
El bucle funcionó sin problemas cuarenta veces durante las pruebas. En la ejecución número cuarenta y uno, en producción, llamó una y otra vez a la misma herramienta SQL con la misma consulta rota hasta que agotó el presupuesto diario de API y una alerta de facturación finalmente despertó a alguien. Nadie escribió un modelo deficiente. Nadie cambió el prompt. El agente simplemente nunca decidió que había terminado.
Este es el patrón que sigo viendo en los equipos que llevan un agente de un prototipo a una carga de trabajo 24/7. Los bucles de agentes de IA a menudo fallan en producción no porque el modelo haya empeorado de repente, sino porque la capa de ejecución carece de disciplina de terminación, contratos de herramientas validados, contexto acotado y estado duradero. Un bucle de agente es un sistema estocástico que toma una decisión secuencial tras otra. Sin unos pocos guardianes específicos, el fallo excepcional se convierte en un fallo garantizado una vez que se ejecuta el tiempo suficiente. Las plataformas de agentes gestionados (Vertex AI Agent Builder, Bedrock Agents, Azure AI Foundry) integran algunos de estos guardianes; esta guía es para quienes elegimos autoalojar y controlar el bucle nosotros mismos.
Las consecuencias son lo suficientemente reales como para que Gartner prevea que más del 40% de los proyectos de IA agentiva sean cancelados antes de finales de 2027, citando costes crecientes y valor poco claro. Lo que sigue son seis formas concretas en que los bucles fallan en producción, el mecanismo detrás de cada una y el patrón de harness que lo soluciona, con los detalles de LangGraph y n8n, además de lo que hace falta para ejecutar esto realmente 24/7.
La versión corta
- Bucles infinitos: El agente nunca decide que ha terminado. Combina un límite máximo de pasos (el
recursion_limitde LangGraph, 25 por defecto) con detección de falta de progreso que elimina llamadas repetidas a herramienta+argumento. - Desbordamiento de contexto: El bucle llena su propia ventana de contexto con el historial acumulado hasta que las llamadas se truncan o fallan. Resume el historial a intervalos fijos para que el contexto de trabajo se mantenga acotado.
- Fallos silenciosos de herramientas: Una herramienta devuelve una cadena vacía, el modelo lo interpreta como una operación válida sin efecto, y el agente "tiene éxito" sin hacer nada. Valida cada resultado de herramienta antes de que lo vea el modelo.
- Degradación del razonamiento: La calidad decae a medida que crece el contexto, incluso por debajo del límite máximo. Comprime a mitad del bucle, pero protege las instrucciones de seguridad fijadas cuando lo hagas.
- Pérdida de estado al reiniciar: Un fallo implica empezar desde cero. Guarda checkpoints en Postgres (LangGraph
PostgresSaver), no en SQLite, para producción. - Tormentas de reintentos: Diez agentes que reintenten diez veces cada uno envían cien peticiones a un servicio caído. Añade backoff exponencial con jitter y un circuit breaker global.
Lo que esta guía no cubre
Esta es una guía de harness, centrada en la ingeniería alrededor del bucle, no en el modelo dentro de él. Algunos temas relacionados quedan deliberadamente fuera del alcance:
- Fallos de coordinación entre agentes (lecturas obsoletas, estado huérfano entre agentes): un problema diferente que merece su propio artículo.
- Seguridad del agente (inyección de prompts, envenenamiento de herramientas): una categoría de fallo separada con su propio modelo de amenazas.
- Selección y ajuste fino del modelo. Esta guía asume que ya has elegido un modelo y estás depurando el sistema a su alrededor.
- Servicios de agentes gestionados, mencionados anteriormente; los patrones aquí son para la ruta de autoalojamiento.
