
Sostituisci GPT-5 con Claude all'interno di un agent funzionante e, nella maggior parte dei casi, il comportamento cambia appena. Modifica come gestisce i tentativi ripetuti, cosa inserisci nella sua finestra di contesto o quando decide di fermarsi, e l'intero agent si comporta diversamente. Questo divario è il segnale rivelatore: il modello è la parte più piccola e più sostituibile di un agent funzionante. L'ingegneria interessante risiede in tutto ciò che lo avvolge.
Quel wrapper ora ha un nome. I professionisti hanno adottato "harness" per lo strato che trasforma un generatore di testo in qualcosa che esegue azioni nel tempo piuttosto che eseguire uno script fisso. Il termine si è diffuso rapidamente su Twitter e nei blog di ingegneria all'inizio del 2026, il che significa che è stato usato anche in modo generico, con la stessa parola che faceva un lavoro leggermente diverso in ogni post che leggevi. Questo articolo lo definisce con precisione: cos'è un harness, di cosa è fatto, come si differenzia da un "framework" e da uno "scaffold", e perché la maggior parte della qualità del tuo agent si nasconde nell'harness, non nel modello.
La versione breve
- Un agent harness è il software attorno a un LLM che gestisce il loop di esecuzione, gli strumenti, la memoria, il contesto, lo stato, la gestione degli errori e i guardrail. Il modello genera testo; l'harness decide cosa vede il modello, cosa può fare, quando fermarsi e cosa succede quando qualcosa si rompe.
- In produzione, la chiamata al modello è spesso la parte visibile più piccola della superficie del sistema. Un modello più debole in un harness ben costruito può battere un modello più forte in uno trascurato, specialmente in attività lunghe e che fanno uso intensivo di strumenti.
- Un harness ha circa da nove a undici componenti ricorrenti. La maggior parte di essi sono cose che il modello non tocca mai direttamente.
- "Harness" non è la stessa cosa di "framework". Un framework (LangGraph, un agents SDK) è la libreria con cui costruisci; l'harness è il livello in esecuzione che quella libreria ti aiuta ad assemblare.
Cos'è un Agent Harness?
Un agent harness è l'infrastruttura software che circonda un modello linguistico e gestisce il loop di esecuzione, l'accesso agli strumenti, la memoria, il contesto, la persistenza dello stato, la gestione degli errori e i guardrail. Il modello genera testo. L'harness decide cosa vede il modello ad ogni turno, quali azioni può intraprendere, quando si ferma e cosa succede quando un passaggio fallisce.
La formulazione più chiara viene da LangChain, che lo riduce a un'equazione: Agent = Model + Harness. Il modello fornisce l'intelligenza. L'harness è ciò che permette a questa intelligenza di fare qualcosa nel mondo reale.
"Un harness è ogni pezzo di codice, configurazione e logica di esecuzione che non è il modello stesso."
— LangChain, L'anatomia di un agent harness
Trovo che il confine sia più facile da percepire attraverso una domanda: quando il tuo agente fa la cosa sbagliata, il ragionamento del modello stesso era errato, o il sistema intorno ad esso ha fornito al modello il contesto sbagliato, gli strumenti sbagliati, o nessun modo per recuperare? La maggior parte delle volte, in un sistema reale, è la seconda opzione. Il modello ha ragionato bene su input errati. Il harness è ciò che controlla gli input.
Punto chiave: Il modello genera; il harness governa. Questa divisione è l'intero concetto.
Quali sono i componenti di un agent harness?
