
Escolher um VPS GPU pode parecer intimidante quando você está olhando para folhas de especificações cheias de números. A contagem de núcleos varia de 2.560 a 21.760, mas o que isso significa?
Um núcleo CUDA é uma unidade de processamento paralelo dentro de GPUs NVIDIA que executa milhares de cálculos simultaneamente, alimentando desde treinamento de IA até renderização 3D. Este guia explica como funcionam, como diferem de CPU e Tensor cores, e quais contagens de núcleos se adequam às suas necessidades sem gastar demais.
O que são núcleos CUDA?

Núcleos CUDA são unidades de processamento individuais dentro de GPUs NVIDIA que executam instruções em paralelo. O que é a tecnologia de núcleo CUDA em sua base? Pense nessas unidades como pequenos trabalhadores atacando partes do mesmo trabalho simultaneamente.
NVIDIA introduziu CUDA (Compute Unified Device Architecture) em 2006 para usar o poder de GPU para computação geral além de gráficos. A documentação oficial de CUDA fornece detalhes técnicos abrangentes. Cada unidade executa operações aritméticas básicas em números de ponto flutuante, perfeito para cálculos repetitivos.
GPUs NVIDIA modernos empacotam milhares dessas unidades em um único chip. GPUs consumidores da geração mais recente contêm mais de 21.000 núcleos, enquanto GPUs de data center baseados na arquitetura Hopper apresentam até 16.896. Essas unidades trabalham juntas por meio de Streaming Multiprocessors (SMs).
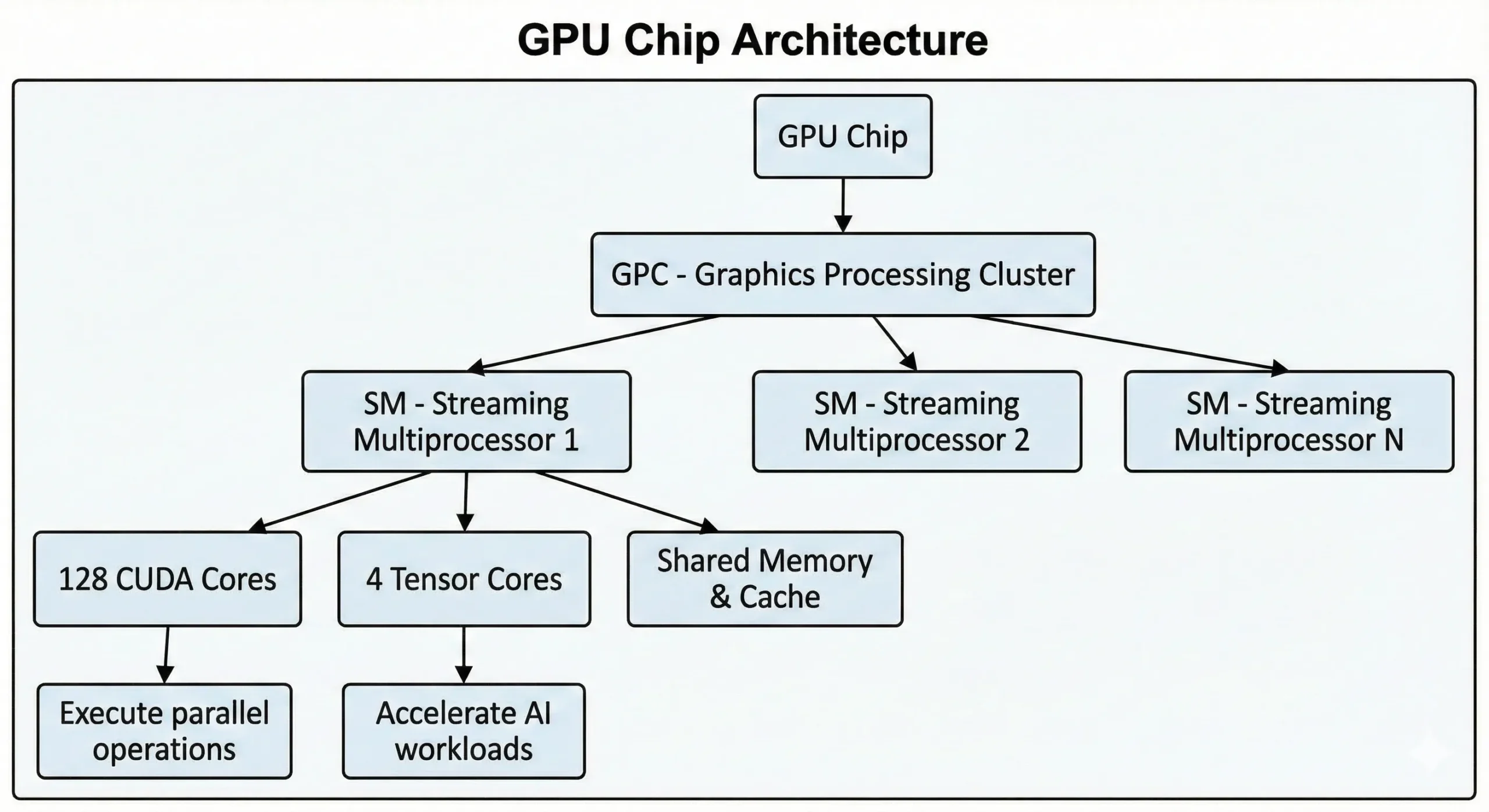
As unidades executam operações SIMT (Single Instruction, Multiple Threads) através de métodos de computação paralela. Uma instrução é executada em muitos pontos de dados ao mesmo tempo. Ao treinar redes neurais ou renderizar cenas 3D, milhares de operações similares ocorrem. Eles dividem esse trabalho em fluxos concorrentes, executando-o simultaneamente em vez de sequencialmente.
