
Jednym z najważniejszych, jeśli nie najważniejszym, aspektów uczenia maszynowego jest uzyskiwanie dokładnych i wiarygodnych prognoz. Innowacyjnym podejściem do tego celu, które zyskało szerokie uznanie, jest Bootstrap Aggregating, powszechnie znany jako bagging w uczeniu maszynowym. W tym artykule omówimy bagging w uczeniu maszynowym, porównamy bagging i boosting, przedstawimy przykład klasyfikatora baggingowego, wyjaśnimy jak działa bagging oraz przeanalizujemy jego zalety i ograniczenia.
Czym jest bagging w uczeniu maszynowym?
To jedyne dwa istotne obrazy używane w popularnych artykułach. Jeden lub oba mogą zostać użyte (jeden tutaj, drugi w innym miejscu), jeśli Design przygotuje ich wersje w stylu Cloudzy.
Czym jest bagging?
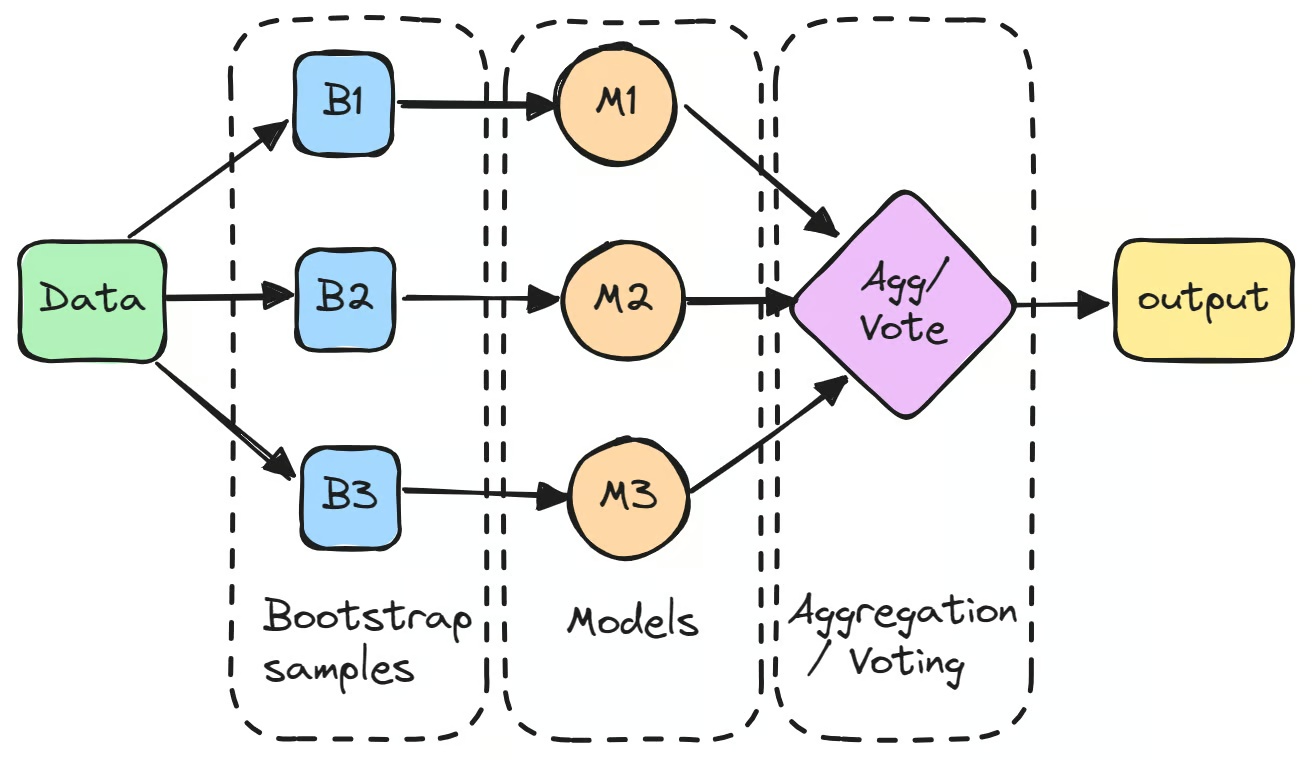
Wyobraź sobie, że próbujesz zgadnąć wagę przedmiotu, pytając wiele osób o ich szacunki. Indywidualnie odpowiedzi mogą się znacznie różnić, ale uśredniając wszystkie wyniki, uzyskasz bardziej wiarygodną wartość. Na tym właśnie polega bagging: łączeniu wyników wielu modeli w celu uzyskania dokładniejszej i bardziej spójnej prognozy.