Bucles infinitos: cuando el agente nunca decide que ha terminado

Un agente entra en un bucle infinito cuando no tiene ni un límite máximo de pasos ni una forma de detectar que ha dejado de avanzar. La solución tiene dos partes: mantener un límite máximo como tope de costes y añadir detección de falta de progreso que calcula un hash de cada llamada herramienta+argumento y termina cuando detecta que la misma llamada se repite. En LangGraph ese límite es el recursion_limit, 25 pasos por defecto; si se supera, el grafo lanza una excepción GraphRecursionError.
La documentación de LangGraph describe ese límite como alcanzar "el número máximo de pasos antes de llegar a una condición de parada", y aquí está la trampa que conviene entender: el recursion_limit no es protección contra bucles. Es un tope que se activa después que el bucle ya ha malgastado veinticinco pasos y el gasto de API que los acompaña. Se supone que la lógica de terminación aprendida por el propio agente lo detiene mucho antes, y esa lógica puede fallar de forma independiente. Un caso reportado de LangGraph muestra un agente de text-to-SQL en bucle hasta alcanzar el recursion_limit a pesar de tener condiciones de parada claras en el prompt. Seguía llamando a la misma herramienta de consulta con el mismo SQL fallido, y el caso se cerró como "no planificado". Lo interpreto como una señal clara: no trates el límite como tu condición de parada. Es tu cinturón de seguridad, no tus frenos.
Aumentar el límite es sencillo; se pasa a través de la configuración al invocar el grafo:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)Lo que realmente detiene un bucle atascado es la detección de progreso. El mecanismo es simple: calcula un hash del nombre de la herramienta más sus argumentos en cada paso, mantén una ventana corta de hashes recientes y detén la ejecución cuando detectes una repetición.
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)Esto detecta al agente que técnicamente está "en ejecución" (llamando a herramientas, generando tokens) pero que cicla sobre la misma acción fallida. El modo de fallo nombrado aquí se corresponde con lo que la taxonomía MAST (IBM Research y UC Berkeley) llama Unaware of Termination Conditions (FM-1.5), uno de los modos de fallo que su análisis asocia con el fracaso total de la tarea.
Un límite de pasos detiene los costes desbocados. La detección de falta de progreso detiene el bucle que técnicamente "avanza" pero que se repite. La producción necesita ambos.
Desbordamiento de la ventana de contexto: cuando el bucle llena su propio contexto con basura
Un bucle de larga duración acumula cada salida de herramienta, cada pensamiento intermedio y cada mensaje que ha producido, y luego mete todo eso de vuelta en la ventana de contexto en cada turno. Con el tiempo la ventana se llena, y las llamadas se truncan silenciosamente o fallan del todo. La solución es la resumización del contexto a intervalos fijos: cada N pasos, comprime el historial acumulado en un resumen progresivo para que el contexto de trabajo se mantenga acotado.
Imagina un agente de investigación que lleva una hora en ejecución. En el paso 60 ya carga el texto completo de cada página que ha consultado, cada resultado de búsqueda, cada traza de razonamiento. Nada de ese historial bruto le ayuda en el paso 61, pero todo ello cuenta contra la ventana, y el modelo está gastando presupuesto de atención en tokens que ya no necesita. Cuando la ventana se llena, el proveedor trunca desde un extremo, y el agente pierde silenciosamente la instrucción que recibió al principio.
El disparador es una decisión de ajuste, y hay un punto de referencia útil para ello. El writeup de Mem0 sobre un sistema real en producción indica que el compresor del agente Hermes "se activa al 50% de la ventana de contexto del modelo por defecto", con una red de seguridad secundaria al 85% para sesiones que se disparan entre turnos. El 50% es un buen punto de partida: comprimir con suficiente antelación para que una sola salida de herramienta grande no supere el límite antes de la siguiente compresión programada.
Nota: El overflow y la degradación del razonamiento son problemas distintos, y la siguiente sección trata el segundo. El overflow es un límite absoluto: se acaban los tokens. La degradación es gradual: el modelo pierde calidad. antes de alcanzar ese límite. Hay que manejar ambos, y el umbral de disparo indicado arriba protege contra el límite duro.
