
Elegir una GPU VPS puede resultar abrumador cuando te enfrentas a fichas técnicas llenas de números. El recuento de núcleos va de 2.560 a 21.760, pero ¿qué significa eso en la práctica?
Un núcleo CUDA es una unidad de procesamiento paralelo dentro de las GPUs de NVIDIA que ejecuta miles de cálculos al mismo tiempo, y es la base de todo, desde el entrenamiento de modelos de AI hasta el renderizado 3D. Esta guía explica cómo funcionan, en qué se diferencian de los núcleos CPU y Tensor, y qué recuento de núcleos se ajusta a tus necesidades sin pagar de más.
¿Qué son los núcleos CUDA?

Los núcleos CUDA son unidades de procesamiento individuales dentro de las GPUs de NVIDIA que ejecutan instrucciones en paralelo. En esencia, ¿qué es la tecnología de núcleos CUDA? Piensa en estas unidades como pequeños trabajadores que resuelven distintas partes del mismo problema al mismo tiempo.
NVIDIA introdujo CUDA (Compute Unified Device Architecture) en 2006 para aprovechar la potencia de las GPUs en computación general, más allá de los gráficos. La documentación oficial de CUDA ofrece todos los detalles técnicos. Cada unidad realiza operaciones aritméticas básicas sobre números en coma flotante, lo que las hace ideales para cálculos repetitivos.
Las GPUs de NVIDIA actuales integran miles de estas unidades en un solo chip. Las GPUs de consumo de última generación superan los 21.000 núcleos, mientras que las GPUs para centros de datos basadas en la arquitectura Hopper cuentan con hasta 16.896. Estas unidades trabajan en conjunto a través de los Streaming Multiprocessors (SMs).
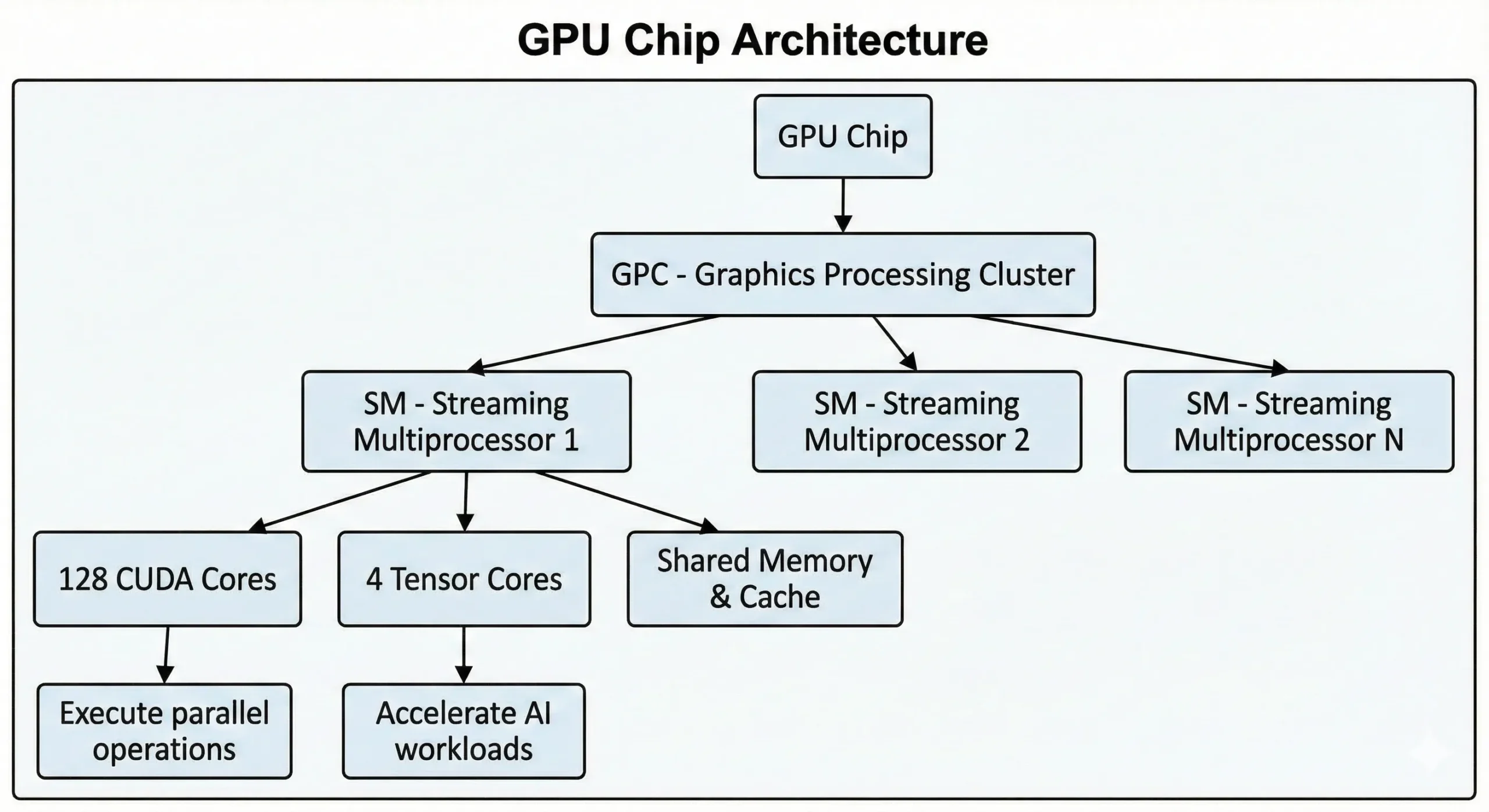
Las unidades ejecutan operaciones SIMT (Single Instruction, Multiple Threads) mediante métodos de computación paralela. Una sola instrucción se aplica sobre muchos datos a la vez. Al entrenar redes neuronales o renderizar escenas 3D, se producen miles de operaciones similares. Estas unidades dividen el trabajo en flujos concurrentes y los ejecutan al mismo tiempo, en lugar de uno tras otro.
Núcleos CUDA vs. núcleos CPU: ¿en qué se diferencian?

