
Løkken kørte rent fyrre gange i test. På det enogfyrredivte kørsel, i produktion, kaldte den det samme SQL-værktøj med den samme fejlbehæftede forespørgsel igen og igen, indtil den brændte dagens API-budget af og en faktureringsadvarsel til sidst vakte nogen. Ingen skrev en dårlig model. Ingen ændrede prompten. Agenten besluttede simpelthen aldrig, at den var færdig.
Dette er det mønster, jeg bliver ved med at se hos teams, der flytter en agent fra en prototype til en 24/7-arbejdsbyrde. AI-agent-løkker fejler ofte i produktion ikke fordi modellen pludselig er blevet dårligere, men fordi eksekveringslaget mangler afslutningsdisciplin, validerede værktøjskontrakter, afgrænset kontekst og holdbar tilstand. En agent-løkke er et stokastisk system, der træffer en sekventiel beslutning ad gangen. Uden et par specifikke sikkerhedsforanstaltninger bliver den sjældne fejl til en garanteret én, når du kører den længe nok. Administrerede agent-platforme (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) har indbygget nogle af disse sikkerhedsforanstaltninger; denne guide er til os, der valgte at self-hoste og eje løkken selv.
Indsatsen er reel nok til, at Gartner forventer over 40% af agentiske AI-projekter vil blive aflyst inden udgangen af 2027, med henvisning til eskalerende omkostninger og uklart udbytte. Det følgende er seks specifikke måder, løkker bryder i produktion, mekanismen bag hver enkelt, og det harness-mønster, der løser det, med LangGraph- og n8n-detaljerne plus hvad det kræver faktisk at køre dette 24/7.
Den korte version
- Uendelige løkker: Agenten beslutter aldrig, at den er færdig. Kombiner et hårdt trin-loft (LangGraph's
recursion_limit, standard 25) med fremgangsdetektering, der afslutter gentagne værktøj+argument-kald. - Kontekst-overflow: Løkken fylder sit eget kontekstvindue med akkumuleret historik, indtil kald afkortes eller fejler. Sammenfat historikken med faste intervaller, så den aktive kontekst forbliver afgrænset.
- Stille værktøjsfejl: Et værktøj returnerer en tom streng, modellen læser det som et gyldigt no-op, og agenten "lykkes" med at gøre ingenting. Valider hvert værktøjsresultat, inden modellen ser det.
- Forringelse af ræsonnement: Kvaliteten forfalder, efterhånden som konteksten vokser, selv under den hårde grænse. Komprimér midt i løkken, men beskyt fastgjorte sikkerhedsinstruktioner, når du gør det.
- Tilstandstab ved genstart: Et nedbrud betyder at starte fra bunden. Checkpoint til Postgres (LangGraph
PostgresSaver), ikke SQLite, til produktion. - Retry-storme: Ti agenter, der hver genforsøger ti gange, rammer en nedbrudden tjeneste med hundrede forespørgsler. Tilføj eksponentiel backoff med jitter og en global circuit breaker.
Hvad denne guide ikke dækker
Dette er en harness-guide med fokus på ingeniørarbejdet omkring løkken, ikke modellen inde i den. Et par relaterede emner er bevidst udeladt:
- Fejl i multi-agent-koordinering (forældede læsninger, forladte tilstande mellem agenter): et andet problem, der er værd at skrive separat om.
- Agent-sikkerhed (prompt injection, tool poisoning): en separat fejlkategori med sin egen trusselsmodel.
- Modelvalg og finjustering. Denne guide forudsætter, at du har valgt en model og debugger systemet omkring den.
- Administrerede agent-tjenester, nævnt ovenfor; mønstrene her er til den selvhostede vej.
Uendelige løkker: Når agenten aldrig beslutter, at den er færdig

En agent løkker evigt, når den hverken har et hårdt trin-loft eller en måde at opdage, at den er holdt op med at gøre fremgang. Løsningen er todelt: behold et hårdt loft som omkostningsbegrænsning, og tilføj fremgangsdetektering, der hasher hvert værktøj+argument-kald og afslutter, når det ser det samme kald gentages. I LangGraph er det loftet recursion_limit, standard 25 trin; overskrid det, og grafen kaster en GraphRecursionError.