Proces rozpoczyna się od stworzenia wielu podzbiorów oryginalnego zbioru danych metodą bootstrappingu, czyli losowego próbkowania z powtórzeniami. Każdy podzbiór służy do niezależnego trenowania osobnego modelu.
Poszczególne modele, często określane jako „słabe uczące się", mogą samodzielnie nie osiągać wysokiej skuteczności ze względu na dużą wariancję. Jednak gdy ich prognozy są agregowane, zazwyczaj poprzez uśrednianie w zadaniach regresji lub głosowanie większościowe w zadaniach klasyfikacji, łączny wynik często przewyższa skuteczność każdego pojedynczego modelu.
Klasycznym przykładem klasyfikatora opartego na baggingu jest algorytm Random Forest, który buduje zespół drzew decyzyjnych w celu poprawy jakości predykcji. Warto jednak odróżnić bagging od boostingu w uczeniu maszynowym: boosting trenuje modele sekwencyjnie, aby zmniejszyć obciążenie (bias), natomiast bagging trenuje modele równolegle, aby zmniejszyć wariancję.
Bagging i boosting w uczeniu maszynowym mają ten sam cel - poprawę jakości modelu - ale działają na różnych aspektach jego zachowania.
Dlaczego bagging jest przydatny?
Jedną z głównych zalet baggingu w uczeniu maszynowym jest redukcja wariancji, dzięki czemu modele lepiej generalizują na nowych danych. Bagging sprawdza się szczególnie dobrze w przypadku algorytmów wrażliwych na wahania w danych treningowych, takich jak drzewa decyzyjne.
Zapobiegając przeuczeniu, bagging zapewnia stabilniejszy i bardziej przewidywalny model. Porównując bagging i boosting w uczeniu maszynowym: bagging koncentruje się na redukcji wariancji przez równoległe trenowanie wielu modeli, podczas gdy boosting dąży do redukcji obciążenia przez trenowanie modeli sekwencyjnie.
Przykładem zastosowania baggingu w uczeniu maszynowym jest prognozowanie ryzyka finansowego, gdzie wiele drzew decyzyjnych trenuje się na różnych podzbiorach historycznych danych rynkowych. Agregując ich predykcje, bagging tworzy bardziej wiarygodny model prognozowania, ograniczając wpływ błędów pojedynczych modeli.
W skrócie: bagging w uczeniu maszynowym wykorzystuje zbiorową wiedzę wielu modeli, dostarczając predykcje dokładniejsze i bardziej wiarygodne niż te pochodzące z pojedynczego modelu.
Jak działa bagging w uczeniu maszynowym: krok po kroku
Aby w pełni zrozumieć, jak bagging poprawia jakość modelu, prześledźmy ten proces krok po kroku.
Pobieranie wielu próbek bootstrap z zestawu danych
Pierwszym krokiem baggingu w uczeniu maszynowym jest utworzenie wielu podzbiorów oryginalnego zestawu danych za pomocą bootstrappingu. Technika ta polega na losowym próbkowaniu danych ze zwracaniem, dlatego niektóre punkty danych mogą pojawić się wielokrotnie w tym samym podzbiorze, a inne mogą w nim nie wystąpić wcale. Dzięki temu każdy model trenuje się na nieco innej wersji danych.
