
In de jaren 60 en 70 monolithische architectuur werd de voorkeur gegeven voor het ontwikkelen van applicaties vanwege beperkte rekenkracht, wat vereiste dat alle functionaliteit in één samenhangend geheel werd gecombineerd.
Dat veranderde eind jaren negentig en begin jaren 2000, toen de monolithische structuur te beperkend werd voor de steeds grotere en complexere applicaties, mede door de opkomst van het internet en gedistribueerde systemen.
Dit leidde tot de ontwikkeling van meer modulaire benaderingen, zoals servicegeoriënteerde architecturen (SOA) en, later, microservices-architectuur (MSA), die begin jaren 2010 uiteindelijk breed ingang vonden.
Dit is echter slechts een beknopte uitleg van het basisprincipe en de toepassing van microservices. Laten we daarom bespreken hoe microservices de monolithische architectuur hebben vervangen, hoe microservices werken en enkele voorbeelden bekijken. Daarna gaan we in op de belangrijkste aspecten van het uitrollen van microservices en wat je kunt doen als je microservices wilt inzetten.
Wat zijn microservices? Hoe werken ze?
Zoals ik eerder aangaf, kwamen microservices op als oplossing voor de toenemende complexiteit en omvang van applicaties, waardoor bedrijven functies konden opsplitsen in onafhankelijk inzetbare services.
De term 'microservices' werd populair gemaakt door experts als Martin Fowler en James Lewis, die het begrip in 2014 formeel introduceerden in een blogpost. Hun werk legde de belangrijkste principes en kenmerken vast, waaronder de behoefte aan onafhankelijk inzetbare services, gedecentraliseerd gegevensbeheer en technologieonafhankelijkheid.
Sindsdien zijn microservices een gangbare architectuurkeuze geworden, mede dankzij ontwikkelingen in containerisatietechnologieën zoals Docker, orkestratiehulpmiddelen zoals Kubernetes en serverless-computerplatforms. Maar hoe werken microservices precies?
Hoe werken microservices?
In de kern splitst een microservices-architectuur een grote applicatie op in kleinere, afzonderlijke services, elk verantwoordelijk voor een specifieke bedrijfsfunctie. Deze services communiceren via een netwerk met elkaar, vaak via REST APIs, gRPC of berichtbrokers zoals RabbitMQ of Apache Kafka.
Volgens de definitie van Martin Fowler en James Lewis hebben microservices vier kerneigenschappen:
- Enkele Verantwoordelijkheid: Elke microservice is ontworpen om een specifieke taak of functie uit te voeren, wat specialisatie mogelijk maakt en de complexiteit beperkt.
- Onafhankelijkheid: Microservices kunnen onafhankelijk van elkaar worden ontwikkeld, geïmplementeerd en geschaald, wat flexibiliteit en veerkracht biedt.
- Gedecentraliseerd gegevensbeheer: Microservices hebben vaak hun eigen databases, waardoor een centrale, gedeelde database niet nodig is.
- Technologieonafhankelijkheid: Teams kunnen per service de meest geschikte technologie kiezen, zonder gebonden te zijn aan de keuzes van andere services.
Deze aanpak staat in contrast met de traditionele monolithische architectuur, waarbij alle applicatiecomponenten strak zijn geïntegreerd in één samenhangend geheel.
Belangrijke fasen bij het uitrollen van microservices
Een microservices-architectuur biedt veel voordelen, zoals hoge schaalbaarheid, flexibiliteit, efficiëntie en foutenisolatie. Maar om microservices effectief uit te rollen, heb je goede kennis van de materie en een gedegen planning nodig.
Daarom is een goed begrip van de kernconcepten, fasen en best practices voor het uitrollen van microservices essentieel voor een succesvolle microservices-architectuur. Laten we de belangrijkste fasen doorlopen en bekijken wat elke fase inhoudt.
Planning en voorbereiding voor het uitrollen van microservices
Goede resultaten vereisen planning en geduld. Om microservices succesvol uit te rollen, heb je daar zeker een flinke dosis van nodig. Volg daarom de best practices voor microservices en zorg dat alles goed voorbereid is voordat je begint.
