
Il loop ha girato pulito quaranta volte in fase di test. Alla quarantunesima esecuzione, in produzione, ha chiamato lo stesso tool SQL con la stessa query rotta più e più volte finché ha bruciato il budget API della giornata e un avviso di fatturazione ha finalmente svegliato qualcuno. Nessuno aveva scritto un modello difettoso. Nessuno aveva cambiato il prompt. L'agente semplicemente non aveva mai deciso di aver finito.
Questo è lo schema che continuo a vedere nei team che spostano un agente da prototipo a un carico di lavoro 24/7. I loop degli agenti AI spesso falliscono in produzione non perché il modello sia improvvisamente peggiorato, ma perché il layer di esecuzione manca di disciplina nella terminazione, contratti di tool validati, contesto limitato e stato durevole. Un loop di agente è un sistema stocastico che prende una decisione sequenziale dopo l'altra. Senza alcuni guardrail specifici, il fallimento raro diventa inevitabile una volta che lo fai girare abbastanza a lungo. Le piattaforme gestite per agenti (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) incorporano alcuni di questi guardrail; questa guida è per chi ha scelto il self-hosting e gestisce il loop in proprio.
La posta in gioco è concreta: Gartner prevede che oltre il 40% dei progetti di AI agentiva verrà cancellato entro la fine del 2027, citando costi crescenti e valore poco chiaro. Quello che segue sono sei modi specifici in cui i loop si rompono in produzione, il meccanismo alla base di ognuno e il pattern di harness che lo corregge, con i dettagli su LangGraph e n8n e ciò che serve per farlo girare davvero 24/7.
La versione breve
- Loop infiniti: L'agente non decide mai di aver finito. Combina un limite rigido sul numero di step (il
recursion_limitdi LangGraph, default 25) con un sistema di rilevamento del mancato progresso che termina le chiamate ripetute agli stessi tool con gli stessi argomenti. - Overflow del contesto: Il loop riempie la propria finestra di contesto con la cronologia accumulata fino a quando le chiamate vengono troncate o falliscono. Sintetizza la cronologia a intervalli fissi in modo che il contesto attivo rimanga entro i limiti.
- Errori silenti nei tool: Un tool restituisce una stringa vuota, il modello la interpreta come un'operazione valida senza effetti, e l'agente "riesce" a non fare nulla. Valida ogni risultato del tool prima che il modello lo veda.
- Degradazione del ragionamento: La qualità decade man mano che il contesto cresce, anche al di sotto del limite massimo. Comprimi a metà loop, ma proteggi le istruzioni di sicurezza bloccate quando lo fai.
- Perdita di stato al riavvio: Un crash significa ricominciare da capo. Fai il checkpoint su Postgres (
PostgresSaverdi LangGraph), non su SQLite, per l'uso in produzione. - Retry storm: Dieci agenti che ognuno riprova dieci volte colpiscono un servizio inattivo con cento richieste. Aggiungi backoff esponenziale con jitter e un circuit breaker globale.
Cosa non copre questa guida
Si tratta di una guida al harness, focalizzata sull'ingegneria attorno al loop, non sul modello al suo interno. Alcuni argomenti correlati sono deliberatamente esclusi dall'ambito:
- Errori di coordinamento tra più agenti (letture obsolete, stato orfano tra agenti): un problema diverso che merita la sua trattazione.
- Sicurezza degli agenti (prompt injection, avvelenamento dei tool): una categoria di errori separata con il suo modello di minaccia.
- Selezione del modello e fine-tuning. Questa guida parte dal presupposto che tu abbia già scelto un modello e stia debuggando il sistema attorno ad esso.
- Servizi gestiti per agenti, già citati; i pattern qui descritti sono per il percorso self-hosted.
