
Bir GPU VPS seçmek, önünüzde sayılarla dolu teknik özellik sayfaları durduğunda bunaltıcı gelebilir. Çekirdek sayıları 2.560'tan 21.760'a kadar çıkıyor, peki bu ne anlama geliyor?
CUDA çekirdeği, NVIDIA GPU'lerin içindeki paralel işlem birimidir; binlerce hesaplamayı aynı anda yürüterek AI eğitiminden 3D görüntü işlemeye kadar her şeyi destekler. Bu rehber, CUDA çekirdeklerinin nasıl çalıştığını, CPU ve Tensor çekirdeklerinden nasıl ayrıldığını ve ihtiyacınıza fazla ödeme yapmadan hangi çekirdek sayısının uygun olduğunu açıklıyor.
CUDA çekirdekleri nedir?

CUDA çekirdekleri, NVIDIA GPU'lerin içinde talimatları paralel olarak yürüten bağımsız işlem birimleridir. CUDA çekirdeği teknolojisinin özüne bakacak olursak: bu birimleri, aynı işin farklı parçalarını aynı anda üstlenen küçük işçiler gibi düşünebilirsiniz.
NVIDIA, CUDA'yı (Compute Unified Device Architecture) 2006 yılında GPU gücünü grafiklerin ötesinde genel amaçlı hesaplama için kullanmak amacıyla tanıttı. resmi CUDA belgeleri kapsamlı teknik ayrıntılar sunmaktadır. Her birim, kayan noktalı sayılar üzerinde temel aritmetik işlemler gerçekleştirir; bu da onu tekrarlı hesaplamalar için ideal kılar.
Modern NVIDIA GPU'ler bu birimlerden binlercesini tek bir çipe sığdırıyor. Son nesil tüketici GPU'leri 21.000'den fazla çekirdek barındırırken Hopper mimarisine dayanan veri merkezi GPU'leri 16.896'ya kadar çekirdek içeriyor. Bu birimler, Akış Çok İşlemcileri (SM'ler) aracılığıyla birlikte çalışır.
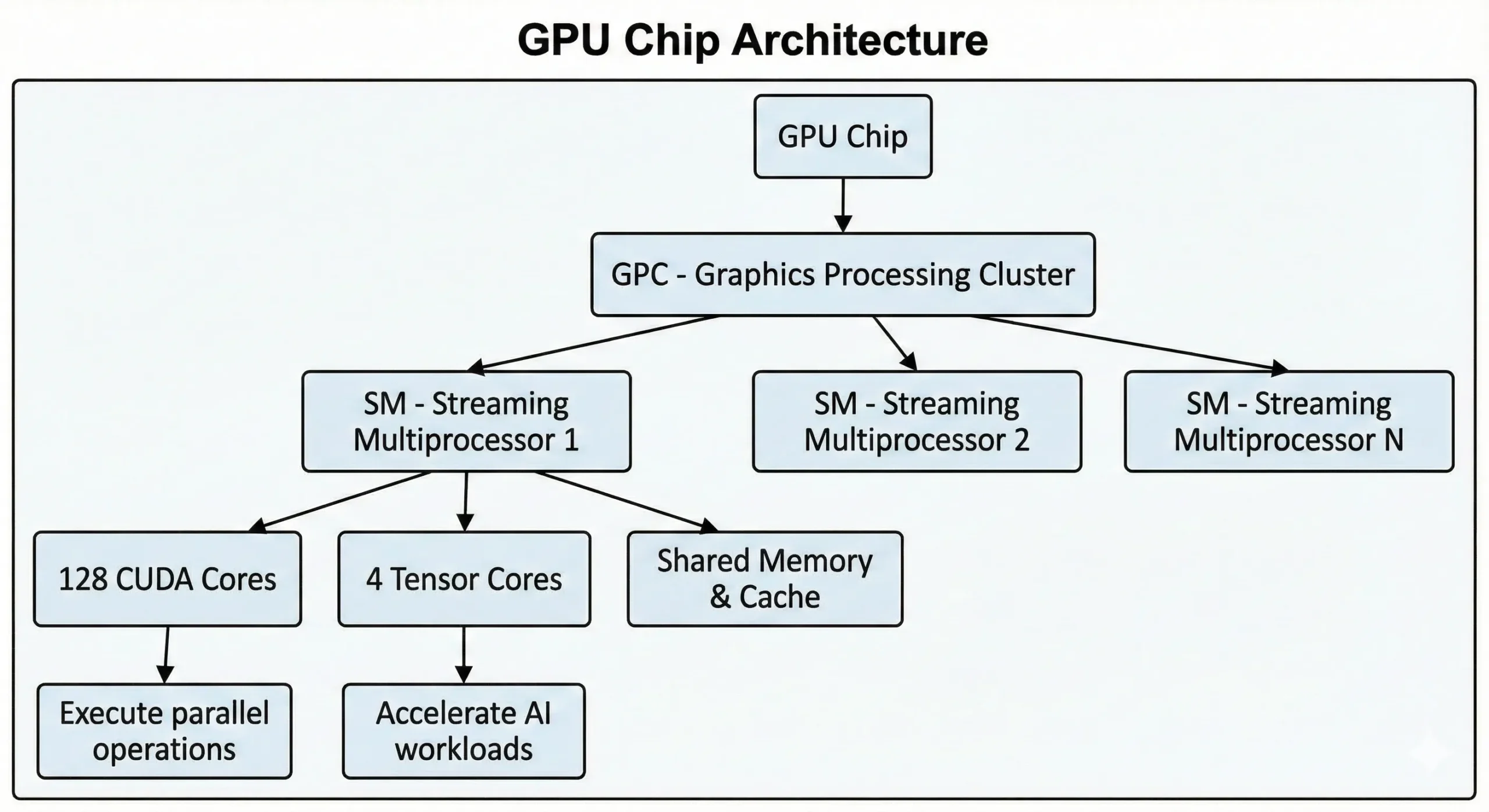
Birimler, paralel hesaplama yöntemleriyle SIMT (Single Instruction, Multiple Threads) işlemleri yürütür. Tek bir talimat, aynı anda birçok veri noktasında çalıştırılır. Sinir ağlarını eğitirken ya da 3D sahneleri işlerken binlerce benzer işlem gerçekleşir. Bu iş yükü eş zamanlı akışlara bölünür ve sırayla değil, paralel olarak yürütülür.
