
Smyčka proběhla čistě čtyřicetkrát při testování. Při jedenapadesátém spuštění v produkci volala stále stejný SQL nástroj se stejným nefunkčním dotazem, dokud nevyčerpala denní rozpočet API a fakturační upozornění konečně neprobudilo někoho ze spánku. Nikdo nenapsal špatný model. Nikdo nezměnil prompt. Agent se prostě nikdy nerozhodl, že je hotov.
Toto je vzor, který stále vídám u týmů, které přesouvají agenta z prototypu na nepřetržitý provoz. Smyčky AI agentů v produkci selhávají nikoli proto, že by model najednou byl horší, ale protože prováděcí vrstvě chybí ukončovací disciplína, ověřené kontrakty nástrojů, ohraničený kontext a odolný stav. Smyčka agenta je stochastický systém, který provádí jedno sekvenční rozhodnutí za druhým. Bez několika konkrétních ochranných prvků se vzácné selhání stane nevyhnutelným, jakmile systém běží dostatečně dlouho. Spravované platformy pro agenty (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) některé tyto ochranné prvky zahrnují přímo; tento průvodce je pro ty z nás, kteří se rozhodli pro self-hosting a vlastní správu smyčky.
Rizika jsou natolik reálná, že Gartner očekává, že více než 40 % projektů s agentní AI bude do konce roku 2027 zrušeno, přičemž důvodem jsou rostoucí náklady a nejasná hodnota. Níže popisuji šest konkrétních způsobů, jak smyčky v produkci selhávají, mechanismus za každým z nich a vzor harnesu, který to opravuje, včetně detailů pro LangGraph a n8n a toho, co je třeba k provozu 24/7.
Zkrácená verze
- Nekonečné smyčky: Agent se nikdy nerozhodne, že je hotov. Kombinujte pevný strop počtu kroků (LangGraph's
recursion_limit, výchozí hodnota 25) s detekcí bez pokroku, která ukončí opakovaná volání stejného nástroje se stejnými argumenty. - Přetečení kontextu: Smyčka zaplní vlastní kontextové okno naakumulovanou historií, až dojde ke zkrácení nebo selhání volání. Sumarizujte historii v pevných intervalech, aby pracovní kontext zůstal ohraničený.
- Tichá selhání nástrojů: Nástroj vrátí prázdný řetězec, model ho přečte jako platný no-op a agent "uspěje" tím, že neudělá nic. Ověřte každý výsledek nástroje dříve, než ho model uvidí.
- Degradace uvažování: Kvalita se zhoršuje s rostoucím kontextem, i když nedosáhnete tvrdého limitu. Uprostřed smyčky komprimujte, ale při tom chraňte připnuté bezpečnostní instrukce.
- Ztráta stavu při restartu: Havárie znamená začít od nuly. Ukládejte kontrolní body do Postgres (LangGraph
PostgresSaver), nikoli do SQLite, pro produkci. - Retry bouře: Deset agentů, každý s deseti pokusy, zasype mrtvou službu stovkou požadavků. Přidejte exponenciální backoff s jitterem a globální circuit breaker.
Co tento průvodce nepokrývá
Jde o průvodce harnesem, zaměřený na inženýrství kolem smyčky, nikoli na model uvnitř ní. Několik souvisejících témat je záměrně mimo rozsah:
- Selhání koordinace multi-agentů (zastaralá čtení, osiřelý stav mezi agenty): jiný problém, který si zaslouží vlastní popis.
- Bezpečnost agentů (prompt injection, otrava nástrojů): samostatná kategorie selhání s vlastním modelem hrozeb.
- Výběr modelu a fine-tuning. Tento průvodce předpokládá, že máte vybraný model a ladíte systém kolem něj.
- Spravované služby pro agenty, zmíněné výše; vzory zde jsou pro cestu se self-hostingem.
