Mere end 178.000 GitHub-brugere har stjernemarkeret en enkelt markdown-fil. Filen fortæller bare en AI, hvordan den skal opføre sig.
Fire regler: Tænk før du koder. Enkelhed først. Kirurgiske ændringer. Målstyret udførelse. Det er det. Intet bibliotek. Intet framework. Ingen installer. Forrest Chang pakkede Andrej Karpathys observationer om LLM-kodningsfejltyper ind i en enkelt CLAUDE.md-fil, og udviklerfællesskabet skubbede den forbi 178.000 GitHub-stjerner i månederne, der fulgte.
Hvis du kniber øjnene sammen og ser på, hvad der skete der, ligner det meget det, som enhver engineering-organisation til sidst fandt ud af, at den havde brug for, efter nok smerte: et fælles sæt af begrænsninger for, hvordan kode bliver skrevet. Et regel-lag. Den slags ting, der plejede at bo i en code review-tjekliste, eller en style guide, eller en senior-ingeniørs institutionelle hukommelse. Vibe-kodnings-fællesskabet fandt en langt lettere version af samme disciplin: skriv reglerne ned i markdown, og lad agenten læse dem, før den skriver kode.
Dette er ikke en engangsforeteelse. Det er et mønster.
TL;DR
- Agent-instruktions-økosystemet (CLAUDE.md, AGENTS.md, delte skills-biblioteker og tilgængelighedsagenter) er ved at blive et distribueret kvalitetshåndhævelses-lag for AI-assisteret kodning.
- Det kvalitetsgab, det reagerer på, er reelt: Snyk scannede 3.984 skills fra ClawHub og skills.sh og fandt, at 1.467, eller 36,82 %, havde mindst én sikkerhedsfejl; 534, eller 13,4 %, havde mindst ét problem på kritisk niveau.
- Fællesskabets svar har været at bygge flere regler, ikke at opgive tilgangen, og institutioner fra Vercel over OWASP til Linux Foundation er nu involveret.
Kvalitetsgabet er reelt, og fællesskabet ved det

13,4 % af fællesskabets skills-filer indeholder kritiske sikkerhedsfejl. Det er fra Snyks ToxicSkills-rapport, udgivet februar 2026 efter scanning af 3.984 skills fra ClawHub og skills.sh. 36,82 % havde mindst én sikkerhedssårbarhed. 76 var direkte ondsindede, hvor 91 % af dem brugte prompt-injektion som leveringsmekanisme.
Den bredere historie om AI-kodekvalitet er tilsvarende. Ifølge CodeRabbits analyse af code review-data har AI-assisteret kode i gennemsnit 10,83 problemer pr. pull request mod 6,45 for menneskeskrevet kode, cirka 1,7 gange flere problemer. GitClears årlige kodestudie rapporterede, hvad det kalder "4x vækst" i kodekloning: en stigning fra 8,3 % til 12,3 % af de ændrede linjer mellem 2021 og 2024.
Det er tal fra leverandører, så tag præcisionen med passende skepsis. Alligevel er de retningsanvisende: AI-assisteret kodning skaber nok kvalitetspres til, at udviklere bygger nye værn omkring den.
Det, der betyder noget, er, hvad fællesskabet gjorde med denne information. Svaret var ikke "skills-filer er farlige, hold op med at bruge dem." Det var: OWASP lancerede Agentic Skills Top 10 (AST10), skills-økosystemets pendant til Web Application Security Top 10. Flere regler. Mere struktur. Et formelt sikkerhedsframework til et uformelt økosystem.
Det er et klassisk engineering-svar, selv fra et fællesskab, der ofte forsøger at undgå tunge processer.
Økosystemet, der dukkede op

I løbet af første halvdel af 2026 begyndte dette at se mindre ud som en håndfuld isolerede markdown-filer og mere som et lagdelt økosystem.
