
Chọn một GPU Cloud VPS có thể cảm thấy áp đảo khi bạn nhìn vào các bảng thông số kỹ thuật đầy những con số. Số lõi nhảy từ 2.560 lên 21.760, nhưng điều đó có nghĩa là gì?
Một CUDA core là một đơn vị xử lý song song bên trong NVIDIA GPU thực hiện hàng ngàn phép tính cùng một lúc, hỗ trợ mọi thứ từ huấn luyện AI đến kết xuất 3D. Hướng dẫn này phân tích cách chúng hoạt động, khác biệt với CPU và Tensor cores, và số lõi nào phù hợp với nhu cầu của bạn mà không trả quá tiền.
CUDA Cores là gì?

CUDA cores là các đơn vị xử lý riêng lẻ bên trong NVIDIA GPU thực hiện lệnh một cách song song. CUDA core technology về cơ bản là gì? Hãy nghĩ về những đơn vị này như những công nhân nhỏ xử lý từng phần công việc cùng một lúc.
NVIDIA giới thiệu CUDA (Compute Unified Device Architecture) vào năm 2006 để sử dụng sức mạnh GPU cho điện toán chung vượt ra ngoài đồ họa. tài liệu CUDA chính thức cung cấp chi tiết kỹ thuật toàn diện. Mỗi đơn vị thực hiện các phép toán số học cơ bản trên số dấu phẩy động, hoàn hảo cho các phép tính lặp lại.
NVIDIA GPU hiện đại chứa hàng ngàn đơn vị này trong một chip duy nhất. GPU consumer từ thế hệ mới nhất chứa hơn 21.000 lõi, trong khi đó GPU data center dựa trên kiến trúc Hopper có tới 16.896. Những đơn vị này hoạt động cùng nhau thông qua Streaming Multiprocessors (SMs).
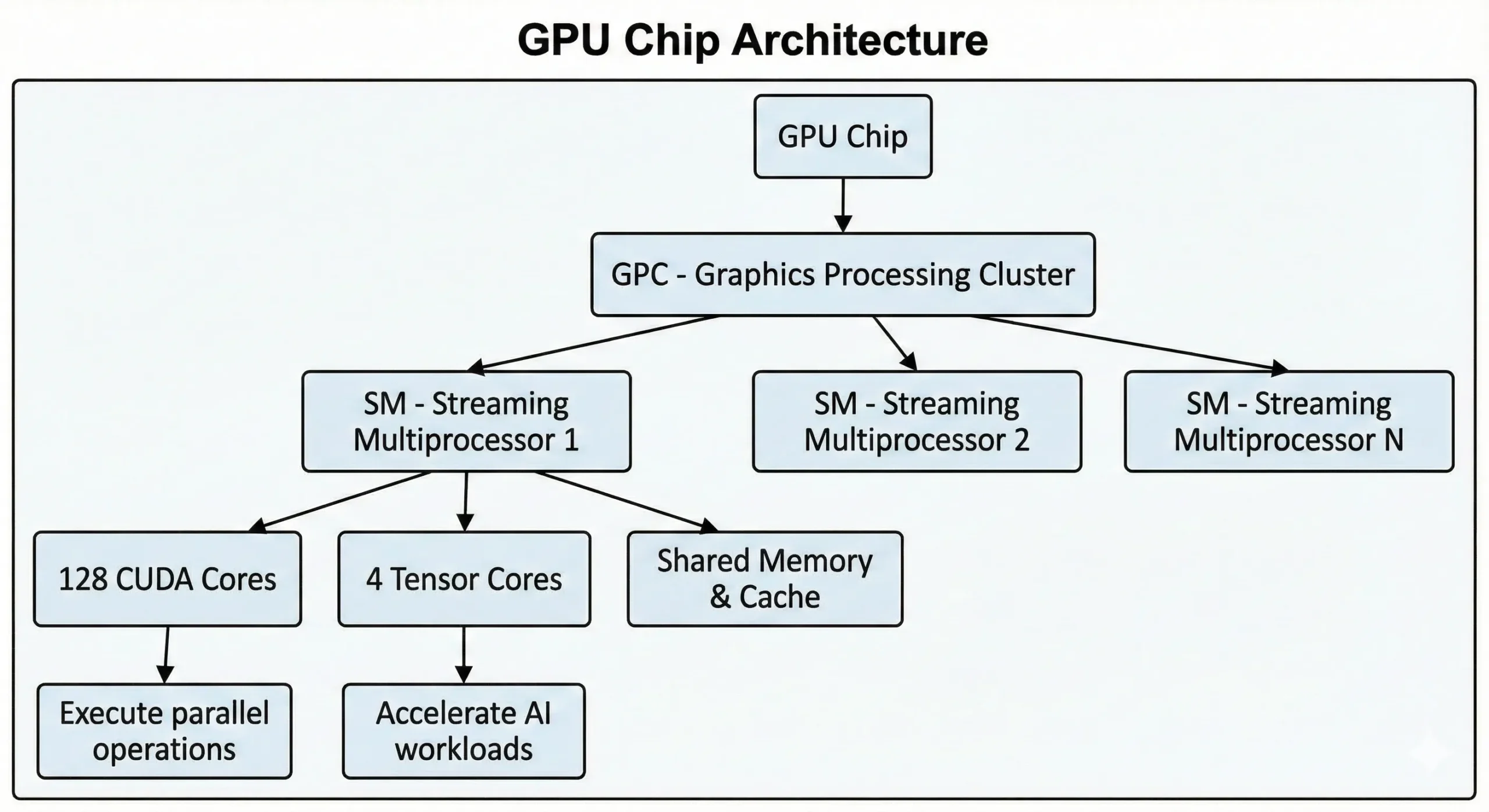
Các đơn vị thực hiện các hoạt động SIMT (Single Instruction, Multiple Threads) thông qua các phương pháp điện toán song song. Một lệnh được thực hiện trên nhiều điểm dữ liệu cùng một lúc. Khi huấn luyện mạng lưới thần kinh hoặc kết xuất các cảnh 3D, hàng ngàn hoạt động tương tự xảy ra. Chúng chia công việc này thành các luồng đồng thời, thực hiện nó một cách song song thay vì tuần tự.