Nekonečné smyčky: když se agent nikdy nerozhodne, že je hotov

Agent se opakuje donekonečna, pokud nemá pevný strop kroků ani způsob, jak zjistit, že přestal dosahovat pokroku. Oprava se skládá ze dvou částí: pevný strop jako záchranná síť nákladů a detekce bez pokroku, která hashuje každé volání nástroje plus jeho argumenty a ukončí smyčku, když detekuje opakování téhož volání. V LangGraph je tímto stropem recursion_limit, výchozí hodnota je 25 kroků; jeho překročení způsobí, že graf vyvolá výjimku. GraphRecursionError.
Dokumentace LangGraph popisuje tento limit jako dosažení "maximálního počtu kroků před splněním podmínky zastavení", a zde je past, které je třeba rozumět: recursion_limit není ochrana smyčky. Je to záchranná síť, která se spustí po poté, co smyčka již promarní pětadvacet kroků a s nimi spojené výdaje na API. Vlastní naučená logika ukončení agenta by ho měla zastavit dávno předtím, a tato logika může selhat nezávisle. Jeden nahlášený případ LangGraph ukazuje agenta pro převod textu na SQL, který se opakoval, dokud nenarazil na recursion_limit i přes jasné podmínky zastavení v promptu. Stále volal stejný nástroj pro dotazy se stejným nefunkčním SQL a problém byl uzavřen jako "neplánováno". Chápu to jako jasný signál: nestačí použít strop jako podmínku zastavení. Je to váš bezpečnostní pás, ne brzdy.
Zvýšení stropu je přímočaré; předáte ho přes konfiguraci při vyvolání grafu:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)To, co skutečně zastaví zaseknutou smyčku, je detekce pokroku. Mechanismus je jednoduchý: hashujte název nástroje plus jeho argumenty při každém kroku, uchovávejte krátké okno posledních hashů a přerušte smyčku, když zaznamenáte opakování.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Tato metoda zachytí agenta, který technicky "běží" (volá nástroje, generuje tokeny), ale opakuje stále stejnou neúspěšnou akci. Pojmenovaný poruchový režim odpovídá tomu, co taxonomie MAST (IBM Research a UC Berkeley) nazývá Neuvědomění si podmínek ukončení (FM-1.5), jeden z poruchových režimů, který jejich analýza spojuje s úplným selháním úkolu.
Pevný strop zastaví nekontrolované náklady. Detekce bez pokroku zastaví smyčku, která technicky "pokračuje", ale opakuje se. Pro produkci jsou potřeba obě.
Přetečení kontextového okna: když smyčka zaplní vlastní kontext odpadem
Dlouhotrvající smyčka shromažďuje každý výstup nástroje, každou meziúvahu a každou zprávu, kterou vyprodukovala, a pak to celé vrací do kontextového okna při každém dalším tahu. Nakonec se okno zaplní a volání jsou buď tiše zkrácena, nebo selžou úplně. Opravou je sumarizace kontextu v pevných intervalech: každých N kroků komprimujte naakumulovanou historii do průběžného souhrnu, aby pracovní kontext zůstal ohraničený.
Představte si výzkumného agenta, který běží hodinu. V kroku 60 nese plný text každé stránky, kterou načetl, každého výsledku vyhledávání, každé stopy uvažování. Žádná z těchto surových historií mu nepomáhá v kroku 61, přesto celá tato data zatěžují kontextové okno a model věnuje pozornost tokenům, které již nepotřebuje. Když se okno zaplní, poskytovatel zkrátí data z jednoho konce a agent tiše ztratí instrukci, kterou dostal na začátku.
Spouštěcí bod je záležitostí ladění a existuje pro něj užitečný referenční bod. Mem0 ve svém popisu reálného produkčního systému uvádí, že kompresní modul agenta Hermes "se spouští standardně při 50 % kontextového okna modelu", s druhotnou záchrannou sítí při 85 % pro relace, které mezi tahy výrazně narostou. Padesát procent je rozumný výchozí bod: komprimujte dostatečně brzy, aby jediný velký výstup nástroje nemohl překročit limit před dalším plánovaným spuštěním komprese.
