Software de monitoramento GPU é a ferramenta que transforma um vago 'meu GPU está estranho' em uma explicação direta e clara, tipo 'hotspot disparou, clocks caíram, e VRAM lotou'.
Neste guia, vou te mostrar as ferramentas que você pode usar para jobs de IA, overlays para games e sessões longas de workstation, e vou indicar quais métricas GPU ajudam a diagnosticar lentidão, stutters e travamentos.
Ao final, você terá uma configuração de software de monitoramento GPU que se encaixa no seu workflow. Você também vai receber stacks prontos para copiar em quatro casos de uso comuns, então não vai precisar ficar procurando artigos de novo.
Resposta Rápida: Melhores Ferramentas de Monitoramento GPU por Caso de Uso
Se você quer só uma lista curta que combine com o seu jeito de trabalhar, comece por essas. Na prática, o melhor stack de software de monitoramento GPU é geralmente uma combinação: uma ferramenta para verificações rápidas, uma para overlays ou logs, e uma para histórico ou alertas.
Aqui está o mapa rápido:
| Caso de Uso | Stack Inicial Recomendado | O Que Você Ganha |
| Treinamento de IA, inferência, jobs HPC | nvidia-smi (NVIDIA) ou AMD SMI (AMD) + logging/exporter | Verificações rápidas, logs scriptáveis, alertas fáceis |
| Jogos no Windows | MSI Afterburner + RTSS + uma ferramenta de captura de frametime | Overlay mais prova para diferenciar stutter de FPS baixo |
| Jogos no Linux | MangoHud + um verificador de terminal (nvtop) | Overlay leve mais verificações por processo |
| Workstations (3D/vídeo/CAD) | HWiNFO logging + um teste de stress simples | Logs longos que você pode compartilhar, reprodução previsível |
| Máquinas GPU compartilhadas | nvtop (Linux) + exportador/painel de controle | Visibilidade VRAM por processo |
Daqui em diante, o essencial é alinhar o software de monitoramento GPU com a forma como você consome dados: na tela, em um log ou em um painel.
A quem se destina este guia
Vou escrever como alguém que já teve de debugar máquinas de verdade. Porque, pela experiência, sei que leitores diferentes precisam de ferramentas GPU diferentes, mesmo que estejam olhando para o mesmo GPU.
Aqui estão os quatro cenários que estou abordando:
- O Construtor de Modelos (IA/ML): se importa com margem VRAM, clocks sustentados, throttling e "o job rodou a noite toda sem cair?"
- O Gamer/Streamer Competitivo: se importa com frametimes, estabilidade do overlay e detectar regressões após atualizações de driver.
- O Usuário de Workstation (3D/vídeo/CAD): se importa com logs, crashes reproduzíveis e identificar se o problema é calor, potência ou driver.
- O Admin Gerenciando Máquinas GPU: se importa com alertas, gráficos de tendência, planejamento de capacidade e detectar falhas cedo.
Assim que você souber em qual categoria se encaixa, fica fácil escolher o software de monitoramento GPU que funciona para você.
Como Escolher Software de Monitoramento GPU
Muitos apps de monitoramento de performance parecem iguais até você usar por uma semana. A diferença principal costuma estar na saída de dados e confiabilidade, não naqueles "recursos" atraentes que cada um desesperadamente anuncia.
Presento três perguntas para ajudar você a escolher software de monitoramento GPU rapidamente:
- Você precisa de um overlay, um log ou os dois?
Gamers querem overlay. Trabalho com IA e workstation geralmente precisa de logs. Admins querem logs mais alertas. - Você precisa de visibilidade por processo?
Se você compartilha uma máquina (lab, estúdio, servidor remoto), visibilidade VRAM por processo é muitas vezes a primeira coisa que você procura. - Você precisa de histórico e alertas?
Se jobs rodam à noite, "vejo depois" não é suficiente. Você quer um gráfico e um alerta.
Para manter isso prático, o resto do guia está organizado por métricas GPU primeiro, depois stacks de ferramentas que se encaixam em cada caso de uso.
Métricas GPU Que Você Deveria Priorizar
Qualquer software de monitoramento GPU oferece um monte de números. Software de monitoramento GPU genuinamente útil oferece aquele punhado específico que explica o comportamento. Agrupo as métricas GPU pela decisão que elas ajudam você a tomar.
