
Một trong những yếu tố quan trọng nhất, nếu không phải là quan trọng nhất, của machine learning là đạt được những dự đoán chính xác và đáng tin cậy. Một cách tiếp cận sáng tạo cho mục tiêu này đã trở nên nổi bật là Bootstrap Aggregating, thường được gọi là bagging trong machine learning. Bài viết này sẽ thảo luận về bagging trong machine learning, so sánh bagging và boosting trong machine learning, cung cấp ví dụ về classifier bagging, hướng dẫn cách bagging hoạt động và khám phá những ưu điểm và nhược điểm của bagging trong machine learning.
Bagging trong Machine Learning là gì?
Đây là hai hình ảnh có liên quan duy nhất được sử dụng trong các bài viết phổ biến, có thể sử dụng một hoặc cả hai (một ở đây và hình khác ở nơi khác) nếu chúng tôi yêu cầu Design tạo phiên bản Cloudzy của chúng.
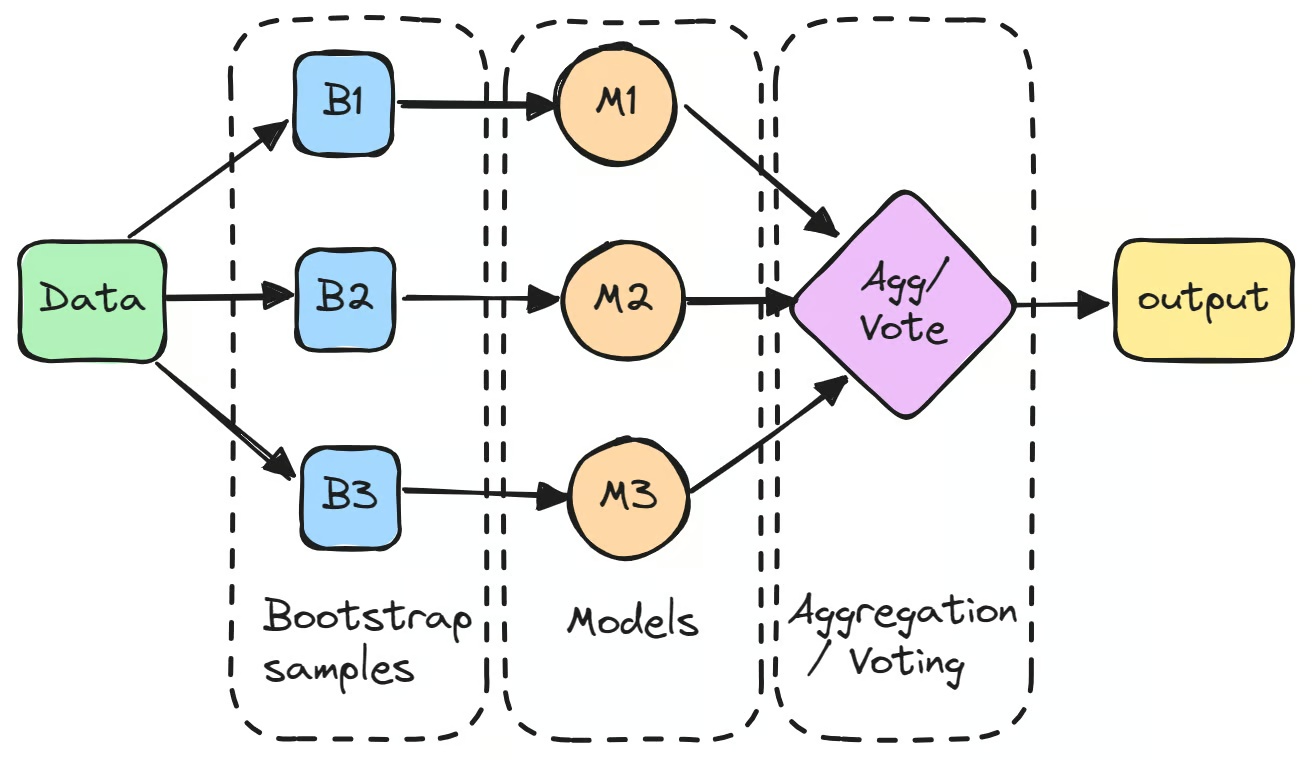
Bagging là gì?
Hãy tưởng tượng bạn đang cố gắng đoán trọng lượng của một vật bằng cách yêu cầu nhiều người ước tính. Riêng lẻ, những ước tính của họ có thể khác nhau rất lớn, nhưng bằng cách lấy trung bình tất cả các ước tính, bạn có thể đi đến một con số đáng tin cậy hơn. Đó là bản chất của bagging: kết hợp các kết quả từ nhiều mô hình để tạo ra dự đoán chính xác và ổn định hơn.
