
테스트에서 루프는 40번 깔끔하게 실행되었습니다. 41번째 실행에서, 프로덕션 환경에서는, 동일한 깨진 쿼리로 동일한 SQL 도구를 계속해서 호출하다가 하루치 API 예산을 다 소진했고, 결국 청구 알림이 울리고 나서야 누군가 잠에서 깨어났습니다. 아무도 잘못된 모델을 만들지 않았습니다. 아무도 프롬프트를 변경하지 않았습니다. 에이전트가 단순히 언제 끝내야 할지를 결정하지 못한 것입니다.
이것이 제가 에이전트를 프로토타입에서 24/7 워크로드로 전환하는 팀들에서 계속 보게 되는 패턴입니다. AI 에이전트 루프는 프로덕션에서 모델이 갑자기 나빠졌기 때문이 아니라, 실행 계층에 종료 규율, 검증된 도구 계약, 제한된 컨텍스트, 그리고 지속적인 상태가 부족하기 때문에 실패합니다. 에이전트 루프는 순차적 결정을 하나씩 내리는 확률적 시스템입니다. 몇 가지 특정 가드레일 없이는, 드물게 발생하는 실패가 오래 실행할수록 필연적인 실패가 됩니다. 관리형 에이전트 플랫폼(Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry)은 이러한 가드레일 중 일부를 내장하고 있습니다. 이 가이드는 직접 호스팅을 선택하고 루프를 직접 소유하기로 한 분들을 위한 것입니다.
위험 부담은 Gartner가 예상할 만큼 충분히 현실적입니다. 에이전트형 AI 프로젝트의 40% 이상이 2027년 말까지 취소될 것, 비용 증가와 불분명한 가치를 이유로 들고 있습니다. 다음은 루프가 프로덕션에서 실패하는 여섯 가지 구체적인 방식, 각각의 메커니즘, 그리고 이를 수정하는 하네스 패턴을 설명합니다. LangGraph와 n8n 세부 사항 및 실제로 24/7로 운영하는 데 필요한 사항도 포함됩니다.
요약
- 무한 루프: 에이전트가 언제 끝내야 할지 결정하지 못합니다. LangGraph의 단계별 상한선(기본값 25)과 반복된 도구+인수 호출을 탐지해 종료하는 진행 없음 감지를 함께 사용하세요.
recursion_limit, 기본값 25)와 진행 없음 감지를 함께 사용하여 반복되는 도구+인수 호출을 종료하세요. - 컨텍스트 오버플로우: 루프가 누적된 히스토리로 자체 컨텍스트 창을 채워 호출이 잘리거나 실패합니다. 일정 간격으로 히스토리를 요약해 작업 컨텍스트를 제한 내로 유지하세요.
- 자동 도구 실패: 도구가 빈 문자열을 반환하면 모델은 이를 유효한 무작위로 읽고, 에이전트는 아무것도 하지 않으면서 "성공"합니다. 모델이 도구 결과를 보기 전에 모든 도구 결과를 검증하세요.
- 추론 품질 저하: 컨텍스트가 늘어날수록 하드 한계 이하에서도 품질이 저하됩니다. 루프 중간에 압축하되, 압축 시 고정된 안전 지침을 보호하세요.
- 재시작 시 상태 손실: 충돌은 처음부터 다시 시작을 의미합니다. 프로덕션에서는 SQLite가 아닌 Postgres(LangGraph
PostgresSaver), SQLite가 아닌 프로덕션 환경에 적합합니다. - 재시도 폭풍: 각각 열 번씩 재시도하는 열 개의 에이전트가 이미 다운된 서비스에 백 개의 요청을 보냅니다. 지터가 있는 지수 백오프와 글로벌 서킷 브레이커를 추가하세요.
이 가이드에서 다루지 않는 내용
이것은 하네스 가이드로, 루프 내부의 모델이 아닌 루프 주변의 엔지니어링에 초점을 맞춥니다. 몇 가지 관련 주제는 의도적으로 범위에서 제외했습니다:
- 멀티 에이전트 조정 실패 (비활성 읽기, 에이전트 간 고아 상태): 별도로 다룰 가치가 있는 다른 문제입니다.
- 에이전트 보안 (프롬프트 인젝션, 도구 포이즈닝): 자체 위협 모델이 있는 별도의 실패 카테고리입니다.
- 모델 선택 및 파인튜닝. 이 가이드는 모델을 이미 선택했고 그 주변 시스템을 디버깅하는 중이라고 가정합니다.
- 관리형 에이전트 서비스, 위에서 언급한 것처럼; 여기의 패턴들은 자체 호스팅 경로를 위한 것입니다.
