
Gør arbejdet hurtigt, betales kun for det, du bruger, og lad andre håndtere patching, og det budskab holder stadig. Men troldedomet forsvinder når uforudsigelige lageromkostninger dukker op eller en glemt S3-politik lader en bucket stå åben. Fra erfaringer købt dyrt, ser jeg de samme store udfordringer inden for cloud-computing dukke op på tværs af stacks og brancher. Ved at få dem på plads tidligt undgår vi det meste af problemerne og holder teamet fokuseret på at release funktioner i stedet for at slukke ildebrande.
Hvorfor disse hovedpine nægtede at Go forsvinder
Cloud-fejl opstår sjældent fra en enkelt katastrofal bug. De opbygges fra små huller, der staplet hen over arkitektur, proces og mennesker. Før vi dykker ned i hver kategori, her er et øjebliksbillede af symptomer, der viser, at noget dybere er galt:
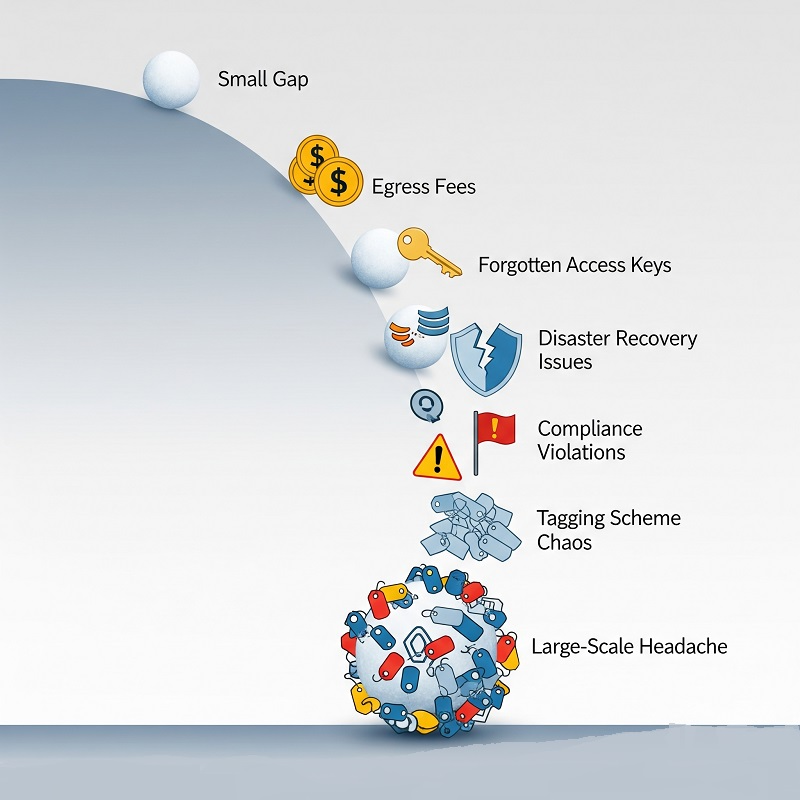
- Et pludseligt hop i udgangsgebyrer udsletter to måneders margin.
- En glemt adgangskey sætter gang i en nat med kryptomining.
- Et regionsdækkende servicesvigt tester en beredskabsplan, som ingen har øvet.
- En compliance-revision flag umærket sensitive data parkeret i objektlager.
- Ti hold vedtager ti mærkningsskemaer, så opkrævningsrapporter læser som hieroglyfer.
Hvert symptom spores tilbage til en eller flere centrale risikoområder. Hold det kort tæt; det guider hvert mildrende skridt senere.
Risici ved cloud computing
Industriundersøgelser peger konsistent på syv centrale risikokategorier, der tegner sig for størstedelen af hændelser på tværs af sektorer. Selvom disse kategorier overlapper, kortlægger de tilsammen de vigtigste udfordringer for cloud-computing som teams møder dagligt - fra budgetoverraskelser til datatyveri:
Fejlkonfiguration og overordnede rettigheder
Selv erfarne ingeniører klikker nogle gange forkert i konsollen. En alt for tilladende sikkerhedsgruppe eller en offentlig lagerbeholder gør et internt værktøj til en risiko på internettet.
Almindelige fejl
- Jokertegn 0.0.0.0/0 regler for administratorporte.
