larghezze di bit basse, ma la tendenza generale resta valida: 5 bit e oltre sono di solito più sicuri, Q4 è la zona di compressione pratica, e 3 bit è dove la perdita di qualità diventa molto più difficile da ignorare.
In pratica: Q4_K_M è il default a cui la maggior parte delle persone dovrebbe puntare, Q5_K_M e Q6_K sono le scelte orientate alla qualità quando hai memoria da parte, e qualsiasi cosa pari o inferiore a Q3_K_S è un'ultima risorsa per hardware che davvero non può contenere di più.
Quale formato di quantizzazione dovresti scaricare: GGUF, GPTQ, AWQ o EXL2?

GGUF è il più portabile dei quattro: gira su CPU, GPU o una combinazione ibrida di entrambe tramite llama.cpp, quindi è la scelta più sicura quando non sei certo di cosa il tuo hardware possa supportare. GPTQ, AWQ ed EXL2 sono più specifici per GPU e runtime. In pratica, sono più comuni su configurazioni NVIDIA/CUDA, ma il supporto a GPTQ e AWQ può variare a seconda del loader e dello stack di serving; vLLM, per esempio, distingue il supporto alla quantizzazione in base a hardware e implementazione. Se stai eseguendo localmente su un Mac, una scheda AMD o una macchina solo CPU, GGUF resta la risposta più sicura. Se hai una GPU NVIDIA e vuoi i token più veloci possibili, entrano in gioco gli altri tre.
| Formato | Hardware/runtime | Velocità (relativa) | VRAM rispetto ai concorrenti | Ideale per |
|---|---|---|---|---|
| GGUF Q4_K_M | Il più ampio, CPU, GPU o ibrido tramite llama.cpp | Moderato | Il più basso | Qualsiasi hardware; default locale |
| GPTQ 4 bit | Di solito CUDA/GPU-first; dipende dal runtime | Veloce (ExLlama) | Medio | GPU-first, strumenti legacy |
| AWQ 4 bit | Di solito CUDA/GPU-first; dipende dal runtime | Veloce | Più alto | Serving vLLM/TGI, caricamento rapido |
| EXL2 ~4,9 bpw | NVIDIA/CUDA-first | Più veloce | Basso-Medio | Velocità massima su NVIDIA |
Un avvertimento su quella tabella: le classifiche di velocità e VRAM provengono dal benchmark di oobabooga, eseguito su hardware dell'era 2023/2024. Considera l'ordine relativo come duraturo. EXL2 è costruito per la velocità, AWQ scambia VRAM per un caricamento rapido, GGUF resta snello e portabile, ma non leggere i numeri assoluti originali di token al secondo come attuali. Una GPU del 2026 presenterà un throughput grezzo molto diverso; ciò che rimane valido è la gerarchia relativa.
Quindi la regola decisionale che ne deriva: se hai una scheda NVIDIA e ti importa soprattutto la velocità, EXL2; se vuoi il default locale più sicuro tra hardware diversi, GGUF. AWQ e GPTQ contano soprattutto quando uno stack di serving specifico (vLLM, TGI) o strumenti già esistenti ti spingono in quella direzione.
Perché un LLM locale usa più memoria del suo file?
La dimensione del file rappresenta solo i pesi del modello. In fase di esecuzione paghi anche la cache KV (lo stato di attenzione per ogni token nella finestra di contesto), le attivazioni (la matematica intermedia di un forward pass) e l'overhead del framework e del driver. Insieme, le componenti che non sono peso aggiungono di solito dal 10 al 20% sopra i pesi per una configurazione a singolo utente, e la sola cache KV può da sola sovrastare tutto il resto una volta che il contesto si allunga. Un file da 4,6 GB può richiedere ben più di 4,6 GB di memoria per funzionare.
Pensa alla memoria di runtime come a quattro componenti impilate una sull'altra:
- Pesi del modello. Il file che hai scaricato. È l'unica parte visibile prima del caricamento.
- Cache KV. Stato di attenzione per la finestra di contesto. Piccolo con contesto breve, enorme con contesto lungo. Questa è la prossima sezione, perché è quella che sorprende le persone.