Núcleos CUDA vs CPU: O que os Diferencia?

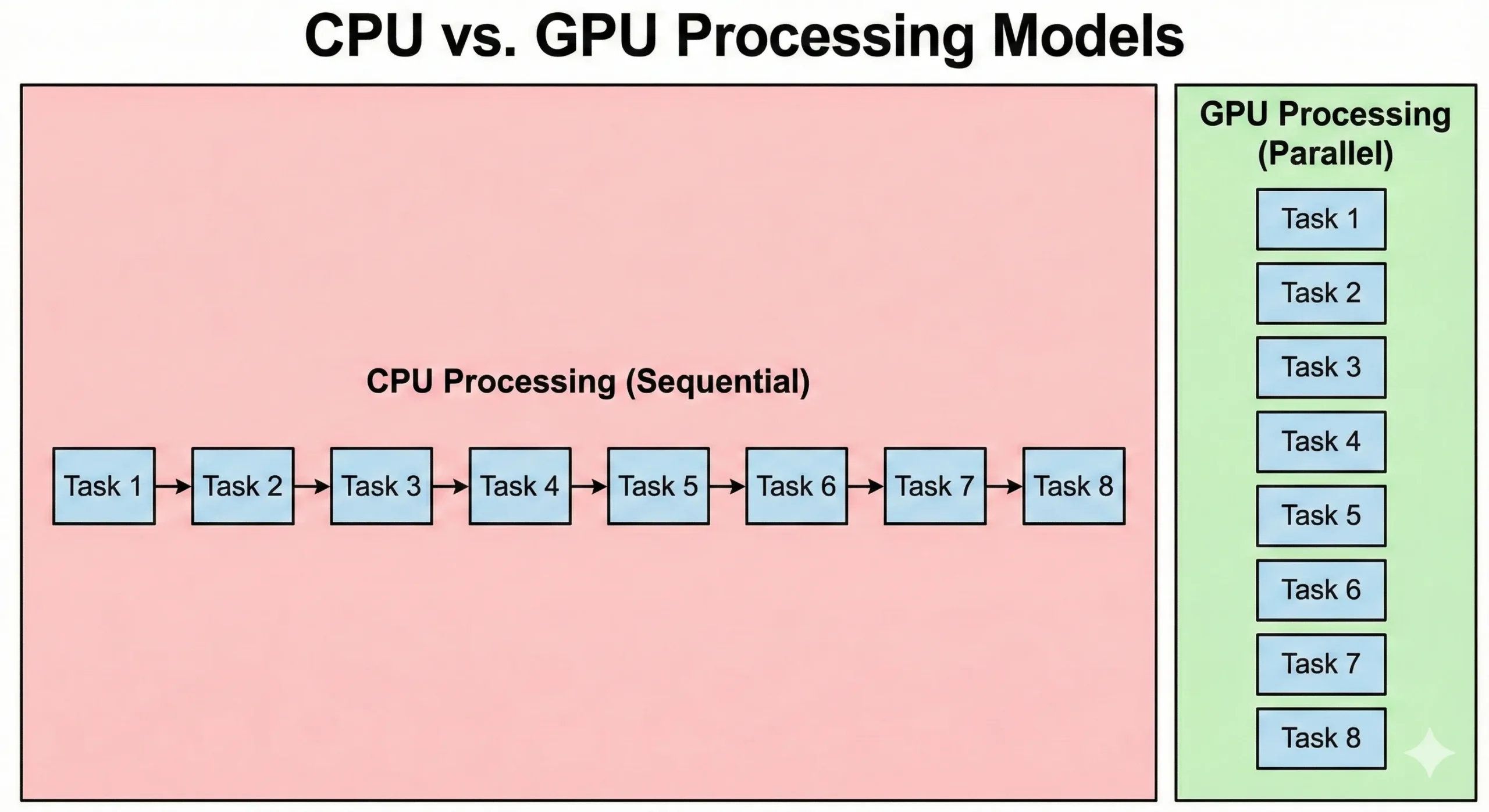
CPUs e GPUs resolvem problemas de formas fundamentalmente diferentes. Um CPU moderno de servidor pode ter 8-128+ núcleos executando em alta velocidade de relógio. Esses processadores são excelentes em operações sequenciais onde cada passo depende do resultado anterior. Eles lidam com lógica complexa e ramificação de forma eficiente.