Métricas de Temperatura e Estrangulamento
Estas são as métricas GPU que explicam "foi rápido por 10 minutos, depois não foi mais":
- Temperatura da GPU
- Temperatura do ponto de acesso (geralmente a primeira coisa a disparar)
- Temperatura da memória/junção (mais relevante em execuções longas de IA e renders longos)
- Velocidade do ventilador (ajuda a identificar perfis de laptop ou curvas de ventoinhas ruins)
Se você quer melhorar a estabilidade, registre essas métricas, pois snapshots únicos raramente fornecem informações suficientes.
Potência, Clocks e Limites
Estas métricas GPU explicam redução de clock e desempenho inconsistente:
- Consumo de energia da placa
- Clock do núcleo e clock da memória
- Limite de potência/estado de desempenho (se sua ferramenta expuser isso)
Em muitos casos reais de debug, potência e clocks pintam uma imagem muito mais clara do que o básico "GPU % de uso".
VRAM e Pressão de Memória
Estas métricas GPU explicam travamentos, erros de OOM e os típicos slowdowns "aleatórios":
- VRAM usado vs total
- Atividade do controlador de memória (ajuda a identificar limites de largura de banda)
- Pressão de RAM do sistema (porque o transbordamento de VRAM também pode arrastar o sistema para baixo)
Para IA, VRAM é geralmente o limite máximo. Para jogos, a pressão de VRAM geralmente aparece como picos de frametime primeiro.
Métricas de Frametime e Frame Pacing
Para games e streaming, FPS sozinho pode ser enganoso. Frametime é a métrica que você deve prestar atenção, pois rastreia a fluidez ou a falta dela:
- Tempo de quadro (ms)
- 1% baixo / 0.1% baixo (bom para comparações)
- GPU ocupada vs CPU ocupada (ajuda a separar gargalos do GPU dos gargalos do CPU)
Por isso aplicativos de monitoramento de desempenho focados em jogos costumam incluir um caminho de captura de frametime. Com o básico das métricas resolvido, podemos falar sobre os melhores stacks de software de monitoramento GPU para cada fluxo de trabalho.
Software de Monitoramento GPU para IA, Treinamento e Servidores

Monitoramento de IA tem uma configuração simples com verificações rápidas em um terminal, além de logs e alertas para execuções longas. Para isso, você quer um software de monitoramento GPU que funcione com CLI e exporte métricas.
NVIDIA: nvidia-smi para Verificações Rápidas e Logs Programáveis
Em sistemas NVIDIA, nvidia-smi geralmente é o primeiro comando que as pessoas executam porque vem com o driver e foi projetado para monitoramento e gerenciamento via NVML.
A documentação oficial está aqui: Interface de Gerenciamento de Sistemas NVIDIA (nvidia-smi).
Se você quer uma abordagem simples "registre e veja depois" (e pode se surpreender com a frequência com que isso resolve o problema), esse padrão é bem confiável:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Esse é o comportamento básico de um software de monitoramento GPU com timestamps, métricas principais GPU e uma saída que funciona bem com scripts.
AMD: AMD SMI para ROCm e Nós HPC
Em nós de computação AMD Linux, AMD SMI é a interface moderna de monitoramento e gerenciamento, e AMD a documenta como um conjunto de ferramentas unificado para monitoramento e controle em contextos HPC.
A documentação oficial está aqui: Documentação AMD SMI.
Se seu ambiente é pesado em AMD, AMD SMI é a base de software de monitoramento GPU sobre a qual outras ferramentas tendem a ser construídas.
Visibilidade por Processo: nvtop para XQNTs0011XZ Compartilhadas
Se você já teve uma máquina compartilhada onde VRAM "misteriosamente" fica cheia, a visibilidade por processo economiza tempo. Em Linux, nvtop é popular exatamente por isso, já que torna "quem está usando VRAM?" óbvio. Em AMD/Intel, você pode precisar de um kernel recente para estatísticas por processo.
Em equipes mistas, frequentemente vejo as pessoas executarem nvtop lado a lado com nvidia-smi ou AMD SMI. É um emparelhamento simples que evita muito trabalho de adivinhação, então recomendo fortemente.
Não Ignore a Escolha de Hardware!
Monitoramento não corrige um limite VRAM; apenas o deixa visível. Se você ainda está mapeando cargas de trabalho para os níveis GPU, nosso guia sobre Melhores GPU para Machine Learning em 2025 é um acompanhamento útil porque enquadra VRAM e largura de banda da mesma forma que você os lerá depois em logs e painéis.
