
Abres la página GGUF de un modelo popular en Hugging Face y hay quince archivos mirándote de vuelta: Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, más carpetas separadas para GPTQ, AWQ y EXL2 en media docena de ajustes de bits. Haces el cálculo rápido para el archivo "de 4 bits": 4 bits × 8 mil millones de parámetros ÷ 8 = 4 GB. Pero el archivo dice 4,6 GB. Y una vez que lo cargas, el modelo usa aún más memoria que eso.
Los nombres de archivo no son ruido. Codifican información real y aprovechable sobre el ancho de bits, el runtime que los carga y el hardware que necesitan. Las tablas de dimensionamiento que has leído te dicen que un modelo de 70B necesita unos 40 GB, útil, pero nunca decodifican el propio formato ni explican por qué el modelo en ejecución quiere más memoria que el archivo en disco.
Así que aquí está el plan: decodificar la convención de nombres de GGUF (con los anchos de bits reales, no los nominales), determinar cuál de los cuatro formatos puede ejecutar realmente tu hardware, y tener en cuenta el único coste de memoria invisible en cada tamaño de archivo, la caché KV. Al final podrás leer un repositorio de modelos y predecir cómo se comportará al cargarse.
TL;DR
- Los niveles de cuantización de GGUF son anchos de bits efectivos, no el número exacto del nombre. Q4_K_M equivale a unos 4,89 bits por peso, por lo que un archivo "de 4 bits" de 8B se sitúa en torno a 4,6 GiB en lugar de la estimación ingenua de 4 bits.
- GGUF es la opción más portable porque llama.cpp puede ejecutarla en CPU, GPU o en una configuración híbrida. GPTQ, AWQ y EXL2 son más específicos de la GPU y del runtime, con EXL2 especialmente ligado a los flujos de trabajo NVIDIA/CUDA.
- La caché KV es independiente de los pesos del modelo y crece con la longitud del contexto. Es la razón por la que un modelo que carga correctamente puede seguir fallando por falta de memoria una vez que la conversación se alarga.
- Por encima del rango de 5 bits, la pérdida de calidad suele ser pequeña. En torno a Q4, el compromiso sigue siendo práctico para muchos casos de uso locales. Por debajo de 4 bits, el coste en calidad se vuelve mucho más notable. Q4_K_M sigue siendo un valor por defecto habitual en la comunidad, mientras que Q5_K_M y Q6_K son más seguros cuando te sobra memoria.
¿Qué significa Q4_K_M en un nombre de archivo GGUF?

Un nombre de cuantización GGUF sigue el patrón Q[bits]_[K]_[S/M/L]. El número es el número de bits objetivo por peso, K significa que es un "K-quant" que almacena factores de escala por cada pequeño bloque de pesos, y la S, M o L final es el nivel de tamaño/calidad (small, medium, large). Como los K-quants almacenan una escala y un valor mínimo por cada bloque además de los pesos, el ancho de bits efectivo es superior a la cifra destacada. Q4_K_M se sitúa en unos 4,89 bits por peso, no 4.
Esa diferencia responde por completo a la pregunta "¿por qué mi archivo de 4 bits pesa 4,6 GB?". La estimación ingenua asume que cada peso cuesta exactamente 4 bits. En realidad, los K-quants gastan bits adicionales por bloque en los metadatos que hacen precisa la cuantización de bajo número de bits, la escala y el mínimo por bloque que permiten al runtime reconstruir cada peso. Multiplica 4,89 bits por 8 mil millones de pesos y llegas cerca de 4,58 GiB, que es lo que realmente pesa el archivo.
Aquí están los anchos de bits efectivos y los tamaños de archivo medidos, tomados de llama.cpp quantize documentation para Llama 3.1 8B como modelo de referencia, junto con el coste de perplejidad de cada nivel medido en el artículo de evaluación de cuantización de llama.cpp (arXiv:2601.14277) sobre Llama-3.1-8B-Instruct:
| Nivel GGUF | BPW efectivo | ~Tamaño del archivo (8B) | Perplejidad vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | referencia |
*Las cifras de perplejidad son específicas de Llama-3.1-8B-Instruct, de arXiv:2601.14277. La columna de BPW/tamaño de archivo y la columna de perplejidad provienen de dos fuentes distintas, medidas por separado, así que lee la tabla como una referencia práctica lado a lado más que como el resultado de un único benchmark. La degradación varía según la tarea, el razonamiento matemático suele sufrir más que el razonamiento de sentido común a anchos de bits bajos, pero la tendencia general se mantiene: 5 bits o más suelen ser más seguros, Q4 es la zona de compresión práctica, y 3 bits es donde la pérdida de calidad se vuelve mucho más difícil de ignorar.
