GPU-monitoreringssoftware er det, der kan omdanne "min GPU virker mærkeligt" til en direkte og klar forklaring, som "hotspot gik i vejret, clockfrekvenser faldt, og VRAM blev fyldt op."
I denne vejledning viser jeg dig værktøjerne, du kan bruge til AI-jobs, gaming-overlays og lange arbejdsøkter, og jeg viser dig de GPU-målinger, der hjælper dig med at diagnosticere langsommelighed, stuttering og nedbrud.
Til slut har du et GPU-monitoreringssoftware-setup, der passer til hvordan du arbejder. Du får også kopierbare stacks til fire almindelige use cases, så du ikke skal søge i artikler igen.
Hurtig svar: Top GPU Monitoreringssoftware efter use case
Hvis du bare ønsker en kort liste, der matcher hvordan folk egentlig arbejder, start med disse. I praksis består den bedste GPU-monitoreringssoftware-stack sædvanligvis af en kombination: et værktøj til hurtige tjek, et til overlays eller logs, og et til historik eller advarsler.
Her er det hurtige overblik:
| Brugssituation | Bedste startstack | Det du får |
| AI-træning, inferens, HPC-jobs | nvidia-smi (NVIDIA) eller AMD SMI (AMD) + logging/exporter | Hurtige tjek, scriptbare logs, simpel alerting |
| Gaming på Windows | MSI Afterburner + RTSS + et frametime-opsamlingsværktøj | Overlay plus bevis for stuttering kontra lav FPS |
| Spil på Linux | MangoHud + en terminal-checker (nvtop) | Let overlay plus per-proces sanitetskontrol |
| Arbejdsstationer (3D/video/CAD) | HWiNFO-logging + en simpel stresstest | Lange logs du kan dele, reproducerbar fejl |
| Delt GPU-maskiner | nvtop (Linux) + eksportør/kontrolpanel | Per-proces VRAM-synlighed |
Herfra handler det mest om at matche GPU overvågningssoftware til din måde at forbruge data på: på skærmen, i en log eller på et dashboard.
Hvem denne guide er til
Jeg skriver dette som nogen, der har været nødt til at debugge rigtige maskiner. Det skyldes, at jeg ved fra erfaring, at forskellige læsere har brug for forskellige GPU værktøjer, selv hvis de kigger på det samme GPU.
Her er de fire setups jeg sigter mod:
- Model Builder (AI/ML): fokuserer på VRAM buffer, stabile clockhastigheder, throttling og "kørte jobbet hele natten uden at gå i stykker?"
- Kompetitiv gamer/streamer: fokuserer på frametider, overlay-stabilitet og registrering af regressioner efter driveropdateringer.
- Workstation-bruger (3D/video/CAD): fokuserer på logs, reproducerbare crashes og isolering af problemer med varme vs strøm vs driveradfærd.
- Admin, der kører GPU-maskiner: fokuserer på advarsler, trendgrafer, kapacitetsplanlægning og tidlig fejldetektering.
Når du ved hvilken kategori du tilhører, kan du nemt vælge den GPU overvågningssoftware, der passer til dig.
Sådan vælger du GPU overvågningssoftware
Mange performance monitoring-apps ser ens ud, indtil du skal bruge dem i en uge. Forskellen ligger som regel i output og pålidelighed, ikke i de attraktive "features", som hver enkelt desperat markedsfører.
Her er tre spørgsmål, der hjælper dig med hurtigt at vælge GPU overvågningssoftware:
- Har du brug for overlay, log eller begge dele?
Gamere vil have overlay. AI- og workstation-arbejde kræver typisk logging. Admins vil have logs plus advarsler. - Har du brug for synlighed per proces?
Hvis du deler en maskine (lab, studie, fjernserver), er per-proces VRAM ofte det første, du kigger efter. - Har du brug for historik og advarsler?
Hvis jobs kører hele natten, er "jeg tjekker det senere" ikke tilstrækkeligt. Du ønsker en graf og en advarsel.
For at holde det praktisk, er resten af guiden organiseret efter GPU metrikkerne først, derefter tool-stacks, der passer til hver use-case.
GPU metrikkerne du bør prioritere
Good GPU overvågningssoftware giver dig masser af tal. Virkelig brugbar GPU overvågningssoftware giver dig det specifikke sæt, der forklarer adfærd. Jeg grupperer GPU metrikkerne efter den beslutning, de hjælper dig med at træffe.