Assim que você tiver o software de monitoramento de servidor GPU sob controle, o próximo passo é overlays e frametimes, já que cargas de trabalho interativas se comportam de forma diferente.
Software de Monitoramento GPU para Jogos e Streaming

Jogos são onde as pessoas têm as opiniões mais fortes sobre ferramentas GPU, principalmente porque overlays falham no pior momento. Para jogos, você quer overlays simples e capturas de frametime reproduzíveis.
MSI Afterburner + RTSS para Overlays em Windows
Essa combinação é bem popular porque você pode criar um overlay limpo com exatamente as métricas GPU que importam, como uso, clocks, VRAM, temperaturas, frametime e talvez velocidade do cooler.
Um aviso sério que aparece repetidamente em threads da comunidade é sobre sites falsos de download. A própria página Afterburner da MSI deixa claro que downloads legítimos devem vir de msi.com e Guru3D, e também lista a linha de versão atual (4.6.6 final, lançado em out 2025).
Problemas de overlay são outra coisa a ficar de olho. Por exemplo, RTSS funciona em alguns jogos e falha em outros, especialmente em render paths modernos. As pessoas relatam casos onde o overlay aparece em Vulkan mas não em DX12 para o mesmo título, ou desaparece após atualizações.
Porém, isso não é por causa de um erro da sua parte, apenas o que acontece quando overlays se conectam a stacks de jogos e drivers em mudança.
Se você quer um overlay de referência estável, mantenha-o simples:
- tempo de quadro
- Uso de GPU
- VRAM utilizado
- Temperatura da GPU
Adicione potência e clocks apenas se estiver ativamente a fazer debug de throttling.
Captura de Frametime para "Stuttering"
Aqui é onde aplicativos de monitoramento de performance que conseguem capturar gráficos de frametime ajudam bastante. FPS médio pode parecer bom enquanto o pacing de frames fica horrível. Gráficos de frametime resolvem essa confusão rápido.
Muitos workflows de benchmark de jogos usam PresentMon por trás, e Documentos NVIDIA que sua análise FrameView usa PresentMon para captura de taxa de quadros e tempo de quadro.
Você não precisa fazer benchmark de todo jogo. Captura de frametime é mais útil para comparações, como antes e depois de uma atualização de driver, antes e depois de mudar um limitador, antes e depois de trocar configurações, e assim por diante.
MangoHud para Overlays Linux
Em Linux, MangoHud é recomendado bastante porque é leve e se integra bem com setups Steam/Proton. As reclamações mais comuns são sobre sensores ausentes ou leituras estranhas em setups híbridos de laptop.