Zoals eerder vermeld, is een van de kernprincipes en kenmerken van microservices het Beginsel van enkele verantwoordelijkheid. Door dit principe consequent toe te passen en ervoor te zorgen dat elke microservice zich richt op precies één functie en verantwoordelijkheid, kunnen je teamleden services onafhankelijk ontwikkelen, uitrollen en schalen.
Een afgeleide van dit principe is het losgekoppeld ontwerp principe. Dit houdt in dat elke service voor communicatie onafhankelijk kan functioneren en minimaal afhankelijk is van andere services. Daardoor hebben wijzigingen of updates aan één service geen gevolgen voor de andere services, wat onafhankelijk schalen mogelijk maakt.
Dit verlaagt het risico op cascadefouten, waarbij een probleem in één onderdeel van het systeem een kettingreactie veroorzaakt die tot storingen door het hele systeem leidt en de volledige service platgooit.
Een belangrijke best practice is het gebruik van dedicated opslag per service bij het uitrollen van microservices. Dit is een logisch gevolg van het loose coupling design principle: het voorkomt conflicten en maakt betere schaalbaarheid per service mogelijk.
Daarnaast heb je asynchrone communicatiepatronen nodig, zoals message brokers, om te garanderen dat elke service kan communiceren zonder directe afhankelijkheden.
Het laatste stukje van de puzzel is het inrichten van Continuous Integration en Continuous Delivery (CI/CD) pipelines voor microservices. Deze pipelines stellen teams in staat om nieuwe functies of fixes uit te rollen via CI/CD-hulpmiddelen zoals Jenkins en GitLab, zodat organisaties de systeemstabiliteit kunnen bewaken terwijl ze regelmatig nieuwe functionaliteit uitbrengen.
Nu je een goed beeld hebt van de planning en voorbereiding die nodig zijn voor het uitrollen van microservices, is het tijd om de verschillende uitrolstrategieën te bespreken.
Uitrolstrategieën voor microservices
Bij het uitrollen van microservices hangt de keuze van een strategie af van de servicefunctie, het verkeer, de infrastructuur, de expertise van het team en de kosten. Over het algemeen zien de uitrolstrategieën voor microservices er als volgt uit:
- Eén service-instantie per container: Bij deze aanpak draait elke microservice in een eigen container, wat betere isolatie biedt dan het model met meerdere instanties per host. Containers maken eenvoudig schalen mogelijk en verbeteren de resourceverdeling.
- Service-instantie per virtuele machine: Elke service draait in een aparte virtuele machine (VM), wat nog meer isolatie biedt dan containers. Dit verbetert de beveiliging en stabiliteit, maar brengt doorgaans meer overhead met zich mee.
- Gefaseerde releases Deploy nieuwe versies van microservices eerst naar een kleine groep gebruikers om de stabiliteit te testen voordat je breed uitrolt. Deze aanpak beperkt de impact bij problemen en maakt snelle terugrolacties mogelijk om de systeemintegriteit te bewaren.
- Blauw-Groen Implementatie: Deze methode maakt gebruik van twee identieke productieomgevingen. Terwijl de ene omgeving live verkeer afhandelt, wordt de andere gebruikt om de volgende release te testen. Blue-green deployment maakt eenvoudige terugrolacties en updates zonder downtime mogelijk, omdat verkeer direct tussen de twee omgevingen kan worden omgeschakeld.
- Gefaseerde Releases: Bij deze strategie worden updates stapsgewijs uitgerold naar verschillende gebruikersgroepen of omgevingen. Dit begint vaak met interne omgevingen voordat productie wordt bereikt. Zo beperk je de reikwijdte van mogelijke problemen en kunnen teams issues in fasen aanpakken.
- Serverloze Implementatie Deze aanpak maakt gebruik van serverless platformen zoals AWS Fargate en Google Cloud Run, die het infrastructuurbeheer automatiseren door schaling en resourceverdeling voor je te regelen. Met serverless deployment hoef je geen onderliggende servers te beheren, zodat je je volledig op je microservices kunt richten.
Nadat je een van de bovenstaande deploymentstrategieën hebt gekozen, heb je een orkestratietool voor microservices nodig.
