
Scegliere una VPS GPU può sembrare travolgente quando hai davanti fogli tecnici pieni di numeri. I conteggi dei core saltano da 2.560 a 21.760, ma cosa significa?
Un CUDA core è un'unità di elaborazione parallela all'interno dei GPU NVIDIA che esegue migliaia di calcoli contemporaneamente, alimentando tutto, dall'addestramento AI al rendering 3D. Questa guida spiega come funzionano, come differiscono dai CPU e dai Tensor core, e quali conteggi di core corrispondono alle tue esigenze senza sprechi.
Cosa sono i core CUDA?

I CUDA core sono unità di elaborazione individuali all'interno dei GPU NVIDIA che eseguono istruzioni in parallelo. Qual è la fondazione della tecnologia CUDA core? Pensa a queste unità come piccoli lavoratori che affrontano contemporaneamente pezzi dello stesso compito.
NVIDIA ha introdotto CUDA (Compute Unified Device Architecture) nel 2006 per sfruttare la potenza dei GPU per l'elaborazione generale oltre la grafica. La documentazione ufficiale CUDA fornisce dettagli tecnici completi. Ogni unità esegue operazioni aritmetiche di base su numeri in virgola mobile, perfette per calcoli ripetitivi.
I moderni GPU NVIDIA integrano migliaia di queste unità in un singolo chip. I GPU consumer dell'ultima generazione contengono oltre 21.000 core, mentre i GPU per data center basati sull'architettura Hopper arrivano fino a 16.896. Queste unità lavorano insieme attraverso Streaming Multiprocessor (SM).
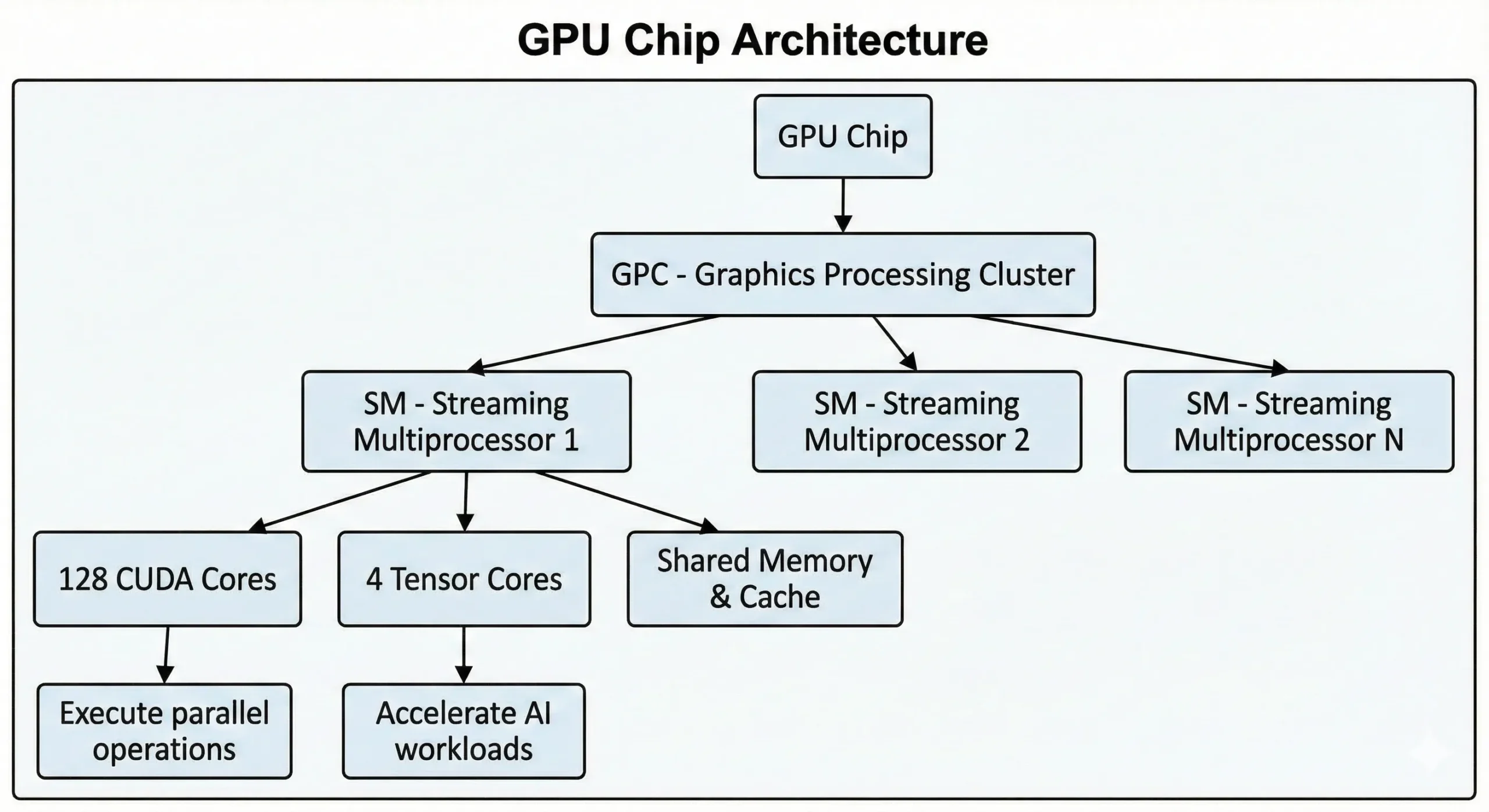
Le unità eseguono operazioni SIMT (Single Instruction, Multiple Threads) attraverso metodi di elaborazione parallela. Un'istruzione viene eseguita su molti punti dati contemporaneamente. Durante l'addestramento di reti neurali o il rendering di scene 3D, avvengono migliaia di operazioni simili. Dividono questo lavoro in flussi concorrenti, eseguendolo simultaneamente invece che sequenzialmente.
