
Negli anni '60 e '70, architettura monolitica era preferito per lo sviluppo di applicazioni a causa delle risorse di calcolo limitate, che richiedevano di combinare tutte le funzionalità in un'unica unità coesa.
Fino alla fine degli anni '90 e agli anni 2000, quando la struttura monolitica iniziò a diventare troppo limitante per la crescente dimensione e complessità delle applicazioni, soprattutto con l'aumento di internet e dei sistemi distribuiti.
Questo portò allo sviluppo di approcci più modulari, come architetture orientate ai servizi (SOA) e, più tardi, architetture a microservizi (MSA), che divennero prominenti nei primi anni 2010.
Detto questo, questa è solo una breve spiegazione del concetto e dell'uso di base dei microservizi. Discutiamo quindi di come i microservizi hanno sostituito l'architettura monolitica, come funzionano i microservizi e alcuni esempi. Successivamente, affronteremo gli aspetti chiave del deployment dei microservizi e cosa fare se vuoi implementarli.
Cosa sono i microservizi? Come funzionano?
Come ho accennato in precedenza, i microservizi sono emersi come una soluzione alla crescente complessità e dimensione delle applicazioni, permettendo alle aziende di scomporre le funzioni in servizi distribuibili in modo indipendente.
Il termine "microservizi" è stato reso popolare da esperti del settore come Martin Fowler e James Lewis, che lo hanno formalmente introdotto in un articolo nel 2014. Il loro lavoro ha definito i principi e le caratteristiche chiave, inclusa la necessità di servizi distribuibili indipendentemente, la gestione decentralizzata dei dati e l'indipendenza tecnologica.
Da allora i microservizi sono diventati una scelta architettonica mainstream, supportata da progressi in tecnologie di containerizzazione come Docker, strumenti di orchestrazione come Kubernetes e piattaforme di serverless computing. Ma come funzionano i microservizi?
Come funzionano i microservizi?
Un'architettura a microservizi divide un'applicazione grande in servizi più piccoli e distinti, ognuno responsabile di una specifica capacità di business. Questi servizi comunicano tra loro in rete, spesso tramite REST APIs, gRPC o message broker come RabbitMQ o Apache Kafka.
Secondo la definizione di Martin Fowler e James Lewis, i microservizi hanno quattro caratteristiche fondamentali:
- Responsabilità Singola: Ogni microservizio è progettato per eseguire un compito o una funzione specifica, permettendo specializzazione e riducendo la complessità.
- Indipendenza: I microservizi possono essere sviluppati, deployati e scalati indipendentemente l'uno dall'altro, offrendo flessibilità e resilienza.
- Gestione dati decentralizzata: I microservizi spesso hanno i propri database, evitando la necessità di un database centralizzato unico.
- Indipendenza Tecnologica: I team possono scegliere la tecnologia migliore per ogni servizio senza essere vincolati dalle scelte di altri servizi.
Questo approccio contrasta con l'architettura monolitica tradizionale, in cui tutti i componenti dell'applicazione sono strettamente integrati in un'unità coesa.
Fasi chiave del deployment di microservizi
Sebbene un'architettura a microservizi offra numerosi vantaggi come alta scalabilità, flessibilità, efficienza e isolamento dei guasti, richiede di sapere come deployare i microservizi in modo efficace e una buona dose di pianificazione per riuscirvi.
Per questo è essenziale avere una comprensione completa dei concetti chiave, delle fasi e delle best practice dei microservizi nel loro deployment, al fine di ottenere un'architettura a microservizi di successo. Vediamo quindi le fasi chiave del deployment di microservizi e cosa comporta ogni fase.
Pianificazione e preparazione del deployment di microservizi
Tutte le cose buone richiedono pianificazione e pazienza, e per deployare i microservizi con successo avrai sicuramente bisogno di una buona dose di entrambe. Per questo è importante seguire le best practice dei microservizi e pianificare e preparare tutto ciò di cui hai bisogno quando distribuisci i microservizi.
Come ho menzionato in precedenza, uno dei principi e delle caratteristiche chiave dei microservizi è il Principio della Responsabilità Singola. Restando fedele a questo principio e assicurandoti che ogni microservizio si concentri su e sia responsabile di una funzione e una capacità, consentirai al tuo team di sviluppare, deployare e scalare i servizi in modo indipendente.