LangGraph's docs beskriver denne grænse som at nå "det maksimale antal trin, inden en stoptilstand nås," og her er fælden, det er værd at forstå: rekursionsgrænsen er ikke løkkebeskyttelse. Det er en bagstop, der aktiveres efter efter at løkken allerede har spildt tyve trin og den tilhørende API-udgift. Agentens egen indlærte afslutningslogik forventes at stoppe den langt inden, og den logik kan svigte uafhængigt. Én rapporteret LangGraph-sag viser en tekst-til-SQL-agent, der loopede, indtil den ramte rekursionsgrænsen trods klare stoptilstande i prompten. Den blev ved med at kalde det samme forespørgselsværktøj med den samme fejlende SQL, og sagen blev lukket som "ikke planlagt". Jeg læser det som et klart signal: behandl ikke loftet som din stoptilstand. Det er din sikkerhedssele, ikke dine bremser.
At hæve loftet er ligetil; du sender det igennem konfigurationen, når du kalder grafen:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Den del, der faktisk stopper en fastlåst løkke, er fremgangsdetektering. Mekanismen er enkel: hash værktøjsnavnet plus dets argumenter ved hvert trin, hold et kort vindue af seneste hashes, og afbryd, når du ser en gentagelse.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Dette fanger agenten, der teknisk set "kører" (kalder værktøjer, genererer tokens) men cykler på den samme mislykkede handling. Den navngivne fejltilstand her svarer til, hvad MAST-taksonomiien (IBM Research og UC Berkeley) kalder Ubevidst om afslutningsbetingelser (FM-1.5), en af de fejltilstande, deres analyse forbinder med direkte opgavefejl.
Et trin-loft stopper ukontrollerede omkostninger. Fremgangsdetektering stopper løkken, der teknisk set "skrider frem", men gentager sig selv. Produktion kræver begge dele.
Kontekstvindue-overflow: Når løkken fylder sit eget kontekstvindue med skrald
En langvarig løkke akkumulerer hvert værktøjsoutput, hver mellemliggende tanke og hver besked, den har produceret, og propper det hele tilbage i kontekstvinduet ved hvert trin. Til sidst fylder vinduet, og kald afkortes enten lydløst eller fejler fuldstændigt. Løsningen er kontekstsummering med faste intervaller: hvert N trin komprimeres den akkumulerede historik til et løbende resumé, så den aktive kontekst forbliver afgrænset.
Forestil dig en research-agent, der har kørt i en time. Ved trin 60 bærer den den fulde tekst af hver side, den har hentet, hvert søgeresultat, hvert ræsonnementsspor. Ingen af den rå historik hjælper den ved trin 61, men al af den tæller mod vinduet, og modellen bruger opmærksomhedsbudget på tokens, den ikke længere har brug for. Når vinduet fylder, afkorter udbyderen fra den ene ende, og agenten mister stille og roligt den instruktion, den fik i starten.
Udløseren er en tuningbeslutning, og der er et nyttigt referencepunkt for den. Mem0's gennemgang af et virkeligt produktionssystem bemærker, at Hermes-agentens kompressor "aktiveres ved 50% af modellens kontekstvindue som standard", med et sekundært sikkerhedsnet ved 85% for sessioner, der svulmer op mellem trin. Halvtreds procent er et fornuftigt udgangspunkt: komprimér tidligt nok til, at et enkelt stort værktøjsoutput ikke kan overskride grænsen, inden næste planlagte komprimering.
Bemærk: Overflow og forringelse af ræsonnement er to forskellige problemer, og det næste afsnit dækker det andet. Overflow er en hård grænse: du løber tør for tokens. Forringelse er gradvis: modellen klarer sig dårligere. inden du rammer grænsen. Du skal håndtere begge, og udløserudgangspunktet ovenfor beskytter mod den hårde grænse.