Poznámka: Overflow a degradace uvažování jsou různé problémy a další část se věnuje druhému z nich. Overflow je pevná hranice: dojdou vám tokens. Degradace je postupná: model podává horší výsledky. ještě předtím, než narazíte na stěnu. Je třeba řešit obojí a výše zmíněný práh aktivace chrání před tvrdou stěnou.
Ohraničený kontext je odpovědnost harnesu, nikoli vlastnost modelu. Sumarizujte v intervalech dříve, než okno vynutí tiché zkrácení.
Tichá selhání volání nástrojů: když agent "uspěje" tím, že neudělá nic
Volání nástroje vrátí prázdný řetězec nebo měkkou zprávu "žádné výsledky nenalezeny", model ji interpretuje jako platný výsledek a agent pokračuje, jako by krok proběhl v pořádku, přičemž vykazuje zdánlivý úspěch, aniž by cokoli udělal. Opravou je validační brána na každý návrat nástroje: ověřte výstup schémou nebo rozumnostní kontrolou dříve, než ho model vůbec uvidí, a zobrazte skutečné selhání, které musí smyčka řešit, namísto prázdného úspěchu.
Tento problém je zákeřný, protože nic nespadne. Vývojář popisující tichá selhání v produkčních agentech to říká přímo: modely interpretují obecné prázdné řetězce jako platné no-opy a pokračují ve vykonávání bez vědomí selhání. Databázový dotaz, který vrátil nula řádků, protože spojení bylo přerušeno, vypadá pro model totožně jako dotaz, který legitimně nic nenašel. Agent tedy hlásí "žádné odpovídající záznamy" a jde dál, a za týden zjistíte, že třetina jeho spuštění byla tiše nefunkční.
Validační brána sedí mezi nástrojem a modelem:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelNejde o konkrétní kontroly; vaše závisí na tom, co každý nástroj legitimně vrací. Jde o to, že neověřená návratová hodnota je rozhodnutí, které jste přenechali stochastickému modelu, a výchozí reakce modelu je pokračovat dál.
