
Vòng lặp chạy trơn tru bốn mươi lần trong quá trình kiểm thử. Đến lần thứ bốn mươi mốt, trong môi trường sản xuất, nó gọi đi gọi lại cùng một công cụ SQL với cùng một câu truy vấn bị lỗi cho đến khi tiêu hết ngân sách API trong ngày và một cảnh báo thanh toán mới đánh thức được ai đó. Không ai viết model kém. Không ai thay đổi prompt. Agent đơn giản là không bao giờ quyết định xong việc.
Đây là khuôn mẫu tôi liên tục thấy với các nhóm chuyển agent từ prototype sang workload chạy 24/7. Vòng lặp AI agent thường thất bại trong sản xuất không phải vì model đột nhiên kém hơn, mà vì lớp thực thi thiếu kỷ luật kết thúc, hợp đồng công cụ được xác thực, context có giới hạn và trạng thái bền vững. Vòng lặp agent là một hệ thống ngẫu nhiên đưa ra từng quyết định tuần tự. Nếu không có một vài guardrail cụ thể, lỗi hiếm gặp sẽ trở thành lỗi chắc chắn một khi bạn chạy đủ lâu. Các nền tảng agent được quản lý (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) tích hợp sẵn một số guardrail này; hướng dẫn này dành cho những ai chọn tự host và tự quản lý vòng lặp.
Rủi ro đủ thực để Gartner dự báo hơn 40% dự án AI theo hướng agentic sẽ bị hủy trước cuối năm 2027, với lý do chi phí leo thang và giá trị không rõ ràng. Sau đây là sáu cách cụ thể khiến vòng lặp thất bại trong sản xuất, cơ chế đằng sau mỗi trường hợp, và mẫu harness giải quyết vấn đề đó, kèm chi tiết LangGraph và n8n cùng những gì cần thiết để thực sự chạy hệ thống này 24/7.
Phiên bản ngắn gọn
- Vòng lặp vô hạn: Agent không bao giờ quyết định xong. Kết hợp giới hạn bước cứng (LangGraph's
recursion_limit, mặc định 25) với tính năng phát hiện không có tiến triển, hủy các lần gọi tool+argument lặp lại. - Tràn context: Vòng lặp lấp đầy cửa sổ context của chính nó bằng lịch sử tích lũy cho đến khi các lần gọi bị cắt ngắn hoặc thất bại. Hãy tóm tắt lịch sử theo các khoảng cố định để context đang dùng luôn có giới hạn.
- Lỗi công cụ thầm lặng: Công cụ trả về chuỗi rỗng, model đọc đó là no-op hợp lệ, và agent "thành công" mà không làm gì cả. Xác thực mọi kết quả trả về từ công cụ trước khi model xem nó.
- Suy giảm suy luận: Chất lượng suy giảm khi context tăng, ngay cả dưới giới hạn cứng. Hãy nén ở giữa vòng lặp, nhưng bảo vệ các hướng dẫn an toàn đã được ghim khi làm vậy.
- Mất trạng thái khi khởi động lại: Sự cố đồng nghĩa với bắt đầu lại từ đầu. Checkpoint vào Postgres (LangGraph
PostgresSaver), không phải SQLite, cho môi trường sản xuất. - Cơn bão retry: Mười agent, mỗi agent retry mười lần, dội lên một dịch vụ đã chết với hàng trăm yêu cầu. Thêm exponential backoff với jitter và một circuit breaker toàn cục.
Những Gì Hướng Dẫn Này Không Đề Cập
Đây là hướng dẫn về harness, tập trung vào kỹ thuật xung quanh vòng lặp, không phải model bên trong. Một số chủ đề liên quan được cố tình đặt ngoài phạm vi:
- Lỗi phối hợp đa agent (đọc dữ liệu cũ, trạng thái mồ côi giữa các agent): vấn đề khác xứng đáng có bài viết riêng.
- Bảo mật agent (prompt injection, tool poisoning): danh mục lỗi riêng biệt với mô hình mối đe dọa của riêng nó.
- Lựa chọn model và tinh chỉnh. Hướng dẫn này giả định bạn đã chọn một model và đang gỡ lỗi hệ thống xung quanh nó.
- Dịch vụ agent được quản lý, đã đề cập ở trên; các mẫu ở đây dành cho con đường tự host.