CUDA Çekirdekleri ile CPU Çekirdekleri: Aralarındaki Fark Nedir?

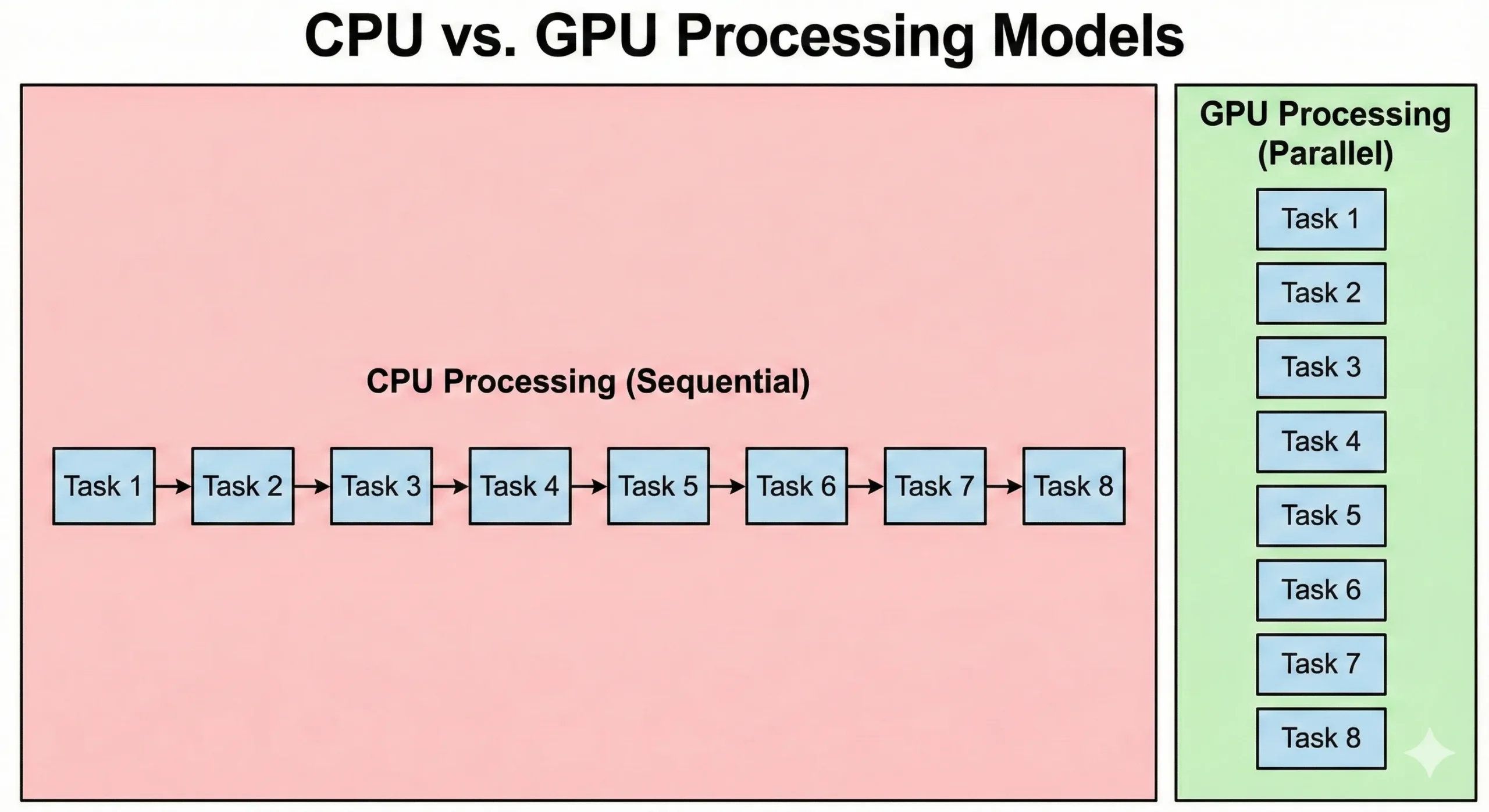
CPU'ler ve GPU'ler sorunları temelden farklı yaklaşımlarla çözer. Modern bir sunucu CPU'si, yüksek saat hızlarında çalışan 8-128 ve üzeri çekirdeğe sahip olabilir. Bu işlemciler, her adımın bir öncekinin sonucuna bağlı olduğu sıralı işlemlerde üstündür. Karmaşık mantık ve dallanma işlemlerini verimli biçimde yönetirler.
