
Jedním z nejdůležitějších aspektů strojového učení je dosažení přesných a spolehlivých predikcí. Jedním z inovativních přístupů, který si v této oblasti získal výraznou pozornost, je bootstrap aggregating, běžněji známý jako bagging ve strojovém učení. Tento článek vysvětlí, co bagging ve strojovém učení je, porovná bagging a boosting ve strojovém učení, ukáže příklad bagging klasifikátoru, vysvětlí, jak bagging funguje, a prozkoumá jeho výhody i nevýhody.
Co je bagging ve strojovém učení?
Toto jsou jediné relevantní obrázky používané v populárních článcích, jeden nebo oba lze použít (jeden zde a druhý jinde), pokud necháme Design vytvořit jejich verze pro Cloudzy.
Co je bagging?
Představte si, že se snažíte odhadnout hmotnost předmětu tím, že požádáte více lidí o jejich odhad. Jednotlivé odhady se mohou výrazně lišit, ale průměrováním všech odhadů dospějete ke spolehlivějšímu výsledku. To je podstata baggingu: kombinování výstupů několika modelů za účelem vytvoření přesnější a spolehlivější predikce.
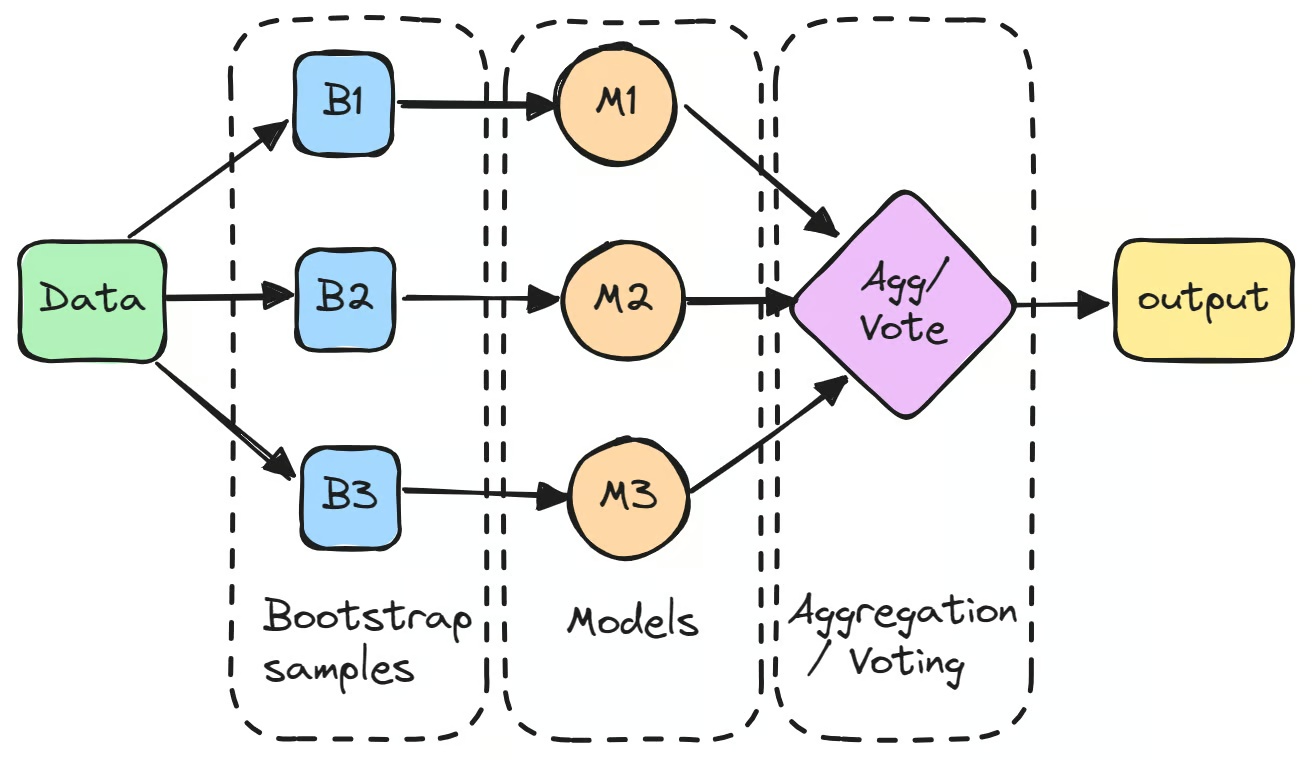
Proces začíná vytvořením více podmnožin původního datového souboru pomocí bootstrappingu, tedy náhodného vzorkování s opakováním. Každá podmnožina slouží k nezávislému trénování samostatného modelu.