Vòng Lặp Vô Hạn: Khi Agent Không Bao Giờ Quyết Định Xong

Agent lặp mãi mãi khi nó không có giới hạn bước cứng cũng không có cách phát hiện đã ngừng tiến triển. Cách khắc phục gồm hai phần: giữ giới hạn cứng như backstop chi phí, và thêm tính năng phát hiện không có tiến triển - mã hóa hash mỗi lần gọi tool-cộng-argument và kết thúc khi thấy cùng một lần gọi lặp lại. Trong LangGraph, giới hạn đó là recursion_limit, mặc định 25 bước; vượt qua nó và đồ thị sẽ ném ra GraphRecursionError.
Tài liệu của LangGraph mô tả giới hạn đó là đạt "số bước tối đa trước khi gặp điều kiện dừng," và đây là bẫy đáng hiểu: recursion_limit không phải là biện pháp bảo vệ vòng lặp. Nó là backstop kích hoạt sau (after) khi vòng lặp đã lãng phí hai mươi lăm bước và chi phí API đi kèm. Logic kết thúc học được của chính agent được giả định sẽ dừng nó trước đó rất lâu, và logic đó có thể thất bại độc lập. Một trường hợp LangGraph được báo cáo cho thấy một agent text-to-SQL lặp cho đến khi chạm recursion_limit dù có điều kiện dừng rõ ràng trong prompt. Nó cứ gọi cùng công cụ truy vấn với cùng SQL bị lỗi, và issue đó bị đóng với nhãn "not planned." Tôi hiểu điều đó là tín hiệu rõ ràng: đừng coi giới hạn là điều kiện dừng của bạn. Nó là dây an toàn, không phải phanh xe.
Tăng giới hạn trần rất đơn giản; bạn truyền nó qua config khi gọi đồ thị:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Phần thực sự dừng vòng lặp bị kẹt là phát hiện tiến triển. Cơ chế rất đơn giản: hash tên công cụ cộng với các argument của nó ở mỗi bước, giữ một cửa sổ ngắn của các hash gần đây, và thoát khi thấy lặp lại.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Điều này bắt được agent đang "chạy" về mặt kỹ thuật (gọi công cụ, tạo token) nhưng xoay vòng trên cùng một hành động thất bại. Chế độ lỗi được đặt tên ở đây ánh xạ tới cái mà phân loại MAST (IBM Research và UC Berkeley) gọi là Không Nhận Thức Được Điều Kiện Kết Thúc (FM-1.5), một trong những chế độ lỗi mà phân tích của họ liên kết với thất bại nhiệm vụ hoàn toàn.
Giới hạn bước dừng chi phí mất kiểm soát. Phát hiện không có tiến triển dừng vòng lặp đang "tiến triển" về mặt kỹ thuật nhưng tự lặp lại. Môi trường sản xuất cần cả hai.
Tràn Cửa Sổ Context: Khi Vòng Lặp Lấp Đầy Context Của Chính Nó Bằng Rác
Một vòng lặp chạy lâu tích lũy mọi đầu ra của công cụ, mọi suy nghĩ trung gian, và mọi tin nhắn đã tạo ra, sau đó nhét tất cả lại vào cửa sổ context ở mỗi lượt. Cuối cùng cửa sổ đầy, và các lần gọi bị cắt ngắn thầm lặng hoặc thất bại hoàn toàn. Cách khắc phục là tóm tắt context theo khoảng cố định: mỗi N bước, nén lịch sử tích lũy thành một bản tóm tắt đang chạy để context đang làm việc luôn có giới hạn.
Hãy hình dung một research agent đã chạy được một tiếng. Đến bước 60, nó đang mang toàn bộ văn bản của mọi trang đã tải, mọi kết quả tìm kiếm, mọi dấu vết suy luận. Không có lịch sử thô nào trong số đó giúp ích ở bước 61, nhưng tất cả đều tính vào cửa sổ, và model đang trả chi phí attention cho các token mà nó không còn cần nữa. Khi cửa sổ đầy, nhà cung cấp cắt ngắn từ một đầu, và agent mất lặng lẽ hướng dẫn được đưa cho nó từ đầu.
Ngưỡng kích hoạt là một quyết định tinh chỉnh, và có một điểm tham chiếu hữu ích. Bài viết của Mem0 về một hệ thống sản xuất thực tế lưu ý rằng bộ nén của Hermes agent "kích hoạt ở mức 50% cửa sổ context của model theo mặc định", với lưới an toàn thứ cấp ở 85% cho các phiên phình ra giữa các lượt. Năm mươi phần trăm là điểm khởi đầu hợp lý: nén đủ sớm để một đầu ra công cụ lớn không thể vượt quá giới hạn trước lần nén theo lịch tiếp theo.