Las CPUs y las GPUs resuelven los problemas de maneras fundamentalmente distintas. Una CPU de servidor moderna puede tener entre 8 y 128 o más núcleos funcionando a alta frecuencia de reloj. Estos procesadores destacan en operaciones secuenciales, donde cada paso depende del resultado anterior. Gestionan con eficiencia la lógica compleja y las ramificaciones.
Las GPUs adoptan un enfoque diferente. Integran miles de núcleos CUDA más simples que funcionan a menor frecuencia de reloj. Estas unidades compensan esa menor velocidad mediante el paralelismo. Cuando 16.000 núcleos trabajan juntos, el rendimiento total supera al de una CPU convencional.
Las CPUs ejecutan el código del sistema operativo y la lógica compleja de las aplicaciones. Aunque las GPUs priorizan el rendimiento total, la sobrecarga derivada del inicio de tareas y la sincronización genera una latencia mayor. El procesamiento gráfico paralelo prioriza el movimiento de datos. Aunque tardan más en arrancar, procesan grandes volúmenes de datos más rápido que las CPUs.
| Característica | Núcleos CPU | Núcleos CUDA |
| Número por chip | 4-128+ núcleos | 2.560-21.760 núcleos |
| Velocidad de reloj | 3,0-5,5 GHz | 1,4-2,5 GHz |
| Estilo de procesamiento | Instrucciones secuenciales y complejas | Instrucciones paralelas y simples |
| Ideal para | Sistemas operativos, tareas monohilo | Álgebra matricial, procesamiento paralelo de datos |
| Latencia | Baja (microsegundos) | Mayor (sobrecarga de inicio) |
| Arquitectura | Uso general | Especializado en cálculos repetitivos |
Las tecnologías Virtual GPU (vGPU) y Multi-Instance GPU (MIG) gestionan la partición de recursos y la planificación para distribuir los procesadores entre varios usuarios. Esta configuración permite a los equipos maximizar el aprovechamiento del hardware mediante tiempo compartido o instancias de hardware dedicadas, según la configuración elegida.
El entrenamiento de redes neuronales implica miles de millones de multiplicaciones matriciales. Un GPU con 10.000 unidades no ejecuta simplemente 10.000 operaciones al mismo tiempo; en cambio, gestiona miles de hilos paralelos agrupados en «warps» para maximizar el rendimiento. Este paralelismo masivo es la razón por la que estas unidades son imprescindibles para los desarrolladores de IA.
