
Quando NVIDIA ha mostrato DLSS 4 generare quindici pixel su ogni sedici con l'IA, una larga fetta del pubblico non ha visto un progresso. Ha visto "frame falsi" e "sbobba di IA": dettaglio generato che sembra giusto finché non lo è più, e che non puoi debuggare nel modo in cui debuggeresti un poligono fuori posto. Un rapporto di PCGuide su un sondaggio della community ha rilevato che il 54% delle risposte era un netto "No" sull' DLSS 5, con gran parte delle critiche rivolte ai tratti del viso e alla reazione della "sbobba di IA". Quella reazione merita di essere presa sul serio, e ci torneremo.
Ma il problema più grande in ognuno di quegli argomenti è che "rendering neurale" viene usato per almeno cinque cose diverse: upscaling, frame generati dall'IA, ricostruzione di scene da foto, le demo di NeRF e Gaussian Splatting che hai visto sui social, e i sistemi di ricerca che renderizzano un'intera immagine con una singola rete. Le persone parlano l'una sopra l'altra perché ciascuna indica un livello diverso usando la stessa parola. Jensen Huang di NVIDIA ha definito questo cambiamento un "momento GPT per la grafica." Questa è l'affermazione. La domanda utile è cosa accade sotto di essa.
Ecco il filo conduttore che rende leggibile tutta la faccenda: la GPU sta sempre più predicendo l'immagine invece di calcolarla. Tradizionalmente, la GPU calcola ogni pixel simulando geometria, illuminazione e materiali (rasterizzazione, e più di recente ray tracing sopra di essa). Il rendering neurale cambia ciò che viene calcolato rispetto a ciò che viene predetto da una rete addestrata. Questa singola distinzione è la spina dorsale di questo articolo. Alla fine sarai in grado di collocare qualsiasi tecnica su uno spettro, sapere quali girano in tempo reale e su quale hardware, e distinguere ciò che oggi è in un gioco da ciò che è un articolo di ricerca o una demo della GTC. Questa è una mappa, non un tutorial. La meccanica profonda di ogni singola tecnica è oggetto di articoli a sé.
La versione breve
- Il rendering neurale è uno spettro, non un sinonimo di DLSS. Comprende la ricerca sulla ricostruzione di scene (NeRF, Gaussian Splatting), i componenti in tempo reale che si collocano dentro la pipeline di rendering (DLSS, Ray Reconstruction, cache di radianza neurale) e i metodi generativi che inventano dettaglio che il frame non ha mai avuto.
- Il filo conduttore è "predire invece di calcolare." Ogni tecnica sostituisce una costosa fase calcolata della pipeline con una rete che predice il risultato per cui è stata addestrata.
- La maggior parte di ciò che esce oggi è ibrido. Upscaling, generazione di frame e riduzione del rumore tramite IA girano ora nei giochi in tempo reale, mentre la compressione neurale delle texture e gli shader neurali stanno emergendo attraverso i toolkit per sviluppatori. I renderer neurali completi che disegnano l'intera immagine con una rete sono ancora in fase di ricerca.
- Sta diventando multi-vendor, non solo una storia di NVIDIA. Il lavoro di Microsoft su DirectX per il ML a livello di shader è iniziato con i Cooperative Vectors in Shader Model 6.9 e si sta muovendo verso un supporto più ampio dell'algebra lineare in Shader Model 6.10, dando ai motori una via per affrontare carichi di lavoro di shader di stampo neurale al di là dello stack di un singolo vendor.
Perché "rendering neurale" significa cinque cose diverse
Il rendering neurale è una classe di metodi che usano reti neurali per predire parti di un'immagine (pixel, illuminazione, materiali, persino interi frame) che la GPU calcolerebbe altrimenti da zero. La rassegna di Tewari et al. lo definisce come la combinazione della grafica computerizzata classica con modelli generativi profondi per un output fotorealistico. Il termine abbraccia un ampio spettro, e "DLSS" è un punto su di esso.
Il motivo per cui la discussione è un pasticcio è che lo spettro ha almeno tre livelli distinti, e il pubblico usa una sola parola per tutti.
Il primo livello è il rendering neurale accademico / di ricostruzione: NeRF, 3D Gaussian Splatting e rendering differenziabile. Questi prendono fotografie o misurazioni di una scena reale e apprendono una rappresentazione da cui puoi renderizzare nuovi angoli di camera. L' articolo originale di NeRF (Mildenhall et al., 2020) addestra una piccola rete a mappare una coordinata 3D e una direzione di vista su colore e densità, poi renderizza nuove viste interrogandola. Questo livello è perlopiù offline. Ricostruisce scene; non alimenta il ciclo di frame del tuo gioco.
Il secondo livello è il rendering neurale di pipeline in tempo reale: reti che girano dentro o accanto a un normale frame rasterizzato. L'upscaling DLSS, Ray Reconstruction e la cache di radianza neurale vivono qui. La pipeline continua a rasterizzare e a fare ray tracing; una rete gestisce una sua fase costosa. Questo è il livello che oggi esce nei giochi.
Il terzo livello è il rendering neurale generativo: la rete produce contenuto d'immagine che il frame non ha mai calcolato. I frame generati di DLSS 4 si collocano al margine di questo, e DLSS 5 (che NVIDIA ha annunciato per l'autunno 2026) lo spinge oltre generando dettaglio di illuminazione e materiali invece di limitarsi a interpolare tra frame renderizzati.