GPUs invertem essa abordagem. Eles empacotam milhares de núcleos CUDA mais simples executando em velocidades de relógio mais baixas. Essas unidades compensam velocidades mais baixas através de paralelismo. Quando 16.000 trabalham juntos, a taxa de transferência total supera a capacidade do CPU padrão.
CPUs executam código do sistema operacional e lógica de aplicação complexa. Enquanto GPUs priorizam taxa de transferência, a sobrecarga da iniciação de tarefa e sincronização resulta em latência mais alta. O processamento gráfico paralelo prioriza mover dados. Embora demorem mais para começar, eles processam grandes conjuntos de dados mais rapidamente que CPUs.
| Recurso | Núcleos de CPU | Núcleos CUDA |
| Número por chip | 4 a 128+ núcleos | 2.560-21.760 núcleos |
| Velocidade do relógio | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Estilo de processamento | Instruções sequenciais e complexas | Instruções paralelas e simples |
| Melhor para | Sistemas operacionais, tarefas single-threaded | Álgebra linear, processamento de dados paralelos |
| Latência | Baixa (microssegundos) | Mais alto (overhead de inicialização) |
| Arquitetura | Multiuso | Especializado em cálculos repetitivos |
As tecnologias Virtual GPU (vGPU) e Multi-Instance GPU (MIG) lidam com particionamento de recursos e agendamento para distribuir processadores entre múltiplos usuários. Essa configuração permite que equipes maximizem a utilização de hardware através de compartilhamento em time-slicing ou instâncias de hardware dedicadas, conforme necessário.
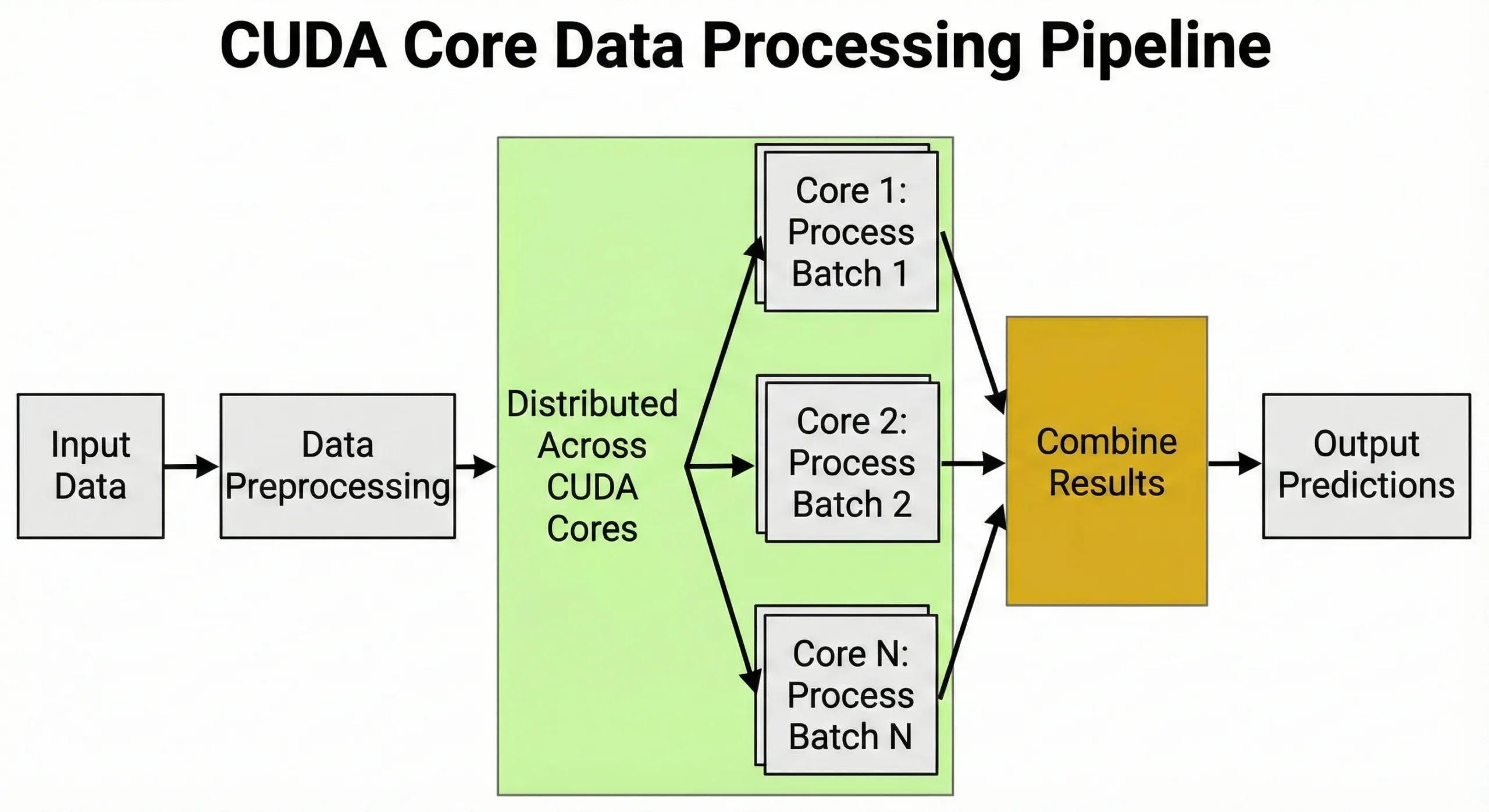
Treinar redes neurais envolve bilhões de multiplicações de matrizes. Um GPU com 10.000 unidades não simplesmente executa 10.000 operações simultaneamente; em vez disso, gerencia milhares de threads paralelas agrupadas em "warps" para maximizar o throughput. Esse paralelismo massivo é o motivo pelo qual essas unidades são essenciais para desenvolvedores de IA.