El contexto acotado es responsabilidad del harness, no una característica del modelo. Resume a intervalos antes de que la ventana fuerce un truncado silencioso.
Fallos silenciosos de llamadas a herramientas: cuando el agente "tiene éxito" sin hacer nada
Una llamada a herramienta devuelve una cadena vacía o un mensaje suave de "no se encontraron resultados", el modelo lo interpreta como un resultado válido, y el agente continúa como si el paso hubiera funcionado, aparentando tener éxito sin hacer nada en absoluto. La solución es una puerta de validación en cada retorno de herramienta: valida el esquema o comprueba el resultado antes de que el modelo lo vea, y devuelve un fallo real que el bucle tenga que gestionar en lugar de un éxito vacío.
Este caso es insidioso porque nada falla. Un desarrollador que documentaba modos de fallo silenciosos en agentes en producción lo expresó directamente: los modelos interpretan las cadenas vacías genéricas como operaciones válidas sin efecto y continúan ejecutándose sin conciencia del fallo. La consulta a la base de datos que devolvió cero filas porque se cayó la conexión es idéntica, para el modelo, a la consulta que legítimamente no encontró nada. Así que el agente reporta "no hay registros coincidentes" y sigue adelante, y te enteras una semana después de que un tercio de sus ejecuciones estaban silenciosamente rotas.
La puerta de validación se sitúa entre la herramienta y el modelo:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the modelLa cuestión no es qué comprobaciones exactas hacer; las tuyas dependerán de lo que cada herramienta devuelve legítimamente. La cuestión es que un valor de retorno sin validar es una decisión que le has entregado a un modelo estocástico, y la respuesta por defecto del modelo es seguir adelante.
Un retorno de herramienta sin validar es un fallo silencioso esperando a ocurrir. Valida la salida; no te fíes solo de la llamada.
Degradación del razonamiento en contextos largos: cuando el agente empeora cuanto más tiempo lleva en ejecución
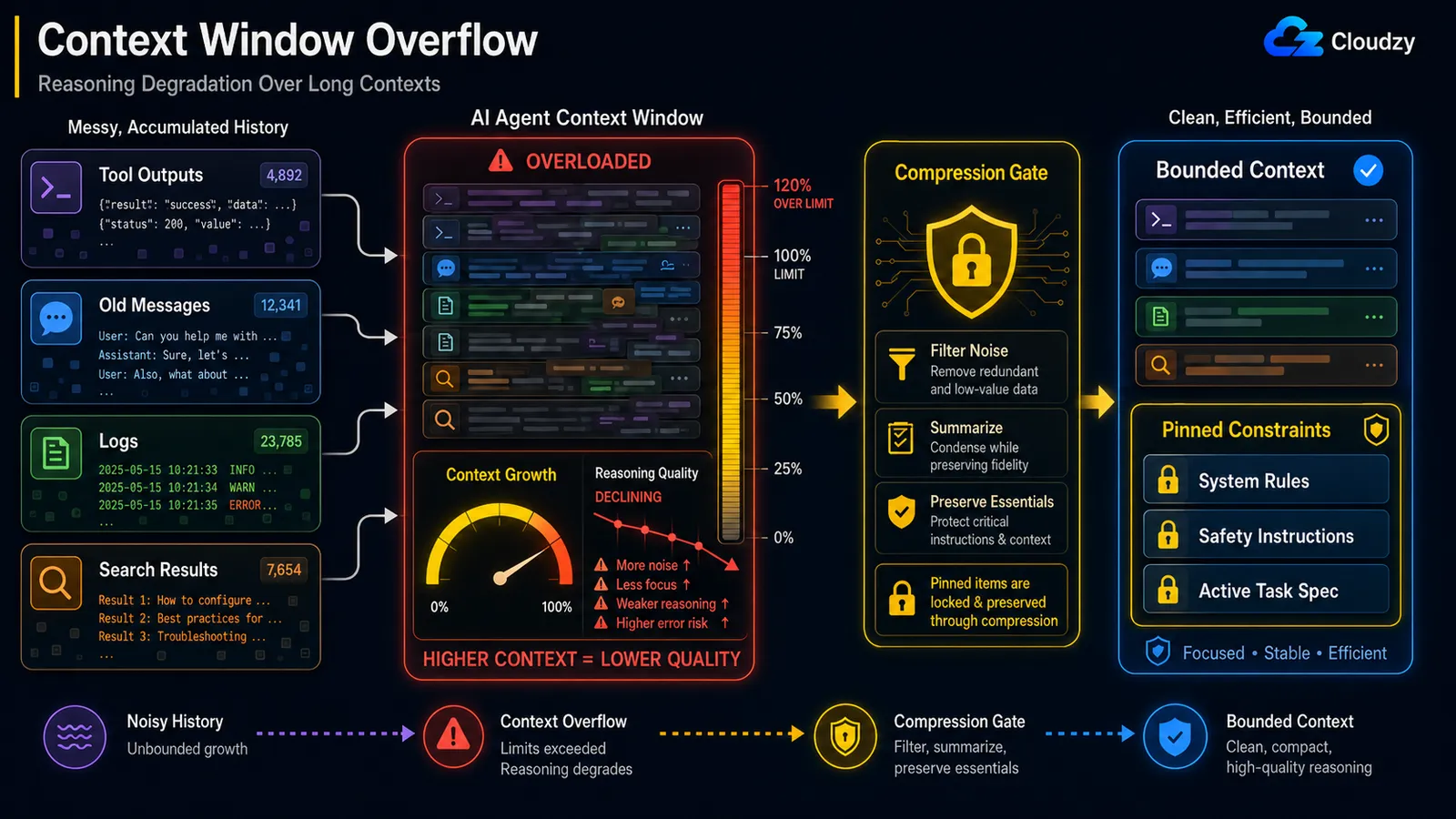
