
Con la creciente demanda de LLM locales, muchos usuarios se pierden a la hora de elegir el más adecuado. Además, ponerlos en marcha no es tan sencillo como parece. Su consumo de recursos es moderado, aunque algunos son más exigentes que otros, lo que hace que muchos prefieran evitarlos. Sin mencionar las horas que los usuarios menos experimentados pueden pasar mirando la terminal sin saber qué hacer.
Hay, sin embargo, dos opciones destacadas que simplifican el proceso. Ollama y LM Studio son dos de las plataformas más utilizadas para ejecutar LLM locales con un rendimiento sólido. Aun así, elegir entre ambas puede ser difícil, ya que cada una está pensada para flujos de trabajo distintos. Sin más preámbulos, veamos la comparativa de Ollama vs LM Studio.
Ollama: una herramienta pensada para perfiles técnicos
Entre las opciones para ejecutar LLM locales, Ollama destaca por su amplio conjunto de funciones. Es altamente configurable y, además, gratuita, al tratarse de una plataforma de código abierto mantenida por la comunidad.
Aunque Ollama simplifica la ejecución de LLM locales, es una herramienta CLI principalmente (interfaz de línea de comandos), por lo que requiere cierto conocimiento de la terminal. Ese enfoque CLI es una ventaja clara en flujos de trabajo de desarrollo gracias a su sencillez. Trabajar con una CLI no es trivial, pero resulta menos costoso de aprender que configurar LLM locales desde cero.
Ollama convierte tu ordenador en un mini-servidor local con una HTTP API, lo que permite que tus aplicaciones y scripts accedan a sus modelos. El resultado es que responde a los prompts igual que un LLM en línea, pero sin enviar tus datos a la nube. Además, su API permite integrar Ollama con sitios web y chatbots.
Por su naturaleza CLI, Ollama también es bastante ligero: consume pocos recursos y está orientado al rendimiento. Esto no significa que puedas ejecutarlo en cualquier equipo antiguo, pero es una opción razonable para quienes quieren destinar el máximo de recursos al propio modelo LLM.
Con todo lo anterior, probablemente ya hayas deducido que Ollama está muy orientado a flujos de trabajo de desarrollo, y es así. Su fácil integración, la privacidad local y el diseño centrado en la API lo convierten en la elección obvia si tienes un perfil de desarrollador.
