
Bạn mở trang GGUF của một mô hình phổ biến trên Hugging Face và có mười lăm file đang nhìn chằm chằm vào bạn: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, cộng thêm các thư mục riêng cho GPTQ, AWQ, và EXL2 với nửa tá mức bit khác nhau. Bạn nhẩm tính cho file "4-bit": 4 bit × 8 tỷ tham số ÷ 8 = 4 GB. Nhưng file lại ghi 4,6 GB. Và khi bạn nạp nó vào, mô hình còn dùng nhiều bộ nhớ hơn thế.
Tên file không phải là nhiễu. Chúng mã hóa thông tin thực sự, có thể học được về độ rộng bit, runtime nạp chúng, và phần cứng chúng cần. Các bảng ước lượng kích thước bạn từng đọc cho bạn biết một mô hình 70B cần khoảng 40 GB, hữu ích đấy, nhưng chúng chẳng bao giờ giải mã bản thân định dạng hay giải thích vì sao mô hình đang chạy lại cần nhiều bộ nhớ hơn file trên đĩa.
Vậy đây là kế hoạch: giải mã quy ước đặt tên GGUF (với độ rộng bit thực sự, không phải danh nghĩa), phân loại xem trong bốn định dạng, phần cứng của bạn thực sự chạy được cái nào, và tính đến một khoản chi phí bộ nhớ vô hình trong mọi kích thước file, đó là KV cache. Đến cuối bài, bạn sẽ có thể đọc một repo mô hình và dự đoán nó sẽ hoạt động ra sao khi nạp vào.
Tóm tắt nhanh
- Các mức lượng tử hóa GGUF là độ rộng bit hiệu dụng, không phải con số chính xác trong tên gọi. Q4_K_M vào khoảng 4,89 bit trên mỗi trọng số, đó là lý do vì sao một file 8B "4-bit" lại rơi vào khoảng 4,6 GiB thay vì con số ước lượng 4-bit ngây thơ.
- GGUF là lựa chọn khả chuyển nhất vì llama.cpp có thể chạy nó trên CPU, GPU, hoặc cấu hình lai. GPTQ, AWQ, và EXL2 gắn chặt hơn với GPU và runtime cụ thể, trong đó EXL2 đặc biệt gắn với quy trình NVIDIA/CUDA.
- KV cache tách biệt với trọng số của mô hình, và nó lớn dần theo độ dài ngữ cảnh. Đó là lý do vì sao một mô hình nạp gọn gàng vẫn có thể bị crash do hết bộ nhớ khi cuộc hội thoại trở nên dài.
- Trên khoảng 5-bit, tổn thất chất lượng thường nhỏ. Ở khoảng Q4, sự đánh đổi vẫn thực tế cho nhiều trường hợp sử dụng cục bộ. Dưới 4-bit, cái giá về chất lượng trở nên dễ nhận thấy hơn nhiều. Q4_K_M vẫn là lựa chọn mặc định phổ biến của cộng đồng, trong khi Q5_K_M và Q6_K an toàn hơn khi bạn có dư bộ nhớ.
Q4_K_M nghĩa là gì trong tên file GGUF?

Tên lượng tử hóa GGUF theo mẫu Q[số bit]_[K]_[S/M/L]. Con số là mục tiêu giá trị bit trên mỗi trọng số, K nghĩa là đây là một "K-quant" lưu trữ hệ số tỷ lệ cho từng khối nhỏ trọng số, và chữ S, M, hoặc L ở cuối là cấp độ kích thước/chất lượng (nhỏ, trung bình, lớn). Vì các K-quant lưu trữ một tỷ lệ và giá trị nhỏ nhất cho mỗi khối cùng với trọng số, hiệu dụng độ rộng bit cao hơn con số nổi bật. Q4_K_M rơi vào khoảng 4,89 bit trên mỗi trọng số, không phải 4.
Khoảng chênh lệch đó chính là toàn bộ câu trả lời cho câu hỏi "tại sao file 4-bit của tôi lại nặng 4,6 GB?". Ước lượng ngây thơ giả định rằng mỗi trọng số tốn đúng 4 bit. Trong thực tế, các K-quant tốn thêm bit trên mỗi khối cho phần metadata giúp việc lượng tử hóa bit thấp trở nên chính xác, tỷ lệ và giá trị nhỏ nhất trên mỗi khối cho phép runtime tái tạo lại từng trọng số. Nhân 4,89 bit với 8 tỷ trọng số, bạn sẽ ra khoảng 4,58 GiB, đúng bằng những gì file thực sự nặng.