Neověřený návrat nástroje je tiché selhání čekající na příležitost. Ověřujte výstup, nespoléhejte se na samotné volání.
Degradace uvažování při dlouhých kontextech: když agent ztrácí kvalitu s délkou běhu
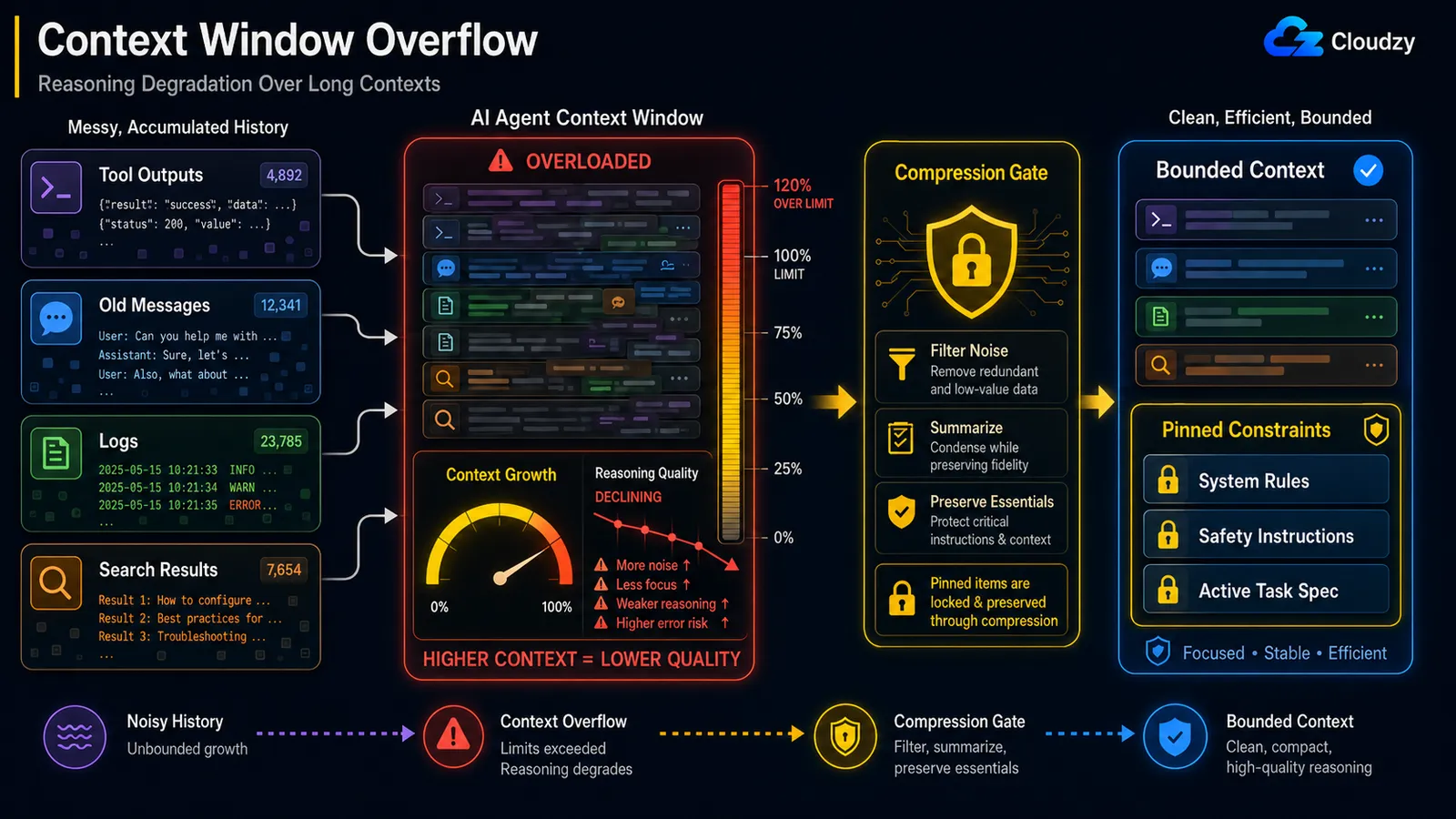
I když zůstanete pod tvrdým limitem kontextu, kvalita uvažování klesá s rostoucím kontextem. Jde o efekt "ztraceno uprostřed", kdy model spolehlivě věnuje pozornost začátku a konci dlouhého kontextu, ale střed mu uniká. Opravou je komprese uprostřed smyčky, která zachovává připnutá omezení: zkomprimujte šum, ochraňte nosné instrukce.
Tento mechanismus má jméno. Inženýrský blog Anthropic ho označuje jako context rot: "s rostoucím počtem tokenů v kontextovém okně klesá schopnost modelu přesně si vybavit informace z tohoto kontextu." Protože "každý token věnuje pozornost každému jinému tokenu", dostanete n² párové vztahy pro n tokenů a pozornost modelu se s délkou kontextu rozptyluje.
Tato podmínka, ochrana nosných instrukcí, je celá ta hra, a existuje zdokumentovaný incident, který ukazuje proč. V nahlášeném případu, agent OpenClaw hromadně smazal doručenou poštu uživatele při kompakci kontextu, protože bezpečnostní instrukce, která mu byla dána ("neprovádějte akci, dokud vám to neřeknu"), byla vypuštěna z aktivního kontextu při komprimaci historie. Omezení, které mělo být poslední věcí k odstranění, bylo zpracováno jako běžná historie a shrnuto pryč.
Naivní přístup "sumarizuj vše starší než N tahů" je tedy nebezpečný. Komprese musí vědět, co nikdy nesmí zahodit:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactTo se liší od problému přetečení v předchozí části. Přetečení je o tom, že dojde místo; degradace je o tom, že model ztrácí výkon, i když místo ještě zbývá. Můžete být na 60 % svého okna a uvažovat již špatně.