Na prática, você pode facilmente parear MangoHud com um verificador de terminal como nvtop. É também um bom exemplo de como software de monitoramento GPU funciona significativamente melhor como uma pequena pilha, em vez de um único aplicativo gigante.
Saindo dos games, o próximo passo natural é monitorar estações de trabalho, porque ali o que importa é ter logs e poder reproduzir problemas.
Hospede servidores de jogos sem lag com hospedagem VPS NVMe de alta velocidade.
VPS para gaming
GPU Software de Monitoramento para Estações de Trabalho e Apps Profissionais
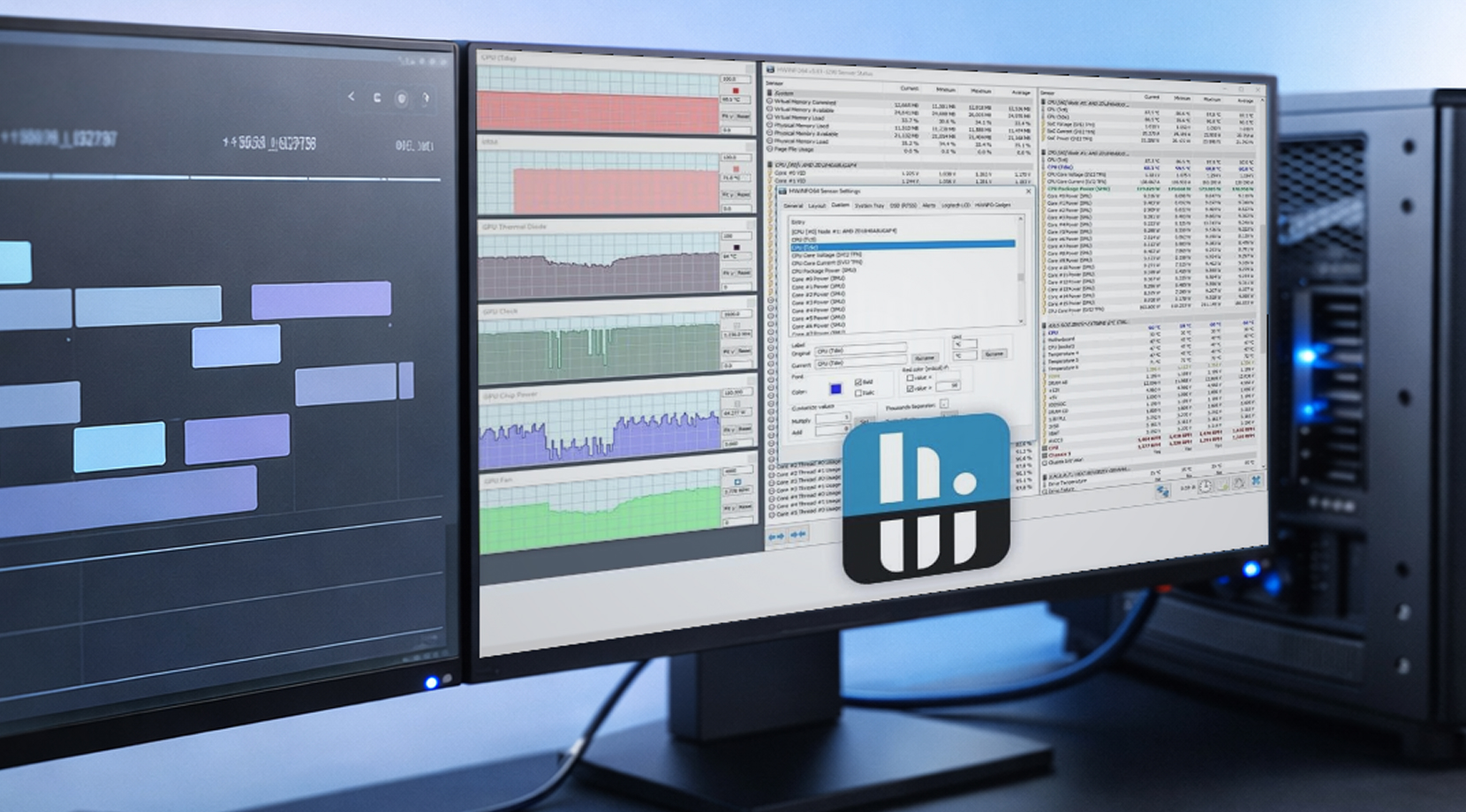
Monitoramento de estação de trabalho não é bem um trabalho de oficial de segurança onde você fica olhando uma sobreposição ao vivo. É mais responder "O que aconteceu ao longo do tempo, e consigo reproduzir isso?"
HWiNFO para Logging em Windows
HWiNFO é popular entre quem trabalha com estações de trabalho porque tem cobertura profunda de sensores e logging fácil de compartilhar. Um simples arquivo CSV com timestamps transforma um relatório vago em algo que você consegue usar para corrigir problemas.
Se você está montando um log de estação de trabalho para a estabilidade do GPU, comece com estas métricas do GPU:
- Temperatura e hotspot do GPU
- VRAM utilizado
- poder da placa
- frequência do núcleo
- Potência do pacote CPU (porque limites de potência da plataforma podem te pegar)
Este é o conjunto "dados suficientes para explicar". É assim porque fazer log de cada sensor só torna o arquivo mais difícil de ler.
GPU-Z para Verificações Rápidas de "Qual GPU É Este?"
GPU-Z ainda é útil porque é rápido e focado. Em equipes com hardware misto, é o jeito mais rápido de confirmar o modelo GPU, o básico do driver e sensores ao vivo sem gastar tempo em menus.
Stress Testing: Só Vale a Pena Com Logging
Testes de stress podem ajudar a reproduzir um crash, mas só se seu software de monitoramento GPU estiver gravando logs enquanto você os executa. Sem aqueles logs, você fica com "crasheou de novo" e praticamente nenhuma linha do tempo.
Neste ponto, a maioria enfrenta os mesmos problemas: overlays que não aparecem, leituras de potência erradas e logs ilegíveis. Vamos resolver isso direto.
Problemas comuns com software de monitorização de GPU e soluções rápidas

A maioria dos problemas cai em alguns padrões. Estas são as correções que tento primeiro porque resolvem as coisas chatas rapidinho.