Afgrænset kontekst er et harness-ansvar, ikke en modelfunktion. Sammenfat med et interval, inden vinduet tvinger en lydløs afkortning.
Stille værktøjskald-fejl: Når agenten "lykkes" med at gøre ingenting
Et værktøjskald returnerer en tom streng eller en blød "ingen resultater fundet"-besked, modellen fortolker det som et gyldigt resultat, og agenten fortsætter, som om trinnet virkede, og ser ud til at lykkes, mens den intet gør. Løsningen er en valideringsport ved hvert værktøjsretur: schema-tjek eller fornuftskontrol af outputtet, inden modellen nogensinde ser det, og vis en reel fejl, løkken skal håndtere, i stedet for en tom succes.
Denne er lumsk, fordi intet bryder ned. En udvikler, der beskriver stille fejltilstande i produktionsagenter siger det direkte: modeller fortolker generiske tomme strenge som gyldige no-ops og fortsætter eksekveringen uden bevidsthed om fejlen. Databaseforespørgslen, der returnerede nul rækker, fordi forbindelsen faldt, ser identisk ud for modellen som forespørgslen, der legitimt ikke fandt noget. Så agenten rapporterer "ingen matchende poster" og går videre, og du finder ud af det en uge senere, at en tredjedel af dens kørelser var lydløst brudte.
Valideringsporten sidder mellem værktøjet og modellen:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelPointen er ikke de præcise tjek; dine vil afhænge af, hvad hvert værktøj legitimt returnerer. Pointen er, at en uvalideret returværdi er en beslutning, du har overladt til en stokastisk model, og modellens standardbevægelse er at fortsætte.
En uvalideret værktøjsretur er en lydløs fejl, der venter på at ske. Valider outputtet; stol ikke på kaldet.
Forringelse af ræsonnement over lange kontekster: Når agenten bliver dårligere, jo længere den kører
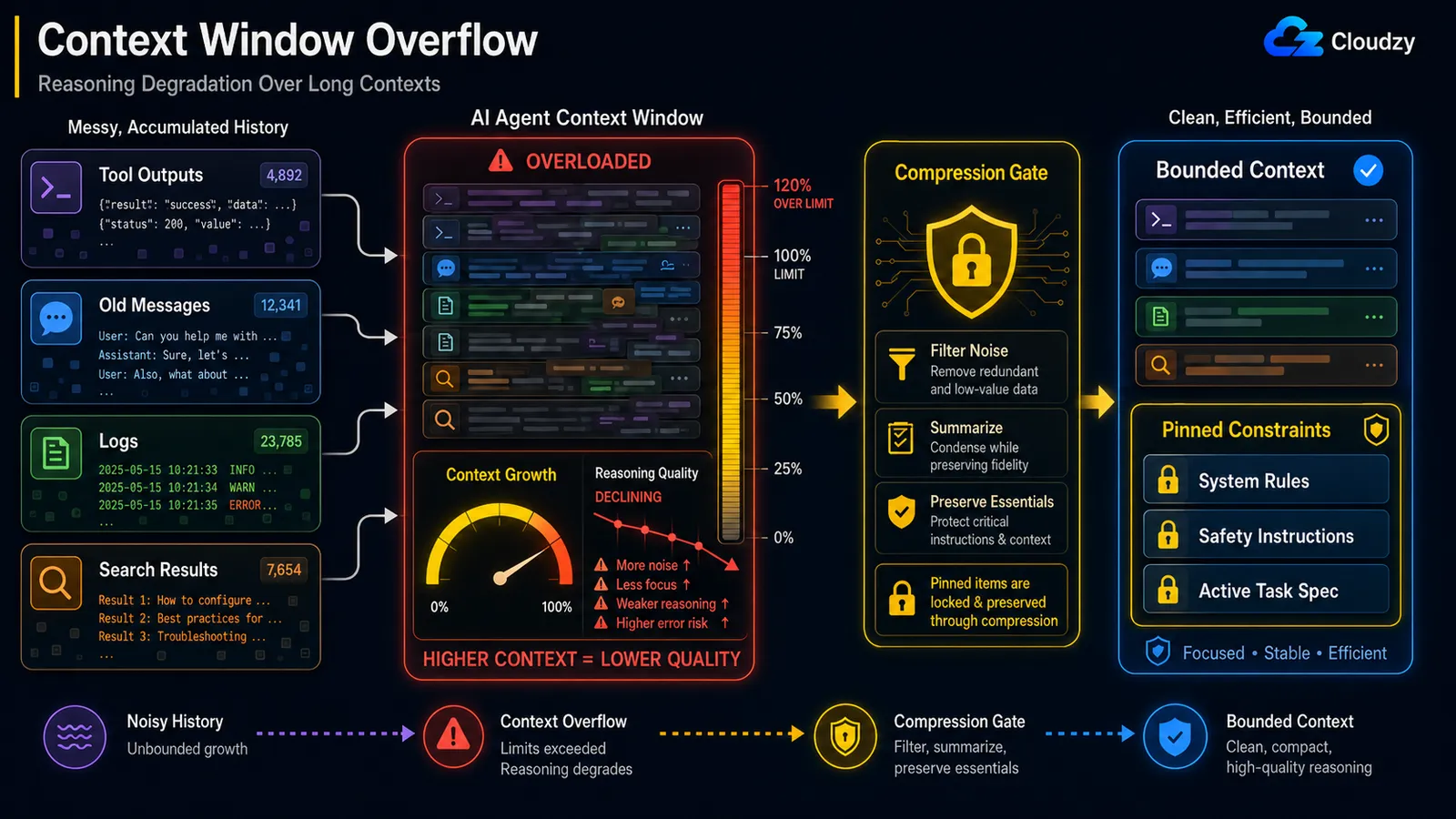