CUDA Cores so với CPU Cores: Điều gì khiến chúng khác?

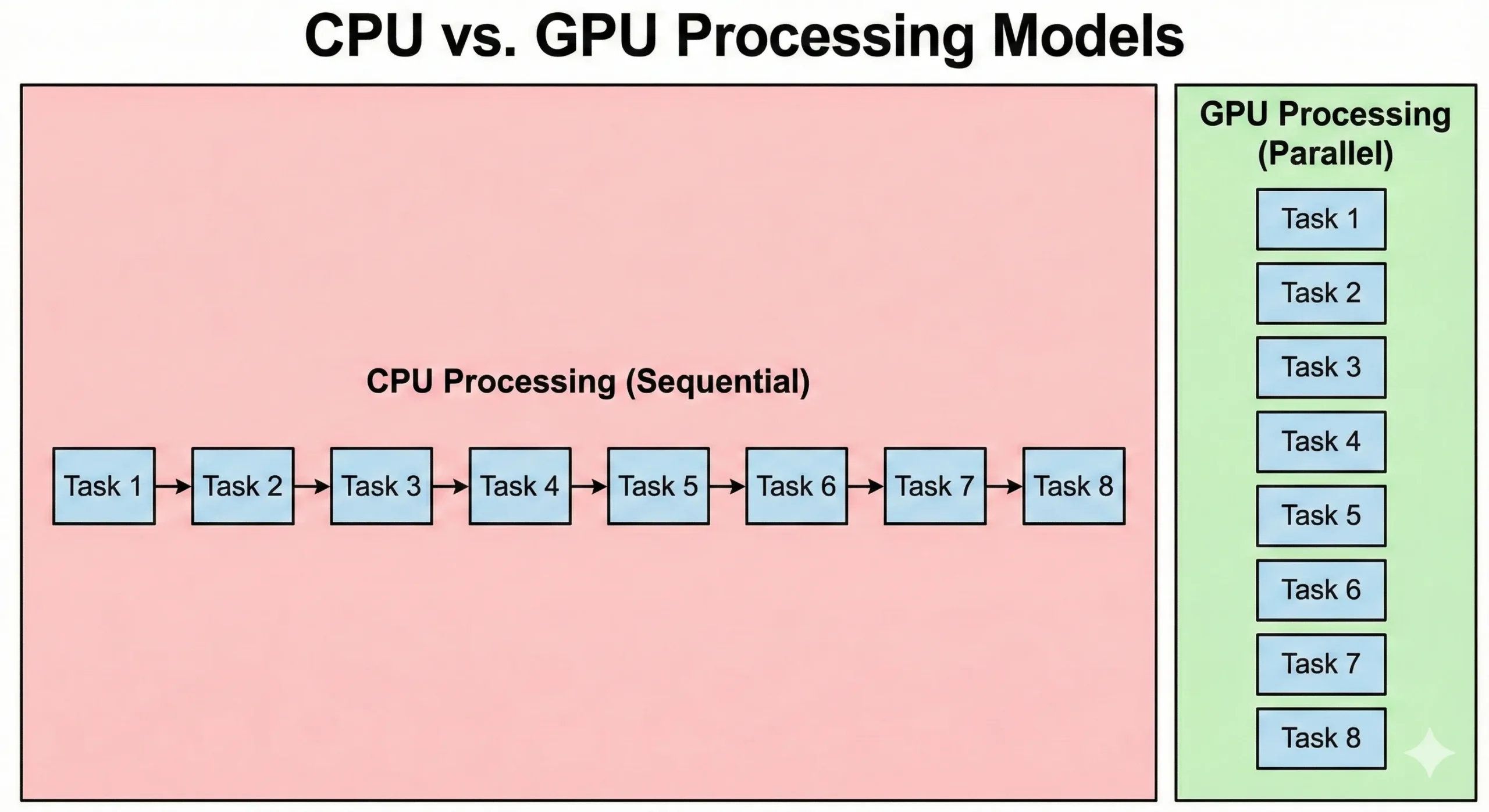
CPU và GPU giải quyết vấn đề theo cách cơ bản khác nhau. Một CPU server hiện đại có thể có 8-128+ lõi chạy ở tốc độ xung nhịp cao. Những bộ xử lý này xuất sắc trong các hoạt động tuần tự nơi mỗi bước phụ thuộc vào kết quả trước đó. Chúng xử lý logic phức tạp và nhánh một cách hiệu quả.