Poznámka: Komprese, která zahodí bezpečnostní omezení, je jiná třída chyby než komprese, která ztratí zastaralý výsledek vyhledávání. Označte omezení, specifikaci úkolu a jakékoli instrukce "nedělat X" jako připnuté a zcela je vylučte ze sumarizátoru.
Komprese, která zahodí bezpečnostní instrukci, je horší než žádná komprese. Při kompresi chraňte připnutá omezení.
Ztráta stavu při restartu: když havárie znamená začít od nuly
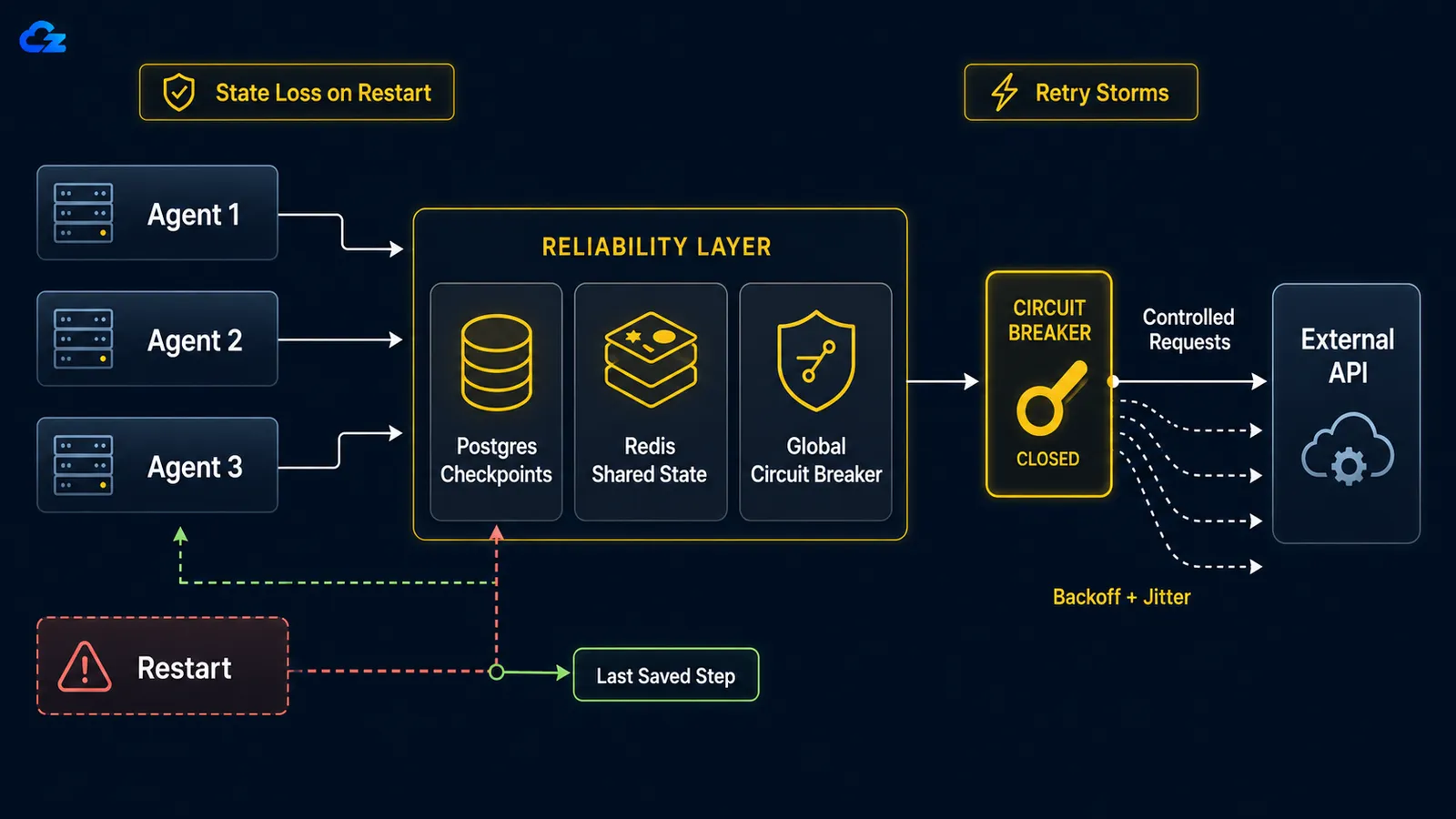
Když dlouhotrvající agent havaruje, ať už kvůli restartu, OOM kill nebo přerušení síťového spojení, neexistuje výchozí možnost obnovení od kontrolního bodu. Smyčka začíná od nuly: opakuje práci, kterou již dokončila, a co je horší, může znovu provést akce, které již provedla, jako například odeslat stejný e-mail dvakrát nebo znovu spustit placené API volání. Opravou je checkpointing: persistujte stav smyčky po každém kroku, aby restart obnovil stav z místa zastavení, nikoli od nuly.