Tyto jednotlivé modely, často označované jako "slabí učitelé", nemusí samy o sobě dosahovat vynikajících výsledků kvůli vysoké varianci. Když jsou však jejich predikce agregovány, zpravidla průměrováním u regresních úloh nebo hlasováním většiny u klasifikačních úloh, kombinovaný výsledek často překoná výkon libovolného jednotlivého modelu.
Typickým příkladem bagging klasifikátoru je algoritmus Random Forest, který sestavuje soubor rozhodovacích stromů za účelem zlepšení prediktivního výkonu. Je důležité nezaměňovat bagging s boostingem ve strojovém učení – boosting trénuje modely postupně, aby snížil bias, zatímco bagging trénuje modely paralelně, aby snížil rozptyl.
Bagging i boosting ve strojovém učení slouží ke zlepšení výkonu modelu, ale každý z nich řeší jinou stránku jeho chování.
Proč je bagging užitečný?
Jednou z hlavních výhod baggingu ve strojovém učení je schopnost snižovat rozptyl, díky níž modely lépe generalizují na nových datech. Bagging je zvláště užitečný u algoritmů citlivých na výkyvy v trénovacích datech, jako jsou rozhodovací stromy.
Prevencí přeučení zajišťuje stabilnější a spolehlivější model. Při porovnání baggingu a boostingu ve strojovém učení se bagging zaměřuje na snížení rozptylu tím, že trénuje více modelů paralelně, zatímco boosting se snaží snížit zkreslení sekvenčním trénováním modelů.
Příklad baggingu ve strojovém učení lze najít v předpovídání finančního rizika, kde se trénuje více rozhodovacích stromů na různých podmnožinách historických tržních dat. Agregací jejich predikcí vzniká spolehlivější předpovědní model, který snižuje dopad chyb jednotlivých modelů.
Bagging ve strojovém učení stojí na jednoduché myšlence: kombinace více modelů dává přesnější a spolehlivější předpovědi než jediný model sám o sobě.
Jak funguje bagging ve strojovém učení: krok za krokem
Abychom pochopili, jak bagging zlepšuje výkon modelu, pojďme si celý proces rozebrat krok za krokem.
Vytvořte z datové sady více bootstrapových vzorků
Prvním krokem při použití baggingu ve strojovém učení je vytvoření několika nových podmnožin z původního datasetu pomocí bootstrappingu. Tato technika spočívá v náhodném vzorkování dat s opakováním – některé datové body se tak v jedné podmnožině mohou objevit vícekrát, jiné nemusí vůbec. Díky tomu je každý model trénován na mírně odlišné verzi dat.
Trénujte samostatný model na každém vzorku
Každý bootstrap vzorek je poté použit k trénování samostatného modelu, zpravidla stejného typu, například rozhodovacích stromů. Tyto modely, označované jako „základní učitelé" nebo „slabí učitelé", jsou trénovány nezávisle na svých příslušných podmnožinách dat. Klasickým příkladem bagging klasifikátoru je rozhodovací strom využívaný v algoritmu Random Forest, který tvoří základ mnoha modelů postavených na principu baggingu. Přestože jednotlivé modely nemusí samy o sobě podávat výrazný výkon, každý z nich přináší jedinečné poznatky vycházející z jeho konkrétních trénovacích dat.
Agregujte predikce
Po natrénování modelů jsou jejich předpovědi agregovány do výsledného výstupu.
- Pro regresní úlohy se předpovědi průměrují, čímž se snižuje rozptyl modelu.
- Pro klasifikační úlohy se výsledná předpověď určuje většinovým hlasováním – vybírá se třída, kterou předpověděla nadpoloviční většina modelů. Tato metoda dává stabilnější výsledky než předpověď jediného modelu.
Finální Předpověď
Kombinací předpovědí z více modelů bagging snižuje vliv chyb jednotlivých modelů a zlepšuje celkovou přesnost. Právě tento agregační proces dělá z baggingu tak účinnou techniku, zejména v úlohách strojového učení, kde se používají modely s vysokou variancí, jako jsou rozhodovací stromy. Efektivně vyhlazuje nesrovnalosti v předpovědích jednotlivých modelů a výsledkem je silnější výsledný model.
Bagging je účinný způsob, jak stabilizovat predikce, ale je tu několik věcí, které je dobré mít na paměti. Pokud jsou základní modely příliš složité, hrozí přetrénování, a to i přesto, že bagging je obecně navržen právě k jeho potlačení.