GPU làm ngược lại. Chúng chứa hàng ngàn CUDA cores đơn giản hơn chạy ở tốc độ xung nhịp thấp hơn. Những đơn vị này bù đắp cho tốc độ thấp thông qua sự song song hóa. Khi 16.000 đơn vị hoạt động cùng nhau, tổng thông lượng vượt quá khả năng CPU tiêu chuẩn.
CPU thực hiện mã hệ điều hành và logic ứng dụng phức tạp. Trong khi GPU ưu tiên thông lượng, chi phí từ khởi tạo tác vụ và đồng bộ hóa dẫn đến độ trễ cao hơn. Xử lý đồ họa song song ưu tiên di chuyển dữ liệu. Mặc dù chúng mất nhiều thời gian hơn để bắt đầu, nhưng chúng xử lý các bộ dữ liệu lớn nhanh hơn CPU.
| Tính năng | Lõi CPU | Lõi CUDA |
| Số lượng trên mỗi chip | 4-128+ lõi | 2.560-21.760 lõi |
| Tốc độ xung nhịp | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Kiểu xử lý | Hướng dẫn tuần tự, phức tạp | Hướng dẫn song song, đơn giản |
| Tốt nhất cho | Hệ điều hành, tác vụ đơn luồng | Toán ma trận, xử lý dữ liệu song song |
| Độ trễ | Thấp (microseconds) | Cao hơn (chi phí khởi động) |
| Kiến trúc | Đa năng | Chuyên biệt hóa cho các phép tính lặp lại |
Công nghệ Virtual GPU (vGPU) và Multi-Instance GPU (MIG) xử lý phân chia tài nguyên và lập lịch để phân bổ bộ xử lý trên nhiều người dùng. Thiết lập này cho phép các nhóm tối đa hóa việc sử dụng phần cứng thông qua chia sẻ theo thời gian hoặc các phiên bản phần cứng chuyên dụng, tùy thuộc vào cấu hình.
Huấn luyện mạng nơ-ron liên quan đến hàng tỷ phép nhân ma trận. Một GPU với 10.000 đơn vị không đơn giản là thực thi 10.000 phép tính cùng lúc; thay vào đó, nó quản lý hàng nghìn luồng song song được nhóm thành các "warp" để tối đa hóa thông lượng. Tính song song khổng lồ này là lý do tại sao những đơn vị này là kiến thức bắt buộc cho các nhà phát triển AI.
CUDA Cores và Tensor Cores: Hiểu Rõ Sự Khác Biệt

NVIDIA GPUs chứa hai loại đơn vị chuyên biệt làm việc cùng nhau: các lõi CUDA tiêu chuẩn và lõi Tensor. Chúng không phải là các công nghệ cạnh tranh; chúng giải quyết các phần khác nhau của tải công việc.
Các đơn vị tiêu chuẩn là bộ xử lý song song đa năng xử lý các phép tính FP32 và FP64, toán học số nguyên và phép biến đổi tọa độ. Công nghệ CUDA cốt lõi này tạo thành nền tảng của máy tính GPU, chạy mọi thứ từ mô phỏng vật lý đến tiền xử lý dữ liệu mà không cần gia tốc chuyên biệt.
Tensor cores là các đơn vị chuyên biệt được thiết kế riêng cho phép nhân ma trận và tác vụ AI. Được giới thiệu trong kiến trúc Volta của NVIDIA (2017), chúng xuất sắc trong các phép tính có độ chính xác FP16 và TF32. Thế hệ mới nhất hỗ trợ FP8 cho suy luận AI còn nhanh hơn.
| Tính năng | Lõi CUDA | Lõi Tensor |
| Mục đích | Máy tính song song đa năng | Phép nhân ma trận cho AI |
| Độ chính xác | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Tốc độ cho AI | 1x đường cơ sở | Nhanh hơn 2-10 lần so với CUDA cores |
| Trường hợp sử dụng | Tiền xử lý dữ liệu, ML truyền thống | Huấn luyện/suy luận học sâu |
| Tính khả dụng | Tất cả NVIDIA GPUs | RTX 20 series và mới hơn, GPUs trung tâm dữ liệu |
GPUs hiện đại kết hợp cả hai. RTX 5090 có 21.760 đơn vị tiêu chuẩn cộng với 680 Tensor cores thế hệ thứ năm. H100 kết hợp 16.896 đơn vị tiêu chuẩn với 528 Tensor cores thế hệ thứ tư để gia tốc học sâu.
Khi huấn luyện mạng nơ-ron, Tensor cores thực hiện công việc nặng trong các lần đi tới và quay lại mô hình. Các đơn vị tiêu chuẩn quản lý tải dữ liệu, tiền xử lý, tính toán hàm mất mát và cập nhật trình tối ưu hóa. Cả hai loại làm việc cùng nhau, với Tensor cores gia tốc các phép tính tính toán yêu cầu nhiều.
Đối với các thuật toán học máy truyền thống như rừng ngẫu nhiên hoặc tăng cường gradient, các đơn vị tiêu chuẩn quản lý công việc vì những cái này không sử dụng các mẫu nhân ma trận mà Tensor cores gia tốc. Nhưng đối với mô hình transformer và mạng nơ-ron tích chập, Tensor cores cung cấp các tăng tốc đáng kể.