Đây là các độ rộng bit hiệu dụng và kích thước file đã được đo, lấy từ llama.cpp quantize documentation , với Llama 3.1 8B làm mô hình tham chiếu, cùng với chi phí perplexity của mỗi mức được đo trong bài báo đánh giá lượng tử hóa llama.cpp (arXiv:2601.14277) trên Llama-3.1-8B-Instruct:
| Mức GGUF | BPW hiệu dụng | ~Kích thước file (8B) | Perplexity so với F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | mức cơ sở |
*Các con số perplexity là riêng cho Llama-3.1-8B-Instruct từ arXiv:2601.14277. Cột BPW/kích thước file và cột perplexity đến từ hai nguồn khác nhau được đo riêng biệt, nên hãy đọc bảng này như một tài liệu tham khảo song song mang tính thực tiễn chứ không phải một lần chạy benchmark duy nhất. Mức suy giảm khác nhau tùy tác vụ, suy luận toán học thường bị ảnh hưởng nhiều hơn suy luận thông thường ở độ rộng bit thấp, nhưng hình dạng tổng thể vẫn đúng: 5-bit trở lên thường an toàn hơn, Q4 là vùng nén thực tế, và 3-bit là nơi tổn thất chất lượng trở nên khó bỏ qua hơn nhiều.
Trên thực tế: Q4_K_M là lựa chọn mặc định mà hầu hết mọi người nên chọn, Q5_K_M và Q6_K là lựa chọn nghiêng về chất lượng khi bạn có dư bộ nhớ, và bất cứ thứ gì ở mức Q3_K_S trở xuống là phương án cuối cùng cho phần cứng thực sự không thể chứa thêm.
Bạn nên tải định dạng lượng tử hóa nào: GGUF, GPTQ, AWQ, hay EXL2?

GGUF là định dạng khả chuyển nhất trong bốn định dạng: nó chạy trên CPU, GPU, hoặc kết hợp cả hai qua llama.cpp, nên đây là lựa chọn an toàn nhất khi bạn không chắc phần cứng của mình hỗ trợ được gì. GPTQ, AWQ, và EXL2 gắn chặt hơn với GPU và runtime cụ thể. Trong thực tế, chúng phổ biến nhất trên các cấu hình NVIDIA/CUDA, nhưng hỗ trợ GPTQ và AWQ có thể khác nhau tùy theo loader và serving stack; ví dụ, vLLM phân chia hỗ trợ lượng tử hóa theo phần cứng và cách triển khai. Nếu bạn chạy cục bộ trên Mac, card AMD, hoặc máy chỉ có CPU, GGUF vẫn là câu trả lời an toàn nhất. Nếu bạn có GPU NVIDIA và muốn token nhanh nhất có thể, ba định dạng còn lại sẽ phát huy tác dụng.
| Định dạng | Phần cứng/runtime | Tốc độ (tương đối) | VRAM so với các định dạng khác | Tốt nhất cho |
|---|---|---|---|---|
| GGUF Q4_K_M | Rộng nhất, CPU, GPU, hoặc lai qua llama.cpp | Vừa phải | Router cấu hình sẵn | Mọi phần cứng; mặc định cục bộ |
| GPTQ 4-bit | Thường ưu tiên CUDA/GPU; tùy thuộc runtime | Nhanh (ExLlama) | Trung bình | Ưu tiên GPU, công cụ cũ |
| AWQ 4-bit | Thường ưu tiên CUDA/GPU; tùy thuộc runtime | Nhanh | Cao nhất | Phục vụ qua vLLM/TGI, nạp nhanh |
| EXL2 ~4,9 bpw | Ưu tiên NVIDIA/CUDA | Nhanh nhất | Thấp-Trung bình | Tốc độ tối đa trên NVIDIA |
Một lưu ý về bảng đó: thứ hạng tốc độ và VRAM đến từ benchmark oobabooga, chạy trên phần cứng thời 2023/2024. Hãy xem tương đối thứ tự này là bền vững. EXL2 được xây dựng cho tốc độ, AWQ đánh đổi VRAM lấy tốc độ nạp nhanh, GGUF vẫn gọn nhẹ và khả chuyển, nhưng đừng xem những con số token mỗi giây tuyệt đối ban đầu là hiện tại. Một GPU năm 2026 sẽ cho ra thông lượng thô rất khác; thứ bậc mới là điều còn giữ nguyên về sau.