Inoltre, una sottocategoria di questo principio è il principio di progettazione a basso accoppiamento. Questo significa che ogni servizio può funzionare in modo indipendente per la comunicazione e dipende minimamente da altri servizi. A sua volta, questo consente ai cambiamenti o agli aggiornamenti di un servizio di non influenzare altri servizi, permettendo un scaling indipendente dei microservizi.
Questo riduce il rischio di cascading failures, in cui un problema o un guasto in una parte del sistema innesca una reazione a catena, portando a guasti in tutto il sistema e causando l'interruzione dell'intero servizio.
Una pratica importante nei microservizi è avere uno storage dati dedicato per ogni servizio quando distribuisci i microservizi come estensione del loose coupling design principle, poiché ciò previene conflitti e consente una migliore scalabilità del servizio.
Inoltre, avrai bisogno di modelli di comunicazione asincrona tra microservizi, come i message broker, per garantire che ogni servizio possa comunicare senza dipendenze dirette.
L'ultimo pezzo del puzzle è implementare pipeline di Continuous Integration e Continuous Delivery (CI/CD) per i microservizi. Queste pipeline permettono ai team di distribuire nuove funzionalità o correzioni attraverso Strumenti CI/CD come Jenkins e GitLab, permettendo alle organizzazioni di mantenere la stabilità del sistema mentre rilasciano frequentemente nuove capacità.
Ora che hai una panoramica generale della pianificazione e della preparazione necessarie per il deployment dei microservizi, parliamo delle strategie di deployment dei microservizi.
Strategie di Deployment dei Microservizi
Quando distribuisci microservizi, la scelta della strategia di deployment dipende dalla funzione del servizio, dal traffico, dall'infrastruttura, dalla competenza del team e dalle considerazioni di costo. In generale, le strategie di deployment dei microservizi sono le seguenti:
- Istanza di Servizio per Contenitore: In questo approccio, ogni microservizio gira nel suo container, offrendo un isolamento migliore rispetto al modello con istanze multiple per host. I container facilitano il scaling facile e migliorano l'allocazione delle risorse.
- Istanza di servizio per macchina virtuale: Ogni servizio gira in una macchina virtuale (VM) separata, fornendo ancora maggior isolamento rispetto ai container. Anche se migliora la sicurezza e la stabilità, generalmente comporta più overhead.
- Rilasci Graduali: Inizialmente, distribuisci versioni di microservizi a un piccolo gruppo di utenti, testando la loro stabilità prima di un rollout completo. Questo approccio minimizza l'impatto se sorgono problemi e consente rollback rapidi per mantenere l'integrità del sistema.
- Distribuzione Blue-Green: Questo metodo usa due ambienti di produzione identici, con un ambiente che serve il traffico live mentre l'altro viene usato per testare il prossimo rilascio. Il blue-green deployment consente rollback facili e aggiornamenti a zero downtime, poiché il traffico può essere spostato facilmente tra i due ambienti.
- Rilasci Graduali: Questa strategia implica un rollout graduale degli aggiornamenti a diversi segmenti di utenti o ambienti. Spesso inizia con ambienti interni prima di raggiungere la produzione, limitando l'impatto di eventuali problemi e permettendo ai team di affrontarli per fasi.
- Distribuzione Senza Server: Questo approccio sfrutta piattaforme serverless come AWS Fargate e Google Cloud Run, che automatizzano la gestione dell'infrastruttura gestendo il scaling e l'allocazione delle risorse per te. Con il deployment serverless, non c'è bisogno di gestire i server sottostanti, permettendoti di concentrarti sui tuoi microservizi stessi.
Una volta scelta una delle strategie di deployment dei microservizi qui sopra, avrai bisogno di uno strumento di orchestrazione dei microservizi.