Quá trình bắt đầu bằng cách tạo nhiều tập con của tập dữ liệu gốc thông qua bootstrapping, đó là lấy mẫu ngẫu nhiên có hoàn lại. Mỗi tập con được dùng để huấn luyện một mô hình riêng biệt một cách độc lập.
Các mô hình riêng lẻ này, thường được gọi là "weak learners", có thể không hoạt động tốt lắm khi đứng một mình do phương sai cao. Tuy nhiên, khi những dự đoán của chúng được tổng hợp, thường là bằng cách lấy trung bình cho các bài toán hồi quy hoặc bình chọn theo đa số cho các bài toán phân loại, kết quả kết hợp thường vượt quá hiệu suất của bất kỳ mô hình nào.
Một ví dụ nổi tiếng về bagging classifier là thuật toán Random Forest, thuật toán này xây dựng một tập hợp các cây quyết định để cải thiện hiệu suất dự đoán. Điều đó nói lên, bagging không nên nhầm lẫn với boosting trong machine learning, boosting sử dụng một cách tiếp cận khác bằng cách huấn luyện các mô hình theo trình tự để giảm thiên kiến, còn bagging hoạt động bằng cách huấn luyện các mô hình song song để giảm phương sai.
Cả bagging và boosting trong machine learning đều nhằm cải thiện hiệu suất mô hình, nhưng chúng nhắm vào các khía cạnh khác nhau của hành vi mô hình.
Tại sao Bagging hữu ích?
Một trong những ưu điểm chính của bagging trong machine learning là khả năng giảm phương sai, giúp các mô hình khái quát hóa tốt hơn đối với dữ liệu chưa thấy. Bagging đặc biệt hữu ích khi xử lý các thuật toán nhạy cảm với những biến động trong dữ liệu huấn luyện, chẳng hạn như cây quyết định.
Bằng cách ngăn chặn quá khớp, nó đảm bảo một mô hình ổn định và đáng tin cậy hơn. Khi so sánh bagging và boosting trong machine learning, bagging tập trung vào giảm phương sai bằng cách huấn luyện nhiều mô hình song song, còn boosting nhằm mục đích giảm thiên kiến bằng cách huấn luyện các mô hình theo trình tự.
Một ví dụ về bagging trong machine learning có thể thấy trong dự đoán rủi ro tài chính, nơi nhiều cây quyết định được huấn luyện trên các tập con khác nhau của dữ liệu thị trường lịch sử. Bằng cách tổng hợp những dự đoán của chúng, bagging tạo ra một mô hình dự báo mạnh mẽ hơn, giảm tác động của những lỗi từ các mô hình riêng lẻ.
Về bản chất, bagging trong machine learning tận dụng trí tuệ tập thể của nhiều mô hình để cung cấp những dự đoán chính xác và đáng tin cậy hơn so với những dự đoán có được từ các mô hình riêng lẻ.
Cách Bagging Trong Machine Learning Hoạt động: Từng Bước
Để hiểu đầy đủ cách bagging nâng cao hiệu suất mô hình, hãy chia quá trình thành từng bước.
Lấy Nhiều Bootstrap Sample từ Tập Dữ liệu
Bước đầu tiên trong bagging trong machine learning là tạo nhiều tập con mới của tập dữ liệu gốc bằng cách sử dụng bootstrapping. Kỹ thuật này liên quan đến việc lấy mẫu dữ liệu một cách ngẫu nhiên có hoàn lại, vì vậy một số điểm dữ liệu có thể xuất hiện nhiều lần trong cùng một tập con, trong khi những điểm khác có thể không xuất hiện chút nào. Quá trình này được thực hiện để đảm bảo rằng mỗi mô hình được huấn luyện trên một phiên bản dữ liệu hơi khác nhau.
Huấn luyện một Mô hình Riêng biệt trên Mỗi Sample
Mỗi bootstrap sample sau đó được sử dụng để huấn luyện một mô hình riêng biệt, thường cùng loại, giống như cây quyết định. Những mô hình này, thường được gọi là "base learners" hoặc "weak learners", được huấn luyện độc lập trên các tập con tương ứng của chúng. Một ví dụ về bagging classifier là cây quyết định được sử dụng trong thuật toán Random Forest, cây này tạo thành nền tảng của nhiều mô hình dựa trên bagging. Mặc dù mỗi mô hình riêng lẻ có thể không hoạt động tốt khi đứng một mình, chúng mỗi mô hình đóng góp những hiểu biết độc đáo dựa trên dữ liệu huấn luyện cụ thể của chúng.
