
Makine öğrenmesinde en kritik konulardan biri, doğru ve güvenilir tahminler üretebilmektir. Bu hedefe yönelik öne çıkan yenilikçi yaklaşımlardan biri, makine öğrenmesinde bagging olarak da bilinen Bootstrap Aggregating'dir. Bu makale; makine öğrenmesinde bagging'i ele alacak, bagging ile boosting'i karşılaştıracak, bir bagging sınıflandırıcısı örneği sunacak, bagging'in nasıl çalıştığını açıklayacak ve makine öğrenmesinde bagging'in avantajları ile dezavantajlarını inceleyecek.
Makine Öğrenmesinde Bagging Nedir?
Popüler makalelerde kullanılan yalnızca iki ilgili görsel var; biri burada, diğeri başka bir yerde olmak üzere her ikisi de kullanılabilir. Design ekibinin Cloudzy versiyonlarını hazırlaması gerekecek.
Bagging nedir?
Bir nesnenin ağırlığını tahmin etmek için birden fazla kişiye sorduğunuzu düşünün. Her birinin tahmini farklı olabilir; ancak tüm tahminlerin ortalamasını aldığınızda çok daha güvenilir bir sonuca ulaşırsınız. Bagging'in özü de budur: birden fazla modelin çıktısını birleştirerek daha doğru ve tutarlı bir tahmin üretmek.
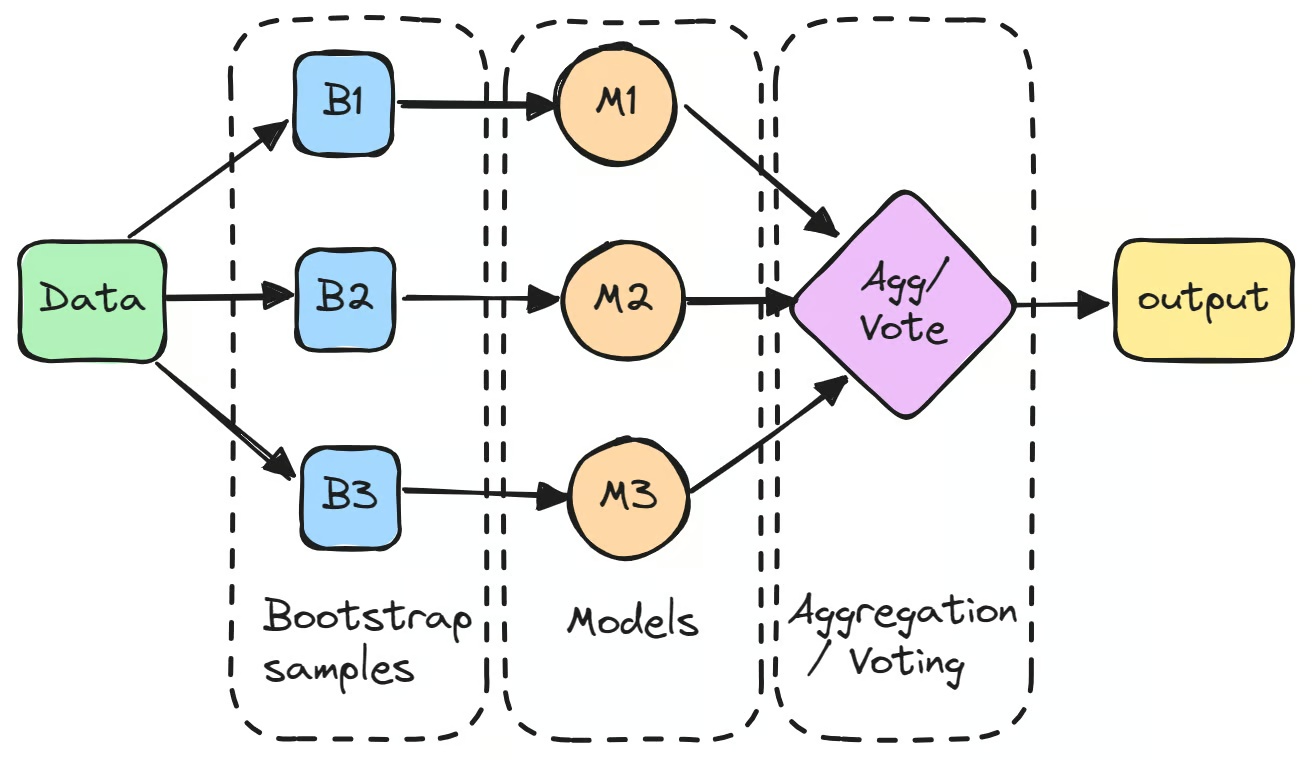
Süreç, orijinal veri kümesinden örnekleme yöntemiyle, yani yerine koyarak rastgele örnekleme yaparak birden fazla alt küme oluşturulmasıyla başlar. Her alt küme, bağımsız olarak ayrı bir modeli eğitmek için kullanılır.