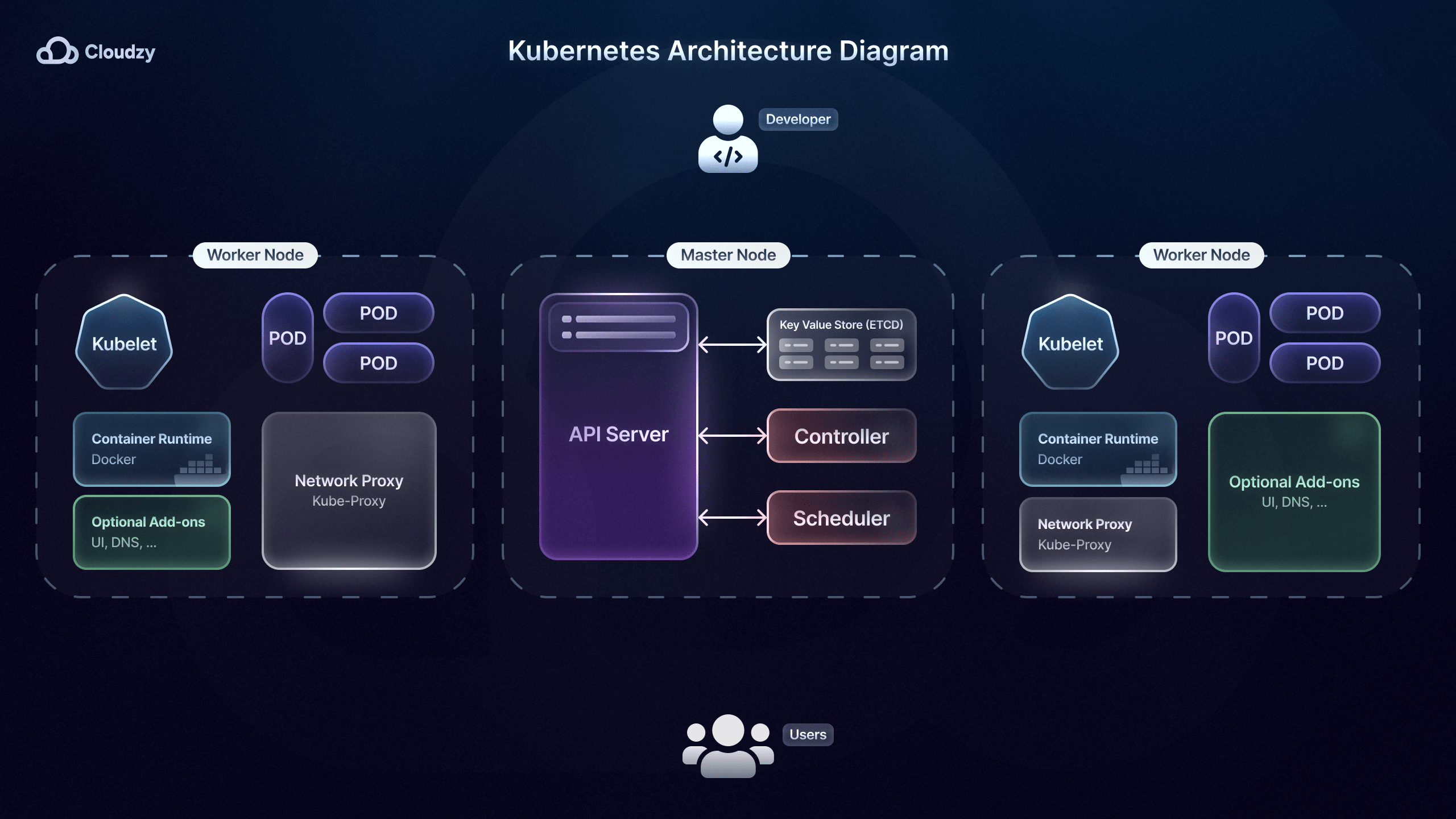
Orchestrazione dei Microservizi
Dopo aver scelto una delle tante strategie di deployment dei microservizi, avrai bisogno di una specie di direttore d'orchestra per l'orchestrazione dei microservizi. Strumenti di orchestrazione dei microservizi, come Kubernetes, aiutano ad automatizzare il deployment dei microservizi, il scaling dei microservizi, il monitoraggio dei microservizi e la gestione dei microservizi containerizzati.
Airbnb, ad esempio, usa Kubernetes, permettendo ai suoi ingegneri di distribuire centinaia di modifiche ai loro microservizi senza supervisione manuale. Una caratteristica importante degli strumenti di orchestrazione dei microservizi come Kubernetes è il bilanciamento del carico integrato.
