
Udskift GPT-5 med Claude inde i en fungerende agent og det meste af tiden ændrer der sig næsten ingenting. Skift hvordan den håndterer genforsøg, hvad du fodrer ind i dens kontekstvindue, eller hvornår den beslutter sig for at stoppe, og hele agenten opfører sig anderledes. Den kløft er tegnet: modellen er den mindste og mest udskiftelige del af en fungerende agent. Den interessante teknik lever i alt, der er pakket rundt om den.
Den wrapper har nu et navn. Praktikere landede på "harness" for det lag, der forvandler en tekstgenerator til noget, der udfører handlinger over tid frem for at køre et fast script. Termen spredte sig hurtigt på Twitter og i engineering-blogs i begyndelsen af 2026, hvilket også betyder, at den blev brugt løst, med det samme ord der gjorde lidt forskelligt arbejde i hvert indlæg du læser. Denne artikel fastlægger det præcist: hvad et harness er, hvad det er lavet af, hvordan det adskiller sig fra et "framework" og et "scaffold", og hvorfor det meste af din agents kvalitet gemmer sig i harness, ikke i modellen.
Den korte version
- Et agent harness er softwaren omkring et LLM, der styrer udførelsesløkken, værktøjer, hukommelse, kontekst, tilstand, fejlhåndtering og sikkerhedsmekanismer. Modellen genererer tekst; harness beslutter hvad modellen ser, hvad den kan gøre, hvornår den stopper, og hvad der sker når noget går galt.
- I produktion er modelkaldet ofte den mindste synlige del af systemets overfladeareal. En svagere model i et velbygget harness kan slå en stærkere model i et sjusket et, især på langvarige, værktøjstunge opgaver.
- Et harness har omtrent ni til elleve tilbagevendende komponenter. De fleste af dem er ting, modellen aldrig berører direkte.
- "Harness" er ikke det samme som "framework". Et framework (LangGraph, et agents SDK) er biblioteket du bygger med; harness er det kørende lag, som biblioteket hjælper dig med at samle.
Hvad er et Agent Harness?
Et agent harness er den software-infrastruktur der omgiver et sprogmodel og styrer udførelsesløkken, værktøjsadgang, hukommelse, kontekst, tilstandspersistens, fejlhåndtering og sikkerhedsmekanismer. Modellen genererer tekst. Harness beslutter hvad modellen ser på hvert træk, hvilke handlinger den kan foretage, hvornår den stopper, og hvad der sker når et trin fejler.
Den klareste formulering kommer fra LangChain, der reducerer det til en ligning: Agent = Model + Harness. Modellen leverer intelligensen. Harness er det, der får denne intelligens til at gøre noget i verden.
"Et harness er hvert stykke kode, konfiguration og udførelseslogik, der ikke er selve modellen."
— LangChain, Anatomien af et agent harness
Jeg finder grænsen lettest at mærke gennem ét spørgsmål: når din agent gør det forkerte, var det så modellens egen ræsonnering, der var forkert, eller gav systemet omkring den modellen den forkerte kontekst, de forkerte værktøjer, eller ingen måde at komme sig på? Det meste af tiden, på et rigtigt system, er det det andet. Modellen ræsonnerede fint over dårlige inputs. Harness er det, der styrer inputs.
Vigtigste pointe: Modellen genererer; harness styrer. Den opdeling er hele konceptet.
Hvad er komponenterne i et agent harness?