En la comparativa Ollama vs LM Studio, Ollama puede ser la opción preferida gracias a su desarrollo centrado en la API. Si una CLI te resulta demasiado ajena, sigue leyendo para conocer una alternativa más accesible, diseñada pensando en la facilidad de uso.
LM Studio: la opción más accesible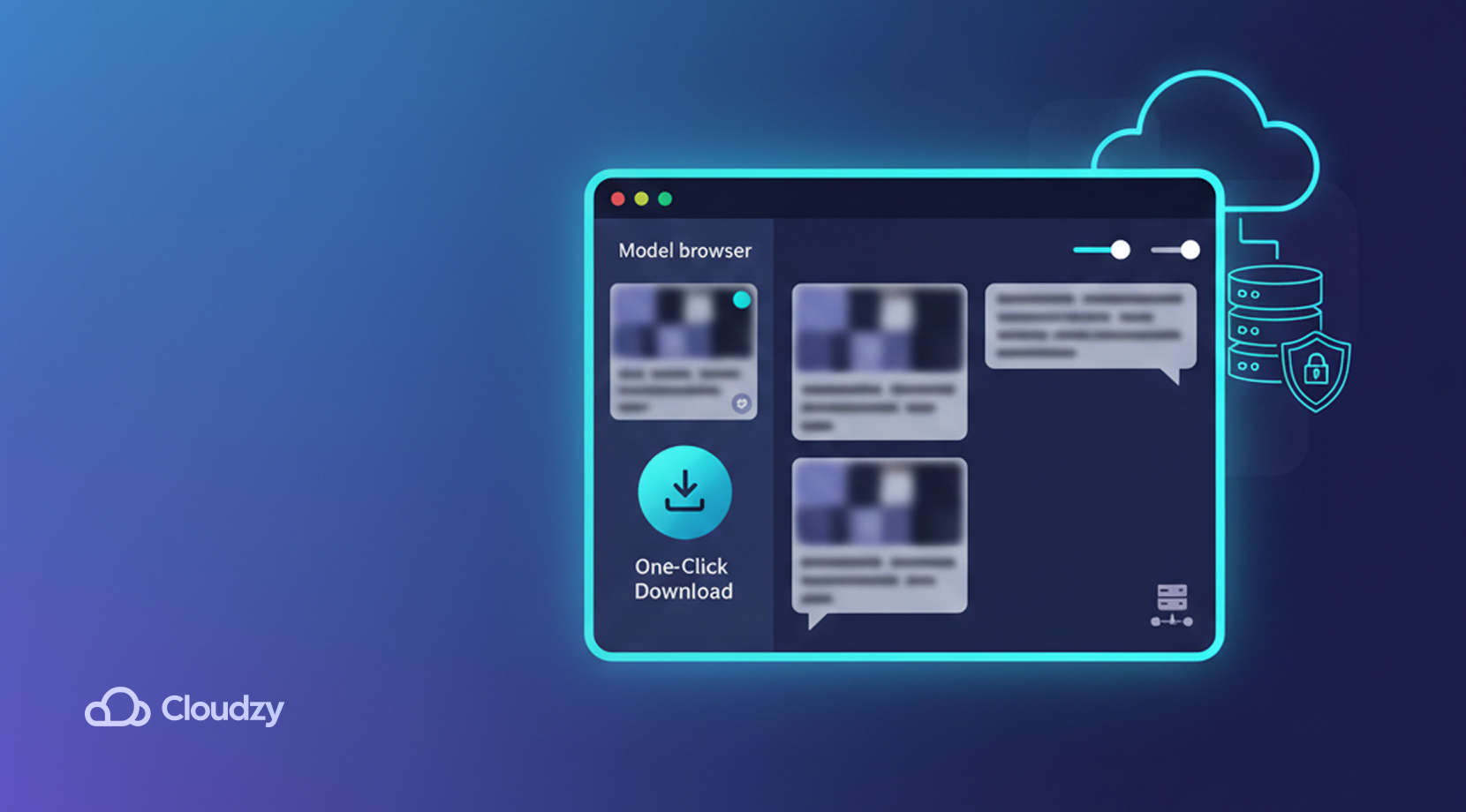
LM Studio es muy diferente a Ollama. En lugar de ser una interfaz CLI completa, no requiere ningún comando de terminal para funcionar. Al contar con una GUI (interfaz gráfica de usuario), se comporta como cualquier otra aplicación de escritorio. Para muchos usuarios nuevos, la comparativa Ollama vs LM Studio se reduce a elegir entre la simplicidad de una CLI y una GUI.
El enfoque de LM Studio para eliminar las barreras técnicas facilita una experiencia sencilla para cualquier tipo de usuario. En lugar de añadir y ejecutar modelos mediante comandos, puedes usar los menús de la aplicación y escribir en un campo de chat. LM Studio resulta accesible para casi cualquier persona que quiera experimentar con LLM locales, ya que su interfaz recuerda a la de ChatGPT.
Incluso incluye un explorador de modelos integrado donde los usuarios pueden descubrir y desplegar el modelo que prefieran, desde modelos ligeros pensados para tareas cotidianas hasta opciones más potentes para trabajos más exigentes. Además, este explorador ofrece descripciones breves de cada modelo, casos de uso recomendados y permite descargarlos con un solo clic.
Aunque la mayoría de los modelos son gratuitos, algunos pueden incluir licencias adicionales y condiciones de uso. Para ciertos flujos de trabajo, LM Studio también puede ofrecer un modo de servidor local para facilitar integraciones, aunque está diseñado principalmente como una interfaz de escritorio accesible para usuarios sin experiencia técnica. Dicho esto, veamos Ollama y LM Studio uno frente al otro.
Observaciones clave: Ollama vs LM Studio
Antes de continuar, conviene aclarar algo importante: la expresión "Ollama vs LM Studio" podría dar a entender que una es objetivamente mejor que la otra, pero no es así, ya que están pensadas para perfiles distintos. Aquí tienes un resumen rápido de Ollama vs LM Studio.