Loop infiniti: quando l'agente non decide mai di aver finito

Un agente entra in loop infinito quando non ha né un limite rigido sul numero di step né un modo per rilevare che ha smesso di fare progressi. La soluzione è in due parti: mantenere un limite rigido come backstop sui costi e aggiungere un rilevamento del mancato progresso che calcola l'hash di ogni chiamata tool-più-argomenti e termina quando vede la stessa chiamata ripetersi. In LangGraph quel limite è il recursion_limit(default 25 step); superarlo fa sollevare un'eccezione al grafo: GraphRecursionError.
La documentazione di LangGraph descrive questo limite come il raggiungimento di "il numero massimo di step prima di raggiungere una condizione di arresto", e questo è il punto da capire bene: il recursion_limit non è una protezione contro i loop. È un backstop che scatta dopo quando il loop ha già sprecato venticinque step e il budget API corrispondente. La logica di terminazione appresa dall'agente stesso dovrebbe fermarlo molto prima, e quella logica può fallire in modo indipendente. Un caso LangGraph segnalato mostra un agente text-to-SQL che va in loop fino a raggiungere il recursion_limit nonostante le chiare condizioni di arresto nel prompt. Continuava a chiamare lo stesso tool di query con lo stesso SQL fallito, e il problema è stato chiuso come "non pianificato". Lo interpreto come un segnale chiaro: non trattare il limite come la tua condizione di arresto. È la tua cintura di sicurezza, non i tuoi freni.
Alzare il limite è semplice; si passa attraverso la config quando si invoca il grafo:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)La parte che ferma davvero un loop bloccato è il rilevamento del progresso. Il meccanismo è semplice: calcola l'hash del nome del tool più i suoi argomenti ad ogni step, tieni una finestra breve degli hash recenti e interrompi quando vedi un duplicato.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Questo intercetta l'agente che è tecnicamente "in esecuzione" (chiama tool, genera token) ma ciclando sulla stessa azione fallita. Il modo di fallire descritto si mappa su quello che la tassonomia MAST (IBM Research e UC Berkeley) chiama Unaware of Termination Conditions (FM-1.5), una delle modalità di errore che la loro analisi associa al fallimento totale del task.
Un limite sugli step ferma i costi fuori controllo. Il rilevamento del mancato progresso ferma il loop che è tecnicamente "in avanzamento" ma si ripete. In produzione servono entrambi.
Overflow della finestra di contesto: quando il loop riempie il proprio contesto di spazzatura
Un loop a lunga esecuzione accumula ogni output dei tool, ogni pensiero intermedio e ogni messaggio che ha prodotto, poi rimette tutto nella finestra di contesto ad ogni turno. Alla fine la finestra si riempie e le chiamate vengono troncate silenziosamente o falliscono del tutto. La soluzione è la sintetizzazione del contesto a intervalli fissi: ogni N step, comprimi la cronologia accumulata in un riassunto progressivo in modo che il contesto attivo rimanga entro i limiti.
Immagina un agente di ricerca in esecuzione da un'ora. Allo step 60 porta con sé il testo completo di ogni pagina recuperata, ogni risultato di ricerca, ogni traccia di ragionamento. Nessuna di quella cronologia grezza lo aiuta allo step 61, eppure tutto conta contro la finestra e il modello sta spendendo budget di attenzione su token che non gli servono più. Quando la finestra si riempie, il provider tronca da un'estremità e l'agente perde silenziosamente l'istruzione ricevuta all'inizio.
Il trigger è una scelta di tuning, e c'è un riferimento utile. Il writeup di Mem0 su un sistema in produzione reale nota che il compressore dell'agente Hermes "scatta al 50% della finestra di contesto del modello per impostazione predefinita", con una rete di sicurezza secondaria all'85% per le sessioni che si gonfiano tra un turno e l'altro. Il cinquanta percento è un punto di partenza sensato: comprimi abbastanza presto da impedire che un singolo output molto grande superi il limite prima della prossima compressione programmata.