CUDA Cores vs Tensor Cores: entendiendo la diferencia

Las GPU de NVIDIA incorporan dos tipos de unidades especializadas que trabajan en conjunto: CUDA cores estándar y Tensor cores. No son tecnologías competidoras, sino que cada una se encarga de una parte distinta de la carga de trabajo.
Las unidades estándar son procesadores paralelos de uso general que gestionan cálculos FP32 y FP64, operaciones con enteros y transformaciones de coordenadas. Esta tecnología CUDA base es el fundamento de la computación con GPU y se encarga de todo, desde simulaciones físicas hasta el preprocesamiento de datos, sin necesidad de aceleración especializada.
Los Tensor cores son unidades especializadas diseñadas exclusivamente para la multiplicación de matrices y tareas de IA. Introducidos en la arquitectura Volta de NVIDIA (2017), destacan en cálculos de precisión FP16 y TF32. La última generación también soporta FP8 para una inferencia de IA aún más rápida.
| Característica | Núcleos CUDA | Núcleos Tensor |
| Propósito | Computación paralela de uso general | Multiplicación matricial para IA |
| Precisión | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Velocidad para IA | 1x (línea base) | 2-10x más rápido que los CUDA cores |
| Casos de uso | Preprocesamiento de datos, ML tradicional | Entrenamiento e inferencia en deep learning |
| Disponibilidad | Todas las NVIDIA GPUs | RTX serie 20 y posteriores, GPUs de centro de datos |
Las GPUs modernas combinan ambos tipos. La RTX 5090 cuenta con 21.760 unidades estándar más 680 Tensor cores de quinta generación. La H100 combina 16.896 unidades estándar con 528 Tensor cores de cuarta generación para acelerar el deep learning.
Al entrenar redes neuronales, los Tensor cores se encargan del trabajo más pesado durante los pases hacia adelante y hacia atrás a través del modelo. Las unidades estándar gestionan la carga de datos, el preprocesamiento, el cálculo de pérdidas y las actualizaciones del optimizador. Ambos tipos trabajan en conjunto: los Tensor cores aceleran las operaciones con mayor carga computacional.
Para algoritmos de machine learning tradicionales como random forests o gradient boosting, las unidades estándar asumen todo el trabajo, ya que estos algoritmos no utilizan los patrones de multiplicación matricial que aceleran los Tensor cores. En cambio, para modelos transformer y redes neuronales convolucionales, los Tensor cores ofrecen mejoras de velocidad notables.
¿Para qué sirven los CUDA cores?

Los CUDA cores ejecutan tareas que requieren muchos cálculos idénticos en paralelo. Cualquier trabajo que implique operaciones matriciales o cálculos numéricos repetitivos se beneficia de su arquitectura.
Aplicaciones de IA y machine learning
El deep learning depende de multiplicaciones matriciales durante el entrenamiento y la inferencia. Al entrenar redes neuronales, cada pase hacia adelante requiere millones de operaciones de multiplicación-acumulación sobre matrices de pesos. La retropropagación añade millones más durante el pase hacia atrás.
Las unidades gestionan el preprocesamiento de datos, la conversión de imágenes a tensores, la normalización de valores y la aplicación de transformaciones de aumento. Esta capacidad para procesar miles de tareas a la vez es precisamente la razón por la que las GPUs son tan importantes para la IA.
Durante el entrenamiento, supervisan los calendarios de tasa de aprendizaje, el cálculo de gradientes y las actualizaciones del estado del optimizador.
Para VPS en operaciones de inferencia de IA que ejecutan sistemas de recomendación o chatbots, procesan solicitudes de forma concurrente y ejecutan cientos de predicciones al mismo tiempo. Nuestra guía sobre las mejores GPU para IA en 2025 explica qué configuraciones funcionan mejor según el tamaño del modelo.
Las 16.896 unidades de la H100 combinadas con los Tensor cores permiten entrenar un modelo de 7.000 millones de parámetros en semanas en lugar de meses. La inferencia en tiempo real para chatbots que atienden a miles de usuarios requiere una capacidad de ejecución concurrente similar.
Computación científica e investigación
Los investigadores utilizan estos procesadores para simulaciones de dinámica molecular, modelado climático y análisis genómico. Cada cálculo es independiente, lo que los hace ideales para la ejecución concurrente. Las instituciones financieras ejecutan simulaciones de Monte Carlo con millones de escenarios en paralelo.