En la práctica: Q4_K_M es la opción por defecto a la que la mayoría debería recurrir, Q5_K_M y Q6_K son las opciones orientadas a la calidad cuando te sobra memoria, y cualquier cosa igual o por debajo de Q3_K_S es un último recurso para hardware que de verdad no puede alojar más.
¿Qué formato de cuantización deberías descargar: GGUF, GPTQ, AWQ o EXL2?

GGUF es el más portable de los cuatro: se ejecuta en CPU, GPU o una combinación de ambas mediante llama.cpp, por lo que es la opción más segura cuando no estás seguro de lo que tu hardware puede soportar. GPTQ, AWQ y EXL2 son más específicos de la GPU y del runtime. En la práctica, son más comunes en configuraciones NVIDIA/CUDA, pero el soporte de GPTQ y AWQ puede variar según el cargador y la pila de servicio; vLLM, por ejemplo, distingue el soporte de cuantización según el hardware y la implementación. Si estás ejecutando localmente en un Mac, una tarjeta AMD, o una máquina solo con CPU, GGUF sigue siendo la respuesta más segura. Si tienes una GPU NVIDIA y quieres los tokens más rápidos posibles, entran en juego los otros tres.
| Formato | Hardware/runtime | Velocidad (relativa) | VRAM vs competidores | Ideal para |
|---|---|---|---|---|
| GGUF Q4_K_M | El más amplio, CPU, GPU o híbrido a través de llama.cpp | Moderada | El más bajo | Cualquier hardware; opción local por defecto |
| GPTQ 4-bit | Generalmente CUDA/GPU en primer lugar; depende del runtime | Rápido (ExLlama) | Medio | GPU en primer lugar, herramientas heredadas |
| AWQ 4-bit | Generalmente CUDA/GPU en primer lugar; depende del runtime | Rápido | Más alta | Servido con vLLM/TGI, carga rápida |
| EXL2 ~4,9 bpw | NVIDIA/CUDA en primer lugar | Más rápido | Bajo-Medio | Velocidad máxima en NVIDIA |
Una salvedad sobre esa tabla: las clasificaciones de velocidad y VRAM provienen benchmark de oobabooga, que se realizó en hardware de la era 2023/2024. Trata el relativa clasificación como duradero. EXL2 está diseñado para la velocidad, AWQ cambia VRAM por carga rápida, GGUF sigue siendo ligero y portable, pero no leas las cifras absolutas originales de tokens por segundo como actuales. Una GPU de 2026 mostrará un rendimiento bruto muy distinto; lo que perdura es el orden jerárquico.
Así que la regla de decisión que se desprende de esto: si tienes una tarjeta NVIDIA y lo que más te importa es la velocidad, EXL2; si quieres la opción local por defecto más segura entre distintos hardware, GGUF. AWQ y GPTQ importan sobre todo cuando una pila de servicio específica (vLLM, TGI) o un conjunto de herramientas existente te lleva hacia allí.
¿Por qué un LLM local usa más memoria que su archivo?
El tamaño del archivo son solo los pesos del modelo. En tiempo de ejecución también pagas la caché KV (el estado de atención para cada token de tu ventana de contexto), las activaciones (el cálculo intermedio de una pasada hacia delante) y el sobrecoste del framework y del controlador. En conjunto, los elementos que no son pesos suelen añadir entre un 10 y un 20% por encima de los pesos para una configuración de un solo usuario, y la caché KV por sí sola puede eclipsar todo lo demás una vez que el contexto se alarga. Un archivo de 4,6 GB puede necesitar bastante más de 4,6 GB de memoria para funcionar.
Piensa en la memoria de ejecución como cuatro componentes apilados uno sobre otro:
- Pesos del modelo. El archivo que descargaste. Es la única pieza visible antes de cargar.