V LangGraph je výběr backendového úložiště kontrolních bodů volbou mezi vývojem a produkcí. Dokumentace persistence LangGraph popisuje SqliteSaver jako "ideální pro experimenty a lokální pracovní postupy" a PostgresSaver jako "ideální pro produkci", a právě na tom druhém běží samotný LangSmith. Oba jsou v kódu záměrně paralelní, což usnadňuje srovnání:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverDvě detaily, které lidi překvapí. Zaprvé, balíčky pro checkpointing se instalují odděleně od základního LangGraph (langgraph-checkpoint-sqlite a langgraph-checkpoint-postgres jsou vlastními závislostmi), takže čerstvá instalace nebude mít Postgres saver, dokud ho nepřidáte. Zadruhé, každá operace checkpointingu potřebuje thread_id v konfiguraci. Toto ID váže konkrétní spuštění k uloženému stavu a restart bez správného thread_id neobnoví vůbec nic.
Tip
Balíčky pro checkpointing LangGraph jsou samostatné instalace. langgraph-checkpoint-postgres není součástí základního langgraph balíčku, takže ho přidejte do produkčního souboru závislostí dříve, než to zjistíte za chodu při incidentu.
n8n má stejné rozdělení mezi vývojem a produkcí, jen pod jiným názvem. Jeho vestavěná možnost paměti se také nazývá Simple Memory (nebo Buffer Window Memory) a produkční cestou je Postgres Chat Memory node pro stav, který musí přežít restart. Vestavěná paměť uchovává konverzaci v běžícím procesu, což je v pořádku pro testování, ale představuje riziko pro provoz 24/7. Praktici provozující agenty n8n v produkci uvádějí, že museli přejít na úložiště podložené Postgres poté, co paměť v procesu rostla, až stáhla celou instanci s sebou. Pokud používáte n8n a váš agent si potřebuje pamatovat cokoli přes restart, připojte ho od začátku k Postgres Chat Memory.
SQLite checkpointing je vývojová pomůcka. Přežití produkčního restartu znamená Postgres (LangGraph) nebo úložiště podložené Postgres (n8n).
Retry bouře: když vaši vlastní agenti zaplaví mrtvou službu
Když padne downstream služba, naivní pokusy o opakování v rámci každého spuštění promění váš fleet agentů v self-inflicted denial-of-service. Oprava má dvě části: exponenciální backoff s jitterem na každém agentu, aby se pokusy o opakování rozložily v čase, a globální circuit breaker, který se sepne po dosažení sdíleného prahu selhání a zastaví celé stádo od bombardování služby, která je evidentně nedostupná.
Matematika je neúprosná. Jak popisuje materiál o vzorech opakování , při deseti paralelních agentech, každý s deseti pokusy, odešlete sto požadavků na službu, která je již na zemi, protože backoff každého agenta je per-execution, nikoli globální. Samotný backoff na úrovni agenta to nevyřeší. Deset agentů, kteří každý slušně počká, stále čeká synchronizovaně, pokud všichni začali ve stejnou dobu, takže opakují v synchronizovaných vlnách. Jitter rozbíjí synchronizaci randomizací čekání každého agenta; circuit breaker rozbíjí stádo tím, že sdílí jeden kus stavu selhání napříč všemi agenty.