CUDA Cores vs Tensor Cores: Entendendo as Diferenças

NVIDIA GPUs contêm dois tipos de unidades especializadas trabalhando juntas: CUDA cores padrão e Tensor cores. Eles não são tecnologias concorrentes; cada um aborda partes diferentes de cargas de trabalho.
Unidades padrão são processadores paralelos de propósito geral que lidam com cálculos FP32 e FP64, operações inteiras e transformações de coordenadas. Essa tecnologia CUDA fundamental forma a base da computação GPU, executando tudo desde simulações de física até pré-processamento de dados sem aceleração especializada.
Tensor cores são unidades especializadas projetadas exclusivamente para multiplicação de matrizes e tarefas de IA. Introduzidas na arquitetura Volta da NVIDIA (2017), elas se destacam em computações de precisão FP16 e TF32. A geração mais recente oferece suporte a FP8 para inferência de IA ainda mais rápida.
| Recurso | Núcleos CUDA | Núcleos Tensor |
| Propósito | Computação paralela geral | Multiplicação de matrizes para IA |
| Precisão | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Velocidade para IA | 1x linha de base | 2-10x mais rápido que CUDA cores |
| Casos de uso | Pré-processamento de dados, ML tradicional | Treinamento e inferência de deep learning |
| Disponibilidade | Todos os GPUs NVIDIA | Série RTX 20 e mais recente, GPUs de datacenter |
GPUs modernos combinam ambas. O RTX 5090 tem 21.760 unidades padrão mais 680 Tensor cores de quinta geração. O H100 combina 16.896 unidades padrão com 528 Tensor cores de quarta geração para aceleração de deep learning.
Ao treinar redes neurais, Tensor cores executam o trabalho pesado durante os passes para frente e para trás através do modelo. Unidades padrão gerenciam carregamento de dados, pré-processamento, cálculos de loss e atualizações de otimizador. Ambos os tipos trabalham juntos, com Tensor cores acelerando operações computacionalmente intensivas.