Start med adfærdslaget. Den Karpathy-inspirerede CLAUDE.md pakker Forrest Changs version af Andrej Karpathys observationer om LLM-kodningsfejl ind i en enkelt instruktionsfil, og den ligger nu på mere end 178.000 GitHub-stjerner, et af de mest stjernemarkerede repositories i GitHubs historie, for en fil bygget omkring fire enkle regler. Hvad de regler er, er mindre interessant end hvad de repræsenterer: et forsøg på at indkode den dømmekraft, en senior-ingeniør ville anvende under code review.
Over det ligger et community-aggregeringslag. Antigravity Awesome Skills har passeret 1.595+ agentic skills og samler genbrugelige playbooks til Claude Code, Cursor, Codex CLI, Gemini CLI, Antigravity og andre AI-kodningsassistenter. Det fungerer som et hurtigt voksende delt bibliotek for området: den slags, en standardiseringskomité kunne producere, hvis den bevægede sig gennem GitHub i stedet for PDF'er.
Så dukkede frameworkene op. Vercel gjorde vercel-labs/agent-skills til et officielt organisations-repository, nu på 28.000 stjerner. React Best Practices-skillen alene indeholder 40+ regler på tværs af otte performance-fokuserede kategorier, herunder waterfalls, bundle-størrelse, server-side performance, client-side datahentning, re-render-optimering, rendering-performance og JavaScript-mikrooptimeringer. Når den virksomhed, der ejer din deployment-platform, leverer officielle kvalitetsregler til AI-agenter, er økosystemet rykket op fra community-eksperiment til produktionsinfrastruktur.
Og øverst, et standardlag. OpenAI donerede AGENTS.md-specifikationen til Linux Foundations Agentic AI Foundation (AAIF) sammen med MCP (Anthropic) og Goose (Block): på tværs af værktøjer, på tværs af agenter, standardiserings-sporet. Retningen går mod portabilitet: AGENTS.md giver teams et fælles sted til projektspecifik agent-vejledning, selv om de enkelte værktøjer stadig kan adskille sig i, hvordan de indlæser og anvender disse instruktioner.
Disse brikker dukkede ikke op som én centralt planlagt stak. De konvergerede, fordi efterspørgslen var reel.