Nota: L'overflow e il degrado del ragionamento sono problemi distinti, e la sezione successiva tratta il secondo. L'overflow è un limite netto: i tokens si esauriscono. Il degrado è graduale: il modello peggiora progressivamente. prima di raggiungere la barriera. Devi gestire entrambi e la soglia del trigger indicata sopra protegge dalla barriera rigida.
Il contesto limitato è una responsabilità del harness, non una funzionalità del modello. Sintetizza a intervalli prima che la finestra imponga un troncamento silenzioso.
Errori silenti nelle chiamate ai tool: quando l'agente "riesce" a non fare nulla
Una chiamata a un tool restituisce una stringa vuota o un messaggio soft tipo "nessun risultato trovato", il modello lo interpreta come un risultato valido e l'agente continua come se lo step avesse funzionato, apparendo di avere successo mentre non fa nulla. La soluzione è un gate di validazione su ogni ritorno del tool: controlla lo schema o fai una sanity-check dell'output prima che il modello lo veda, e porta in superficie un errore reale che il loop deve gestire invece di un successo vuoto.
Questo è insidioso perché niente va in crash. Uno sviluppatore che descrive le modalità di fallimento silente negli agenti in produzione lo dice direttamente: i modelli interpretano le stringhe vuote generiche come no-op validi e continuano l'esecuzione senza consapevolezza del fallimento. La query al database che ha restituito zero righe perché la connessione è caduta è identica, per il modello, alla query che legittimamente non ha trovato nulla. Quindi l'agente riporta "nessun record corrispondente" e va avanti, e lo scopri una settimana dopo che un terzo delle sue esecuzioni era silenziosamente rotto.
Il gate di validazione si trova tra il tool e il modello:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelIl punto non sono i controlli esatti; i tuoi dipenderanno da ciò che ogni tool restituisce legittimamente. Il punto è che un valore di ritorno non validato è una decisione che hai affidato a un modello stocastico, e la mossa di default del modello è continuare.