CUDA Cores Được Sử Dụng Để Làm Gì?

Lõi CUDA cung cấp sức mạnh tính toán cho các tác vụ đòi hỏi rất nhiều phép toán giống nhau thực hiện cùng lúc. Bất kỳ công việc nào liên quan đến các phép toán ma trận hoặc tính toán số lặp lại đều được hưởng lợi từ kiến trúc của chúng.
Các ứng dụng AI và Machine Learning
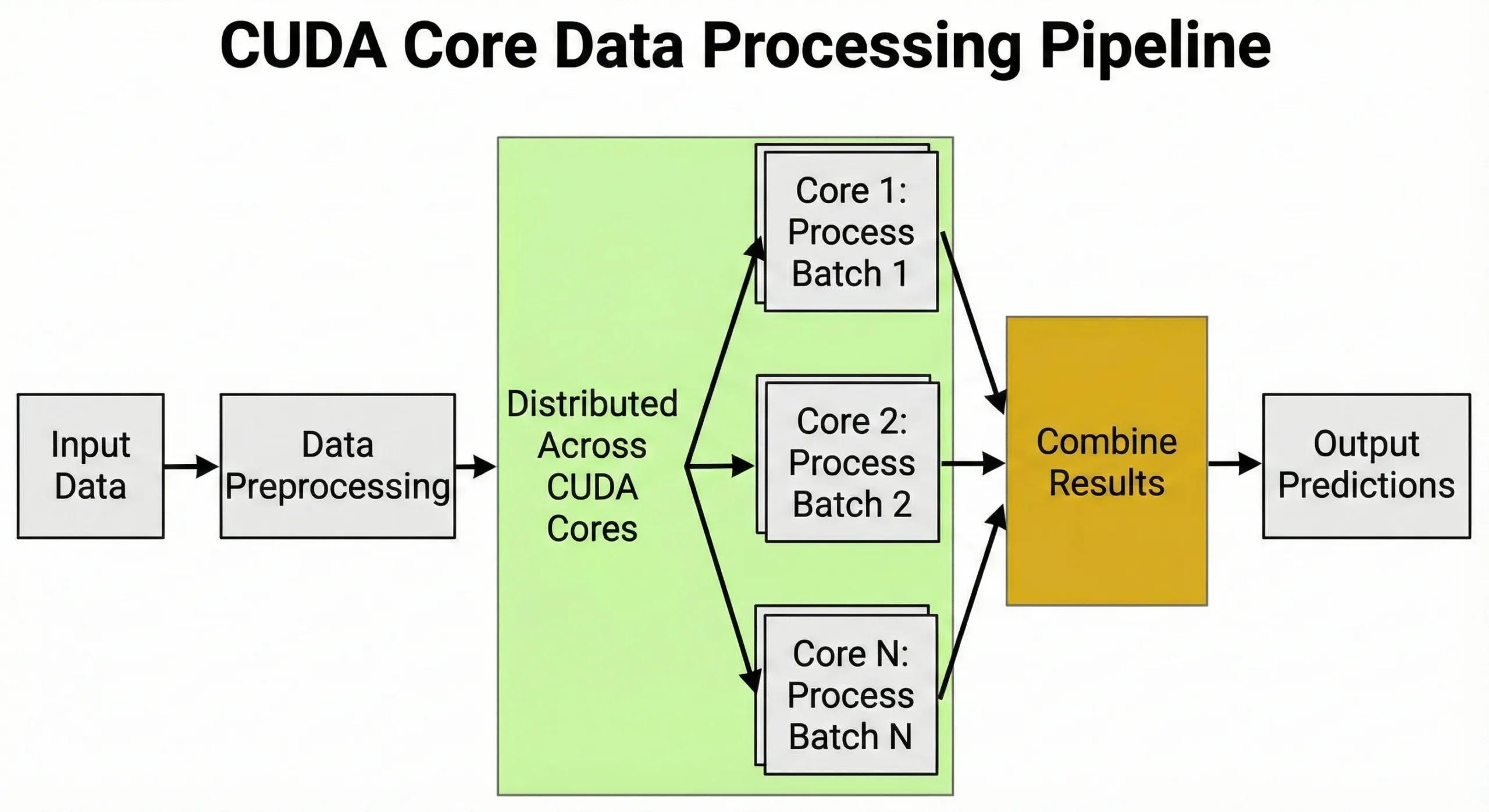
Deep learning dựa vào các phép nhân ma trận trong quá trình huấn luyện và suy luận. Khi huấn luyện mạng nơ-ron, mỗi bước tiến phía trước đòi hỏi hàng triệu phép toán nhân-cộng trên các ma trận trọng số. Lan truyền ngược thêm hàng triệu phép toán nữa trong bước quay lại.
Các đơn vị quản lý tiền xử lý dữ liệu, chuyển đổi hình ảnh thành tensor, chuẩn hóa giá trị và áp dụng các phép biến đổi tăng cường dữ liệu. Khả năng xử lý hàng nghìn tác vụ cùng lúc chính là lý do tại sao GPU lại quan trọng đối với AI.
Trong quá trình huấn luyện, chúng giám sát lịch trình tỉ lệ học, tính toán gradient và cập nhật trạng thái bộ tối ưu hóa.