CUDA core vs CPU core: cosa li rende diversi?

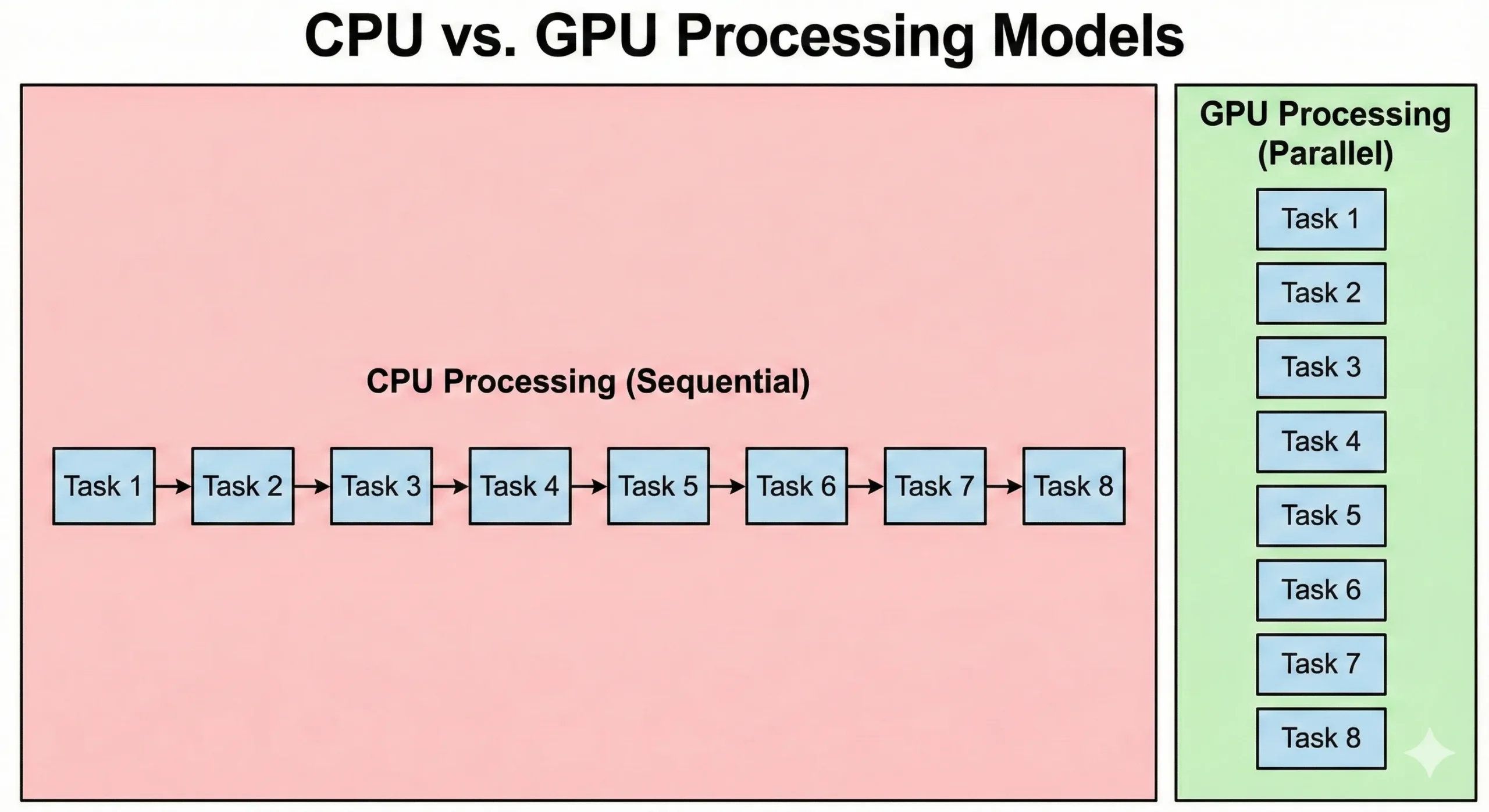
I CPU e i GPU risolvono i problemi in modi fondamentalmente diversi. Un moderno CPU server potrebbe avere 8-128+ core che funzionano ad alte velocità di clock. Questi processori eccellono nelle operazioni sequenziali dove ogni passaggio dipende dal risultato precedente. Gestiscono la logica complessa e la ramificazione in modo efficiente.