Část backoffu je v Pythonu vyřešený problém; knihovna tenacity zvládá exponenciální-s-jitterem čistě:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)Circuit breaker musí být globální: sdílený napříč všemi agenty, nikoli znovu vytvářený pro každé spuštění. Když selhání překročí práh, otevře se, každý agent rychle selže namísto odeslání požadavku a po ochlazení propustí jediný testovací požadavek, zda je služba zpět. Breaker, který žije uvnitř procesu každého agenta, nic nechrání, protože nic není sdíleno; mrtvá služba stále dostane plných sto požadavků.
Backoff na úrovni spuštění stále nechá deset agentů zasypat mrtvou službu synchronizovaně. Circuit breaker musí být globální, aby zastavil stádo.
Šest selhání na jednom místě
Před infrastrukturní částí: celý katalog na jednom místě, selhání, mechanismus, který ho způsobuje, oprava harnesu a kde příslušný parametr v každém frameworku najdete.
| Režim selhání | Mechanismus | Oprava harnesu | Parametr frameworku |
|---|---|---|---|
| Nekonečná smyčka | Žádný strop kroků ani kontrola pokroku | Pevný strop + detekce bez pokroku | LangGraph recursion_limit (25) / n8n Max Iterations |
| Přetečení kontextu | Historie roste, dokud nezaplní okno | Sumarizace v intervalech | Na úrovni aplikace (komprimovat při cca 50 % okna) |
| Tiché selhání nástroje | Prázdné/měkké vrácené hodnoty jsou čteny jako platné no-opy | Validační brána na každý výsledek nástroje | Wrapper nástroje na úrovni aplikace |
| Degradace uvažování | Pozornost klesá s rostoucím kontextem ("context rot") | Komprese uprostřed smyčky chránící připnutá omezení | Na úrovni aplikace, s vědomím omezení |
| Ztráta stavu při restartu | Žádný kontrolní bod; smyčka se restartuje od nuly | Persistentní checkpointing | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Retry bouře | Per-execution pokusy kaskádují na mrtvé službě | Backoff + jitter + globální circuit breaker | tenacity + sdílený stav breakeru |
Poznámka pro čtenáře používající CrewAI, AutoGen, Dify nebo ručně psanou Python smyčku: parametry frameworku se mění, ale šest vzorů nikoli. Deduplikace, intervalová sumarizace, validace schématu, komprese s vědomím omezení, checkpointing a globální circuit breaker jsou koncepty nezávislé na frameworku. Specifika pro LangGraph a n8n jsou zde konkrétními vodítky, nikoli hranicí, kde vzory přestávají platit.
Nastavení velikosti produkčního nasazení agenta
Každý vzor výše předpokládá, že kontrolujete správce procesů, databázi a chování při restartu. Checkpointing vám nic nepřinese, pokud se havarovaná smyčka nikdy nevrátí do provozu, a globální circuit breaker potřebuje místo pro uchování sdíleného stavu. Právě tuto kontrolu vám self-hosting dává a spravovaná černá skříňka nikoli; takže poslední rozhodnutí je, jak dimenzovat server, který to celé provozuje 24/7.
Pro většinu nasazení s jedním agentem (jeden agent, LLM volání odcházející na externí API, základní Postgres checkpointing) stačí malá instance: přibližně 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. Těžké výpočty probíhají na straně poskytovatele modelu; váš server orchestruje, ukládá kontrolní body a drží stav, neprovádí inference. Přejděte přibližně na 4 GB RAM, 2 vCPU, and 120 GB NVMe když je agent stavový a vícekrokový s Postgres checkpointingem plus Redis pro hydrataci relací, nebo když spouštíte souběžné pracovní postupy sdílející hostitel.