GPU'ler bu yaklaşımı tersine çevirir. Daha düşük saat hızlarında çalışan binlerce basit CUDA çekirdeğini bir araya getirirler. Bu birimler, düşük hızı paralellikle telafi eder. 16.000 birim birlikte çalıştığında toplam iş hacmi, standart bir CPU kapasitesini aşar.
CPU'ler işletim sistemi kodunu ve karmaşık uygulama mantığını yürütür. GPU'ler iş hacmini ön planda tutsa da görev başlatma ve senkronizasyon yükü daha yüksek gecikmeye yol açar. Paralel grafik işleme, veri aktarımını önceliklendirir. Başlamak daha uzun sürer ama büyük veri kümelerini CPU'lerden daha hızlı işlerler.
| Özellik | CPU Çekirdekleri | CUDA Çekirdekleri |
| Çip başına birim sayısı | 4 ile 128+ çekirdek | 2.560-21.760 çekirdek |
| İşlemci Hızı | 3,0-5,5 GHz | 1,4-2,5 GHz |
| İşleme Stili | Sıralı, karmaşık talimatlar | Paralel, basit komutlar |
| Şunlar için ideal | İşletim sistemleri, tek iş parçacıklı görevler | Matris matematiği, paralel veri işleme |
| Gecikme | Düşük (mikrosaniye) | Daha yüksek (başlatma gecikmesi) |
| Mimari | Genel amaçlı | Tekrarlayan hesaplamalar için özelleştirilmiş |
Sanal GPU (vGPU) ve Çok Örnekli GPU (MIG) teknolojileri, işlemcileri birden fazla kullanıcıya dağıtmak için kaynak bölümleme ve zamanlama işlemlerini yönetir. Bu yapı; yapılandırmaya bağlı olarak zaman dilimli paylaşım veya adanmış donanım örnekleri aracılığıyla ekiplerin donanım kullanımını en üst düzeye çıkarmasını sağlar.
Sinir ağlarını eğitmek milyarlarca matris çarpımı gerektirir. 10.000 birime sahip bir GPU, 10.000 işlemi aynı anda yürütmez; bunun yerine, verimliliği artırmak için binlerce paralel iş parçacığını "warp" adı verilen gruplar halinde yönetir. Bu geniş ölçekli paralellik, bu birimlerin AI geliştiricileri için neden bu kadar kritik olduğunu açıklar.
CUDA Core ve Tensor Core: Aralarındaki Fark

NVIDIA GPU'ler birlikte çalışan iki özelleştirilmiş birim türü içerir: standart CUDA core'lar ve Tensor core'lar. Bunlar rakip teknolojiler değildir; her biri farklı iş yükü bileşenlerini ele alır.
Standart birimler; FP32 ve FP64 hesaplamalarını, tam sayı işlemlerini ve koordinat dönüşümlerini yürüten genel amaçlı paralel işlemcilerdir. GPU hesaplamalarının temelini oluşturan bu CUDA teknolojisi, fizik simülasyonlarından veri ön işlemeye kadar pek çok görevi özel bir hızlandırma olmaksızın çalıştırır.
Tensor core'lar, yalnızca matris çarpımı ve AI görevleri için tasarlanmış özelleştirilmiş birimlerdir. NVIDIA'nın Volta mimarisinde (2017) tanıtılan bu birimler, FP16 ve TF32 hassasiyetindeki hesaplamalarda üstün performans gösterir. En yeni nesil, daha hızlı AI çıkarımı için FP8 desteği sunar.
| Özellik | CUDA Çekirdekleri | Tensor Çekirdekleri |
| Amaç | Genel paralel hesaplama | AI için matris çarpımı |
| Hassasiyet | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Yapay Zeka için Hız | 1x temel performans | CUDA core'lardan 2-10 kat daha hızlı |
| Kullanım alanları | Veri ön işleme, geleneksel ML | Derin öğrenme eğitimi/çıkarımı |
| Kullanılabilirlik | Tüm NVIDIA GPU'ler | RTX 20 serisi ve üzeri, veri merkezi GPU'leri |
Modern GPU'ler her ikisini de bir arada kullanır. RTX 5090, 21.760 standart birime ek olarak 680 adet beşinci nesil Tensor core içerir. H100 ise derin öğrenme hızlandırması için 16.896 standart birimi 528 adet dördüncü nesil Tensor core ile eşleştirir.
Sinir ağları eğitilirken Tensor core'lar, modelin ileri ve geri geçişlerindeki ağır hesaplamaları üstlenir. Standart birimler ise veri yükleme, ön işleme, kayıp hesaplama ve optimizer güncellemelerini yönetir. Her iki tür birlikte çalışır; Tensor core'lar hesaplama açısından yoğun işlemleri hızlandırır.