Lưu ý: Overflow và sự suy giảm khả năng suy luận là hai vấn đề khác nhau, và phần tiếp theo sẽ đề cập đến vấn đề thứ hai. Overflow là giới hạn cứng: bạn hết tokens. Suy giảm là tiệm tiến: mô hình hoạt động kém dần. trước khi bạn chạm bức tường. Bạn cần xử lý cả hai, và ngưỡng kích hoạt trên đây bảo vệ chống lại bức tường cứng.
Context có giới hạn là trách nhiệm của harness, không phải tính năng của model. Hãy tóm tắt theo khoảng thời gian trước khi cửa sổ buộc phải cắt ngắn thầm lặng.
Lỗi Gọi Công Cụ Thầm Lặng: Khi Agent "Thành Công" Mà Không Làm Gì
Một lần gọi công cụ trả về chuỗi rỗng hoặc thông báo "không tìm thấy kết quả", model diễn giải đó là kết quả hợp lệ, và agent tiếp tục như thể bước đó đã thành công, có vẻ thành công trong khi không làm gì cả. Cách khắc phục là một cổng xác thực ở mọi kết quả trả về từ công cụ: kiểm tra schema hoặc kiểm tra tỉnh trước khi model thấy nó, và thông báo lỗi thực sự mà vòng lặp phải xử lý thay vì một thành công rỗng.
Cái này hiểm vì không có gì sụp đổ. Một developer viết về các chế độ lỗi thầm lặng trong production agent đã nói thẳng: các model diễn giải chuỗi rỗng chung chung là no-op hợp lệ và tiếp tục thực thi mà không nhận thức được lỗi. Truy vấn cơ sở dữ liệu trả về không hàng nào vì kết nối bị ngắt trông giống hệt, với model, với truy vấn hợp pháp thực sự không tìm thấy gì. Vì vậy agent báo cáo "không có bản ghi phù hợp" và tiếp tục, và bạn phát hiện ra một tuần sau rằng một phần ba số lần chạy của nó đã bị lỗi thầm lặng.
Cổng xác thực nằm giữa công cụ và model:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelVấn đề không phải là các kiểm tra chính xác; của bạn sẽ phụ thuộc vào những gì mỗi công cụ trả về hợp lệ. Vấn đề là một giá trị trả về không được xác thực là quyết định bạn đã giao cho một model ngẫu nhiên, và hành động mặc định của model là tiếp tục.
Kết quả trả về từ công cụ không được xác thực là lỗi thầm lặng chờ xảy ra. Xác thực đầu ra, đừng tin vào lần gọi.
