
인기 있는 모델의 Hugging Face GGUF 페이지를 열면 열다섯 개의 파일이 당신을 마주 본다: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, 그리고 GPTQ, AWQ, EXL2를 위한 여섯 가지 비트 설정별 별도 폴더까지. "4비트" 파일에 대해 간단히 계산해본다: 4비트 × 80억 파라미터 ÷ 8 = 4GB. 하지만 파일은 4.6GB라고 한다. 그리고 일단 로드하면, 모델은 그보다 더 많은 메모리를 사용한다.
파일 이름은 소음이 아니다. 비트 폭, 그것을 로드하는 런타임, 그리고 필요한 하드웨어에 관한 실제로 학습 가능한 정보를 인코딩한다. 당신이 읽어본 사이징 표는 70B 모델이 대략 40GB가 필요하다고 알려준다. 유용하지만, 포맷 자체를 해독하거나 실행 중인 모델이 디스크의 파일보다 더 많은 메모리를 원하는 이유를 설명하지는 않는다.
그래서 계획은 이렇다: GGUF 명명 규칙을 (명목상이 아니라 진짜 비트 폭으로) 해독하고, 네 가지 포맷 중 당신의 하드웨어가 실제로 실행할 수 있는 것이 무엇인지 가려내고, 모든 파일 크기에서 보이지 않는 단 하나의 메모리 비용인 KV 캐시를 계산에 넣는 것이다. 끝까지 읽으면 모델 저장소를 보고 로드될 때 어떻게 동작할지 예측할 수 있게 될 것이다.
요약
- GGUF 양자화 수준은 이름에 있는 정확한 숫자가 아니라 유효 비트 폭이다. Q4_K_M은 가중치당 약 4.89비트이며, 이것이 "4비트" 8B 파일이 순진한 4비트 추정치가 아니라 약 4.6GiB 정도가 되는 이유다.
- GGUF는 가장 이식성이 뛰어난 옵션이다. llama.cpp가 CPU, GPU, 또는 하이브리드 구성에서 실행할 수 있기 때문이다. GPTQ, AWQ, EXL2는 GPU와 런타임에 더 특화되어 있으며, 특히 EXL2는 NVIDIA/CUDA 워크플로에 묶여 있다.
- KV 캐시는 모델 가중치와 별개이며, 컨텍스트 길이에 따라 커진다. 이것이 깔끔하게 로드된 모델이 대화가 길어지면 여전히 메모리 부족으로 충돌할 수 있는 이유다.
- 5비트 범위 이상에서는 품질 손실이 보통 작다. Q4 정도에서는 여전히 많은 로컬 사용 사례에 실용적인 트레이드오프다. 4비트 아래로 내려가면 품질 비용이 훨씬 더 두드러진다. Q4_K_M은 여전히 흔한 커뮤니티 기본값이며, 여유 메모리가 있을 때는 Q5_K_M과 Q6_K가 더 안전하다.
GGUF 파일 이름에서 Q4_K_M은 무슨 뜻일까?

GGUF 양자화 이름은 Q[비트]_[K]_[S/M/L] 패턴을 따른다. 숫자는 목표 가중치당 비트 수이며, K는 가중치의 작은 블록마다 스케일링 인자를 저장하는 "K-quant"임을 의미하고, 끝에 붙는 S, M, L은 크기/품질 등급(소, 중, 대)이다. K-quant는 각 블록마다 가중치와 함께 스케일과 최소값을 저장하기 때문에, 실제 비트 폭은 헤드라인 숫자보다 높다. Q4_K_M은 가중치당 약 4.89비트에 이르며, 4가 아니다.
그 격차가 "왜 내 4비트 파일이 4.6GB지?"라는 질문에 대한 답 전체다. 순진한 추정치는 모든 가중치가 정확히 4비트를 소모한다고 가정한다. 실제로는 K-quant가 저비트 양자화를 정확하게 만드는 메타데이터, 즉 런타임이 각 가중치를 재구성할 수 있게 해주는 블록별 스케일과 최소값에 블록당 추가 비트를 쓴다. 4.89비트를 80억 가중치에 곱하면 약 4.58GiB에 이르는데, 이것이 파일이 실제로 차지하는 무게다.