Un ritorno di tool non validato è un fallimento silente in attesa di accadere. Valida l'output, non fidarti della chiamata.
Degradazione del ragionamento su contesti lunghi: quando l'agente peggiora più a lungo funziona
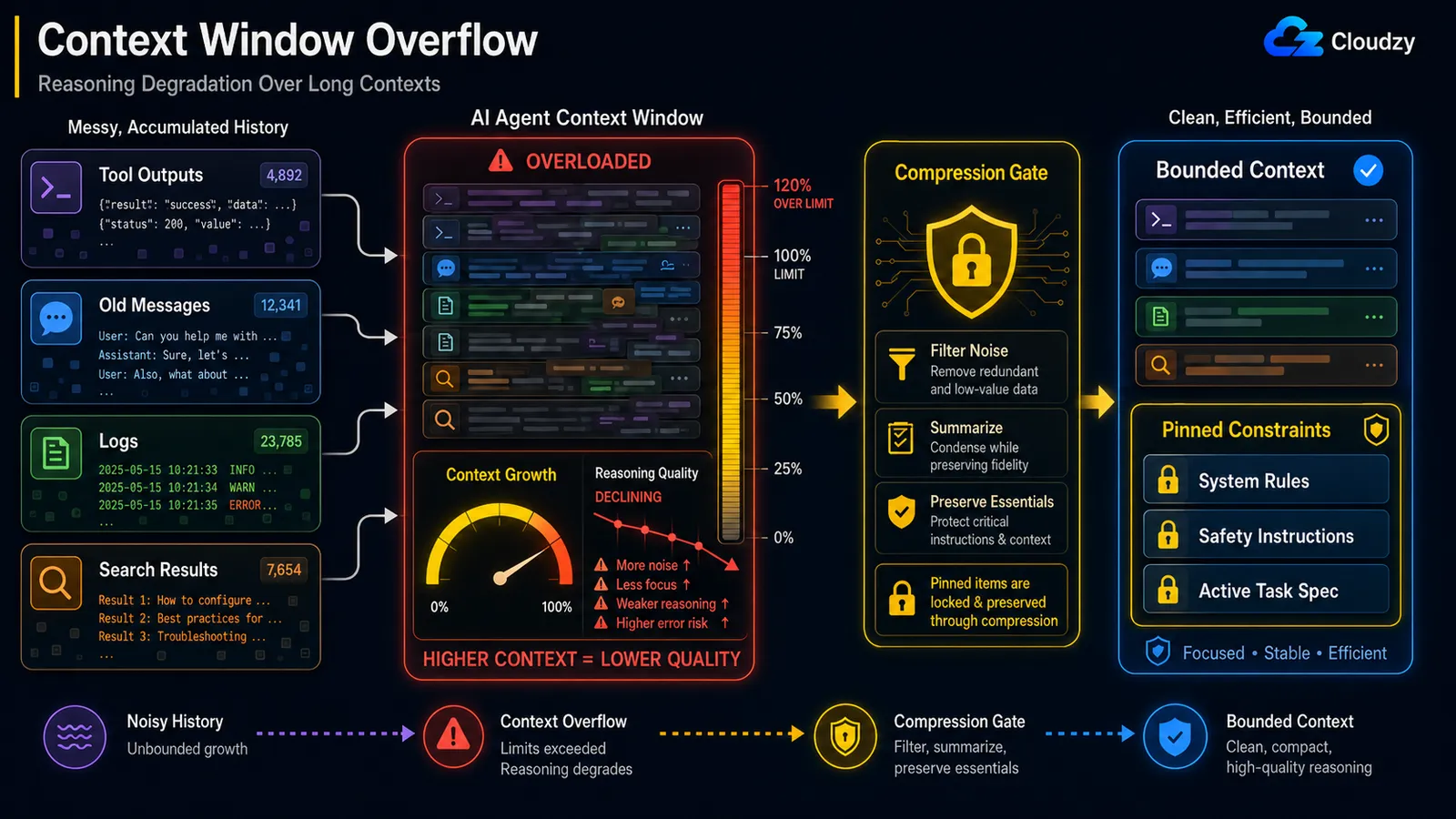
Anche quando si rimane sotto il limite rigido del contesto, la qualità del ragionamento decade man mano che il contesto cresce. Questo è l'effetto "lost in the middle": il modello attende in modo affidabile all'inizio e alla fine di un contesto lungo, ma perde il mezzo. La soluzione è la compressione a metà loop che preserva i vincoli bloccati: comprimi il rumore, proteggi le istruzioni portanti.
Il meccanismo ha un nome. Il blog di engineering di Anthropic lo indica come context rot: "man mano che il numero di token nella finestra di contesto aumenta, la capacità del modello di richiamare accuratamente le informazioni da quel contesto diminuisce." Perché "ogni token attende a ogni altro token," si ottengono n² relazioni a coppie per n token, e l'attenzione del modello si assottiglia più a lungo scorre il contesto.
Quel qualificatore, proteggi le istruzioni portanti, è l'intera posta in gioco, e c'è un incidente documentato che ne mostra il perché. In un caso segnalato, un agente OpenClaw ha cancellato in massa la casella di posta di un utente durante una compressione del contesto, perché l'istruzione di sicurezza che gli era stata fornita ("non agire finché non te lo dico") era stata eliminata dal contesto attivo quando la cronologia è stata compressa. Il vincolo che avrebbe dovuto essere l'ultimo a sparire è stato trattato come cronologia ordinaria e sintetizzato via.
Quindi un approccio naive del tipo "sintetizza tutto ciò che è più vecchio di N turni" è pericoloso. La compressione deve sapere cosa non può mai eliminare:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactQuesto è distinto dal problema di overflow della sezione precedente. L'overflow riguarda l'esaurimento dello spazio; la degradazione riguarda il modello che peggiora mentre c'è ancora spazio. Puoi essere al 60% della tua finestra e ragionare già male.