Una caratteristica di bilanciamento del carico competente aiuta a distribuire il traffico in entrata tra più istanze di un microservizio. Questo previene che una singola istanza diventi un collo di bottiglia e migliora la capacità del sistema di gestire picchi di traffico.
Kubernetes gioca un ruolo significativo nella gestione dei microservizi attraverso le sue capacità di auto-guarigione, dove i container non funzionanti vengono automaticamente sostituiti e riavviati. Il New York Times sfrutta questa caratteristica per mantenere i suoi microservizi senza impattare l'esperienza dell'utente e tempi di fermo.
Inoltre, Kubernetes migliora anche la sicurezza dei microservizi in quanto le configurazioni e i segreti, come le credenziali del database o le chiavi API, vengono gestiti tramite ConfigMaps e Secrets. Questo è particolarmente importante per aziende e servizi, come Uber, che gestiscono informazioni sensibili di clienti e utenti.
Infine, strumenti di orchestrazione dei microservizi come Kubernetes sono particolarmente vantaggiosi per le strategie di microservizi che implicano aggiornamenti rolling e rollback, come i rilasci in fasi. Gli aggiornamenti rolling permettono alle nuove versioni di microservizi di essere distribuite senza interruzioni del servizio mantenendo alcune istanze della versione precedente in esecuzione.
Una volta configurato il tuo strumento di orchestrazione dei microservizi, avrai bisogno di costruire e automatizzare Pipeline CI/CD per il deployment di microservizi.
Pipeline CI/CD per il deployment di microservizi
Come abbiamo visto, le pipeline di Continuous Integration e Continuous Delivery per i microservizi sono componenti essenziali del loro deployment. Le pipeline CD sono responsabili di distribuire automaticamente i cambiamenti di codice in produzione non appena superano le fasi di testing e integrazione.
Quando i cambiamenti di codice superano le fasi di testing e integrazione, la parte CD della pipeline entra in gioco e il servizio viene distribuito a uno strumento di orchestrazione di microservizi come un cluster Kubernetes.
Inoltre, le fasi di testing e integrazione sono completamente automatizzate nella pipeline CI/CD: test unitari, test di integrazione e test end-to-end sono incorporati nel processo.
Questo consente ai team di validare gli aggiornamenti ad ogni stage mantenendo la stabilità del sistema. E se qualcosa va storto nel codice, anche dopo tutti i test, i rollback automatici ripristinano la versione stabile precedente.
Infine, implementare pipeline CI/CD per microservizi seguendo le best practice aiuta le organizzazioni a sviluppare più velocemente, ridurre gli errori manuali e mantenere elevati standard di qualità.
Molte aziende come Spotify, Expedia, iRobot, Lufthansa, Pandora e altre usano pipeline CI/CD per microservizi attraverso strumenti come CircleCI, AWS CodePipeline e GitLab per automatizzare il deployment, garantire la coerenza della qualità del codice e rilasciare rapidamente nuove funzionalità mantenendo la stabilità del sistema.
Modelli di comunicazione tra microservizi
Il modo in cui i microservizi comunicano tra loro dipende interamente dalla loro funzione, dall'architettura complessiva, dalla scalabilità desiderata e dall'affidabilità. In generale, ci sono due categorie principali di modelli di comunicazione: sincrono e i piani asincrono modelli di comunicazione tra microservizi.
Nei modelli di comunicazione sincroni, i servizi interagiscono in tempo reale: un servizio invia una richiesta e attende una risposta prima di procedere. I modelli sincroni più comuni sono: REST (Representational State Transfer) API, gRPC (Go Google Remote Procedure Call), e GraphQL.
Questo tipo di comunicazione si usa soprattutto in settori che richiedono l'elaborazione dei dati in tempo reale e risposte immediate. Finanza, sanità ed e-commerce usano frequentemente la comunicazione sincrona per garantire che transazioni, recupero dati e interazioni avvengano istantaneamente, offrendo un'esperienza utente fluida e reattiva.
Detto questo, sebbene la comunicazione sincrona offra vantaggi come risposte in tempo reale e semplicità, presenta anche svantaggi: potenziali colli di bottiglia dovuti all'accoppiamento stretto, bassa scalabilità sotto carico, tempi di risposta lenti e latenza elevata durante picchi di traffico.