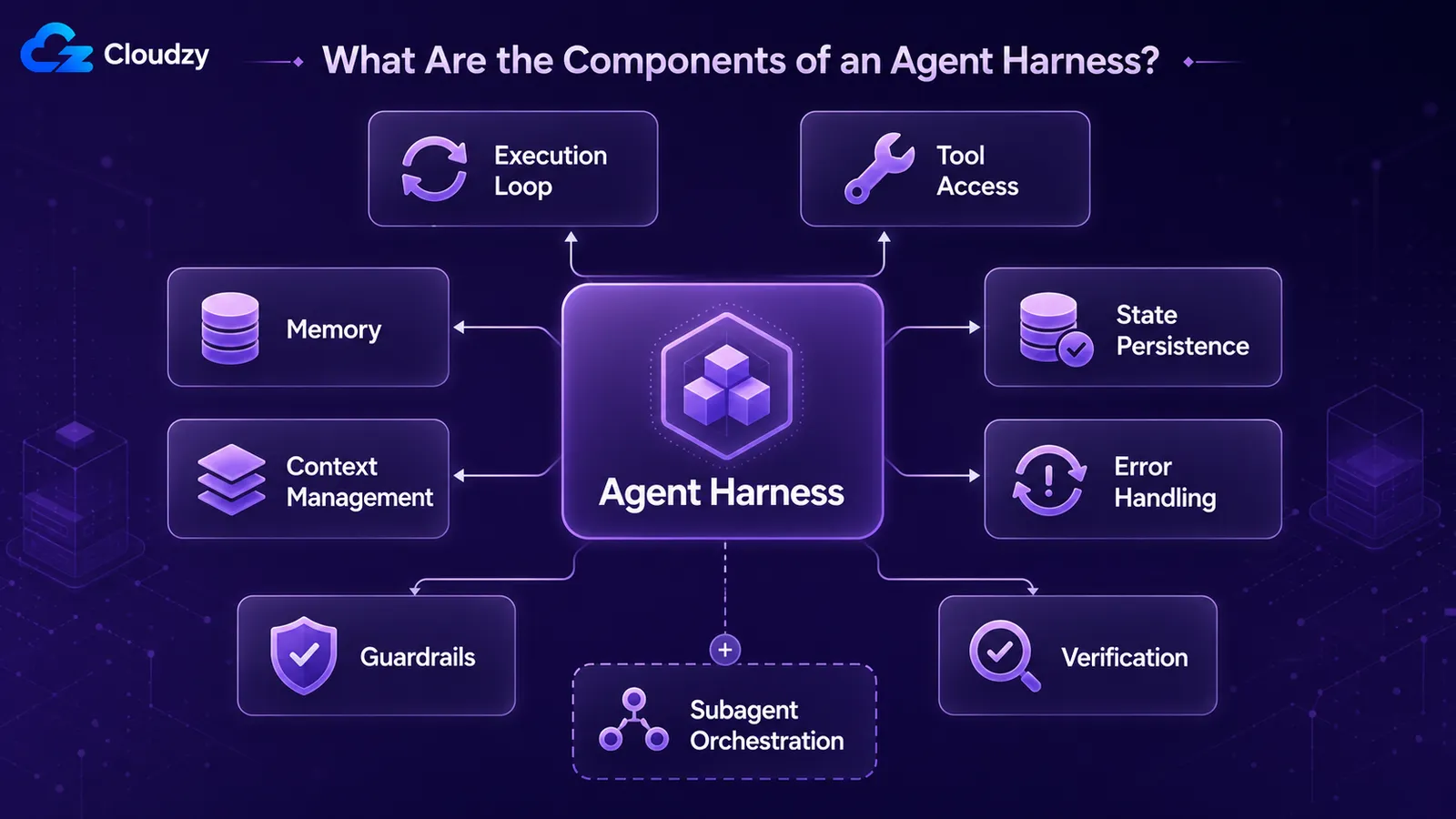
Enhver produktionsharness samler de samme tilbagevendende dele: en udførelsesloop der driver modellen tur for tur, værktøjsadgang der lader den handle, hukommelse på tværs af ture, kontekststyring for hvad den ser lige nu, tilstandspersistens så arbejde overlever på tværs af sessioner, fejlhåndtering for mislykkede trin og sikkerhedsrails der begrænser hvad den kan gøre. Produktionssystemer tilføjer verifikationsloops og subagent-orkestrering.
Et nyttigt inventar, udledt af hvordan praktikere beskriver virkelige systemer:
- Udførelses- / kontrolloop: det der driver agenten tur for tur. Kald modellen, læs dens output, kør det ønskede tool, send resultatet tilbage, gentag indtil stopbetingelsen.
- Tool-adgang: de funktioner, API'er, kodeudførelse og filsystem som modellen kan nå.
- Hukommelse: hvad agenten beholder på tværs af ture og sessioner.
- Kontekststyring: hvad der pakkes ind i modellens vindue ved hvert tur, og hvad der komprimeres ud når det løber over.
- Tilstandspersistens / checkpointing: gemme agentens tilstand så et crashet eller sat på pause kørsel kan genoptages.
- Fejlhåndtering: genforsøg, fallbacks og gendannelse når et tool-kald eller et model-kald fejler.
- Sikkerhedsrækværk: begrænsninger for, hvad agenten kan gøre, såsom tilladte værktøjer, tringrænser og outputvalidering.