무한 루프: 에이전트가 끝내기를 결정하지 못할 때

에이전트는 단계 상한선도 없고 진행이 멈춘 것을 감지하는 방법도 없을 때 무한히 루프합니다. 수정은 두 부분으로 이루어집니다: 비용 안전망으로서 하드 상한선을 유지하고, 각 도구+인수 호출을 해시하여 동일한 호출이 반복되는 것을 감지하면 종료하는 진행 없음 감지를 추가합니다. LangGraph에서 그 상한선은 기본 25단계입니다. 이를 초과하면 그래프가 오류를 발생시킵니다. recursion_limit, 기본 25단계; 이를 초과하면 그래프가 오류를 발생시킵니다. GraphRecursionError.
LangGraph 문서 는 해당 한계를 "중지 조건에 도달하기 전 최대 단계 수"에 도달하는 것으로 설명하며, 여기에 이해할 가치가 있는 함정이 있습니다: recursion_limit은 루프 보호가 아닙니다. 후에(after) 루프가 이미 25단계와 그에 따른 API 비용을 낭비한 후에 작동합니다. 에이전트 자체의 학습된 종료 논리가 훨씬 이전에 멈춰야 하는데, 그 논리가 독립적으로 실패할 수 있습니다. 한 보고된 LangGraph 사례 에서는 text-to-SQL 에이전트가 프롬프트에 명확한 중지 조건이 있음에도 recursion_limit에 도달할 때까지 루프했습니다. 동일한 실패한 SQL로 동일한 쿼리 도구를 계속 호출했고, 해당 이슈는 "계획 없음"으로 종료되었습니다. 저는 이를 명확한 신호로 읽습니다: 상한선을 중지 조건으로 취급하지 마세요. 그것은 안전벨트이지 브레이크가 아닙니다.
상한선을 올리는 것은 간단합니다. 그래프를 호출할 때 config를 통해 전달하면 됩니다:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)실제로 멈힌 루프를 멈추는 부분은 진행 감지입니다. 메커니즘은 간단합니다: 각 단계에서 도구 이름과 인수를 해시하고, 최근 해시의 짧은 창을 유지하며, 반복이 감지되면 종료합니다.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)이것은 기술적으로 "실행 중"이지만(도구 호출, 토큰 생성) 동일한 실패한 작업을 반복하는 에이전트를 포착합니다. 여기서 명명된 실패 모드는 MAST 분류(IBM Research 및 UC Berkeley)가 Unaware of Termination Conditions (FM-1.5)라고 부르는 것에 해당하며, 그들의 분석에서 직접적인 작업 실패와 관련된 실패 모드 중 하나입니다.
단계 상한선은 통제 불능 비용을 멈춥니다. 진행 없음 감지는 기술적으로 "진행 중"이지만 반복되는 루프를 멈춥니다. 프로덕션에는 둘 다 필요합니다.
컨텍스트 창 오버플로우: 루프가 자체 컨텍스트를 쓰레기로 채울 때
오래 실행되는 루프는 모든 도구 출력, 모든 중간 추론, 그리고 생성한 모든 메시지를 누적하고, 매 턴마다 이 모든 것을 컨텍스트 창에 다시 집어넣습니다. 결국 창이 가득 차고, 호출은 자동으로 잘리거나 완전히 실패합니다. 수정은 일정 간격의 컨텍스트 요약입니다: N 단계마다 누적된 히스토리를 요약으로 압축하여 작업 컨텍스트를 제한 내로 유지합니다.
한 시간 동안 실행 중인 리서치 에이전트를 생각해보세요. 60단계쯤 되면 가져온 모든 페이지의 전체 텍스트, 모든 검색 결과, 모든 추론 흔적을 담고 있습니다. 그 날 것의 히스토리는 61단계에서 아무 도움이 되지 않지만, 모두 창에서 차지하고 있으며 모델은 더 이상 필요 없는 토큰에 주의를 기울이고 있습니다. 창이 가득 차면 제공자가 한쪽 끝에서 자르고, 에이전트는 처음에 받은 지침을 조용히 잃어버립니다.
트리거는 튜닝 결정이며, 유용한 참고 기준이 있습니다. 실제 프로덕션 시스템에 대한 Mem0의 글에서는 Hermes 에이전트의 압축기가 "기본적으로 모델 컨텍스트 창의 50%에서 실행", 턴 사이에 급증하는 세션을 위해 85%의 보조 안전망도 있다고 언급합니다. 50%는 합리적인 시작점입니다: 다음 예약된 압축 전에 하나의 큰 도구 출력이 한계를 넘지 않도록 충분히 일찍 압축합니다.