Nota: Una compressione che elimina un vincolo di sicurezza è una classe di bug diversa da una compressione che perde un risultato di ricerca obsoleto. Tagga i vincoli, la specifica del task e qualsiasi istruzione "non fare X" come bloccati ed escludili completamente dal sintetizzatore.
Una compressione che elimina un'istruzione di sicurezza è peggio di nessuna compressione. Proteggi i vincoli bloccati quando comprimi.
Perdita di stato al riavvio: quando un crash significa ricominciare da zero
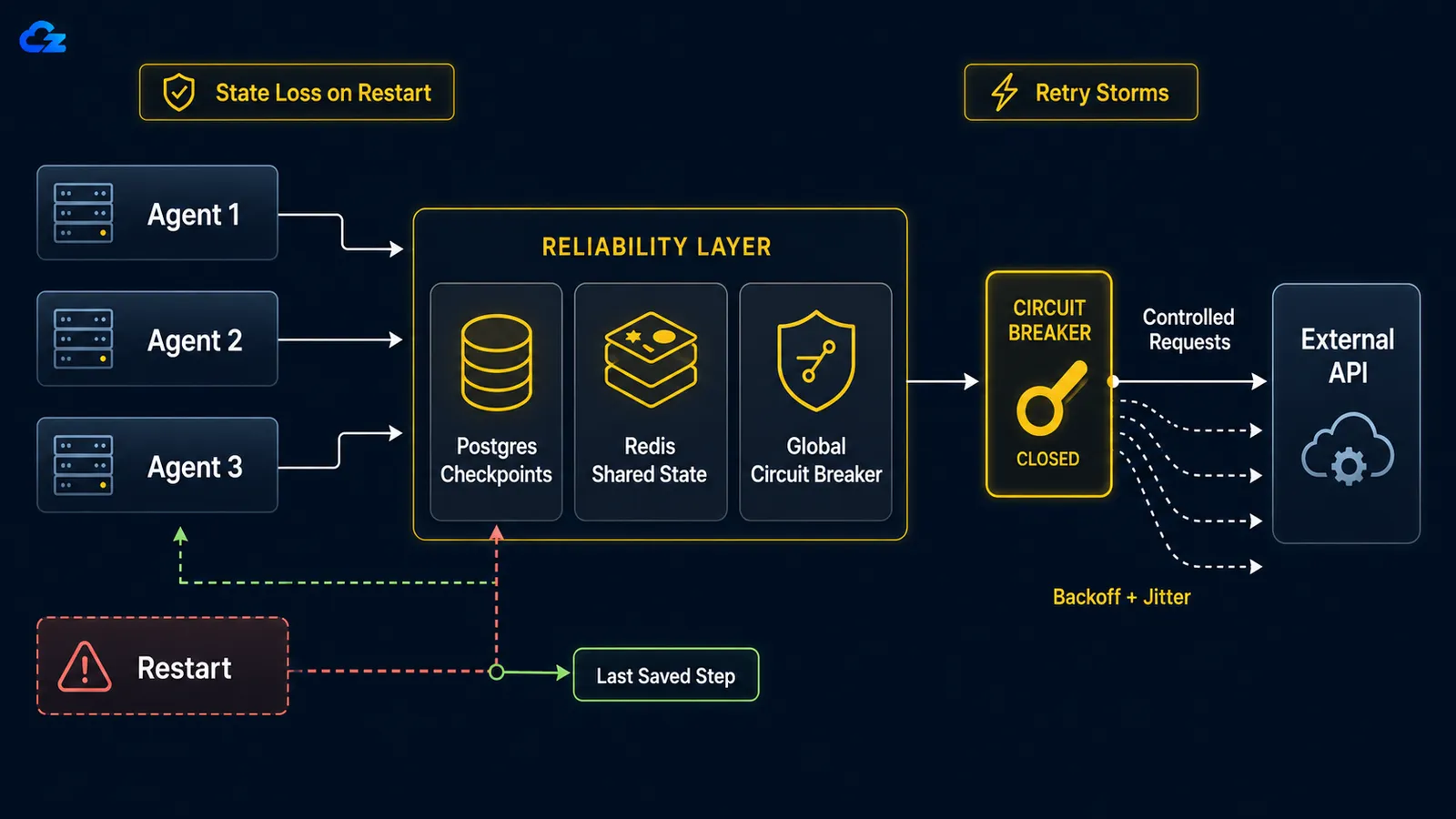
Quando un agente a lunga esecuzione va in crash, che sia per un riavvio, un kill OOM o una connessione di rete interrotta, non esiste ripresa dal checkpoint per impostazione predefinita. Il loop riparte da zero: ripete il lavoro già completato e, peggio ancora, può rieseguire azioni già intraprese, come inviare la stessa email due volte o ripetere una chiamata API a pagamento. La soluzione è il checkpointing: persistere lo stato del loop dopo ogni step in modo che un riavvio si reidrati da dove si era fermato invece che da zero.