Renderizado 3D y producción de vídeo
El trazado de rayos calcula cómo la luz rebota en escenas 3D siguiendo rayos independientes a través de cada píxel. Mientras los RT cores dedicados gestionan el recorrido, las unidades estándar se encargan del muestreo de texturas y la iluminación. Esta división determina la velocidad de renderizado en escenas con millones de rayos.
NVENC gestiona la codificación para H.264 y H.265, mientras que las arquitecturas más recientes (Ada Lovelace y Hopper) añaden soporte por hardware para AV1. CUDA se ocupa de efectos, filtros, escalado, reducción de ruido, transformaciones de color y la integración del pipeline. Esto permite que el motor de codificación trabaje en paralelo con los procesadores para una producción de vídeo más rápida.
El renderizado 3D en Blender o Maya distribuye miles de millones de cálculos de shaders de superficie entre las unidades disponibles. Los sistemas de partículas también se benefician, ya que simulan miles de partículas interactuando al mismo tiempo. Estas funciones son fundamentales en la creación digital de alto nivel.
Cómo los núcleos CUDA afectan al rendimiento de GPU

El número de núcleos da una idea aproximada de la capacidad de ejecución en paralelo, pero los núcleos CUDA requieren ir más allá de los números. La velocidad de reloj, el ancho de banda de memoria, la eficiencia de la arquitectura y la optimización del software son factores igual de determinantes.
Una GPU con 10.000 unidades a 2,0 GHz ofrece resultados distintos que una con 10.000 unidades a 1,5 GHz. A mayor velocidad de reloj, más cálculos completa cada unidad por segundo. Las arquitecturas más recientes hacen más trabajo por ciclo gracias a una mejor planificación de instrucciones.
Comprueba si el dispositivo está trabajando a pleno rendimiento, pero ten en cuenta que nvidia-smi la utilización es una métrica aproximada. Mide el porcentaje de tiempo en que un kernel está activo, no cuántos núcleos están ejecutando trabajo.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderEjemplo de salida: 85%, 92% (85% de tiempo activo, 92% de actividad del controlador de memoria)