- Caché KV. El estado de atención de la ventana de contexto. Pequeño con contexto corto, enorme con contexto largo. Esta es la siguiente sección, porque es la que sorprende a la gente.
- Activaciones. La memoria de trabajo de una pasada hacia delante. Para inferencia local de un solo flujo (tamaño de lote 1), es pequeña, típicamente unos cientos de megabytes.
- Sobrecoste del framework. La huella propia del runtime más el contexto del controlador de la GPU. Para un runtime local ligero, esto puede ser pequeño en comparación con los pesos del modelo y la caché KV; los frameworks de servicio más pesados pueden reservar mucho más. La reserva de memoria propia de tu sistema operativo queda fuera de esto y es de nuevo independiente.
Los pesos y el sobrecoste del framework son predecibles. La caché KV es la variable que convierte un modelo que "cabe" en un modelo que falla, así que vale la pena hacer el cálculo real.
¿Cuánta memoria usa la caché KV?
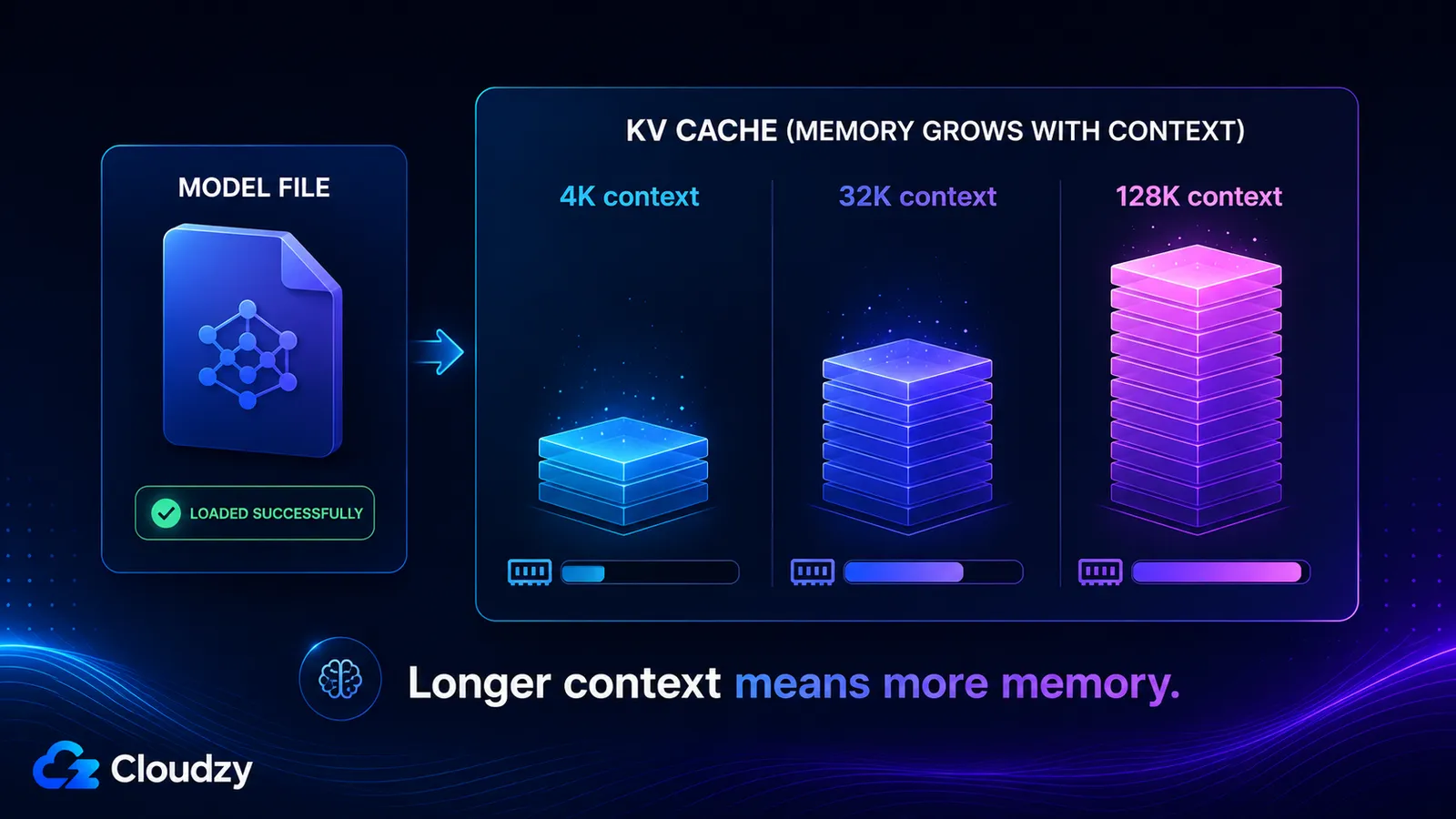
La caché KV almacena los vectores clave y valor de cada token de tu ventana de contexto, así que crece de forma aproximadamente lineal con la longitud del contexto y es completamente independiente de los pesos del modelo. Su tamaño lo determina el número de capas del modelo, su número de cabezas KV, la dimensión de cabeza, la longitud del contexto y la precisión de la caché. Activa un contexto largo y puedes añadir decenas de gigabytes de los que un modelo que cargaba sin problemas nunca te advirtió.