Suy Giảm Suy Luận Qua Context Dài: Khi Agent Càng Chạy Lâu Càng Tệ
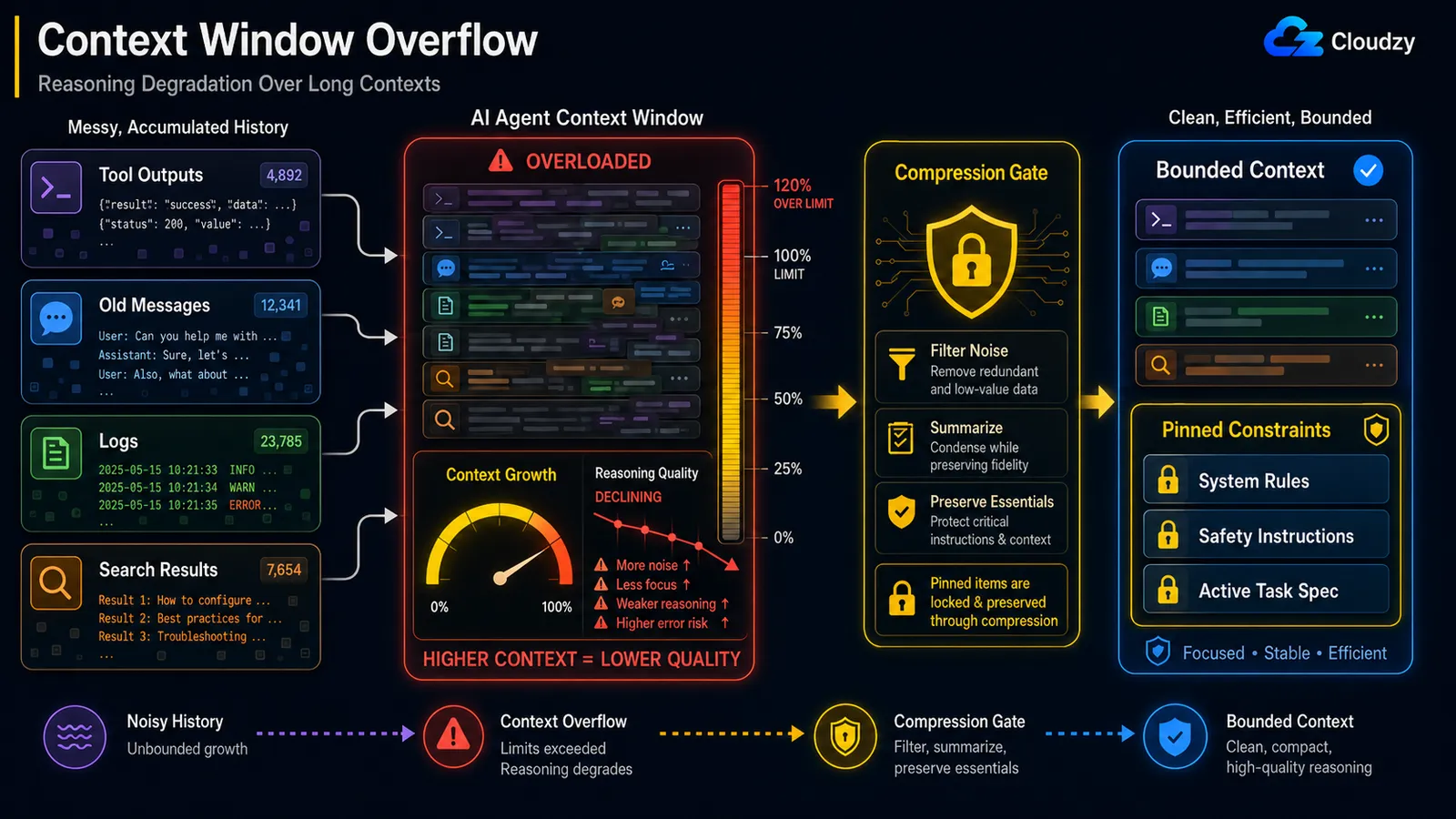
Ngay cả khi bạn ở dưới giới hạn context cứng, chất lượng suy luận suy giảm khi context tăng. Đây là hiệu ứng "lost in the middle", khi model đáng tin cậy chú ý đến phần đầu và cuối của một context dài nhưng mất phần giữa. Cách khắc phục là nén giữa vòng lặp bảo toàn các ràng buộc đã ghim: nén nhiễu, bảo vệ các hướng dẫn quan trọng.
Cơ chế có một tên gọi. Blog kỹ thuật của Anthropic gọi nó là context rot: "khi số token trong cửa sổ context tăng lên, khả năng của model để nhớ lại chính xác thông tin từ context đó giảm đi." Vì "mỗi token chú ý đến mọi token khác," bạn có n² mối quan hệ theo cặp cho n token, và attention của model trải mỏng hơn khi context chạy dài hơn.
Điều kiện đó, bảo vệ các hướng dẫn quan trọng, là cả trò chơi, và có một sự cố được ghi lại cho thấy lý do tại sao. Trong một trường hợp được báo cáo, một agent OpenClaw đã xóa hàng loạt hộp thư đến của người dùng trong quá trình nén context, vì hướng dẫn an toàn được đưa cho nó ("đừng hành động cho đến khi tôi nói") đã bị loại khỏi context đang hoạt động khi lịch sử được nén. Ràng buộc đáng lẽ phải là thứ cuối cùng bị loại bỏ đã bị xử lý như lịch sử thông thường và được tóm tắt đi.
Vì vậy, một chiến lược "tóm tắt tất cả mọi thứ cũ hơn N lượt" đơn giản là nguy hiểm. Nén phải biết những gì nó không bao giờ được bỏ:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactĐiều này khác với vấn đề tràn ở phần trước. Tràn là về việc hết chỗ; suy giảm là về model trở nên tệ hơn trong khi vẫn còn chỗ. Bạn có thể ở 60% cửa sổ và đã suy luận kém.
Lưu ý: Nén xóa ràng buộc an toàn là lỗi thuộc lớp khác với nén mất kết quả tìm kiếm cũ. Gắn thẻ các ràng buộc, đặc tả nhiệm vụ, và mọi hướng dẫn "không làm X" là đã ghim, và loại chúng hoàn toàn khỏi bộ tóm tắt.