Si tu GPU muestra un 60-70% de utilización, probablemente hay cuellos de botella en etapas anteriores, como la carga de datos de CPU o tamaños de lote pequeños. Sin embargo, incluso un 100% de utilización puede ser engañoso si tus kernels están limitados por memoria o son monohilo. Para obtener una imagen real de la saturación de los núcleos, usa herramientas de análisis como Nsight Systems y revisa las métricas "SM Efficiency" o "SM Active".
El ancho de banda de memoria suele convertirse en el cuello de botella antes de agotar la capacidad de cómputo. Si tu GPU procesa datos más rápido de lo que la memoria los suministra, las unidades quedan inactivas. El modelo H100 SXM5 dispone de 3,35 TB/s de ancho de banda para alimentar sus 16.896 núcleos. La versión PCIe, en cambio, reduce esto a 2 TB/s.
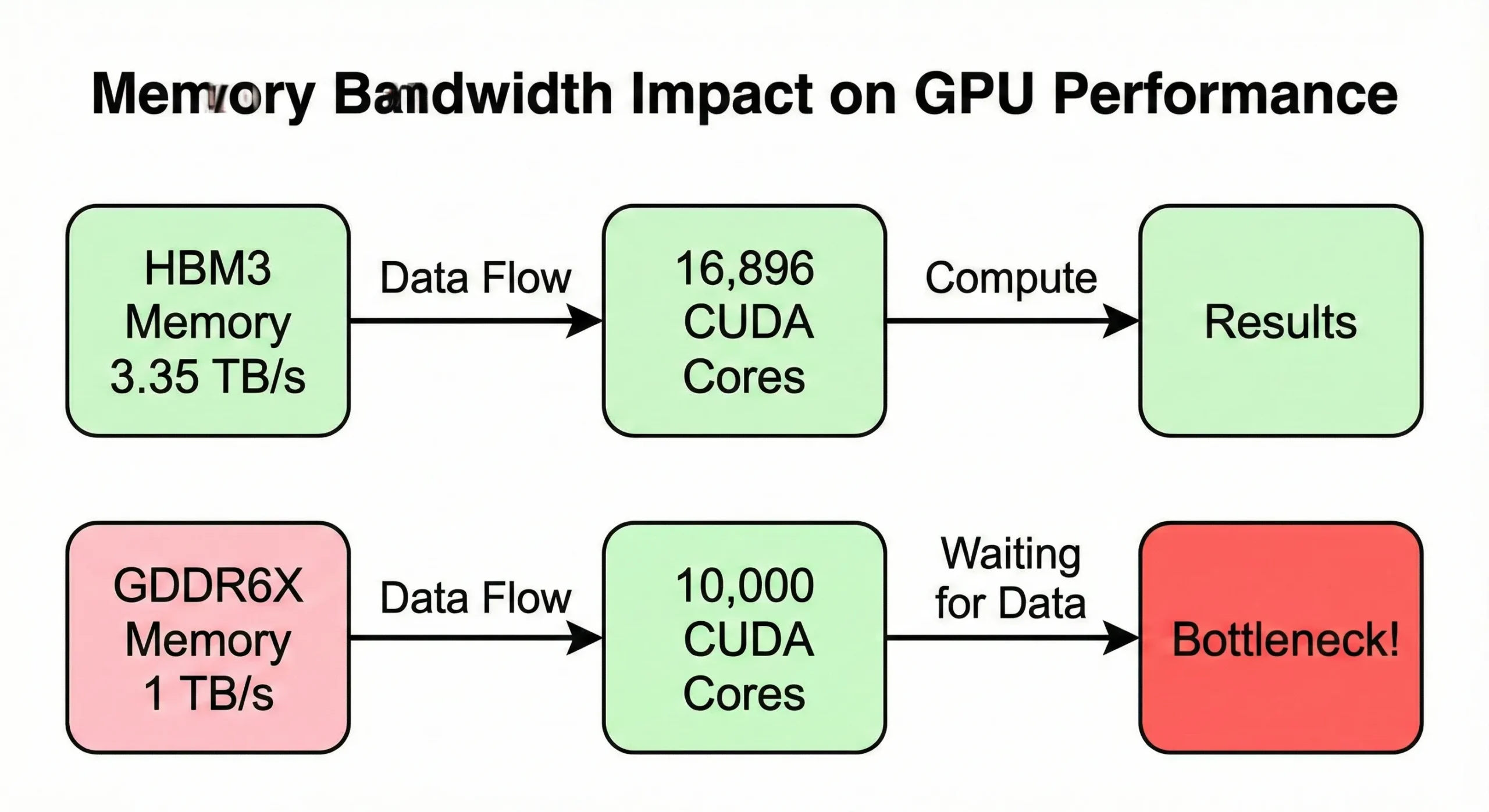
Las GPU de consumo con recuentos similares pero menor ancho de banda (alrededor de 1 TB/s) muestran velocidad reducida en operaciones intensivas en memoria.
La capacidad de VRAM determina el tamaño de las tareas que puedes ejecutar. Para los pesos FP16 de un modelo de 70B, el entrenamiento completo requiere más memoria. Debes tener en cuenta los gradientes y los estados del optimizador, que a menudo triplican el consumo de memoria a menos que uses estrategias de descarga.
La A100 de 80 GB está orientada a la inferencia de alto rendimiento y al ajuste fino. Por su parte, la RTX 4090 de 24 GB, habitualmente asociada a modelos de 7B, puede ejecutar sorprendentemente modelos de más de 30B parámetros si se aplican técnicas modernas de cuantización como INT4. Sin embargo, quedarse sin VRAM fuerza transferencias de datos entre CPU y GPU que destruyen el rendimiento.
La optimización del software determina si tu código realmente aprovecha todas esas unidades. Los kernels mal escritos pueden usar solo una fracción de los recursos disponibles. Bibliotecas como cuDNN para deep learning y RAPIDS para ciencia de datos están muy optimizadas para maximizar la utilización.
Más núcleos CUDA no siempre significan mejor rendimiento

Comprar una GPU con el mayor número de núcleos parece lógico, pero es dinero mal gastado si las unidades superan la capacidad de otros componentes del sistema o si tu tarea no escala con el número de núcleos.
El ancho de banda de memoria impone el primer límite. Las 21.760 unidades de la RTX 5090 son alimentadas por 1.792 GB/s de ancho de banda de memoria. Algunas GPU más antiguas con menos unidades pueden tener un ancho de banda proporcionalmente mayor por unidad.