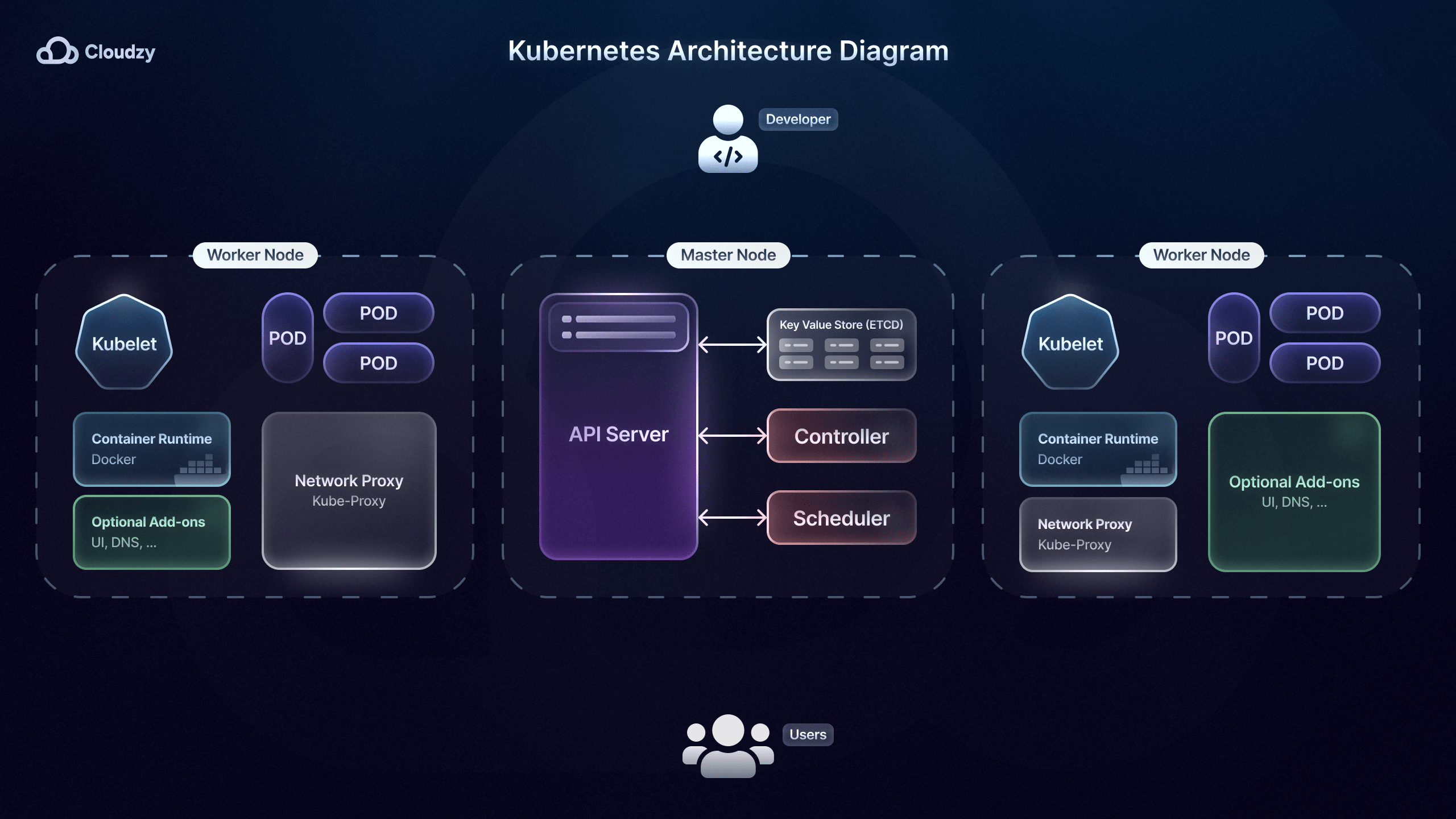
Microservices Orchestratie
Nadat je een deploymentstrategie voor microservices hebt gekozen, heb je een soort dirigent nodig voor de orkestratie. Orkestratietools voor microservices, zoals Kubernetes, helpen bij het automatiseren van de deployment, het schalen, het monitoren en het beheer van gecontaineriseerde microservices.
Airbnb gebruikt bijvoorbeeld Kubernetes, waarmee haar engineers honderden wijzigingen aan microservices kunnen deployen zonder handmatige tussenkomst. Een belangrijke functie van orkestratietools zoals Kubernetes is de ingebouwde load balancing.