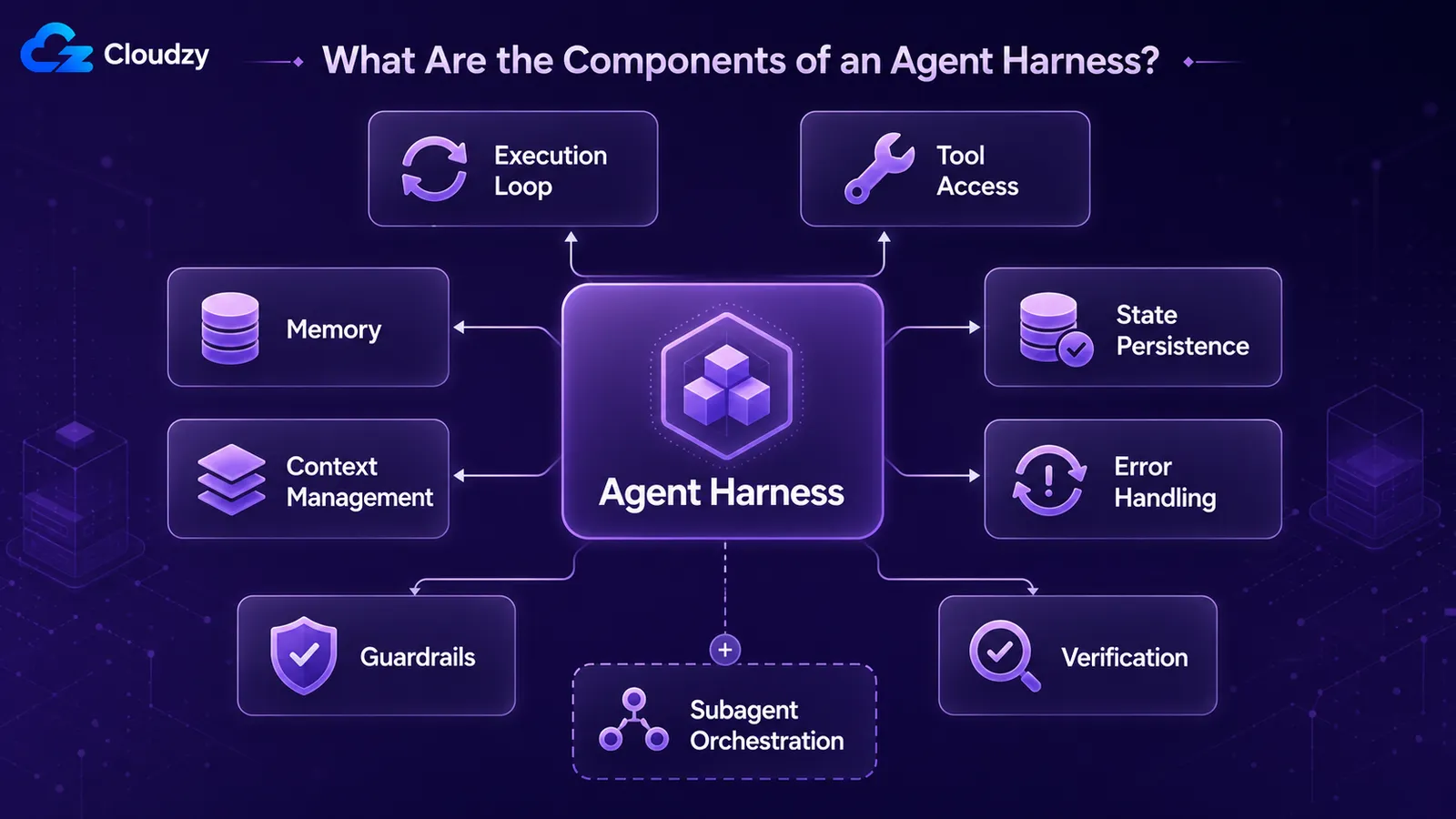
Ogni harness di produzione assembla le stesse parti ricorrenti: un execution loop che guida il modello turno per turno, l'accesso agli strumenti che gli permette di agire, la memoria tra i turni, la gestione del contesto per ciò che vede in questo momento, la persistenza dello stato perché il lavoro sopravviva tra le sessioni, la gestione degli errori per i passaggi falliti e i guardrail che limitano ciò che può fare. I sistemi di produzione aggiungono verification loop e orchestrazione di subagenti.
Un inventario utile, tratto da come i professionisti descrivono i sistemi reali:
- Execution / control loop: ciò che guida l'agente turno per turno. Chiamare il modello, leggere l'output, eseguire qualsiasi tool richiesto, restituire il risultato, ripetere fino alla condizione di stop.
- Accesso ai tool: le funzioni, API, esecuzione di codice e filesystem raggiungibili dal modello.
- Memoria: ciò che l'agente mantiene tra un turno e l'altro e tra sessioni diverse.
- Gestione del contesto: cosa viene caricato nella finestra del modello ad ogni turno e cosa viene compattato quando si riempie.
- Persistenza dello stato / checkpointing: salvare lo stato dell'agente in modo che un'esecuzione interrotta o in pausa possa riprendere.
- Gestione degli errori: tentativi, fallback e recupero quando una chiamata a un tool o al modello fallisce.
- Guardrail: limiti su ciò che l'agente può fare, come gli strumenti consentiti, i limiti di passaggi e la validazione dell'output.