Para algoritmos de aprendizado de máquina tradicional como florestas aleatórias ou gradient boosting, unidades padrão gerenciam o trabalho, pois esses não usam padrões de multiplicação de matrizes que Tensor cores aceleram. Mas para modelos transformer e redes neurais convolucionais, Tensor cores proporcionam acelerações dramáticas.
Para Que Servem os CUDA Cores?

Núcleos CUDA potencializam tarefas que exigem muitas operações idênticas executadas simultaneamente. Qualquer trabalho envolvendo operações matriciais ou cálculos numéricos repetidos se beneficia de sua arquitetura.
Aplicações de IA e Machine Learning
Deep learning depende de multiplicações matriciais durante treinamento e inferência. Ao treinar redes neurais, cada passada adiante requer milhões de operações de multiplicação-adição nas matrizes de pesos. Retropropagação adiciona milhões mais durante a passada reversa.
Unidades gerenciam pré-processamento de dados, convertendo imagens em tensores, normalizando valores e aplicando transformações de aumento. Essa capacidade de lidar com milhares de tarefas simultaneamente é exatamente por que GPUs são importantes para IA.
Durante o treinamento, elas supervisionam agendamentos de taxa de aprendizado, cálculos de gradientes e atualizações de estado do otimizador.
Para VPS em operações de inferência de IA executando sistemas de recomendação ou chatbots, elas processam requisições concorrentemente, executando centenas de predições simultaneamente. Nosso guia sobre melhor GPU para IA 2025 cobre quais configurações funcionam para tamanhos diferentes de modelo.
Os 16.896 núcleos do H100 combinados com Tensor cores treinam um modelo de 7 bilhões de parâmetros em semanas em vez de meses. Inferência em tempo real para chatbots servindo milhares de usuários requer poder de execução concorrente similar.
Computação Científica e Pesquisa
Pesquisadores usam estes processadores para simulações de dinâmica molecular, modelagem climática e análise genômica. Cada cálculo é independente, tornando-os perfeitos para execução concorrente. Instituições financeiras executam simulações de Monte Carlo com milhões de cenários simultaneamente.
Renderização 3D e Produção de Vídeo
Ray tracing calcula a luz ricocheteando através de cenas 3D traçando raios independentes por cada pixel. Enquanto núcleos RT dedicados gerenciam travessia, núcleos padrão gerenciam amostragem de texturas e iluminação. Esta divisão determina a velocidade de cenas com milhões de raios.
NVENC gerencia codificação para H.264 e H.265, enquanto as arquiteturas mais recentes (Ada Lovelace e Hopper) introduzem suporte em hardware para AV1. CUDA ajuda com efeitos, filtros, escalonamento, denoise, transformações de cor e cola de pipeline. Isso permite que o mecanismo de codificação trabalhe ao lado de processadores paralelos para produção de vídeo mais rápida.
Renderização 3D em Blender ou Maya distribui bilhões de cálculos de shader de superfície entre os núcleos disponíveis. Sistemas de partículas se beneficiam já que simulam milhares de partículas interagindo simultaneamente. Esses recursos são fundamentais para criação digital de alto nível.
Como Núcleos CUDA Impactam o Desempenho do GPU

Contagens de núcleos dão uma ideia aproximada da capacidade de execução concorrente, mas núcleos CUDA exigem olhar além dos números. Velocidade de clock, largura de banda de memória, eficiência de arquitetura e otimização de software desempenham papéis maiores.
Um GPU com 10.000 núcleos rodando a 2.0 GHz entrega resultados diferentes de um com 10.000 a 1.5 GHz. Maior velocidade de clock significa que cada núcleo completa mais cálculos por segundo. Arquiteturas mais novas empacotam mais trabalho em cada ciclo através de melhor agendamento de instruções.
Verifique se você está mantendo o dispositivo ocupado, mas lembre-se que nvidia-smi utilização é uma métrica grosseira. Ela mede a porcentagem de tempo que um kernel está ativo, não quantos núcleos estão fazendo trabalho.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderExemplo de saída: 85%, 92% (85% tempo ativo, 92% atividade do controlador de memória)
Se seu GPU mostra utilização de 60-70%, você provavelmente tem gargalos anteriores como carregamento de dados CPU ou tamanhos de lote pequenos. No entanto, mesmo 100% de utilização pode ser enganosa se seus kernels são limitados por memória ou single-threaded. Para uma visão verdadeira da saturação de núcleos, use profilers como Nsight Systems para rastrear métricas de "SM Efficiency" ou "SM Active".