Termiske data og droslingmålinger
Dette er GPU-målingerne som forklarer "det var hurtigt i 10 minutter, så var det ikke":
- GPU-temperatur
- Hotspot-temperatur (ofte det første der stiger)
- Hukommelsestemperatur/junction (mere relevant ved lange AI-kørsler og lange renderinger)
- Blæserhastighed (hjælper med at spotte laptop-profiler eller dårlige fan-kurver)
Hvis du gerne vil forbedre stabiliteten, log disse målinger. Enkeltudsnit giver sjældent nok information.
Strøm, clockhastigheder og grænser
Disse GPU-målinger forklarer nedklocking og uensartet ydeevne:
- Strømforbrug på kortet
- Core clock og hukommelsesclock
- Strømgrænse/ydelsesstatus (hvis dit værktøj viser det)
I meget virkelighedens debugging giver strøm og clockhastigheder et meget klarere billede end simpel "GPU-udnyttelse %".
VRAM og hukommelsespres
Disse GPU-målinger forklarer stutter, OOM-fejl og de typiske "tilfældige" vendinger:
- VRAM brugt vs i alt
- Hukommelseskontrolleraktivitet (hjælper med at spotte båndbredde-grænser)
- Systemhukommelsespres (fordi VRAM-overløb kan også trække systemet ned)
For AI er VRAM ofte den hårde grænse. For spil viser VRAM-pres sig ofte først som frametime-toppe.
Frametime og frame pacing-målinger
For gaming og streaming kan FPS alene være vildledende. Frametime er den målinger du skal være opmærksom på, da det viser glatheden eller manglen deraf:
- Frametime (ms)
- 1% lav / 0.1% lav (godt til sammenligninger)
- GPU belastning vs CPU belastning (hjælper med at skelne GPU flaskehalse fra CPU flaskehalse)
Derfor inkluderer spil-orienterede performance monitoring-apps ofte en frametime capture-sti. Nu hvor vi har det grundlæggende på plads, kan vi tale om de bedste GPU monitoring software-stakke til hver workflow.
GPU Monitoring Software til AI, Training og Servere

AI monitoring har et simpelt setup med hurtige checks i terminalen, plus logs og alerts til længerevarende kørsler. Til dette skal du have GPU monitoring software der understøtter CLI og eksporterer metrics.
NVIDIA: nvidia-smi til hurtige checks og scriptbare logs
På NVIDIA-systemer, nvidia-smi er normalt den første kommando folk kører, fordi den følger med driveren og er designet til monitoring og styring via NVML.
Officiel dokumentation findes her: NVIDIA-systemstyringsinterface (nvidia-smi).
Hvis du ønsker en simpel "log det og se på det senere"-tilgang (og du ville blive overrasket over hvor ofte det løser problemet), er dette mønster ret pålidelig:
nvidia-smi –query-gpu=timestamp,name,utilization.gpu,utilization.memory,memory.used,memory.total,temperature.gpu,power.draw,clocks.sm \
–format=csv,noheader,nounits -l 5 >> gpu_log.csv
Dette er grundlæggende GPU monitoring software-adfærd med timestamps, vigtige GPU metrics, og et output der fungerer godt med scripts.
AMD: AMD SMI til ROCm og HPC-noder
På AMD Linux compute-noder er AMD SMI det moderne monitoring- og styringsinterface, og AMD dokumenterer det som et samlet værktøjssæt til monitoring og kontrol i HPC-sammenhænge.
Officiel dokumentation findes her: AMD SMI dokumentation.
Hvis dit miljø er AMD-tungt, er AMD SMI det GPU monitoring software-fundament som andet værktøj normalt bygger på.
Per-process visibilitet: nvtop til delte GPUs
Hvis du nogensinde har haft en delt boks hvor VRAM "mystisk" bliver fuld, giver per-process visibilitet dig tid tilbage. På Linux, nvtop er populær af netop den grund, fordi den gør "hvem bruger VRAM?" åbenlyst. På AMD/Intel skal du muligvis have en nylig kernel for per-process statistik.
I blandede teams ser jeg ofte folk køre nvtop side om side med nvidia-smi eller AMD SMI. Det er en simpel kombination der undgår meget gætteri, så jeg anbefaler det varmt.
Overses ikke hardwarevalget!
Overvågning løser ikke et VRAM loft; det gør bare loftet synligt. Hvis du stadig mapper workloads til GPU tiers, hjælper vores guide på Bedste GPU til machine learning i 2025 som et brugbart supplement, fordi den præsenterer VRAM og båndbredde på samme måde som du læser dem senere i logs og dashboards.