Selv når du holder dig under den hårde kontekstgrænse, forringes ræsonnemenskvaliteten, efterhånden som konteksten vokser. Dette er "lost in the middle"-effekten, hvor modellen pålideligt er opmærksom på starten og slutningen af en lang kontekst, men mister midten. Løsningen er mid-løkke-komprimering, der bevarer fastgjorte begrænsninger: komprimér støjen, beskyt de bærende instruktioner.
Mekanismen har et navn. Anthropics tekniske blog refererer til det som context rot: "efterhånden som antallet af tokens i kontekstvinduet stiger, falder modellens evne til nøjagtigt at genkalde information fra den kontekst." Fordi "hvert token er opmærksomt på hvert andet token," får du n² parvis-relationer for n tokens, og modellens opmærksomhed strækkes tyndere, jo længere konteksten kører.
Den kvalificering, beskyt de bærende instruktioner, er hele spillet, og der er en dokumenteret hændelse, der viser hvorfor. I en rapporteret sag, slettede en OpenClaw-agent massivt en brugers indbakke under en kontekstkomprimering, fordi den sikkerhedsinstruktion, den havde fået ("udfør ikke handlinger, indtil jeg siger til"), blev fjernet fra den aktive kontekst, da historikken blev komprimeret. Den begrænsning, der burde have været det allersidste, der gik, blev behandlet som almindelig historik og sammenfatter.
Så en naiv "sammenfat alt ældre end N trin" er farlig. Komprimering skal vide, hvad den aldrig må tabe:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactDette er forskelligt fra overflow-problemet i det foregående afsnit. Overflow handler om at løbe tør for plads; forringelse handler om, at modellen bliver dårligere, mens der stadig er plads. Du kan være ved 60% af dit vindue og allerede ræsonnere dårligt.
Bemærk: Komprimering, der taber en sikkerhedsbegrænsning, er en anden klasse af fejl end komprimering, der mister et forældet søgeresultat. Tag begrænsningerne, opgavespecifikationen og alle "gør ikke X"-instruktioner som fastgjorte, og udeluk dem fra opsummeringen helt.