Nén xóa hướng dẫn an toàn còn tệ hơn không nén. Bảo vệ các ràng buộc đã ghim khi bạn nén.
Mất Trạng Thái Khi Khởi Động Lại: Khi Sự Cố Đồng Nghĩa Với Bắt Đầu Lại
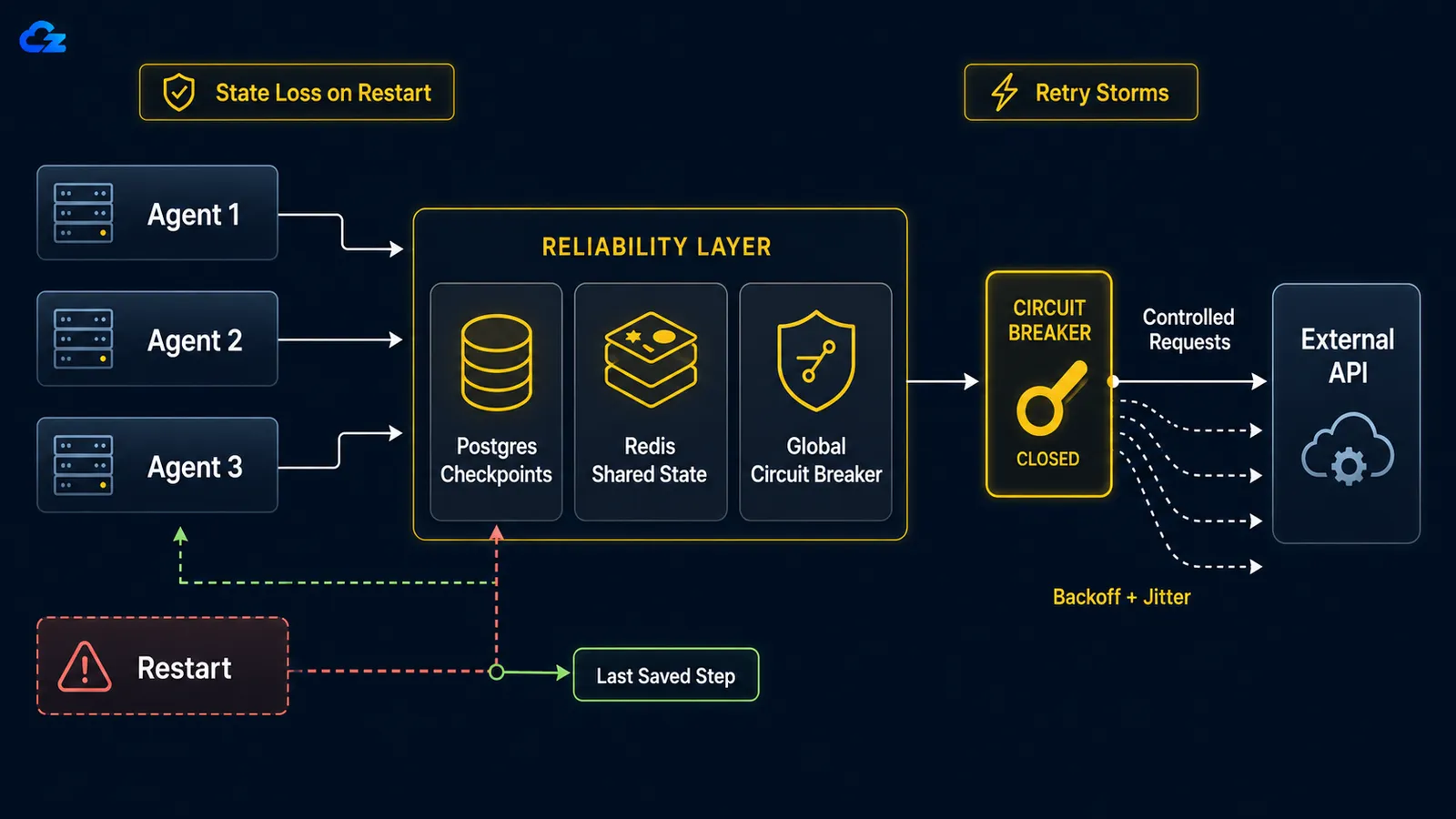
Khi một agent chạy lâu bị sự cố, dù từ khởi động lại, OOM kill, hay kết nối mạng bị ngắt, mặc định không có resume-from-checkpoint. Vòng lặp bắt đầu lại từ đầu: nó làm lại công việc đã hoàn thành và tệ hơn, có thể thực thi lại các hành động đã thực hiện, như gửi cùng một email hai lần hay chạy lại một lần gọi API trả phí. Cách khắc phục là checkpointing: lưu trạng thái vòng lặp sau mỗi bước để khi khởi động lại, nó tái tạo từ nơi dừng lại thay vì từ không.