| Característica | Ollama | LM Studio |
| Facilidad de uso | Menos intuitivo al principio; requiere conocimientos de terminal | Fácil para principiantes; todo se maneja con clics |
| Compatibilidad con modelos | Gran variedad de modelos de código abierto populares: gpt-oss, gemma 3, qwen 3 | Los mismos que Ollama: gpt-oss, gemma3, qwen3 |
| Personalización | Muy personalizable; se integra fácilmente mediante API | Menos flexible; los ajustes se hacen mediante interruptores y controles deslizantes |
| Requisitos de hardware | Eso depende; los modelos más grandes son más lentos sin suficiente hardware | También depende del tamaño del modelo y del hardware disponible |
| Privacidad | Privacidad garantizada por defecto; sin API externos adicionales | Los chats se quedan en local; la app sí contacta con servidores para actualizaciones y búsqueda o descarga de modelos. |
| Uso sin conexión | Totalmente funcional sin conexión una vez descargados los modelos | También funciona sin conexión una vez descargados los modelos |
| Plataformas disponibles | Linux, Windows, macOS | Linux, Windows, macOS |
- Modelos avanzados y exigencia de hardware: Siempre que es posible, lo normal es optar por modelos más grandes y capaces. Sin embargo, ejecutarlos en la mayoría de portátiles puede causar problemas serios, ya que los modelos más grandes consumen más CPU y VRAM. Esto puede traducirse en respuestas lentas, un contexto limitado o que el modelo directamente no cargue.
- Problemas de batería: Ejecutar LLMs localmente puede agotar la batería rápidamente bajo carga elevada. Esto reduce la autonomía y, de paso, hace que los ventiladores y el disipador de calor generen un ruido bastante molesto.
Ollama vs LM Studio: descarga de modelos
Otra diferencia entre Ollama y LM Studio es cómo descargan los modelos. Como se mencionó antes, Ollama no instala LLMs locales con un solo clic. En su lugar, hay que usar su terminal integrado y comandos de texto. Los comandos, eso sí, son sencillos de entender.
Aquí tienes una forma rápida de ejecutar modelos en Ollama.
- Descarga tu modelo favorito escribiendo ollama pull gpt-oss o cualquier otro modelo que prefieras (no olvides incluir una etiqueta, que puedes elegir desde la biblioteca).
Ejemplo: ollama pull gpt-oss:20b - Luego puedes ejecutar ese modelo con el comando ollama run gpt-oss
- También puedes añadir más herramientas. Por ejemplo, puedes añadir Claude con ollama launch claude
Si los terminales y comandos no son lo tuyo, prueba LM Studio. No necesitas escribir nada en ningún terminal para empezar a usarlo y descargar modelos. Ve directamente a su descargador de modelos integrado y busca LLMs por palabras clave como Llama o Gemma.
También puedes introducir Hugging Face URLs completos en la barra de búsqueda.
Incluso puedes acceder a la pestaña de descubrimiento desde cualquier lugar pulsando ⌘ + 2 en Mac, o Ctrl + 2 en Windows / Linux.
Ollama: Superior en velocidad
A veces la velocidad lo es todo, tanto para usuarios como para empresas. En la comparativa de Ollama vs LM Studio en términos de velocidad, Ollama resulta más rápido, aunque los resultados pueden variar según la configuración y el hardware.
En el caso de un usuario de Reddit en el subreddit r/ollama, Ollama procesó más rápido que LM Studio.
Y no es una afirmación sin fundamento: ese usuario probó Ollama y LM Studio ejecutando qwen2.5:1.5b cinco veces y calculó el promedio de tokens por segundo.
Ollama vs LM Studio: rendimiento y requisitos de hardware
En cuanto al rendimiento, la comparativa Ollama vs LM Studio depende más del hardware que de la interfaz. Ejecutar LLMs en local por primera vez es una experiencia muy distinta a los LLMs en la nube a los que estamos acostumbrados. Tener un LLM solo para ti se siente liberador, hasta que chocas con los límites del hardware.
Dado que los precios de RAM y VRAM se han disparado en los últimos años, equipar tu máquina con la potencia suficiente para ejecutar LLMs de gran tamaño es cada vez más difícil.
Los modelos populares suelen consumir entre 24 y 64 GB de RAM
Así es. Los requisitos de hardware no tienen que ver con quién gana en la comparativa Ollama vs LM Studio. Si quieres una experiencia fluida ejecutando modelos de tamaño mediano o grande sin ralentizaciones ni fallos, lo más recomendable es contar con entre 24 y 64 GB de RAM. Aun así, en la mayoría de los casos esa cantidad de RAM se queda corta con contextos largos y cargas de trabajo intensas.
Puedes ejecutar modelos más pequeños, conocidos habitualmente como modelos cuantizados, con entre 8 y 16 GB de RAM, pero no obtendrás el mismo rendimiento ni las mismas capacidades que con los modelos más grandes, y seguirá habiendo compromisos en calidad y velocidad. Por desgracia, RAM no es el único factor; el resto de componentes también deben estar a la altura.
