
Uno degli aspetti più importanti, se non il più importante, del machine learning è ottenere previsioni accurate e affidabili. Un approccio innovativo per raggiungere questo obiettivo che ha guadagnato importanza è il bootstrap aggregating, più comunemente noto come bagging nel machine learning. Questo articolo affronterà il bagging nel machine learning, confronterà il bagging e il boosting nel machine learning, fornirà un esempio di bagging classifier, spiegherà come funziona il bagging, e esplorerà i vantaggi e gli svantaggi del bagging nel machine learning.
Che cos'è il bagging nel machine learning?
Queste due sono le uniche immagini rilevanti utilizzate negli articoli popolari, una o entrambe possono essere utilizzate (una qui e l'altra altrove) se faremo in modo che il design creasse versioni Cloudzy.
Cos'è il bagging?
Immagina di cercare di indovinare il peso di un oggetto chiedendo stime a più persone. Singolarmente, le loro supposizioni potrebbero variare notevolmente, ma facendo la media di tutte le stime, puoi arrivare a una cifra più affidabile. Questo è il concetto fondamentale del bagging: combinare gli output di più modelli per produrre una previsione più accurata e stabile.
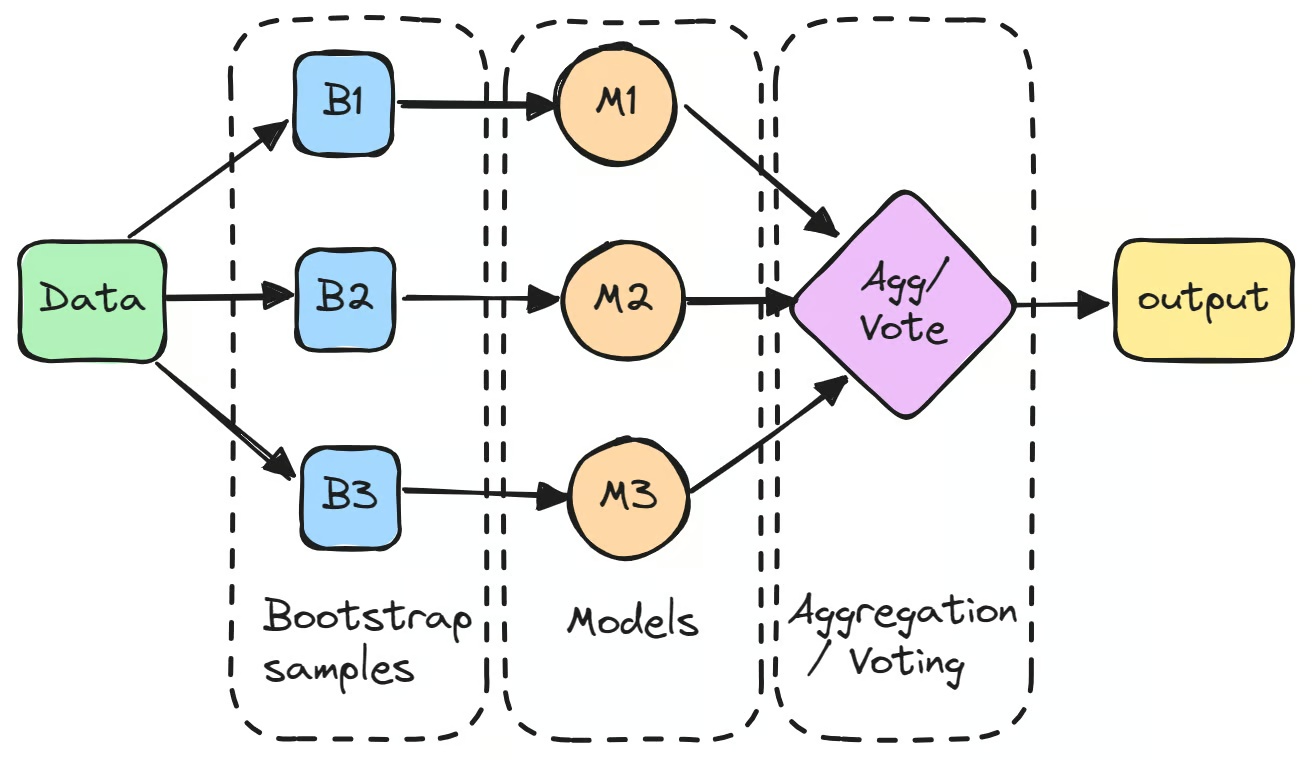
Il processo inizia creando più sottoinsiemi del dataset originale tramite bootstrapping, che è un campionamento casuale con reinserimento. Ogni sottoinsieme viene utilizzato per addestrare un modello separato in modo indipendente.