Trong LangGraph, việc chọn checkpoint backend là sự lựa chọn giữa dev và production. Tài liệu persistence của LangGraph mô tả SqliteSaver là "lý tưởng để thử nghiệm và workflow cục bộ" và PostgresSaver là "lý tưởng để sử dụng trong sản xuất," và cái sau là thứ LangSmith tự chạy. Hai cái được cố ý song song trong code, điều này làm cho sự tương phản dễ thấy:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverHai chi tiết hay gây vấn đề. Đầu tiên, các gói checkpoint cài đặt riêng biệt với LangGraph core (langgraph-checkpoint-sqlite và langgraph-checkpoint-postgres là các dependency riêng), vì vậy một máy mới sẽ không có Postgres saver cho đến khi bạn thêm nó. Thứ hai, mọi thao tác checkpoint cần một thread_id trong config. ID đó là thứ liên kết một lần chạy nhất định với trạng thái đã lưu, và khởi động lại không có thread_id đúng sẽ không tái tạo gì cả.
Mẹo hay: Các gói checkpoint LangGraph được cài đặt riêng.
langgraph-checkpoint-postgreskhông được kéo vào bởi góilanggraphcơ sở, vì vậy hãy ghim nó vào file requirements sản xuất của bạn trước khi phát hiện ra theo cách khó trong một sự cố.
n8n có cùng sự phân chia dev-versus-production, chỉ với tên khác. Tùy chọn bộ nhớ tích hợp của nó cũng được gọi là Simple Memory (hoặc Buffer Window Memory), và con đường sản xuất là node Postgres Chat Memory cho trạng thái cần tồn tại qua khởi động lại. Bộ nhớ tích hợp giữ cuộc hội thoại trong tiến trình đang chạy, điều này ổn để kiểm thử và là rủi ro cho workload 24/7. Những người thực hành chạy n8n agent trong thực tế báo cáo phải di chuyển sang kho lưu trữ Postgres-backed sau khi bộ nhớ trong tiến trình tăng đến mức kéo instance xuống. Nếu bạn đang dùng n8n và agent cần nhớ bất cứ điều gì qua khởi động lại, hãy kết nối nó với Postgres Chat Memory ngay từ đầu.
SQLite checkpointing là sự tiện lợi dành cho phát triển. Để tồn tại qua khởi động lại sản xuất, cần Postgres (LangGraph) hoặc kho lưu trữ Postgres-backed (n8n).
Cơn Bão Retry: Khi Chính Agent Của Bạn DDoS Một Dịch Vụ Đã Chết
Khi một dịch vụ downstream ngừng hoạt động, các retry ngây thơ per-execution biến fleet agent của bạn thành một cuộc tấn công từ chối dịch vụ tự gây ra. Cách khắc phục có hai nửa: exponential backoff với jitter trên mỗi agent để trải các retry theo thời gian, và một circuit breaker toàn cục kích hoạt sau khi đạt ngưỡng thất bại chung và ngăn cả đàn tấn công một dịch vụ rõ ràng đã chết.
Toán học không khoan nhượng. Như một bài viết về retry pattern trình bày, với mười agent song song, mỗi agent retry mười lần, bạn gửi một trăm yêu cầu đến một dịch vụ đã sập, vì backoff của mỗi agent là per-execution, không phải toàn cục. Backoff per-agent một mình không giải quyết được điều này. Mười agent mỗi agent backoff lịch sự vẫn backoff đồng loạt nếu tất cả bắt đầu cùng lúc, vì vậy chúng retry theo làn sóng đồng bộ. Jitter phá vỡ đồng bộ bằng cách ngẫu nhiên hóa thời gian chờ của mỗi agent; circuit breaker phá vỡ đàn bằng cách chia sẻ một trạng thái thất bại giữa tất cả chúng.
