
Uno de los aspectos más importantes del aprendizaje automático, si no el que más, es obtener predicciones precisas y fiables. Un enfoque innovador que ha ganado relevancia para lograr este objetivo es el Bootstrap Aggregating, más conocido como bagging en machine learning. Este artículo explica qué es el bagging en machine learning, compara el bagging y el boosting en machine learning, incluye un ejemplo de clasificador bagging, describe cómo funciona el bagging y analiza sus ventajas e inconvenientes.
¿Qué es el bagging en machine learning?
Estas dos son las únicas imágenes relevantes utilizadas en los artículos más populares. Se puede usar una o ambas (una aquí y la otra en otro lugar) si pedimos a Diseño que cree versiones de Cloudzy.
¿Qué es bagging?
Imagina que intentas adivinar el peso de un objeto pidiendo estimaciones a varias personas. Cada una puede dar una cifra muy distinta, pero si promedias todas las respuestas, obtienes un resultado más fiable. Eso es, en esencia, el bagging: combinar las predicciones de varios modelos para obtener un resultado final más preciso y estable.
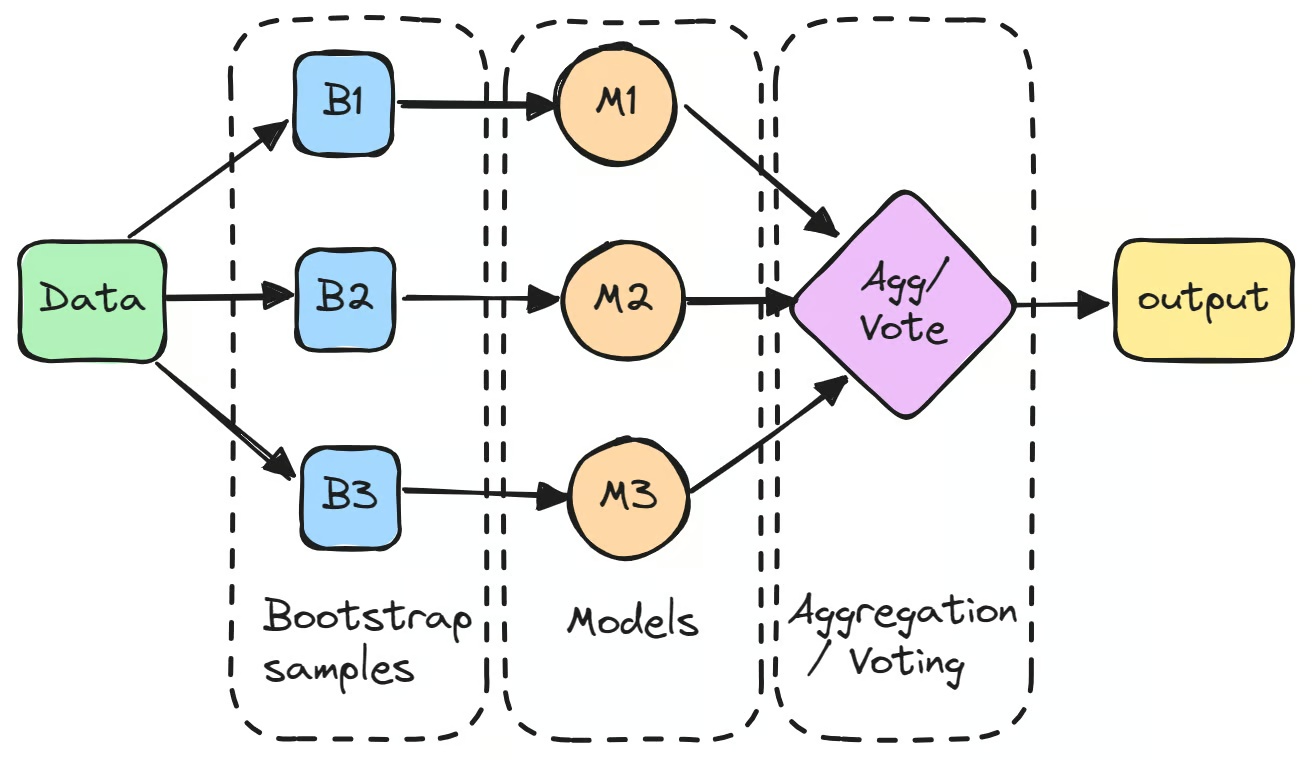
El proceso comienza generando múltiples subconjuntos del conjunto de datos original mediante bootstrapping, es decir, muestreo aleatorio con reemplazo. Cada subconjunto se usa para entrenar un modelo independiente por separado.