"Zayıf öğreniciler" olarak da adlandırılan bu bireysel modeller, yüksek varyans nedeniyle tek başlarına pek iyi sonuç vermeyebilir. Ancak tahminleri bir araya getirildiğinde; regresyon görevlerinde ortalama alınarak, sınıflandırma görevlerinde ise çoğunluk oylamasıyla birleştirilen sonuç, çoğu zaman herhangi bir tek modelin performansını aşar.
Bagging sınıflandırıcısının iyi bilinen bir örneği, tahmin performansını artırmak için bir karar ağaçları topluluğu oluşturan Random Forest algoritmasıdır. Bununla birlikte, bagging'i makine öğrenmesindeki boosting ile karıştırmamak gerekir. Boosting, önyargıyı azaltmak için modelleri sıralı olarak eğitirken; bagging, varyansı azaltmak için modelleri paralel olarak eğitir.
Makine öğrenmesinde hem bagging hem de boosting, model performansını artırmayı hedefler; ancak modelin davranışının farklı yönlerine odaklanırlar.
Bagging neden faydalıdır?
Makine öğrenmesinde bagging'in temel avantajlarından biri, varyansı azaltarak modellerin görülmemiş verilere daha iyi uyum sağlamasına yardımcı olmasıdır. Bagging, özellikle eğitim verisindeki dalgalanmalara duyarlı algoritmalar, örneğin karar ağaçları, söz konusu olduğunda oldukça faydalıdır.
Aşırı uyumu (overfitting) engelleyerek daha kararlı ve güvenilir bir model ortaya çıkarır. Makine öğrenmesinde bagging ile boosting karşılaştırıldığında; bagging, birden fazla modeli paralel olarak eğiterek varyansı azaltmaya odaklanırken, boosting modelleri sıralı eğiterek önyargıyı azaltmayı hedefler.
Makine öğrenmesinde bagging'e somut bir örnek vermek gerekirse, finansal risk tahmininde birden fazla karar ağacı geçmiş piyasa verisinin farklı alt kümeleri üzerinde eğitilir. Tahminleri bir araya getirerek bagging, bireysel model hatalarının etkisini azaltan daha güvenilir bir tahmin modeli oluşturur.
Özetle, makine öğrenmesinde bagging, birden fazla modelin kolektif bilgisinden yararlanarak tek tek modellerden elde edilenden daha doğru ve güvenilir tahminler üretir.
Makine Öğrenmesinde Bagging Nasıl Çalışır: Adım Adım
Bagging'in model performansını nasıl artırdığını tam olarak anlamak için süreci adım adım inceleyelim.
Veri Kümesinden Birden Fazla Bootstrap Örneği Alın
Makine öğrenmesinde bagging'in ilk adımı, bootstrapping yöntemiyle orijinal veri kümesinden birden fazla yeni alt küme oluşturmaktır. Bu teknik, verilerin yerine koyarak rastgele örneklenmesini içerir; dolayısıyla bazı veri noktaları aynı alt kümede birden fazla kez görünebilirken, bazıları hiç görünmeyebilir. Bu işlem, her modelin verinin biraz farklı bir sürümü üzerinde eğitilmesini sağlamak için yapılır.
Her Örnekten Ayrı Bir Model Eğitin
Her bootstrap örneği, genellikle karar ağaçları gibi aynı türden ayrı bir modeli eğitmek için kullanılır. "Temel öğreniciler" veya "zayıf öğreniciler" olarak adlandırılan bu modeller, ilgili alt kümeleri üzerinde bağımsız olarak eğitilir. Bagging sınıflandırıcısına bir örnek, birçok bagging tabanlı modelin temelini oluşturan Random Forest algoritmasında kullanılan karar ağacıdır. Her bir model tek başına iyi bir performans göstermeyebilir; ancak her biri kendi eğitim verisine dayalı özgün içgörüler sunar.