- Attivazioni. La memoria di lavoro di un forward pass. Per l'inferenza locale a flusso singolo (batch size 1), è piccola, tipicamente poche centinaia di megabyte.
- Overhead del framework. L'ingombro proprio del runtime più il contesto del driver GPU. Per un runtime locale leggero, questo può essere piccolo rispetto ai pesi del modello e alla cache KV; framework di serving più pesanti possono riservarne molto di più. La riserva di memoria del sistema operativo stesso è esterna a questo ed è a sua volta separata.
I pesi e l'overhead del framework sono prevedibili. La cache KV è la variabile che trasforma un modello che "entra" in un modello che va in crash, quindi vale la pena ripercorrere i calcoli reali.
Quanta memoria usa la cache KV?
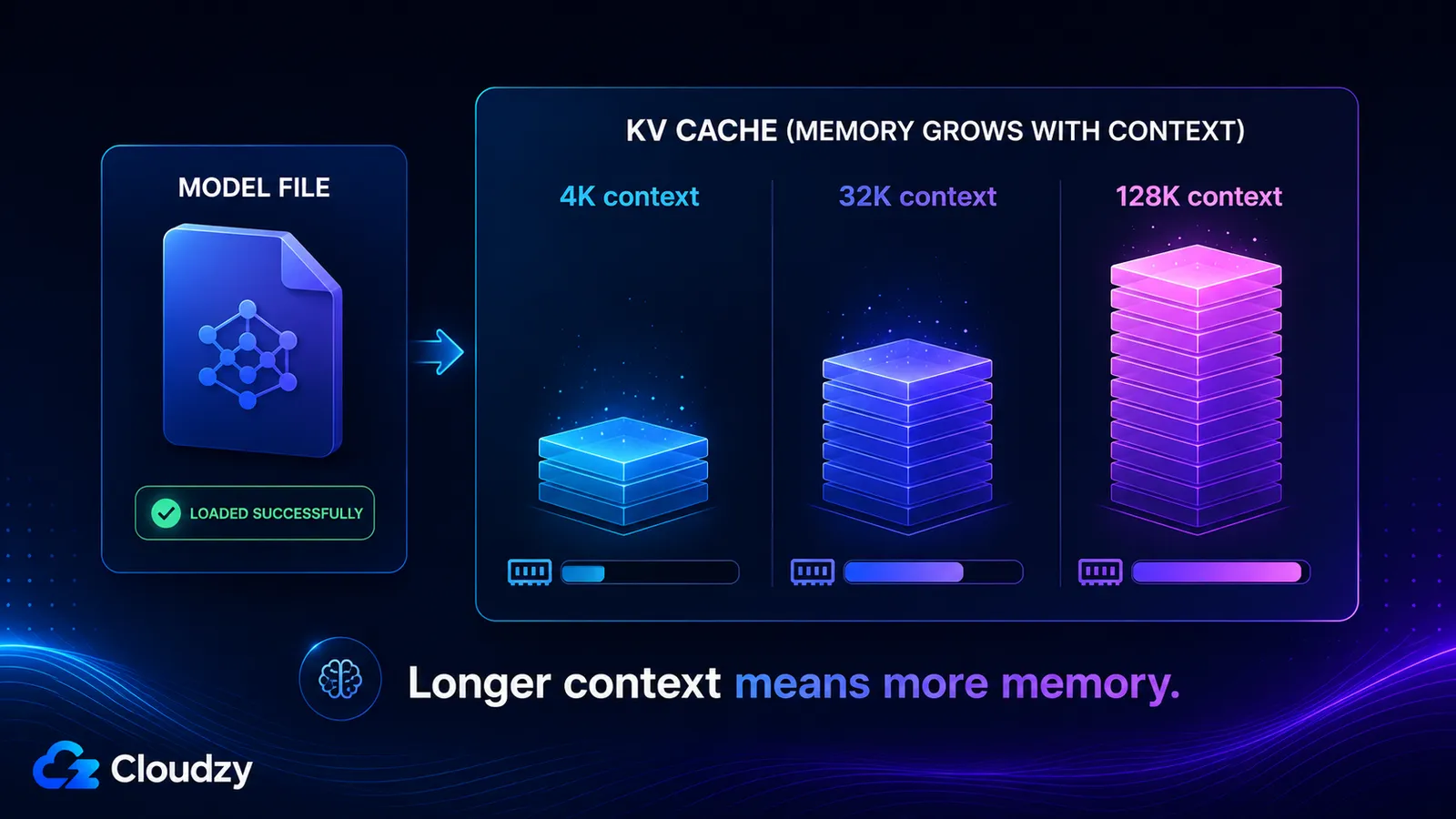
La cache KV memorizza i vettori chiave e valore per ogni token nella finestra di contesto, quindi cresce in modo approssimativamente lineare con la lunghezza del contesto ed è completamente separata dai pesi del modello. La sua dimensione è determinata dal numero di livelli del modello, dal numero di teste KV, dalla dimensione della testa, dalla lunghezza del contesto e dalla precisione della cache. Attiva un contesto lungo e puoi aggiungere decine di gigabyte di cui un modello caricato correttamente non ti ha mai avvertito.