Trenowanie oddzielnego modelu na każdej próbce
Każda próbka bootstrap służy do wytrenowania osobnego modelu, zazwyczaj tego samego typu, na przykład drzewa decyzyjnego. Te modele, często nazywane "bazowymi uczącymi" lub "słabymi uczącymi", trenowane są niezależnie na swoich odpowiednich podzbiorach. Przykładem klasyfikatora baggingowego jest drzewo decyzyjne stosowane w algorytmie Random Forest, które stanowi podstawę wielu modeli opartych na baggingu. Choć każdy model z osobna może nie osiągać wysokiej skuteczności, każdy wnosi unikalne spostrzeżenia wynikające ze swoich danych treningowych.
Agregacja predykcji
Po wytrenowaniu modeli ich predykcje są agregowane w celu uzyskania końcowego wyniku.
- W zadaniach regresji predykcje są uśredniane, co redukuje wariancję modelu.
- W zadaniach klasyfikacji ostateczna predykcja wyłaniana jest przez głosowanie większościowe, gdzie wybierana jest klasa wskazana przez największą liczbę modeli. Metoda ta daje stabilniejszą predykcję niż wynik pojedynczego modelu.
Prognoza końcowa
Łącząc predykcje wielu modeli, bagging ogranicza wpływ błędów dowolnego pojedynczego modelu, poprawiając ogólną dokładność. Właśnie ten proces agregacji sprawia, że bagging jest tak skuteczną techniką, szczególnie w zadaniach uczenia maszynowego, gdzie stosuje się modele o wysokiej wariancji, takie jak drzewa decyzyjne. Efektywnie wygładza on niespójności w predykcjach poszczególnych modeli, dając silniejszy model końcowy.
Choć bagging skutecznie stabilizuje predykcje, warto pamiętać o kilku kwestiach: istnieje ryzyko przeuczenia, jeśli modele bazowe są zbyt złożone, mimo że redukcja przeuczenia jest ogólnym celem baggingu.
Metoda jest też obliczeniowo kosztowna, dlatego warto dostosować liczbę modeli bazowych lub rozważyć bardziej wydajne metody zespołowe, a ponadto wybór odpowiedniego GPU dla ML i DL jest zawsze ważne.
Zadbaj o zróżnicowanie modeli bazowych, co przekłada się na lepsze wyniki. Jeśli pracujesz z niezbalansowanymi danymi, przed zastosowaniem baggingu warto sięgnąć po techniki takie jak SMOTE, aby uniknąć słabej skuteczności na klasach mniejszościowych.
Zastosowania Baggingu
Skoro wiemy już, jak działa bagging, czas przyjrzeć się jego rzeczywistym zastosowaniom. Bagging znalazł zastosowanie w wielu branżach, pomagając poprawić dokładność i stabilność predykcji w złożonych scenariuszach. Przyjrzyjmy się bliżej najbardziej istotnym obszarom jego zastosowania:
- Klasyfikacja i regresja: Bagging jest powszechnie stosowany do poprawy jakości klasyfikatorów i regresorów przez redukcję wariancji i zapobieganie przeuczeniu. Na przykład Random Forests, które korzystają z baggingu, sprawdzają się w takich zadaniach jak klasyfikacja obrazów i modelowanie predykcyjne.
- Wykrywanie anomalii: W obszarach takich jak wykrywanie oszustw czy wykrywanie włamań sieciowych algorytmy baggingu osiągają lepsze wyniki, skutecznie identyfikując wartości odstające i anomalie w danych.
- Ocena ryzyka finansowego: Techniki baggingu są stosowane w bankowości do udoskonalania modeli scoringu kredytowego, zwiększając dokładność procesów przyznawania kredytów i oceny ryzyka finansowego.
- Diagnostyka Medyczna: W medycynie bagging znalazł zastosowanie w wykrywaniu zaburzeń neurokognitywnych, takich jak choroba Alzheimera, poprzez analizę zbiorów danych MRI, wspierając wczesną diagnostykę i planowanie leczenia.
- Przetwarzanie języka naturalnego (NLP): Bagging wspiera zadania takie jak klasyfikacja tekstu i analiza sentymentu, agregując przewidywania wielu modeli i prowadząc do dokładniejszego rozumienia języka.