Rastgele ormanlar veya gradyan artırımı gibi geleneksel makine öğrenmesi algoritmalarında standart birimler işi yönetir; bu algoritmalar, Tensor core'ların hızlandırdığı matris çarpımı kalıplarını kullanmaz. Ancak transformer modelleri ve evrişimli sinir ağlarında Tensor core'lar ciddi hız kazanımları sağlar.
CUDA Core'lar Ne İşe Yarar?

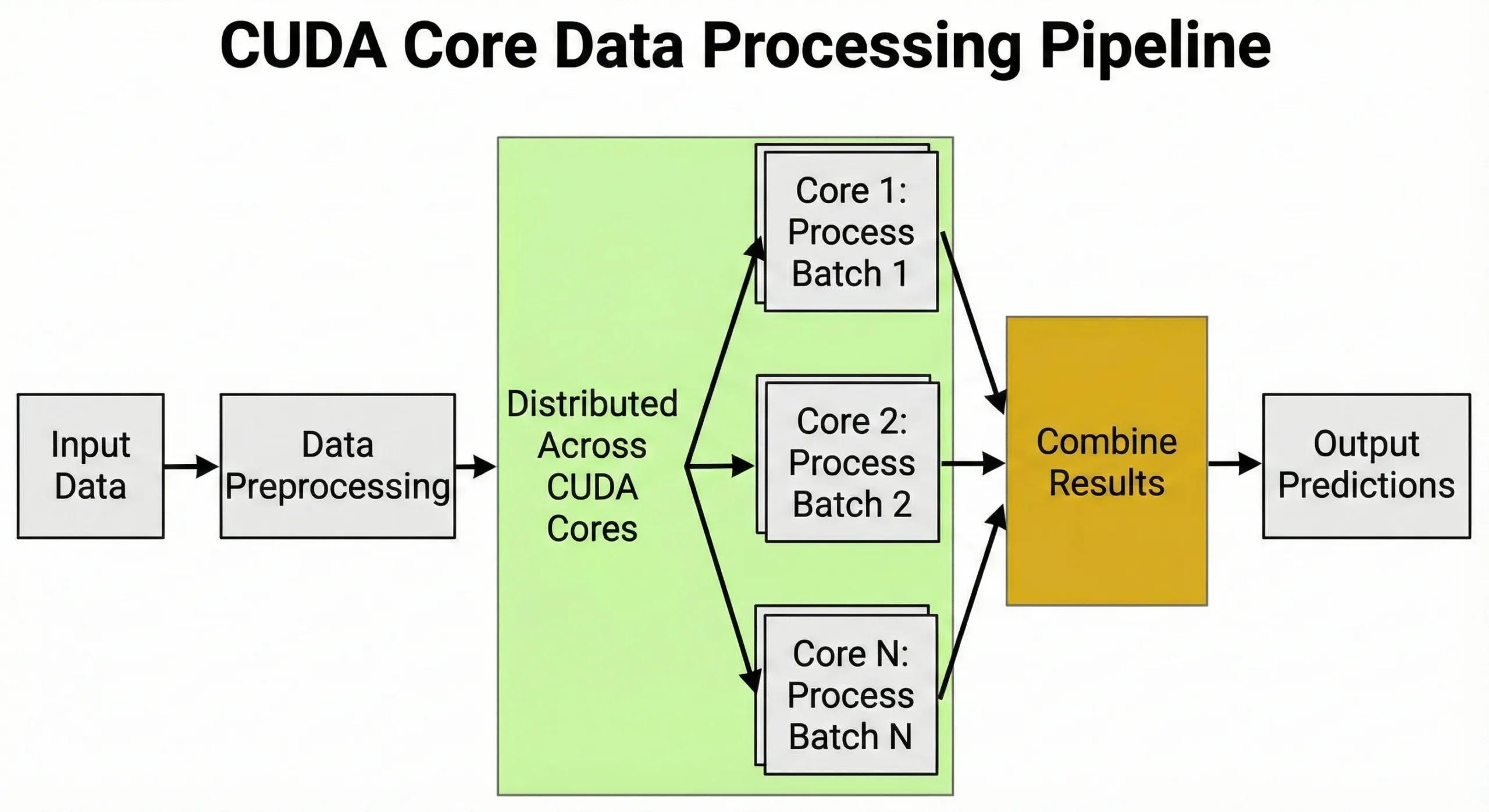
CUDA core'lar, aynı anda çok sayıda özdeş hesaplama gerektiren görevleri çalıştırır. Matris işlemleri veya tekrarlayan sayısal hesaplamalar içeren her iş, bu mimari sayesinde doğrudan avantaj elde eder.
Yapay Zeka ve Makine Öğrenmesi Uygulamaları
Derin öğrenme, hem eğitim hem de çıkarım aşamalarında matris çarpmalarına dayanır. Sinir ağları eğitilirken her ileri geçiş, ağırlık matrisleri üzerinde milyonlarca çarpma-toplama işlemi gerektirir. Geri yayılım ise geri geçiş sırasında bunlara milyonlarca işlem daha ekler.
Birimler, görüntüleri tensörlere dönüştürme, değerleri normalleştirme ve artırma dönüşümleri uygulama gibi veri ön işleme görevlerini yönetir. Binlerce görevi aynı anda ele alabilme kapasitesi, GPU'lerin yapay zeka için bu kadar önemli olmasının temel nedenidir.