Vậy quy tắc quyết định rút ra từ đây là: nếu bạn có card NVIDIA và quan tâm nhất đến tốc độ, chọn EXL2; nếu bạn muốn lựa chọn mặc định cục bộ an toàn nhất trên các loại phần cứng khác nhau, chọn GGUF. AWQ và GPTQ chủ yếu quan trọng khi một serving stack cụ thể (vLLM, TGI) hoặc công cụ sẵn có đẩy bạn theo hướng đó.
Vì sao một LLM cục bộ dùng nhiều bộ nhớ hơn kích thước file của nó?
Kích thước file chỉ là trọng số của mô hình. Khi chạy, bạn còn phải trả thêm cho KV cache (trạng thái attention cho mỗi token trong cửa sổ ngữ cảnh), activation (các phép tính trung gian của một lượt forward pass), và chi phí phụ của framework cùng driver. Gộp lại, các phần không phải trọng số này thường cộng thêm 10 đến 20% so với trọng số cho một cấu hình một người dùng, và riêng KV cache có thể lấn át mọi thứ khi ngữ cảnh trở nên dài. Một file 4,6 GB có thể cần nhiều hơn hẳn 4,6 GB bộ nhớ để chạy.
Hãy hình dung bộ nhớ runtime như bốn thành phần xếp chồng lên nhau:
- Trọng số mô hình. File bạn đã tải về. Đây là phần duy nhất nhìn thấy được trước khi bạn nạp mô hình.
- KV cache. Trạng thái attention cho cửa sổ ngữ cảnh. Nhỏ khi ngữ cảnh ngắn, khổng lồ khi ngữ cảnh dài. Đây là phần tiếp theo, vì đây là điều khiến mọi người bất ngờ.
- Activation. Bộ nhớ làm việc của một lượt forward pass. Với suy luận cục bộ đơn luồng (batch size 1), phần này nhỏ, thường chỉ vài trăm megabyte.
- Chi phí phụ của framework. Dấu chân riêng của runtime cộng với ngữ cảnh driver GPU. Với một runtime cục bộ nhẹ, phần này có thể nhỏ so với trọng số mô hình và KV cache; các framework phục vụ nặng hơn có thể dành riêng nhiều hơn hẳn. Việc hệ điều hành của bạn tự dành riêng bộ nhớ nằm ngoài phần này và lại là một khoản riêng biệt.
Trọng số và chi phí phụ của framework có thể dự đoán được. KV cache là biến số biến một mô hình "vừa vặn" thành một mô hình bị crash, nên đáng để đi qua phép toán thực tế.
KV cache dùng bao nhiêu bộ nhớ?