Tổng hợp Các Dự đoán
Sau khi huấn luyện các mô hình, những dự đoán của chúng được tổng hợp để tạo thành kết quả cuối cùng.
- Đối với các bài toán hồi quy, các dự đoán được lấy trung bình, giảm phương sai của mô hình.
- Đối với các bài toán phân loại, dự đoán cuối cùng được xác định thông qua bình chọn theo đa số, nơi lớp được dự đoán bởi hầu hết các mô hình được chọn. Phương pháp này cung cấp một dự đoán ổn định hơn so với kết quả của một mô hình đơn.
Dự Đoán Cuối Cùng
Bằng cách kết hợp những dự đoán từ nhiều mô hình, bagging giảm tác động của những lỗi từ bất kỳ mô hình nào, cải thiện độ chính xác chung. Quá trình tổng hợp này là thứ khiến bagging trở thành một kỹ thuật mạnh mẽ, đặc biệt là trong các bài toán machine learning nơi các mô hình phương sai cao như cây quyết định được sử dụng. Nó có hiệu quả làm trơn các sự không nhất quán trong các dự đoán của mô hình riêng lẻ, tạo ra một mô hình cuối cùng mạnh mẽ hơn.
Mặc dù bagging hiệu quả trong việc ổn định các dự đoán, có một số điều cần lưu ý bao gồm rủi ro quá khớp nếu các mô hình cơ sở quá phức tạp, bất chấp mục đích chung của bagging là giảm nó.
Nó cũng tốn kém tính toán, vì vậy việc điều chỉnh số lượng base learners hoặc xem xét các phương pháp ensemble hiệu quả hơn có thể giúp, và lựa chọn GPU phù hợp cho ML và DL luôn quan trọng.
Hãy chắc chắn có sự đa dạng mô hình giữa các base learners để có kết quả tốt hơn, và nếu bạn đang làm việc với dữ liệu không cân bằng, các kỹ thuật như SMOTE có thể hữu ích trước khi áp dụng bagging để tránh hiệu suất kém trên các lớp thiểu số.
Ứng dụng của Bagging
Bây giờ chúng ta đã hiểu cách bagging hoạt động, hãy xem nó được ứng dụng thực tế ở đâu. Bagging đã được áp dụng rộng rãi trong nhiều lĩnh vực, giúp cải thiện độ chính xác và tính ổn định của dự đoán trong các tình huống phức tạp. Cùng tìm hiểu một số ứng dụng có tác động nhất:
- Phân loại và Hồi quy: Bagging được sử dụng rộng rãi để nâng cao hiệu suất của các bộ phân loại và bộ hồi quy bằng cách giảm phương sai và ngăn chặn overfitting. Chẳng hạn, Random Forests sử dụng bagging và rất hiệu quả trong các tác vụ như phân loại hình ảnh và mô hình dự đoán.
- Phát Hiện Bất Thường: Trong các lĩnh vực như phát hiện gian lận và phát hiện xâm nhập mạng, các thuật toán bagging mang lại hiệu suất vượt trội bằng cách xác định chính xác các ngoại lệ và bất thường trong dữ liệu.
- Đánh giá Rủi ro Tài chính: Các kỹ thuật bagging được sử dụng trong ngân hàng để cải thiện các mô hình tính điểm tín dụng, nâng cao độ chính xác của quy trình phê duyệt khoản vay và đánh giá rủi ro tài chính.
- Chẩn đoán Y tế: Trong y tế, bagging đã được áp dụng để phát hiện các rối loạn nhận thức thần kinh như bệnh Alzheimer bằng cách phân tích dữ liệu MRI, hỗ trợ chẩn đoán sớm và lập kế hoạch điều trị.
- Xử lý Ngôn ngữ Tự nhiên (NLP): Bagging góp phần vào các tác vụ như phân loại văn bản và phân tích cảm xúc bằng cách tập hợp dự đoán từ nhiều mô hình, dẫn đến hiểu ngôn ngữ mạnh mẽ hơn.
Ưu điểm và Nhược điểm của Bagging
Như bất kỳ kỹ thuật học máy nào, bagging cũng có những ưu điểm và nhược điểm riêng. Hiểu rõ những điểm này sẽ giúp bạn quyết định khi nào và cách sử dụng bagging trong các mô hình của mình.