Nửa backoff là vấn đề đã được giải quyết trong Python; thư viện tenacity xử lý exponential-with-jitter gọn gàng:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Circuit breaker là nửa phải toàn cục: chia sẻ giữa mọi agent, không được khởi tạo lại per-execution. Khi thất bại vượt ngưỡng, nó mở, mọi agent thất bại nhanh thay vì gọi ra ngoài, và sau thời gian cooldown nó cho một probe duy nhất đi qua để kiểm tra xem dịch vụ có trở lại không. Breaker nằm trong tiến trình của chính mỗi agent không bảo vệ được gì, vì không có gì được chia sẻ; dịch vụ đã chết vẫn nhận đủ một trăm yêu cầu.
Backoff per-execution vẫn để mười agent tấn công một dịch vụ đã chết đồng loạt. Circuit breaker phải toàn cục để ngăn đàn.
Sáu Lỗi Trong Một Lần Nhìn
Trước phần cơ sở hạ tầng, đây là toàn bộ danh mục trong một chỗ: lỗi, cơ chế gây ra nó, cách khắc phục harness, và nơi tham số liên quan nằm trong mỗi framework.
| Chế độ lỗi | Cơ chế | Cách khắc phục harness | Tham số framework |
|---|---|---|---|
| Vòng lặp vô hạn | Không có giới hạn bước hoặc kiểm tra tiến triển | Giới hạn cứng + phát hiện không có tiến triển | LangGraph recursion_limit (25) / n8n Max Iterations |
| Tràn context | Lịch sử tăng cho đến khi cửa sổ đầy | Tóm tắt theo khoảng thời gian | Cấp độ ứng dụng (nén ở ~50% cửa sổ) |
| Lỗi công cụ thầm lặng | Kết quả rỗng/mềm được đọc là no-op hợp lệ | Cổng xác thực ở mọi kết quả công cụ | Tool wrapper cấp độ ứng dụng |
| Suy giảm suy luận | Attention suy giảm khi context tăng ("context rot") | Nén giữa vòng lặp bảo toàn các ràng buộc đã ghim | Cấp độ ứng dụng, nhận thức về ràng buộc |
| Mất trạng thái khi khởi động lại | Không có checkpoint; vòng lặp bắt đầu lại từ không | Checkpointing bền vững | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Cơn bão retry | Retry per-execution xếp chồng trên một dịch vụ đã chết | Backoff + jitter + circuit breaker toàn cục | tenacity + trạng thái breaker chia sẻ |
Lưu ý cho bạn đọc đang dùng CrewAI, AutoGen, Dify, hoặc vòng lặp Python tự xây: các tham số framework thay đổi, nhưng sáu mẫu không thay đổi. Loại trùng lặp, tóm tắt theo khoảng, xác thực schema, nén nhận thức về ràng buộc, checkpointing, và circuit breaker toàn cục là các khái niệm độc lập với framework. Các chi tiết LangGraph và n8n ở đây là các điểm bám cụ thể, không phải ranh giới nơi các mẫu áp dụng.
Định Cỡ Deployment Agent Sản Xuất
Mọi mẫu ở trên giả định bạn kiểm soát process manager, cơ sở dữ liệu, và hành vi khởi động lại. Checkpointing không có giá trị gì nếu một vòng lặp bị sự cố không bao giờ khởi động lại, và một circuit breaker toàn cục cần chỗ để giữ trạng thái chia sẻ của nó. Sự kiểm soát đó chính xác là những gì tự host mang lại và hộp đen được quản lý thì không, vì vậy quyết định cuối cùng là định cỡ máy chạy nó 24/7.
Với hầu hết các deployment đơn agent (một agent, các lần gọi LLM đi ra một API bên ngoài, Postgres checkpointing cơ bản) một instance nhỏ là đủ: khoảng 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Tính toán nặng nằm ở phía nhà cung cấp model; máy của bạn đang điều phối, checkpointing, và giữ trạng thái, không chạy inference. Nâng lên khoảng 4 GB RAM, 2 vCPU, and 120 GB NVMe khi agent có trạng thái và đa bước với Postgres checkpointing cộng Redis cho session hydration, hoặc khi bạn đang chạy các workflow đồng thời chia sẻ host.
Lý do điều này muốn một VPS tự quản lý thay vì một nền tảng bị hạn chế là lý do giống như tại sao các cách khắc phục hoạt động: chúng cần quyền root. Postgres của riêng bạn để checkpointing, Redis của riêng bạn cho trạng thái phiên, và một process manager thực sự như systemd or pm2, để khi một vòng lặp chết, supervisor khởi động lại nó và nó tái tạo từ checkpoint cuối thay vì bắt đầu lại công việc. Toàn bộ câu chuyện phục hồi đó phụ thuộc vào việc sở hữu vòng đời tiến trình.