Een goede load balancing-functie verdeelt inkomend verkeer over meerdere instanties van een microservice. Dit voorkomt dat één instantie een knelpunt wordt en verbetert het vermogen van het systeem om pieken in de vraag op te vangen.
Kubernetes speelt een centrale rol in het beheer van microservices dankzij de zelfherstellende mogelijkheden: mislukte containers worden automatisch vervangen en opnieuw gestart. The New York Times gebruikt deze functie om zijn microservices te onderhouden zonder de gebruikerservaring te verstoren of downtime te veroorzaken.
Daarnaast verbetert Kubernetes de beveiliging van microservices door configuraties en geheimen, zoals databasereferenties of API-sleutels, te beheren via ConfigMaps en Secrets. Dit is vooral belangrijk voor bedrijven en diensten zoals Uber, die omgaan met gevoelige klant- en gebruikersgegevens.
Ten slotte zijn orkestratietools zoals Kubernetes bijzonder nuttig voor strategieën met rolling updates en terugrolacties, zoals gefaseerde releases. Rolling updates maken het mogelijk nieuwe microserviceversies te deployen zonder serviceonderbrekingen, doordat een deel van de instanties van de oude versie actief blijft.
Nadat je je orkestratietool voor microservices hebt ingesteld, moet je CI/CD-pijplijnen voor de deployment van microservices bouwen en automatiseren.
CI/CD-pipelines voor de deployment van microservices
Zoals eerder besproken, zijn Continuous Integration- en Continuous Delivery-pipelines een belangrijk onderdeel van de deployment van microservices. De CD-pipelines zijn verantwoordelijk voor het automatisch deployen van codewijzigingen naar productie zodra ze de test- en integratiefasen van de CI/CD-pipeline hebben doorlopen.
Vervolgens zorgt het CD-gedeelte van de CI/CD-pipeline ervoor dat zodra codewijzigingen de test- en integratiefasen doorstaan, de service wordt gedeployed naar een orkestratietool zoals een Kubernetes-cluster.
Bovendien worden de test- en integratiefasen volledig automatisch uitgevoerd door de CI/CD-pipeline, waarbij unit tests, integratietests en end-to-end tests in de pipeline zijn opgenomen.
Zo kunnen teams updates in elke fase valideren terwijl de systeemstabiliteit gewaarborgd blijft. Als er toch problemen zijn met codewijzigingen, kunnen geautomatiseerde terugrolacties de vorige stabiele versie herstellen.
Ten slotte helpt het implementeren van CI/CD-pipelines voor microservices volgens de best practices organisaties om sneller te ontwikkelen, handmatige fouten te verminderen en consistente kwaliteitsnormen te handhaven.
Veel bedrijven zoals Spotify, Expedia, iRobot, Lufthansa en Pandora gebruiken CI/CD-pipelines voor microservices via tools als CircleCI, AWS CodePipeline en GitLab om deploymentprocessen te automatiseren, consistente codekwaliteit te waarborgen en nieuwe functies snel uit te rollen zonder de systeemstabiliteit in gevaar te brengen.
Communicatiepatronen voor microservices
Hoe microservices onderling communiceren hangt volledig af van de functie, de algehele architectuur, de gewenste schaalbaarheid en de betrouwbaarheid van je microservices. Over het algemeen worden er twee hoofdtypen communicatiepatronen gebruikt: synchroon en asynchrone communicatiepatronen voor microservices.
Bij synchrone communicatiepatronen voor microservices communiceren services in real time: een service stuurt een verzoek en wacht op een antwoord voordat hij verdergaat. De meest gebruikte synchrone communicatiepatronen zijn REST (Representational State Transfer) API's, gRPC (Google Remote Procedure Call), en GraphQL.
Dit soort synchrone communicatiepatronen voor microservices wordt doorgaans toegepast in sectoren en door bedrijven die real-time gegevensverwerking en directe reacties vereisen. Sectoren zoals financiën, zorg en e-commerce maken vaak gebruik van synchrone communicatiepatronen om transacties, gegevensopvraging en gebruikersinteracties direct te laten plaatsvinden, wat zorgt voor een vloeiende gebruikerservaring.