Questi tre livelli si comportano in modo diverso, girano a velocità diverse e necessitano di hardware diverso. Trattarli come una cosa sola è il motivo per cui due persone possono dire allo stesso tempo "il rendering neurale è sopravvalutato" e "il rendering neurale è il futuro" e avere entrambe in parte ragione.
In sintesi della sezione: Il termine precede DLSS e non ne è un sinonimo. DLSS è un'applicazione (in tempo reale, dentro la pipeline) all'interno di uno spettro molto più ampio che va dalla ricostruzione di scene offline ai frame interamente generati.
Come il rendering neurale sta sostituendo parti della pipeline a forza bruta
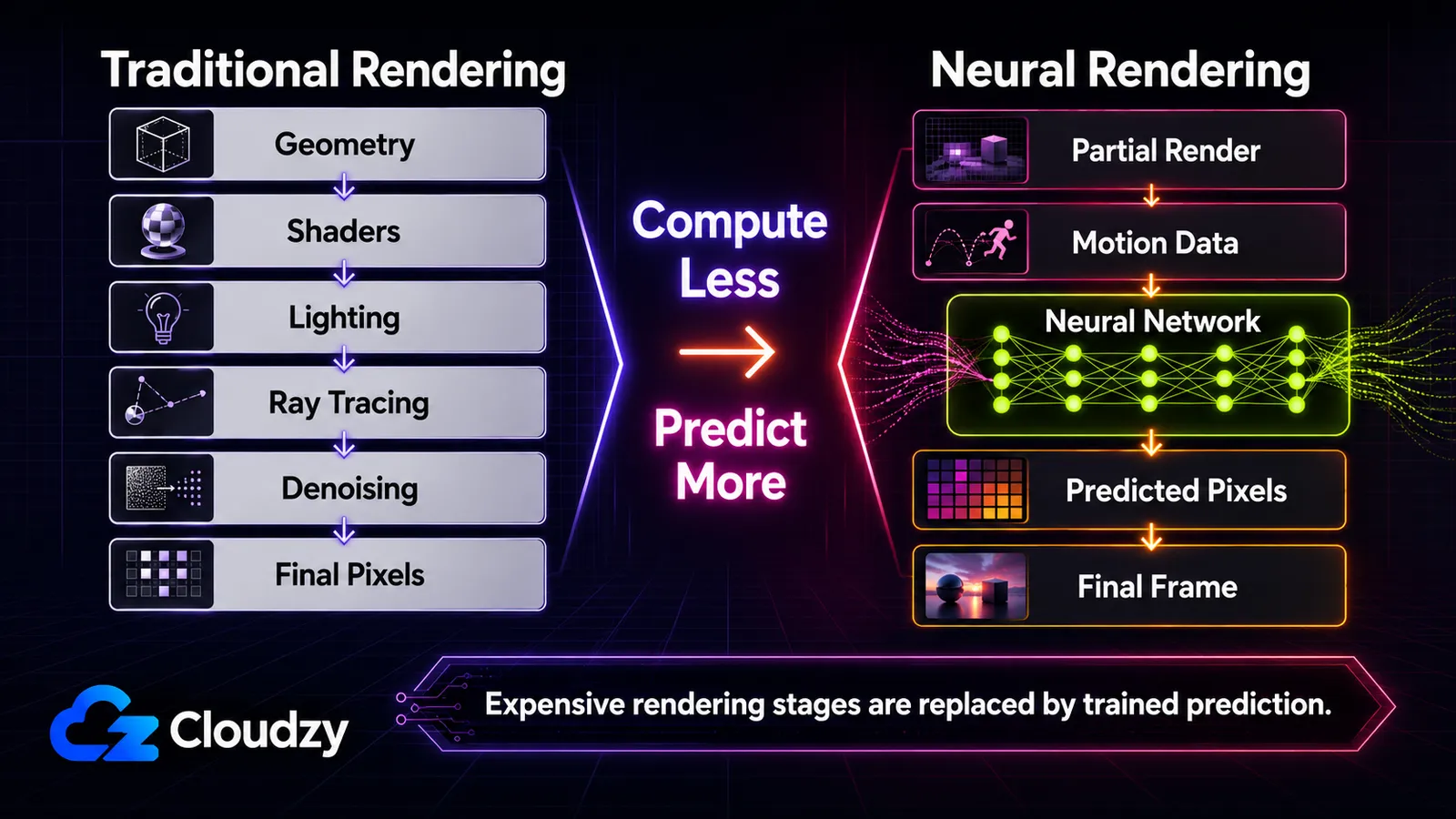
Con la piena generazione multi-frame di DLSS 4, circa quindici pixel su ogni sedici sullo schermo sono prodotti dall'IA invece che renderizzati in modo tradizionale (secondo i dati di NVIDIA su DLSS 4). Quel numero è l'intero cambiamento compresso in una sola statistica: il renderer calcola una frazione dell'immagine e predice il resto.