I modelli di comunicazione asincroni, al contrario, sono in genere più adatti ai microservizi poiché si basano sul principio di Loose Coupling che abbiamo discusso in precedenza.
Questo modello disaccoppia i servizi permettendo loro di inviare e ricevere messaggi tramite un broker come Kafka o RabbitMQ. Inviando messaggi a una coda che funge da buffer, i servizi comunicano indipendentemente senza attendere una risposta come accade nella comunicazione sincrona. Questo buffer consente agli altri servizi di elaborare i messaggi al loro ritmo, permettendo al mittente di continuare il suo lavoro senza aspettare il destinatario.
La comunicazione asincrona non solo disaccoppia i servizi nel deployment di microservizi, ma offre anche la stessa reattività in tempo reale della comunicazione sincrona.
Questo è dovuto all'architettura event-driven della comunicazione asincrona: i servizi comunicano emettendo eventi quando accade un'azione specifica. Gli altri servizi si iscrivono a questi eventi e reagiscono di conseguenza. Questo permette sistemi altamente reattivi che rispondono ai cambiamenti in tempo reale senza accoppiamento diretto tra i servizi.
Inoltre, in asincrono Pubblicazione-Sottoscrizione (Pub/Sub) in questo modello, i servizi publisher inviano messaggi a un topic e gli altri servizi subscriber ascoltano quel topic per ricevere gli aggiornamenti. Questo modello supporta più sottoscrittori, trasmettendo simultaneamente messaggi a molti servizi.
Infine, come nei modelli event-driven, i modelli asincroni di comunicazione saga basata su choreography tra microservizi usano anch'essi gli eventi per comunicare; tuttavia, in questo modello esiste un ordine specifico: gli eventi attivano il passo successivo e attivano un particolare servizio.
La differenza qui è che nei pattern guidati dagli eventi non esiste una sequenza o un flusso predeterminato, e più servizi possono reagire a un evento anziché seguire un processo e un ordine specifici come nel pattern saga basato su coreografia.
Il tipo di pattern di comunicazione asincrona tra microservizi che utilizzi dipende dall'attività e dalla funzione complessiva dei tuoi microservizi. Code di messaggi come RabbitMQ e Amazon SQS vengono generalmente usate per la pianificazione delle attività, la distribuzione dei carichi di lavoro, e nell'e-commerce per l'elaborazione degli ordini e i sistemi di notifica.
I broker di messaggi guidati dagli eventi, come Apache Kafka e AWS EventBridge, vengono generalmente usati per elaborare flussi di eventi su larga scala in tempo reale e per il routing degli eventi tra microservizi in settori come i servizi finanziari e gli ambienti AWS.
Per i broker di messaggi Publish-Subscribe (Pub/Sub) come Google Cloud Pub/Sub e Redis Streams, questi broker di messaggi vengono solitamente utilizzati per la messaggistica scalabile su sistemi distribuiti, per l'analisi in tempo reale e l'acquisizione di eventi, nonché per notifiche in tempo reale e applicazioni di chat.
Infine, i broker di messaggi saga basati su coreografia vengono principalmente usati per l'elaborazione degli ordini dell'e-commerce, i sistemi di prenotazione di viaggi, e per casi in cui transazioni complesse e multi-step devono essere coordinate tra più servizi senza controllo centralizzato.