- IAM-roller, der giver fuld adgang længe efter en migration er afsluttet.
Databrud og lækage
Når fejlkonfigurationer åbner døren, slipper data ud. Databrud er en tilbagevendende hovedpine i cloud-sikkerhed, og de starter sjældent med sofistikerede zero-days - de kommer gennem eksponerede endpoints eller forældet legitimationsoplysninger.
Intern trussel og uautoriserede administratorer
Ikke al risiko kommer udefra. Kontraktansat personale med bevarede rettigheder eller medarbejdere, der starter ikke-godkendte tjenester, skaber blindpunkter, som standardovervågning ikke fanger.
Usikre APIs og eksponering i forsyningskæden
Hver cloud-native app er afhængig af tredjepartsbiblioteker og APIs. Manglende hastighedsbegrænsninger eller usikrede biblioteker inviterer til misbrug og gør en uskyldigt udseende funktion til et angrebspunkt.
Begrænset overblik og manglende overvågning
Hvis logs ligger på en konto og advarsler på en anden, strækker hændelser sig, mens teams søger efter kontekst. Blindpunkter skjuler både ydeevnedrift og aktive indtrængen.
Sikkerhedsproblemer, der holder teams vågen om natten
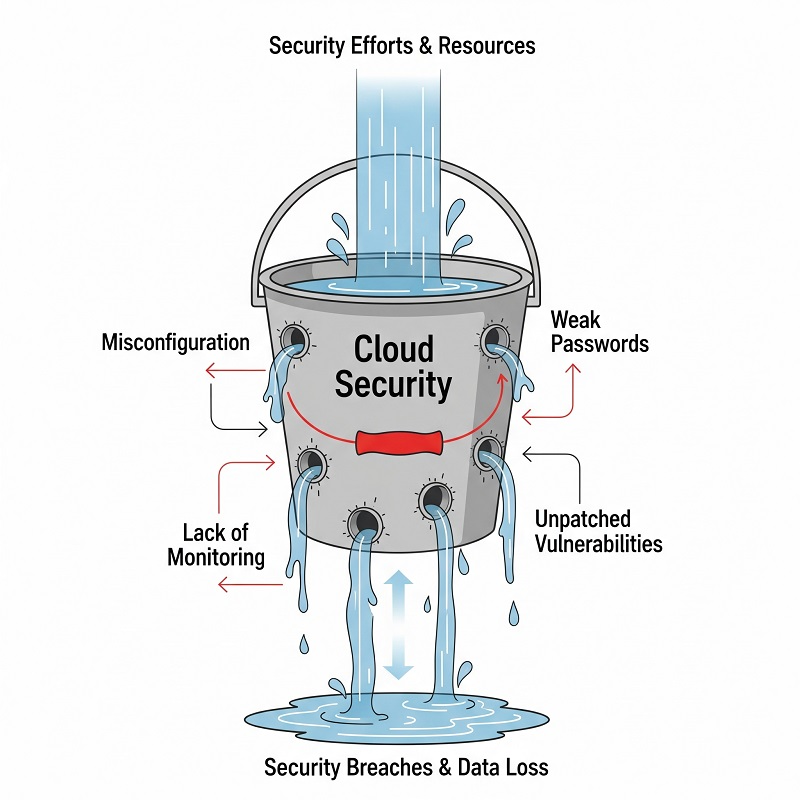
De principper, som er præsenteret i vores artikel om hvad er cloud security giver et solidt grundlag, men sofistikerede angribere slipper alligevel igennem, medmindre virksomheder automatiserer loggennemgang, MFA og least-privilege-design. Uden disse sikkerhedsforanstaltninger bliver de vigtigste sikkerhedsproblemer i cloud-computing fra teoretiske til presserende. Moderne Skysikkerhedsværktøjer hjælper med at reducere detektionstiden, men kun når teams integrerer dem i dagligt arbejde.
Vigtigste punkter:
- Kortlæg ethvert eksternt endpoint; scan for utilsigtet eksponering hver uge.
- Rotér nøgler automatisk; behandl længerevarende legitimationsoplysninger som teknisk gæld.
- Føre revisionslogge ind i et centralt SIEM, og alert derefter på anomalier i stedet for rå fejl.