Når du har styr på GPU overvågningssoftware til servere, er næste trin overlays og frametider, da interaktive workloads opfører sig anderledes.
GPU overvågningssoftware til gaming og streaming

Gaming er hvor folk har de stærkeste meninger om GPU værktøjer, primært fordi overlays fejler på det værst tænkelige tidspunkt. Til gaming vil du have simple overlays og pålidelige frametime-registreringer.
MSI Afterburner + RTSS til overlays på Windows
Den kombination er ret populær fordi du kan bygge et rent overlay med præcis de GPU-målinger du har brug for, såsom forbrug, clockfrekvenser, VRAM, temperatur, frametime og eventuelt blæserhastighed.
En alvorlig advarsel som dukker op gentagne gange i community-tråde er falske downloadsteder. MSI's egen Afterburner-side påpeger at legitime downloads skal komme fra msi.com og Guru3D, og den viser også den aktuelle releaselinje (4.6.6 final, udgivet oktober 2025).
Overlay-problemer er en anden ting at være opmærksom på. For eksempel fungerer RTSS i nogle spil og fejler i andre, især med moderne render paths. Folk rapporterer tilfælde hvor overlayét vises i Vulkan men ikke DX12 for samme titel, eller forsvinder efter opdateringer.
Men det skyldes ikke en fejl fra din side, det er bare hvad der sker når overlays hooker ind i skiftende spil- og driver-stakke.
Hvis du vil have et stabilt baseline overlay, hold det kort:
- frametid
- GPU-forbrug
- VRAM brugt
- GPU-temperatur
Tilføj kun strøm og clocks, hvis du aktivt debugger throttling.
Frametime-registrering for "stutter"
Det er her performance-monitoring apps som kan registrere frametime-grafer hjælper meget. Gennemsnitlig FPS kan se fint ud mens frame pacing føles dårlig. Frametime-grafer afklarer det hurtigt.
Mange gaming benchmark-workflows benytter PresentMon under motorhjelmen, og NVIDIA dokumenter at dets FrameView-analyse bruger PresentMon til frame rate og frametime-registrering.
Du behøver ikke benchmarke hvert spil. Frametime-registrering er mest brugbar til sammenligninger, som før og efter en driver-opdatering, før og efter ændring af en limiter, før og efter ændring af indstillinger, og så videre.
MangoHud til Linux overlays
På Linux bliver MangoHud anbefalet meget fordi det er let og integreres pænt med Steam/Proton-opsætninger. De mest almindelige klager handler om manglende sensorer eller udsendelser på hybrid laptop-opsætninger.