Eğitim sırasında öğrenme hızı zamanlamalarını, gradyan hesaplamalarını ve optimize edici durum güncellemelerini denetlerler.
Öneri sistemleri veya sohbet botları çalıştıran yapay zeka çıkarım işlemleri için VPS, istekleri eş zamanlı olarak işler ve yüzlerce tahmini aynı anda yürütür. Şu kaynaktaki rehberimiz: yapay zeka için en iyi GPU 2025 farklı model boyutları için hangi yapılandırmaların uygun olduğunu ele alıyor.
H100'nin Tensor çekirdekleriyle birleşen 16.896 birimi, 7 milyar parametreli bir modeli aylar yerine haftalar içinde eğitir. Binlerce kullanıcıya hizmet veren sohbet botları için gerçek zamanlı çıkarım da benzer düzeyde eş zamanlı yürütme gücü gerektirir.
Bilimsel Hesaplama ve Araştırma
Araştırmacılar bu işlemcileri moleküler dinamik simülasyonları, iklim modellemesi ve genomik analiz için kullanır. Her hesaplama bağımsız olduğundan eş zamanlı yürütme için idealdir. Finans kurumları ise milyonlarca senaryoyu aynı anda işleyerek Monte Carlo simülasyonları çalıştırır.
3D Render ve Video Prodüksiyonu
Ray tracing, her pikselden bağımsız ışınlar izleyerek 3D sahnelerdeki ışığın nasıl yansıdığını hesaplar. RT çekirdekleri geçiş işlemlerini üstlenirken standart birimler doku örnekleme ve aydınlatmayı yönetir. Bu iş bölümü, milyonlarca ışın içeren sahnelerin hızını doğrudan belirler.
NVENC, H.264 ve H.265 kodlamasını üstlenirken Ada Lovelace ve Hopper gibi yeni mimariler AV1 için donanım desteği sunuyor. CUDA ise efektler, filtreler, ölçekleme, gürültü giderme, renk dönüşümleri ve ardışık düzen entegrasyonunda devreye giriyor. Bu sayede kodlama motoru, daha hızlı video üretimi için paralel işlemcilerle birlikte çalışabiliyor.
Blender veya Maya'da 3D render, milyarlarca yüzey gölgelendirici hesaplamasını mevcut birimler arasında dağıtır. Parçacık sistemleri de aynı anda binlerce parçacığın etkileşimini simüle ettiğinden bu işten büyük ölçüde yararlanır. Bu özellikler, üst düzey dijital içerik üretiminin temel taşlarıdır.
CUDA Çekirdekleri GPU Performansını Nasıl Etkiler?

Çekirdek sayısı, eş zamanlı yürütme kapasitesi hakkında genel bir fikir verir; ancak CUDA çekirdeklerini değerlendirmek için rakamların ötesine bakmak gerekir. Saat hızı, bellek bant genişliği, mimari verimliliği ve yazılım optimizasyonu belirleyici rol oynar.
2,0 GHz'de çalışan 10.000 birimli bir GPU ile 1,5 GHz'de çalışan 10.000 birimli bir GPU farklı sonuçlar verir. Daha yüksek saat hızı, her birimin saniyede daha fazla işlem tamamlaması anlamına gelir. Yeni mimariler ise daha iyi komut zamanlaması sayesinde her döngüde daha fazla iş yapar.
Cihazı meşgul tutup tutmadığınızı kontrol edin; ancak nvidia-smi kullanım oranının kaba bir metrik olduğunu unutmayın. Bu oran, bir çekirdeğin aktif olduğu sürenin yüzdesini ölçer; kaç çekirdeğin çalıştığını değil.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderÖrnek çıktı: %85, %92 (%85 aktif süre, %92 bellek denetleyici etkinliği)
GPU'niz %60-70 kullanım oranı gösteriyorsa, büyük olasılıkla CPU veri yükleme veya küçük toplu iş boyutları gibi yukarı akış darboğazları vardır. Öte yandan, çekirdekleriniz belleğe bağlıysa veya tek iş parçacıklı çalışıyorsa %100 kullanım oranı bile yanıltıcı olabilir. Çekirdek doygunluğunu gerçek anlamda ölçmek için "SM Efficiency" veya "SM Active" metriklerini izlemek üzere Nsight Systems gibi profil oluşturucuları kullanın.
Bellek bant genişliği, hesaplama kapasitesi dolmadan önce sıklıkla darboğaza dönüşür. GPU'niz veriyi bellekten beslenenden daha hızlı işliyorsa birimler boşta bekler. H100 SXM5 modeli 3,35 TB/s bant genişliği kullanır 16.896 çekirdeği beslemek için. Ancak PCIe versiyonunda bu değer 2 TB/s'ye düşer.