I GPU capovolgono questo approccio. Integrano migliaia di CUDA core più semplici che funzionano a velocità di clock inferiori. Queste unità compensano le velocità inferiori attraverso il parallelismo. Quando 16.000 lavorano insieme, il throughput totale supera la capacità di un CPU standard.
I CPU eseguono il codice del sistema operativo e la logica complessa dell'applicazione. Mentre i GPU danno priorità al throughput, l'overhead dall'inizializzazione dei task e dalla sincronizzazione determina latenze più alte. L'elaborazione grafica parallela dà priorità al movimento dei dati. Sebbene richiedano più tempo per avviarsi, elaborano grandi set di dati più velocemente dei CPU.
| Funzione | Nuclei CPU | Core CUDA |
| Numero per chip | 4-128+ core | 2.560-21.760 core |
| Velocità di clock | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Stile di elaborazione | Istruzioni sequenziali e complesse | Istruzioni parallele e semplici |
| Ideale per | Sistemi operativi, attività a singolo thread | Algebra lineare, elaborazione dati parallela |
| Latenza | Basso (microsecondi) | Maggiore (overhead di lancio) |
| Architettura | Generico | Specializzati per calcoli ripetitivi |
Le tecnologie Virtual GPU (vGPU) e Multi-Instance GPU (MIG) gestiscono il partizionamento delle risorse e la pianificazione per distribuire i processori fra più utenti. Questa configurazione consente ai team di massimizzare l'utilizzo dell'hardware attraverso la condivisione time-sliced o istanze hardware dedicate, a seconda delle esigenze.
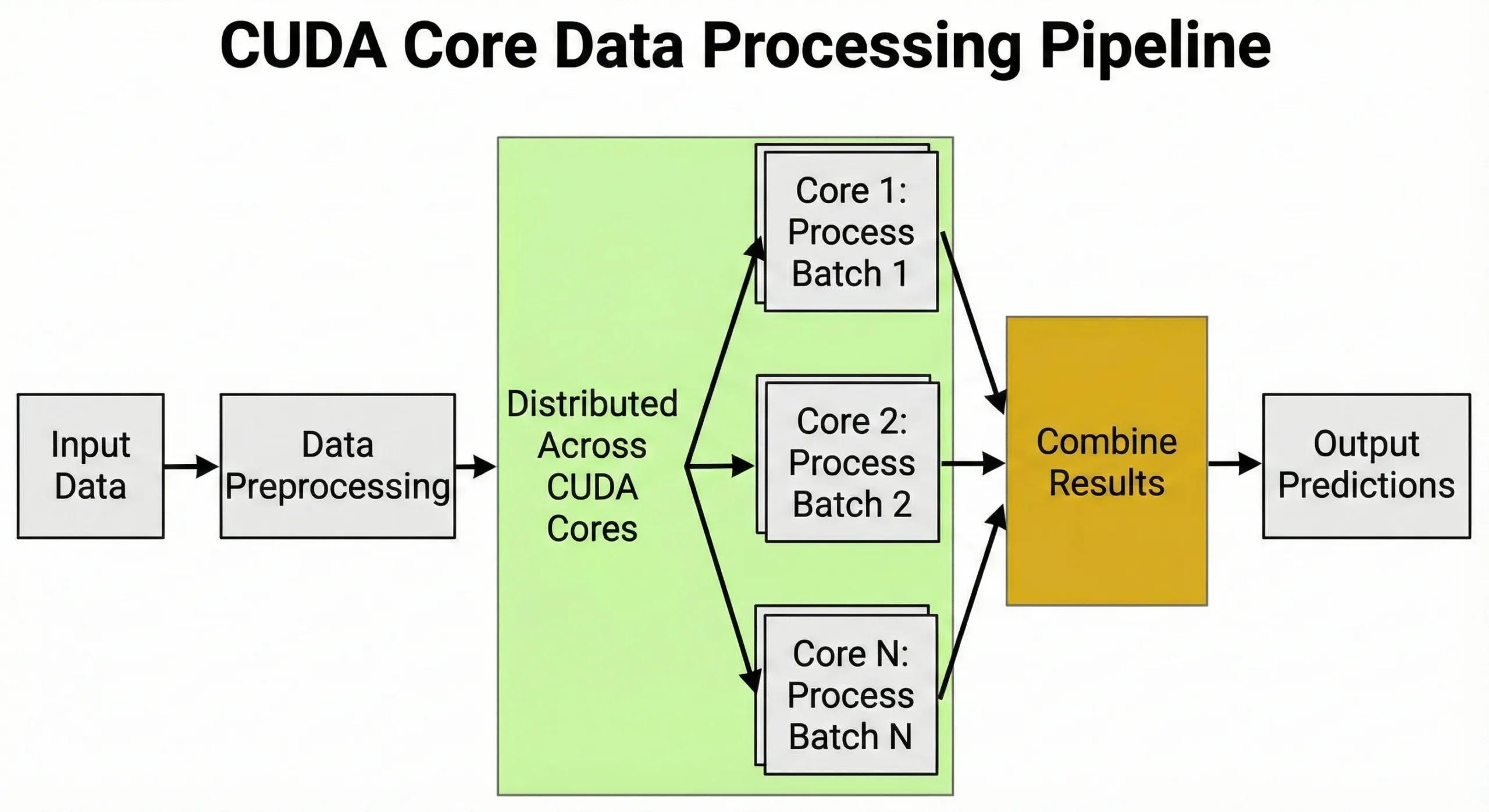
L'addestramento di reti neurali richiede miliardi di moltiplicazioni matriciali. Un GPU con 10.000 unità non esegue semplicemente 10.000 operazioni contemporaneamente; invece, gestisce migliaia di thread paralleli raggruppati in "warp" per massimizzare il throughput. Questo parallelismo massiccio è il motivo per cui queste unità sono fondamentali per chi sviluppa con l'IA.
CUDA Cores vs Tensor Cores: le differenze spiegate

Gli GPU di NVIDIA contengono due tipi di unità specializzate che lavorano insieme: core CUDA standard e Tensor core. Non sono tecnologie in competizione; affrontano diverse parti del carico di lavoro.