- Verifikationsløkker: agenten (eller harness) tjekker sit eget arbejde, inden det erklæres færdigt.
- Subagent-orkestrering: starte, delegere til og indsamle fra sub-agenter ved større opgaver.
Ikke alle disse er universelle. Udførelsesløkken, værktøjer, konteksthåndtering og fejlhåndtering dukker op selv i en weekendprototype. Tilstandspersistens, verifikation og subagent-orkestrering er der, hvor prototyper og produktionssystemer skilles. En prototype kan springe dem over; en langkørende produktionsagent kan ikke. Anthropic's gennemgang af langkørende agenter er en gennemgang af de produktionseksklusive dele: hvordan en agent genopbygger sin forståelse fra en fremskridtsfil efter at dens kontekstvindue er nulstillet, og hvordan testning kobles ind i løkken.
For den der ønsker den akademiske bro, er en nylig undersøgelse af agentarkitekturer folder den samme mekanisme ind i en mindre formel tuple af kernekomponenter. Praktikerlisten og undersøgelsens ramme er to zoomniveauer på den samme struktur: undersøgelsen komprimerer, inventaret ovenfor udvider. Behandl ni-til-elleve-tallet som de komponenter, de fleste produktionsharnesses deler, ikke en ratificeret standard; feltet har endnu ikke ratificeret noget.
Vigtigste pointe: De fleste af en agents bevægelige dele lever i harness, ikke i modellen. Modellen er en komponent blandt mange.
Hvorfor betyder harness mere end modellen?
En svagere model inde i et veldesignet harness overgår ofte en stærkere model i et dårligt designet. Årsagen er mekanisk, ikke magisk: end-to-end pålidelighed for en agent er produktet af hvert trins pålidelighed, og de fleste af disse trin (værktøjsvalg, kontekstsamling, fejlgendannelse) er harness'ets opgave, ikke modellens. Forbedr dem, og hele kæden bliver mere pålidelig, uanset hvilket model der sidder indeni.
Aritmetikken gør det konkret. Antag at hvert trin i en ti-trins opgave lykkes 99% af tiden. End-to-end succes er ikke 99%. Det er 0,99 i tiende potens, cirka 90%. Skub hvert trin til 99,9% og end-to-end hopper til ca. 99%. Pålidelighed pr. trin akkumuleres, og pålidelighed pr. trin er overvejende en harness-egenskab. Det er derfor optimering af fejlhåndtering og kontekststyring betaler sig mere end at skifte til et model der er et halvt point bedre på et benchmark.
Der er et produktionssignal, der peger i samme retning. MongoDB, med henvisning til Vercels casestudy, rapporterer at Vercel reducerede størstedelen af deres agents værktøjer og så dens succesrate stige markant på samme model, med et mindre og renere harness. Læs det som konvergerende evidens snarere end bevis: det er ét produktionstillfælde, ikke et kontrolleret eksperiment, men det peger i samme retning som den akkumulerede aritmetik og undersøgelsesarbejdet ovenfor.
Dette er den heuristik, jeg som platform-ingeniør hele tiden vender tilbage til: kontekst er flaskehalsen, ikke rå modelkapacitet, og stillads bygget til at dække over nutidens modellers mangler har en tendens til at blive overtaget efterhånden som modellerne forbedres. Byg de holdbare dele af harness (loopet, tilstanden, gendannelsen) og lad modellen nedenunder blive bedre i sin egen takt.
Vigtigste pointe: Når din agent fejler, mistænk harness'et før modellen. Sandsynligheden taler for det.
Hvad er forskellen mellem et harness, et scaffold og et framework?