Questi modelli individuali, spesso chiamati "weak learner", potrebbero non performare eccezionalmente bene da soli a causa dell'alta varianza. Tuttavia, quando le loro previsioni vengono aggregate, tipicamente mediando per i compiti di regressione o tramite votazione maggioritaria per i compiti di classificazione, il risultato combinato spesso supera le prestazioni di qualunque singolo modello.
Un esempio noto di classificatore con bagging è l'algoritmo Random Forest, che costruisce un insieme di alberi decisionali per migliorare le prestazioni predittive. Detto questo, il bagging non deve essere confuso con il boosting in machine learning, che adotta un approccio diverso addestrando i modelli sequenzialmente per ridurre la distorsione. Il bagging funziona addestrando i modelli in parallelo per ridurre la varianza.
Sia il bagging che il boosting in machine learning puntano a migliorare le prestazioni del modello, ma si concentrano su aspetti diversi del comportamento del modello.
Perché il bagging è utile?
Uno dei principali vantaggi del bagging in machine learning è la sua capacità di ridurre la varianza, aiutando i modelli a generalizzare meglio su dati non visti. Il bagging è particolarmente vantaggioso quando si affrontano algoritmi sensibili alle fluttuazioni nei dati di addestramento, come gli alberi decisionali.
Prevenendo l'overfitting, assicura un modello più stabile e affidabile. Quando si confrontano bagging e boosting in machine learning, il bagging si concentra sulla riduzione della varianza addestrando più modelli in parallelo, mentre il boosting mira a ridurre la distorsione addestrando i modelli sequenzialmente.
Un esempio di bagging in machine learning si vede nella previsione del rischio finanziario, dove più alberi decisionali vengono addestrati su diversi sottoinsiemi di dati storici di mercato. Aggregando le loro previsioni, il bagging crea un modello di previsione più robusto, riducendo l'impatto degli errori dei singoli modelli.
In sostanza, il bagging in machine learning sfrutta la saggezza collettiva di più modelli per fornire previsioni che sono più accurate e affidabili rispetto a quelle derivate da singoli modelli.
Come Funziona il Bagging in Machine Learning: Passo dopo Passo
Per comprendere pienamente come il bagging migliora le prestazioni del modello, analizziamo il processo passo dopo passo.
Crea Più Campioni Bootstrap dal Dataset
Il primo passo nel bagging in machine learning è creare più nuovi sottoinsiemi del dataset originale utilizzando il bootstrapping. Questa tecnica comporta il campionamento casuale dei dati con reinserimento, così alcuni punti dati potrebbero apparire più volte nello stesso sottoinsieme, mentre altri potrebbero non apparire affatto. Questo processo viene fatto per assicurare che ogni modello sia addestrato su una versione leggermente diversa dei dati.
Addestra un Modello Separato su Ogni Campione
Ogni campione bootstrap viene quindi utilizzato per addestrare un modello separato, tipicamente dello stesso tipo, come gli alberi decisionali. Questi modelli, spesso chiamati "base learner" o "weak learner", vengono addestrati indipendentemente sui loro rispettivi sottoinsiemi. Un esempio di classificatore con bagging è l'albero decisionale utilizzato nell'algoritmo Random Forest, che forma la base di molti modelli basati su bagging. Sebbene ogni singolo modello potrebbe non performare bene da solo, ciascuno contribuisce intuizioni uniche basate sui loro specifici dati di addestramento.
Aggrega le Previsioni
Dopo aver addestrato i modelli, le loro previsioni vengono aggregate per formare l'output finale.
- Per i compiti di regressione, le previsioni vengono mediate, riducendo la varianza del modello.
- Per i compiti di classificazione, la previsione finale viene determinata tramite votazione maggioritaria, dove la classe prevista dalla maggior parte dei modelli viene selezionata. Questo metodo fornisce una previsione più stabile rispetto all'output di un singolo modello.
Previsione Finale
Combinando le previsioni da più modelli, il bagging riduce l'impatto degli errori di qualunque modello, migliorando l'accuratezza complessiva. Questo processo di aggregazione è ciò che rende il bagging una tecnica così potente, soprattutto nei compiti di machine learning dove vengono utilizzati modelli ad alta varianza come gli alberi decisionali. Effettivamente attenua le incongruenze nelle previsioni dei singoli modelli, risultando in un modello finale più forte.
Sebbene il bagging sia efficace per stabilizzare le previsioni, alcune cose da tenere a mente includono il rischio di overfitting se i modelli base sono troppo complessi, nonostante lo scopo generale del bagging sia ridurlo.