Incluso cuando te mantienes por debajo del límite duro de contexto, la calidad del razonamiento decae a medida que el contexto crece. Este es el efecto "lost in the middle": el modelo atiende de forma fiable al principio y al final de un contexto largo, pero pierde el medio. La solución es la compresión a mitad del bucle que preserva las restricciones fijadas: comprime el ruido, protege las instrucciones que sostienen el sistema.
El mecanismo tiene nombre. El blog de ingeniería de Anthropic lo menciona como context rot: : "a medida que aumenta el número de tokens en la ventana de contexto, la capacidad del modelo para recordar con precisión la información de ese contexto disminuye." Porque "cada token atiende a cada otro token", obtienes n² relaciones por pares para n tokens, y la atención del modelo se estira más conforme se alarga el contexto.
Ese matiz, proteger las instrucciones que sostienen el sistema, es lo que marca la diferencia, y hay un incidente documentado que explica por qué. En un caso reportado, un agente OpenClaw eliminó en masa la bandeja de entrada de un usuario durante una compactación de contexto, porque la instrucción de seguridad que se le había dado ("no tomes acción hasta que te lo indique") fue eliminada del contexto activo cuando el historial se comprimió. La restricción que debería haber sido lo último en descartarse fue tratada como historial ordinario y resumida.
Así que un simple "resume todo lo anterior a N turnos" es peligroso. La compresión debe saber qué nunca puede eliminar:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactEsto es distinto del problema de desbordamiento de la sección anterior. El desbordamiento es quedarse sin espacio; la degradación es que el modelo empeore mientras todavía queda espacio. Puedes estar al 60% de tu ventana y ya estar razonando mal.
Nota: Una compresión que elimina una restricción de seguridad es una clase de error diferente a una compresión que pierde un resultado de búsqueda obsoleto. Etiqueta las restricciones, la especificación de la tarea y cualquier instrucción "no hagas X" como fijadas, y exclúyelas por completo del resumidor.