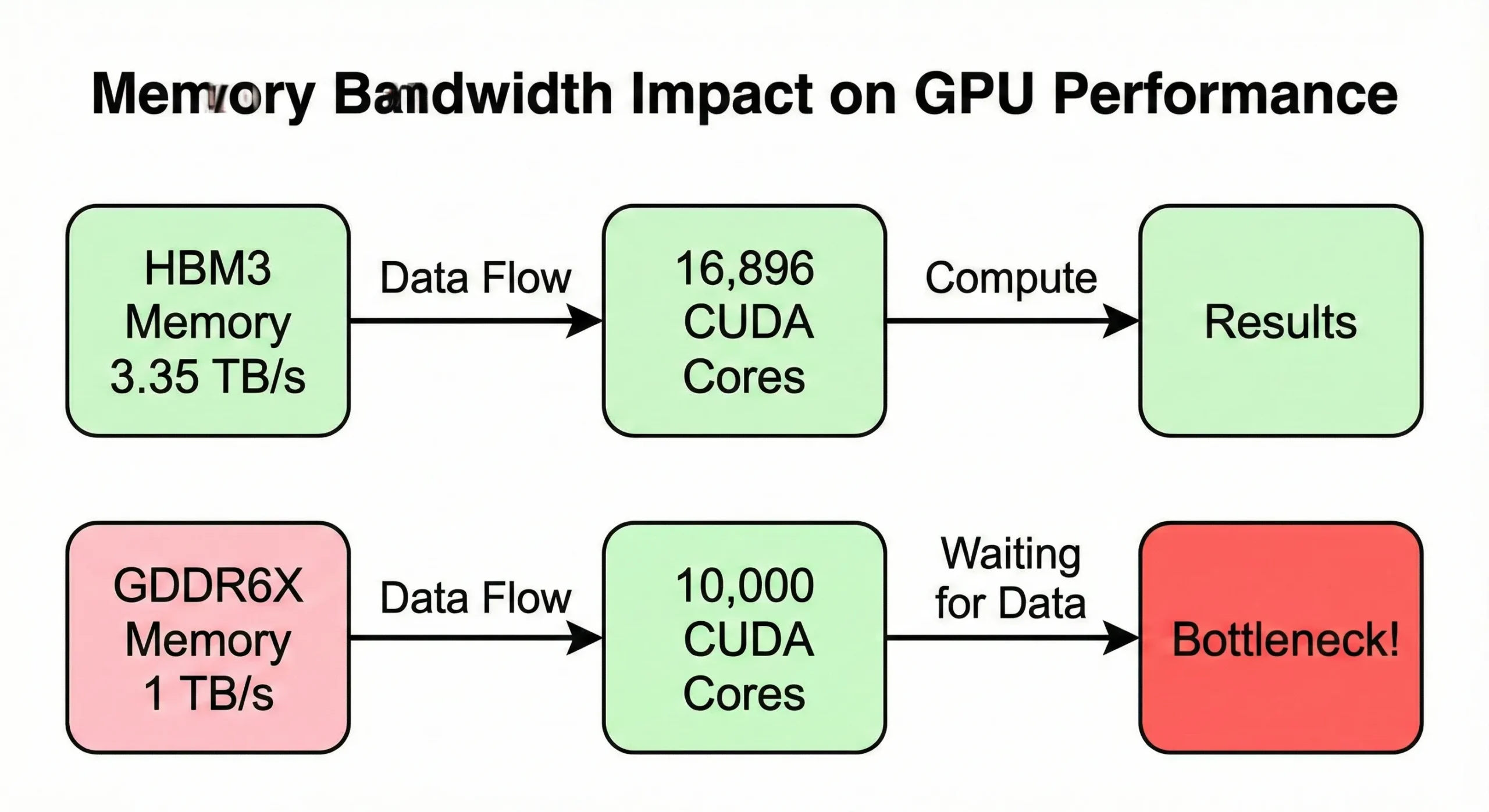
Benzer çekirdek sayısına ancak daha düşük bant genişliğine (~1 TB/s) sahip tüketici GPU'leri, bellek yoğun işlemlerde gerçek dünya performansı açısından geride kalır.
VRAM kapasitesi, çalıştırabileceğiniz görevlerin boyutunu belirler. Bir 70B modeliçin FP16 ağırlıkları yeterli olsa da tam eğitim çok daha fazla bellek gerektirir. Gradyanları ve optimizer durumlarını da hesaba katmanız gerekir. Boşaltma stratejileri kullanmadığınız sürece bu durumlar bellek ayak izini genellikle üç katına çıkarır.
A100 80GB, yüksek verimli çıkarım ve ince ayar için tasarlanmıştır. 24GB'lık RTX 4090 ise genellikle 7B modeller için anılsa da INT4 gibi modern kuantizasyon teknikleri kullanıldığında 30B+ parametreli modelleri de çalıştırabilir. Ancak VRAM tükendiğinde CPU-GPU veri transferleri devreye girer ve bu durum verimi ciddi biçimde düşürür.
Yazılım optimizasyonu, kodunuzun mevcut tüm birimleri gerçekten kullanıp kullanmadığını belirler. Kötü yazılmış çekirdekler, kullanılabilir kaynakların yalnızca küçük bir bölümünü devreye sokabilir. Derin öğrenme için cuDNN ve veri bilimi için RAPIDS gibi kütüphaneler, kullanım oranını en üst düzeye çıkarmak amacıyla kapsamlı biçimde optimize edilmiştir.