Den dimension, ingen taler om
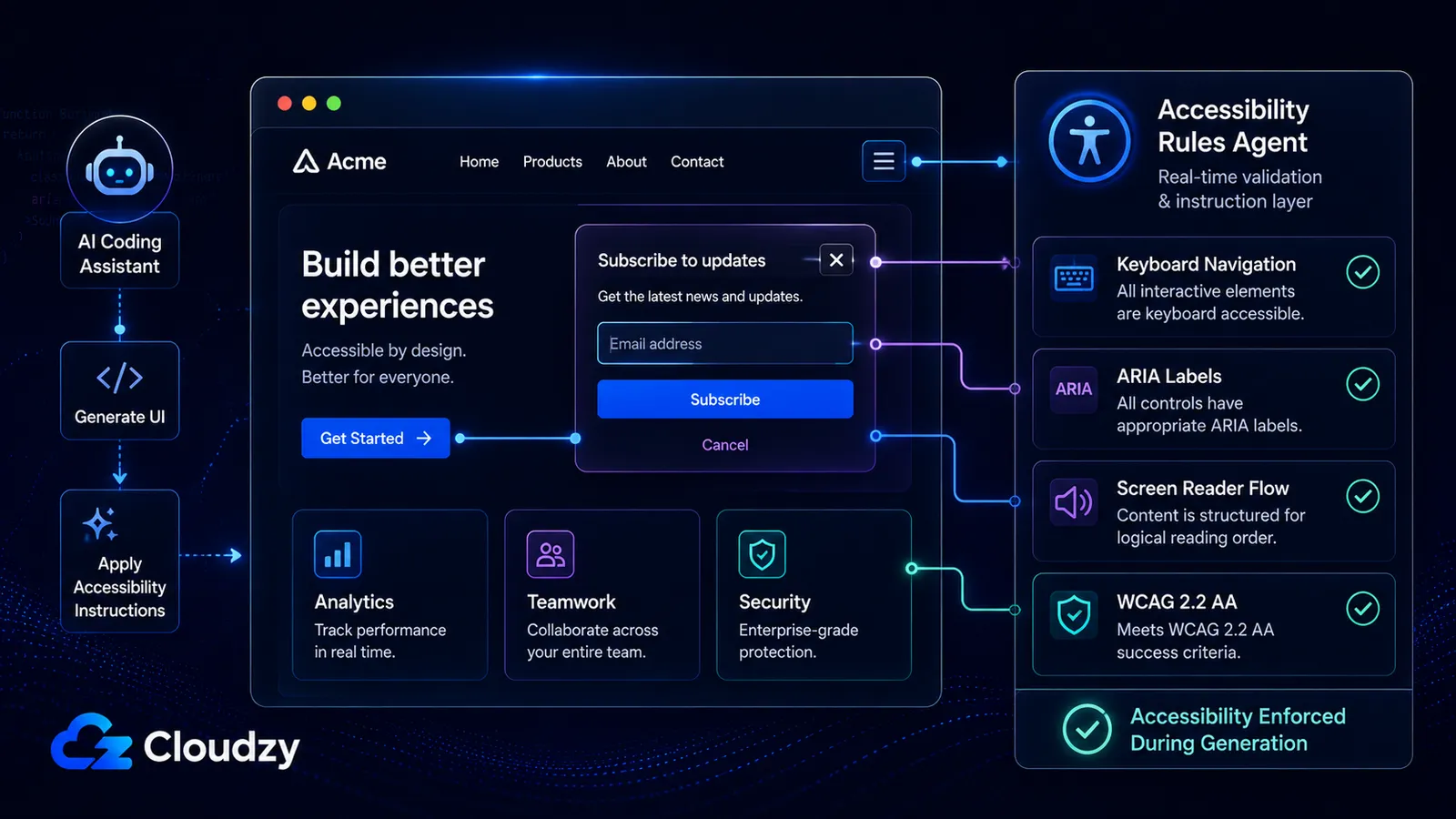
Data om sikkerhed og kodekvalitet får dækning. Tilgængelighedsdimensionen gør det næsten aldrig.
Community-Access/accessibility-agents startede den 21. februar 2026 med seks agenter. Pr. juni 2026: 79 specialiserede agenter på tværs af otte teams, 18 genbrugelige tilgængelighedsskills, WCAG 2.2 AA-målsætning og understøttelse på tværs af fem platforme: Claude Code, GitHub Copilot, Gemini CLI, Codex CLI og en MCP Server, der kan betjene MCP-kompatible klienter.
Hvad dette projekt er, i klar tale: et fællesskab af udviklere besluttede, at AI-kodningsværktøjer genererer utilgængelig kode som standard (de springer ARIA-regler over, ignorerer keyboard-navigation, producerer modaler, der fanger skærmlæsere) og byggede 79 specialiserede agenter til at håndhæve de regler, AI'en bliver ved med at glemme.
Det er bemærkelsesværdigt, at det sker. Frontend-ingeniører har historisk underleveret på tilgængelighed. Det er det første, der skæres væk under deadline-pres. accessibility-agents-projektet er vibe-kodere, der skriver de regler, de ellers ville have brug for en senior-ingeniør til at håndhæve, og gør det offentligt, gratis, på tværs af fem understøttede integrationer.
Efter min læsning er projektet usædvanligt grundigt for en frivillig tilgængelighedsindsats, især fordi det gør tilgængelighed fra en sen QA-bekymring til genbrugelige agent-instruktioner, der kører under kodegenerering.
Hvorfor dette var uundgåeligt
Argumentet om, at "skills-filer bare er READMEs til AI", er rimeligt, hvis du ser på en enkelt fil. Det holder ikke længere, når du ser på OWASP, der lancerer et sikkerhedsframework til økosystemet, Vercel, der leverer et officielt kvalitetsbibliotek, eller et frivilligt tilgængelighedsprojekt, der vokser til 79 specialiserede agenter.
Her er hvad der faktisk sker: kvalitetshåndhævelse forsvinder ikke, når du fjerner processen. Den dukker op igen i en anden form, fordi fraværet af kvalitet hurtigt skaber smerte, og den person, der er tættest på den smerte, retter den ved kilden.