I praksis kan du nemt kombinere MangoHud med en terminal-checker som nvtop. Det er også et godt eksempel på hvordan GPU overvågningssoftware fungerer markant bedre som en lille stack i stedet for én stor monolitisk app.
Fra gaming er det naturligt næste trin arbejdsstationsovervågning, fordi logfiler og reproducerbar fejlsøgning er det vigtigste.
Host lagfrie gameservere med højhastigheds NVMe VPS-hosting.
VPS til gaming
GPU Overvågningssoftware til arbejdsstationer og professionelle applikationer
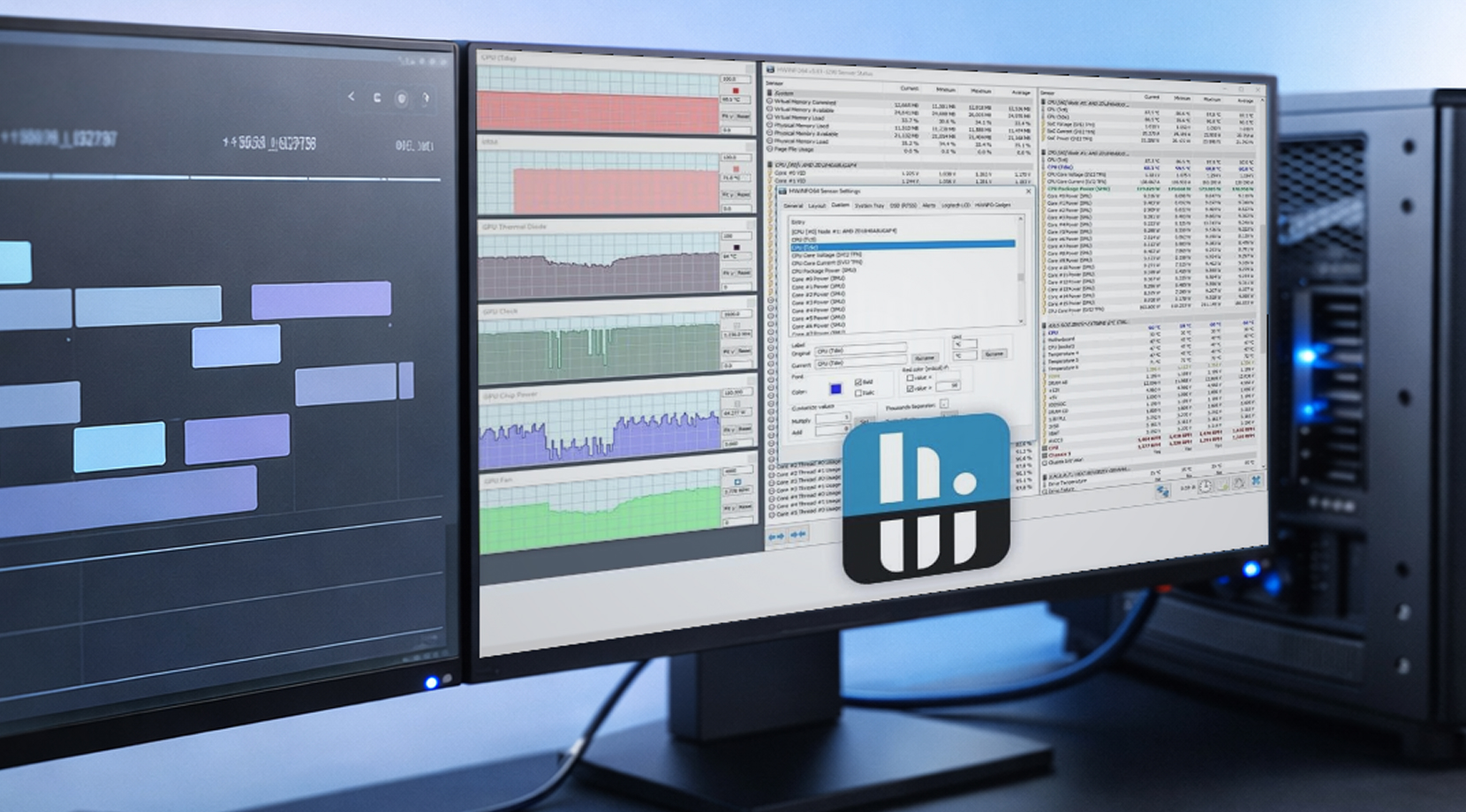
Arbejdsstationsovervågning er mindre om at være sikkerhedsofficer, der ser et live-overlay, og mere om at svare på 'Hvad skete der over tid, og kan jeg genskabe det?'
HWiNFO til logging på Windows
HWiNFO er populær blandt arbejdsstationsbrugere, fordi det har omfattende sensordata og logging, som er nemt at dele. En simpel CSV-log med tidsstempler kan nemt gøre en vag rapport til noget, du aktivt kan bruge til at løse problemer.
Hvis du bygger en arbejdsstationslog for GPU-stabilitet, start med disse GPU-metrics:
- GPU-temperatur og hotspot
- VRAM brugt
- boardstrøm
- kernefrekvens
- CPU-pakkestrøm (fordi platformens strømgrænser kan give problemer)
Dette er 'nok data til at forklare det'-sættet. Det skyldes, at logging af hver sensor bare gør filen sværere at læse.
GPU-Z til hurtige 'hvilken GPU er det her?' tjek
GPU-Z er stadig nyttig, fordi det er hurtigt og fokuseret. På teams med blandet hardware er det den hurtigste måde at bekræfte GPU-modellen, driverbasics og live-sensorer på uden at grave gennem menuer.
Stresstest: kun brugbar med logging
Stresstests kan hjælpe med at genskabe et nedbrud, men kun hvis din GPU-overvågningssoftware logger, mens du kører dem. Uden disse logs bliver du siddende med 'det styrtede ned igen' og stort set ingen tidslinje.
På dette punkt støder de fleste på de samme problemer, såsom overlays, der ikke vises, strømaflesninger, der ser forkerte ud, og logfiler, der bliver ulæselige. Lad os håndtere disse direkte.
Almindelige problemer med GPU-monitoreringssoftware og hurtige løsninger

De fleste problemer falder i få mønstre. Dette er de løsninger, jeg prøver først, fordi de løser det kedelige hurtigt.