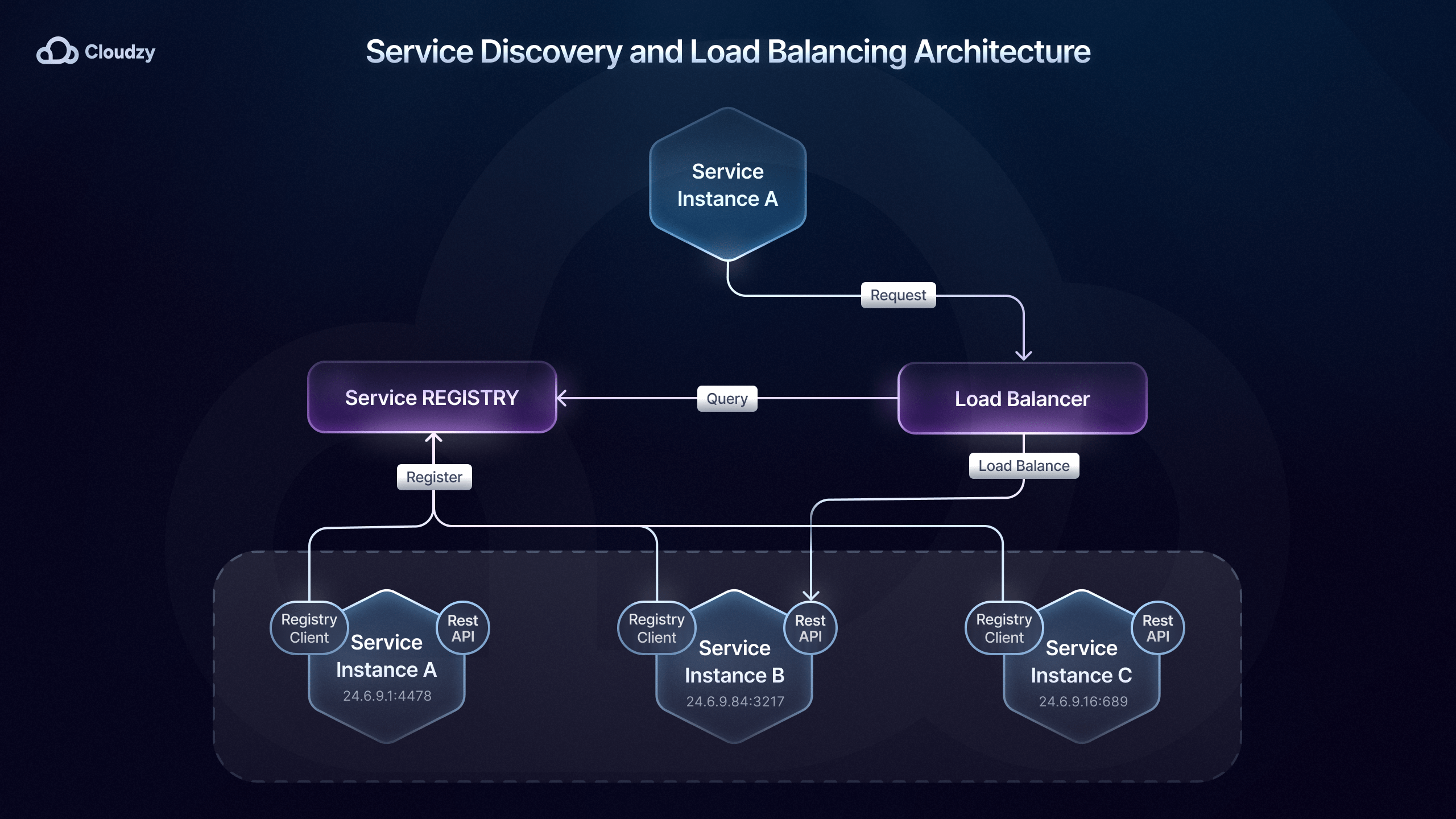
Service discovery per microservizi
Una volta configurato e implementato un pattern di comunicazione adatto alle tue esigenze, dovrai assicurarti che i tuoi servizi possano localizzarsi l'uno con l'altro. Come ho menzionato in precedenza, i tool di orchestrazione dei microservizi come Kubernetes giocano un ruolo importante nella service discovery dei microservizi.
Questo avviene attraverso la service discovery integrata che Kubernetes DNS fornisce, che aggiorna dinamicamente gli indirizzi IP e i record DNS mentre i servizi si ridimensionano o cambiano posizione all'interno del cluster.
Questo metodo di service discovery per microservizi è chiamato server-side discovery perché la responsabilità del routing è delegata a un load balancer, che interroga il registro e indirizza il traffico all'istanza appropriata.
D'altro canto, abbiamo anche il metodo client-side discovery per la service discovery dei microservizi, dove il servizio o il gateway API interroga un service registry come Consul o Eureka per trovare le istanze disponibili.
La scelta del metodo di service discovery migliore per il tuo deployment di microservizi dipende dai requisiti e dalla scala del sistema.
Con la service discovery client-side dei microservizi, il client ha il pieno controllo su quale istanza contattare. Questo non solo consente una maggiore personalizzazione ma riduce anche la complessità, poiché non è necessario un servizio di discovery centralizzato.