La fórmula es lo bastante corta para memorizarla:
Bytes de la caché KV = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
El 2 inicial corresponde a los dos tensores almacenados por token, uno para las claves, otro para los valores. bytes_per_element es 2 para una caché FP16. El resto son constantes de arquitectura que puedes leer en una ficha de modelo.
Calculémoslo para Llama 3.1 8B, que tiene 32 capas, 8 cabezas KV y una dimensión de cabeza de 128. Con un contexto de 4096 tokens, tamaño de lote 1, caché FP16:
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
Escala el contexto y la cifra escala con él, porque todos los términos excepto context_tokens son fijos:
- Contexto 4K: ~536 MB
- Contexto 32K: ~4,3 GB
- Contexto 128K: ~17 GB
Esas dos últimas cifras explican por qué un modelo puede declarar una ventana de contexto de 128K, cargar sin problemas, y luego agotar la memoria en el momento en que realmente usas esa ventana. La caché KV a contexto completo es mayor que los propios pesos cuantizados.
Aquí está la parte que hace posibles los modelos modernos de contexto largo: Llama 3.1 8B usa Grouped Query Attention (GQA)Tiene 32 cabezas de consulta pero solo 8 cabezas KV, la caché almacena vectores clave/valor para 8 cabezas, no 32. Aplica la misma fórmula con 32 cabezas KV (el diseño más antiguo Multi-Head Attention, donde las cabezas KV igualan a las cabezas de consulta) y cada cifra anterior se multiplica por 4. Esos 17 GB a 128K se convierten en 68 GB. GQA es la razón arquitectónica por la que el cálculo sigue siendo viable a medida que las ventanas de contexto han crecido.
El tamaño del archivo no es tu presupuesto de memoria. Cuando los pesos o la caché KV ya no caben en la ruta de memoria rápida y el runtime tiene que recurrir a la RAM del sistema a través de PCIe, el rendimiento no se degrada suavemente. Se desploma en cuanto mueves datos por PCIe en cada token. Presupuesta la memoria de forma que quepan tanto los pesos como la caché KV a tu longitud de contexto real, no solo los pesos.
¿Cómo eliges una cuantización para tu GPU o Mac?
Empieza por tu hardware y runtime. Los propietarios de GPU NVIDIA tienen el menú más amplio y deberían sopesar EXL2 por velocidad bruta o GGUF por portabilidad. Si estás en AMD, Apple Silicon, hardware solo con CPU, o una configuración mixta, GGUF a través de llama.cpp suele ser el punto de partida más seguro. A partir de ahí, elige el nivel de cuantización más alto que quepa una vez que hayas presupuestado la caché KV a la longitud de contexto que realmente usas, no al máximo del modelo.
Una trampa de Apple Silicon que conviene conocer: la GPU no recibe toda tu memoria unificada (consulta nuestro artículo complementario sobre qué es realmente la memoria unificada para una imagen completa de cómo funciona ese conjunto compartido). La comunidad de autoalojamiento ha documentado un límite de alrededor del 75% de la memoria unificada total disponible para la GPU documentado (Apple no lo confirma oficialmente y puede cambiar con las actualizaciones de macOS). Así que un "Mac de 64 GB" es realmente ~48 GB para el modelo más su caché KV, planifica con la cifra más baja.