Le unità standard sono processori paralleli general-purpose che gestiscono i calcoli FP32 e FP64, la matematica intera e le trasformazioni di coordinate. Questa tecnologia CUDA fondamentale forma la base del calcolo GPU, eseguendo tutto, dalle simulazioni fisiche alla preparazione dei dati senza accelerazione specializzata.
I Tensor core sono unità specializzate progettate esclusivamente per la moltiplicazione matriciale e i compiti di IA. Introdotti nell'architettura Volta di NVIDIA (2017), eccellono nei calcoli di precisione FP16 e TF32. L'ultima generazione supporta FP8 per un'inferenza dell'IA ancora più veloce.
| Funzione | Core CUDA | Core Tensor |
| Scopo | Calcolo parallelo generale | Moltiplicazione matriciale per IA |
| Precisione | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Velocità per l'IA | 1x linea di base | 2-10x più veloce rispetto ai core CUDA |
| Casi d'uso | Preparazione dei dati, ML tradizionale | Addestramento e inferenza del deep learning |
| Disponibilità | Tutti gli GPU di NVIDIA | RTX 20 series e più recenti, GPU per data center |
Gli GPU moderni combinano entrambi. L'RTX 5090 ha 21.760 unità standard più 680 Tensor core di quinta generazione. L'H100 abbina 16.896 unità standard con 528 Tensor core di quarta generazione per l'accelerazione del deep learning.
Durante l'addestramento di reti neurali, i Tensor core svolgono il lavoro pesante durante il forward pass e il backward pass attraverso il modello. Le unità standard gestiscono il caricamento dei dati, la preparazione, i calcoli della loss e gli aggiornamenti dell'optimizer. Entrambi i tipi lavorano insieme, con i Tensor core che accelerano le operazioni computazionalmente intensive.
Per gli algoritmi di machine learning tradizionali come le random forest o il gradient boosting, le unità standard gestiscono il lavoro poiché questi non utilizzano i pattern di moltiplicazione matriciale che i Tensor core accelerano. Ma per i modelli transformer e le reti neurali convoluzionali, i Tensor core forniscono accelerazioni drammatiche.