Zalety i wady baggingu
Jak każda technika uczenia maszynowego, bagging ma swoje zalety i wady. Zrozumienie ich pomaga ocenić, kiedy i jak stosować bagging w swoich modelach.
Zalety Baggingu:
- Redukcja wariancji i przeuczenia: Jedną z najważniejszych zalet baggingu w uczeniu maszynowym jest zdolność do redukcji wariancji, co zapobiega przeuczeniu. Trenując wiele modeli na różnych podzbiorach danych, bagging sprawia, że model nie staje się nadmiernie wrażliwy na wahania w danych treningowych, co przekłada się na bardziej ogólny i stabilny model.
- Skuteczność przy modelach o wysokiej wariancji: Bagging sprawdza się szczególnie dobrze w połączeniu z modelami o wysokiej wariancji, takimi jak drzewa decyzyjne. Modele te mają tendencję do przeuczania się i charakteryzują się wysoką wariancją, jednak bagging łagodzi ten problem poprzez uśrednianie wyników lub głosowanie wielu modeli. Dzięki temu przewidywania są bardziej wiarygodne i mniej podatne na szum w danych.
- Lepsza stabilność i wydajność modelu: Łącząc wiele modeli trenowanych na różnych podzbiorach danych, bagging często przekłada się na lepszą ogólną wydajność. Poprawia dokładność predykcji, jednocześnie zmniejszając wrażliwość modelu na niewielkie zmiany w zbiorze danych, co ostatecznie czyni go bardziej niezawodnym.
Wady Baggingu:
- Wyższy koszt obliczeniowy: Ponieważ bagging wymaga trenowania wielu modeli, naturalnie zwiększa koszt obliczeniowy. Trenowanie i agregowanie przewidywań z wielu modeli może być czasochłonne, szczególnie przy dużych zbiorach danych lub złożonych modelach, takich jak drzewa decyzyjne.
- Ograniczona skuteczność dla modeli o niskiej wariancji: Choć bagging jest bardzo skuteczny dla modeli o wysokiej wariancji, nie przynosi większych korzyści w przypadku modeli o niskiej wariancji, takich jak regresja liniowa. W tych przypadkach poszczególne modele mają już niskie błędy, więc agregowanie przewidywań niewiele poprawia wyniki.
- Utrata interpretowalności: Łącząc wiele modeli, bagging może obniżać interpretowalność modelu końcowego. Na przykład w Random Forest proces podejmowania decyzji opiera się na wielu drzewach decyzyjnych, co utrudnia prześledzenie rozumowania stojącego za konkretną predykcją.
Kiedy stosować bagging?
Wiedza o tym, kiedy stosować bagging w projektach uczenia maszynowego, jest kluczowa dla osiągnięcia optymalnych wyników. Technika ta sprawdza się w określonych sytuacjach, ale nie zawsze jest najlepszym wyborem dla każdego problemu.
Gdy twój model jest podatny na przeuczenie
Jednym z głównych przypadków użycia baggingu jest sytuacja, gdy model jest podatny na przeuczenie, szczególnie w przypadku modeli o wysokiej wariancji, takich jak drzewa decyzyjne. Modele te mogą dobrze radzić sobie na danych treningowych, ale często nie generalizują dobrze na nowych danych, ponieważ zbyt ściśle dopasowują się do konkretnych wzorców zbioru treningowego.
Bagging pomaga z tym walczyć, trenując wiele modeli na różnych podzbiorach danych, a następnie uśredniając wyniki lub stosując głosowanie, by uzyskać bardziej stabilną predykcję. Zmniejsza to ryzyko przeuczenia i sprawia, że model lepiej radzi sobie z nowymi, niewidzianymi wcześniej danymi.
Kiedy chcesz poprawić stabilność i dokładność
Jeśli chcesz zwiększyć stabilność i dokładność modelu bez nadmiernego poświęcania interpretowalności, bagging to doskonały wybór. Agregacja predykcji z wielu modeli wzmacnia końcowy wynik, co jest szczególnie przydatne przy pracy z zaszumionymi danymi.