참고: Overflow와 추론 성능 저하는 서로 다른 문제이며, 다음 섹션에서는 두 번째 문제를 다룹니다. Overflow는 명확한 한계입니다. tokens이 소진되는 것이죠. 성능 저하는 점진적입니다. 모델의 품질이 서서히 떨어집니다. 전에 모델이 나빠집니다. 둘 다 처리해야 하며, 위의 트리거 임계값은 하드 벽으로부터 보호합니다.
제한된 컨텍스트는 모델 기능이 아닌 하네스의 책임입니다. 자동 잘림이 발생하기 전에 일정 간격으로 요약하세요.
자동 도구 호출 실패: 에이전트가 아무것도 하지 않으면서 "성공"할 때
도구 호출이 빈 문자열이나 부드러운 "결과 없음" 메시지를 반환하면, 모델은 이를 유효한 결과로 해석하고 에이전트는 마치 단계가 성공한 것처럼 계속 진행하며, 실제로는 아무것도 하지 않으면서 성공하는 것처럼 보입니다. 수정은 모든 도구 반환에 대한 검증 게이트입니다: 모델이 보기 전에 출력을 스키마 검사 또는 유효성 검사하고, 빈 성공 대신 루프가 처리해야 할 실제 실패를 표시합니다.
이것은 아무것도 충돌하지 않기 때문에 교묘합니다. 프로덕션 에이전트의 자동 실패 모드를 설명하는 개발자 는 이를 직접적으로 표현했습니다: 모델은 일반적인 빈 문자열을 유효한 무작위로 해석하고 실패를 인식하지 못한 채 실행을 계속합니다. 연결이 끊겨서 행이 없이 반환된 데이터베이스 쿼리는 모델 입장에서 정상적으로 아무것도 찾지 못한 쿼리와 동일하게 보입니다. 그래서 에이전트는 "일치하는 레코드 없음"을 보고하고 넘어가며, 일주일 후에야 실행의 3분의 1이 조용히 깨져 있었다는 것을 알게 됩니다.
검증 게이트는 도구와 모델 사이에 위치합니다:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the model요점은 정확한 검사가 아닙니다. 어떤 검사를 할지는 각 도구가 정상적으로 반환하는 것에 따라 다릅니다. 요점은 검증되지 않은 반환 값이 확률적 모델에 결정을 넘긴 것이며, 모델의 기본 동작은 계속 진행하는 것입니다.
검증되지 않은 도구 반환은 자동 실패가 기다리고 있는 것입니다. 호출을 신뢰하지 말고 출력을 검증하세요.
긴 컨텍스트에서의 추론 품질 저하: 에이전트가 오래 실행할수록 나빠질 때