La formula è abbastanza breve da tenere a mente:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Il 2 iniziale rappresenta i due tensori memorizzati per token, uno per le chiavi, uno per i valori. bytes_per_element è 2 per una cache FP16. Il resto sono costanti architetturali leggibili da una model card.
Calcoliamola per Llama 3.1 8B, che ha 32 livelli, 8 teste KV e una dimensione della testa di 128. Con un contesto di 4.096 token, batch size 1, cache FP16:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Aumenta il contesto e il numero cresce di conseguenza, perché ogni termine tranne context_tokens è fisso:
- Contesto 4K: ~536 MB
- Contesto 32K: ~4,3 GB
- Contesto 128K: ~17 GB
Questi ultimi due valori spiegano perché un modello possa dichiarare una finestra di contesto di 128K, caricarsi senza problemi, e poi esaurire la memoria nel momento in cui usi effettivamente quella finestra. La cache KV a contesto pieno è più grande degli stessi pesi quantizzati.
Ecco la parte che rende possibili i moderni modelli a contesto lungo: Llama 3.1 8B usa Grouped Query Attention (GQA)questo meccanismo. Ha 32 teste di query ma solo 8 teste KV, la cache memorizza vettori chiave/valore per 8 teste, non per 32. Esegui la stessa formula con 32 teste KV (il vecchio design Multi-Head Attention, in cui le teste KV eguagliano le teste di query) e ogni numero sopra si moltiplica per 4. Quei 17 GB a 128K diventano 68 GB. GQA è la ragione architetturale per cui i calcoli restano sostenibili man mano che le finestre di contesto sono cresciute.
La dimensione del file non è il tuo budget di memoria. Quando i pesi o la cache KV non entrano più nel percorso di memoria veloce e il runtime deve ripiegare sulla RAM di sistema via PCIe, il throughput non degrada gradualmente. Precipita non appena inizi a spostare dati attraverso il PCIe a ogni token. Pianifica la memoria in modo che sia i pesi sia la cache KV alla tua lunghezza di contesto reale entrino, non solo i pesi.
Come scegliere una quantizzazione per la tua GPU o il tuo Mac?
Parti dal tuo hardware e runtime. I proprietari di GPU NVIDIA hanno la scelta più ampia e dovrebbero valutare EXL2 per la velocità pura o GGUF per la portabilità. Se sei su AMD, Apple Silicon, hardware solo CPU, o una configurazione mista, GGUF tramite llama.cpp è di solito il punto di partenza più sicuro. Da lì, scegli il livello di quantizzazione più alto che entra dopo aver preventivato la cache KV alla lunghezza di contesto che usi realmente, non al massimo del modello.
Una trappola dell'Apple Silicon che vale la pena conoscere: la GPU non riceve tutta la tua memoria unificata (vedi il nostro articolo di approfondimento su cos'è davvero la memoria unificata per il quadro completo di come funziona quel pool condiviso). La comunità self-hosting ha documentato un limite di circa il 75% della memoria unificata totale disponibile per la GPU (questo non è confermato ufficialmente da Apple e può cambiare con gli aggiornamenti di macOS). Quindi un "Mac da 64 GB" corrisponde realisticamente a ~48 GB per il modello più la sua cache KV, pianifica sul numero più piccolo.