Tahminleri Bir Araya Getirin
Modeller eğitildikten sonra tahminleri, nihai çıktıyı oluşturmak için bir araya getirilir.
- Regresyon görevlerinde tahminler ortalaması alınarak birleştirilir; bu da modelin varyansını azaltır.
- Sınıflandırma görevlerinde nihai tahmin, çoğunluk oylamasıyla belirlenir: en fazla model tarafından öngörülen sınıf seçilir. Bu yöntem, tek bir modelin çıktısına kıyasla daha kararlı bir tahmin sağlar.
Nihai Tahmin
Birden fazla modelin tahminlerini birleştirerek bagging, herhangi bir modelin hatalarının etkisini azaltır ve genel doğruluğu artırır. Bu birleştirme süreci, bagging'i makine öğrenmesinde, özellikle karar ağaçları gibi yüksek varyanslı modellerin kullanıldığı görevlerde bu denli güçlü bir teknik yapan şeydir. Bireysel model tahminlerindeki tutarsızlıkları etkin biçimde düzelterek daha güçlü bir nihai model ortaya çıkarır.
Bagging, tahminleri kararlı hale getirmede etkili olsa da göz önünde bulundurulması gereken bazı noktalar vardır: temel modeller çok karmaşıksa, bagging'in genel amacına rağmen aşırı uyum riski ortaya çıkabilir.
Bunun yanı sıra hesaplama maliyeti yüksek olabilir; temel öğrenici sayısını ayarlamak veya daha verimli topluluk yöntemlerini değerlendirmek bu sorunu hafifletebilir. ML ve DL için doğru GPU'yi seçmek her zaman önemlidir.
Daha iyi sonuçlar için temel öğreniciler arasında model çeşitliliği sağladığınızdan emin olun; dengesiz verilerle çalışıyorsanız, azınlık sınıflarında düşük performanstan kaçınmak için bagging uygulamadan önce SMOTE gibi teknikler işe yarayabilir.
Bagging Uygulama Alanları
Bagging'in nasıl çalıştığını inceledikten sonra, gerçek dünyada nerede kullanıldığına bakalım. Bagging, pek çok sektörde karmaşık senaryolarda tahmin doğruluğunu ve kararlılığını artırmak için kullanılıyor. En etkili uygulama alanlarına daha yakından bakalım:
- Sınıflandırma ve Regresyon: Bagging, varyansı azaltıp aşırı öğrenmeyi önleyerek sınıflandırıcı ve regresör performansını artırmak için yaygın olarak kullanılır. Örneğin, bagging'i kullanan Random Forest'lar görüntü sınıflandırma ve tahmine dayalı modelleme gibi görevlerde etkili sonuçlar verir.
- Anomali Tespiti: Dolandırıcılık tespiti ve ağ saldırısı tespiti gibi alanlarda bagging algoritmaları, verideki aykırı değerleri ve anomalileri başarıyla tespit ederek.
- Finansal Risk Değerlendirmesi: Bankacılık sektöründe bagging teknikleri, kredi puanlama modellerini geliştirmek, kredi onay süreçlerinin ve finansal risk değerlendirmelerinin doğruluğunu artırmak için kullanılır.
- Tıbbi Tanı: Sağlık alanında bagging, MRI veri setlerini analiz ederek Alzheimer gibi nörobilişsel bozuklukların tespitinde uygulanmış ve erken tanı ile tedavi planlamasına.
- Doğal Dil İşleme (NLP): Bagging, birden fazla modelden gelen tahminleri bir araya getirerek metin sınıflandırma ve duygu analizi gibi görevlere katkı sağlar; bu da daha güvenilir bir dil anlayışı elde edilmesini mümkün kılar.
Bagging'in Avantajları ve Dezavantajları
Her makine öğrenimi tekniği gibi bagging'in de kendine özgü avantajları ve dezavantajları vardır. Bunları anlamak, modellerinizde bagging'i ne zaman ve nasıl kullanacağınıza karar vermenizi kolaylaştırır.