Komprimering, der taber en sikkerhedsinstruktion, er værre end ingen komprimering. Beskyt fastgjorte begrænsninger, når du komprimerer.
Tilstandstab ved genstart: Når et nedbrud betyder at starte forfra
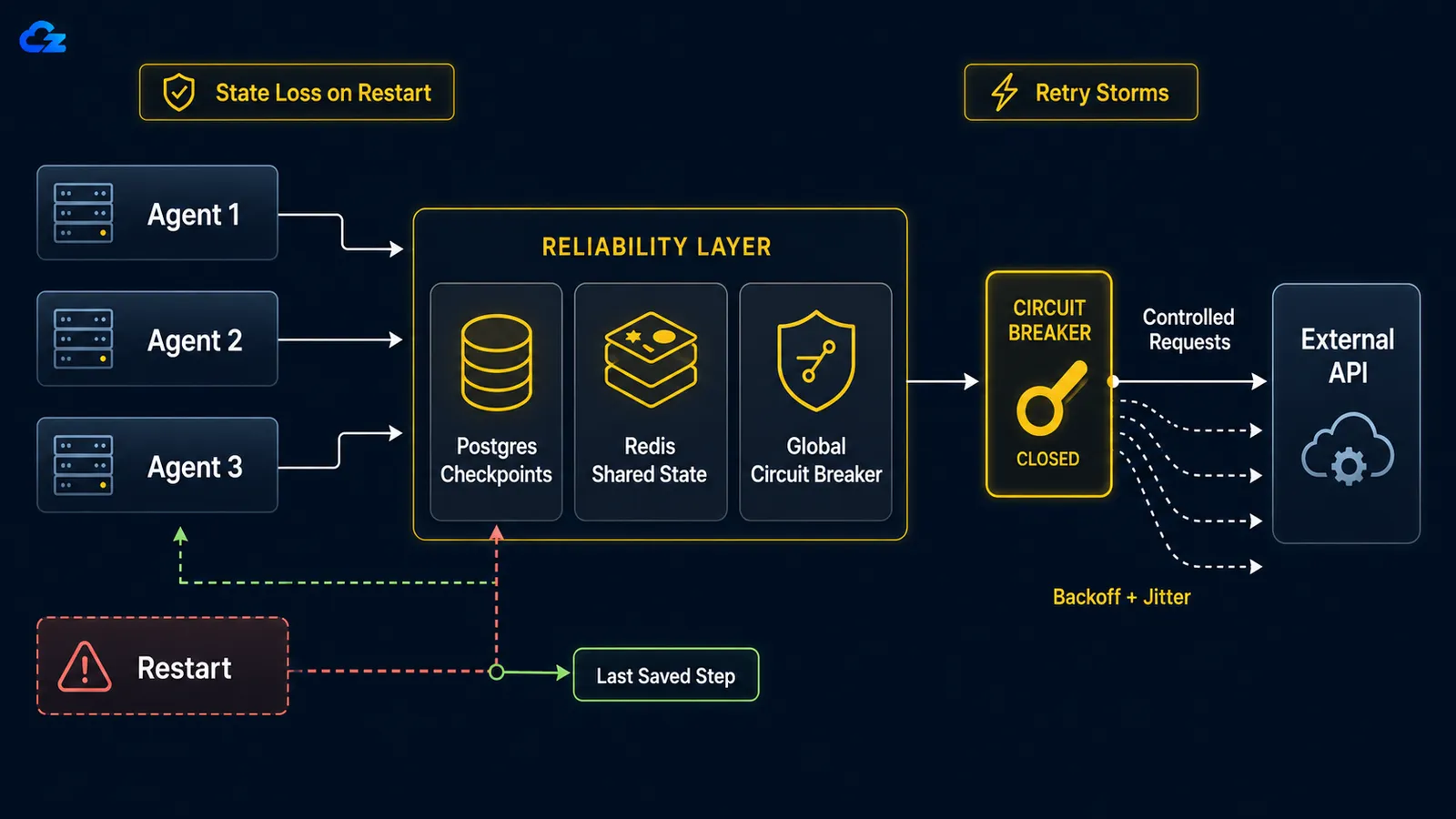
Når en langvarig agent nedbrydes, hvad enten det skyldes en genstart, et OOM-drab eller en tabt netværksforbindelse, er der ingen genoptagelse fra checkpoint som standard. Løkken starter forfra fra bunden: den gentager arbejde, den allerede har afsluttet, og endnu værre kan den genudføre handlinger, den allerede har foretaget, som at sende den samme e-mail to gange eller køre et betalt API-kald igen. Løsningen er checkpointing: bevar løkkens tilstand efter hvert trin, så en genstart genhydrerer fra, hvor den stoppede, i stedet for fra nul.