Vì chúng tôi chạy n8n như một ứng dụng one-click trong marketplace của mình, phần thiết lập đó là con đường ngắn nhất ở phía chúng tôi: bạn có thể triển khai n8n trên Cloudzy VPS với cấu hình Postgres-backed mà con đường sản xuất cần, trên một instance mà bạn có quyền root để thêm Redis và giám sát tiến trình của riêng mình. Đây là cùng footprint tự host được mô tả ở trên, nơi bạn sở hữu cơ sở dữ liệu và hành vi khởi động lại, điều làm cho checkpointing và tự phục hồi thực sự hoạt động.
Các mẫu harness chỉ đáng tin cậy bằng máy chủ chúng chạy trên. Checkpointing không có giá trị gì nếu tiến trình không bao giờ khởi động lại.
Câu hỏi thường gặp
Làm Thế Nào Để Ngăn LangGraph Agent Lặp Mãi Mãi?
Sử dụng hai cơ chế cùng nhau. Đặt recursion_limit như giới hạn bước cứng (mặc định là 25) để vòng lặp mất kiểm soát không thể đốt ngân sách vô hạn, và thêm tính năng phát hiện không có tiến triển - mã hóa hash mỗi lần gọi tool-cộng-argument và kết thúc khi cùng lần gọi lặp lại trong một cửa sổ gần đây. Giới hạn trần một mình là backstop kích hoạt sau khi sự lãng phí đã xảy ra, không phải bảo vệ vòng lặp thực sự. Phát hiện tiến triển là thứ thực sự dừng vòng lặp bị kẹt.
recursion_limit Đúng Trong LangGraph Dành Cho Môi Trường Sản Xuất Là Bao Nhiêu?
Không có con số phổ quát. Định cỡ nó theo số bước hợp pháp tối đa mà agent của bạn cần, cộng thêm biên độ, và coi nó nghiêm ngặt là backstop chi phí. Tăng giới hạn không làm cho agent đang lặp hội tụ. Nếu agent của bạn đang chạm giới hạn cao, cách khắc phục là phát hiện tiến triển, không phải giới hạn trần cao hơn.
Tại Sao n8n AI Agent Của Tôi Cứ Chạm Max Iterations?
Chạm giới hạn Max Iterations có nghĩa là agent không hội tụ: nó đang thực hiện nhiều bước hơn giới hạn cho phép mà không đạt đến điểm dừng. Tăng giới hạn chỉ nếu nhiệm vụ thực sự cần nhiều bước hơn; nếu không, hãy coi đó là tín hiệu agent đang bị kẹt. Cẩn thận một bẫy cụ thể: GitHub issue #22771 báo cáo rằng khi đạt giới hạn lặp với "On Error: Continue" được đặt, thực thi có thể định tuyến đến đầu ra Success thay vì đầu ra Error, vì vậy một lần chạy bị giới hạn và thất bại có thể trông như thành công trong workflow của bạn.
Làm Thế Nào Để Lưu Trữ Trạng Thái Agent Qua Các Lần Khởi Động Lại?
Trong LangGraph, sử dụng PostgresSaver checkpointing thay vì SqliteSaver, được thiết kế cho phát triển cục bộ. Trong n8n, sử dụng node Postgres Chat Memory thay vì bộ nhớ tích hợp trong tiến trình. Cả hai đều yêu cầu cơ sở dữ liệu bền vững, và trong LangGraph mọi thao tác checkpoint cần một thread_id liên kết một lần chạy nhất định với trạng thái đã lưu.
Điều Gì Gây Ra Suy Giảm Suy Luận Trong Các Lần Chạy Agent Dài?
Chất lượng suy luận giảm khi context tăng, ngay cả trước khi bạn chạm giới hạn token cứng. Đây là hiệu ứng "lost in the middle", khi model chú ý đến phần đầu và cuối của một context dài nhưng mất phần giữa. Blog kỹ thuật của Anthropic gọi cơ chế nền tảng là "context rot": vì mỗi token chú ý đến mọi token khác, bạn có n² mối quan hệ theo cặp và attention của model trải mỏng hơn khi context dài ra. Cách khắc phục là nén giữa vòng lặp tóm tắt lịch sử cũ trong khi giữ nguyên các ràng buộc đã ghim và hướng dẫn an toàn.