Il rendering tradizionale si guadagna ogni pixel. La GPU rasterizza la geometria, esegue gli shader per calcolare illuminazione e materiali e (con il ray tracing) simula la luce che rimbalza per la scena. Il ray tracing in particolare è brutalmente costoso, perché la luce realistica richiede molti rimbalzi e molti campioni per pixel, e il rumore del sottocampionamento va ripulito dopo. Man mano che le scene si sono fatte più ambiziose, le fasi più costose sono diventate i bersagli ovvi: invece di calcolarle, addestrare una rete a predire il loro output.
La progressione è stata costante più che improvvisa:
- 2018, DLSS 1.0. Il primo passo commerciale: renderizzare a bassa risoluzione, predire l'immagine ad alta risoluzione. Spostare l'upscaling da "calcolare più pixel" a "predire più pixel."
- 2020, NeRF. Ricostruzione di scene da immagini tramite un campo di radianza appreso. Predire nuove viste invece di modellare e renderizzare la geometria.
- 2021, cache di radianza neurale. Predire la luce rimbalzata durante il path tracing così che il renderer possa smettere di tracciare prima.
- 2022, DLSS 3 Frame Generation. Generare interi frame intermedi invece di renderizzarli.
- 2023, 3D Gaussian Splatting. Un'alternativa più veloce e orientata al tempo reale rispetto a NeRF per le scene ricostruite.
- 2025, DLSS 4 + RTX Kit. Generazione multi-frame più un toolkit di componenti neurali (compressione delle texture, cache di radianza, shader neurali).
- 2025, DirectX Cooperative Vectors (anteprima). Un'API multi-vendor per la matematica matriciale che gli shader neurali richiedono (introdotta in anteprima come parte di Shader Model 6.9).
- 2026, DLSS 4.5. Miglioramenti incrementali di qualità e di Ray Reconstruction (descritti da NVIDIA al Computex).
- Autunno 2026, DLSS 5 (annunciato). La prossima spinta verso il rendering neurale generativo.
Letto dall'alto in basso, ogni riga è la stessa mossa applicata a una fase diversa: prendere qualcosa che la pipeline calcolava e farlo predire invece a una rete.
I sei livelli: cosa l'IA sostituisce a ogni fase della pipeline
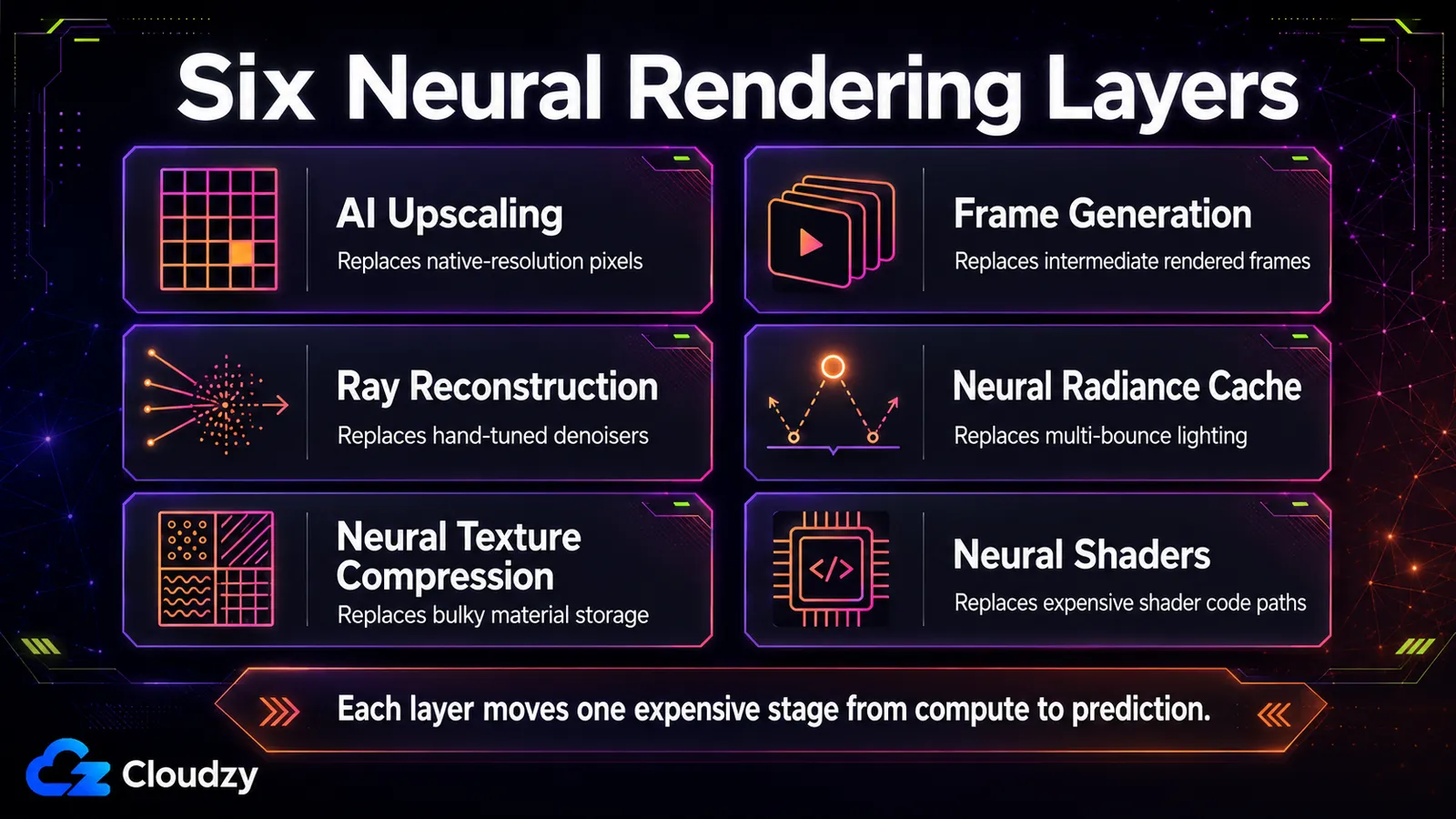
Sei tecniche reggono la maggior parte del rendering neurale in tempo reale di oggi, e ciascuna sostituisce una specifica fase calcolata: upscaling (risoluzione), generazione di frame (numero di frame), ray reconstruction (riduzione del rumore), cache di radianza neurale (illuminazione globale), compressione neurale delle texture (archiviazione dei materiali) e shader neurali (calcolo dentro lo shader). Sapere quale fase tocca ciascuna è la maggior parte della battaglia.