Las diferencias de arquitectura importan. Una GPU más reciente con 14.000 unidades a 2,2 GHz supera a una más antigua con 16.000 unidades a 1,8 GHz gracias a un mejor rendimiento por ciclo de instrucción. Tu código necesita una paralelización adecuada para aprovechar eficazmente 20.000 unidades.
Por qué los núcleos CUDA importan al elegir GPU VPS

Elegir la configuración de núcleos CUDA GPU adecuada para tu VPS evita gastar dinero en recursos que no usas o encontrarte con cuellos de botella a mitad del proyecto.
Los 80 GB de memoria del H100 permiten ejecutar inferencia para modelos de 70B parámetros con cuantización de 4 bits. Sin embargo, para entrenamiento completo, 80 GB suelen ser insuficientes incluso para un modelo de 34B cuando se tienen en cuenta los gradientes y los estados del optimizador. En entrenamiento FP16, la huella de memoria crece considerablemente y a menudo requiere fragmentación entre varios GPUs.
Las operaciones de inferencia para predicciones en tiempo real necesitan menos unidades, pero se benefician de una latencia baja. El desarrollo y la creación de prototipos funcionan bien con GPUs de gama media para probar algoritmos y depurar código.
Una RTX 4060 Ti con 4.352 unidades te permite hacer pruebas sin pagar por hardware sobredimensionado. Una vez validado tu enfoque, sube a GPUs de producción para las ejecuciones de entrenamiento completas.
El renderizado y el trabajo con vídeo escala con las unidades hasta cierto punto. El renderizador Cycles de Blender aprovecha todos los recursos disponibles de forma eficiente. Un GPU con 8.000-10.000 unidades renderiza escenas entre 2 y 3 veces más rápido que uno con 4.000.
En Cloudzy ofrecemos VPS con GPU hosting de alto rendimiento pensado para cargas de trabajo exigentes. Elige el RTX 5090 o el RTX 4090 para renderizado rápido e inferencia de IA eficiente en coste, o escala hasta A100s para workloads de deep learning a gran escala. Todos los planes funcionan sobre una red de 40 Gbps con políticas que priorizan la privacidad y opciones de pago con criptomonedas, dándote potencia real sin la burocracia corporativa.
Ya sea entrenando modelos de IA, renderizando escenas 3D o ejecutando simulaciones científicas, tú eliges el número de núcleos que se ajusta a tus necesidades.
El presupuesto importa. Un A100 con 6.912 unidades cuesta considerablemente menos que un H100 con 16.896. Para muchas operaciones, dos A100s ofrecen una mejor relación precio-rendimiento que un solo H100. El punto de equilibrio depende de si tu código escala bien entre varios GPUs.
Cómo elegir el número de núcleos CUDA adecuado
Ajusta tus requisitos a las características reales de tu carga de trabajo, sin dejarte llevar por las cifras más altas del mercado.
Empieza analizando tu trabajo actual. Si estás entrenando modelos en hardware local o en instancias en la nube, revisa las métricas de utilización del GPU. Si tu GPU actual muestra un 60-70% de utilización de forma constante, no estás llegando al límite de las unidades.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Este benchmark sencillo indica si los núcleos de tu GPU están ofreciendo el rendimiento esperado. Compara tus resultados con los benchmarks publicados para tu modelo de GPU.
Actualizar el hardware no servirá de nada. Primero debes resolver los cuellos de botella: memoria, ancho de banda o bloqueos de CPU. Después, estima los requisitos de memoria calculando el tamaño del modelo en bytes más la memoria de activaciones.
Añade el tamaño del batch multiplicado por las salidas de cada capa e incluye los estados del optimizador. Este total debe caber en VRAM. Una vez que conoces la memoria necesaria, comprueba qué GPUs cumplen ese umbral.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Ten en cuenta tus plazos. Si necesitas resultados en horas, paga por más unidades. Las ejecuciones de entrenamiento que pueden durar días funcionan bien en GPUs más pequeños con tiempos de finalización proporcionalmente más largos.
El coste por hora multiplicado por las horas necesarias da el coste total, lo que a veces hace que los GPUs más lentos sean más baratos en general. Comprueba la eficiencia de escalado usando los frameworks que incluyen herramientas de benchmarking para medir cambios en el rendimiento.