Důvod, proč je pro to vhodný self-managed VPS a nikoli omezená platforma, je tentýž, proč opravy vůbec fungují: potřebují root přístup. Vlastní Postgres pro checkpointing, vlastní Redis pro stav relací a skutečný správce procesů jako systemd or pm2, takže když smyčka selže, supervisor ji restartuje a obnoví stav z posledního kontrolního bodu namísto spuštění úlohy od začátku. Celý příběh o obnově závisí na vlastnictví životního cyklu procesu.
Protože n8n provozujeme jako aplikaci jedním klikem v našem vlastním marketplace, je tato část nastavení u nás nejrychlejší cestou: můžete nasadit n8n na Cloudzy VPS s konfigurací podloženou Postgres, kterou produkční cesta potřebuje, na instanci, kde máte root přístup pro přidání vlastního Redis a dohledu nad procesy. Jde o stejnou self-hostenou architekturu popsanou výše, kde vlastníte databázi a chování při restartu, což je to, co dělá checkpointing a automatické obnovení skutečně funkčními.
Vzory harnesu jsou jen tak spolehlivé jako server, na kterém běží. Checkpointing vám nic nedá, pokud se proces nikdy nerestartuje.
Časté dotazy
Jak zabráním svému LangGraph agentu ve věčném opakování?
Použijte dva mechanismy dohromady. Nastavte recursion_limit jako pevný strop kroků (výchozí hodnota je 25), aby nekontrolovaná smyčka nemohla vypálit neomezený rozpočet, a přidejte detekci bez pokroku, která hashuje každé volání nástroje plus argumenty a ukončí smyčku, když se stejné volání opakuje v nedávném okně. Samotný strop je záchranná síť, která se spustí poté, co k plýtvání došlo, nikoli skutečná ochrana smyčky. Detekce pokroku je to, co skutečně zastaví zaseknutou smyčku.
Jaká je správná hodnota recursion_limit pro LangGraph v produkci?
Neexistuje univerzální číslo. Nastavte ho na maximální počet legitimních kroků, které by váš agent kdy mohl potřebovat, plus rezervu, a nakládejte s ním přísně jako se záchrannou sítí nákladů. Zvýšení limitu nezpůsobí, že by se smyčkující agent konvergoval. Pokud váš agent naráží na vysoký limit, opravou je detekce pokroku, nikoli vyšší strop.
Proč můj n8n AI agent stále naráží na Max Iterations?
Dosažení limitu Max Iterations znamená, že agent nekonverguje: provádí více kroků, než limit dovoluje, aniž by dosáhl zastavení. Zvyšte limit pouze tehdy, pokud úkol legitimně potřebuje více kroků; jinak to berte jako signál, že agent je zaseknut. Dávejte pozor na jednu konkrétní past: GitHub issue #22771 uvádí, že když je při dosažení limitu iterací nastaveno "On Error: Continue", může se spuštění přesměrovat na výstup Success místo Error, takže omezené, neúspěšné spuštění může v pracovním postupu vypadat jako úspěšné.
Jak persistuji stav agenta přes restarty?
V LangGraph použijte PostgresSaver checkpointing namísto SqliteSaver, který je určen pro lokální vývoj. V n8n použijte uzel Postgres Chat Memory namísto vestavěné paměti v procesu. Obojí vyžaduje persistentní databázi a v LangGraph každá operace checkpointingu potřebuje thread_id který váže konkrétní spuštění k uloženému stavu.
Co způsobuje degradaci uvažování při dlouhých bězích agenta?
Kvalita uvažování klesá s rostoucím kontextem, ještě před dosažením tvrdého tokénového limitu. Jde o efekt "ztraceno uprostřed", kdy model věnuje pozornost začátku a konci dlouhého kontextu, ale střed mu uniká. Inženýrský blog Anthropic označuje základní mechanismus jako "context rot": protože každý token věnuje pozornost každému jinému tokenu, dostanete n² párové vztahy a pozornost modelu se s délkou kontextu rozptyluje. Opravou je komprese uprostřed smyčky, která sumarizuje zastaralou historii a přitom zachovává připnutá omezení a bezpečnostní instrukce v nezměněném stavu.