Queste si dividono in base a dove nella pipeline gira la rete. Alcune operano proprio alla fine come post-processo su un frame finito; alcune girano a metà pipeline accanto al ray tracing; alcune vivono dentro lo shader stesso. Quella posizione non è un dettaglio. Determina quanto velocemente la tecnica può girare e di quale hardware ha bisogno. La tabella mappa quelle sei tecniche; le sottosezioni qui sotto spiegano il meccanismo che non entrava in modo pulito in ogni cella.
| Tecnica | Cosa sostituisce | Fattibilità in tempo reale | Hardware richiesto | Multi-vendor? |
|---|---|---|---|---|
| Upscaling con IA (super risoluzione) | Calcolare i pixel a risoluzione nativa | Tempo reale, basso overhead | Core tensoriali / matriciali (RTX 20+, RDNA 4, Intel XMX) | Sì come categoria; le implementazioni restano specifiche del vendor (DLSS, FSR / FSR Upscaling, XeSS) |
| Generazione di frame | Renderizzare i frame intermedi | Tempo reale; aggiunge latenza | RTX 40+ (DLSS 3), RTX 50 per il multi-frame | In parte; specifica del vendor |
| Ray reconstruction | Lo stack di denoiser regolati a mano | Tempo reale | RTX 20+ | NVIDIA oggi |
| Cache di radianza neurale | Calcolare la luce indiretta a più rimbalzi | Tempo reale (~2,6 ms riportati) | Core matriciali di classe RTX | NVIDIA oggi (RTX Kit) |
| Compressione neurale delle texture | Archiviazione dei materiali con compressione a blocchi | Decodifica in tempo reale | Core matriciali di classe RTX | SDK/strumenti NVIDIA oggi; un supporto più ampio del ML a livello di shader è in via di standardizzazione separata |
| Shader neurali | Percorsi di codice shader calcolati | Tempo reale | GPU con ML a livello di shader / capaci di calcolo matriciale | Emergente tramite il percorso DirectX SM 6.9 / SM 6.10 |
Upscaling con IA (super risoluzione)
L'upscaling con IA renderizza il frame a una risoluzione più bassa e predice il risultato ad alta risoluzione, così la GPU disegna molti meno pixel e una rete riempie la struttura. DLSS, l'FSR 4 di AMD e l'XeSS di Intel fanno tutti questo tramite sovracampionamento temporale: campionano pixel diversi attraverso frame consecutivi e combinano quella cronologia con i vettori di movimento per ricostruire dettaglio che un singolo frame a bassa risoluzione non contiene.
Questo è il livello più maturo e più ampiamente diffuso, ed è dove la realtà multi-vendor è più chiara. DLSS 4 ha spostato il suo upscaler da una rete convoluzionale a un transformer per una migliore stabilità del dettaglio. FSR 4 è il primo upscaler basato su ML di AMD, che gira su RDNA 4 con inferenza FP8 invece delle euristiche scritte a mano delle versioni precedenti di FSR. XeSS usa le unità matriciali XMX di Intel. Tre vendor, la stessa idea di fondo: predire i pixel che non hai renderizzato.
Generazione di frame e generazione multi-frame
La generazione di frame predice interi frame tra quelli che la GPU renderizza effettivamente, combinando dati di gioco come i vettori di movimento con la stima del flusso ottico e l'IA. DLSS 3 usava l'Optical Flow Accelerator della serie RTX 40 per inserire un frame generato tra i frame renderizzati; la Multi Frame Generation di DLSS 4 su hardware della serie RTX 50 può generare fino a tre frame aggiuntivi per ogni frame renderizzato in modo tradizionale, e NVIDIA afferma che DLSS 4 sostituisce il passo di flusso ottico via hardware con un modello di IA più efficiente.
Questo è il livello di cui parla davvero l'argomento dei "frame falsi", e qui l'inquadramento conta. Un frame generato è un'interpolazione plausibile di dove stava andando la scena: ti mostra contenuto visivo utilizzabile. Ma è predetto, non renderizzato dallo stato effettivo del gioco, e non porta logica di gioco né input nuovi. In modo cruciale, la generazione di frame gira dopo che un frame è renderizzato, il che aggiunge latenza invece di rimuoverla; il Reflex 2 di NVIDIA esiste specificamente per recuperare quella latenza. Quindi "la generazione di frame rende il gioco più veloce" è una verità parziale: aumenta la fluidità percepita (più frame mostrati) senza aumentare il ritmo con cui il gioco effettivamente si aggiorna e risponde. Quel divario tra ciò che vedi e ciò che il gioco sa è l'intero dibattito, e per il gioco competitivo, dove la latenza di input decide gli esiti, è un compromesso da soppesare.