Daha Fazla CUDA Çekirdeği Her Zaman Daha İyi Performans Anlamına Gelmez

En yüksek çekirdek sayısına sahip GPU'yi satın almak mantıklı görünebilir; ancak birimler diğer sistem bileşenlerini aşıyorsa ya da göreviniz çekirdek sayısıyla ölçeklenmiyorsa paranızı boşa harcamış olursunuz.
Bellek bant genişliği ilk sınırı oluşturur. RTX 5090'nin 21.760 birimi, 1.792 GB/s bellek bant genişliğiyle beslenir. Daha az birime sahip eski GPU'ler, birim başına orantısal olarak daha yüksek bant genişliği sunabilir.
Mimari farklılıklar belirleyici rol oynar. 2,2 GHz'de 14.000 birimle çalışan yeni bir GPU, saat başına daha iyi komut işleme kapasitesi sayesinde 1,8 GHz'de 16.000 birimli eski bir modeli geride bırakır. 20.000 birimi verimli kullanmak için kodunuzun düzgün paralelleştirilmesi gerekir.
GPU VPS Seçerken CUDA Çekirdeklerinin Önemi

VPS için doğru CUDA çekirdeği GPU yapılandırmasını seçmek, kullanılmayan kaynaklar için para harcamanızı veya proje ortasında darboğaza girmenizi engeller.
H100'nin 80GB belleği, 4-bit kuantizasyon kullanarak 70B parametreli modellerde çıkarım işlemlerini kaldırabilir. Ancak tam eğitimde, gradyanlar ve optimizer durumları hesaba katıldığında 80GB bile 34B'lik bir model için çoğu zaman yetersiz kalır. FP16 eğitiminde bellek ayak izi önemli ölçüde genişler ve genellikle çok GPU'li parçalama gerektirir.
Gerçek zamanlı tahmin sunan çıkarım işlemleri daha az birime ihtiyaç duyar, ancak düşük gecikmeden fayda sağlar. Algoritma testi ve hata ayıklama gibi geliştirme ve prototipleme çalışmaları için orta seviye GPU'ler yeterlidir.
4.352 birimli bir RTX 4060 Ti, fazla donanım bedeli ödemeden test yapmanızı sağlar. Yaklaşımınızı doğruladıktan sonra, tam eğitim koşuları için üretim GPU'lerine geçebilirsiniz.
Render ve video işlemleri, belli bir noktaya kadar birim sayısıyla ölçeklenir. Blender'ın Cycles render motoru, mevcut tüm kaynakları verimli biçimde kullanır. 8.000-10.000 birimlik bir GPU, sahneleri 4.000 birimlikine kıyasla 2-3 kat daha hızlı render eder.
Cloudzy olarak yüksek performanslı GPU VPS Ağır iş yükleri için tasarlanmış hosting hizmeti sunuyoruz. Hızlı render ve uygun maliyetli AI çıkarımı için RTX 5090 ya da RTX 4090'yi seçebilir, büyük ölçekli derin öğrenme iş yükleri için A100'ye geçebilirsiniz. Tüm planlar 40 Gbps ağ, gizlilik odaklı politikalar ve kripto para ödeme seçenekleriyle çalışır; gerçek güç, kurumsal bürokratik karmaşa olmadan.
AI modeli eğitmek, 3D sahneleri render etmek veya bilimsel simülasyonlar çalıştırmak olsun, ihtiyacınıza göre çekirdek sayısını seçersiniz.
Bütçe her zaman önemlidir. 6.912 birimli bir A100, 16.896 birimli H100'ye kıyasla ciddi ölçüde daha ucuzdur. Pek çok işlem için iki A100, tek bir H100'ye göre daha iyi bir fiyat-performans oranı sunar. Denge noktası, kodunuzun birden fazla GPU'ye ölçeklenip ölçeklenmediğine bağlıdır.
Doğru CUDA Çekirdek Sayısı Nasıl Seçilir
Gereksinimlerinizi piyasadaki en yüksek rakamlara göre değil, gerçek iş yükü özelliklerinize göre belirleyin.
Mevcut iş yükünüzü analiz ederek başlayın. Modelleri yerel donanımda veya bulut sunucularında eğitiyorsanız, GPU kullanım metriklerini inceleyin. Mevcut GPU'niz sürekli %60-70 kullanım gösteriyorsa, birimlerinizi tam kapasite kullanmıyorsunuz demektir.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Bu basit benchmark testi, GPU çekirdeklerinizin beklenen performansı sağlayıp sağlamadığını gösterir. Sonuçlarınızı, GPU modeliniz için yayımlanmış benchmark değerleriyle karşılaştırın.
Yükseltme yapmak sorunu çözmez. Önce bellek, bant genişliği veya CPU duraklamaları gibi darboğazları gidermeniz gerekiyor. Ardından model boyutunu byte cinsinden ve aktivasyon belleğini hesaplayarak bellek gereksinimlerini tahmin edin.
Katman çıktılarını batch boyutuyla çarpın, bir de optimizer durumlarını ekleyin. Bu toplamın tamamının VRAM içine sığması gerekir. Gereken bellek miktarını belirledikten sonra, bu eşiği karşılayan GPU'lere bakın.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Zaman çizelgenizi göz önünde bulundurun. Saatler içinde sonuç almanız gerekiyorsa daha fazla birim için ödeme yapın. Günler sürebilen eğitim işlemleri, daha küçük GPU'lerde orantılı olarak daha uzun tamamlanma süreleriyle sorunsuz çalışır.