Traditionel engineering-disciplin (code review, style guides, QA-gates, arkitekturgovernance) eksisterer for at fange det, som individuelle udviklere springer over under tidspres. Den fungerer, når du har et team og en proces. Vibe-kodere har, af design, ofte ingen af delene. Så de forhåndsindkodede reviewet i agentens instruktioner.
CLAUDE.md er forhåndsindkodet code review. Awesome Skills er en distribueret style guide. AGENTS.md er en governance-standard. Ordene ændrede sig. Funktionen gjorde ikke.
Det interessante er ikke, at begrænsningerne dukkede op igen, det var uundgåeligt. Det interessante er, at de dukkede op igen hurtigere, end de gjorde første gang, og mere offentligt, og på et kvalitetsniveau, der gør nogle engineering-organisationer med modne processer flove.
Vibe-kodnings-fællesskabet genopfandt ikke engineering-disciplin modvilligt, under pres fra ledelsen. De byggede den, fordi de ramte en mur, og værktøjerne til at løse det var kun en markdown-fil væk.
Ofte stillede spørgsmål
Hvad kommer der i en CLAUDE.md-fil?
Adfærdsbegrænsninger for AI'en: hvad den skal undgå, hvad den skal prioritere, arkitekturregler, sikkerhedsmæssige røde flag og projektspecifikke konventioner. Kvalitetsfokuseret brug går videre end workflow-genveje: regler som "fjern aldrig fejlhåndtering for at få tests til at bestå" står side om side med "brug altid TypeScript." For reelle, afprøvede eksempler kan du starte med Awesome Skills-community-aggregeringen. Vercels agent-skills er en anden stærk reference.
Hvad er AGENTS.md, og hvordan adskiller den sig fra CLAUDE.md?
AGENTS.md er en universel standard for projektspecifik agent-vejledning, udgivet af OpenAI og doneret til Linux Foundations Agentic AI Foundation i december 2025. CLAUDE.md er Claude Codes projektvejlednings-fil. De overlapper i formål, men de er ikke identiske formater i alle værktøjer. Den praktiske konklusion er, at teams i stigende grad kan skrive agent-instruktioner én gang og tilpasse dem på tværs af værktøjer som Codex, Cursor, Copilot, Gemini CLI og Claude Code.
Er skills-filer sikre at bruge?
Community-baserede skills bør læses, før de importeres. Snyks ToxicSkills-rapport fandt, at 36 % af de scannede community-skills havde mindst én sikkerhedsfejl, og 13,4 % havde fejl på kritisk niveau, med prompt-injektion som den primære angrebsmekanisme. OWASP Agentic Skills Top 10 er referenceframeworket til at forstå angrebsfladen. Skills-filer fra officielle repositories eller etablerede open source-projekter bærer generelt lavere supply chain-risiko end anonyme community-bidrag, men de bør stadig reviewes før import.
Hvad er OWASP Agentic Skills Top 10 (AST10)?
OWASP's sikkerhedsframework fra 2026 til skills-økosystemet, analogt med OWASP Web Application Security Top 10, men som specifikt adresserer den angrebsflade, der skabes af AI-agent-instruktionsfiler. Det dækker de ti mest kritiske sikkerhedsrisici på tværs af platforme, herunder Claude Code, Cursor/Codex og VS Code. Frameworket er under aktiv udvikling pr. 2026, med en v1.0-udgivelse planlagt til Q4 2026.
Har jeg brug for skills-filer, hvis jeg bygger et personligt projekt?
Kun hvis du vil have konsistent AI-adfærd. Uden begrænsninger optimerer AI-kodningsværktøjer for opgaveafslutning, ikke kodekvalitet, hvilket fungerer fint, indtil det producerer dupleret logik, manglende fejlhåndtering eller utilgængelige UI-komponenter. Omkostningen er lav: én fil pr. projekt, vedligeholdt efterhånden som du opdager, hvad AI'en bliver ved med at få galt. De Karpathy-inspirerede regler er et fornuftigt udgangspunkt; community-skills-bibliotekerne lader dig hente domænespecifikke regler ind (sikkerhed, tilgængelighed, sprog-idiomer) uden at skrive dem fra bunden.