Ray Reconstruction (riduzione del rumore con IA)
Ray Reconstruction sostituisce lo stack di filtri di riduzione del rumore regolati a mano su cui si basa il rendering ray-traced con una singola rete neurale addestrata a ricostruire un'immagine pulita da un input ray-traced rumoroso e sottocampionato. Il path tracing può permettersi solo pochi campioni di luce per pixel in tempo reale, il che lascia l'output grezzo rumoroso; qualcosa deve ripulirlo prima che tu lo veda.
L'approccio tradizionale era una catena di denoiser specializzati, ciascuno regolato a mano per un effetto specifico. Sostituirla con una singola rete addestrata tende a preservare dettaglio che i filtri regolati a mano spalmavano, soprattutto su riflessi e illuminazione fine, ed è una rete da mantenere invece di una loro pipeline fragile. Questo è un esempio pulito del filo conduttore: la fase di riduzione del rumore è passata da "calcolare con euristiche scritte a mano" a "predire con un modello addestrato."
Cache di radianza neurale (illuminazione globale)
La cache di radianza neurale (NRC) predice come la luce rimbalza per una scena così che il path tracer possa smettere di tracciare la maggior parte dei raggi prima, invece di seguire ogni rimbalzo fino in fondo. L'illuminazione globale (la luce morbida e indiretta che rimbalza da pareti e pavimenti) è una delle cose più costose nella grafica in tempo reale, e il meccanismo che fa funzionare la NRC è raramente spiegato in linguaggio semplice, perciò vale la pena rallentare.
Ecco il meccanismo. Un path tracer normalmente segue ogni raggio di luce attraverso molti rimbalzi, ed è lì che il costo esplode. La NRC addestra una piccola rete durante il rendering (non in anticipo) per predire la luce che arriva a un punto dopo ulteriori rimbalzi. Così il path tracer traccia un raggio per un rimbalzo o due, poi chiede alla rete "qual è il resto della luce qui?" e termina il percorso prima; l' articolo sulla cache di radianza neurale in tempo reale (Müller et al., 2021) riporta di terminare in questo modo la grande maggioranza dei percorsi. Pensala come una cache che non memorizza risposte esatte già viste, ma apprende il pattern dell'illuminazione della scena abbastanza bene da rispondere a interrogazioni che non ha visto, e continua a riapprendere mentre la scena cambia. NVIDIA riporta che la NRC gira con circa 2,6 ms di overhead, che è ciò che la rende fattibile in tempo reale invece di una curiosità di ricerca.
Compressione neurale delle texture
La compressione neurale delle texture (NTC) comprime insieme tutti i canali di texture di un materiale con una rete, raggiungendo fino a 8 volte di risparmio di VRAM rispetto alla compressione a blocchi tradizionale a parità di qualità visiva (secondo la documentazione dell'RTX Kit di NVIDIA). Un materiale moderno non è una sola texture. È una pila di esse (colore, normali, rugosità, metallicità e altro), e quei canali sono correlati in modi che la compressione a blocchi, che comprime ogni canale in modo indipendente, butta via.
La NTC sfrutta quella correlazione. Apprendendo la struttura congiunta di tutti i canali di un materiale in una volta, archivia lo stesso materiale in molta meno memoria e lo decodifica al volo al momento del rendering. La VRAM è un vincolo persistente man mano che i giochi spingono il dettaglio delle texture, perciò "far stare 8 volte più materiale nella stessa memoria" è una vittoria diretta e pratica invece di un trucco visivo.
Shader neurali e DirectX Cooperative Vectors
Gli shader neurali eseguono piccole reti neurali dentro uno shader programmabile (i programmi per pixel/per vertice che la GPU esegue già) così che una rete possa approssimare un costoso effetto calcolato proprio dove serve quell'effetto. Invece di applicare l'IA come un passaggio separato, l'MLP gira come parte dello shader sulle unità matriciali della GPU (Tensor Core sull'hardware NVIDIA).
I Tensor Core gestiscono la matematica matriciale su cui girano queste reti, distinti dai core generici che gestiscono il resto del lavoro. Ciò che trasforma gli shader neurali da funzione di un singolo vendor in una capacità più ampia del settore è il livello di API sottostante. Microsoft ha introdotto DirectX Cooperative Vectors in anteprima con Shader Model 6.9 nel 2025 per esporre operazioni vettoriali/matriciali dentro gli shader HLSL. Entro il 2026, Shader Model 6.9 era passato alla versione di rilascio, e Microsoft ha detto che Cooperative Vector veniva deprecato in favore di un design più ampio di algebra lineare previsto per Shader Model 6.10. La conclusione sicura non è che i Cooperative Vectors siano l'API definitiva, ma che DirectX si sta muovendo verso un supporto del ML a livello di shader multi-vendor.