A cosa servono i CUDA Core?

I core CUDA eseguono attività che richiedono molti calcoli identici simultaneamente. Qualsiasi operazione con matrici o calcoli numerici ripetuti beneficia dalla loro architettura.
Applicazioni di AI e Machine Learning
Il deep learning si basa su moltiplicazioni di matrici durante l'addestramento e l'inferenza. Quando addestri reti neurali, ogni forward pass richiede milioni di operazioni moltiplicative-additive su matrici di pesi. La backpropagation aggiunge milioni di operazioni durante il backward pass.
Le unità gestiscono il preprocessing dei dati, convertono immagini in tensori, normalizzano valori e applicano trasformazioni di augmentation. La capacità di gestire migliaia di attività contemporaneamente è esattamente il motivo per cui gli GPU sono importanti per l'AI.
Durante l'addestramento, supervisionano i schedule del learning rate, i calcoli dei gradienti e gli aggiornamenti dello stato dell'optimizer.
Per VPS per operazioni di AI inference che eseguono sistemi di raccomandazione o chatbot, elaborano le richieste concorrentemente, eseguendo centinaia di predizioni simultaneamente. La nostra guida su i migliori GPU per AI 2025 illustra quali configurazioni funzionano per diverse dimensioni di modelli.
Gli H100 con 16.896 unità combinate con Tensor core addestrano un modello da 7 miliardi di parametri in settimane anziché mesi. L'inferenza in tempo reale per chatbot che servono migliaia di utenti richiede una simile potenza di esecuzione concorrente.
Calcolo Scientifico e Ricerca
I ricercatori usano questi processori per simulazioni di dinamica molecolare, modellazione climatica e analisi genomica. Ogni calcolo è indipendente, rendendoli perfetti per l'esecuzione concorrente. Le istituzioni finanziarie eseguono simulazioni Monte Carlo con milioni di scenari contemporaneamente.
Rendering 3D e Produzione Video
Il ray tracing calcola il rimbalzo della luce attraverso scene 3D tracciando raggi indipendenti per ogni pixel. Mentre i core RT dedicati gestiscono l'attraversamento, le unità standard gestiscono il texture sampling e l'illuminazione. Questa divisione determina la velocità di scene con milioni di raggi.
NVENC gestisce la codifica per H.264 e H.265, mentre le architetture più recenti (Ada Lovelace e Hopper) introducono supporto hardware per AV1. CUDA aiuta con effetti, filtri, scaling, denoise, trasformazioni di colore e pipelines. Questo permette al motore di codifica di lavorare insieme ai processori paralleli per una produzione video più veloce.
Il rendering 3D in Blender o Maya distribuisce miliardi di calcoli di shader su superficie tra le unità disponibili. I sistemi di particelle beneficiano poiché simulano migliaia di particelle che interagiscono contemporaneamente. Queste caratteristiche sono fondamentali per la creazione digitale di alto livello.
Come i Core CUDA Impattano le Prestazioni di GPU

Il numero di core ti dà un'idea approssimativa della capacità di esecuzione concorrente, ma i core CUDA richiedono di andare oltre i numeri. La velocità di clock, la larghezza di banda della memoria, l'efficienza dell'architettura e l'ottimizzazione del software giocano tutti un ruolo importante.
Un GPU con 10.000 unità che funzionano a 2.0 GHz produce risultati diversi da uno con 10.000 a 1.5 GHz. Una velocità di clock più alta significa che ogni unità completa più calcoli al secondo. Le architetture più recenti concentrano più lavoro in ogni ciclo con una migliore pianificazione delle istruzioni.
Verifica se mantieni il dispositivo occupato, ma ricorda che nvidia-smi l'utilization è una metrica approssimativa. Misura la percentuale di tempo in cui un kernel è attivo, non quanti core stanno svolgendo lavoro.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderEsempio di output: 85%, 92% (85% tempo attivo, 92% attività del controller di memoria)
Se il tuo GPU mostra un'utilization tra il 60-70%, probabilmente hai colli di bottiglia a monte come il caricamento dati di CPU o batch size ridotti. Tuttavia, anche un'utilization del 100% può essere ingannevole se i tuoi kernel sono memory-bound o single-threaded. Per un quadro reale della saturazione dei core, usa profiler come Nsight Systems per tracciare le metriche 'SM Efficiency' o 'SM Active'.
La larghezza di banda della memoria spesso diventa il collo di bottiglia prima di esaurire la capacità di calcolo. Se il tuo GPU elabora i dati più velocemente di quanto la memoria li fornisca, le unità rimangono inattive. Il modello H100 SXM5 utilizza 3,35 TB/s di larghezza di banda per alimentare i suoi 16.896 core. La versione PCIe, però, la riduce a 2 TB/s.