Hoewel synchrone communicatiepatronen voor microservices voordelen bieden zoals real-time reacties en eenvoud, kleven er ook nadelen aan: mogelijke knelpunten door sterke koppeling, beperkte schaalbaarheid onder hoge belasting, trage reactietijden en hoge latentie bij piekverkeer.
Asynchrone communicatiepatronen voor microservices zijn daarentegen doorgaans beter geschikt voor microservices, omdat ze gebaseerd zijn op het principe van losse koppeling dat we eerder hebben besproken.
Dit type communicatiepatroon ontkoppelt services door hen berichten te laten uitwisselen via een broker zoals Kafka of RabbitMQ. Door berichten naar een wachtrij te sturen die als buffer fungeert, communiceren services onafhankelijk van elkaar, zonder te wachten op een antwoord zoals bij synchrone communicatiepatronen. Die buffer stelt andere services in staat berichten in hun eigen tempo te verwerken, zodat de afzender door kan gaan met zijn werk zonder op de ontvanger te wachten.
Het asynchrone communicatiepatroon voor microservices biedt niet alleen een ontkoppelde structuur voor de deployment van microservices, maar levert ook dezelfde real-time respons als synchrone communicatiepatronen.
Dit is te danken aan de event-driven architectuur van asynchrone, event-driven communicatiepatronen voor microservices: services communiceren door events uit te sturen wanneer een specifieke actie plaatsvindt. Andere services kunnen op die events inschrijven en er direct op reageren. Dit maakt systemen mogelijk die in real time op wijzigingen reageren, zonder directe koppeling tussen services.
Bovendien, in asynchrone Publiceren-Abonneren (Pub/Sub) bij communicatiepatronen voor microservices sturen services (publishers) berichten naar een topic, waarna andere services (subscribers) dat topic volgen om updates te ontvangen. Dit model ondersteunt meerdere subscribers en kan berichten tegelijkertijd naar vele services uitzenden.
Tot slot maken asynchrone choreografie-gebaseerde saga communicatiepatronen voor microservices eveneens gebruik van events om onderling te communiceren. In dit patroon geldt echter een vaste volgorde: events activeren de volgende stap en de bijbehorende service.
Het verschil met event-driven patronen is dat daarin geen vaste volgorde of workflow bestaat: meerdere services kunnen op een event reageren, in plaats van het specifieke proces en de vaste volgorde die gelden in het choreography-based saga-patroon.
Welk asynchroon communicatiepatroon voor microservices je gebruikt, hangt af van de taak en de algehele functie van je microservices. Berichtenwachtrijen zoals RabbitMQ en Amazon SQS worden doorgaans ingezet voor taakplanning, werklastdistributie en orderverwerking en notificatiesystemen in e-commerce.
Event-driven message brokers zoals Apache Kafka en AWS EventBridge worden doorgaans gebruikt voor het verwerken van grootschalige eventstromen in real time en voor eventroutering tussen microservices in sectoren als financiële dienstverlening en AWS-omgevingen.
Publish-Subscribe (Pub/Sub) message brokers zoals Google Cloud Pub/Sub en Redis Streams worden gewoonlijk ingezet voor schaalbaar berichtenverkeer in gedistribueerde systemen, real-time analyses, event-ingestie en real-time notificaties en chatapplicaties.
Choreography-based saga message brokers worden voornamelijk gebruikt voor orderverwerking in e-commerce, boekingssystemen voor reizen en situaties waarbij complexe, meerstappentransacties over meerdere services gecoördineerd moeten worden zonder centrale aansturing.