Largura de banda de memória frequentemente se torna o gargalo antes de maximar a capacidade de cálculo. Se seu GPU processa dados mais rápido do que a memória supre, núcleos ficam ociosos. O modelo H100 SXM5 usa largura de banda de 3,35 TB/s para alimentar seus 16.896 núcleos. A versão PCIe, porém, reduz isso para 2 TB/s.
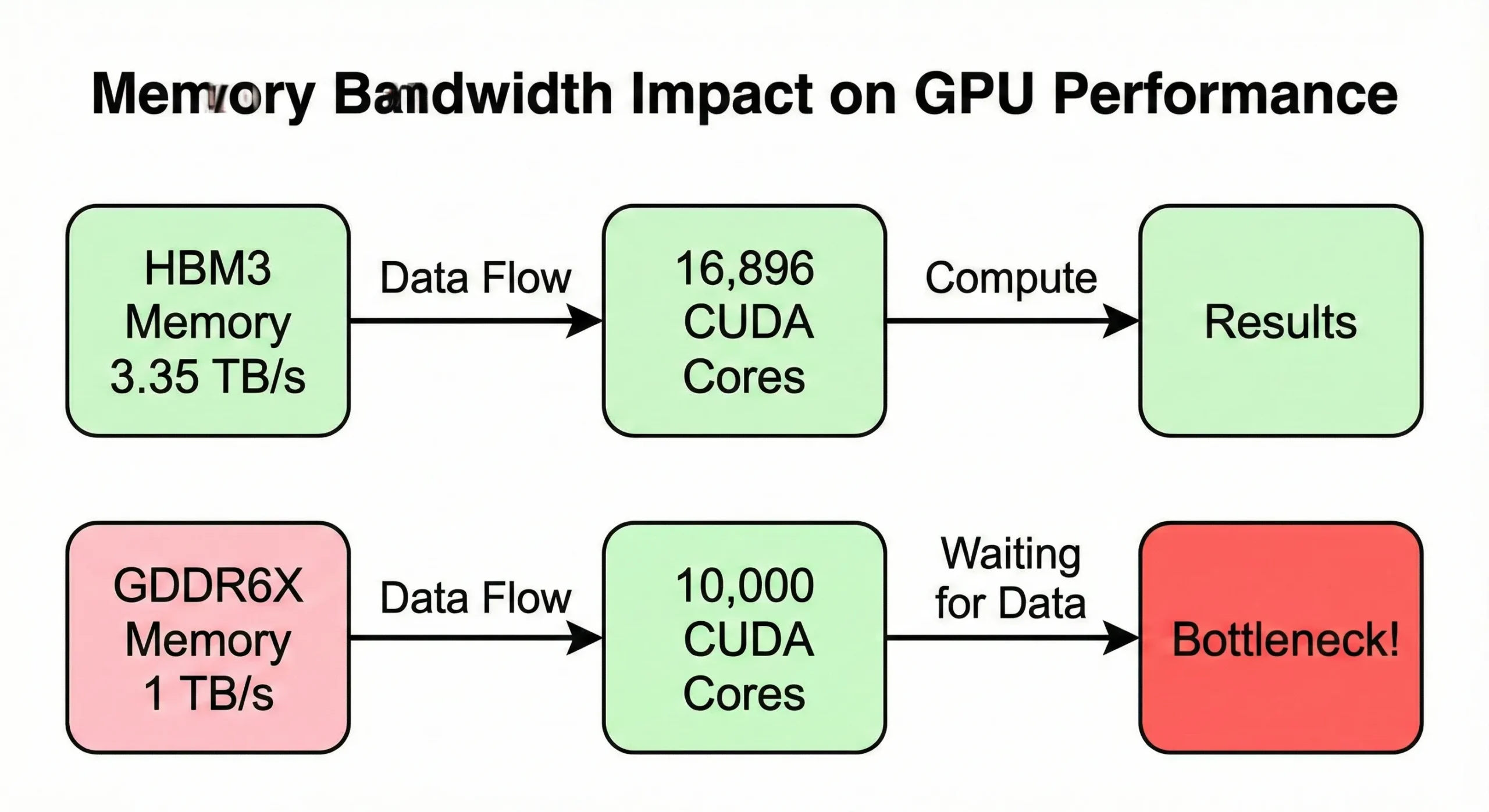
Consumer GPUs com contagens similares mas menor largura de banda (cerca de 1 TB/s) mostram velocidade reduzida no mundo real em operações intensivas de memória.