I LangGraph er valget af checkpoint-backend valget mellem dev og produktion. LangGraph's persistence docs beskriver SqliteSaver som "ideel til eksperimentering og lokale arbejdsgange" og PostgresSaver som "ideel til brug i produktion," og sidstnævnte er, hvad LangSmith selv kører på. De to er bevidst parallelle i kode, hvilket gør kontrasten let at se:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverTo detaljer, der bider folk. For det første installeres checkpoint-pakkerne separat fra core LangGraph (langgraph-checkpoint-sqlite og langgraph-checkpoint-postgres er egne afhængigheder), så en frisk maskine har ikke Postgres-gemeren, inden du tilføjer den. For det andet kræver hver checkpoint-operation en thread_id i konfigurationen. Det ID er det, der knytter en given kørsel til dens gemte tilstand, og en genstart uden den rigtige thread_id genhydrerer ingenting.
Pro-tip: LangGraph-checkpoint-pakkerne er separate installationer.
langgraph-checkpoint-postgrestrækkes ikke ind af basispakkenlanggraph, så pin den i din produktions-kravfil, inden du finder ud af det den hårde vej under en hændelse.
n8n har den samme dev-versus-produktion-opdeling, blot under andre navne. Dens indbyggede hukommelsesmulighed kaldes også Simple Memory (eller Buffer Window Memory), og produktionsvejen er Postgres Chat Memory-noden for tilstand, der skal overleve en genstart. Den indbyggede hukommelse holder samtalen i den kørende proces, hvilket er fint til test og en risiko for en 24/7-arbejdsbyrde. Praktikere, der kører n8n-agenter live, rapporterer at have skullet migrere til et Postgres-understøttet lager, efter at in-process-hukommelsen voksede, til den tog instansen ned med sig. Hvis du bruger n8n, og din agent skal huske noget på tværs af en genstart, så tilslut det til Postgres Chat Memory fra starten.
SQLite-checkpointing er en udviklingsbekvemmelighed. At overleve en produktionsgenstart kræver Postgres (LangGraph) eller et Postgres-understøttet lager (n8n).
Retry-storme: Når dine egne agenter DDoS'er en nedbrudden tjeneste
Når en downstream-tjeneste går ned, gør naive per-eksekverings-genforsøg din agent-flåde til et selvpålagt denial-of-service. Løsningen har to halvdele: eksponentiel backoff med jitter på hver agent for at sprede genforsøgene i tid, og en global circuit breaker, der udløses efter en delt fejlgrænse og forhindrer hele flokken i at hamre en tjeneste, der tydeligvis er nede.
Matematikken er ubarmhjertig. Som en retry-mønster-gennemgang formulerer det: med ti parallelle agenter, der hver genforsøger ti gange, sender du hundrede forespørgsler til en tjeneste, der allerede er på gulvet, fordi hver agents backoff er per-eksekvering, ikke global. Per-agent-backoff alene løser ikke dette. Ti agenter, der hver bakker pænt af, bakker stadig af i unison, hvis de alle startede på samme tid, så de genforsøger i synkroniserede bølger. Jitter bryder synkroniseringen ved at randomisere hver agents ventetid; circuit breakeren bryder flokken ved at dele én fejltilstand på tværs af dem alle.