Estos modelos individuales, conocidos habitualmente como «aprendices débiles», pueden no rendir especialmente bien por sí solos debido a su alta varianza. Sin embargo, cuando se agregan sus predicciones, ya sea promediándolas en tareas de regresión o por votación mayoritaria en tareas de clasificación, el resultado combinado suele superar al de cualquier modelo individual.
Un ejemplo conocido de clasificador con bagging es el algoritmo Random Forest, que construye un conjunto de árboles de decisión para mejorar la capacidad predictiva. Dicho esto, no debe confundirse el bagging con el boosting en machine learning: el boosting entrena los modelos de forma secuencial para reducir el sesgo, mientras que el bagging los entrena en paralelo para reducir la varianza.
Tanto el bagging como el boosting en machine learning buscan mejorar el rendimiento del modelo, pero actúan sobre aspectos distintos de su comportamiento.
¿Por qué es útil bagging?
Una de las principales ventajas del bagging en machine learning es su capacidad para reducir la varianza, lo que ayuda a los modelos a generalizar mejor ante datos nuevos. El bagging resulta especialmente útil con algoritmos sensibles a las fluctuaciones en los datos de entrenamiento, como los árboles de decisión.
Al evitar el sobreajuste, produce modelos más estables y fiables. Si comparamos bagging y boosting en machine learning, el bagging se centra en reducir la varianza entrenando múltiples modelos en paralelo, mientras que el boosting busca reducir el sesgo entrenándolos de forma secuencial.
Un ejemplo de bagging en machine learning aplicado puede verse en la predicción de riesgo financiero, donde se entrenan múltiples árboles de decisión sobre distintos subconjuntos de datos históricos del mercado. Al agregar sus predicciones, el bagging construye un modelo de pronóstico más sólido y reduce el impacto de los errores de cada modelo individual.
En definitiva, el bagging en machine learning aprovecha el criterio colectivo de múltiples modelos para obtener predicciones más precisas y fiables que las de cualquier modelo por separado.
Cómo funciona el bagging en machine learning: paso a paso
Para entender bien cómo el bagging mejora el rendimiento de los modelos, veamos el proceso paso a paso.
Obtener múltiples muestras bootstrap del conjunto de datos
El primer paso del bagging en machine learning consiste en crear varios subconjuntos nuevos del conjunto de datos original mediante bootstrapping. Esta técnica consiste en muestrear los datos aleatoriamente con reemplazo, por lo que algunos puntos pueden aparecer varias veces en el mismo subconjunto mientras que otros pueden no aparecer. De esta forma, cada modelo se entrena con una versión ligeramente distinta de los datos.
Entrenar un modelo independiente con cada muestra
Cada muestra bootstrap se usa para entrenar un modelo por separado, normalmente del mismo tipo, como árboles de decisión. Estos modelos, llamados habitualmente «aprendices base» o «aprendices débiles», se entrenan de forma independiente sobre sus respectivos subconjuntos. Un ejemplo de clasificador con bagging es el árbol de decisión que usa el algoritmo Random Forest, que constituye la base de muchos modelos basados en bagging. Aunque cada modelo individual puede no rendir bien por sí solo, cada uno aporta perspectivas únicas a partir de sus datos de entrenamiento específicos.
Agregar las predicciones
Una vez entrenados los modelos, sus predicciones se agregan para obtener el resultado final.
- En tareas de regresión, las predicciones se promedian, lo que reduce la varianza del modelo.
- En tareas de clasificación, la predicción final se determina por votación mayoritaria: se selecciona la clase que predice la mayoría de los modelos. Este método produce una predicción más estable que la de un modelo individual.
Predicción final
Al combinar las predicciones de varios modelos, el bagging reduce el impacto de los errores de cualquier modelo concreto y mejora la precisión global. Este proceso de agregación es lo que hace del bagging una técnica tan potente, especialmente en tareas de machine learning donde se usan modelos de alta varianza como los árboles de decisión. Suaviza de forma efectiva las inconsistencias entre las predicciones individuales y produce un modelo final más sólido.
Aunque el bagging es eficaz para estabilizar predicciones, hay que tener en cuenta que los modelos base demasiado complejos pueden provocar sobreajuste, a pesar de que reducirlo sea precisamente el objetivo general del bagging.
También es computacionalmente costoso, por lo que puede ser útil ajustar el número de aprendices base o considerar métodos de ensemble más eficientes, además de elegir el GPU adecuado para ML y DL siempre es importante.