Ưu điểm của Bagging:
- Giảm Phương sai và Overfitting: Một trong những ưu điểm quan trọng nhất của bagging trong học máy là khả năng giảm phương sai, giúp ngăn chặn overfitting. Bằng cách huấn luyện nhiều mô hình trên các tập con khác nhau của dữ liệu, bagging đảm bảo rằng mô hình không trở nên quá nhạy cảm với những biến động trong dữ liệu huấn luyện, dẫn đến một mô hình tổng quát hóa tốt hơn và ổn định hơn.
- Hoạt động tốt với Mô hình Phương sai cao: Bagging đặc biệt hiệu quả khi được sử dụng với các mô hình phương sai cao như cây quyết định. Những mô hình này có xu hướng overfitting dữ liệu và có phương sai cao, nhưng bagging giảm thiểu điều này bằng cách lấy trung bình hoặc bỏ phiếu trên nhiều mô hình. Điều này giúp làm cho dự đoán đáng tin cậy hơn và ít bị ảnh hưởng bởi nhiễu trong dữ liệu.
- Cải thiện Tính ổn định và Hiệu suất Mô hình: Bằng cách kết hợp nhiều mô hình được huấn luyện trên các tập con khác nhau của dữ liệu, bagging thường dẫn đến hiệu suất tổng thể tốt hơn. Nó giúp cải thiện độ chính xác dự đoán đồng thời giảm độ nhạy cảm của mô hình với những thay đổi nhỏ trong tập dữ liệu, cuối cùng làm cho mô hình đáng tin cậy hơn.
Nhược điểm của Bagging:
- Tăng Chi phí Tính toán: Vì bagging yêu cầu huấn luyện nhiều mô hình, nên nó tự nhiên làm tăng chi phí tính toán. Huấn luyện và tổng hợp dự đoán từ nhiều mô hình có thể tốn thời gian, đặc biệt khi sử dụng các tập dữ liệu lớn hoặc các mô hình phức tạp như cây quyết định.
- Không hiệu quả đối với Mô hình Phương sai thấp: Mặc dù bagging rất hiệu quả đối với các mô hình phương sai cao, nó không mang lại nhiều lợi ích khi được áp dụng cho các mô hình phương sai thấp như hồi quy tuyến tính. Trong những trường hợp này, các mô hình riêng lẻ đã có tỷ lệ lỗi thấp, vì vậy tổng hợp dự đoán chỉ có ít tác dụng trong việc cải thiện kết quả.
- Mất Khả Năng Diễn Giải Với sự kết hợp của nhiều mô hình, bagging có thể giảm khả năng diễn giải của mô hình cuối cùng. Chẳng hạn, trong Random Forest, quá trình ra quyết định dựa trên nhiều cây quyết định, làm cho việc theo dõi lý do đằng sau một dự đoán cụ thể trở nên khó khăn hơn.
Khi nào tôi nên sử dụng Bagging?
Biết khi nào áp dụng bagging trong các dự án machine learning là chìa khóa để đạt kết quả tối ưu. Kỹ thuật này hoạt động tốt trong những tình huống cụ thể, nhưng không phải lúc nào cũng là lựa chọn tốt nhất cho mọi bài toán.
Khi Model Của Bạn Dễ Bị Overfitting
Một trong những trường hợp sử dụng chính của bagging là khi model của bạn dễ bị overfitting, đặc biệt với các model có phương sai cao như decision trees. Những model này có thể hoạt động tốt trên dữ liệu huấn luyện nhưng thường không khái quát hóa tốt cho dữ liệu chưa từng thấy vì chúng quá phù hợp với các mô hình cụ thể của tập huấn luyện.
Bagging giúp chống lại điều này bằng cách huấn luyện nhiều model trên các tập dữ liệu khác nhau và lấy trung bình hoặc bình chọn để tạo ra dự đoán ổn định hơn. Điều này giảm khả năng overfitting, giúp model xử lý tốt hơn dữ liệu mới chưa từng thấy.
Khi Bạn Muốn Cải Thiện Tính Ổn Định và Độ Chính Xác
Nếu bạn muốn cải thiện tính ổn định và độ chính xác của model mà không ảnh hưởng quá nhiều đến khả năng diễn giải, bagging là lựa chọn tuyệt vời. Việc tổng hợp dự đoán từ nhiều model làm cho kết quả cuối cùng mạnh mẽ hơn, điều này đặc biệt hữu ích trong các nhiệm vụ liên quan đến dữ liệu nhiễu.