Driftsmæssige og økonomiske overraskelser
Høj tilgængelighed virker enkel, indtil en multi-AZ-databaseklynge pludselig fordobler dit regning. Blandt de de vigtigste udfordringer for cloud-computing problemer der gemmer sig i det åbne, ligger omkostningsdrift tæt på toppen. Supportbilletter hober sig op, når instansfamilier udgår fra understøttelse, eller når kapacitetsbegrænsninger bremser opskalering.
Teams, der har behov for detaljeret kontrol, flytter nogle gange latencyfølsomme tjenester til en letvægts VPS Cloud opsætning. Ved at fastgøre arbejdsbelastninger til garanterede vCPUs undgår de støjende naboeffekter og bevarer fleksibilitet hos udbydere.
Almindelige cloudproblemer på driftsfronten
- Underforsynede grænser, der blokerer pludseligt trafikstigning.
- Leverandørlåsning, der gør dataplanændringer langsomme og dyre.
- Uventede gebyr for tværregionalt datasæt under failover-tests.
Gostyring og compliancefaldgruber
Revisorer taler deres eget sprog, og cloud tilføjer nyt fagudtryk oven i købet. Når mærkning, opbevaringsperioder og krypteringspolitikker divergerer, stiger fund hurtigt. Tabellen nedenfor fremhæver fire hyppige mangler, jeg møder under parathedsvurderinger:
| Overholdelseskløft | Typisk trigger | Sandsynlighed | Forretningspåvirkning |
| Klassificerede personlige data gemt i objektlager | Manglende dataoversigt | Mellem | Bøder, brandskade |
| Intet MFA på privilegerede konti | Hastighed over proces | Høj | Kontokkapring |
| Katastrofeberedskabsplan aldrig testet | Ressourcepres | Mellem | Længere nedetid |
| Proprietære funktioner dybt indlejret | Bekvemmelighed på buildtidspunktet | Lav | Dyr udgang, langsomt migrering |
Bemærk, hvordan hver række binder tilbage til en af vores computingudfordringer ovenfor. Synlighed, mindste privilegie og reproducerbar test danner ryggraden i enhver succesfuld revisionscyklus.
Sådan løser du smertepunkterne
Der findes ingen universel løsning, men et lagdelt tillempning reducerer risiko hurtigt. Jeg grupperer taktikker i tre kategorier:
- Styrk fundamentet
- Definér baseline for alle konti med infrastructure-as-code; driftadvarelser fanger skjulte ændringer.
- Gennemtving MFA på identity provider-niveau, ikke per applikation.
- Automatisér registrering og reaktion
- Centralisér logs, og saml dem med ressourcetags, så advarsler forklarer hvad hvad der gik galt, ikke bare at det gik galt hvor det gik i stykker.
- Start sandkassekopier ugentligt for at teste patchsæt før produktionsmiljøet ser dem.
- Forbered dig på det uundgåelige
- Kør øvelses-scenarier: sluk en tjeneste og se dashboards svinge; læringspunkterne holder bedre end slideshows.
- Hold et rent, bærbart image klar; en enkelt klik Køb Cloud Server giver dig en sikkerhedsventil når regioner bryder sammen.
Adopter først de dele der passer til din stack, så udvid dækningen. Små sejre, som automatisk tagging eller daglig nøgleomdrejning, staplet op over tid.
Afsluttende tanker
Cloud-adoption fortsætter opad, så at ignorere smertepunkterne er ikke en mulighed. Ved at sammenligne dit miljø med de vigtigste udfordringer for cloud-computing det som er beskrevet her, finder du svage områder tidligt, holder udgifter forudsigelige, og gør det muligt for udvikler at udrulning nye features med tillid. Rejsen slutter aldrig helt, men med klart blik, solidt værktøj og en vane med regelmæssig gennemgang forbliver cloud en accelerator i stedet for en kilde til opkald midt på natten.
Fart, konsistens og lufttæt sikring er indbygget i Cloudzy's VPS Cloud-portefølje. Hver instans kører på NVMe-lagerplads, høj-frekvente CPUs og redundante Tier-1-ruter, hvilket betyder arbejdsbelastninger lanceres hurtigt og forbliver responsive selv under stor belastning. Firewalls i virksomhedsklasse, isolerede lejere og kontinuerlig patching låser stakken uden at bremse noget. Hvis du vil købe en Cloudserver der flueskyder alle sikkerhed og pålidelighed, så kig ikke længere!