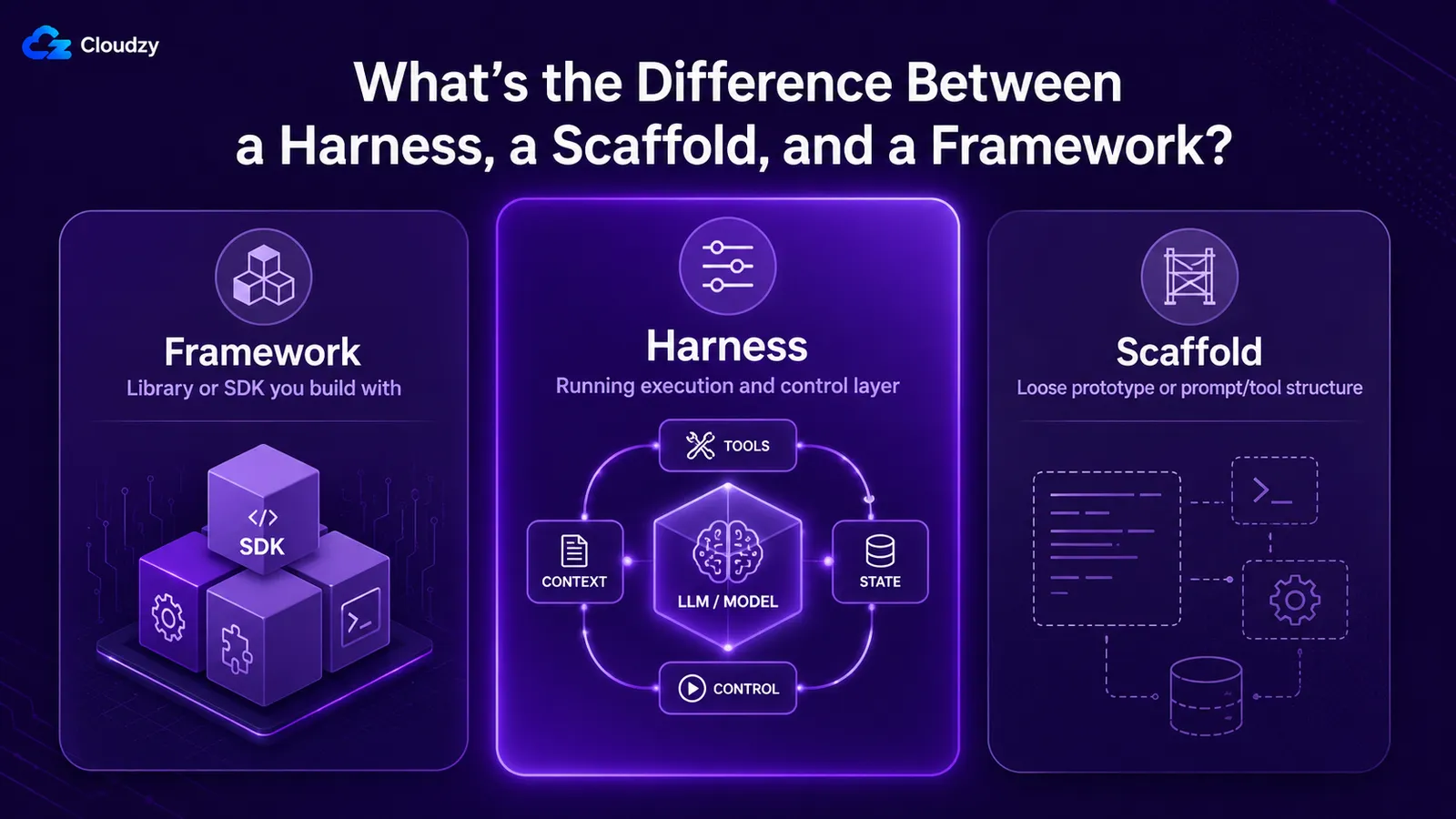
Disse tre bruges om hinanden, og det bør de ikke. A framework er det bibliotek eller SDK, du bygger med, f.eks. LangGraph eller et agents SDK. Et harness er det kørende eksekutions- og governance-lag omkring modellen, som et framework hjælper dig med at samle. Et scaffold er den løseste af de tre: nogle gange næsten et synonym for harness, nogle gange prototypeversionen af en, nogle gange specifikt prompt-og-værktøjsbeskrivelseslaget.
Vokabularet er genuint uafgjort, og det reneste er at kortlægge brugen frem for at lovgive om en. HuggingFace's Agent-ordliste siger det direkte:
"Mange af disse termer har endnu ikke universelt accepterede definitioner, og forskellige frameworks bruger det samme ord forskelligt."
— HuggingFace, Agent-ordliste
| Begreb | Hvad det henviser til | Relation |
|---|---|---|
| Framework | Biblioteket eller SDK du bygger med (LangGraph, et agents SDK) | Et værktøj til at samle et harness |
| Harness | Det kørende lag omkring modellen: loop, tools, kontekst, tilstand, guardrails | Det du sender og kører |
| Scaffold | Brugt løst: et næsten-synonym for harness, eller prototypeniveau / prompt-lagsversionen | Overlapper med harness; mindre præcist |
| Loop | Eksekveringscyklussen inde i harness | En komponent i harness |
Den praktiske konklusion for at ræsonnere om dit eget system: når nogen siger "framework", så spørg om de mener biblioteket eller det kørende ting. Når nogen siger "scaffold", spørg om de mener hele harness eller kun prompt-og-værktøjslaget. Disambigueringen er værdien her, ikke et krav om det sidste ord.