Questo articolo riguarda la lettura del formato e la previsione del suo comportamento a runtime: decodificare il nome della quantizzazione, scegliere il formato supportato dal tuo hardware e preventivare la cache KV separatamente dai pesi. Abbinare un modello specifico a una quantità specifica di memoria, la tabella di corrispondenza tra dimensione e memoria, è una questione correlata ma separata che tratteremo in un futuro articolo di approfondimento.
Leggi il repository
Ora puoi guardare la pagina di un modello e leggerla invece di indovinare. Decodifica il nome della quantizzazione nella sua larghezza in bit effettiva, riconosci che GGUF è il formato locale più ampio mentre GPTQ, AWQ ed EXL2 sono più specifici per runtime, e ricorda che la dimensione del file è solo il pavimento, la cache KV si accumula sopra e cresce con il tuo contesto. Apri i file del modello che vuoi, scegli il formato che il tuo hardware può eseguire, scegli il livello di quantizzazione più alto che entra dopo aver lasciato margine per la cache KV alla tua lunghezza di contesto reale, ed eviterai il crash per esaurimento della memoria che ha dato origine a tutta questa domanda.
Domande frequenti
Cosa significa Q4_K_M?
Q4_K_M è un livello di quantizzazione GGUF: circa 4 bit per peso (Q4), con scaling K-quant per blocco (K), al livello di dimensione/qualità medio (M). La sua effettiva larghezza in bit è di circa 4,89 bit per peso, non esattamente 4, perché i K-quant memorizzano una scala e un valore minimo per ogni blocco di pesi. Ecco perché un file di modello "a 4 bit" da 8B è di circa 4,6 GB anziché 3,5 GB.
La quantizzazione riduce la qualità dell'LLM?
Sì, ma il costo dipende molto da quanto si spinge la compressione. Su Llama-3.1-8B-Instruct misurato in arXiv:2601.14277, la perplexity aumenta solo di circa lo 0,4% a Q6_K e resta vicino all'1% nella fascia Q5. Scendendo a Q4 l'aumento è ancora modesto (pochi punti percentuali); sotto Q3_K_M sale ripidamente, raggiungendo il +22% a Q3_K_S. Per la maggior parte degli usi, Q4_K_M e livelli superiori sono effettivamente senza perdite; la penalità ripida si trova a 3 bit e sotto.
Qual è la differenza tra GGUF, GPTQ, AWQ ed EXL2?
GGUF (eseguito da llama.cpp) è il formato portabile, funziona su CPU, GPU o in configurazione ibrida su un'ampia gamma di hardware. GPTQ, AWQ ed EXL2 sono più specifici per GPU e runtime. A 4 bit, tutti e quattro possono rientrare in una fascia di qualità ristretta, quindi la differenza pratica sta nell'hardware, nel supporto dei loader, nella velocità e nell'uso della VRAM: EXL2 è la scelta orientata alla velocità per NVIDIA/CUDA, AWQ è comune negli stack di serving, GPTQ si adatta a strumenti GPU e repository di modelli più datati, e GGUF resta l'opzione locale più portabile.
Perché il mio LLM locale usa più memoria del file?
La dimensione del file è solo i pesi del modello. In fase di esecuzione paghi anche la cache KV (stato di attenzione per ogni token nella finestra di contesto), le attivazioni, e l'overhead del framework più il driver. La cache KV è di solito la colpevole quando il divario è grande, perché cresce con la lunghezza del contesto ed è allocata separatamente dai pesi, un modello il cui file è di pochi gigabyte può richiedere molta più memoria non appena imposti un contesto lungo.
In che modo la lunghezza del contesto influisce sull'uso della memoria?
La cache KV cresce in modo approssimativamente lineare con la lunghezza del contesto, quindi raddoppiare il contesto raddoppia all'incirca la cache. Per Llama 3.1 8B, la cache è di circa 536 MB a 4K token, ~4,3 GB a 32K, e ~17 GB a 128K (FP16, flusso singolo). Questa crescita è interamente separata dai pesi del modello, motivo per cui dichiarare una finestra di contesto lunga può portare un modello a esaurire la memoria anche se si è caricato correttamente.