È anche computazionalmente costoso, quindi regolare il numero di base learner o considerare metodi ensemble più efficienti può aiutare. scegliere il GPU giusto per ML e DL è sempre importante.
Assicurati di avere una certa diversità di modelli tra i base learner per risultati migliori. Se lavori con dati squilibrati, tecniche come SMOTE possono essere utili prima di applicare il bagging per evitare scarse prestazioni sulle classi minoritarie.
Applicazioni del Bagging
Ora che abbiamo capito come funziona il bagging, vediamo dove viene realmente utilizzato. Il bagging si è diffuso in molti settori, aiutando a migliorare l'accuratezza e la stabilità delle previsioni in scenari complessi. Analizziamo insieme alcune delle applicazioni più importanti:
- Classificazione e Regressione: Il bagging è ampiamente usato per migliorare le prestazioni di classificatori e modelli di regressione riducendo la varianza e prevenendo l'overfitting. Ad esempio, le Random Forest, che sfruttano il bagging, sono efficaci in compiti come la classificazione di immagini e la modellazione predittiva.
- Rilevamento Anomalie In campi come la rilevazione delle frodi e il rilevamento delle intrusioni di rete, gli algoritmi di bagging offrono prestazioni superiori perché identificano efficacemente outlier e anomalie nei dati.
- Valutazione del Rischio Finanziario: Le tecniche di bagging sono impiegate nel settore bancario per migliorare i modelli di credit scoring, aumentando l'accuratezza dei processi di approvazione dei prestiti e delle valutazioni del rischio finanziario.
- Diagnostica Medica: In sanità, il bagging è stato applicato per rilevare disturbi neurocognitivi come l'Alzheimer analizzando dataset di risonanze magnetiche, supportando la diagnosi precoce e la pianificazione del trattamento.
- Elaborazione del Linguaggio Naturale (NLP): Il bagging contribuisce a compiti come la classificazione del testo e l'analisi del sentiment aggregando previsioni da più modelli, portando a una comprensione più robusta del linguaggio.
Vantaggi e Svantaggi del Bagging
Come ogni tecnica di machine learning, il bagging ha i suoi vantaggi e svantaggi. Comprenderli può aiutare a decidere quando e come usare il bagging nei tuoi modelli.
Vantaggi del Bagging:
- Riduce la Varianza e l'Overfitting: Uno dei vantaggi più importanti del bagging nel machine learning è la capacità di ridurre la varianza, che previene l'overfitting. Allenando più modelli su diversi sottoinsiemi dei dati, il bagging ti assicura che il modello non diventi troppo sensibile alle fluttuazioni nei dati di addestramento, ottenendo un modello più generalizzabile e stabile.
- Funziona Bene con Modelli ad Alta Varianza: Il bagging è particolarmente efficace quando utilizzato con modelli ad alta varianza come gli alberi decisionali. Questi modelli tendono a fare overfitting e hanno una varianza elevata, ma il bagging mitiga questo problema facendo la media o votando su più modelli. Questo rende le previsioni più affidabili e meno influenzate dal rumore nei dati.
- Migliora la Stabilità e le Prestazioni del Modello: Combinando più modelli addestrati su diversi sottoinsiemi dei dati, il bagging spesso porta a prestazioni complessive migliori. Aiuta a migliorare l'accuratezza predittiva riducendo la sensibilità del modello a piccoli cambiamenti nel dataset, il che rende il modello più affidabile.
Svantaggi del Bagging:
- Aumenta il Costo Computazionale: Poiché il bagging richiede l'addestramento di più modelli, naturalmente aumenta il costo computazionale. Allenare e aggregare le previsioni di molti modelli può essere dispendioso in termini di tempo, soprattutto quando si lavora con dataset grandi o modelli complessi come gli alberi decisionali.
- Non Efficace per Modelli a Bassa Varianza: Mentre il bagging è altamente efficace per modelli ad alta varianza, non fornisce molti benefici quando applicato a modelli a bassa varianza come la regressione lineare. In questi casi, i modelli individuali hanno già tassi di errore bassi, quindi aggregare le previsioni non migliora molto i risultati.
- Perdita di Interpretabilità: Con la combinazione di più modelli, il bagging può ridurre l'interpretabilità del modello finale. Ad esempio, in Random Forest, il processo decisionale si basa su più alberi decisionali, rendendo più difficile tracciare il ragionamento dietro una specifica previsione.
Quando Devo Usare il Bagging?
Saper riconoscere quando applicare il bagging nei progetti di machine learning è fondamentale per ottenere risultati ottimali. Questa tecnica funziona bene in situazioni specifiche, ma non è sempre la scelta migliore per ogni problema.