Overlay Desaparecendo em um Game
Se uma sobreposição desaparece em um título moderno, é frequentemente um problema de hook por jogo ou um conflito com anti-cheat ou camadas anti-tamper.
O que você pode fazer que muitas vezes ajuda:
- Atualize RTSS e reinicie o perfil por jogo
- Defina um "nível de detecção de aplicação" mais alto para o perfil do game
- Tente um API diferente se o game suporta
- Volte para overlays nativos quando um título bloqueia overlays de terceiros
Nem todo game vai cooperar, e não vale a pena perder horas por causa de um título teimoso.
Leituras de Energia Incomuns (0W, Linhas Retas, Sensores Ausentes)
Isso aparece muito em laptops e configurações híbridas onde o GPU ativo pode mudar. Nesses casos, valide com uma segunda ferramenta, como nvidia-smi (NVIDIA) ou AMD SMI (AMD), pois são boas para verificar se o GPU está realmente ativo.
Logs Muito Ruidosos
Superamostragem é a causa usual. Para a maioria dos problemas, 1 a 5 segundos é suficiente. Para jobs de IA longos, 5 segundos funciona bem. Intervalos menores aumentam o tamanho do arquivo e dificultam a leitura dos gráficos.
Depois que o básico está resolvido, monitoramento remoto é o próximo passo lógico, porque muitos fluxos de trabalho do GPU agora rodam fora da máquina.
Monitoramento Remoto do GPU e Uma Opção de Cloud Prática
Trabalho remoto muda o significado de "bom software de monitoramento do GPU". Você nem sempre está olhando para a máquina, então precisa de verificações que consiga fazer rapidamente, mais histórico que possa revisar depois.
Uma configuração remota limpa geralmente fica assim:
- Verificações de CLI (nvidia-smi ou AMD SMI)
- um arquivo de log que você possa baixar depois
- um exportador/dashboard se precisar de alertas
Se o hardware local está bloqueando o progresso (limites do VRAM, compartilhar um único GPU, precisar de um ambiente limpo por projeto), rodar workloads em um GPU VPS pode ser o jeito mais simples de manter o ritmo.
Cloudzy GPU VPS

Se você quer tempo remoto do GPU que funcione para fluxos de IA, gaming e rendering, nossa Cloudzy GPU VPS inclui opções NVIDIA como RTX 5090, A100 e RTX 4090, mais armazenamento NVMe, acesso root completo, conexões de até 40 Gbps, proteção DDoS e objetivo declarado de 99.95% de uptime.
De um ponto de vista de monitoramento, comporta-se como uma máquina normal já que você pode rodar software de monitoramento do GPU via SSH, registrar métricas do GPU para jobs longos e adicionar dashboards se quiser histórico e alertas.
Se ainda está decidindo entre uma instância GPU e uma configuração apenas CPU, nossos artigos sobre O que é um VPS GPU? e GPU vs CPU VPS detalham as diferenças práticas por tipo de workload.
Com o monitoramento remoto resolvido, o último passo é juntar tudo em stacks reutilizáveis.
Stacks Reutilizáveis para Cada Persona
Aqui estão stacks fáceis de seguir que você pode adotar sem reescrever seu fluxo todo. São ótimos pontos de partida para suas configurações, que você pode depois ajustar às suas necessidades específicas.
- Construtor de Modelos (AI/ML): Software de monitoramento do GPU via nvidia-smi ou AMD SMI, mais um log CSV simples, mais um exportador/dashboard se jobs rodarem sem supervisão.
- Gamer Competitivo/Streamer: Overlay de software de monitoramento do GPU via Afterburner + RTSS, mais uma ferramenta de captura de frametime para comparações, mais um conjunto mínimo de métricas na tela.
- Usuário de Estação de Trabalho Software de monitoramento GPU via registro HWiNFO, mais GPU-Z para verificações rápidas de identidade, além de teste de estresse apenas quando você puder registrar a execução.
- Máquinas GPU em Execução do Admin: Software de monitoramento GPU como serviço: exportador + painéis + alertas, mais visibilidade por processo (nvtop) para máquinas compartilhadas.
Se você tirar apenas uma coisa deste guia, que seja esta: escolha software de monitoramento GPU com base em onde você precisa dos dados (sobreposição, registro, painel), depois mantenha seu conjunto de métricas pequeno o suficiente para que você realmente o use.