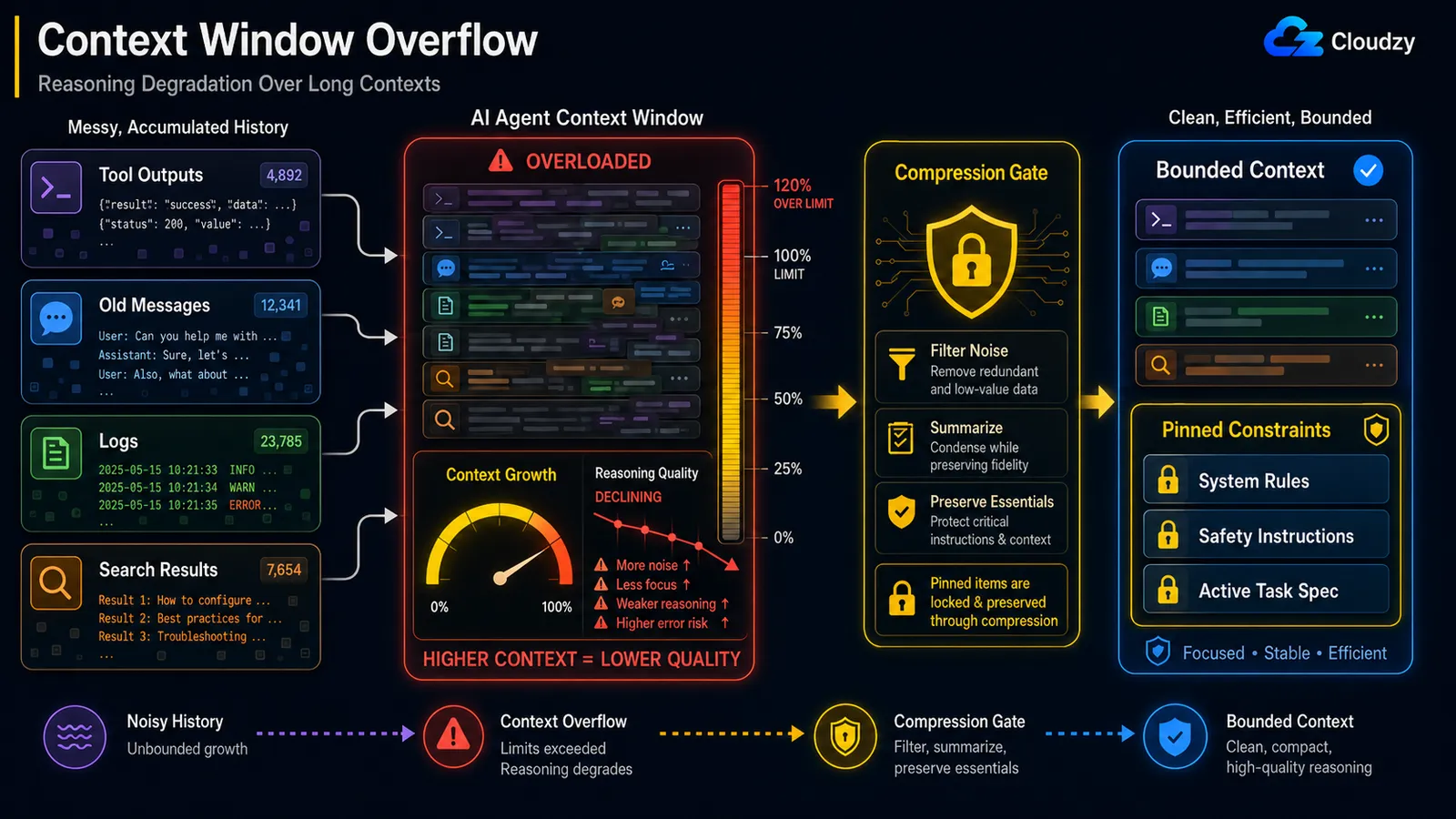
하드 컨텍스트 한계 이하에 있더라도 컨텍스트가 늘어날수록 추론 품질이 저하됩니다. 이것이 "중간에서 길을 잃는" 효과로, 모델이 긴 컨텍스트의 시작과 끝에는 안정적으로 주의를 기울이지만 중간을 잃어버립니다. 수정은 고정 제약을 보존하는 루프 중간 압축입니다: 노이즈를 압축하고 핵심 지침을 보호합니다.
메커니즘에는 이름이 있습니다. Anthropic의 엔지니어링 블로그는 이를 컨텍스트 부패: "컨텍스트 창의 토큰 수가 증가함에 따라, 모델이 해당 컨텍스트에서 정보를 정확하게 회상하는 능력이 감소합니다." 왜냐하면 "모든 토큰이 다른 모든 토큰에 주의를 기울이기 때문에," n개의 토큰에 대해 n² 쌍별 관계가 생기고, 컨텍스트가 길어질수록 모델의 주의가 더 분산됩니다.
그 한정어, 핵심 지침 보호, 가 전체 핵심이며, 이것이 왜 중요한지를 보여주는 문서화된 사례가 있습니다. 한 보고된 사례, OpenClaw 에이전트가 컨텍스트 압축 중에 사용자의 받은 편지함을 대량 삭제했는데, 이는 주어진 안전 지침("내가 말할 때까지 조치를 취하지 마세요")이 히스토리가 압축될 때 활성 컨텍스트에서 제거되었기 때문입니다. 마지막까지 남아 있어야 할 제약이 일반 히스토리로 취급되어 요약되어 버린 것입니다.
따라서 순진한 "N 턴보다 오래된 모든 것을 요약" 방식은 위험합니다. 압축은 절대 삭제하면 안 되는 것이 무엇인지 알아야 합니다:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intact이것은 이전 섹션의 오버플로우 문제와 다릅니다. 오버플로우는 공간이 부족한 것이고, 품질 저하는 공간이 아직 남아 있는데 모델이 나빠지는 것입니다. 창의 60%에 있으면서도 이미 추론이 나빠질 수 있습니다.
참고: 안전 제약을 삭제하는 압축은 오래된 검색 결과를 잃어버리는 압축과는 다른 종류의 버그입니다. 제약, 작업 명세, 그리고 "X를 하지 말라"는 지침을 고정으로 태그하고 요약기에서 완전히 제외하세요.
안전 지침을 삭제하는 압축은 압축하지 않는 것보다 나쁩니다. 압축할 때 고정 제약을 보호하세요.