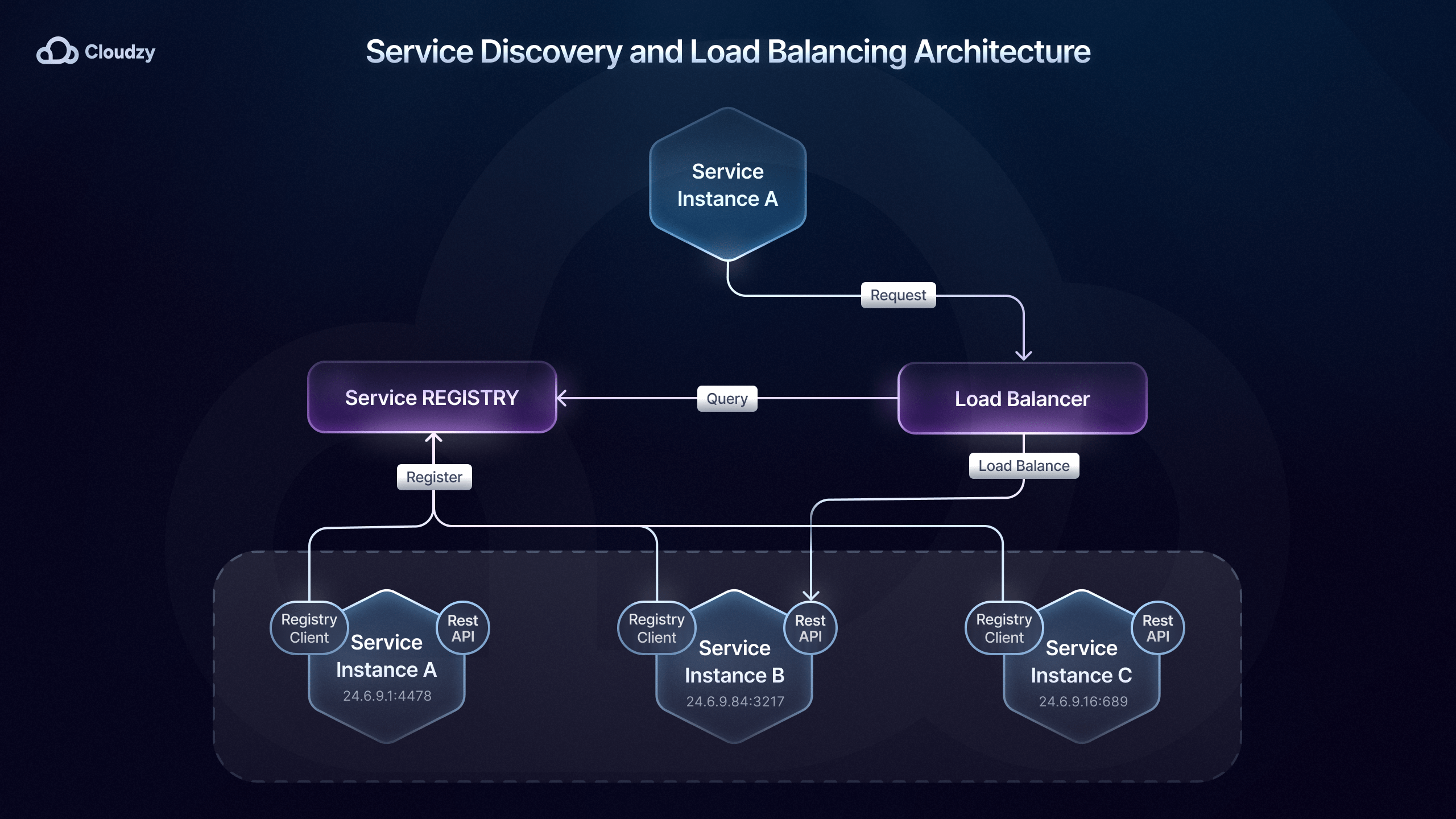
Service discovery voor microservices
Zodra je een communicatiepatroon hebt opgezet dat bij je behoeften past, moet je ervoor zorgen dat je services elkaar überhaupt kunnen vinden. Zoals eerder vermeld, spelen microservices-orkestratietools zoals Kubernetes een belangrijke rol bij service discovery binnen microservices.
Dit gebeurt via de ingebouwde service discovery van Kubernetes DNS, die IP-adressen en DNS-records dynamisch bijwerkt wanneer services opschalen of van locatie wisselen binnen het cluster.
Deze methode van service discovery heet server-side discovery, omdat de routeringsverantwoordelijkheid wordt overgedragen aan een load balancer, die vervolgens het register raadpleegt en verkeer naar de juiste instantie stuurt.
Daarnaast bestaat ook de client-side discovery-methode, waarbij de service of API-gateway een serviceregister zoals Consul of Eureka raadpleegt om beschikbare instanties te vinden.