Saatlik maliyet ile gereken saat sayısının çarpımı toplam maliyeti verir; bu nedenle bazı durumlarda daha yavaş GPU'ler genel olarak daha uygun maliyetli olabilir. Verim değişimlerini gösteren benchmark araçları sunan çeşitli framework'leri kullanarak ölçekleme verimliliğini test edin.
Birimi ikiye katlamak yalnızca 1,5 kat hızlanma sağlıyorsa, fazladan kaynaklar maliyetini karşılamıyor demektir. Fiyat-performans oranının en iyi olduğu noktayı bulun.
| İş Yükü Türü | Önerilen Çekirdekler | Örnek GPU'lar | Notlar |
| Model geliştirme ve hata ayıklama | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Hızlı iterasyon, düşük maliyet |
| Küçük ölçekli AI eğitimi (<7B parametre) | 6,000-10,000 | RTX 4090, L40S | Bireysel kullanıcılar ve küçük işletmeler için ideal |
| Büyük ölçekli AI eğitimi (7B-70B parametre) | 14,000+ | A100, H100 | Veri merkezi GPUs gerektirir |
| Gerçek zamanlı çıkarım (yüksek iş hacmi) | 10,000-16,000 | RTX 5080, L40 | Maliyet ve performansı dengeleyin |
| 3D render ve video kodlama | 8,000-12,000 | RTX 4080, RTX 4090 | Karmaşıklığa ayak uydurur |
| Bilimsel hesaplama ve HPC | 10,000+ | A100, H100 | FP64 desteği gerekli |
Popüler VPS GPUler ve CUDA Çekirdek Sayıları

Farklı GPU katmanları, farklı kullanıcı gruplarına hitap eder. GPUaaS nedir? GPU-as-a-Service'in kısaltmasıdır; Cloudzy gibi sağlayıcılar, fiziksel donanım satın almanıza ve bakımını üstlenmenize gerek kalmadan bu güçlü NVIDIA GPU'lere ihtiyaç duyduğunuzda erişim imkânı sunar.
| GPU Modeli | CUDA Çekirdekleri | VRAM | Bellek Bant Genişliği | Mimari | En Uygun |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Amiral gemisi iş istasyonu, 8K render |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | Üst düzey AI, 4K render |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/s | Hopper | Büyük ölçekli AI eğitimi |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | Kurumsal AI, uygun maliyetli veri merkezi |
| A100 | 6,912 | 40/80GB HBM2e | 1.555–2.039 GB/s | Ampere | Orta segment AI, kanıtlanmış güvenilirlik |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Oyun, orta segment AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Çok iş yüklü veri merkezi |
Tüketici RTX kartları (4070, 4080, 4090, 5080, 5090) içerik üreticileri ve oyuncular için tasarlanmıştır; ancak AI geliştirme için de oldukça işlevseldir. Veri merkezi kartlarına kıyasla daha düşük fiyata güçlü tek-GPU hızı sunarlar.
VPS sağlayıcıları, bütçe odaklı kullanıcılar için genellikle bu kartları tercih eder. Veri merkezi kartları (A100, H100, L40) ise güvenilirliği, ECC belleği ve çoklu-GPU ölçeklendirmeyi ön planda tutar. 7/24 çalışmaya ve gelişmiş özelliklere destek verirler.
Çok Örnekli GPU (MIG), tek bir GPU'yi birbirinden yalıtılmış birden fazla örneğe bölmenizi sağlar. A100, daha yeni alternatiflere karşın dengeli özellikleri sayesinde popülerliğini korumaktadır.
NVIDIA çekirdekleri, bellek ve fiyat arasındaki dengesi, onu çoğu üretim ortamı AI işlemi için güvenli bir tercih haline getirir. H100 2,4 kat daha fazla birim sunar; ancak maliyeti de önemli ölçüde yüksektir.
Sonuç
Paralel işleme birimleri, modern AI, render ve bilimsel hesaplamayı mümkün kılar. Bunların bellek, saat hızları ve yazılımla nasıl etkileşime girdiğini anlamak, GPU VPS yapılandırmalarını doğru seçmenize yardımcı olur.
İş yükünüz etkili biçimde paralelleştiğinde ve bellek bant genişliği gibi bileşenler buna ayak uydurduğunda daha fazla birim işe yarar. Ancak darboğazlarınız başka yerdeyse, salt en yüksek çekirdek sayısının peşinden gitmek para israfından öteye geçmez.
Gerçek iş yüklerinizi profil çıkararak başlayın, zamanın nerede harcandığını belirleyin ve gereksiz kapasite satın almadan GPU özelliklerini bu gereksinimlere göre eşleştirin.
Çoğu AI geliştirme çalışması için 6.000-10.000 birim, maliyet ve performans arasındaki ideal noktayı sunar. Büyük modeller eğiten veya yüksek verimli çıkarım yapan üretim ortamları, H100 gibi 14.000+ birimli GPU'lerden faydalanır.
Render ve video işleri, yaklaşık 16.000 birime kadar birimlerle verimli biçimde ölçeklenir; bu noktadan sonra sınırlayıcı etken bellek bant genişliğine dönüşür.