Quando il Tuo Modello è Soggetto all'Overfitting
Uno dei principali casi d'uso del bagging è quando il tuo modello è soggetto all'overfitting, soprattutto con modelli ad alta varianza come gli alberi decisionali. Questi modelli possono funzionare bene sui dati di addestramento ma spesso non riescono a generalizzare ai dati non visti, perché si adattano troppo strettamente ai pattern specifici del set di addestramento.
Il bagging aiuta a combattere questo problema addestrando più modelli su diversi sottoinsiemi dei dati e utilizzando la media o il voto per creare una previsione più stabile. Questo riduce la probabilità di overfitting, rendendo il modello migliore nel gestire dati nuovi e non visti.
Quando Vuoi Migliorare la Stabilità e l'Accuratezza
Se vuoi migliorare la stabilità e l'accuratezza del tuo modello senza compromettere troppo l'interpretabilità, il bagging è una scelta eccellente. L'aggregazione delle previsioni da più modelli rende il risultato finale più potente, il che è particolarmente utile per attività che coinvolgono dati rumorosi.
Che tu stia affrontando problemi di classificazione o compiti di regressione, il bagging può aiutare a produrre risultati più coerenti, aumentando l'accuratezza mantenendo l'efficienza.
Quando Hai Risorse Computazionali Sufficienti
Un altro fattore importante nel decidere se utilizzare il bagging è la disponibilità di risorse computazionali. Poiché il bagging richiede l'addestramento di più modelli simultaneamente, il costo computazionale può diventare significativo, soprattutto con dataset di grandi dimensioni o modelli complessi.
Se hai accesso alla potenza computazionale necessaria, i vantaggi del bagging superano di gran lunga i costi. Tuttavia, se le risorse sono limitate, potresti voler considerare tecniche alternative o limitare il numero di modelli nel tuo ensemble.
Quando Lavori con Modelli ad Alta Varianza
Il bagging è particolarmente utile quando si lavora con modelli che hanno alta varianza e sono sensibili alle fluttuazioni nei dati di addestramento. Gli alberi decisionali, ad esempio, sono spesso utilizzati con il bagging nella forma di Random Forests perché le loro prestazioni tendono a variare notevolmente in base ai dati di addestramento.
Addestrando più modelli su diversi sottoinsiemi di dati e combinando le loro previsioni, il bagging riduce la varianza, portando a un modello più affidabile.
Quando Hai Bisogno di un Classificatore Robusto
Se stai lavorando a problemi di classificazione e hai bisogno di un classificatore robusto, il bagging può migliorare significativamente la stabilità delle tue previsioni. Ad esempio, una Random Forest, che è un esempio di classificatore basato su bagging, può fornire una previsione più accurata aggregando i risultati di molti alberi decisionali individuali.
Questo approccio funziona bene quando i modelli individuali potrebbero essere deboli, ma la loro forza combinata risulta in un modello complessivo potente.
Inoltre, se stai cercando la piattaforma giusta per implementare le tecniche di bagging in modo efficiente, strumenti come Databricks e Snowflake forniscono una piattaforma di analitiche unificata che può essere molto utile per gestire dataset di grandi dimensioni ed eseguire metodi ensemble come il bagging.
Se stai cercando un approccio meno tecnico al machine learning, strumenti di intelligenza artificiale senza codice potrebbero essere un'opzione. Sebbene non si concentrino direttamente su tecniche avanzate come il bagging, molte piattaforme no-code consentono agli utenti di sperimentare metodi di ensemble learning, incluso il bagging, senza aver bisogno di competenze di codifica estese.
Questo ti permette di applicare tecniche più sofisticate e comunque ottenere previsioni accurate, concentrandoti sulle prestazioni del modello piuttosto che sul codice sottostante.
Considerazioni finali
Il bagging nel machine learning è una tecnica potente che migliora le prestazioni del modello riducendo la varianza e migliorando la stabilità. Aggregando le previsioni di più modelli addestrati su diversi sottoinsiemi di dati, il bagging aiuta a creare risultati più accurati e affidabili. È particolarmente efficace per modelli ad alta varianza come gli alberi decisionali, dove aiuta a prevenire l'overfitting e assicura che il modello generalizzi meglio ai dati non visti.
Sebbene il bagging abbia vantaggi significativi, come ridurre l'overfitting e migliorare l'accuratezza, presenta alcuni compromessi. Aumenta il costo computazionale a causa dell'addestramento di più modelli e può ridurre l'interpretabilità. Nonostante questi inconvenienti, la sua capacità di migliorare le prestazioni lo rende una tecnica preziosa nell'ensemble learning, insieme ad altri metodi come il boosting e lo stacking.
Hai usato il bagging in progetti di machine learning? Raccontaci la tua esperienza e come ha funzionato per te!