Este artículo trata de leer el formato y predecir su comportamiento en tiempo de ejecución: decodificar el nombre de cuantización, elegir el formato que tu hardware soporta, y presupuestar la caché KV por separado de los pesos. Emparejar un modelo específico con una cantidad específica de memoria, la tabla de referencia de tamaño a memoria, es una cuestión relacionada pero distinta que abordaremos en un futuro artículo complementario.
Lee el repositorio
Ahora puedes mirar la página de un modelo y leerla en lugar de adivinar. Decodifica el nombre de cuantización a su ancho de bits efectivo, reconoce que GGUF es el formato local más amplio mientras que GPTQ, AWQ y EXL2 son más específicos del runtime, y recuerda que el tamaño del archivo es solo el suelo, la caché KV se apila encima y crece con tu contexto. Abre los archivos del modelo que quieres, elige el formato que tu hardware puede ejecutar, escoge el nivel de cuantización más alto que quepa una vez que hayas dejado margen para la caché KV a tu longitud de contexto real, y evitarás el fallo por falta de memoria que dio origen a toda esta pregunta.
Preguntas frecuentes
¿Qué significa Q4_K_M?
Q4_K_M es un nivel de cuantización de GGUF: aproximadamente 4 bits por peso (Q4), usando el escalado por bloque de K-quant (K), en el nivel de tamaño/calidad medio (M). Su ancho de bits efectivo efectivo es de unos 4,89 bits por peso, no exactamente 4, porque los K-quants almacenan una escala y un valor mínimo para cada bloque de pesos. Por eso un archivo de modelo 8B "de 4 bits" pesa unos 4,6 GB en lugar de 3,5 GB.
¿La cuantización reduce la calidad de los LLM?
Sí, pero el coste depende en gran medida de hasta dónde lo lleves. En Llama-3.1-8B-Instruct medido en arXiv:2601.14277, la perplejidad solo sube alrededor de un 0,4% en Q6_K y se mantiene cerca del 1% en toda la banda Q5. Baja a Q4 y el aumento sigue siendo modesto (unos pocos puntos porcentuales); por debajo de Q3_K_M sube bruscamente, alcanzando +22% en Q3_K_S. Para la mayoría de los usos, Q4_K_M y superior es efectivamente sin pérdidas; la penalización fuerte vive en 3 bits y por debajo.
¿Cuál es la diferencia entre GGUF, GPTQ, AWQ y EXL2?
GGUF (ejecutado por llama.cpp) es el formato portable, funciona en CPU, GPU o una configuración híbrida en una amplia gama de hardware. GPTQ, AWQ y EXL2 son más específicos de la GPU y del runtime. En 4 bits, los cuatro pueden situarse en una banda de calidad estrecha, así que la diferencia práctica está en el hardware, el soporte del cargador, la velocidad y el uso de VRAM: EXL2 es la elección centrada en velocidad para NVIDIA/CUDA, AWQ es habitual en pilas de servicio, GPTQ encaja con herramientas de GPU y repositorios de modelos más antiguos, y GGUF sigue siendo la opción local más portable.
¿Por qué mi LLM local usa más memoria que el archivo?
El tamaño del archivo son solo los pesos del modelo. En tiempo de ejecución también pagas la caché KV (el estado de atención para cada token de la ventana de contexto), las activaciones, y el sobrecoste del framework más el controlador. La caché KV suele ser la culpable cuando la diferencia es grande, porque crece con la longitud del contexto y se asigna por separado de los pesos, un modelo cuyo archivo pesa unos pocos gigabytes puede necesitar mucha más memoria una vez que fijas un contexto largo.
¿Cómo afecta la longitud del contexto al uso de memoria?
La caché KV crece de forma aproximadamente lineal con la longitud del contexto, así que duplicar tu contexto duplica aproximadamente la caché. Para Llama 3.1 8B, la caché es de unos 536 MB a 4K tokens, ~4,3 GB a 32K, y ~17 GB a 128K (FP16, un solo flujo). Ese crecimiento es totalmente independiente de los pesos del modelo, por lo que declarar una ventana de contexto larga puede llevar a un modelo a quedarse sin memoria aunque cargara sin problemas.