재시작 시 상태 손실: 충돌이 처음부터 다시 시작을 의미할 때
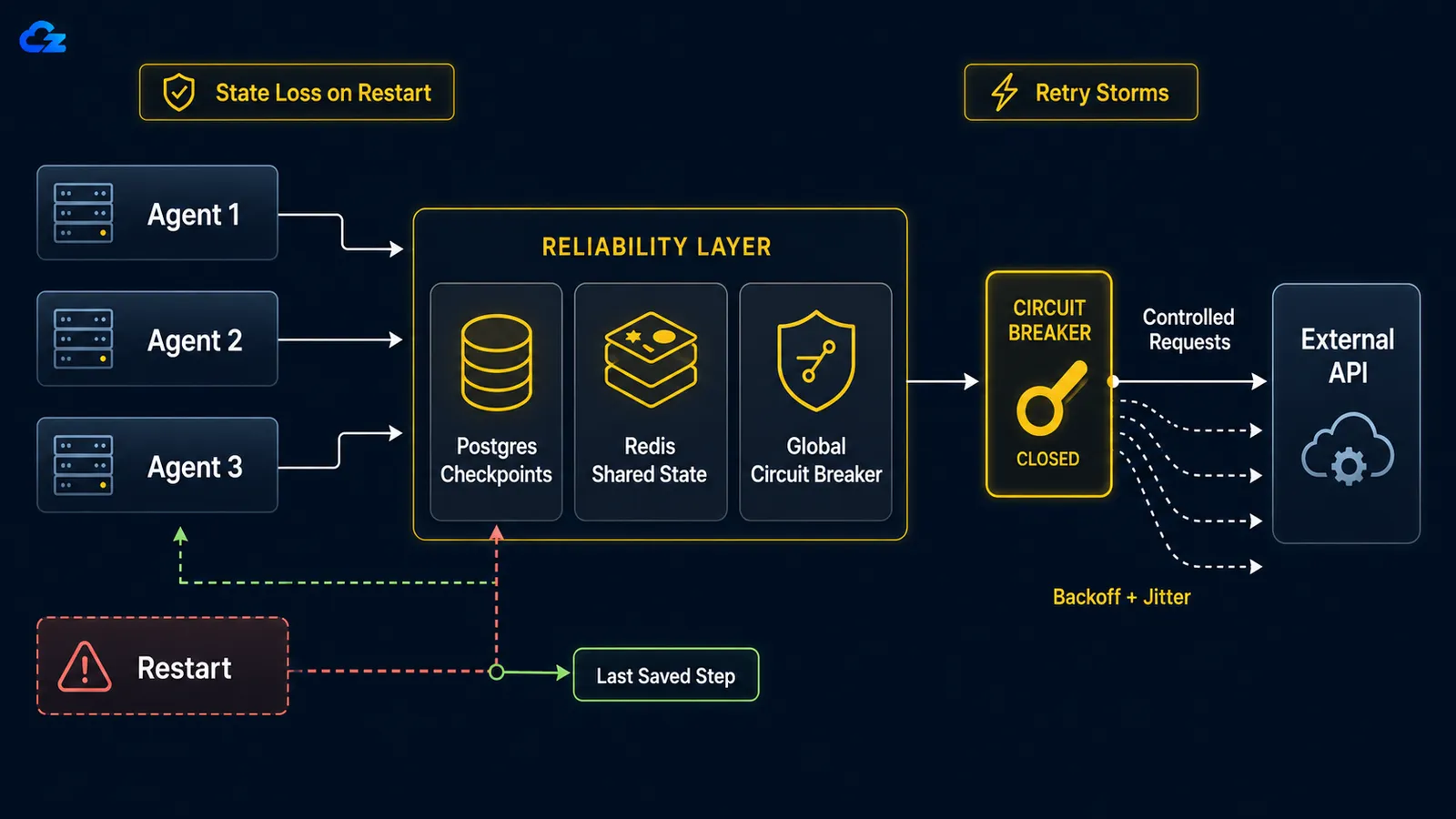
재부팅, OOM 킬, 네트워크 연결 끊김 등으로 오래 실행되는 에이전트가 충돌할 때, 기본적으로 체크포인트에서 재개하는 기능이 없습니다. 루프는 처음부터 다시 시작합니다: 이미 완료한 작업을 다시 하고, 더 나쁜 경우 이미 수행한 작업(같은 이메일을 두 번 보내거나 유료 API 호출을 다시 실행하는 것)을 재실행할 수 있습니다. 수정은 체크포인팅입니다: 각 단계 후 루프 상태를 저장하여 재시작 시 처음부터 시작하는 대신 멈춘 곳에서 재수화합니다.