Jde také o výpočetně náročný přístup, takže může pomoci úprava počtu základních modelů nebo volba efektivnějších metod souborového učení, a výběr správného GPU pro ML a DL je vždy důležité.
Dbejte na to, aby se základní modely od sebe lišily – diverzita mezi nimi vede k lepším výsledkům. Pokud pracujete s nevyváženými daty, zvažte před aplikací baggingu techniky jako SMOTE, abyste předešli slabé výkonnosti na menšinových třídách.
Aplikace Baggingu
Teď když víme, jak bagging funguje, podívejme se, kde se skutečně používá v praxi. Bagging si našel uplatnění v celé řadě odvětví, kde pomáhá zlepšovat přesnost a spolehlivost předpovědí v složitých situacích. Pojďme se blíže podívat na některé z nejvýznamnějších použití:
- Klasifikace a regrese: Bagging se hojně využívá ke zlepšení výkonu klasifikátorů a regresorů – snižuje rozptyl a zabraňuje přetrénování. Například Random Forests, které bagging využívají, dobře fungují při klasifikaci obrázků nebo prediktivním modelování.
- Detekce anomálií V oblastech jako je detekce podvodů a detekce síťových průniků nabízejí baggingové algoritmy vynikající výkon díky efektivní identifikaci odlehlých hodnot a anomálií v datech.
- Hodnocení finančního rizika: Baggingové techniky se v bankovnictví využívají ke zlepšení modelů kreditního skórování, což zvyšuje přesnost procesů schvalování úvěrů a hodnocení finančních rizik.
- Lékařská Diagnostika Ve zdravotnictví byl bagging použit k detekci neurokognitivních poruch, jako je Alzheimerova choroba, a to analýzou MRI datasetů. Přispívá tak k včasné diagnostice a plánování léčby.
- Zpracování přirozeného jazyka (NLP): Bagging přispívá k úlohám, jako je klasifikace textu a analýza sentimentu, agregací predikcí z více modelů, což vede k přesnějšímu porozumění jazyku.
Výhody a nevýhody baggingu
Stejně jako každá technika strojového učení má bagging své výhody i nevýhody. Jejich pochopení pomáhá rozhodnout, kdy a jak bagging ve svých modelech použít.
Výhody balení:
- Snižuje rozptyl a přetrénování: Jednou z nejvýznamnějších výhod baggingu ve strojovém učení je schopnost snižovat rozptyl, čímž zabraňuje přetrénování. Trénováním více modelů na různých podmnožinách dat zajišťuje bagging, že model není příliš citlivý na výkyvy v trénovacích datech, a výsledkem je obecnější a stabilnější model.
- Dobře funguje s modely s vysokým rozptylem: Bagging je obzvláště účinný v kombinaci s modely s vysokým rozptylem, jako jsou rozhodovací stromy. Tyto modely mají tendenci k přetrénování a vysokému rozptylu, ale bagging to zmírňuje průměrováním nebo hlasováním přes více modelů. Predikce jsou tak spolehlivější a méně náchylné k ovlivnění šumem v datech.
- Zlepšuje stabilitu a výkon modelu: Kombinováním více modelů trénovaných na různých podmnožinách dat bagging často vede k lepšímu celkovému výkonu. Zvyšuje prediktivní přesnost a zároveň snižuje citlivost modelu na malé změny v datové sadě, což model celkově činí spolehlivějším.
Nevýhody Baggingu:
- Zvyšuje výpočetní náročnost: Protože bagging vyžaduje trénování více modelů, přirozeně zvyšuje výpočetní náročnost. Trénování a agregace predikcí z mnoha modelů může být časově náročné, zejména při práci s velkými datovými sadami nebo složitými modely, jako jsou rozhodovací stromy.
- Není účinný pro modely s nízkým rozptylem: Zatímco u modelů s vysokým rozptylem je bagging velmi účinný, u modelů s nízkým rozptylem, jako je lineární regrese, nepřináší příliš velký přínos. V těchto případech mají jednotlivé modely již tak nízkou chybovost, takže agregace predikcí výsledky příliš nezlepší.
- Ztráta interpretovatelnosti: Kombinací více modelů může bagging snížit interpretovatelnost výsledného modelu. Například v Random Forest je rozhodovací proces založen na více rozhodovacích stromech, což ztěžuje sledování logiky za konkrétní predikcí.
Kdy použít bagging?
Vědět, kdy bagging v projektech strojového učení použít, je klíčem k dosažení optimálních výsledků. Tato technika funguje dobře v konkrétních situacích, ale není vždy nejlepší volbou pro každý problém.
