
Een van de belangrijkste aspecten van machine learning, zo niet het belangrijkste, is het behalen van nauwkeurige en betrouwbare voorspellingen. Een innovatieve aanpak die hiervoor bekendheid heeft gekregen is Bootstrap Aggregating, beter bekend als bagging in machine learning. Dit artikel bespreekt bagging in machine learning, vergelijkt bagging en boosting in machine learning, geeft een voorbeeld van een bagging-classifier, legt uit hoe bagging werkt en verkent de voor- en nadelen van bagging in machine learning.
Wat is bagging in machine learning?
Dit zijn de enige twee relevante afbeeldingen die in populaire artikelen worden gebruikt. Een of beide kunnen worden gebruikt (één hier en de andere elders) als Design Cloudzy-versies ervan maakt.
Wat is bagging?
Stel je voor dat je het gewicht van een object probeert te schatten door meerdere mensen om hun schatting te vragen. Individueel kunnen hun schattingen sterk uiteenlopen, maar door alle schattingen te middelen kom je tot een betrouwbaarder getal. Dit is de kern van bagging: de uitkomsten van meerdere modellen combineren om een nauwkeurigere en betrouwbaardere voorspelling te produceren.
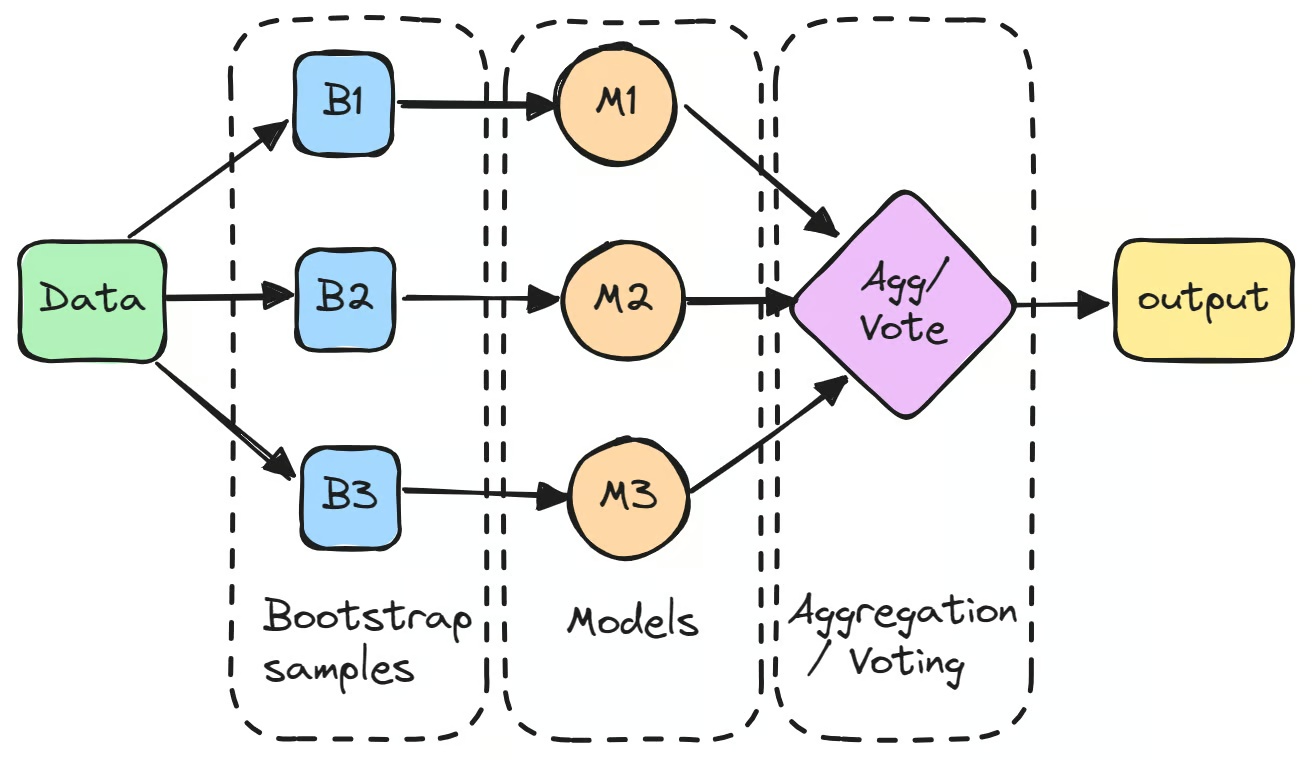
Het proces begint met het aanmaken van meerdere subsets van de originele dataset via bootstrapping, wat neerkomt op willekeurige steekproeven met teruglegging. Elke subset wordt gebruikt om een afzonderlijk model onafhankelijk te trainen.