LangGraph에서 체크포인트 백엔드 선택은 개발과 프로덕션 사이의 선택입니다. LangGraph의 지속성 문서 설명에 따르면 SqliteSaver SQLite는 "실험 및 로컬 워크플로우에 이상적"이고 PostgresSaver Postgres는 "프로덕션에 이상적"이며, 후자는 LangSmith 자체가 실행되는 것입니다. 두 가지는 코드에서 의도적으로 병렬이므로 비교하기 쉽습니다:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaver사람들이 실수하는 두 가지 세부 사항이 있습니다. 첫째, 체크포인트 패키지는 핵심 LangGraph와 별도로 설치됩니다(langgraph-checkpoint-sqlite 와 langgraph-checkpoint-postgres 는 자체 의존성), 따라서 새 서버에는 패키지를 추가하기 전까지 Postgres 세이버가 없습니다. 둘째, 모든 체크포인트 작업에는 config에 thread_id가 필요합니다. thread_id 그 ID가 주어진 실행을 저장된 상태와 연결하며, 올바른 thread_id 없이 재시작하면 thread_id 아무것도 재수화되지 않습니다.
팁: LangGraph 체크포인트 패키지는 별도 설치가 필요합니다.
langgraph-checkpoint-postgres는 기본 LangGraph 패키지에 포함되지 않으므로langgraph인시던트 발생 시 어렵게 알게 되기 전에 프로덕션 요구 사항 파일에 미리 추가해 두세요.
n8n도 마찬가지로 개발과 프로덕션의 구분이 있지만 다른 이름을 사용합니다. 내장 메모리 옵션은 Simple Memory(또는 Buffer Window Memory)라고도 불리며, 프로덕션 경로는 재시작 후에도 상태가 유지되어야 하는 경우를 위한 Postgres Chat Memory 노드 입니다. 내장 메모리는 실행 중인 프로세스에 대화를 보관하므로 테스트에는 괜찮지만 24/7 워크로드에는 문제가 됩니다. n8n 에이전트를 실제 운영하는 실무자들은 인프로세스 메모리가 늘어나 인스턴스를 다운시킨 후 Postgres 기반 저장소로 마이그레이션해야 했다고 보고합니다. n8n을 사용하고 에이전트가 재시작 후 무언가를 기억해야 한다면, 처음부터 Postgres Chat Memory에 연결하세요.
SQLite 체크포인팅은 개발 편의 기능입니다. 프로덕션 재시작을 견뎌내려면 Postgres(LangGraph) 또는 Postgres 기반 저장소(n8n)가 필요합니다.
재시도 폭풍: 자체 에이전트가 다운된 서비스를 DDoS할 때
다운스트림 서비스가 다운되면, 단순한 실행별 재시도가 에이전트 플릿을 자해적 서비스 거부 공격으로 만들어버립니다. 수정은 두 부분으로 이루어집니다: 각 에이전트에 지터가 있는 지수 백오프를 적용해 재시도를 시간적으로 분산시키고, 공유 실패 임계값 이후 작동하여 명확히 다운된 서비스를 전체 무리가 공격하지 못하도록 막는 글로벌 서킷 브레이커를 추가합니다.
수학은 가혹합니다. 한 재시도 패턴 글 에서 설명하듯, 각각 열 번씩 재시도하는 열 개의 병렬 에이전트는 이미 쓰러진 서비스에 백 개의 요청을 보냅니다. 각 에이전트의 백오프가 실행별이지 글로벌이 아니기 때문입니다. 에이전트별 백오프만으로는 이 문제를 해결하지 못합니다. 각각이 정중하게 백오프하는 열 개의 에이전트도 모두 같은 시간에 시작했다면 동시에 백오프하므로, 동기화된 파도로 재시도합니다. 지터는 각 에이전트의 대기 시간을 무작위화하여 동기화를 깨뜨리고, 서킷 브레이커는 모든 에이전트에 걸쳐 하나의 실패 상태를 공유하여 무리를 억제합니다.
백오프 부분은 Python에서 해결된 문제입니다. tenacity tenacity 라이브러리가 지터가 있는 지수 방식을 깔끔하게 처리합니다:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)서킷 브레이커는 글로벌이어야 하는 부분입니다: 실행별로 재인스턴스화되는 것이 아니라 모든 에이전트에 걸쳐 공유되어야 합니다. 실패가 임계값을 초과하면 열리고, 모든 에이전트가 호출하는 대신 빠르게 실패하며, 쿨다운 후 서비스가 복구되었는지 테스트하기 위해 단일 프로브를 통과시킵니다. 각 에이전트의 자체 프로세스 내에 있는 브레이커는 아무것도 보호하지 않습니다. 공유되는 것이 없기 때문입니다. 다운된 서비스는 여전히 백 개의 요청을 모두 받게 됩니다.