In LangGraph la scelta del backend di checkpoint è la scelta tra sviluppo e produzione. La documentazione sulla persistenza di LangGraph descrive SqliteSaver come "ideale per la sperimentazione e i flussi di lavoro locali" e PostgresSaver come "ideale per l'uso in produzione", ed è quest'ultimo quello su cui LangSmith stesso gira. I due sono deliberatamente paralleli nel codice, il che rende facile vedere il contrasto:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverDue dettagli che fanno inciampare le persone. Primo, i pacchetti di checkpoint si installano separatamente dal core LangGraph (langgraph-checkpoint-sqlite e i piani langgraph-checkpoint-postgres sono dipendenze proprie), quindi un'installazione fresca non avrà il saver Postgres finché non lo aggiungi. Secondo, ogni operazione di checkpoint ha bisogno di un thread_id nella config. Quell'ID è ciò che lega una data esecuzione al suo stato salvato, e un riavvio senza il giusto thread_id non reidrata nulla.
Consiglio: I pacchetti di checkpoint di LangGraph sono installazioni separate.
langgraph-checkpoint-postgresnon viene incluso dal pacchetto baselanggraphquindi aggiungilo nelle dipendenze di produzione prima di scoprirlo nel modo difficile durante un incidente.
n8n ha la stessa divisione sviluppo-versus-produzione, solo con nomi diversi. La sua opzione di memoria integrata si chiama anche Simple Memory (o Buffer Window Memory), e il percorso produzione è il nodo Postgres Chat Memory per lo stato che deve sopravvivere a un riavvio. La memoria integrata tiene la conversazione nel processo in esecuzione, il che va bene per i test ed è un rischio per un carico di lavoro 24/7. I professionisti che gestiscono agenti n8n in produzione riferiscono di dover migrare a uno store con backend Postgres dopo che la memoria in-process è cresciuta fino ad abbattere l'istanza. Se sei su n8n e il tuo agente deve ricordare qualcosa tra un riavvio e l'altro, collegalo subito a Postgres Chat Memory.
Il checkpointing su SQLite è una comodità per lo sviluppo. Sopravvivere a un riavvio in produzione significa Postgres (LangGraph) o uno store con backend Postgres (n8n).
Retry storm: quando i tuoi stessi agenti mandano in DDoS un servizio inattivo
Quando un servizio downstream va giù, i retry naive per-esecuzione trasformano il tuo parco agenti in un denial-of-service auto-inflitto. La soluzione ha due metà: backoff esponenziale con jitter su ogni agente per distribuire i retry nel tempo, e un circuit breaker globale che scatta dopo una soglia di errori condivisa e impedisce all'intero gruppo di martellare un servizio chiaramente inattivo.
La matematica è spietata. Come illustra un writeup sui pattern di retry , con dieci agenti paralleli che riprovano ognuno dieci volte, invii cento richieste a un servizio già a terra, perché il backoff di ogni agente è per-esecuzione, non globale. Il backoff per-agente da solo non risolve questo. Dieci agenti che arretrano educatamente arretrano comunque all'unisono se sono partiti tutti nello stesso momento, quindi riprovano in ondate sincronizzate. Il jitter rompe la sincronizzazione randomizzando l'attesa di ogni agente; il circuit breaker rompe il gruppo condividendo un unico pezzo di stato di errore tra tutti.