Bagging'in Avantajları:
- Varyansı ve Aşırı Öğrenmeyi Azaltır: Bagging'in makine öğrenimindeki en önemli avantajlarından biri, aşırı öğrenmeyi önlemeye yardımcı olan varyansı azaltma kapasitesidir. Farklı veri alt kümeleri üzerinde birden fazla model eğiterek bagging, modelin eğitim verilerindeki dalgalanmalara aşırı duyarlı hale gelmesini engeller ve böylece daha genellenebilir, kararlı bir model ortaya çıkar.
- Yüksek Varyanslı Modellerle Uyumlu Çalışır: Bagging, karar ağaçları gibi yüksek varyanslı modellerle birlikte kullanıldığında özellikle etkilidir. Bu modeller veriye aşırı uyum sağlama ve yüksek varyans sergileme eğilimindedir; bagging ise birden fazla modelin tahminlerini ortalaması ya da oylaması yoluyla bu sorunu hafifletir. Sonuç olarak tahminler daha güvenilir hale gelir ve verideki gürültüden daha az etkilenir.
- Model Kararlılığını ve Performansını Artırır: Farklı veri alt kümeleri üzerinde eğitilen birden fazla modeli birleştirerek bagging, genellikle daha iyi bir genel performans sağlar. Tahmin doğruluğunu artırırken modelin veri setindeki küçük değişikliklere olan duyarlılığını da azaltır; bu da modeli uzun vadede daha güvenilir kılar.
Bagging'in Dezavantajları:
- Hesaplama Maliyetini Artırır: Bagging, birden fazla modelin eğitilmesini gerektirdiğinden hesaplama maliyetini doğal olarak artırır. Özellikle büyük veri kümeleri veya karar ağaçları gibi karmaşık modeller kullanıldığında, çok sayıda modeli eğitmek ve tahminleri bir araya getirmek oldukça zaman alabilir.
- Düşük Varyanslı Modellerde Etkisizdir: Bagging, yüksek varyanslı modellerde son derece etkili olsa da lineer regresyon gibi düşük varyanslı modellere uygulandığında belirgin bir fayda sağlamaz. Bu durumlarda bireysel modeller zaten düşük hata oranlarına sahip olduğundan, tahminleri bir araya getirmek sonuçları kayda değer ölçüde iyileştirmez.
- Yorumlanabilirliği Azaltır: Birden fazla modelin birleştirilmesi, nihai modelin yorumlanabilirliğini düşürebilir. Örneğin Random Forest'ta karar alma süreci birden fazla karar ağacına dayandığından, belirli bir tahminin arkasındaki mantığı izlemek güçleşir.
Bagging Ne Zaman Kullanılmalı?
Bagging'in makine öğrenmesi projelerinde ne zaman kullanılacağını bilmek, en iyi sonuçlara ulaşmanın anahtarıdır. Bu teknik belirli durumlarda iyi sonuç verir; ancak her problem için en uygun seçenek olmayabilir.
Modeliniz Aşırı Uyuma Eğilimli Olduğunda
Bagging'in başlıca kullanım alanlarından biri, özellikle karar ağaçları gibi yüksek varyanslı modellerde aşırı uyuma eğilimli modeller üzerinde çalışmaktır. Bu modeller eğitim verisinde iyi performans gösterebilir; ancak eğitim kümesinin belirli örüntülerine çok sıkı bağlandıkları için yeni veriye genellikle iyi uyum sağlayamazlar.
Bagging, farklı veri alt kümeleri üzerinde birden fazla model eğiterek ve bu tahminleri ortalama ya da oylama yoluyla birleştirerek aşırı uyumun önüne geçer. Bu sayede model, daha önce görmediği verileri daha başarılı biçimde işler.
Kararlılığı ve Doğruluğu Artırmak İstediğinizde
Yorumlanabilirlikten çok fazla ödün vermeden modelinizin kararlılığını ve doğruluğunu artırmak istiyorsanız bagging iyi bir seçenektir. Birden fazla modelden gelen tahminlerin bir araya getirilmesi, özellikle gürültülü verilerle çalışılan görevlerde nihai sonucu daha güvenilir kılar.