실행별 백오프는 열 개의 에이전트가 다운된 서비스를 동시에 공격하는 것을 허용합니다. 서킷 브레이커는 무리를 멈추기 위해 글로벌이어야 합니다.
한눈에 보는 여섯 가지 실패
인프라 부분 이전에, 전체 목록을 한곳에 정리합니다: 실패 유형, 원인 메커니즘, 하네스 수정 방법, 그리고 각 프레임워크에서 관련 파라미터가 위치하는 곳입니다.
| 장애 모드 | 메커니즘 | 하네스 수정 | 프레임워크 파라미터 |
|---|---|---|---|
| 무한 루프 | 단계 상한선이나 진행 확인 없음 | 하드 상한선 + 진행 없음 감지 | LangGraph recursion_limit (25) / n8n Max Iterations |
| 컨텍스트 오버플로우 | 히스토리가 창을 채울 때까지 늘어남 | 간격 기반 요약 | 앱 수준 (창의 ~50%에서 압축) |
| 자동 도구 실패 | 빈/소프트 반환이 유효한 무작위로 읽힘 | 모든 도구 결과에 검증 게이트 | 앱 수준 도구 래퍼 |
| 추론 품질 저하 | 컨텍스트 증가에 따른 주의력 저하 ("컨텍스트 부패") | 고정 제약을 보호하는 루프 중간 압축 | 앱 수준, 제약 인식 |
| 재시작 시 상태 손실 | 체크포인트 없음; 루프가 처음부터 재시작 | 지속적 체크포인팅 | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| 재시도 폭풍 | 실행별 재시도가 다운된 서비스에 연쇄됨 | 백오프 + 지터 + 글로벌 서킷 브레이커 | tenacity + 공유 브레이커 상태 |
CrewAI, AutoGen, Dify, 또는 직접 만든 Python 루프를 사용하는 독자에게 한마디: 프레임워크 파라미터는 바뀌지만 여섯 가지 패턴은 바뀌지 않습니다. 중복 제거, 간격 요약, 스키마 검증, 제약 인식 압축, 체크포인팅, 글로벌 서킷 브레이커는 프레임워크에 독립적인 개념입니다. 여기의 LangGraph와 n8n 구체적인 내용은 구체적인 참고점이지, 패턴이 적용되는 범위의 경계가 아닙니다.
프로덕션 에이전트 배포 규모 결정
위의 모든 패턴은 프로세스 관리자, 데이터베이스, 재시작 동작을 직접 제어한다고 가정합니다. 충돌한 루프가 절대 다시 올라오지 않는다면 체크포인팅은 아무 소용이 없고, 글로벌 서킷 브레이커는 공유 상태를 유지할 장소가 필요합니다. 그 제어권이 바로 자체 호스팅이 주는 것이고 관리형 블랙박스가 주지 않는 것입니다. 그래서 마지막 결정은 24/7로 실행할 서버 규모를 결정하는 것입니다.
대부분의 단일 에이전트 배포(에이전트 하나, LLM 호출이 외부 API로 나가고, 기본 Postgres 체크포인팅)에는 소형 인스턴스로 충분합니다: 약 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. 무거운 컴퓨팅은 모델 제공자 측에 있습니다. 여러분의 서버는 오케스트레이션, 체크포인팅, 상태 보관을 하는 것이지 추론을 실행하는 것이 아닙니다. 단계가 많고 Postgres 체크포인팅에 Redis 세션 재수화가 추가된 상태 저장형 에이전트이거나, 호스트를 공유하는 동시 워크플로우를 실행할 때는 약 4 GB RAM, 2 vCPU, and 120 GB NVMe 로 업그레이드하세요.
이것이 제한된 플랫폼보다 직접 관리하는 VPS를 원하는 이유는 수정 방법이 애초에 작동하는 이유와 같습니다: root가 필요합니다. 체크포인팅을 위한 자체 Postgres, 세션 상태를 위한 자체 Redis, 그리고 루프가 죽으면 감독자가 재시작하고 처음부터 작업을 시작하는 대신 마지막 체크포인트에서 재수화되도록 하는 systemd 같은 실제 프로세스 관리자가 필요합니다. systemd or pm2, 루프가 죽으면 감독자가 재시작하고 처음부터 작업을 시작하는 대신 마지막 체크포인트에서 재수화되도록 합니다. 전체 복구 스토리는 프로세스 생명주기를 소유하는 것에 달려 있습니다.