- Cicli di verifica: l'agente (o il harness) controlla il proprio lavoro prima di dichiararlo completato.
- Orchestrazione di subagenti: creare subagenti, delegare loro compiti e raccogliere risultati su attività più grandi.
Non tutti questi sono universali. Il ciclo di esecuzione, gli strumenti, la gestione del contesto e la gestione degli errori compaiono anche in un prototipo del weekend. La persistenza dello stato, la verifica e l'orchestrazione dei subagenti sono il punto in cui prototipi e sistemi di produzione si separano. Un prototipo può ignorarli; un agente di produzione a lungo termine non può. Il documento di Anthropic su agenti a lungo termine è una panoramica delle parti esclusivamente per la produzione: come un agente ricostruisce la propria comprensione da un file di avanzamento dopo il ripristino della sua finestra di contesto, e come i test vengono integrati nel ciclo.
Per chi vuole il collegamento accademico, un recente rassegna delle architetture degli agenti piega la stessa meccanica in una tupla formale più piccola di componenti fondamentali. L'elenco del professionista e l'inquadramento del sondaggio sono due livelli di zoom sulla stessa struttura: il sondaggio comprime, l'inventario sopra espande. Tratta il conteggio da nove a undici come i componenti che la maggior parte dei harness di produzione condivide, non uno standard ratificato; il settore non ha ancora ratificato nulla.
Punto chiave: La maggior parte dei componenti mobili di un agente vive nel harness, non nel modello. Il modello è un componente tra i tanti.
Perché il harness conta più del modello?
Un modello più debole all'interno di un harness ben progettato supera frequentemente un modello più forte in uno mal progettato. Il motivo è meccanico, non magico: l'affidabilità end-to-end di un agente è il prodotto dell'affidabilità di ogni singolo passaggio, e la maggior parte di quei passaggi (selezione degli strumenti, assemblaggio del contesto, recupero degli errori) è compito del harness, non del modello. Migliorarli rende l'intera catena più affidabile, indipendentemente dal modello che si trova all'interno.
L'aritmetica lo rende concreto. Supponiamo che ogni passo in un'attività di dieci passi abbia successo il 99% delle volte. Il successo end-to-end non è il 99%. È 0,99 alla decima potenza, circa il 90%. Portate ogni passo al 99,9% e l'end-to-end sale a circa il 99%. L'affidabilità per passo si accumula, e l'affidabilità per passo è in modo preponderante una proprietà del harness. Ecco perché ottimizzare la gestione degli errori e la gestione del contesto è più redditizio che sostituire con un modello mezzo punto migliore su qualche benchmark.
Ci sono segnali di produzione che puntano nella stessa direzione. MongoDB, citando il caso studio di Vercel, riporta che Vercel ha ridotto la maggior parte degli strumenti del proprio agente e ha visto il suo tasso di successo salire nettamente sullo stesso modello, con un harness più piccolo e più pulito. Leggetelo come evidenza convergente piuttosto che come prova: è un caso di produzione, non un esperimento controllato, ma punta nella stessa direzione dell'aritmetica composta e del lavoro di indagine sopra.
Questa è l'euristica a cui continuo a tornare come ingegnere di piattaforma: il contesto è il collo di bottiglia, non la capacità grezza del modello, e le impalcature costruite per coprire i gap dei modelli attuali tendono a venire inglobate man mano che i modelli migliorano. Costruite le parti durevoli del harness (il loop, lo stato, il ripristino) e lasciate che il modello sottostante migliori secondo il proprio ritmo.
Punto chiave: Quando il tuo agente fallisce, sospetta prima del harness, non del modello. Le probabilità lo confermano.
Qual è la differenza tra un harness, uno scaffold e un framework?