Deze individuele modellen, vaak aangeduid als 'zwakke leerders', presteren op zichzelf mogelijk niet bijzonder goed vanwege hoge variantie. Wanneer hun voorspellingen echter worden samengevoegd - doorgaans door middeling bij regressietaken of meerderheidsstemming bij classificatietaken - overtreft het gecombineerde resultaat vaak de prestaties van elk afzonderlijk model.
Een bekend voorbeeld van een bagging-classifier is het Random Forest-algoritme, dat een ensemble van beslissingsbomen opbouwt om de voorspellende prestaties te verbeteren. Bagging mag niet worden verward met boosting in machine learning: boosting traint modellen opeenvolgend om bias te verminderen, terwijl bagging modellen parallel traint om variantie te verminderen.
Zowel bagging als boosting in machine learning zijn gericht op betere modelprestaties, maar ze pakken verschillende aspecten van het modelgedrag aan.
Waarom is bagging nuttig?
Een van de belangrijkste voordelen van bagging in machine learning is het vermogen om variantie te verminderen, waardoor modellen beter generaliseren naar nieuwe data. Bagging is vooral waardevol bij algoritmen die gevoelig zijn voor schommelingen in de trainingsdata, zoals beslissingsbomen.
Door overfitting te voorkomen, levert bagging een stabieler en betrouwbaarder model op. Vergeleken met boosting in machine learning richt bagging zich op het verminderen van variantie door meerdere modellen parallel te trainen, terwijl boosting bias vermindert door modellen opeenvolgend te trainen.
Een voorbeeld van bagging in machine learning is financiële risicovoorspelling, waarbij meerdere beslissingsbomen worden getraind op verschillende deelverzamelingen van historische marktdata. Door hun voorspellingen samen te voegen, ontstaat een stabieler voorspellingsmodel dat minder gevoelig is voor fouten van individuele modellen.
Kort gezegd combineert bagging in machine learning de inzichten van meerdere modellen om voorspellingen te doen die nauwkeuriger en betrouwbaarder zijn dan die van afzonderlijke modellen.
Hoe bagging in machine learning werkt: stap voor stap
Om goed te begrijpen hoe bagging de modelprestaties verbetert, doorlopen we het proces stap voor stap.
Meerdere bootstrap-samples nemen uit de dataset
De eerste stap bij bagging in machine learning is het aanmaken van meerdere nieuwe deelverzamelingen van de originele dataset via bootstrapping. Deze techniek houdt in dat data willekeurig met teruglegging wordt gesampeld, waardoor sommige datapunten meerdere keren in dezelfde deelverzameling kunnen voorkomen, terwijl andere helemaal niet voorkomen. Dit zorgt ervoor dat elk model wordt getraind op een iets andere versie van de data.
Een apart model trainen op elke sample
Elke bootstrap-sample wordt vervolgens gebruikt om een apart model te trainen, doorgaans van hetzelfde type, zoals beslissingsbomen. Deze modellen, ook wel 'base learners' of 'weak learners' genoemd, worden onafhankelijk getraind op hun eigen deelverzameling. Een voorbeeld van een bagging-classifier is de beslissingsboom in het Random Forest-algoritme, dat de basis vormt van veel bagging-modellen. Elk individueel model presteert misschien niet goed op zichzelf, maar elk brengt unieke inzichten mee op basis van zijn specifieke trainingsdata.
De voorspellingen samenvoegen
Na het trainen worden de voorspellingen van alle modellen samengevoegd tot een eindresultaat.
- Voor regressietaken worden de voorspellingen gemiddeld, wat de variantie van het model verlaagt.
- Voor classificatietaken wordt de uiteindelijke voorspelling bepaald door meerderheidstemming: de klasse die door de meeste modellen wordt voorspeld, wordt geselecteerd. Dit levert een stabielere voorspelling op dan die van een enkel model.
Uiteindelijke Voorspelling
Door voorspellingen van meerdere modellen te combineren, vermindert bagging de impact van fouten in één enkel model en verbetert het de algehele nauwkeurigheid. Dit samenvoegingsproces maakt bagging zo effectief, vooral bij machine learning-taken waarbij modellen met een hoge variantie, zoals beslissingsbomen, worden gebruikt. Het vlakt inconsistenties in individuele modelvoorspellingen af en leidt tot een sterker eindmodel.
Hoewel bagging effectief is voor het stabiliseren van voorspellingen, zijn er een aantal aandachtspunten: als de basismodellen te complex zijn, bestaat er alsnog een risico op overfitting, ondanks dat bagging juist bedoeld is om dat te verminderen.
Bagging is ook rekenintensief. Het aanpassen van het aantal base learners of het overwegen van efficiëntere ensemble-methoden kan helpen, en het kiezen van de juiste GPU voor ML en DL is altijd belangrijk.