다음은 측정된 유효 비트 폭과 파일 크기이며, 다음에서 가져왔다: llama.cpp quantize documentation 참조 모델로서 Llama 3.1 8B를 위한 것이며, llama.cpp 양자화 평가 논문에서 측정된 각 수준의 퍼플렉시티 비용과 함께 (arXiv:2601.14277) Llama-3.1-8B-Instruct에서:
| GGUF 수준 | 실제 BPW | ~파일 크기 (8B) | F16 대비 퍼플렉시티* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3.4 GiB | +22% |
| Q3_K_M | 3.95 | ~3.7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4.0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4.4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4.6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5.3 GiB | +1.1% |
| Q6_K | 6.56 | ~6.1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8.0 GiB | +0.1% |
| F16 | 16.00 | ~15.0 GiB | 기준 |
*퍼플렉시티 수치는 arXiv:2601.14277의 Llama-3.1-8B-Instruct에 특화된 것이다. BPW/파일 크기 열과 퍼플렉시티 열은 별도로 측정된 두 개의 다른 출처에서 나온 것이므로, 이 표를 단일 벤치마크 실행이 아니라 실용적인 나란히 놓은 참고 자료로 읽어라. 작업별 저하는 다양하며, 수학 추론은 낮은 비트 폭에서 상식 추론보다 더 크게 손상되는 경향이 있지만, 전반적인 형태는 유지된다: 5비트 이상이 보통 더 안전하고, Q4는 실용적인 압축 구간이며, 3비트는 품질 손실을 무시하기 훨씬 더 어려워지는 지점이다.
실무적으로는: Q4_K_M이 대부분의 사람이 선택해야 할 기본값이고, Q5_K_M과 Q6_K는 여유 메모리가 있을 때 품질을 우선하는 선택이며, Q3_K_S 이하는 정말로 더 담을 수 없는 하드웨어를 위한 최후의 수단이다.
어떤 양자화 포맷을 다운로드해야 할까: GGUF, GPTQ, AWQ, 아니면 EXL2?

GGUF는 네 가지 중 가장 이식성이 뛰어나다. llama.cpp를 통해 CPU, GPU, 또는 둘의 하이브리드에서 실행되므로, 하드웨어가 무엇을 지원하는지 확실하지 않을 때 가장 안전한 선택이다. GPTQ, AWQ, EXL2는 GPU와 런타임에 더 특화되어 있다. 실무에서는 NVIDIA/CUDA 구성에서 가장 흔하지만, GPTQ와 AWQ 지원은 로더와 서빙 스택에 따라 다를 수 있다. 예를 들어 vLLM은 양자화 지원을 하드웨어와 구현에 따라 나눈다. Mac, AMD 카드, 또는 CPU 전용 기계에서 로컬로 실행 중이라면, GGUF는 여전히 가장 안전한 답이다. NVIDIA GPU가 있고 가능한 한 가장 빠른 토큰을 원한다면, 나머지 세 가지가 등장한다.
| 포맷 | 하드웨어/런타임 | 속도(상대적) | 동급 대비 VRAM | 적합한 용도 |
|---|---|---|---|---|
| GGUF Q4_K_M | 가장 광범위함, llama.cpp를 통해 CPU, GPU, 또는 하이브리드 | 중간 | 가장 낮음 | 모든 하드웨어; 로컬 기본값 |
| GPTQ 4-bit | 보통 CUDA/GPU 우선; 런타임에 따라 다름 | 빠름 (ExLlama) | 중간 | GPU 우선, 레거시 툴링 |
| AWQ 4-bit | 보통 CUDA/GPU 우선; 런타임에 따라 다름 | 빠름 | 최고 | vLLM/TGI 서빙, 빠른 로드 |
| EXL2 ~4.9 bpw | NVIDIA/CUDA 우선 | 가장 빠른 | 낮음-중간 | NVIDIA에서 최대 속도 |
그 표에 대한 유의점 하나: 속도와 VRAM 순위는 다음에서 나온 것이다: oobabooga 벤치마크, 이는 2023/2024년대 하드웨어에서 실행된 것이다. 순위를 상대적 순위는 오래 지속되는 것으로 다뤄라. EXL2는 속도를 위해 만들어졌고, AWQ는 빠른 로딩을 위해 VRAM을 희생하며, GGUF는 가볍고 이식성 있게 유지된다. 하지만 원래의 절대적인 초당 토큰 수치를 현재 것으로 읽지는 마라. 2026년형 GPU는 매우 다른 원시 처리량을 보여줄 것이다. 계속 유지되는 것은 순위 서열이다.