Sınıflandırma ya da regresyon problemlerinde bagging, tutarlılığı artırarak daha istikrarlı sonuçlar üretmenize yardımcı olur.
Yeterli Hesaplama Kaynaklarınız Olduğunda
Bagging kullanıp kullanmamaya karar verirken göz önünde bulundurulması gereken önemli bir etken de hesaplama kaynaklarının yeterliliğidir. Bagging, birden fazla modelin eş zamanlı eğitilmesini gerektirdiğinden, özellikle büyük veri kümeleri veya karmaşık modellerde hesaplama maliyeti önemli ölçüde artabilir.
Gerekli hesaplama gücüne erişiminiz varsa bagging'in faydaları maliyetin çok üzerinde olacaktır. Kaynaklar kısıtlıysa alternatif teknikler değerlendirmeyi ya da ensemble içindeki model sayısını sınırlamayı düşünebilirsiniz.
Yüksek Varyanslı Modellerle Çalışıyorsanız
Bagging, eğitim verisindeki dalgalanmalara duyarlı ve yüksek varyanslı modellerle çalışırken özellikle işe yarar. Karar ağaçları, performansı eğitim verisine göre büyük farklılıklar gösterebileceğinden Random Forest biçiminde sıklıkla bagging ile birlikte kullanılır.
Farklı veri alt kümeleri üzerinde birden fazla model eğitip tahminleri birleştirerek bagging, varyansı dengeler ve daha güvenilir bir model ortaya çıkarır.
Güçlü Bir Sınıflandırıcıya İhtiyaç Duyduğunuzda
Sınıflandırma problemleri üzerinde çalışıyor ve güçlü bir sınıflandırıcıya ihtiyaç duyuyorsanız bagging, tahminlerinizin kararlılığını önemli ölçüde artırabilir. Örneğin bir bagging sınıflandırıcısı olan Random Forest, çok sayıda bireysel karar ağacının sonuçlarını bir araya getirerek daha doğru tahminler üretir.
Bu yaklaşım, bireysel modeller zayıf kaldığında bile onların toplu gücünün güçlü bir genel model ortaya çıkardığı durumlarda etkili biçimde çalışır.
Ayrıca bagging tekniklerini verimli biçimde uygulamak için doğru platformu arıyorsanız şu araçlar işinize yarayabilir: Databricks ve Snowflake büyük veri kümelerini yönetmek ve bagging gibi topluluk yöntemleri çalıştırmak için oldukça kullanışlı, birleşik bir analiz platformu sunar.
Makine öğrenmesine daha az teknik bir yaklaşım arıyorsanız, kodsuz AI araçları da bir seçenek olabilir. Bagging gibi ileri teknikler üzerine doğrudan odaklanmasalar da pek çok kodsuz platform, kapsamlı kodlama bilgisi gerektirmeden kullanıcıların bagging dahil topluluk öğrenimi yöntemlerini denemesine olanak tanır.
Bu sayede, temel koda odaklanmak yerine model performansına yoğunlaşarak daha gelişmiş teknikler uygulayabilir ve yine de doğru tahminler elde edebilirsiniz.
Son Sözler
Makine öğrenmesinde bagging, varyansı azaltarak ve kararlılığı artırarak model performansını güçlendiren etkili bir tekniktir. Farklı veri alt kümeleri üzerinde eğitilmiş birden fazla modelin tahminlerini bir araya getirerek daha doğru ve güvenilir sonuçlar üretir. Özellikle karar ağaçları gibi yüksek varyanslı modellerde aşırı uyumu önlemeye ve modelin görülmemiş verilere daha iyi genelleme yapmasına yardımcı olur.
Bagging'in aşırı uyumu azaltma ve doğruluğu artırma gibi önemli avantajları olsa da beraberinde bazı ödünleşimler getirir. Birden fazla model eğitildiğinden hesaplama maliyeti artar ve yorumlanabilirlik azalabilir. Bu dezavantajlara karşın performansı artırma kapasitesi, bagging'i boosting ve stacking gibi diğer yöntemlerin yanı sıra topluluk öğrenmesinde değerli bir teknik haline getirir.
Makine öğrenmesi projelerinde bagging kullandınız mı? Deneyiminizi ve işe yarayıp yaramadığını bizimle paylaşın!