Ad esempio, il deployment di microservizi di Netflix utilizza la service discovery client-side con Eureka e Ribbon per il bilanciamento del carico, consentendo al client di scegliere l'istanza migliore in base a criteri come la latenza e il carico del server.
Tuttavia, la service discovery server-side dei microservizi è più adatta per ambienti più grandi poiché una service discovery centralizzata può migliorare l'efficienza e consentire un bilanciamento del carico coerente su un sistema distribuito.
Le soluzioni di service discovery server-side per microservizi come Kubernetes, AWS Elastic Load Balancing, e API Gateways (Kong, NGINX, ecc.) aiutano a instradare il traffico in modo efficiente e a mantenere l'alta disponibilità e vengono utilizzate da aziende come Airbnb, Pinterest, Expedia, Lyft, ecc.
Sicurezza dei Microservizi
Sebbene l'architettura monolitica sia generalmente inferiore a MSA, un aspetto in cui l'architettura monolitica aveva il vantaggio era la sicurezza. Poiché i microservizi sono costruiti sul principio del Loose Coupling e sono distribuiti per natura, non è possibile implementare una misura di sicurezza singola e generale.
Poiché ogni servizio deve essere protetto indipendentemente, sono necessarie protezioni aggiuntive dato che la superficie di attacco è molto più ampia nei microservizi. A tale scopo, standard come OAuth2 e JSON Web Tokens (JWT) vengono comunemente utilizzati per l'autenticazione e l'autorizzazione, come avrai potuto intuire.
Inoltre, un gateway API viene spesso impiegato anche per gestire la sicurezza tra microservizi in quanto applica l'autenticazione e l'autorizzazione nel punto di ingresso. Inoltre, i gateway API possono anche implementare rate limiting, logging e monitoring, che forniscono ulteriori livelli di sicurezza dei microservizi.
Sebbene questi proteggono il punto di ingresso principale, sono necessarie ulteriori misure di sicurezza dei microservizi per coprire la comunicazione tra servizi.
Qui entrano in gioco i service mesh poiché aggiungono un livello di sicurezza di rete dei microservizi e crittografano il traffico tra i servizi e applicano politiche come mutual TLS. Questi mesh di servizi fondamentalmente configurano una crittografia end-to-end completa che migliora significativamente la sicurezza dei microservizi.
Scalabilità dei Microservizi
Uno dei maggiori vantaggi di MSA, e il motivo principale per cui è stato sviluppato per sostituire l'architettura monolitica, è la sua elevata scalabilità. In genere, il scaling dei microservizi può avvenire in due modi: verticale e orizzontale.
Fondamentalmente, il scaling verticale dei microservizi (scaling up) consiste nell'aggiungere più risorse, come CPU o memoria, a un'istanza esistente. In alternativa, il scaling orizzontale dei microservizi (scaling out) distribuisce il carico e aumenta la capacità.
In termini di implementazione, il scaling verticale dei microservizi è il più semplice dei due poiché tutto quello che devi fare è modificare una singola istanza passando a un server più grande, aumentando la memoria o la potenza di elaborazione in un'istanza cloud, o aggiungendo più storage.
Questo tipo di scaling viene generalmente utilizzato nei casi in cui aumentare la potenza RAM o CPU può migliorare le prestazioni delle query e l'elaborazione dei dati, come per i servizi responsabili del caching in memoria.
Detto questo, lo scaling verticale dei microservizi è più semplice e offre un miglioramento immediato delle prestazioni, ma ha anche dei difetti. Lo scaling verticale è limitato dalla capacità hardware del server, quindi a un certo punto dovrai passare allo scaling orizzontale per continuare a scalare.
Inoltre, lo scaling verticale ha costi elevati poiché l'hardware e le istanze più grandi generalmente hanno un prezzo alto. Infine, se l'istanza scalata si guasta, il servizio si ferma completamente, poiché non ci sono istanze aggiuntive per gestire il carico.
Per lo scaling orizzontale dei microservizi, invece di aumentare le risorse di una singola istanza, distribuisci nuove istanze del servizio. Anche se queste istanze funzionano in modo indipendente, gestiscono lo stesso servizio e parti dello stesso carico di lavoro.