Una compresión que elimina una instrucción de seguridad es peor que ninguna compresión. Protege las restricciones fijadas cuando comprimas.
Pérdida de estado al reiniciar: cuando un fallo significa empezar de cero
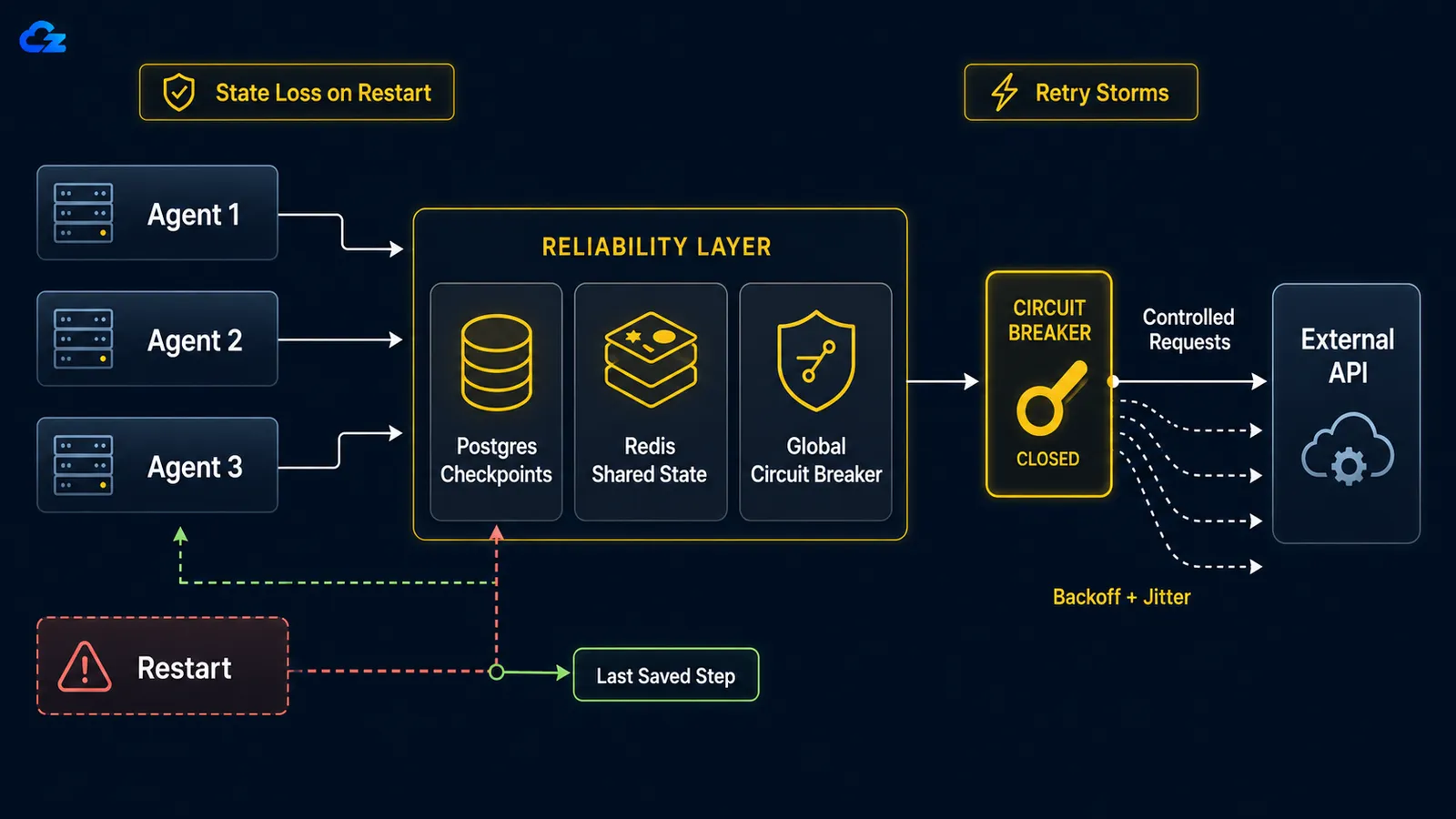
Cuando un agente de larga duración falla, ya sea por un reinicio, un OOM kill o una conexión de red cortada, no hay reanudación desde un checkpoint por defecto. El bucle empieza desde cero: rehace el trabajo que ya había completado y, lo que es peor, puede volver a ejecutar acciones que ya realizó, como enviar el mismo correo dos veces o repetir una llamada de API de pago. La solución es el checkpointing: persiste el estado del bucle tras cada paso para que un reinicio se rehidrate desde donde se detuvo en lugar de desde el principio.