그래서 여기서 나오는 결정 규칙은 이렇다: NVIDIA 카드가 있고 속도를 가장 중요하게 여긴다면 EXL2; 다양한 하드웨어에서 가장 안전한 로컬 기본값을 원한다면 GGUF. AWQ와 GPTQ는 특정 서빙 스택(vLLM, TGI)이나 기존 도구가 그쪽으로 이끌 때 주로 중요해진다.
왜 로컬 LLM은 파일보다 더 많은 메모리를 사용할까?
파일 크기는 오직 모델 가중치일 뿐이다. 런타임에는 KV 캐시(컨텍스트 윈도우의 모든 토큰에 대한 어텐션 상태), 활성화값(순전파의 중간 연산), 프레임워크 및 드라이버 오버헤드에 대한 비용도 지불한다. 가중치가 아닌 부분들은 합쳐서 단일 사용자 구성에서 가중치 위에 통상 10~20%를 추가하며, 컨텍스트가 길어지면 KV 캐시 하나만으로도 나머지 모든 것을 압도할 수 있다. 4.6GB 파일이 실행되기 위해 4.6GB보다 훨씬 많은 메모리를 필요로 할 수 있다.
런타임 메모리를 서로 위에 쌓인 네 가지 구성 요소로 생각하라:
- 모델 가중치. 당신이 다운로드한 파일이다. 로드하기 전에 보이는 유일한 부분이다.
- KV 캐시. 컨텍스트 윈도우에 대한 어텐션 상태. 짧은 컨텍스트에서는 작고, 긴 컨텍스트에서는 엄청나게 커진다. 이것이 다음 섹션이다. 사람들을 놀라게 하는 것이 바로 이것이기 때문이다.
- 활성화값. 순전파의 작업 메모리. 단일 스트림 로컬 추론(배치 크기 1)의 경우, 이는 작다. 보통 수백 메가바이트 정도다.
- 프레임워크 오버헤드. 런타임 자체의 사용량에 GPU 드라이버 컨텍스트를 더한 것. 가벼운 로컬 런타임의 경우, 이는 모델 가중치와 KV 캐시에 비해 작을 수 있다. 더 무거운 서빙 프레임워크는 훨씬 더 많이 예약할 수 있다. 운영체제 자체의 메모리 예약은 이것과 별개이며 또 다시 분리되어 있다.
가중치와 프레임워크 오버헤드는 예측 가능하다. KV 캐시는 "들어맞는" 모델을 "충돌하는" 모델로 바꾸는 변수이므로, 실제 계산을 짚어볼 가치가 있다.
KV 캐시는 메모리를 얼마나 사용할까?