Welke methode van service discovery het beste past bij je microservices-deployment hangt af van de eisen en schaal van het systeem.
Bij client-side service discovery heeft de client volledige controle over met welke instantie hij communiceert. Dit biedt meer maatwerk en vermindert tegelijkertijd de complexiteit, omdat er geen centrale discovery-service nodig is.
Zo gebruikt Netflix's microservices-deployment client-side service discovery met Eureka en Ribbon voor load balancing, waardoor de client de beste instantie kan kiezen op basis van criteria zoals latentie en serverbelasting.
Server-side service discovery is echter beter geschikt voor grotere omgevingen, omdat een centrale service discovery de efficiëntie verhoogt en consistente load balancing mogelijk maakt binnen een gedistribueerd systeem.
Server-side service discovery-oplossingen zoals Kubernetes, AWS Elastic Load Balancing en API Gateways (Kong, NGINX, enzovoort) zorgen voor efficiënte verkeersrouting en hoge beschikbaarheid. Bedrijven als Airbnb, Pinterest, Expedia en Lyft maken er gebruik van.
Microservice Beveiliging
Hoewel monolithische architectuur op de meeste vlakken onderdoet voor MSA, had monolithische architectuur traditioneel een voordeel op het gebied van beveiliging. Omdat microservices gebaseerd zijn op het principe van losse koppeling en van nature gedistribueerd zijn, is één overkoepelende beveiligingsmaatregel niet toepasbaar.
Omdat elke service afzonderlijk beveiligd moet worden, zijn extra maatregelen noodzakelijk: het aanvalsoppervlak is bij microservices aanzienlijk groter. Standaarden zoals OAuth2 en JSON Web Tokens (JWT) worden dan ook veelvuldig ingezet voor authenticatie en autorisatie.
Daarnaast wordt vaak een API-gateway ingezet om beveiliging binnen microservices te beheren, doordat authenticatie en autorisatie al op het toegangspunt worden afgedwongen. Bovendien kunnen API-gateways ook rate limiting, logging en monitoring toepassen, wat extra beveiligingslagen oplevert.
Hoewel dit het belangrijkste toegangspunt beveiligt, zijn er aanvullende beveiligingsmaatregelen nodig voor communicatie tussen services onderling.
Hier komen service meshes van pas: ze voegen een netwerkbeveiligingslaag toe, versleutelen verkeer tussen services en dwingen beleid af zoals wederzijdse TLS. Deze service meshes zorgen in feite voor end-to-end-encryptie die de beveiliging van microservices aanzienlijk versterkt.
Microservice Schaling
Een van de grootste voordelen van MSA, en de reden waarom het werd ontwikkeld als alternatief voor monolithische architectuur, is de hoge schaalbaarheid. Microservices kunnen doorgaans op twee manieren worden opgeschaald: verticaal en horizontaal.
Verticaal opschalen (scaling up) houdt in dat je meer resources toevoegt aan een bestaande instantie, zoals extra CPU of geheugen. Horizontaal opschalen (scaling out) verdeelt de belasting en vergroot de capaciteit door nieuwe instanties toe te voegen.
Wat implementatie betreft is verticaal opschalen de eenvoudigere optie: je past één instantie aan door over te stappen op een grotere server, meer geheugen of rekenkracht toe te voegen aan een cloud-instantie, of extra opslag toe te voegen.
Dit type opschaling wordt doorgaans toegepast wanneer meer RAM- of CPU-capaciteit de queryprestaties en gegevensverwerking verbetert, zoals bij services die verantwoordelijk zijn voor in-memory caching.
Verticaal opschalen is eenvoudiger en levert direct prestatieverbetering op, maar kent ook nadelen. De schaalbaarheid is begrensd door de hardwarecapaciteit van de server, waardoor je op een gegeven moment moet overstappen op horizontaal opschalen om verder te groeien.
Bovendien brengt verticaal opschalen hoge kosten met zich mee, want grotere hardware en instanties hebben doorgaans een stevig prijskaartje. En als de opgeschaalde instantie uitvalt, gaat de service volledig offline: er zijn geen andere instanties om de belasting over te nemen.
Bij horizontaal opschalen upgrade je niet de resources van één instantie, maar deploy je nieuwe instanties van die service. Die instanties werken onafhankelijk van elkaar, maar verwerken dezelfde service en delen dezelfde werklast.