A differenza dello scaling verticale, lo scaling orizzontale dei microservizi è illimitato, il che significa che puoi aggiungere tutte le istanze che desideri per gestire carichi di lavoro crescenti e picchi di traffico, offrendo una maggiore scalabilità.
Inoltre, poiché hai più istanze, se una si guasta, non metti tutte le uova nello stesso paniere, poiché le altre istanze possono continuare a gestire le richieste. Infine, lo scaling orizzontale è molto più conveniente a lungo termine, poiché puoi utilizzare più istanze più piccole e economiche per creare prestazioni più affidabili e potenti.
Detto questo, lo scaling orizzontale e l'aggiunta di più istanze richiedono più load balancer, meccanismi di service discovery per i microservizi e strumenti di orchestrazione dei microservizi, rendendo la tua architettura di microservizi molto più complessa.
Lo scaling orizzontale è più adatto a casi d'uso come servizi web e applicazioni come piattaforme di e-commerce o social media, che spesso subiscono fluttuazioni del traffico e un volume elevato di richieste.
Detto questo, non è proprio una questione di uno o l'altro, poiché entrambi i tipi di scaling sono supportati nei microservizi e sono necessari in molti casi. Generalmente, le organizzazioni più piccole utilizzano lo scaling verticale poiché è molto più semplice da implementare e gestire, ma nel tempo, con la crescita dell'applicazione, viene introdotto lo scaling orizzontale per gestire la domanda pesante.
Infine, le piattaforme cloud offrono servizi di auto-scaling che aggiungono o rimuovono automaticamente istanze in base alla domanda in tempo reale, il che aiuta significativamente le organizzazioni a bilanciare scaling verticale e orizzontale.
Monitoraggio dei Microservizi
A questo punto, hai completato abbastanza la distribuzione dei microservizi; tutto ciò che rimane è assicurarsi che funzioni in modo coerente e affidabile. Qui entrano in gioco strumenti di monitoraggio dei microservizi come Prometheus e Grafana entra.
Questi strumenti forniscono informazioni in tempo reale sulle metriche del servizio in modo che i team possono tracciare l'utilizzo delle risorse, la latenza e i tassi di errore. Inoltre, questi strumenti offrono anche tracciamento distribuito (Jaeger, Zipkin, ecc.), che aiuta a visualizzare i flussi di richiesta tra i servizi e può essere estremamente utile per diagnosticare i problemi.
Infine, poiché i guasti possono propagarsi tra i servizi a causa della natura distribuita dei microservizi, l'aggregazione dei log è una pratica critica nel monitoraggio dei microservizi. Consolidando i log in una piattaforma centralizzata e configurando avvisi in tempo reale, sarai sempre un passo avanti rispetto ai problemi e potrai rispondere in modo proattivo prima che impattino gli utenti.
Considerazioni finali
Anche se il mondo dei microservizi è certamente difficile da comprendere, imparare i fondamenti e le fasi chiave della distribuzione dei microservizi può rendere l'intero processo molto più facile. Inoltre, con il passare degli anni, sempre più strumenti con molte più funzionalità sono a tua disposizione, rendendo la distribuzione dei microservizi più semplice che mai.
Domande frequenti
Quali strategie di deployment sono comunemente usate per i microservizi?
Sebbene esistano molte strategie diverse per la distribuzione dei microservizi, le strategie di distribuzione più comunemente utilizzate includono istanze di servizio per container, rilasci graditi, distribuzione blue-green e distribuzione serverless, ognuna offrendo diversi livelli di isolamento, flessibilità e scalabilità.
Quale ruolo svolge Kubernetes nell'orchestrare i microservizi?
I microservizi dipendono da strumenti di orchestrazione dei microservizi come Kubernetes per automatizzare la distribuzione, scalare e gestire i servizi containerizzati, fornendo bilanciamento del carico, auto-scaling e capacità di auto-guarigione per garantire microservizi resilienti ed efficienti.
Come posso garantire la sicurezza in un ambiente di microservizi?
A causa della loro natura distribuita, i microservizi sono più complicati dal punto di vista della sicurezza rispetto all'architettura monolitica. La sicurezza nei microservizi comporta l'autenticazione e l'autorizzazione delle richieste, la crittografia della comunicazione tra i servizi e l'implementazione di gateway API e service mesh come Istio per la gestione centralizzata della sicurezza.