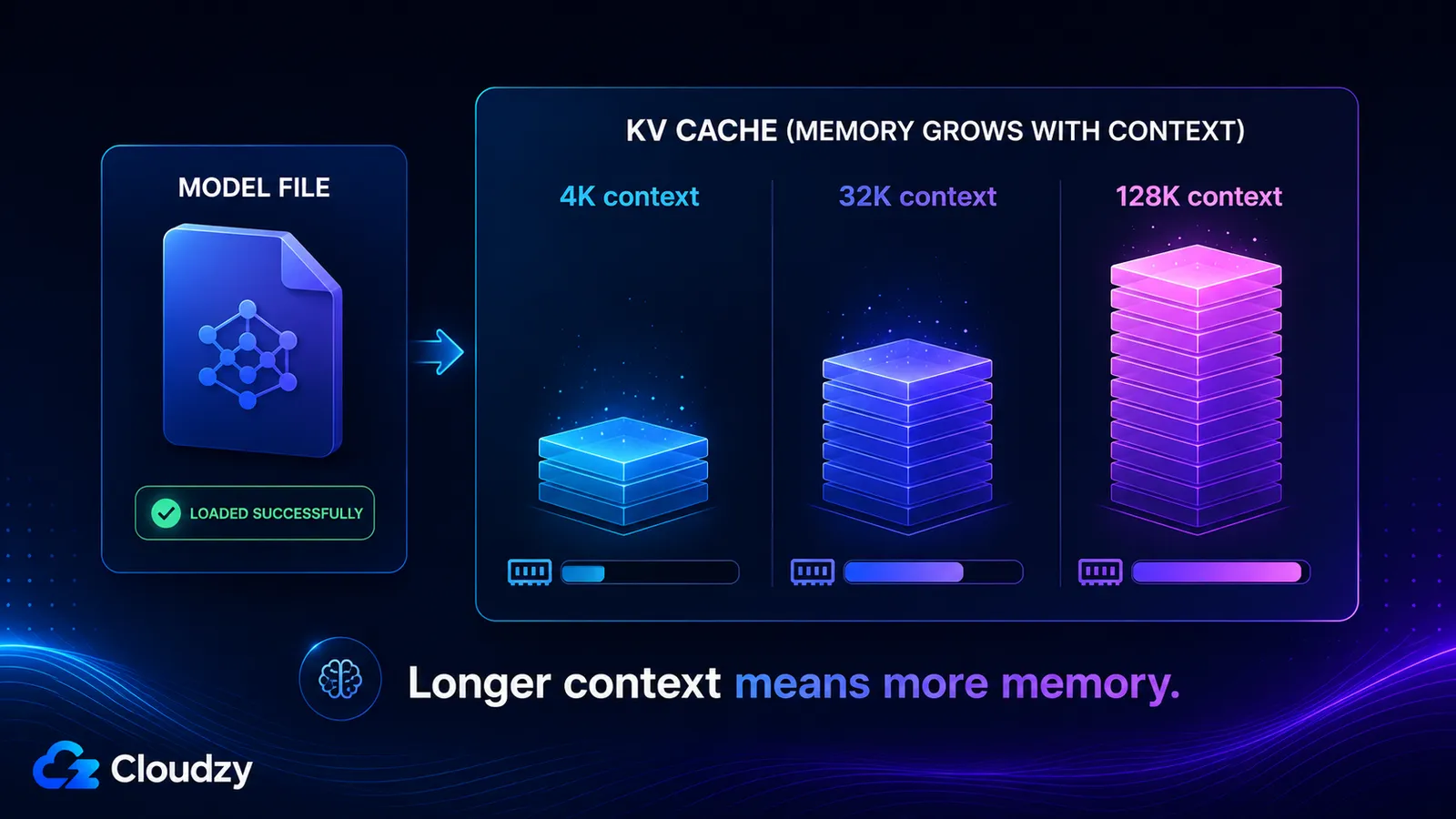
KV 캐시는 컨텍스트 윈도우의 모든 토큰에 대한 키와 값 벡터를 저장하므로, 컨텍스트 길이에 대략 선형적으로 커지며 모델 가중치와는 완전히 별개다. 그 크기는 모델의 레이어 수, KV 헤드 수, 헤드 차원, 컨텍스트 길이, 캐시의 정밀도로 결정된다. 긴 컨텍스트를 켜면, 문제없이 로드된 모델이 전혀 경고하지 않은 수십 기가바이트를 추가할 수 있다.
공식은 머릿속에 담아둘 수 있을 만큼 짧다:
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
맨 앞의 2는 토큰당 저장되는 두 개의 텐서를 위한 것이다. 하나는 키, 하나는 값이다. bytes_per_element는 FP16 캐시의 경우 2다. 나머지는 모델 카드에서 읽을 수 있는 아키텍처 상수다.