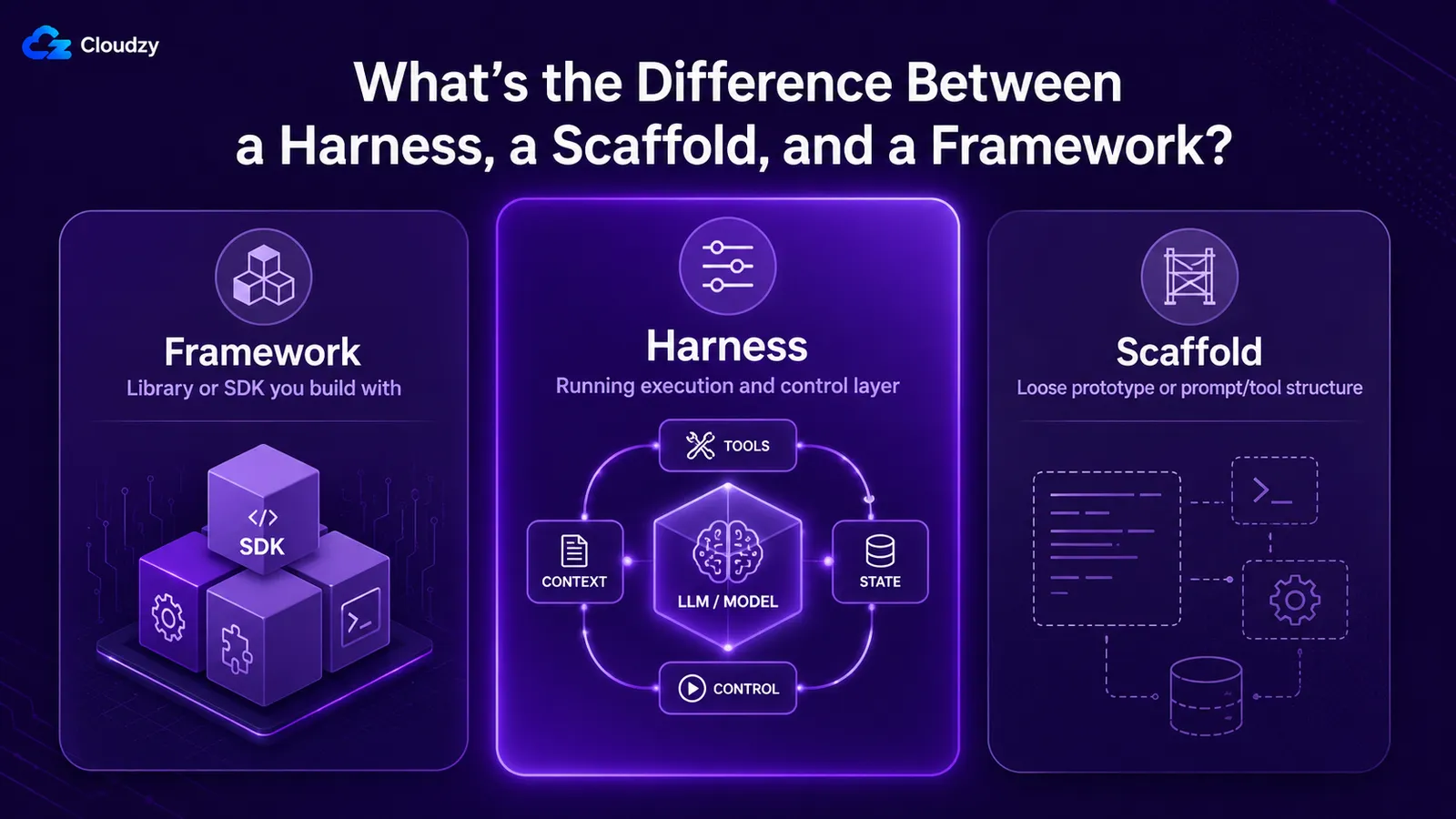
Questi tre vengono usati in modo intercambiabile, e non dovrebbero. Un framework è la libreria o SDK con cui costruisci, come LangGraph o un agents SDK. Un harness è il livello di esecuzione e governance attivo attorno al modello, che un framework aiuta ad assemblare. Un scaffold è il più vago dei tre: a volte quasi sinonimo di harness, a volte la versione prototipo di uno, a volte specificamente il livello di prompt e descrizione degli strumenti.
Il vocabolario è genuinamente incerto, e la cosa più chiara è mappare gli usi piuttosto che legiferarne uno. Quello di HuggingFace Glossario degli agenti lo dice direttamente:
"Molti di questi termini non hanno ancora definizioni universalmente accettate, e framework diversi usano la stessa parola in modo diverso."