A capacidade VRAM determina o tamanho de suas tarefas. Seja para pesos FP16 de um modelo 70B, treinamento completo requer mais memória. Você deve considerar gradientes e estados do otimizador. Esses estados frequentemente triplicam o consumo de memória a menos que você use estratégias de offload
O A100 80GB visa inferência de alto desempenho e ajuste fino. Enquanto isso, o RTX 4090 24GB, frequentemente citado para modelos 7B, pode surpreendentemente executar modelos com 30B+ parâmetros se usar técnicas de quantização modernas como INT4. Porém, ficar sem VRAM força transferências de dados CPU-GPU que destroem o desempenho.
A otimização de software determina se seu código realmente usa todas aquelas unidades. Kernels mal escritos podem ativar apenas uma fração dos recursos disponíveis. Bibliotecas como cuDNN para deep learning e RAPIDS para data science são muito otimizadas para maximizar utilização.
Mais Núcleos CUDA Nem Sempre Significam Melhor Desempenho

Comprar um GPU com a maior contagem de núcleos parece lógico, mas você desperdiça dinheiro se unidades superam outros componentes do sistema ou sua tarefa não escala com contagem de núcleos.
A largura de banda de memória cria o primeiro limite. O RTX 5090 com 21.760 unidades é alimentado por 1.792 GB/s de largura de banda de memória. GPUs mais antigos com fewer unidades podem ter largura de banda proporcionalmente maior por unidade.
Diferenças de arquitetura importam. Um GPU mais recente com 14.000 unidades a 2,2 GHz supera um GPU mais antigo com 16.000 a 1,8 GHz graças a instruções melhores por ciclo. Seu código precisa de paralelização adequada para usar 20.000 unidades efetivamente.
Por que Núcleos CUDA Importam ao Escolher GPU VPS

Escolher a configuração certa de núcleos CUDA GPU para seu VPS evita desperdiçar dinheiro em recursos não utilizados ou atingir gargalos no meio do projeto.
A memória 80GB do H100 processa inferência para modelos com 70B parâmetros usando quantização 4-bit. Para treinamento completo, porém, até 80GB é frequentemente insuficiente para um modelo 34B uma vez que você considera gradientes e estados do otimizador. Em treinamento FP16, a pegada de memória expande significativamente, frequentemente requerendo sharding multi-GPU.
Operações de inferência servindo predições em tempo real precisam de fewer unidades mas se beneficiam de baixa latência. Trabalho de desenvolvimento e prototipagem funcionam bem com GPUs mid-range para testar algoritmos e debugar código.
Um RTX 4060 Ti com 4.352 unidades deixa você testar sem pagar por hardware excessivo. Uma vez validada sua abordagem, escale para GPUs de produção para rodadas de treinamento completo.
Renderização e trabalho com vídeo escalam com unidades até certo ponto. O renderizador Cycles do Blender usa todos os recursos disponíveis eficientemente. Um GPU com 8.000-10.000 unidades renderiza cenas 2-3x mais rápido que um com 4.000.
Na Cloudzy, oferecemos VPS com GPU hospedagem de alto desempenho construída para trabalho pesado. Escolha o RTX 5090 ou RTX 4090 para renderização rápida e inferência de IA econômica, ou escale para A100s para cargas massivas de deep learning. Todos os planos rodam em rede 40 Gbps com políticas de privacidade em primeiro lugar e opções de pagamento em criptomoedas, dando você poder bruto sem burocracia corporativa.
Seja treinando modelos de IA, renderizando cenas 3D, ou rodando simulações científicas, você escolhe a contagem de núcleos que se adequa suas necessidades.
Considerações orçamentárias importam. Um A100 com 6.912 unidades custa significativamente menos que um H100 com 16.896. Para muitas operações, dois A100s oferecem melhor relação preço-velocidade que um H100. O ponto de equilíbrio depende se seu código escala entre múltiplos GPUs.
Como Escolher o Número Certo de Núcleos CUDA
Adapte seus requisitos às características reais da carga de trabalho em vez de perseguir os números mais altos disponíveis no mercado.
Comece analisando seu trabalho atual. Se está treinando modelos em hardware local ou instâncias em nuvem, verifique as métricas de utilização do GPU. Se seu GPU atual mostrar 70-80% de utilização consistentemente, você não está maximizando os núcleos.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Este benchmark simples mostra se seus núcleos GPU estão entregando o throughput esperado. Compare seus resultados com benchmarks publicados para seu modelo GPU.
Fazer upgrade não ajuda. Você precisa resolver primeiro gargalos como memória, largura de banda ou travamentos CPU. Em seguida, estime os requisitos de memória calculando o tamanho do modelo em bytes mais a memória de ativação.