레이어가 32개, KV 헤드가 8개, 헤드 차원이 128인 Llama 3.1 8B에 대해 계산해보자. 4,096 토큰 컨텍스트, 배치 크기 1, FP16 캐시에서:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
컨텍스트를 늘리면 그 숫자도 함께 늘어난다. context_tokens를 제외한 모든 항이 고정되어 있기 때문이다:
- 4K 컨텍스트: ~536 MB
- 32K 컨텍스트: ~4.3 GB
- 128K 컨텍스트: ~17 GB
이 마지막 두 수치가 바로 모델이 128K 컨텍스트 윈도우를 표방하고 문제없이 로드된 다음, 실제로 그 윈도우를 사용하는 순간 메모리를 소진해버리는 이유다. 전체 컨텍스트에서의 KV 캐시는 양자화된 가중치 자체보다 더 크다.
바로 이 부분이 현대의 롱컨텍스트 모델을 애초에 가능하게 만드는 것이다: Llama 3.1 8B는 Grouped Query Attention (GQA). 쿼리 헤드는 32개지만 KV 헤드는 8개뿐이며, 캐시는 32개가 아니라 8개 헤드에 대한 키/값 벡터를 저장한다. 동일한 공식을 32개 KV 헤드로(KV 헤드가 쿼리 헤드와 같은 예전 Multi-Head Attention 설계로) 실행하면 위의 모든 수치가 4배가 된다. 128K에서의 그 17GB는 68GB가 된다. GQA는 컨텍스트 윈도우가 커져도 계산이 감당할 만하게 유지되는 아키텍처적 이유다.
파일 크기는 당신의 메모리 예산이 아니다. 가중치나 KV 캐시가 더 이상 빠른 메모리 경로에 들어가지 않고 런타임이 PCIe를 통해 시스템 RAM으로 폴백해야 할 때, 처리량은 부드럽게 저하되지 않는다. 매 토큰마다 PCIe로 데이터를 옮기게 되는 순간 절벽처럼 뚝 떨어진다. 가중치뿐 아니라 실제 사용하는 컨텍스트 길이에서의 가중치와 KV 캐시가 둘 다 들어맞도록 메모리를 예산하라.
GPU나 Mac을 위한 양자화는 어떻게 골라야 할까?
하드웨어와 런타임에서 출발하라. NVIDIA GPU 소유자는 가장 넓은 메뉴를 가지고 있으며, 순수 속도를 위한 EXL2 또는 이식성을 위한 GGUF를 저울질해야 한다. AMD, Apple Silicon, CPU 전용 하드웨어, 또는 혼합 구성이라면 llama.cpp를 통한 GGUF가 보통 가장 안전한 출발점이다. 거기서부터, 모델의 최대치가 아니라 실제로 사용하는 컨텍스트 길이에서 KV 캐시를 예산으로 잡은 후 들어맞는 가장 높은 양자화 수준을 골라라.
알아둘 만한 Apple Silicon의 함정 하나: GPU가 통합 메모리 전부를 갖지는 못한다 (그 공유 풀이 어떻게 작동하는지 전체 그림을 보려면 다음에 대한 우리의 관련 글을 참고하라: 통합 메모리가 실제로 무엇인지 그 공유 풀이 어떻게 작동하는지에 대한 전체 그림을 위해). 셀프 호스팅 커뮤니티는 약 75% 정도의 상한선을 문서화했다 GPU가 사용할 수 있는 전체 통합 메모리 중에서 말이다 (이는 Apple의 공식 확인을 받은 것이 아니며 macOS 업데이트로 바뀔 수 있다). 그래서 "64GB Mac"은 현실적으로 모델과 그 KV 캐시를 위해 ~48GB 정도이며, 더 작은 숫자를 기준으로 계획을 세워라.
이 기사는 포맷을 읽고 런타임 동작을 예측하는 것에 관한 것이다: 양자화 이름을 해독하고, 하드웨어가 지원하는 포맷을 고르고, KV 캐시를 가중치와 별도로 예산하라. 특정 모델을 특정 메모리 양에 맞추는 것, 즉 크기-메모리 조회표는 관련되어 있지만 별개의 질문으로, 향후 관련 글에서 다룰 예정이다.