Když je váš model náchylný k přetrénování
Jedním z hlavních případů použití baggingu je situace, kdy je váš model náchylný k přetrénování, zejména u modelů s vysokým rozptylem, jako jsou rozhodovací stromy. Tyto modely mohou na trénovacích datech dosahovat dobrých výsledků, ale při zobecnění na neznámá data často selhávají, protože se příliš těsně přizpůsobí konkrétním vzorům trénovací sady.
Bagging tento problém řeší tak, že trénuje více modelů na různých podmnožinách dat a jejich výstupy průměruje nebo kombinuje hlasováním, čímž vzniká stabilnější predikce. To snižuje riziko přeučení a model lépe zvládá nová, dosud neviděná data.
Když chcete zvýšit stabilitu a přesnost
Pokud chcete zvýšit stabilitu a přesnost svého modelu, aniž byste příliš obětovali srozumitelnost, je bagging výbornou volbou. Agregace predikcí z více modelů dělá výsledek spolehlivějším, což se hodí zejména při práci s daty obsahujícími šum.
Ať už řešíte klasifikační úlohy nebo regresní problémy, bagging pomáhá dosáhnout konzistentnějších výsledků a zároveň zvyšuje přesnost při zachování efektivity.
Když máte dostatek výpočetních zdrojů
Dalším důležitým faktorem při rozhodování, zda bagging použít, je dostupnost výpočetních zdrojů. Protože bagging vyžaduje trénování více modelů současně, mohou být výpočetní náklady značné, zejména u velkých datových sad nebo složitých modelů.
Pokud máte k dispozici potřebný výpočetní výkon, přínosy baggingu náklady výrazně převyšují. Pokud jsou ale zdroje omezené, zvažte alternativní techniky nebo omezte počet modelů v ansámblu.
Když pracujete s modely s vysokou variancí
Bagging je zvlášť užitečný u modelů s vysokou variancí, které jsou citlivé na výkyvy v trénovacích datech. Rozhodovací stromy se například často používají s baggingem v podobě Random Forests, protože jejich výkon se výrazně liší v závislosti na trénovacích datech.
Trénováním více modelů na různých podmnožinách dat a kombinováním jejich predikcí bagging varianci vyhlazuje a výsledný model je spolehlivější.
Když potřebujete odolný klasifikátor
Pokud pracujete na klasifikačních úlohách a potřebujete odolný klasifikátor, bagging může výrazně zlepšit stabilitu vašich predikcí. Například Random Forest, což je typický příklad bagging klasifikátoru, dokáže poskytnout přesnější predikci agregací výsledků mnoha jednotlivých rozhodovacích stromů.
Tento přístup funguje dobře i tehdy, když jsou jednotlivé modely slabé, protože jejich kombinovaný výkon tvoří silný celkový model.
Pokud hledáte vhodnou platformu pro efektivní implementaci technik baggingu, nástroje jako Databricks a Snowflake nabízejí jednotnou analytickou platformu, která může být velmi užitečná pro správu velkých datových sad a spouštění ansámblových metod, jako je bagging.
Pokud preferujete méně technický přístup k strojovému učení, Nástroje AI bez kódu může být další možností. I když se přímo nezaměřují na pokročilé techniky jako bagging, mnoho no-code platforem umožňuje uživatelům experimentovat s metodami ansámblového učení včetně baggingu bez potřeby hlubokých znalostí programování.
To vám umožní využívat sofistikovanější techniky a dosahovat přesných predikcí, aniž byste se museli soustředit na samotný kód, a zaměřit se místo toho na výkon modelu.
Závěrečné myšlenky
Bagging je v strojovém učení účinná technika, která zlepšuje výkon modelu snížením variance a zvýšením stability. Agregací predikcí více modelů trénovaných na různých podmnožinách dat pomáhá bagging dosahovat přesnějších a spolehlivějších výsledků. Je zvlášť efektivní u modelů s vysokou variancí, jako jsou rozhodovací stromy, kde pomáhá předcházet přeučení a zajišťuje, že model lépe generalizuje na neviděná data.
Přestože má bagging významné výhody, jako je snížení přeučení a zlepšení přesnosti, přináší i určité kompromisy. Zvyšuje výpočetní náklady kvůli trénování více modelů a může snížit srozumitelnost. I přes tyto nevýhody je díky schopnosti zvýšit výkon cennou technikou v ansámblovém učení, spolu s dalšími metodami jako boosting a stacking.
Použili jste bagging ve svých projektech strojového učení? Podělte se s námi o své zkušenosti a o tom, jak vám to fungovalo!