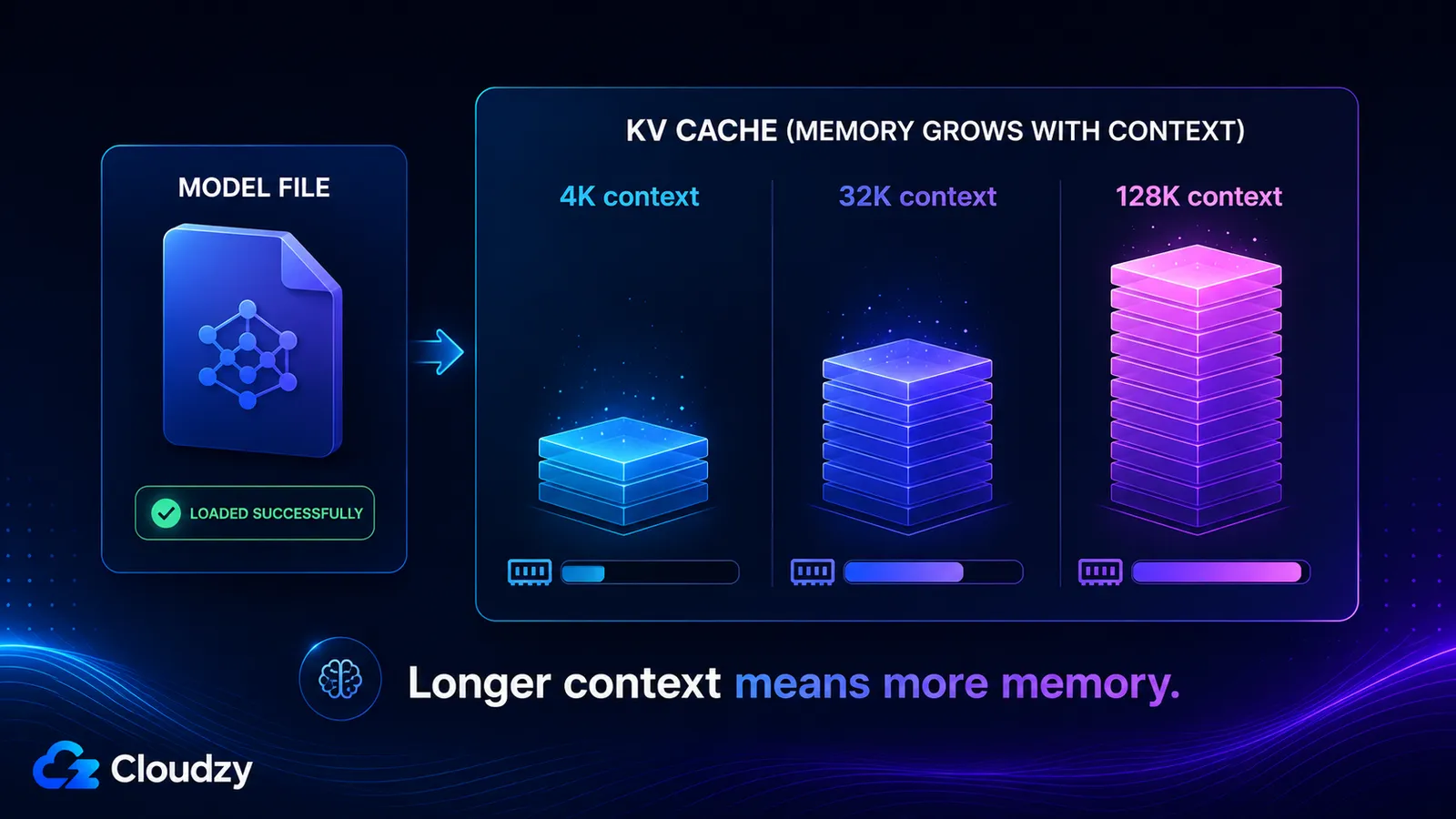
KV cache lưu trữ các vector key và value cho mỗi token trong cửa sổ ngữ cảnh của bạn, nên nó lớn dần gần như tuyến tính theo độ dài ngữ cảnh và hoàn toàn tách biệt với trọng số mô hình. Kích thước của nó được quyết định bởi số lớp của mô hình, số lượng KV head, kích thước head, độ dài ngữ cảnh, và độ chính xác của cache. Bật ngữ cảnh dài lên và bạn có thể cộng thêm hàng chục gigabyte mà một mô hình đã nạp thành công chưa từng cảnh báo bạn.
Công thức đủ ngắn để ghi nhớ trong đầu:
byte KV cache = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Số 2 dẫn đầu là cho hai tensor được lưu trên mỗi token, một cho key, một cho value. bytes_per_element là 2 đối với cache FP16. Phần còn lại là các hằng số kiến trúc bạn có thể đọc được từ model card.
Hãy tính cho Llama 3.1 8B, có 32 lớp, 8 KV head, và kích thước head là 128. Với ngữ cảnh 4.096 token, batch size 1, cache FP16:
2 × 32 × 8 × 128 × 4096 × 2 byte ≈ 536 MB
Tăng ngữ cảnh lên và con số sẽ tăng theo, vì mọi số hạng ngoại trừ context_tokens đều cố định:
- Ngữ cảnh 4K: ~536 MB
- Ngữ cảnh 32K: ~4,3 GB
- Ngữ cảnh 128K: ~17 GB
Hai con số cuối cùng đó là lý do vì sao một mô hình có thể tuyên bố cửa sổ ngữ cảnh 128K, nạp thành công vui vẻ, rồi cạn kiệt bộ nhớ ngay khoảnh khắc bạn thực sự dùng đến cửa sổ đó. KV cache ở ngữ cảnh đầy đủ còn lớn hơn cả bản thân trọng số đã lượng tử hóa.