Zorg voor voldoende diversiteit tussen de base learners voor betere resultaten. Werk je met ongebalanceerde data, dan kunnen technieken zoals SMOTE nuttig zijn vóór het toepassen van bagging, om slechte prestaties op minderheidsklassen te vermijden.
Toepassingen van Bagging
Nu we hebben bekeken hoe bagging werkt, is het tijd om te kijken waar het in de praktijk wordt gebruikt. Bagging heeft zijn weg gevonden naar uiteenlopende sectoren en helpt de nauwkeurigheid en stabiliteit van voorspellingen te verbeteren in complexe situaties. Hieronder een aantal van de meest impactvolle toepassingen:
- Classificatie en regressie: Bagging wordt veel gebruikt om de prestaties van classifiers en regressors te verbeteren door variantie te verminderen en overfitting tegen te gaan. Zo zijn Random Forests, die gebruikmaken van bagging, effectief bij taken als beeldclassificatie en voorspellend modelleren.
- Afwijkingsdetectie: In vakgebieden zoals fraudedetectie en detectie van netwerkinbraak bieden bagging-algoritmen betere prestaties door effectief uitschieters en anomalieën in data te identificeren.
- Financiële risicobeoordeling: In de bankwereld worden bagging-technieken ingezet om kredietscoringsmodellen te verbeteren, wat de nauwkeurigheid van leninggoedkeuringsprocessen en financiële risicobeoordelingen ten goede komt.
- Medische Diagnostiek: In de gezondheidszorg wordt bagging toegepast om neurocognitieve aandoeningen zoals de ziekte van Alzheimer op te sporen door MRI-datasets te analyseren, wat bijdraagt aan vroege diagnose en behandelplanning.
- Natuurlijke taalverwerking (NLP): Bagging draagt bij aan taken zoals tekstclassificatie en sentimentanalyse door voorspellingen van meerdere modellen samen te voegen, wat leidt tot een beter taalbegrip.
Voordelen en nadelen van bagging
Zoals elke machine learning-techniek heeft bagging zijn eigen voor- en nadelen. Inzicht daarin helpt bepalen wanneer en hoe je bagging in je modellen inzet.
Voordelen van Bagging:
- Vermindert variantie en overfitting: Een van de grootste voordelen van bagging in machine learning is het vermogen om variantie te verminderen, waardoor overfitting wordt tegengegaan. Door meerdere modellen te trainen op verschillende deelverzamelingen van de data zorgt bagging ervoor dat het model niet te gevoelig wordt voor schommelingen in de trainingsdata, wat resulteert in een beter generaliseerbaar en stabieler model.
- Werkt goed met modellen met hoge variantie: Bagging is vooral effectief in combinatie met modellen met hoge variantie, zoals beslissingsbomen. Deze modellen neigen naar overfitting en hebben een hoge variantie, maar bagging compenseert dit door voorspellingen van meerdere modellen te middelen of te combineren via voting. Dit maakt voorspellingen betrouwbaarder en minder gevoelig voor ruis in de data.
- Verbetert modelstabiliteit en prestaties: Door meerdere modellen te combineren die getraind zijn op verschillende deelverzamelingen van de data leidt bagging vaak tot betere algehele prestaties. Het verhoogt de voorspellingsnauwkeurigheid en vermindert de gevoeligheid van het model voor kleine wijzigingen in de dataset, waardoor het model uiteindelijk betrouwbaarder wordt.
Nadelen van Bagging:
- Verhoogt de rekenlast: Omdat bagging het trainen van meerdere modellen vereist, neemt de rekenlast navenant toe. Het trainen en samenvoegen van voorspellingen van veel modellen kan tijdrovend zijn, zeker bij grote datasets of complexe modellen zoals beslissingsbomen.
- Weinig effectief voor modellen met lage variantie: Hoewel bagging zeer effectief is voor modellen met hoge variantie, levert het weinig op bij modellen met lage variantie, zoals lineaire regressie. In die gevallen hebben de afzonderlijke modellen al lage foutmarges, waardoor het samenvoegen van voorspellingen nauwelijks iets toevoegt.
- Verlies van interpreteerbaarheid: Door meerdere modellen te combineren kan bagging de interpreteerbaarheid van het uiteindelijke model verminderen. In Random Forest bijvoorbeeld is het beslissingsproces gebaseerd op meerdere beslissingsbomen, waardoor het moeilijker wordt om de redenering achter een specifieke voorspelling te volgen.
Wanneer gebruik ik bagging?
Weten wanneer je bagging toepast in machine learning-projecten is essentieel voor goede resultaten. De techniek werkt goed in bepaalde situaties, maar is niet altijd de beste keuze voor elk probleem.