Đối với VPS để các hoạt động suy luận AI chạy các hệ thống đề xuất hoặc chatbot, chúng xử lý các yêu cầu song song, thực hiện hàng trăm dự đoán cùng lúc. Hướng dẫn của chúng tôi về GPU tốt nhất cho AI 2025 bao gồm cấu hình nào hoạt động cho các kích cỡ mô hình khác nhau.
H100 với 16.896 đơn vị kết hợp với Tensor cores huấn luyện mô hình 7 tỷ tham số trong vài tuần thay vì vài tháng. Suy luận thời gian thực cho chatbot phục vụ hàng nghìn người dùng cần sức mạnh thực hiện song song tương tự.
Tính toán khoa học và nghiên cứu
Các nhà nghiên cứu sử dụng những bộ xử lý này cho các mô phỏng động lực học phân tử, mô hình hóa khí hậu và phân tích gen học. Mỗi phép tính là độc lập, khiến chúng hoàn hảo cho thực hiện song song. Các tổ chức tài chính chạy mô phỏng Monte Carlo với hàng triệu kịch bản cùng lúc.
Kết xuất 3D và sản xuất video
Ray tracing tính toán ánh sáng phản xạ qua các cảnh 3D bằng cách truy vết các tia độc lập qua mỗi pixel. Trong khi các lõi RT chuyên dụng xử lý phần giao cắt, các đơn vị tiêu chuẩn quản lý lấy mẫu kết cấu và ánh sáng. Sự phân chia này quyết định tốc độ của các cảnh với hàng triệu tia.
NVENC xử lý mã hóa cho H.264 và H.265, trong khi các kiến trúc mới nhất (Ada Lovelace và Hopper) giới thiệu hỗ trợ phần cứng cho AV1. CUDA giúp với các hiệu ứng, bộ lọc, chia tỉ lệ, giảm nhiễu, biến đổi màu sắc và keo dán pipeline. Điều này cho phép công cụ mã hóa hoạt động cùng với các bộ xử lý song song để tăng tốc độ sản xuất video.
Kết xuất 3D trong Blender hoặc Maya chia hàng tỷ phép tính shader bề mặt trên các đơn vị có sẵn. Các hệ thống hạt được hưởng lợi vì chúng mô phỏng hàng nghìn hạt tương tác cùng lúc. Những tính năng này là chìa khóa cho sáng tạo kỹ thuật số cấp cao.
Cách các lõi CUDA ảnh hưởng đến hiệu suất GPU

Số lượng lõi cho bạn ý tưởng sơ bộ về khả năng thực hiện song song, nhưng các lõi CUDA đòi hỏi nhìn vượt ra ngoài các con số. Tốc độ xung nhịp, băng thông bộ nhớ, hiệu suất kiến trúc và tối ưu hóa phần mềm đều đóng vai trò chính.
GPU với 10.000 đơn vị chạy ở 2.0 GHz mang lại kết quả khác so với GPU có 10.000 đơn vị ở 1.5 GHz. Tốc độ xung nhịp cao hơn có nghĩa là mỗi đơn vị hoàn thành nhiều phép tính hơn trên giây. Các kiến trúc mới hơn thực hiện nhiều công việc hơn trong mỗi chu kỳ thông qua lập lịch lệnh tốt hơn.
Kiểm tra xem bạn có giữ thiết bị bận rộn hay không, nhưng hãy nhớ rằng nvidia-smi mức sử dụng là một thước đo thô. Nó đo lường tỷ lệ phần trăm thời gian một kernel hoạt động, chứ không phải bao nhiêu lõi đang hoạt động.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderKết quả mẫu: 85%, 92% (85% thời gian hoạt động, 92% hoạt động bộ điều khiển bộ nhớ)
Nếu GPU của bạn hiển thị mức sử dụng 60-70%, bạn có thể gặp phải các nút cổ chai ở phía trước như tải dữ liệu CPU hoặc kích cỡ lô nhỏ. Tuy nhiên, ngay cả 100% mức sử dụng cũng có thể gây hiểu lầm nếu các kernel của bạn bị giới hạn bộ nhớ hoặc đơn luồng. Để có bức tranh đúng của tình trạng bão hòa lõi, sử dụng các công cụ profiler như Nsight Systems để theo dõi các chỉ số 'SM Efficiency' hoặc 'SM Active'.
Băng thông bộ nhớ thường trở thành nút cổ chai trước khi sức mạnh tính toán đạt cực đại. Nếu GPU của bạn xử lý dữ liệu nhanh hơn bộ nhớ cung cấp, các đơn vị sẽ ở trạng thái chờ. Model H100 SXM5 sử dụng băng thông 3,35 TB/s để cấp nguồn cho 16.896 nhân. Phiên bản PCIe giảm con số này xuống 2 TB/s.