Anders dan verticaal opschalen kent horizontaal opschalen geen bovengrens: je kunt zoveel instanties toevoegen als nodig om groeiende werklasten en verkeerspieken op te vangen, wat aanzienlijk meer schaalbaarheid biedt.
Bovendien geldt: als één instantie uitvalt, leg je niet alles op één paard, want andere instanties blijven verzoeken verwerken. Op de lange termijn is horizontaal opschalen ook veel kostenefficiënter, omdat je meerdere kleinere en goedkopere instanties kunt combineren tot een betrouwbaardere en krachtigere geheel.
Horizontaal opschalen en het toevoegen van meer instanties vereisen echter ook meer load balancers, service discovery-mechanismen en orkestratietools, wat de microservices-architectuur aanzienlijk complexer maakt.
Horizontaal opschalen is het meest geschikt voor webservices en applicaties zoals e-commerceplatforms of sociale media, die vaak te maken hebben met wisselend verkeer en een hoog volume aan verzoeken.
Dat gezegd hebbende, is het geen kwestie van óf-óf: beide vormen van schalen worden ondersteund binnen microservices en zijn in veel situaties noodzakelijk. Kleinere organisaties kiezen doorgaans voor verticaal schalen, omdat dit eenvoudiger te implementeren en te beheren is. Naarmate de applicatie groeit, wordt horizontaal schalen geïntroduceerd om de toegenomen vraag aan te kunnen.
Tot slot bieden cloudplatforms auto-scaling-diensten die automatisch instanties toevoegen of verwijderen op basis van de actuele vraag. Dit helpt organisaties aanzienlijk om verticaal en horizontaal schalen in balans te houden.
Microservice-monitoring
Op dit punt is je microservices-deployment vrijwel afgerond. Wat overblijft, is zorgen dat alles consistent en betrouwbaar werkt. Hier komen monitoring-tools voor microservices om de hoek kijken, zoals Prometheus en Grafana stap in.
Deze tools bieden realtime inzicht in servicestatistieken, zodat teams het resourcegebruik, de latency en foutpercentages kunnen bijhouden. Daarnaast ondersteunen ze distributed tracing (Jaeger, Zipkin, etc.), waarmee je request-flows door services heen visualiseert. Dit is enorm waardevol bij het opsporen van problemen.
Omdat storingen zich door het gedistribueerde karakter van microservices als een kettingreactie kunnen verspreiden, is log-aggregatie een essentieel onderdeel van microservice-monitoring. Door logs samen te brengen in een centraal platform en realtime meldingen in te stellen, blijf je problemen altijd voor en kun je proactief ingrijpen voordat gebruikers er last van hebben.
Slotgedachten
Microservices zijn zeker geen eenvoudig onderwerp, maar als je de basisprincipes en de belangrijkste stappen van microservices-deployment begrijpt, wordt het gehele proces een stuk behapbaarder. Bovendien komen er met de jaren steeds meer tools beschikbaar met meer mogelijkheden, waardoor microservices-deployment toegankelijker wordt dan ooit.
Veelgestelde vragen
Welke deployment-strategieën worden vaak gebruikt voor microservices?
Er zijn veel verschillende strategieën voor microservices-deployment. De meest gebruikte zijn: service instances per container, gefaseerde releases, blue-green deployment en serverless deployment. Elke strategie biedt een andere mate van isolatie, flexibiliteit en schaalbaarheid.
Welke rol speelt Kubernetes bij het orkestreren van microservices?
Microservices zijn afhankelijk van orkestratietools zoals Kubernetes om de deployment te automatiseren en containerized services te schalen en te beheren. Kubernetes biedt load balancing, auto-scaling en self-healing, zodat microservices betrouwbaar en efficiënt blijven draaien.
Hoe zorg ik voor beveiliging in een microservices-omgeving?
Door hun gedistribueerde opzet is beveiliging bij microservices complexer dan bij monolithische architectuur. Beveiliging binnen microservices omvat het authenticeren en autoriseren van verzoeken, het versleutelen van communicatie tussen services, en het implementeren van API-gateways en service meshes zoals Istio voor centraal beveiligingsbeheer.