In sintesi della sezione: Le sei tecniche si ordinano in base a dove gira la rete: post-processo alla fine del frame, a metà pipeline accanto al ray tracing, o dentro lo shader stesso. Quella posizione è ciò che determina se una tecnica può girare in tempo reale e di quale hardware ha bisogno.
Cosa gira in tempo reale, e su quale hardware
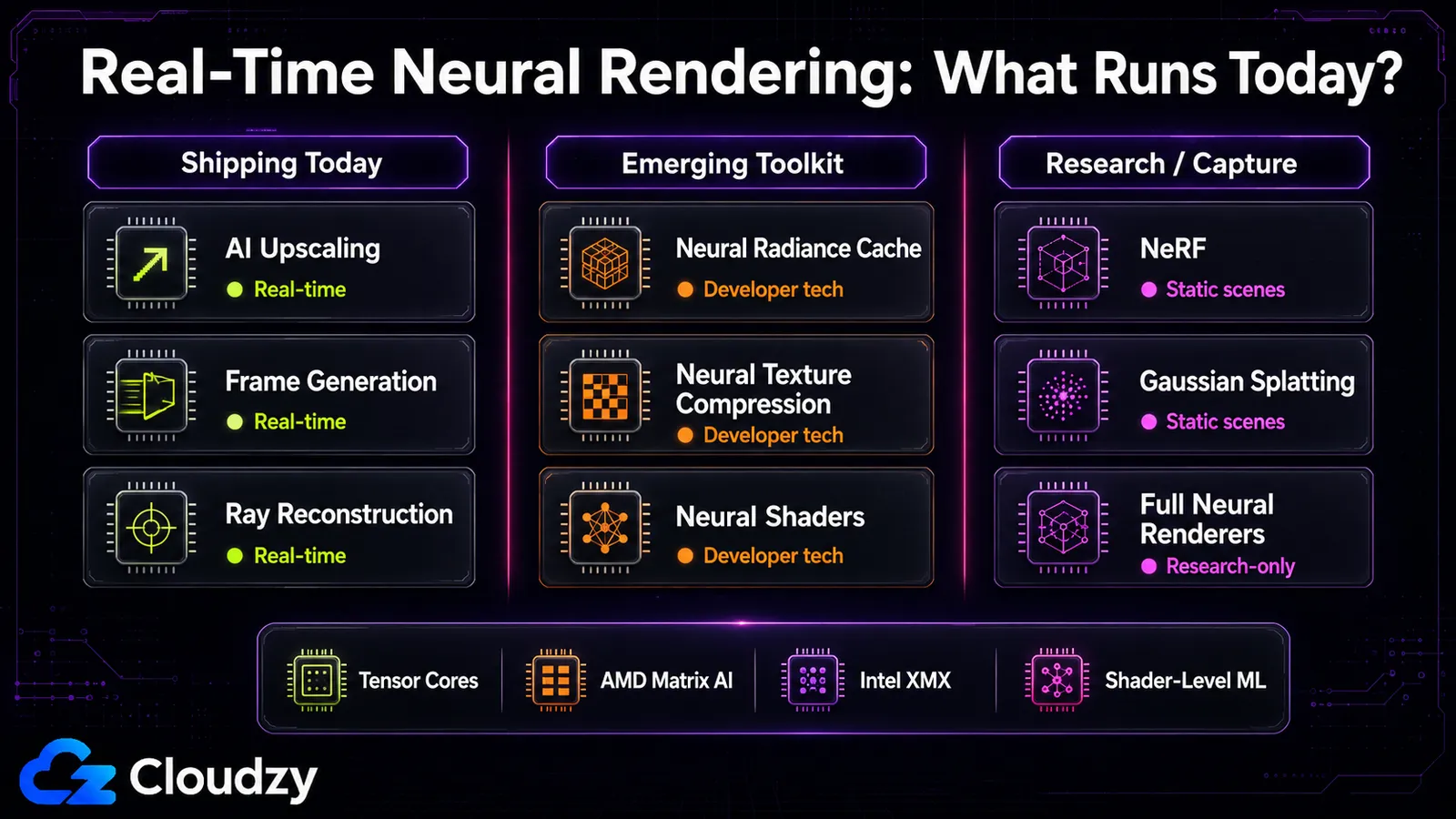
La linea del tempo reale è più netta di quanto suggerisca l'hype: l'upscaling con IA di solito gira con basso overhead, la NRC aggiunge circa 2,6 ms, e il 3D Gaussian Splatting si avvicina al tempo reale per le scene statiche. Il NeRF originale e i renderer neurali completi come RenderFormer sono saldamente solo da ricerca, impiegando troppo tempo per frame per un uso interattivo. "Il rendering neurale è in tempo reale" è vero per il livello dentro la pipeline e falso per i livelli di ricostruzione e di renderer completo.
Quella divisione segue esattamente lo spettro. Alcuni componenti dentro la pipeline, specialmente upscaling, generazione di frame e Ray Reconstruction, girano già nei giochi pubblicati. Altri, come NRC, NTC e shader neurali, si descrivono meglio come tecnologie per sviluppatori e funzioni di toolkit emergenti che come funzioni di produzione comuni. Il livello di ricostruzione è misto: il NeRF originale è lento, ma il 3D Gaussian Splatting è stato una spinta deliberata verso il tempo reale e ci arriva per le scene statiche. Il livello del renderer interamente neurale (una singola rete che produce l'intera immagine) è dove vive la ricerca e i tempi per frame sono lontanissimi dall'essere interattivi.