Asegúrate de incluir cierta diversidad de modelos entre los aprendices base para obtener mejores resultados. Si trabajas con datos desbalanceados, técnicas como SMOTE pueden ser útiles antes de aplicar bagging para evitar un rendimiento deficiente en las clases minoritarias.
Aplicaciones del Bagging
Ahora que hemos explorado cómo funciona el bagging, es momento de ver dónde se usa en la práctica. El bagging ha encontrado su lugar en una gran variedad de sectores, ayudando a mejorar la precisión y la estabilidad de las predicciones en escenarios complejos. Veamos algunas de sus aplicaciones más relevantes:
- Clasificación y regresión: El bagging se usa ampliamente para mejorar el rendimiento de clasificadores y regresores reduciendo la varianza y evitando el sobreajuste. Por ejemplo, los Random Forests, que se basan en bagging, son eficaces en tareas como la clasificación de imágenes y el modelado predictivo.
- Detección de anomalías: En áreas como la detección de fraude y la detección de intrusiones en redes, los algoritmos de bagging ofrecen un rendimiento superior al identificar eficazmente valores atípicos y anomalías en los datos.
- Evaluación del riesgo financiero: Las técnicas de bagging se aplican en banca para mejorar los modelos de scoring crediticio, incrementando la precisión en los procesos de aprobación de préstamos y en la evaluación del riesgo financiero.
- Diagnóstico médico: En el ámbito sanitario, el bagging se ha utilizado para detectar trastornos neurocognitivos como el Alzheimer mediante el análisis de conjuntos de datos de MRI, facilitando el diagnóstico temprano y la planificación del tratamiento.
- Procesamiento del Lenguaje Natural (NLP): El bagging contribuye a tareas como la clasificación de texto y el análisis de sentimientos agregando las predicciones de múltiples modelos, lo que conduce a una comprensión del lenguaje más fiable.
Ventajas y desventajas del Bagging
Como cualquier técnica de machine learning, el bagging tiene sus propias ventajas y desventajas. Conocerlas ayuda a decidir cuándo y cómo utilizarlo en tus modelos.
Ventajas del Bagging:
- Reduce la varianza y el sobreajuste: Una de las ventajas más destacadas del bagging en machine learning es su capacidad para reducir la varianza, lo que ayuda a prevenir el sobreajuste. Al entrenar múltiples modelos sobre diferentes subconjuntos de los datos, el bagging garantiza que el modelo no se vuelva demasiado sensible a las fluctuaciones en los datos de entrenamiento, lo que se traduce en un modelo más generalizable y estable.
- Funciona bien con modelos de alta varianza: El bagging es especialmente eficaz cuando se usa con modelos de alta varianza, como los árboles de decisión. Estos modelos tienden a sobreajustarse y presentan una varianza elevada, pero el bagging lo mitiga promediando o votando sobre múltiples modelos. Esto hace que las predicciones sean más fiables y menos susceptibles al ruido en los datos.
- Mejora la estabilidad y el rendimiento del modelo: Al combinar múltiples modelos entrenados sobre diferentes subconjuntos de los datos, el bagging suele conducir a un mejor rendimiento general. Mejora la precisión predictiva y reduce la sensibilidad del modelo ante pequeños cambios en el conjunto de datos, lo que en última instancia lo hace más fiable.
Desventajas del bagging:
- Mayor coste computacional: El bagging requiere entrenar varios modelos, lo que aumenta el coste computacional. Entrenar modelos y combinar sus predicciones puede llevar bastante tiempo, sobre todo con conjuntos de datos grandes o modelos complejos como los árboles de decisión.
- Poca utilidad en modelos de baja varianza: Aunque el bagging es muy eficaz para modelos de alta varianza, apenas aporta beneficios cuando se aplica a modelos de baja varianza como la regresión lineal. En estos casos, los modelos individuales ya tienen tasas de error bajas, por lo que combinar sus predicciones mejora poco los resultados.
- Pérdida de interpretabilidad: Al combinar varios modelos, el bagging puede reducir la interpretabilidad del modelo final. En un Random Forest, por ejemplo, el proceso de toma de decisiones se basa en múltiples árboles de decisión, lo que dificulta rastrear el razonamiento detrás de una predicción concreta.
¿Cuándo debería usar bagging?
Saber cuándo aplicar bagging en proyectos de machine learning es clave para obtener buenos resultados. Esta técnica funciona bien en situaciones específicas, pero no siempre es la mejor opción para cada problema.