Si duplicar las unidades solo da 1,5x de aceleración, el coste adicional no se justifica. Busca el punto óptimo donde la relación precio-rendimiento es máxima.
| Tipo de carga de trabajo | Núcleos recomendados | Ejemplos de GPU | Notas |
| Desarrollo y depuración de modelos | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Iteración rápida, costes más bajos |
| Entrenamiento de IA a pequeña escala (menos de 7B parámetros) | 6,000-10,000 | RTX 4090, L40S | Ideal para usuarios particulares y pequeñas empresas |
| Entrenamiento de IA a gran escala (7B-70B parámetros) | 14,000+ | A100, H100 | Requiere GPUs de centro de datos |
| Inferencia en tiempo real (alto rendimiento) | 10,000-16,000 | RTX 5080, L40 | Equilibrio entre coste y rendimiento |
| Renderizado 3D y codificación de vídeo | 8,000-12,000 | RTX 4080, RTX 4090 | Se adapta a la complejidad del proyecto |
| Computación científica y HPC | 10,000+ | A100, H100 | Requiere soporte FP64 |
GPUs VPS más populares y sus conteos de núcleos CUDA

Cada nivel de GPU está orientado a un tipo de usuario distinto. ¿Qué es GPUaaS? Es GPU como servicio: proveedores como Cloudzy te dan acceso bajo demanda a estas potentes GPUs de NVIDIA, sin necesidad de comprar ni gestionar el hardware físico.
| Modelo de GPU | Núcleos CUDA | VRAM | Ancho de banda de memoria | Arquitectura | Ideal para |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Estación de trabajo de gama alta, renderizado en 8K |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1.008 GB/s | Ada Lovelace | IA de alto rendimiento, renderizado 4K |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Entrenamiento de IA a gran escala |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | IA empresarial, centros de datos rentables |
| A100 | 6,912 | 40/80GB HBM2e | 1.555-2.039 GB/s | Ampere | IA de gama media, fiabilidad contrastada |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming e IA de nivel medio |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Centros de datos para cargas de trabajo múltiples |
Las tarjetas RTX de consumo (4070, 4080, 4090, 5080, 5090) están orientadas a creadores y gaming, pero funcionan bien para el desarrollo de IA. Ofrecen una velocidad GPU elevada a precios inferiores a las tarjetas de centro de datos.
Los proveedores de VPS suelen disponer de estas tarjetas para usuarios con presupuesto ajustado. Las tarjetas de centro de datos (A100, H100, L40) priorizan la fiabilidad, la memoria ECC y el escalado multi-GPU. Están diseñadas para operaciones 24/7 y admiten funciones avanzadas.
Multi-Instance GPU (MIG) permite dividir una GPU en varias instancias aisladas. La A100 sigue siendo muy popular pese a opciones más recientes, gracias a sus especificaciones equilibradas.
Su equilibrio entre núcleos NVIDIA, memoria y precio la convierte en la opción segura para la mayoría de las operaciones de IA en producción. La H100 ofrece 2,4 veces más unidades, pero tiene un coste significativamente mayor.
Conclusión
Los motores de procesamiento paralelo hacen posible la IA moderna, el renderizado y la computación científica. Entender cómo funcionan e interactúan con la memoria, las frecuencias de reloj y el software te ayuda a elegir las configuraciones de GPU VPS adecuadas.
Más unidades ayudan cuando tu trabajo se paraleliza bien y componentes como el ancho de banda de memoria acompañan. Sin embargo, perseguir ciegamente el mayor número de núcleos es dinero malgastado si tus cuellos de botella están en otro lado.
Empieza analizando tus operaciones reales, identificando dónde se consume el tiempo y ajustando las especificaciones de GPU a esas necesidades sin adquirir capacidad innecesaria.
Para la mayoría del trabajo de desarrollo de IA, entre 6.000 y 10.000 unidades ofrecen el mejor equilibrio entre coste y rendimiento. Las operaciones en producción que entrenan modelos grandes o sirven inferencia de alto rendimiento se benefician de GPUs con más de 14.000 unidades, como la H100.
El renderizado y el trabajo con vídeo escalan de forma eficiente hasta alrededor de 16.000 unidades, a partir de las cuales el ancho de banda de memoria se convierte en el factor limitante.