— HuggingFace, Glossario degli agenti
| Termine | A cosa si riferisce | Relazione |
|---|---|---|
| Framework | La libreria o SDK con cui costruisci (LangGraph, un SDK per agenti) | Uno strumento per assemblare un harness |
| Harness | Il livello in esecuzione attorno al modello: loop, strumenti, contesto, stato, guardrail | Ciò che distribuisci ed esegui |
| Scaffold | Usato in senso lato: quasi sinonimo di harness, o la versione a livello prototipo / strato di prompt | Si sovrappone a harness; meno preciso |
| Loop | Il ciclo di esecuzione all'interno del harness | Un componente del harness |
La conclusione pratica per ragionare sul proprio sistema: quando qualcuno dice "framework", chiedi se intende la libreria o la cosa in esecuzione. Quando qualcuno dice "scaffold", chiedi se intende l'intero harness o solo il livello prompt-e-strumenti. Il valore qui è la disambiguazione, non una pretesa all'ultima parola.
Come LangGraph implementa il pattern harness?
LangGraph è una popolare implementazione Python open-source del pattern harness. Modella l'esecuzione dell'agente come un grafo orientato di nodi e archi, con stato tipizzato che scorre tra di essi e ogni transizione checkpointabile. Se i componenti astratti sopra sembrano sfuggenti, LangGraph è il posto dove vederli prendere forma concreta in uno strumento reale.
La mappatura è vicina all'uno a uno. I nodi e gli archi sono il ciclo di esecuzione: ogni nodo fa lavoro, ogni arco decide dove va il controllo successivamente. L'oggetto di stato tipizzato passato tra i nodi è il componente context-and-state reso esplicito. Il checkpointing (LangGraph persiste lo stato tramite savers come la sua implementazione basata su Postgres) è il componente di persistenza dello stato. Un limite di passi configurabile è un guardrail di condizione di stop, che impedisce a un agente malfunzionante di ciclare all'infinito. Stessi componenti, nominati e collegati da una libreria specifica.
Se vuoi eseguire un agente LangGraph sul tuo server, tutto il giorno, questa è una domanda di deployment piuttosto che concettuale. Vedi la nostra guida Linux VPS per quel percorso. Qui, LangGraph è solo l'esempio elaborato: prova che "ciclo di esecuzione", "persistenza dello stato" e "guardrail" non sono astrazioni, sono cose che puoi indicare nel codice reale.
Domande frequenti
Cos'è un Agent Harness?
Un agent harness è il software attorno a un language model che lo trasforma in un agente. Gestisce il ciclo di esecuzione, l'accesso agli strumenti, la memoria, il contesto, la persistenza dello stato, la gestione degli errori e i guardrail. Il modello genera testo; il harness decide cosa vede il modello, cosa può fare, quando fermarsi e cosa succede quando qualcosa fallisce.
Un agent harness è lo stesso di un agent framework?
No. Un framework è la libreria o SDK con cui costruisci, come LangGraph o un agents SDK. L'harness è il livello di esecuzione e governance attivo attorno al modello (il loop, gli strumenti, il contesto, lo stato e i guardrail) che un framework ti aiuta ad assemblare. Usi un framework per costruire un harness.
Quali componenti ha ogni agent harness?
La maggior parte degli harness condivide un nucleo ricorrente: un loop di esecuzione, accesso agli strumenti, memoria, gestione del contesto, persistenza dello stato, gestione degli errori e guardrail. Gli harness di produzione aggiungono loop di verifica e orchestrazione di subagent. I prototipi possono saltare le parti solo per la produzione, ma il loop, gli strumenti, la gestione del contesto e la gestione degli errori compaiono quasi ovunque.
Cosa significa "Il LLM è la parte più piccola del tuo sistema agente"?
Significa che la maggior parte del comportamento e dell'affidabilità di un agente proviene dall'harness, non dal modello. L'affidabilità end-to-end è il prodotto del tasso di successo di ogni passaggio, e la maggior parte dei passaggi è lavoro dell'harness. MongoDB, citando il caso studio di Vercel, riporta un salto nel tasso di successo dovuto solo a modifiche all'harness, sullo stesso modello. Questo è la prova che correggere l'harness supera la correzione del modello.
Dove risiede la qualità del tuo agente
L'harness è dove vive la maggior parte della qualità di un agente, e ora hai il vocabolario per individuare i problemi nel tuo sistema. Puoi definire un harness, nominarne i componenti, distinguerlo da un framework e da un scaffold, e ragionare su se un dato fallimento sia un problema del modello o un problema dell'harness.
Quindi la prossima volta che il tuo agente si comporta male, controlla prima il layer harness: il contesto che stai fornendo, gli strumenti che hai esposto, le condizioni di stop che hai impostato, il modo in cui si riprende da un passaggio fallito. Cerca un modello più grande solo dopo che quel layer è verificato. La maggior parte delle volte, non sarà necessario.