Backoff-halvdelen er et løst problem i Python; biblioteket tenacity håndterer eksponentiel-med-jitter rent:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Circuit breakeren er den halvdel, der skal være global: delt på tværs af alle agenter, ikke geninstansieret per eksekvering. Når fejl overskrider en grænse, åbner den, hver agent fejler hurtigt i stedet for at kalde ud, og efter en afkølingsperiode lader den en enkelt probe igennem for at teste, om tjenesten er tilbage. En breaker, der lever inde i hver agents egen proces, beskytter ingenting, fordi intet er delt; den nedbrudde tjeneste får stadig de fulde hundrede forespørgsler.
Per-eksekverings-backoff lader stadig ti agenter hamre en nedbrudden tjeneste i unison. Circuit breakeren skal være global for at stoppe flokken.
De seks fejl på ét blik
Inden infrastruktur-delen, her er hele kataloget på ét sted: fejlen, mekanismen, der forårsager den, harness-løsningen og hvor den relevante parameter er i hvert framework.
| Fejltilstand | Mekanisme | Harness-løsning | Framework-parameter |
|---|---|---|---|
| Uendelig løkke | Intet trin-loft eller fremgangsdetektering | Hårdt loft + fremgangsdetektering | LangGraph recursion_limit (25) / n8n Max Iterations |
| Kontekst-overflow | Historik vokser, indtil vinduet fylder | Intervalbaseret summering | App-niveau (komprimér ved ~50% af vinduet) |
| Stille værktøjsfejl | Tomme/bløde returværdier læses som gyldige no-ops | Valideringsport ved hvert værktøjsresultat | App-niveau-værktøjsindpakning |
| Forringelse af ræsonnement | Opmærksomhed forfalder, efterhånden som konteksten vokser ("context rot") | Mid-løkke-komprimering, der beskytter fastgjorte begrænsninger | App-niveau, begrænsningsopmærksom |
| Tilstandstab ved genstart | Ingen checkpoint; løkke genstarter fra nul | Vedvarende checkpointing | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry-storm | Per-eksekverings-genforsøg kaskaderer på en nedbrudden tjeneste | Backoff + jitter + global circuit breaker | tenacity + delt breaker-tilstand |
En note til læsere på CrewAI, AutoGen, Dify eller en håndlavet Python-løkke: framework-parametrene ændrer sig, men de seks mønstre gør det ikke. Deduplicering, intervalbaseret summering, schemavalidering, begrænsningsopmærksom komprimering, checkpointing og en global circuit breaker er framework-agnostiske koncepter. LangGraph- og n8n-specifikationerne her er konkrete håndtag, ikke grænsen for, hvor mønstrene finder anvendelse.
Dimensionering af en produktions-agent-implementering
Hvert mønster ovenfor forudsætter, at du kontrollerer processen, databasen og genstartsadfærden. Checkpointing giver dig ingenting, hvis en nedbruddet løkke aldrig kommer op igen, og en global circuit breaker har brug for et sted at holde sin delte tilstand. Den kontrol er præcis, hvad self-hosting giver dig, og en administreret black box ikke gør, så den sidste beslutning er at dimensionere den maskine, der kører det 24/7.
For de fleste single-agent-implementeringer (én agent, LLM-kald der sendes ud til en ekstern API, grundlæggende Postgres-checkpointing) er en lille instans nok: omkring 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Den tunge beregning lever på modelleudbydernes side; din maskine orkestrerer, checkpointer og holder tilstand, ikke kører inferens. Gå op til omtrent 4 GB RAM, 2 vCPU, and 120 GB NVMe når agenten er tilstandsfuld og multi-step med Postgres-checkpointing plus Redis til sessionshydrering, eller når du kører samtidige arbejdsgange, der deler hosten.