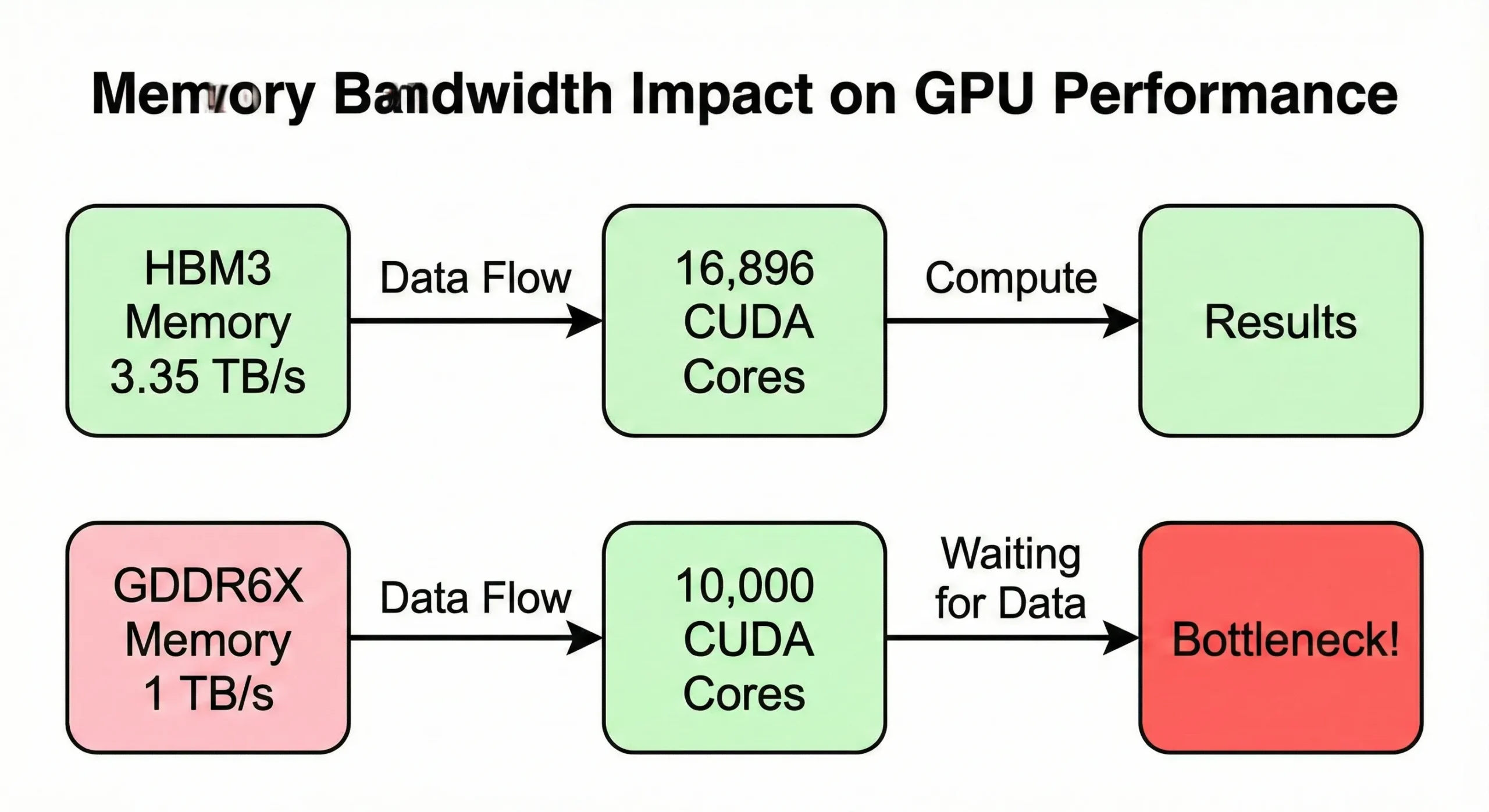
GPU tiêu dùng có số lượng tương tự nhưng băng thông thấp hơn (khoảng 1 TB/s) cho thấy tốc độ giảm trong các tác vụ sử dụng bộ nhớ nhiều.
Dung lượng VRAM xác định kích thước các tác vụ của bạn. Cho dù là trọng số FP16 cho Mô hình 70B, huấn luyện đầy đủ yêu cầu nhiều bộ nhớ hơn. Bạn phải tính đến các gradient và trạng thái bộ tối ưu hóa. Những trạng thái này thường làm tăng gấp ba lần dung lượng trừ khi bạn sử dụng chiến lược offload
A100 80GB nhắm vào suy luận thông lượng cao và tinh chỉnh. Trong khi đó, RTX 4090 24GB, thường được trích dẫn cho các mô hình 7B, có thể chạy các mô hình tham số 30B+ nếu bạn sử dụng các kỹ thuật lượng tử hóa hiện đại như INT4. Tuy nhiên, hết dung lượng VRAM buộc các chuyển dữ liệu CPU-GPU làm hủy thông lượng.
Tối ưu hóa phần mềm xác định xem mã của bạn có thực sự sử dụng tất cả những đơn vị đó không. Các kernel viết kém chỉ có thể sử dụng một phần tài nguyên có sẵn. Các thư viện như cuDNN cho deep learning và RAPIDS cho data science được tinh chỉnh nặng nề để tối đa hóa sử dụng.
Nhiều CUDA Cores Không Phải Lúc Nào Cũng Có Nghĩa Hiệu Suất Tốt Hơn

Mua một GPU với số lõi cao nhất có vẻ hợp lý, nhưng bạn lãng phí tiền nếu các đơn vị vượt qua các thành phần hệ thống khác hoặc tác vụ của bạn không mở rộng theo số lõi.