En LangGraph, la elección del backend de checkpoint es la elección entre desarrollo y producción. La documentación de persistencia de LangGraph describe SqliteSaver como "ideal para experimentación y flujos de trabajo locales" y PostgresSaver como "ideal para uso en producción", y este último es sobre el que corre el propio LangSmith. Los dos son deliberadamente paralelos en código, lo que facilita ver el contraste:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverDos detalles que suelen causar problemas. Primero, los paquetes de checkpoint se instalan por separado del núcleo de LangGraph (langgraph-checkpoint-sqlite y langgraph-checkpoint-postgres son dependencias propias), así que un servidor nuevo no tendrá el saver de Postgres hasta que lo añadas. Segundo, cada operación de checkpoint necesita un thread_id en la configuración. Ese ID es lo que vincula una ejecución concreta con su estado guardado, y un reinicio sin el thread_id correcto no rehidrata nada.
Consejo pro: Los paquetes de checkpoint de LangGraph se instalan por separado.
langgraph-checkpoint-postgresno se incluye con el paquete baselanggraph, así que añádelo a tu archivo de requisitos de producción antes de descubrirlo de la peor manera durante un incidente.
n8n tiene la misma división entre desarrollo y producción, solo que con nombres distintos. Su opción de memoria integrada también se llama Simple Memory (o Buffer Window Memory), y la ruta de producción es el nodo Postgres Chat Memory para el estado que debe sobrevivir un reinicio. La memoria integrada mantiene la conversación en el proceso en ejecución, lo cual está bien para pruebas y es una responsabilidad para una carga de trabajo 24/7. Practicantes que ejecutan agentes n8n en producción reportan haber tenido que migrar a un almacén respaldado por Postgres después de que la memoria en proceso creciera hasta tumbar la instancia. Si usas n8n y tu agente necesita recordar algo entre reinicios, conéctalo a Postgres Chat Memory desde el principio.
El checkpointing en SQLite es una conveniencia de desarrollo. Sobrevivir un reinicio en producción requiere Postgres (LangGraph) o un almacén respaldado por Postgres (n8n).
Tormentas de reintentos: cuando tus propios agentes hacen DDoS a un servicio caído
Cuando un servicio externo cae, los reintentos ingenuos por ejecución convierten tu flota de agentes en una denegación de servicio autoinfligida. La solución tiene dos mitades: backoff exponencial con jitter en cada agente para distribuir los reintentos en el tiempo, y un circuit breaker global que se dispara tras un umbral compartido de fallos y detiene a toda la manada para que no siga machacando un servicio que claramente está caído.
La matemática es implacable. Como lo expresa un artículo sobre patrones de reintento : con diez agentes paralelos que reintenten diez veces cada uno, envías cien peticiones a un servicio que ya está en el suelo, porque el backoff de cada agente es por ejecución, no global. El backoff por agente solo no resuelve esto. Diez agentes que cada uno aplica backoff correctamente siguen haciéndolo al unísono si todos empezaron al mismo tiempo, así que reintentarán en oleadas sincronizadas. El jitter rompe la sincronización aleatorizando la espera de cada agente; el circuit breaker rompe la manada compartiendo un único dato de estado de fallo entre todos.