저장소 읽기
이제 당신은 모델 페이지를 보고 추측하는 대신 읽을 수 있다. 양자화 이름을 그 유효 비트 폭으로 해독하고, GGUF가 가장 광범위한 로컬 포맷인 반면 GPTQ, AWQ, EXL2는 더 런타임에 특화되어 있다는 것을 인식하고, 파일 크기는 단지 바닥일 뿐이며 KV 캐시가 그 위에 쌓이고 컨텍스트와 함께 커진다는 것을 기억하라. 원하는 모델의 파일을 열고, 하드웨어가 실행할 수 있는 포맷을 고르고, 실제 컨텍스트 길이에서 KV 캐시를 위한 여유를 남긴 후 들어맞는 가장 높은 양자화 수준을 선택하면, 이 모든 질문을 시작하게 만든 메모리 부족 충돌을 피할 수 있을 것이다.
자주 묻는 질문
Q4_K_M은 무슨 뜻일까?
Q4_K_M은 GGUF 양자화 수준이다: 가중치당 약 4비트(Q4), 블록별 K-quant 스케일링을 사용하며(K), 중간 크기/품질 등급(M)이다. 그것의 실제 비트 폭은 가중치당 약 4.89비트이며 정확히 4가 아니다. K-quant가 각 가중치 블록마다 스케일과 최소값을 저장하기 때문이다. 이것이 "4비트" 8B 모델 파일이 3.5GB가 아니라 약 4.6GB인 이유다.
양자화가 LLM 품질을 떨어뜨릴까?
그렇다, 하지만 비용은 얼마나 밀어붙이느냐에 크게 좌우된다. arXiv:2601.14277에서 측정된 Llama-3.1-8B-Instruct에서, 퍼플렉시티는 Q6_K에서 약 0.4%만 상승하고 Q5 대역 전체에서 약 1% 정도를 유지한다. Q4로 내려가면 증가는 여전히 미미하다(몇 퍼센트 정도). Q3_K_M 아래로 내려가면 가파르게 상승하여 Q3_K_S에서 +22%에 이른다. 대부분의 용도에서 Q4_K_M 이상은 사실상 무손실이다. 가파른 손실은 3비트 이하에서 나타난다.
GGUF, GPTQ, AWQ, EXL2의 차이점은 무엇일까?
GGUF(llama.cpp가 실행함)는 이식 가능한 포맷으로, 광범위한 하드웨어에서 CPU, GPU, 또는 하이브리드 구성에서 작동한다. GPTQ, AWQ, EXL2는 GPU와 런타임에 더 특화되어 있다. 4비트에서는 넷 다 좁은 품질 대역에 들어올 수 있으므로, 실질적인 차이는 하드웨어, 로더 지원, 속도, VRAM 사용량이다: EXL2는 속도에 초점을 맞춘 NVIDIA/CUDA 선택이고, AWQ는 서빙 스택에서 흔하며, GPTQ는 오래된 GPU 툴링과 모델 저장소에 맞고, GGUF는 가장 이식성 있는 로컬 옵션으로 남는다.
왜 내 로컬 LLM은 파일보다 더 많은 메모리를 사용할까?
파일 크기는 단지 모델 가중치일 뿐이다. 런타임에는 KV 캐시(컨텍스트 윈도우의 모든 토큰에 대한 어텐션 상태), 활성화값, 프레임워크와 드라이버 오버헤드에 대한 비용도 지불한다. 격차가 클 때 보통 범인은 KV 캐시다. 컨텍스트 길이에 따라 커지고 가중치와 별도로 할당되기 때문이다. 파일이 몇 기가바이트에 불과한 모델도 긴 컨텍스트를 설정하면 훨씬 더 많은 메모리가 필요할 수 있다.
컨텍스트 길이는 메모리 사용량에 어떤 영향을 미칠까?
KV 캐시는 컨텍스트 길이에 대략 선형적으로 커지므로, 컨텍스트를 두 배로 늘리면 캐시도 대략 두 배가 된다. Llama 3.1 8B의 경우, 캐시는 4K 토큰에서 약 536MB, 32K에서 ~4.3GB, 128K에서 ~17GB다(FP16, 단일 스트림). 이 증가는 모델 가중치와 완전히 별개이며, 이것이 긴 컨텍스트 윈도우를 표방하는 것이 문제없이 로드되었더라도 모델을 메모리 부족으로 몰아넣을 수 있는 이유다.