Băng thông bộ nhớ tạo ra giới hạn đầu tiên. 21.760 đơn vị RTX 5090 được cấp nguồn bởi 1.792 GB/s băng thông bộ nhớ. GPU cũ hơn với ít đơn vị hơn có thể có băng thông cao hơn tương đối trên mỗi đơn vị.
Sự khác biệt về kiến trúc là quan trọng. GPU mới hơn với 14.000 đơn vị ở 2,2 GHz vượt trội hơn GPU cũ hơn với 16.000 ở 1,8 GHz nhờ các lệnh tốt hơn trên mỗi chu kỳ. Mã của bạn cần song song hóa thích hợp để sử dụng 20.000 đơn vị một cách hiệu quả.
Tại Sao CUDA Cores Quan Trọng Khi Chọn GPU VPS

Chọn cấu hình GPU lõi CUDA phù hợp cho VPS của bạn ngăn chặn lãng phí tiền trên các tài nguyên không sử dụng hoặc gặp điểm nghẽn giữa dự án.
Bộ nhớ 80GB của H100 xử lý suy luận cho các mô hình tham số 70B sử dụng lượng tử hóa 4 bit. Tuy nhiên, để huấn luyện đầy đủ, ngay cả 80GB thường không đủ cho mô hình 34B khi bạn tính đến gradient và trạng thái bộ tối ưu hóa. Trong huấn luyện FP16, dung lượng bộ nhớ mở rộng đáng kể, thường yêu cầu sharding đa-GPU.
Các hoạt động suy luận phục vụ dự đoán thời gian thực cần ít đơn vị hơn nhưng hưởng lợi từ độ trễ thấp. Công việc phát triển và tạo mẫu hoạt động tốt với GPU tầm trung để kiểm tra các thuật toán và gỡ lỗi mã.
RTX 4060 Ti với 4.352 đơn vị cho phép bạn kiểm tra mà không phải trả tiền cho phần cứng quá mức. Sau khi xác thực phương pháp của bạn, hãy mở rộng đến GPU sản xuất cho các lần chạy huấn luyện đầy đủ.
Hiển thị và công việc video mở rộng với các đơn vị đến một điểm nhất định. Bộ kết xuất Cycles của Blender sử dụng tất cả các tài nguyên có sẵn một cách hiệu quả. GPU với 8.000-10.000 đơn vị kết xuất các cảnh nhanh hơn 2-3 lần so với cảnh có 4.000 đơn vị.
Tại Cloudzy, chúng tôi cung cấp dịch vụ lưu trữ hiệu năng cao GPU VPS được xây dựng cho những công việc nặng. Chọn RTX 5090 hoặc RTX 4090 để kết xuất nhanh và suy luận AI tiết kiệm chi phí, hoặc mở rộng quy mô lên A100 cho các khối lượng học sâu lớn. Tất cả các gói chạy trên mạng 40 Gbps với các chính sách ưu tiên quyền riêng tư và các tùy chọn thanh toán tiền điện tử, cung cấp cho bạn sức mạnh thô mà không cần những thủ tục doanh nghiệp phức tạp.
Cho dù bạn đang huấn luyện các mô hình AI, kết xuất các cảnh 3D hay chạy các mô phỏng khoa học, bạn chọn số lõi phù hợp với nhu cầu của bạn.
Các cân nhắc về ngân sách quan trọng. A100 với 6.912 đơn vị có giá ít hơn đáng kể so với H100 với 16.896. Đối với nhiều hoạt động, hai A100 cung cấp tỷ lệ giá-tốc độ tốt hơn so với một H100. Điểm hòa vốn phụ thuộc vào việc mã của bạn có mở rộng trên nhiều GPU hay không.
Cách Chọn Số Lượng CUDA Cores Phù Hợp
Chọn cấu hình phù hợp với tải công việc thực tế thay vì cố gắng mua số lượng cao nhất trên thị trường.
Bắt đầu bằng cách đo lường công việc hiện tại. Nếu bạn đang huấn luyện mô hình trên phần cứng cục bộ hoặc các instance cloud, kiểm tra chỉ số sử dụng GPU. Nếu GPU hiện tại của bạn đang sử dụng 60-70% liên tục, bạn chưa dùng hết công suất.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Bài kiểm tra đơn giản này cho biết các lõi GPU của bạn có đạt được thông lượng dự kiến hay không. So sánh kết quả của bạn với các điểm chuẩn công khai cho mô hình GPU của bạn.
Nâng cấp sẽ không giúp được. Bạn cần giải quyết các nút thắt như bộ nhớ, băng thông hoặc tắc nghẽn CPU trước. Tiếp theo, ước tính yêu cầu bộ nhớ bằng cách tính kích thước mô hình tính bằng byte cộng với bộ nhớ kích hoạt.
Cộng kích thước lô với đầu ra lớp và bao gồm các trạng thái tối ưu hóa. Tổng này phải được chứa trong VRAM. Khi bạn biết bộ nhớ cần thiết, kiểm tra những GPU nào đáp ứng ngưỡng đó.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Xem xét thời gian thực hiện của bạn. Nếu bạn cần kết quả trong vài giờ, hãy chi trả thêm cho nhiều đơn vị hơn. Các lần huấn luyện có thể mất vài ngày thì chạy tốt trên GPU nhỏ hơn với thời gian hoàn thành kéo dài hơn.