Đây là phần khiến các mô hình ngữ cảnh dài hiện đại có thể tồn tại: Llama 3.1 8B sử dụng Grouped Query Attention (GQA)Nó có 32 query head nhưng chỉ 8 KV head, cache chỉ lưu vector key/value cho 8 head, không phải 32. Chạy cùng công thức đó với 32 KV head (thiết kế Multi-Head Attention cũ hơn, nơi số KV head bằng số query head) và mọi con số ở trên nhân lên gấp 4 lần. 17 GB ở mức 128K trở thành 68 GB. GQA chính là lý do kiến trúc khiến phép toán vẫn còn chịu đựng được khi các cửa sổ ngữ cảnh ngày càng lớn.
Kích thước file không phải là ngân sách bộ nhớ của bạn. Khi trọng số hoặc KV cache không còn vừa với đường bộ nhớ nhanh và runtime phải rơi trở lại vào RAM hệ thống qua PCIe, thông lượng không suy giảm từ từ. Nó rơi xuống thẳng đứng ngay khi bạn phải di chuyển dữ liệu qua PCIe cho mỗi token. Hãy lập ngân sách bộ nhớ sao cho cả trọng số lẫn KV cache ở độ dài ngữ cảnh thực tế của bạn đều vừa, chứ không chỉ trọng số.
Bạn chọn bản lượng tử hóa cho GPU hoặc Mac của mình như thế nào?
Hãy bắt đầu từ phần cứng và runtime của bạn. Người dùng GPU NVIDIA có thực đơn rộng nhất và nên cân nhắc EXL2 vì tốc độ thuần túy hoặc GGUF vì tính khả chuyển. Nếu bạn dùng AMD, Apple Silicon, phần cứng chỉ có CPU, hoặc cấu hình hỗn hợp, GGUF qua llama.cpp thường là điểm khởi đầu an toàn nhất. Từ đó, hãy chọn mức lượng tử hóa cao nhất vừa vặn sau khi bạn đã dự trù ngân sách cho KV cache ở độ dài ngữ cảnh mà bạn thực sự dùng, chứ không phải mức tối đa của mô hình.
Có một cái bẫy đáng biết ở Apple Silicon: GPU không nhận được toàn bộ bộ nhớ hợp nhất của bạn (xem bài viết đồng hành của chúng tôi về bộ nhớ hợp nhất thực sự là gì để có bức tranh đầy đủ về cách bể chia sẻ đó hoạt động). Cộng đồng self-hosting đã ghi nhận một giới hạn khoảng 75% trong tổng bộ nhớ hợp nhất khả dụng cho GPU (điều này không được Apple xác nhận chính thức và có thể thay đổi theo các bản cập nhật macOS). Vậy nên một "Mac 64 GB" thực tế chỉ có khoảng ~48 GB cho mô hình cộng với KV cache của nó, hãy lập kế hoạch dựa trên con số nhỏ hơn đó.
Bài viết này nói về việc đọc hiểu định dạng và dự đoán hành vi runtime của nó: giải mã tên lượng tử hóa, chọn định dạng phần cứng của bạn hỗ trợ, và dự trù ngân sách KV cache tách biệt với trọng số. Việc khớp một mô hình cụ thể với một lượng bộ nhớ cụ thể, bảng tra cứu kích thước sang bộ nhớ, là một câu hỏi liên quan nhưng riêng biệt mà chúng tôi sẽ đề cập trong một bài viết đồng hành trong tương lai.
Đọc hiểu Repo
Giờ đây bạn có thể nhìn vào trang của một mô hình và đọc hiểu nó thay vì đoán mò. Giải mã tên lượng tử hóa ra độ rộng bit hiệu dụng của nó, nhận ra rằng GGUF là định dạng cục bộ rộng nhất trong khi GPTQ, AWQ, và EXL2 gắn chặt hơn với runtime cụ thể, và nhớ rằng kích thước file chỉ là mức sàn, KV cache chồng lên trên và lớn dần theo ngữ cảnh của bạn. Mở các file cho mô hình bạn muốn, chọn định dạng phần cứng của bạn chạy được, chọn mức lượng tử hóa cao nhất vừa vặn sau khi bạn đã chừa chỗ cho KV cache ở độ dài ngữ cảnh thực tế của mình, và bạn sẽ tránh được sự cố crash do hết bộ nhớ vốn là khởi nguồn của toàn bộ câu hỏi này.