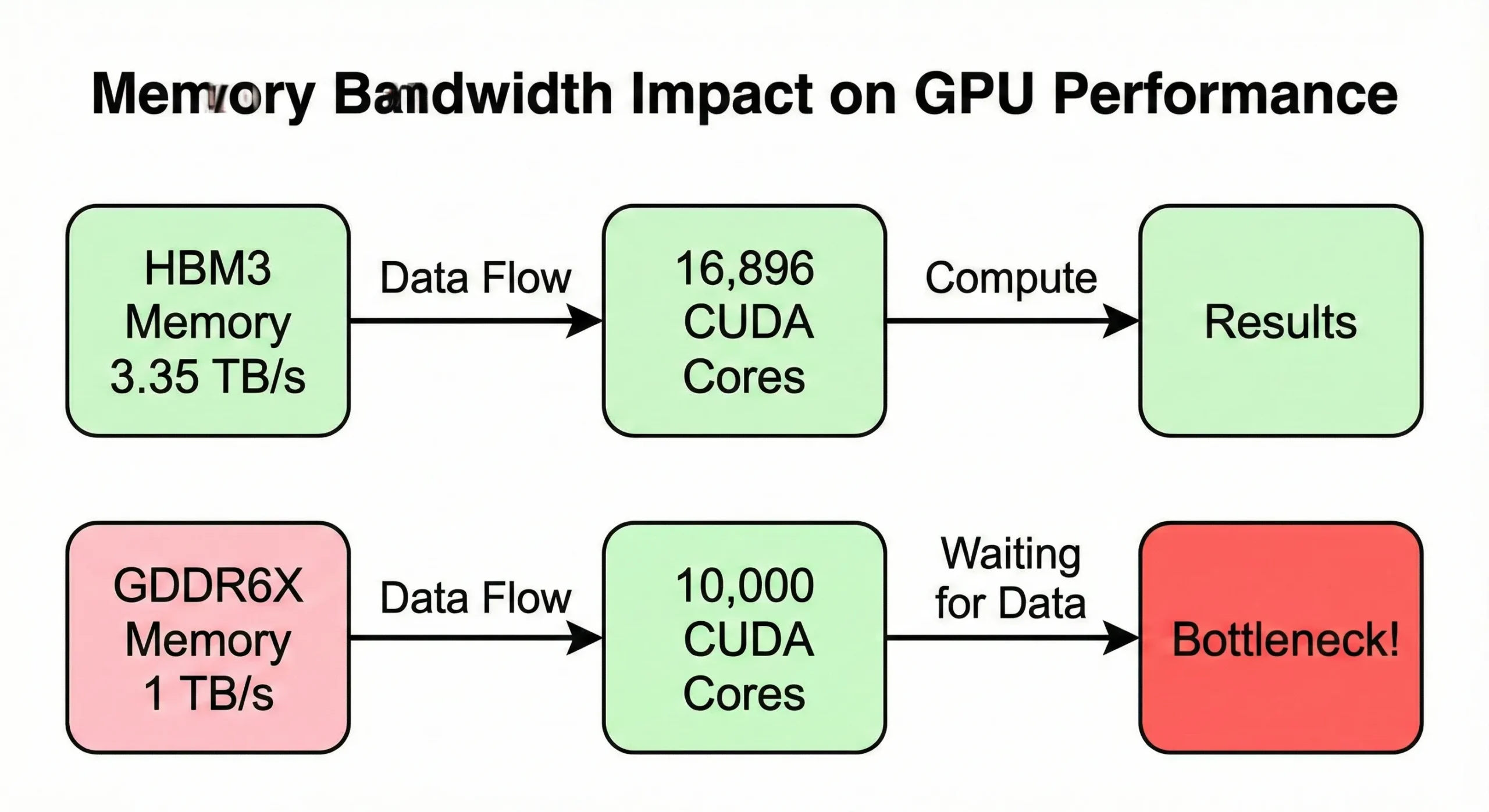
Gli GPU consumer con conteggi simili ma larghezza di banda inferiore (circa 1 TB/s) mostrano velocità ridotte nel mondo reale su operazioni intensive di memoria.
La capacità di VRAM determina le dimensioni dei tuoi task. Che si tratti di pesi FP16 per un modello 70B, l'addestramento completo richiede più memoria. Devi tenere conto dei gradienti e degli stati dell'ottimizzatore. Questi stati spesso triplicano l'impronta se non usi strategie di offload
L'A100 80GB è destinato all'inferenza e al fine-tuning ad alta velocità. Nel frattempo, l'RTX 4090 24GB, spesso citato per modelli 7B, può sorprendentemente eseguire modelli con più di 30B parametri se usi tecniche di quantizzazione moderne come INT4. Tuttavia, rimanere senza VRAM forza trasferimenti di dati CPU-GPU che distruggono il throughput.