La mitad del backoff es un problema resuelto en Python; la librería tenacity gestiona el exponencial-con-jitter limpiamente:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)El circuit breaker es la mitad que debe ser global: compartido entre todos los agentes, no reinstanciado por ejecución. Cuando los fallos superan un umbral, se abre, todos los agentes fallan rápido en lugar de llamar al exterior, y tras un periodo de enfriamiento deja pasar una única prueba para verificar si el servicio ha vuelto. Un breaker que vive dentro del proceso de cada agente no protege nada, porque nada se comparte; el servicio caído sigue recibiendo las cien peticiones completas.
El backoff por ejecución sigue permitiendo que diez agentes machaquen un servicio caído al unísono. El circuit breaker debe ser global para detener a la manada.
Los seis fallos de un vistazo
Antes de la parte de infraestructura, aquí está todo el catálogo en un solo lugar: el fallo, el mecanismo que lo provoca, la corrección en el harness y dónde vive el parámetro relevante en cada framework.
| Modo de fallo | Mecanismo | Corrección en el harness | Parámetro del framework |
|---|---|---|---|
| Bucle infinito | Sin límite de pasos ni comprobación de progreso | Límite máximo + detección de falta de progreso | LangGraph recursion_limit (25) / n8n Max Iterations |
| Desbordamiento de contexto | El historial crece hasta que se llena la ventana | Resumización por intervalos | A nivel de aplicación (comprime al ~50% de la ventana) |
| Fallo silencioso de herramienta | Los retornos vacíos o suaves se leen como operaciones válidas sin efecto | Puerta de validación en cada resultado de herramienta | Wrapper de herramienta a nivel de aplicación |
| Degradación del razonamiento | La atención decae conforme crece el contexto ("context rot") | Compresión a mitad del bucle que protege las restricciones fijadas | A nivel de aplicación, con conciencia de restricciones |
| Pérdida de estado al reiniciar | Sin checkpoint; el bucle reinicia desde cero | Checkpointing persistente | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| Tormenta de reintentos | Los reintentos por ejecución se propagan en cascada sobre un servicio caído | Backoff + jitter + circuit breaker global | tenacity + estado compartido del breaker |
Una nota para los lectores que usan CrewAI, AutoGen, Dify o un bucle Python personalizado: los parámetros del framework cambian, pero los seis patrones no. La deduplicación, la resumización por intervalos, la validación de esquemas, la compresión con conciencia de restricciones, el checkpointing y un circuit breaker global son conceptos independientes del framework. Los detalles específicos de LangGraph y n8n aquí son ejemplos concretos, no el límite de dónde aplican los patrones.
Dimensionar un despliegue de agentes en producción
Cada patrón anterior asume que controlas el gestor de procesos, la base de datos y el comportamiento al reiniciar. El checkpointing no sirve de nada si un bucle que falla nunca vuelve a levantarse, y un circuit breaker global necesita un lugar donde guardar su estado compartido. Ese control es exactamente lo que el autoalojamiento te da y una caja negra gestionada no, así que la última decisión es dimensionar el servidor que lo ejecuta 24/7.
Para la mayoría de despliegues de un solo agente (un agente, llamadas LLM saliendo a una API externa, checkpointing básico con Postgres) una instancia pequeña es suficiente: alrededor de 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage. La computación pesada vive en el lado del proveedor del modelo; tu servidor orquesta, guarda checkpoints y mantiene el estado, no ejecuta inferencia. Sube a aproximadamente 4 GB RAM, 2 vCPU, and 120 GB NVMe cuando el agente es con estado y multipaso con checkpointing en Postgres más Redis para la hidratación de sesiones, o cuando estás ejecutando flujos de trabajo concurrentes que comparten el host.