Grunden til, at dette ønsker en selvadministreret VPS frem for en begrænset platform, er den samme grund til, at løsningerne overhovedet virker: de kræver root. Din egen Postgres til checkpointing, din egen Redis til sessionstilstand, og en rigtig proceshåndtering som f.eks. systemd or pm2, så når en løkke dør, genstarter supervisoren den, og den genhydrerer fra sit sidste checkpoint i stedet for at starte jobbet forfra. Hele den gendannelseshistorie afhænger af at eje proceslivscyklussen.
Fordi vi kører n8n som en one-click-app i vores eget marketplace, er den del af opsætningen den korteste vej på vores side: du kan deploye n8n på en Cloudzy VPS med den Postgres-understøttede konfiguration, som produktionsvejen kræver, på en instans, hvor du har root-adgang til at tilføje din egen Redis og procestilsyn. Det er det samme selvhostede fodaftryk, der er beskrevet ovenfor, hvor du ejer databasen og genstartsadfærden, hvilket er det, der gør checkpointing og auto-recovery faktisk fungerende.
Harness-mønstrene er kun så pålidelige som den maskine, de kører på. Checkpointing giver dig ingenting, hvis processen aldrig genstarter.
Ofte stillede spørgsmål
Hvordan stopper jeg min LangGraph-agent fra at loope for evigt?
Brug to mekanismer sammen. Sæt recursion_limit som et hårdt trin-loft (standarden er 25), så en ukontrolleret løkke ikke kan brænde ubegrænset budget, og tilføj fremgangsdetektering, der hasher hvert værktøj+argument-kald og afslutter, når det samme kald gentages inden for et nyligt vindue. Loftet alene er en bagstop, der aktiveres, efter at spildet er sket, ikke rigtig løkkebeskyttelse. Fremgangsdetektering er det, der faktisk stopper en fastlåst løkke.
Hvad er den rigtige recursion_limit til LangGraph i produktion?
Der er ikke noget universelt tal. Dimensionér det til det maksimale antal legitime trin, din agent nogensinde bør have brug for, plus en margen, og behandl det strengt som en omkostningsbagstop. At hæve grænsen får ikke en loopende agent til at konvergere. Hvis din agent rammer en høj grænse, er løsningen fremgangsdetektering, ikke et højere loft.
Hvorfor rammer min n8n AI-agent ved Max Iterations?
At ramme Max Iterations-loftet betyder, at agenten ikke konvergerer: den tager flere trin end grænsen tillader uden at nå et stop. Hæv kun grænsen, hvis opgaven legitimt har brug for flere trin; ellers behandl det som et signal om, at agenten sidder fast. Pas på én specifik fælde: GitHub issue #22771 rapporterer, at når iterationsgrænsen nås med "On Error: Continue" sat, kan eksekveringen rutes til Success-outputtet i stedet for Error-outputtet, så en begrænset, mislykket kørsel kan se ud som en succes i din arbejdsgang.
Hvordan bevarer jeg agent-tilstand på tværs af genstarter?
I LangGraph, brug PostgresSaver checkpointing frem for SqliteSaver, som er beregnet til lokal udvikling. I n8n, brug Postgres Chat Memory-noden frem for den in-process-indbyggede hukommelse. Begge kræver en vedvarende database, og i LangGraph kræver hver checkpoint-operation en thread_id der knytter en given kørsel til dens gemte tilstand.
Hvad forårsager forringelse af ræsonnement ved lange agent-kørelser?
Ræsonnemenskvalitet falder, efterhånden som konteksten vokser, selv inden du rammer den hårde token-grænse. Dette er "lost in the middle"-effekten, hvor modellen er opmærksom på starten og slutningen af en lang kontekst, men mister midten. Anthropics tekniske blog refererer til den underliggende mekanisme som "context rot": fordi hvert token er opmærksomt på hvert andet token, får du n² parvis-relationer, og modellens opmærksomhed strækkes tyndere, efterhånden som konteksten forlænges. Løsningen er mid-løkke-komprimering, der sammenfatter forældet historik, mens fastgjorte begrænsninger og sikkerhedsinstruktioner bevares intakte.