L'ottimizzazione del software determina se il tuo codice utilizza effettivamente tutti quei core. I kernel scarsamente scritti potrebbero utilizzare solo una frazione delle risorse disponibili. Librerie come cuDNN per il deep learning e RAPIDS per la data science sono pesantemente ottimizzate per massimizzare l'utilizzo.
Più CUDA Core Non Sempre Significano Prestazioni Migliori

Acquistare un GPU con il conteggio di core più alto sembra logico, ma spreco soldi se i core superano altri componenti del sistema o il tuo task non scala con il conteggio dei core.
La larghezza di banda della memoria crea il primo limite. I 21.760 core dell'RTX 5090 sono alimentati da 1.792 GB/s di larghezza di banda della memoria. Gli GPU più vecchi con meno core potrebbero avere larghezza di banda proporzionalmente più alta per core.
Le differenze architettoniche contano. Un GPU più nuovo con 14.000 core a 2,2 GHz supera un GPU più vecchio con 16.000 a 1,8 GHz grazie a migliori istruzioni per clock. Il tuo codice ha bisogno di parallelizzazione adeguata per utilizzare 20.000 core in modo efficace.
Perché i CUDA Core Contano Quando Scegli GPU VPS

Scegliere la giusta configurazione CUDA core GPU per il tuo VPS evita di sprecare soldi su risorse inutilizzate o di colpire colli di bottiglia a metà progetto.
La memoria 80GB dell'H100 gestisce l'inferenza per modelli con parametri 70B usando quantizzazione a 4 bit. Per l'addestramento completo, però, anche 80GB è spesso insufficiente per un modello 34B una volta che consideri gradienti e stati dell'ottimizzatore. Nell'addestramento FP16, l'impronta di memoria si espande significativamente, spesso richiedendo sharding multi-GPU.
Le operazioni di inferenza che servono previsioni in tempo reale richiedono meno core ma traggono vantaggio dalla bassa latenza. Il lavoro di sviluppo e prototipazione funziona bene con GPU di fascia media per testare algoritmi e debuggare il codice.
Un RTX 4060 Ti con 4.352 core ti permette di testare senza pagare hardware eccessivo. Una volta convalidato il tuo approccio, scala fino agli GPU di produzione per esecuzioni di addestramento complete.
Il rendering e il lavoro video scalano con i core fino a un certo punto. Il renderer Cycles di Blender utilizza tutte le risorse disponibili in modo efficiente. Un GPU con 8.000-10.000 core renderizza scene 2-3 volte più velocemente di uno con 4.000.
Su Cloudzy, offriamo hosting ad alte prestazioni GPU VPS costruito per compiti pesanti. Scegli l'RTX 5090 o l'RTX 4090 per rendering veloce e inferenza AI conveniente, oppure scala fino agli A100 per carichi di lavoro di deep learning massiccia. Tutti i piani funzionano su una rete a 40 Gbps con politiche privacy-first e opzioni di pagamento in criptovaluta, fornendoti pura potenza senza il rosso di scena enterprise.
Che si tratti di addestrare modelli AI, renderizzare scene 3D o eseguire simulazioni scientifiche, scegli il conteggio di core che si adatta alle tue esigenze.
Le considerazioni di budget contano. Un A100 con 6.912 core costa significativamente meno di un H100 con 16.896. Per molte operazioni, due A100 forniscono un rapporto prezzo-velocità migliore rispetto a un H100. Il punto di pareggio dipende da se il tuo codice scala su più GPU.
Come Scegliere il Numero Giusto di CUDA Core
Adatta i tuoi requisiti alle caratteristiche effettive del carico di lavoro, piuttosto che inseguire i numeri più alti disponibili sul mercato.
Inizia profilando il tuo lavoro attuale. Se stai addestrando modelli su hardware locale o istanze cloud, controlla le metriche di utilizzo di GPU. Se l'utilizzo attuale di GPU è costantemente al 60-70%, non stai massimizzando i core.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Questo semplice benchmark mostra se i tuoi core GPU stanno fornendo il throughput previsto. Confronta i risultati con i benchmark pubblicati per il tuo modello GPU.
Un upgrade non aiuterà. Devi prima affrontare i colli di bottiglia come memoria, larghezza di banda o stalli di CPU. Poi stima i requisiti di memoria calcolando la dimensione del modello in byte più la memoria di attivazione.