Overlay mangler i et spil
Hvis et overlay forsvinder i en moderne titel, er det ofte et per-spil hook-problem eller en konflikt med anti-cheat eller anti-tamper-lag.
Det du kan gøre, der ofte hjælper:
- Opdater RTSS og nulstil per-spil-profilen
- Indstil et højere 'application detection level' for spilprofilen
- Prøv en anden API, hvis spillet understøtter det
- Gå tilbage til indbyggede overlays, når en titel blokerer tredjeparts-overlays
Ikke alle spil vil samarbejde, og det er ikke værd at miste timer på en urolig titel.
Usædvanlige strømafledninger (0W, flade kurver, manglende sensorer)
Det optræder ofte på bærbare computere og hybride opsætninger, hvor den aktive GPU kan ændres. I sådan tilfælde bør du dobbelttjekke med et andet værktøj, som nvidia-smi (NVIDIA) eller AMD SMI (AMD), da de er gode til at tjekke, om GPU faktisk er aktiv.
Log-filer med for meget støj
Oversampling er som regel årsagen. Til de fleste fejlfindinger er 1-5 sekunder tilstrækkeligt. For længerevarende AI-jobs er 5 sekunder fint. Kortere intervaller gør filstørrelsen større og gør diagrammer sværere at læse.
Når grundlaget er på plads, bliver fjernmonitoring det næste logiske skridt, fordi mange GPU-workflows nu kører uden for maskinen.
Fjernmonitoring af GPU og en praktisk cloudløsning
Fjernarbejde ændrer, hvad "god GPU-monitoringssoftware" betyder. Du sidder ikke altid foran maskinen, så du har brug for tests, du kan køre hurtigt, plus historie, du kan gennemgå senere.
En velorganiseret fjernopsætning ser normalt sådan ud:
- CLI-kontroller (nvidia-smi eller AMD SMI)
- en logfil, du kan hente senere
- en eksportør/dashboard, hvis du har brug for advarsler
Hvis lokalt hardware holder dig tilbage (VRAM-begrænsninger, deling af en enkelt GPU, behov for et rent miljø per projekt), kan køring af arbejdsbelastninger på en GPU VPS være den enkleste vej til at komme videre.
Cloudzy GPU VPS

Hvis du ønsker fjern-GPU-tid, der passer til AI-, spil- og renderingsworkflows, er vores Cloudzy GPU VPS udstyret med NVIDIA-muligheder som RTX 5090, A100 og RTX 4090, plus NVMe-lagerkapacitet, fuld root-adgang, forbindelser på op til 40 Gbps, DDoS-beskyttelse og et tilstået 99,95%-driftidsmål.
Fra et monitoringsynspunkt fungerer den som en normal maskine, da du kan køre GPU-monitoringssoftware over SSH, logge GPU-metriske data til længerevarende jobs og tilføje dashboards, hvis du ønsker historie og advarsler.
Hvis du stadig vælger mellem en GPU-instans og en CPU-eneste opsætning, gennemgår vores artikler Hvad er en GPU VPS? og GPU versus CPU VPS de praktiske forskelle efter arbejdsbelastningstype.
Med fjernmonitoring dækket er det sidste trin at samle det hele til genkendelige stacks.
Genkendelige stacks for hver persona
Her er nemme, trin-for-trin stacks, du kan tilpasse uden at omskrive hele dit arbejdsflow. De er gode startpunkter til dine opsætninger, som du senere kan tilpasse efter dine specifikke behov.
- Modelbuilder (AI/ML): GPU-monitoringssoftware via nvidia-smi eller AMD SMI, plus en simpel CSV-log, plus en eksportør/dashboard, hvis jobs kører uden opsyn.
- Konkurrencespiller/streamer: GPU-monitoringssoftware overlay via Afterburner + RTSS, plus et frametime-capturingværktøj til sammenligninger, plus et minimalt metrisk sæt på skærmen.
- Workstation Bruger: GPU overvågningssoftware via HWiNFO-logging, plus GPU-Z til hurtige identitetskontroller, plus stresstest kun når du kan logge kørslen.
- Administration af GPU-maskiner: GPU overvågningssoftware som service: eksportør + dashboards + alarmer, plus visibilitet pr. proces (nvtop) til delte servere.
Hvis du kun tager én ting med fra denne guide, så gør det her: vælg GPU overvågningssoftware ud fra hvor du har brug for dataene (overlay, log, dashboard), og hold dit metrikset lille nok til at du faktisk bruger det.