La metà del backoff è un problema risolto in Python; la libreria tenacity gestisce l'esponenziale-con-jitter in modo pulito:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Il circuit breaker è la metà che deve essere globale: condivisa tra ogni agente, non reistanziata per ogni esecuzione. Quando i fallimenti superano una soglia, si apre, ogni agente fallisce velocemente invece di chiamare il servizio, e dopo un cooldown lascia passare una singola sonda per testare se il servizio è tornato. Un breaker che vive all'interno del processo di ogni agente non protegge nulla, perché nulla è condiviso; il servizio inattivo riceve comunque le cento richieste complete.
Il backoff per-esecuzione lascia comunque dieci agenti martellare un servizio inattivo all'unisono. Il circuit breaker deve essere globale per fermare il gruppo.
I sei errori in sintesi
Prima della parte sull'infrastruttura, ecco l'intero catalogo in un unico posto: il fallimento, il meccanismo che lo causa, il fix del harness e dove si trova il parametro rilevante in ogni framework.
| Modalità di errore | Meccanismo | Fix del harness | Parametro del framework |
|---|---|---|---|
| Loop infinito | Nessun limite di step o controllo del progresso | Limite rigido + rilevamento del mancato progresso | LangGraph recursion_limit (25) / n8n Max Iterations |
| Overflow del contesto | La cronologia cresce fino a riempire la finestra | Sintetizzazione a intervalli | A livello di app (comprimi a ~50% della finestra) |
| Errore silente del tool | Ritorni vuoti/soft letti come no-op validi | Gate di validazione su ogni risultato del tool | Wrapper tool a livello di app |
| Degradazione del ragionamento | L'attenzione decade man mano che il contesto cresce ("context rot") | Compressione a metà loop che protegge i vincoli bloccati | A livello di app, constraint-aware |
| Perdita di stato al riavvio | Nessun checkpoint; il loop riparte da zero | Checkpointing persistente | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry storm | I retry per-esecuzione si propagano su un servizio inattivo | Backoff + jitter + circuit breaker globale | tenacity + stato del breaker condiviso |
Una nota per i lettori su CrewAI, AutoGen, Dify o un loop Python scritto a mano: i parametri del framework cambiano, ma i sei pattern no. Deduplicazione, sintetizzazione a intervalli, validazione dello schema, compressione consapevole dei vincoli, checkpointing e un circuit breaker globale sono concetti indipendenti dal framework. I dettagli su LangGraph e n8n qui sono riferimenti concreti, non il limite di applicabilità dei pattern.
Dimensionare un deployment di agenti in produzione
Ogni pattern sopra presuppone che tu controlli il process manager, il database e il comportamento al riavvio. Il checkpointing non serve a nulla se un loop crashato non viene mai riavviato, e un circuit breaker globale ha bisogno di un posto dove tenere il suo stato condiviso. Quel controllo è esattamente ciò che il self-hosting ti dà e un servizio gestito non ti dà, quindi l'ultima decisione è dimensionare il server che lo farà girare 24/7.
Per la maggior parte dei deployment con un singolo agente (un agente, chiamate LLM verso un'API esterna, checkpointing Postgres di base) un'istanza piccola è sufficiente: circa 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Il compute pesante vive sul lato del provider del modello; il tuo server orchestra, fa checkpoint e mantiene lo stato, non esegue inference. Passa a circa 4 GB RAM, 2 vCPU, and 120 GB NVMe quando l'agente è stateful e multi-step con checkpointing Postgres più Redis per la reidratazione della sessione, o quando stai eseguendo workflow concorrenti che condividono l'host.