Aggiungi la dimensione del batch per gli output dei layer e includi gli stati dell'ottimizzatore. Questo totale deve rientrare in VRAM. Una volta noti i requisiti di memoria, verifica quali GPU soddisfano questa soglia.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Considera i tuoi tempi. Se hai bisogno di risultati in poche ore, paga per più core. Gli addestramenti che possono durare giorni funzionano benissimo su GPU più piccoli con tempi di completamento proporzionalmente più lunghi.
Costo orario moltiplicato per le ore necessarie dà il costo totale, a volte rendendo gli GPU più lenti più convenienti complessivamente. Testa l'efficienza di scaling usando molti framework che forniscono strumenti di benchmarking che mostrano i cambiamenti di throughput.
Se raddoppiare i core fornisce solo 1,5x di velocità, gli extra non valgono il loro costo. Cerca i punti ideali dove il rapporto prezzo-velocità raggiunge il picco.
| Tipo di Carico di Lavoro | Core Consigliati | GPU di esempio | Note |
| Sviluppo e debug di modelli | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Iterazione rapida, costi ridotti |
| Addestramento AI su piccola scala (<7B parametri) | 6,000-10,000 | RTX 4090, L40S | Adatto a consumer e piccole imprese |
| Addestramento AI su larga scala (7B-70B parametri) | 14,000+ | A100, H100 | Richiede GPU per data center |
| Inferenza in tempo reale (throughput elevato) | 10,000-16,000 | RTX 5080, L40 | Equilibrio tra costo e prestazioni |
| Rendering 3D e codifica video | 8,000-12,000 | RTX 4080, RTX 4090 | Scala con la complessità |
| Calcolo scientifico e HPC | 10,000+ | A100, H100 | Richiede supporto FP64 |
VPS GPU Popolari e i Loro Conteggi CUDA Core

Diversi livelli di GPU servono diversi segmenti di utenti. Cos'è GPUaaS? È GPU-as-a-Service, dove provider come Cloudzy offrono accesso su richiesta a questi potenti GPU NVIDIA senza richiedere l'acquisto e la manutenzione di hardware fisico.
| Modello GPU | Core CUDA | VRAM | Larghezza di banda della memoria | Architettura | Ideale per |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Workstation di punta, rendering 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | AI di fascia alta, rendering 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Addestramento AI su larga scala |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | AI aziendale, datacenter conveniente |
| A100 | 6,912 | 40/80 GB HBM2e | 1.555-2.039 GB/s | Ampere | AI di fascia media, affidabilità provata |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, AI di fascia media |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Datacenter multi-workload |
Le schede RTX consumer (4070, 4080, 4090, 5080, 5090) sono pensate per creator e gamer, ma funzionano bene anche per lo sviluppo AI. Offrono buone prestazioni single-thread a prezzi inferiori rispetto alle schede datacenter.
I provider spesso stock questi modelli per clienti sensibili al costo. Le schede datacenter (A100, H100, L40) puntano su affidabilità, memoria ECC e scaling multi-thread. Gestiscono operazioni 24/7 e supportano funzionalità avanzate.
Multi-Instance GPU (MIG) ti permette di dividere una GPU in più istanze isolate. La A100 rimane popolare nonostante opzioni più recenti, grazie alle sue specifiche bilanciate.
Il suo equilibrio tra core NVIDIA, memoria e prezzo la rende la scelta sicura per la maggior parte delle operazioni AI in produzione. La H100 offre 2,4 volte più core ma costa significativamente di più.
Conclusione
I motori di elaborazione parallela rendono possibili l'AI moderno, il rendering e il calcolo scientifico. Capire come funzionano e interagiscono con la memoria, le velocità di clock e il software ti aiuta a scegliere le giuste configurazioni GPU.
Più core aiutano quando il tuo lavoro si parallelizza efficacemente, e componenti come la larghezza di banda della memoria riescono a tener dietro. Ma inseguire ciecamente il conteggio di core più alto spreca denaro se i tuoi colli di bottiglia sono altrove.
Inizia profilando le tue operazioni reali, identificando dove viene speso il tempo, e abbina le specifiche della GPU a quei requisiti senza acquistare capacità inutile.
Per la maggior parte del lavoro di sviluppo AI, 6.000-10.000 core offrono il miglior compromesso tra costo e capacità. Le operazioni in produzione, addestramento di modelli grandi o inference ad alto throughput traggono vantaggio da GPU con 14.000+ core come la H100.
Il rendering e il lavoro video si scalano efficientemente fino a circa 16.000 core, oltre il quale la larghezza di banda della memoria diventa il fattore limitante.