Cuando tu modelo tiende al sobreajuste
Uno de los principales casos de uso del bagging es cuando el modelo tiende al sobreajuste, especialmente en modelos de alta varianza como los árboles de decisión. Estos modelos pueden funcionar bien con los datos de entrenamiento, pero a menudo no generalizan bien ante datos nuevos porque se ajustan demasiado a los patrones concretos del conjunto de entrenamiento.
El bagging ayuda a combatir esto entrenando varios modelos sobre distintos subconjuntos de datos y promediando o votando para generar una predicción más estable. Esto reduce la probabilidad de sobreajuste y hace que el modelo sea más eficaz ante datos nuevos.
Cuando quieres mejorar la estabilidad y la precisión
Si buscas mejorar la estabilidad y la precisión de tu modelo sin sacrificar demasiada interpretabilidad, el bagging es una buena opción. Combinar las predicciones de varios modelos hace que el resultado final sea más fiable, algo especialmente útil en tareas que manejan datos con ruido.
Tanto en problemas de clasificación como en tareas de regresión, el bagging puede generar resultados más consistentes, mejorando la precisión sin perder eficiencia.
Cuando tienes suficientes recursos computacionales
Otro factor importante a la hora de decidir si usar bagging es la disponibilidad de recursos computacionales. Como el bagging requiere entrenar varios modelos a la vez, el coste computacional puede volverse considerable, especialmente con conjuntos de datos grandes o modelos complejos.
Si tienes acceso a la potencia de cómputo necesaria, los beneficios del bagging compensan con creces los costes. Si los recursos son limitados, puede que prefieras considerar técnicas alternativas o reducir el número de modelos en tu ensemble.
Cuando trabajas con modelos de alta varianza
El bagging es especialmente útil con modelos que tienen alta varianza y son sensibles a las variaciones en los datos de entrenamiento. Los árboles de decisión, por ejemplo, se usan habitualmente con bagging en forma de Random Forests, ya que su rendimiento puede variar mucho según los datos de entrenamiento.
Al entrenar varios modelos sobre distintos subconjuntos de datos y combinar sus predicciones, el bagging reduce la varianza y produce un modelo más fiable.
Cuando necesitas un clasificador sólido
Si trabajas en problemas de clasificación y necesitas un clasificador sólido, el bagging puede mejorar considerablemente la estabilidad de tus predicciones. Un Random Forest, que es un ejemplo clásico de clasificador basado en bagging, puede ofrecer predicciones más precisas al agregar los resultados de muchos árboles de decisión individuales.
Este enfoque funciona bien cuando los modelos individuales son débiles, pero su contribución conjunta da lugar a un modelo global más potente.
Además, si buscas la plataforma adecuada para implementar técnicas de bagging de forma eficiente, herramientas como Databricks y Snowflake ofrecen una plataforma de análisis unificada muy útil para gestionar grandes conjuntos de datos y ejecutar métodos de conjunto como el bagging.
Si buscas una aproximación menos técnica al machine learning, las herramientas de IA sin código pueden ser una opción. Aunque no se centran directamente en técnicas avanzadas como el bagging, muchas plataformas sin código permiten a los usuarios experimentar con métodos de aprendizaje de conjunto, incluido el bagging, sin necesidad de conocimientos avanzados de programación.
Esto te permite aplicar técnicas más sofisticadas y obtener predicciones precisas centrándote en el rendimiento del modelo, no en el código subyacente.
Reflexiones finales
El bagging en machine learning es una técnica eficaz que mejora el rendimiento del modelo al reducir la varianza y aumentar la estabilidad. Al agregar las predicciones de múltiples modelos entrenados con distintos subconjuntos de datos, el bagging produce resultados más precisos y fiables. Es especialmente útil para modelos de alta varianza como los árboles de decisión, ya que ayuda a prevenir el sobreajuste y garantiza que el modelo generalice mejor ante datos nuevos.
Aunque el bagging tiene ventajas claras, como reducir el sobreajuste y mejorar la precisión, también implica ciertas compensaciones. Aumenta el coste computacional al entrenar varios modelos y puede reducir la interpretabilidad. A pesar de estos inconvenientes, su capacidad para mejorar el rendimiento lo convierte en una técnica valiosa dentro del aprendizaje de conjunto, junto a otros métodos como el boosting y el stacking.
¿Has utilizado bagging en proyectos de machine learning? Cuéntanos tu experiencia y cómo te fue.