L'hardware è l'altra metà della risposta, ed è qui che atterra la storia multi-vendor. Ogni tecnica qui gira sulle unità di matematica matriciale che le GPU moderne integrano per l'inferenza dell'IA:
- NVIDIA ha i Tensor Core su ogni scheda RTX dalla serie 20 in poi, motivo per cui la maggior parte di queste tecniche ha debuttato lì.
- AMD indirizza attualmente il suo FSR Upscaling basato su ML alle GPU RDNA 4 / serie Radeon RX 9000 per il percorso ML; su hardware precedente, l'SDK di AMD ripiega sui percorsi analitici di FSR 3.1.5. Tratta un supporto più ampio delle GPU più vecchie come una voce di roadmap in movimento, non come una funzione garantita di FSR 4 a meno che tu non citi un annuncio specifico di AMD.
- Intel usa i motori matriciali XMX sulle GPU Arc per XeSS.
DLSS stesso è vincolato per funzione in base alla generazione: l'upscaling funziona fino alla serie RTX 20, la generazione di frame originale richiede la serie RTX 40, e la generazione multi-frame è solo della serie RTX 50. Se stai cercando di ragionare su cosa può fare una data scheda, quel vincolo di generazione è la risposta pratica, non il livello di marketing.
Cosa puoi usare oggi rispetto a cosa sta arrivando: upscaling, generazione di frame e Ray Reconstruction sono disponibili nei giochi oggi. I componenti dell'RTX Kit come NRC, NTC e shader neurali sono disponibili come tecnologie e strumenti per sviluppatori, ma non dovresti lasciar intendere che siano tutti già comuni nei giochi pubblicati. Gaussian Splatting ha strumenti aperti utilizzabili per la cattura delle scene. Ciò che non c'è ancora: renderer neurali completi che disegnano un intero frame con una rete, shader neurali multi-vendor maturi (il supporto di AMD è agli inizi) e le funzioni generative di DLSS 5 (annunciate per l'autunno 2026). Se vuoi sperimentare con il lato della ricostruzione (eseguire NeRF o carichi di inferenza da solo), quello è un lavoro di calcolo su GPU , non qualcosa che il tuo gioco fa per te.
Cosa il rendering neurale non è: cinque idee sbagliate

La maggior parte degli argomenti sul rendering neurale diventa più facile una volta che identifichi di quale livello dello spettro tratta l'affermazione. Cinque idee sbagliate emergono di continuo.
1. "L'upscaling DLSS è rendering neurale." DLSS è an applicazione del rendering neurale, il livello in tempo reale dentro la pipeline, non l'intero campo. Il termine precede DLSS e include NeRF, Gaussian Splatting e i metodi generativi. Equiparare i due è come chiamare "database" un sinonimo di un prodotto che capita di usare.
2. "La generazione di frame rende i giochi più veloci." Aumenta il numero di frame che vedi, il che fa sembrare il movimento più fluido, ma gira dopo il rendering e aggiunge latenza. Il ritmo con cui il gioco si aggiorna e risponde al tuo input non aumenta. Per il gioco competitivo quella latenza è un compromesso reale; per la fluidità visiva è una vera vittoria. "Più veloce" confonde le due cose.
3. "DLSS 5 è consapevole del 3D / legge la scena 3D." Questo è quello che più vale la pena capire bene, perché la copertura tecnologica continua a rappresentarlo in modo sbagliato. Come lo descrive NVIDIA, DLSS 5 prende come input i dati di colore e i vettori di movimento di ogni frame, poi usa il suo modello addestrato per dedurre la semantica della scena, come personaggi, capelli, tessuti, pelle e condizioni di illuminazione. È radicato nel contenuto del gioco, ma NVIDIA non lo descrive come una lettura diretta del file completo della scena 3D del gioco. "Guidato dal 3D" significa che l'inferenza è coerente con la geometria (rispetta come le superfici si muovono e si relazionano), non che la rete legga direttamente la geometria della scena. La distinzione conta perché delimita ciò che la tecnica può e non può sapere.
4. "NeRF è in tempo reale ora." Dipende da quale tecnica intendi, che è proprio il problema dello spettro. Il NeRF originale non è in tempo reale. Il 3D Gaussian Splatting si avvicina al tempo reale per le scene statiche. I sistemi di ricerca che renderizzano un intero frame con una rete (RenderFormer e simili) non sono affatto in tempo reale. "NeRF" è diventato un termine ombrello per una mezza dozzina di metodi con velocità estremamente diverse.
5. "Il rendering neurale sostituirà presto la rasterizzazione." I sistemi di oggi sono ibridi: i componenti neurali si collocano dentro una pipeline di rasterizzazione e ray tracing, non al suo posto. Sostituire completamente la pipeline classica con un singolo renderer generativo è un obiettivo di ricerca a lungo orizzonte, non una direzione di prodotto a breve termine. Prendi "il futuro è interamente neurale" come una direzione di marcia, non come una previsione datata.
In sintesi della sezione: L'unica causa alla radice di quasi ogni disaccordo sul rendering neurale è che le persone usano la stessa parola per livelli diversi dello spettro. Colloca prima l'affermazione sullo spettro, e la maggior parte della discussione scompare.