Niezależnie od tego, czy rozwiązujesz problemy klasyfikacji, czy zadania regresji, bagging pomaga uzyskiwać spójniejsze wyniki, podnosząc dokładność przy zachowaniu efektywności.
Kiedy masz wystarczające zasoby obliczeniowe
Kolejnym istotnym czynnikiem przy decyzji o zastosowaniu baggingu jest dostępność zasobów obliczeniowych. Ponieważ bagging wymaga jednoczesnego trenowania wielu modeli, koszty obliczeniowe mogą być znaczące, szczególnie przy dużych zbiorach danych lub złożonych modelach.
Jeśli masz dostęp do odpowiedniej mocy obliczeniowej, korzyści z baggingu zdecydowanie przewyższają koszty. Jeśli jednak zasoby są ograniczone, warto rozważyć alternatywne techniki lub zmniejszyć liczbę modeli w zespole.
Kiedy pracujesz z modelami o wysokiej wariancji
Bagging jest szczególnie przydatny przy pracy z modelami o wysokiej wariancji, wrażliwymi na wahania w danych treningowych. Drzewa decyzyjne, na przykład, często są używane z baggingiem w postaci lasów losowych, ponieważ ich wydajność mocno zależy od danych treningowych.
Trenując wiele modeli na różnych podzbiorach danych i łącząc ich predykcje, bagging wygładza wariancję, prowadząc do bardziej niezawodnego modelu.
Kiedy potrzebujesz niezawodnego klasyfikatora
Jeśli pracujesz nad problemami klasyfikacji i potrzebujesz niezawodnego klasyfikatora, bagging może znacznie poprawić stabilność predykcji. Las losowy, będący przykładem klasyfikatora baggingowego, może dostarczać dokładniejsze predykcje poprzez agregację wyników wielu pojedynczych drzew decyzyjnych.
To podejście sprawdza się, gdy pojedyncze modele mogą być słabe, ale ich połączona siła daje solidny model końcowy.
Dodatkowo, jeśli szukasz odpowiedniej platformy do efektywnego wdrażania technik baggingowych, narzędzia takie jak Databricks i Snowflake oferują ujednoliconą platformę analityczną, która może być bardzo pomocna przy zarządzaniu dużymi zbiorami danych i uruchamianiu metod zespołowych, takich jak bagging.
Jeśli szukasz mniej technicznego podejścia do uczenia maszynowego, narzędzia AI bez kodu może być również opcją. Choć nie skupiają się bezpośrednio na zaawansowanych technikach jak bagging, wiele platform no-code pozwala użytkownikom eksperymentować z metodami zespołowymi, w tym baggingiem, bez potrzeby zaawansowanych umiejętności programistycznych.
Dzięki temu możesz stosować bardziej zaawansowane techniki i uzyskiwać dokładne predykcje, skupiając się na wydajności modelu, a nie na samym kodzie.
Podsumowanie
Bagging w uczeniu maszynowym to skuteczna technika poprawiająca działanie modeli przez redukcję wariancji i zwiększenie stabilności. Agregując predykcje wielu modeli trenowanych na różnych podzbiorach danych, bagging pomaga uzyskiwać dokładniejsze i bardziej niezawodne wyniki. Jest szczególnie efektywny dla modeli o wysokiej wariancji, takich jak drzewa decyzyjne, gdzie zapobiega przeuczeniu i sprawia, że model lepiej generalizuje na nowych danych.
Choć bagging ma istotne zalety, takie jak redukcja przeuczenia i poprawa dokładności, wiąże się też z pewnymi kompromisami. Zwiększa koszty obliczeniowe ze względu na trenowanie wielu modeli i może obniżać interpretowalność. Mimo tych wad, jego zdolność do poprawy wydajności czyni go cenną techniką w uczeniu zespołowym, obok innych metod, takich jak boosting i stacking.
Czy stosowałeś bagging w projektach uczenia maszynowego? Podziel się swoim doświadczeniem i opisz, jak sprawdził się w praktyce!