Il motivo per cui si vuole un VPS self-managed piuttosto che una piattaforma vincolata è lo stesso per cui i fix funzionano: richiedono il root. Il tuo Postgres per il checkpointing, il tuo Redis per lo stato della sessione e un vero process manager come systemd or pm2, in modo che quando un loop muore, il supervisore lo riavvii e si reidrati dall'ultimo checkpoint invece di ricominciare il lavoro da capo. L'intera storia del recovery dipende dal possedere il ciclo di vita del processo.
Poiché gestiamo n8n come app one-click nel nostro marketplace, quella parte del setup è il percorso più breve dal nostro lato: puoi distribuire n8n su un VPS Cloudzy con la configurazione con backend Postgres che il percorso produzione richiede, su un'istanza dove hai accesso root per aggiungere il tuo Redis e la supervisione dei processi. È lo stesso footprint self-hosted descritto sopra, dove possiedi il database e il comportamento al riavvio, il che fa funzionare davvero il checkpointing e il recovery automatico.
I pattern del harness sono affidabili solo quanto il server su cui girano. Il checkpointing non serve a nulla se il processo non viene mai riavviato.
Domande frequenti
Come impedisco al mio agente LangGraph di ciclare all'infinito?
Usa due meccanismi insieme. Imposta recursion_limit come limite rigido sul numero di step (il default è 25) in modo che un loop fuori controllo non possa bruciare budget illimitato, e aggiungi un rilevamento del mancato progresso che calcola l'hash di ogni chiamata tool-più-argomenti e termina quando la stessa chiamata si ripete in una finestra recente. Il limite da solo è un backstop che scatta dopo che lo spreco è già avvenuto, non una vera protezione contro i loop. Il rilevamento del progresso è ciò che ferma davvero un loop bloccato.
Qual è il recursion_limit giusto per LangGraph in produzione?
Non esiste un numero universale. Dimensionalo al numero massimo di step legittimi che il tuo agente dovrebbe mai aver bisogno, più un margine, e trattalo strettamente come un backstop sui costi. Alzare il limite non fa convergere un agente in loop. Se il tuo agente raggiunge un limite alto, il fix è il rilevamento del progresso, non un limite più alto.
Perché il mio agente AI su n8n continua a raggiungere il limite Max Iterations?
Raggiungere il limite Max Iterations significa che l'agente non converge: sta impiegando più step del limite consentito senza raggiungere un arresto. Alza il limite solo se il task ha legittimamente bisogno di più step; altrimenti trattalo come un segnale che l'agente è bloccato. Attenzione a una trappola specifica: la issue #22771 di GitHub riporta che quando il limite di iterazioni viene raggiunto con "On Error: Continue" impostato, l'esecuzione può andare all'output Success invece che all'output Error, così un'esecuzione bloccata e fallita può sembrare un successo nel tuo workflow.
Come persisto lo stato dell'agente tra i riavvii?
In LangGraph, usa il checkpointing PostgresSaver invece di SqliteSaver, che è pensato per lo sviluppo locale. In n8n, usa il nodo Postgres Chat Memory invece della memoria integrata in-process. Entrambi richiedono un database persistente, e in LangGraph ogni operazione di checkpoint ha bisogno di un thread_id che lega una data esecuzione al suo stato salvato.
Cosa causa la degradazione del ragionamento nelle esecuzioni lunghe degli agenti?
La qualità del ragionamento cala man mano che il contesto cresce, anche prima di raggiungere il limite massimo di token. Questo è l'effetto "lost in the middle": il modello attende all'inizio e alla fine di un contesto lungo ma perde il mezzo. Il blog di engineering di Anthropic indica il meccanismo sottostante come "context rot": poiché ogni token attende a ogni altro token, si ottengono n² relazioni a coppie e l'attenzione del modello si assottiglia man mano che il contesto si allunga. La soluzione è la compressione a metà loop che sintetizza la cronologia obsoleta mantenendo intatti i vincoli bloccati e le istruzioni di sicurezza.