Hvordan implementerer LangGraph Harness-mønsteret?
LangGraph er en populær open-source Python-implementering af harness-mønsteret. Det modellerer agentudførelse som en rettet graf af knuder og kanter, med typet tilstand der flyder mellem dem og hver overgang der kan checkpointes. Hvis de abstrakte komponenter ovenfor føles ubegribelige, er LangGraph et sted at se dem tage konkret form i et rigtigt værktøj.
Tilknytningen er tæt på en-til-en. Knuder og kanter er udførelsesløkken: hver knude udfører arbejde, hver kant beslutter, hvor kontrollen går hen næste gang. Det typede tilstandsobjekt, der sendes mellem knuder, er kontekst-og-tilstand-komponenten gjort eksplicit. Checkpointing (LangGraph bevarer tilstand via savers som dens Postgres-baserede implementering) er tilstandspersistens-komponenten. En konfigurerbar tringrænse er en stopbetingelse-guardrail, der forhindrer en fejlbehæftet agent i at loope for evigt. Samme komponenter, navngivet og forbundet af et specifikt bibliotek.
Hvis du vil køre en LangGraph-agent på din egen server, hele døgnet, er det et deployment-spørgsmål snarere end et konceptuelt. Se vores Linux VPS-guide for den vej. Her er LangGraph blot det udarbejdede eksempel: bevis for at "udførelsesløkke", "tilstandspersistens" og "guardrail" ikke er abstraktioner, de er ting du kan pege på i rigtig kode.
Ofte stillede spørgsmål
Hvad er et Agent Harness?
Et agent-harness er softwaren omkring en sprogmodel, der forvandler den til en agent. Det styrer udførelsesløkken, adgang til værktøjer, hukommelse, kontekst, tilstandspersistens, fejlhåndtering og guardrails. Modellen genererer tekst; harness bestemmer hvad modellen ser, hvad den kan gøre, hvornår den skal stoppe og hvad der sker når noget fejler.
Er et agent harness det samme som et agent framework?
Nej. Et framework er det bibliotek eller SDK, du bygger med, som LangGraph eller et agents SDK. Harness er det kørende udførelses- og styrings-lag omkring modellen (løkken, værktøjer, kontekst, tilstand og guardrails), som et framework hjælper dig med at sammensætte. Du bruger et framework til at bygge en harness.
Hvilke komponenter har enhver agent harness?
De fleste harnesses deler en tilbagevendende kerne: en udførelsesløkke, adgang til værktøjer, hukommelse, kontekststyring, tilstandspersistens, fejlhåndtering og guardrails. Produktions-harnesses tilføjer verifikationsløkker og subagent-orkestrering. Prototyper kan springe de produktionsspecifikke dele over, men løkken, værktøjer, konteksthåndtering og fejlhåndtering optræder næsten overalt.
Hvad betyder "LLM er den mindste del af dit agentsystem"?
Det betyder, at det meste af en agents adfærd og pålidelighed kommer fra harness, ikke fra modellen. End-to-end pålidelighed er produktet af hver enkelt trins succesrate, og de fleste trin er harness-arbejde. MongoDB rapporterer, med reference til Vercels casestudie, et hop i succesraten udelukkende fra harness-ændringer, på det samme model. Det er bevis for, at at rette harness overgår at rette modellen.
Hvor din agents kvalitet bor
Harness er det sted, hvor det meste af en agents kvalitet er, og du har nu ordforrådet til at lokalisere problemer i dit eget system. Du kan definere en harness, navngive dens komponenter, skelne den fra et framework og et scaffold, og ræsonnere om, hvorvidt en given fejl er et modelproblem eller et harness-problem.
Så næste gang din agent opfører sig forkert, skal du revidere harness-laget først: den kontekst, du giver den, de værktøjer, du har eksponeret, de stoppebetingelser, du har sat, den måde, den kommer sig fra et fejlet trin. Grib kun efter en større model, efter at det lag er kontrolleret. Det meste af tiden vil det ikke være nødvendigt.