Chi phí mỗi giờ nhân với số giờ cần thiết cho tổng chi phí, đôi khi khiến GPU chậm hơn rẻ hơn nhìn chung. Kiểm tra hiệu quả mở rộng bằng cách sử dụng nhiều framework có các công cụ so chuẩn cho biết sự thay đổi thông lượng.
Nếu tăng gấp đôi số đơn vị chỉ cho tốc độ 1,5 lần, các đơn vị bổ sung không đáng giá chi phí của chúng. Tìm điểm tối ưu nơi tỷ lệ giá-tốc độ cao nhất.
| Loại Khối Lượng Công Việc | Lõi Được Khuyên Dùng | GPU Ví Dụ | Ghi chú |
| Phát triển & gỡ lỗi mô hình | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Lặp lại nhanh chóng, chi phí thấp hơn |
| Huấn luyện AI quy mô nhỏ (<7B params) | 6,000-10,000 | RTX 4090, L40S | Phù hợp với người dùng cá nhân và doanh nghiệp nhỏ |
| Huấn luyện AI quy mô lớn (7B-70B params) | 14,000+ | A100, H100 | Yêu cầu GPU trung tâm dữ liệu |
| Suy luận thời gian thực (thông lượng cao) | 10,000-16,000 | RTX 5080, L40 | Cân bằng chi phí và hiệu suất |
| Kết xuất 3D & mã hóa video | 8,000-12,000 | RTX 4080, RTX 4090 | Tăng theo độ phức tạp |
| Tính toán khoa học & HPC | 10,000+ | A100, H100 | Cần hỗ trợ FP64 |
Các VPS GPU Phổ biến và Số Lõi CUDA của Chúng

Các cấp GPU khác nhau phục vụ các phân khúc người dùng khác nhau. GPUaaS là gì? Đó là GPU-as-a-Service, nơi các nhà cung cấp như Cloudzy cung cấp quyền truy cập theo yêu cầu vào những NVIDIA GPU mạnh mẽ này mà không yêu cầu bạn phải mua và duy trì phần cứng vật lý.
| Mô hình GPU | Lõi CUDA | VRAM | Băng thông bộ nhớ | Kiến trúc | Tốt nhất cho |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/s | Blackwell | Máy trạm hàng đầu, kết xuất 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | AI cao cấp, kết xuất 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Đào tạo AI quy mô lớn |
| H100 PCIe | 14,592 | 80GB HBM2e | 2,000 GB/s | Hopper | AI doanh nghiệp, trung tâm dữ liệu tiết kiệm chi phí |
| A100 | 6,912 | 40/80GB HBM2e | 1,555-2,039 GB/s | Ampere | AI tầm trung, độ tin cậy đã được chứng minh |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Game, AI tầm trung |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Trung tâm dữ liệu đa khối lượng công việc |
Thẻ RTX tiêu dùng (4070, 4080, 4090, 5080, 5090) hướng tới những người sáng tạo và game thủ nhưng hoạt động tốt cho phát triển AI. Chúng cung cấp hiệu năng đơn luồng mạnh mẽ với giá thấp hơn so với thẻ trung tâm dữ liệu.
Các nhà cung cấp VPS thường có sẵn những thẻ này cho người dùng tính toán chi phí. Thẻ trung tâm dữ liệu (A100, H100, L40) ưu tiên độ tin cậy, bộ nhớ ECC và tính năng mở rộng đa luồng. Chúng quản lý hoạt động 24/7 và hỗ trợ các tính năng nâng cao.
Multi-Instance GPU (MIG) cho phép bạn phân chia một GPU thành nhiều instance riêng lẻ. A100 vẫn phổ biến dù có các lựa chọn mới hơn vì những thông số kỹ thuật cân bằng.
Sự cân bằng giữa nhân NVIDIA, bộ nhớ và giá thành khiến nó trở thành lựa chọn an toàn cho hầu hết các hoạt động AI sản xuất. H100 cung cấp gấp 2,4 lần nhiều nhân nhưng chi phí cao hơn đáng kể.
Kết luận
Các công cụ xử lý song song làm cho AI hiện đại, rendering và tính toán khoa học trở thành khả năng. Cách chúng hoạt động và tương tác với bộ nhớ, tốc độ xung nhịp và phần mềm giúp bạn chọn cấu hình GPU VPS.
Nhiều nhân hơn sẽ giúp khi công việc của bạn song song hóa hiệu quả và các thành phần như băng thông bộ nhớ theo kịp. Nhưng chạy theo đuôi số nhân cao nhất sẽ lãng phí tiền nếu nút cổ chai của bạn nằm ở nơi khác.
Bắt đầu bằng cách phân tích hoạt động thực tế của bạn, xác định nơi tiêu tốn thời gian và khớp thông số kỹ thuật GPU với những yêu cầu đó mà không mua quá dung lượng không cần thiết.
Đối với hầu hết công việc phát triển AI, 6.000-10.000 nhân cung cấp điểm cân bằng tốt giữa chi phí và khả năng. Hoạt động sản xuất đào tạo các mô hình lớn hoặc phục vụ suy luận thông lượng cao được hưởng lợi từ GPU với 14.000+ nhân như H100.
Rendering và công việc video mở rộng hiệu quả với nhân lên tới khoảng 16.000, sau đó băng thông bộ nhớ trở thành yếu tố hạn chế.