Câu hỏi thường gặp
Q4_K_M nghĩa là gì?
Q4_K_M là một mức lượng tử hóa GGUF: khoảng 4 bit trên mỗi trọng số (Q4), sử dụng cách tỷ lệ hóa K-quant theo từng khối (K), ở cấp độ kích thước/chất lượng trung bình (M). Độ rộng bit hiệu dụng hiệu dụng vào khoảng 4,89 bit trên mỗi trọng số, không phải chính xác 4, vì các K-quant lưu trữ một tỷ lệ và giá trị nhỏ nhất cho mỗi khối trọng số. Đó là lý do vì sao file mô hình 8B "4-bit" có kích thước khoảng 4,6 GB thay vì 3,5 GB.
Lượng tử hóa có làm giảm chất lượng LLM không?
Có, nhưng cái giá phải trả phụ thuộc nhiều vào việc bạn đẩy nó đi xa đến đâu. Trên Llama-3.1-8B-Instruct được đo trong arXiv:2601.14277, perplexity chỉ tăng khoảng 0,4% ở Q6_K và duy trì gần 1% suốt dải Q5. Giảm xuống Q4, mức tăng vẫn còn khiêm tốn (vài phần trăm); dưới Q3_K_M nó tăng vọt, đạt +22% ở Q3_K_S. Với hầu hết mục đích sử dụng, Q4_K_M trở lên gần như không mất mát; mức phạt nặng nề nằm ở 3-bit trở xuống.
Sự khác biệt giữa GGUF, GPTQ, AWQ, và EXL2 là gì?
GGUF (chạy bởi llama.cpp) là định dạng khả chuyển, nó hoạt động trên CPU, GPU, hoặc cấu hình lai trên phạm vi phần cứng rộng. GPTQ, AWQ, và EXL2 gắn chặt hơn với GPU và runtime cụ thể. Ở mức 4-bit, cả bốn định dạng đều có thể rơi vào một dải chất lượng hẹp, nên sự khác biệt thực tế nằm ở phần cứng, hỗ trợ loader, tốc độ, và mức dùng VRAM: EXL2 là lựa chọn tập trung vào tốc độ cho NVIDIA/CUDA, AWQ phổ biến trong các serving stack, GPTQ phù hợp với công cụ GPU cũ và các repo mô hình cũ, còn GGUF vẫn là lựa chọn cục bộ khả chuyển nhất.
Vì sao LLM cục bộ của tôi dùng nhiều bộ nhớ hơn kích thước file?
Kích thước file chỉ là trọng số của mô hình. Khi chạy, bạn còn phải trả thêm cho KV cache (trạng thái attention cho mỗi token trong cửa sổ ngữ cảnh), activation, và chi phí phụ của framework cùng driver. KV cache thường là thủ phạm khi khoảng chênh lệch lớn, vì nó lớn dần theo độ dài ngữ cảnh và được cấp phát tách biệt với trọng số, một mô hình có file chỉ vài gigabyte có thể cần nhiều bộ nhớ hơn hẳn một khi bạn đặt ngữ cảnh dài.
Độ dài ngữ cảnh ảnh hưởng đến mức sử dụng bộ nhớ như thế nào?
KV cache lớn dần gần như tuyến tính theo độ dài ngữ cảnh, nên gấp đôi ngữ cảnh của bạn thì gần như gấp đôi cache. Với Llama 3.1 8B, cache khoảng 536 MB ở 4K token, ~4,3 GB ở 32K, và ~17 GB ở 128K (FP16, đơn luồng). Sự tăng trưởng đó hoàn toàn tách biệt với trọng số mô hình, đó là lý do vì sao việc khai báo một cửa sổ ngữ cảnh dài có thể đẩy một mô hình vào tình trạng hết bộ nhớ dù nó đã nạp thành công tốt đẹp.