Dove sta andando tutto questo
La traiettoria è coerente con tutto quanto sopra: oggi pipeline ibride, più fasi che passano dal calcolare al predire, shader neurali multi-vendor che allargano chi può pubblicare tutto questo, e la frontiera del renderer interamente neurale ancora lontana anni. Il prossimo passo per il consumatore è DLSS 5, annunciato per l'autunno 2026, che entra nel rendering neurale generativo producendo dettaglio di illuminazione e materiali che il gioco non ha mai calcolato, invece di limitarsi a interpolare tra frame renderizzati. NVIDIA ha mostrato la tecnologia in contesti della serie RTX 50, ma i suoi requisiti hardware finali per il consumatore andrebbero trattati come non confermati finché NVIDIA non pubblica un elenco di compatibilità chiaro.
Lo sguardo in avanti ha due metà. Sul lato vicino, la mossa che conta di più non è una singola tecnica. È la standardizzazione. Il percorso DirectX di Microsoft si sta spostando dai Cooperative Vectors verso un'algebra lineare più ampia a livello di shader, che potrebbe permettere ai motori di affrontare carichi di stampo neurale senza puntare su una sola marca di GPU. Sul lato lontano, i ricercatori di NVIDIA hanno descritto un punto d'arrivo in un futuro lontano, talvolta proposto come un ipotetico "DLSS 10," in cui il renderer è interamente neurale e la pipeline classica è scomparsa (riportato di seconda mano da una tavola rotonda di Digital Foundry; trattalo come una direzione dichiarata, non come una roadmap). Il punto d'arrivo della scala è un sistema che genera un mondo coerente invece di disegnarne uno.
Vale la pena però mantenere lo scetticismo. Il dettaglio generato può divergere dall'intento artistico, e una rete può allucinare immagini plausibili ma sbagliate che non hanno equivalente tradizionale da debuggare: un problema di QA segnalato alla GDC 2026, e la sostanza dietro gran parte della reazione della "sbobba di IA". Costruire per dove sta andando la grafica non significa fingere che l'output attuale sia finito. Significa osservare quali fasi passano dal calcolare al predire in seguito, e giudicare ciascuna per ciò che fa all'immagine invece che per la parola che le è attaccata.
Domande frequenti
DLSS è rendering neurale?
Sì, ma è solo un tipo. DLSS è un'applicazione del rendering neurale: in particolare il livello in tempo reale dentro la pipeline, che copre l'upscaling con IA e la generazione di frame. Il termine più ampio precede DLSS e include anche metodi di ricostruzione di scene come NeRF e Gaussian Splatting e metodi generativi che inventano nuovo dettaglio d'immagine. Quindi ogni funzione di DLSS è rendering neurale, ma molto rendering neurale non è DLSS.
Qual è la differenza tra rendering neurale e ray tracing?
Il ray tracing simula la luce calcolando come i raggi rimbalzano attraverso una scena; il rendering neurale predice i risultati da una rete addestrata invece di calcolarli. Non sono rivali. Si combinano. Ray Reconstruction, per esempio, usa una rete neurale per ridurre il rumore dell'output ray-traced rumoroso, e la cache di radianza neurale predice la luce rimbalzata così che il ray tracer possa fermarsi prima. Le tecniche neurali rendono il ray tracing accessibile in tempo reale.
DLSS Frame Generation aggiunge latenza?
Sì. La generazione di frame gira dopo che un frame è renderizzato e inserisce frame predetti tra quelli renderizzati, il che aggiunge latenza invece di rimuoverla: il Reflex 2 di NVIDIA esiste specificamente per compensare. Aumenta la fluidità percepita (più frame mostrati) senza aumentare quanto velocemente il gioco si aggiorna e risponde all'input. Per il gioco competitivo è un compromesso; per la fluidità in singolo giocatore è di solito una vittoria netta.
NeRF è in tempo reale?
Dipende da quale tecnica intendi. Il NeRF originale non è in tempo reale. Il 3D Gaussian Splatting, un metodo successivo, si avvicina al tempo reale per le scene statiche. I renderer neurali completi che disegnano un intero frame con una rete sono solo da ricerca e lontani dalle velocità interattive. "NeRF" è spesso usato in modo lasco per coprire diversi metodi con prestazioni molto diverse, che è la fonte di gran parte della confusione.
Il rendering neurale sostituirà la rasterizzazione?
Non presto. I sistemi di oggi sono ibridi: i componenti neurali girano dentro una pipeline di rasterizzazione e ray tracing, non al suo posto. Sostituire interamente la pipeline classica con un singolo renderer generativo è un obiettivo di ricerca a lungo orizzonte, non un prodotto a breve termine. La direzione realistica è che più fasi della pipeline passino col tempo da calcolate a predette, con la rasterizzazione che fa ancora lavoro reale per anni.
Cos'è la compressione neurale delle texture?
La compressione neurale delle texture (NTC) è un metodo neurale che comprime insieme tutti i canali di texture di un materiale (colore, normali, rugosità e il resto), raggiungendo fino a 8 volte di risparmio di VRAM rispetto alla compressione a blocchi tradizionale a parità di qualità visiva, secondo NVIDIA. Funziona apprendendo le correlazioni tra i canali che la compressione a blocchi, che comprime ogni canale separatamente, scarta. Il materiale compresso viene decodificato al volo al momento del rendering.