Some o tamanho do lote vezes as saídas da camada e inclua os estados do otimizador. Este total deve caber em VRAM. Depois de saber a memória necessária, verifique quais GPUs atendem esse limite.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Considere seu cronograma. Se precisa de resultados em horas, pague por mais núcleos. Treinamentos que podem levar dias funcionam bem em GPUs menores com tempos de conclusão proporcionalmente mais longos.
Custo por hora vezes horas necessárias dá o custo total, às vezes tornando GPUs mais lentos mais baratos no geral. Teste a eficiência de escalonamento usando vários frameworks que fornecem ferramentas de benchmark mostrando mudanças de throughput.
Se duplicar núcleos oferece apenas 1.5x de aceleração, os extras não valem seu custo. Procure por pontos ideais onde a proporção preço-velocidade é máxima.
| Tipo de Carga de Trabalho | Núcleos Recomendados | Exemplo de GPUs | Notas |
| Desenvolvimento e depuração de modelos | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Iteração rápida, custos menores |
| Treinamento de IA em pequena escala (<7B parâmetros) | 6,000-10,000 | RTX 4090, L40S | Adequado para consumidor e pequena empresa |
| Treinamento de IA em larga escala (7B-70B parâmetros) | 14,000+ | A100, H100 | Requer GPUs de data center |
| Inferência em tempo real (alto throughput) | 10,000-16,000 | RTX 5080, L40 | Equilibre custo e desempenho |
| Renderização 3D e codificação de vídeo | 8,000-12,000 | RTX 4080, RTX 4090 | Escala com a complexidade |
| Computação científica e HPC | 10,000+ | A100, H100 | Requer suporte FP64 |
Modelos VPS GPU Populares e Suas Contagens de Núcleos CUDA

Diferentes níveis de GPU servem diferentes segmentos de usuários. O que é GPUaaS? É GPU-as-a-Service, onde provedores como Cloudzy oferecem acesso sob demanda a estes poderosos NVIDIA GPUs sem exigir que você compre e mantenha hardware físico.
| Modelo GPU | Núcleos CUDA | VRAM | Largura de Banda de Memória | Arquitetura | Ideal para |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Estação de trabalho de ponta, renderização 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1.008 GB/s | Ada Lovelace | IA de ponta alta, renderização 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Treinamento de IA em larga escala |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | IA corporativa, datacenter econômico |
| A100 | 6,912 | 40/80 GB HBM2e | 1.555–2.039 GB/s | Ampere | IA intermediária, confiabilidade comprovada |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Jogos, IA intermediária |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Datacenter multi-workload |
Placas RTX consumer (4070, 4080, 4090, 5080, 5090) são voltadas para criadores e games, mas funcionam bem para desenvolvimento de IA. Oferecem velocidade de núcleo única forte a preços menores que placas de datacenter.
Provedores VPS frequentemente oferecem essas para usuários sensíveis ao custo. Placas de datacenter (A100, H100, L40) priorizam confiabilidade, memória ECC e escalabilidade multi-núcleo. Gerenciam operações 24/7 e suportam recursos avançados.
Multi-Instance GPU (MIG) permite particionar uma GPU em múltiplas instâncias isoladas. A A100 continua popular apesar de opções mais novas por causa de suas especificações equilibradas.
Seu equilíbrio de núcleos NVIDIA, memória e preço a torna a escolha segura para a maioria das operações de IA em produção. A H100 oferece 2,4x mais núcleos, mas custa significativamente mais.
Conclusão
Engines de processamento paralelo tornam possível IA moderna, renderização e computação científica. Como funcionam e interagem com memória, velocidades de clock e software ajuda você a escolher configurações de GPU VPS.
Mais núcleos ajudam quando seu trabalho é efetivamente paralelizável e componentes como bandwidth de memória acompanham. Mas perseguir cegamente a contagem de núcleos mais alta desperdiça dinheiro se seus gargalos estão em outro lugar.
Comece analisando suas operações reais, identificando onde o tempo é gasto e compatibilizando especificações de GPU a esses requisitos sem superbuying capacidade desnecessária.
Para a maioria do trabalho de desenvolvimento de IA, 6.000-10.000 núcleos fornecem o ponto ideal entre custo e capacidade. Operações de produção treinando modelos grandes ou servindo inference de alta vazão se beneficiam de GPUs com 14.000+ núcleos como a H100.
Renderização e trabalho de vídeo escalam eficientemente com núcleos até cerca de 16.000, depois o qual bandwidth de memória se torna o fator limitante.