Wanneer je model gevoelig is voor overfitting
Een van de voornaamste toepassingen van bagging is wanneer je model gevoelig is voor overfitting, met name bij modellen met hoge variantie zoals beslissingsbomen. Deze modellen kunnen goed presteren op trainingsdata, maar generaliseren vaak slecht naar nieuwe data omdat ze te nauw aansluiten bij de specifieke patronen van de trainingsset.
Bagging bestrijdt dit door meerdere modellen te trainen op verschillende deelverzamelingen van de data en de uitkomsten te middelen of te combineren via stemming, wat leidt tot een stabielere voorspelling. Dit verkleint de kans op overfitting en maakt het model beter in staat om nieuwe, ongeziene data te verwerken.
Wanneer je stabiliteit en nauwkeurigheid wilt verbeteren
Als je de stabiliteit en nauwkeurigheid van je model wilt verbeteren zonder te veel in te leveren op interpreteerbaarheid, is bagging een uitstekende keuze. Door voorspellingen van meerdere modellen samen te voegen, wordt het eindresultaat betrouwbaarder. Dat is vooral handig bij taken met veel ruis in de data.
Of je nu classificatieproblemen aanpakt of regressietaken uitvoert, bagging helpt om consistentere resultaten te produceren: hogere nauwkeurigheid zonder in te leveren op efficiëntie.
Wanneer je over voldoende rekenkracht beschikt
Een andere belangrijke factor bij de keuze voor bagging is de beschikbaarheid van rekenkracht. Omdat bagging vereist dat meerdere modellen tegelijkertijd worden getraind, kunnen de rekenkosten flink oplopen, met name bij grote datasets of complexe modellen.
Als je over de benodigde rekenkracht beschikt, wegen de voordelen van bagging ruimschoots op tegen de kosten. Heb je beperkte middelen, dan is het de moeite waard om alternatieve technieken te overwegen of het aantal modellen in je ensemble te beperken.
Wanneer je werkt met modellen met hoge variantie
Bagging is bijzonder nuttig bij modellen met een hoge variantie die gevoelig zijn voor schommelingen in de trainingsdata. Decision trees worden bijvoorbeeld vaak gecombineerd met bagging in de vorm van Random Forests, omdat hun prestaties sterk kunnen variëren afhankelijk van de trainingsdata.
Door meerdere modellen te trainen op verschillende deelverzamelingen van de data en hun voorspellingen te combineren, effent bagging de variantie uit en levert het een betrouwbaarder model op.
Wanneer je een betrouwbare classifier nodig hebt
Als je aan classificatieproblemen werkt en een betrouwbare classifier nodig hebt, kan bagging de stabiliteit van je voorspellingen aanzienlijk verbeteren. Een Random Forest, een klassiek voorbeeld van een bagging-classifier, levert nauwkeurigere voorspellingen door de resultaten van veel afzonderlijke decision trees samen te voegen.
Deze aanpak werkt goed wanneer individuele modellen zwak zijn, maar hun gecombineerde kracht resulteert in een sterk overallmodel.
Als je op zoek bent naar het juiste platform om bagging-technieken efficiënt toe te passen, bieden tools als Databricks en Snowflake een geïntegreerd analyseplatform dat zeer bruikbaar is voor het beheren van grote datasets en het uitvoeren van ensemble-methoden zoals bagging.
Ben je op zoek naar een minder technische aanpak van machine learning, no-code AI tools kan ook een optie zijn. Hoewel ze zich niet direct richten op geavanceerde technieken zoals bagging, stellen veel no-code-platforms gebruikers in staat om te experimenteren met ensemble learning-methoden, inclusief bagging, zonder uitgebreide programmeerkennis.
Zo kun je geavanceerdere technieken toepassen en toch nauwkeurige voorspellingen behalen, terwijl je je richt op modelprestaties in plaats van de onderliggende code.
Slotgedachten
Bagging is een krachtige techniek in machine learning die de modelprestaties verbetert door variantie te verlagen en stabiliteit te verhogen. Door de voorspellingen van meerdere modellen die zijn getraind op verschillende deelverzamelingen van de data samen te voegen, levert bagging nauwkeurigere en betrouwbaardere resultaten. Het is vooral effectief voor modellen met hoge variantie, zoals decision trees, omdat het overfitting helpt voorkomen en ervoor zorgt dat het model beter generaliseert naar ongeziene data.
Hoewel bagging duidelijke voordelen heeft, zoals het verminderen van overfitting en het verbeteren van nauwkeurigheid, kleven er ook een paar nadelen aan. Het verhoogt de rekenkosten door het trainen van meerdere modellen en kan de interpreteerbaarheid verminderen. Ondanks deze nadelen maakt het vermogen om prestaties te verbeteren het een waardevolle techniek binnen ensemble learning, naast andere methoden zoals boosting en stacking.
Heb je bagging gebruikt in machine learning-projecten? Laat ons weten wat je ervaringen zijn en hoe het voor jou heeft gewerkt!