Las GPUs potentes son una piedra angular para mantener a raya la frustración
Aunque los modelos pueden ejecutarse en CPUs, la unidad de procesamiento gráfico sigue siendo fundamental. Sin una GPU rápida y una cantidad generosa de VRAM, la generación de tokens irá token a token, las respuestas largas tendrán demoras considerables y la experiencia se vuelve insoportable rápidamente.
No te hagas ilusiones, porque ni siquiera el poderoso RTX 5070Ti ni el RTX 5080 son suficientes para deep learning en serio. Esto se debe a que, en algunos setups con contexto de 60 000+ tokens, el propio Ollama indica que se necesitan ~23 GB de VRAM, bastante más que los 16 GB de VRAM típicos que ofrecen esas GPUs.
Buscar algo por encima de ese rango de potencia también resulta astronómicamente caro. Si el precio no es un problema para ti, todavía hay algunas opciones de GPU que considerar al ejecutar LLMs locales.
A estas alturas, puede que te hayas perdido entre tanta información sobre cómo montar una máquina lo bastante potente para ejecutar modelos LLM locales de mayor tamaño. Este es el punto de inflexión para muchos, que empiezan a plantearse una solución diferente.
Una alternativa que muchos entusiastas consideran es usar máquinas virtuales con hardware potente ya preconfigurado. Usar un VPS (servidor privado virtual), por ejemplo, es una buena forma de conectar tu portátil u otro equipo personal a un servidor privado de tu elección, con todos los requisitos previos ya instalados.
Si un VPS te parece una buena solución, te recomendamos seriamente el VPS Ollamade Cloudzy, donde puedes trabajar en un entorno limpio. Incluye Ollama preinstalado, así que puedes ponerte a trabajar con LLMs locales desde el primer momento y con total privacidad. El precio es competitivo, con 12 ubicaciones, un uptime del 99,95 % y soporte 24/7. Los recursos no escasean: vCPUs dedicadas, memoria DDR5 y almacenamiento NVMe con un enlace de hasta 40 Gbps.
Ollama vs LM Studio: ¿Cuál necesitas?
Como se ha mencionado antes, ambas plataformas son muy capaces y ninguna es objetivamente mejor que la otra. La clave está en que cada una encaja con un tipo de flujo de trabajo distinto, así que depende de lo que necesites.
Elige Ollama para automatización y desarrollo
Cuando usas Ollama, el objetivo no es simplemente chatear con un modelo, sino integrarlo como componente dentro de otro proyecto. Ollama es ideal para:
- Desarrolladores crear productos como chatbots, copilotos y otras aplicaciones que requieren deep learning
- Flujos de trabajo con un alto grado de automatización, como scripts de resumen de informes o generación de borradores de forma programada
- Equipos que necesitan versiones de modelos consistentes en cualquier entorno
- Cualquier usuario que quiera una arquitectura centrada en la API, para que otras herramientas puedan conectarse a los modelos de forma habitual
En definitiva, si necesitas que los modelos sean fiables para tus aplicaciones, Ollama probablemente sea tu mejor opción.
LM Studio es la opción más accesible para empezar con LLMs locales
Si buscas explorar configuraciones de IA local sin complicaciones técnicas, LM Studio es claramente la mejor opción.
En general, LM Studio es más adecuado para:
- Principiantes que le tienen miedo a la terminal y a los comandos
- Escritores, creadores o estudiantes que necesitan una interfaz de chat sencilla con asistencia de IA
- Personas que prueban distintas opciones, y quieren comparar varios modelos rápidamente para encontrar el que mejor se adapta a sus necesidades
- Cualquiera que esté empezando a familiarizarse con los prompts y prefiere ajustar la configuración sin tener que escribir comandos
En resumen, si quieres descargar y empezar a usar algunos LLMs locales de inmediato, LM Studio es lo que necesitas.
Ollama vs LM Studio: Recomendación final
Si dejamos a un lado el debate entre Ollama y LM Studio, lo que realmente importa es tu experiencia diaria: tu flujo de trabajo y las limitaciones de tu hardware.
Ollama es, en general:
- Flexible y orientado a desarrolladores
Mientras que LM Studio es:
- Accesible para principiantes, con una interfaz gráfica dedicada
Ambos requieren hardware potente y costoso para funcionar bien. Mucha gente no tiene la posibilidad de ejecutar un LLM local de gran tamaño por su cuenta. Por eso, si quieres ejecutar modelos avanzados sin exigirle demasiado a tu hardware, considera probar Ollama en un VPS GPU dedicado. A continuación encontrarás algunas preguntas frecuentes sobre Ollama vs LM Studio.