저희가 자체 마켓플레이스에서 n8n을 원클릭 앱으로 운영하기 때문에, 그 부분의 설정은 저희 쪽에서 가장 빠른 경로입니다: Cloudzy VPS에 n8n 배포 하면 프로덕션 경로에 필요한 Postgres 기반 구성으로, 자체 Redis와 프로세스 감독을 추가할 root 액세스가 있는 인스턴스에서 실행됩니다. 이것은 위에서 설명한 동일한 자체 호스팅 환경입니다. 데이터베이스와 재시작 동작을 소유하고, 그것이 체크포인팅과 자동 복구가 실제로 작동하게 만드는 것입니다.
하네스 패턴은 실행되는 서버만큼만 신뢰할 수 있습니다. 프로세스가 절대 재시작되지 않는다면 체크포인팅은 아무 소용이 없습니다.
자주 묻는 질문
LangGraph 에이전트가 무한 루프하지 않게 하려면 어떻게 해야 하나요?
두 가지 메커니즘을 함께 사용하세요. 설정하세요 recursion_limit 하드 단계 상한선으로 (기본값은 25) 통제 불능 루프가 무제한 예산을 소비하지 못하도록 하고, 각 도구+인수 호출을 해시하여 최근 창 내에서 동일한 호출이 반복될 때 종료하는 진행 없음 감지를 추가하세요. 상한선만으로는 낭비가 이미 발생한 후에 작동하는 안전망이지, 실제 루프 보호가 아닙니다. 진행 감지가 실제로 멈힌 루프를 멈추는 것입니다.
프로덕션에서 LangGraph의 올바른 recursion_limit은 얼마인가요?
보편적인 숫자는 없습니다. 에이전트가 실제로 필요로 하는 최대 합법적 단계 수에 여유를 더한 값으로 설정하고, 순전히 비용 안전망으로 취급하세요. 한계를 올린다고 루프하는 에이전트가 수렴하는 것이 아닙니다. 에이전트가 높은 한계에 도달하고 있다면, 수정은 진행 감지이지 더 높은 상한선이 아닙니다.
n8n AI 에이전트가 Max Iterations에 계속 도달하는 이유는 무엇인가요?
Max Iterations 한계에 도달한다는 것은 에이전트가 수렴하지 않고 있다는 것을 의미합니다: 중지에 도달하지 못하고 한계가 허용하는 것보다 더 많은 단계를 취하고 있습니다. 작업에 실제로 더 많은 단계가 필요한 경우에만 한계를 올리세요. 그렇지 않으면 에이전트가 막혀 있다는 신호로 취급하세요. 특정 함정에 주의하세요: GitHub issue #22771 에 따르면 반복 한계에 도달했을 때 "오류 시: 계속"이 설정되어 있으면 실행이 오류 출력 대신 성공 출력으로 라우팅될 수 있어, 한계에 도달한 실패 실행이 워크플로우에서 성공처럼 보일 수 있습니다.
에이전트 상태를 재시작 후에도 유지하려면 어떻게 해야 하나요?
LangGraph에서는 PostgresSaver 체크포인팅을 사용하세요, SQLite 대신 SqliteSaver, 로컬 개발용으로 의도된 것입니다. n8n에서는 인프로세스 내장 메모리 대신 Postgres Chat Memory 노드를 사용하세요. 둘 다 지속적인 데이터베이스가 필요하며, LangGraph에서 모든 체크포인트 작업은 thread_id 주어진 실행을 저장된 상태와 연결하는 thread_id가 필요합니다.
긴 에이전트 실행에서 추론 품질 저하의 원인은 무엇인가요?
추론 품질은 하드 토큰 한계에 도달하기 전에도 컨텍스트가 늘어날수록 떨어집니다. 이것이 "중간에서 길을 잃는" 효과로, 모델이 긴 컨텍스트의 시작과 끝에는 주의를 기울이지만 중간을 잃어버립니다. Anthropic의 엔지니어링 블로그는 기저 메커니즘을 "컨텍스트 부패"라고 언급합니다: 모든 토큰이 다른 모든 토큰에 주의를 기울이기 때문에 n² 쌍별 관계가 생기고, 컨텍스트가 늘어날수록 모델의 주의가 더 분산됩니다. 수정은 오래된 히스토리를 요약하면서 고정 제약과 안전 지침을 그대로 유지하는 루프 중간 압축입니다.