Cho dù bạn đang giải quyết bài toán phân loại hay hồi quy, bagging có thể giúp tạo ra kết quả nhất quán hơn, nâng cao độ chính xác trong khi vẫn duy trì hiệu quả.
Khi Bạn Có Đủ Tài Nguyên Tính Toán
Một yếu tố quan trọng khác khi quyết định có sử dụng bagging hay không là tính khả dụng của tài nguyên tính toán. Vì bagging yêu cầu huấn luyện nhiều model cùng lúc, chi phí tính toán có thể trở nên đáng kể, đặc biệt với các tập dữ liệu lớn hoặc model phức tạp.
Nếu bạn có quyền truy cập vào công suất tính toán cần thiết, lợi ích của bagging sẽ vượt trội hơn chi phí. Tuy nhiên, nếu tài nguyên bị hạn chế, bạn có thể muốn xem xét các kỹ thuật thay thế hoặc giới hạn số lượng model trong ensemble của bạn.
Khi Bạn Đang Làm Việc Với Model Có Phương Sai Cao
Bagging đặc biệt hữu ích khi làm việc với các model có phương sai cao và nhạy cảm với những biến động trong dữ liệu huấn luyện. Decision trees, chẳng hạn, thường được sử dụng với bagging dưới dạng Random Forests vì hiệu suất của chúng có xu hướng thay đổi rất lớn dựa trên dữ liệu huấn luyện.
Bằng cách huấn luyện nhiều model trên các tập con dữ liệu khác nhau và kết hợp dự đoán của chúng, bagging làm mịn phương sai, dẫn đến một model đáng tin cậy hơn.
Khi Bạn Cần Một Classifier Mạnh Mẽ
Nếu bạn đang làm việc trên bài toán phân loại và cần một classifier mạnh mẽ, bagging có thể cải thiện đáng kể tính ổn định của dự đoán của bạn. Chẳng hạn, Random Forest, là một ví dụ về classifier sử dụng bagging, có thể cung cấp dự đoán chính xác hơn bằng cách tổng hợp kết quả từ nhiều decision trees riêng lẻ.
Phương pháp này hoạt động tốt khi các model riêng lẻ có thể yếu, nhưng sức mạnh kết hợp của chúng tạo ra một model tổng thể mạnh mẽ.
Ngoài ra, nếu bạn đang tìm kiếm nền tảng phù hợp để triển khai các kỹ thuật bagging một cách hiệu quả, các công cụ như Databricks và Snowflake cung cấp một nền tảng phân tích thống nhất có thể rất hữu ích để quản lý các tập dữ liệu lớn và chạy các phương pháp ensemble như bagging.
Nếu bạn đang tìm kiếm một cách tiếp cận ít kỹ thuật hơn đối với machine learning, công cụ AI không cần mã cũng có thể là một tùy chọn. Mặc dù chúng không tập trung trực tiếp vào các kỹ thuật nâng cao như bagging, nhiều nền tảng không cần mã hóa cho phép người dùng thử nghiệm các phương pháp học ensemble, bao gồm bagging, mà không cần kỹ năng mã hóa mở rộng.
Điều này cho phép bạn áp dụng các kỹ thuật tinh vi hơn và vẫn đạt được dự đoán chính xác trong khi tập trung vào hiệu suất model thay vì code bên dưới.
Lời kết
Bagging trong machine learning là một kỹ thuật mạnh mẽ giúp nâng cao hiệu suất model bằng cách giảm phương sai và cải thiện tính ổn định. Bằng cách tổng hợp dự đoán của nhiều model được huấn luyện trên các tập con dữ liệu khác nhau, bagging giúp tạo ra kết quả chính xác và đáng tin cậy hơn. Nó đặc biệt hiệu quả đối với các model có phương sai cao như decision trees, nơi nó giúp ngăn chặn overfitting và đảm bảo model khái quát hóa tốt hơn cho dữ liệu chưa từng thấy.
Mặc dù bagging có những lợi thế đáng kể, chẳng hạn như giảm overfitting và cải thiện độ chính xác, nhưng nó cũng có một số đánh đổi. Nó làm tăng chi phí tính toán do huấn luyện nhiều model và có thể giảm khả năng diễn giải. Bất chấp những nhược điểm này, khả năng nâng cao hiệu suất của nó khiến nó trở thành một kỹ thuật giá trị trong ensemble learning, cùng với các phương pháp khác như boosting và stacking.
Bạn đã từng sử dụng bagging trong các dự án machine learning chưa? Hãy chia sẻ trải nghiệm của bạn và nó hoạt động như thế nào cho bạn!