La razón por la que esto quiere un VPS autogestionado en lugar de una plataforma restringida es la misma razón por la que las correcciones funcionan: necesitan acceso root. Tu propio Postgres para el checkpointing, tu propio Redis para el estado de sesión, y un gestor de procesos real como systemd or pm2, para que cuando un bucle muera, el supervisor lo reinicie y se rehidrate desde su último checkpoint en lugar de empezar el trabajo desde cero. Todo ese proceso de recuperación depende de ser propietario del ciclo de vida del proceso.
Dado que ejecutamos n8n como aplicación de un clic en nuestro propio marketplace, esa parte de la configuración es el camino más corto por nuestra parte: puedes desplegar n8n en un VPS de Cloudzy con la configuración respaldada por Postgres que necesita la ruta de producción, en una instancia donde tienes acceso root para añadir tu propio Redis y supervisión de procesos. Es el mismo footprint de autoalojamiento descrito arriba, donde controlas la base de datos y el comportamiento al reiniciar, que es lo que hace que el checkpointing y la recuperación automática funcionen de verdad.
Los patrones del harness son tan fiables como el servidor en el que corren. El checkpointing no sirve de nada si el proceso nunca se reinicia.
Preguntas frecuentes
¿Cómo evito que mi agente LangGraph entre en un bucle infinito?
Usa dos mecanismos juntos. Establece recursion_limit como límite máximo de pasos (el valor por defecto es 25) para que un bucle desbocado no pueda consumir presupuesto ilimitado, y añade detección de falta de progreso que calcula un hash de cada llamada herramienta+argumento y termina cuando la misma llamada se repite dentro de una ventana reciente. El límite solo es un tope que se activa después de que el gasto ha ocurrido, no una protección real contra bucles. La detección de progreso es lo que realmente detiene un bucle atascado.
¿Cuál es el recursion_limit correcto para LangGraph en producción?
No hay un número universal. Ajústalo al número máximo de pasos que tu agente debería necesitar legítimamente, más un margen, y trátalo estrictamente como un tope de costes. Aumentar el límite no hace que un agente en bucle converja. Si tu agente está alcanzando un límite alto, la solución es la detección de progreso, no un límite más alto.
¿Por qué mi agente de IA en n8n sigue alcanzando el Max Iterations?
Alcanzar el límite de Max Iterations significa que el agente no está convergiendo: está tomando más pasos de los que el límite permite sin llegar a una parada. Aumenta el límite solo si la tarea legítimamente necesita más pasos; de lo contrario, trátalo como una señal de que el agente está atascado. Ten cuidado con una trampa específica: GitHub issue #22771 reporta que cuando se alcanza el límite de iteraciones con "On Error: Continue" activado, la ejecución puede enrutarse a la salida de éxito en lugar de a la de error, así que una ejecución fallida y limitada puede parecer un éxito en tu flujo de trabajo.
¿Cómo persisto el estado del agente entre reinicios?
En LangGraph, usa checkpointing con PostgresSaver en lugar de SqliteSaver, que está pensado para desarrollo local. En n8n, usa el nodo Postgres Chat Memory en lugar de la memoria integrada en proceso. Ambos requieren una base de datos persistente, y en LangGraph cada operación de checkpoint necesita un thread_id que vincule una ejecución concreta con su estado guardado.
¿Qué causa la degradación del razonamiento en ejecuciones largas de agentes?
La calidad del razonamiento cae a medida que crece el contexto, incluso antes de alcanzar el límite duro de tokens. Este es el efecto "lost in the middle": el modelo atiende al principio y al final de un contexto largo, pero pierde el medio. El blog de ingeniería de Anthropic describe el mecanismo subyacente como "context rot": dado que cada token atiende a cada otro token, obtienes n² relaciones por pares y la atención del modelo se estira más conforme se alarga el contexto. La solución es la compresión a mitad del bucle que resume el historial obsoleto manteniendo intactas las restricciones fijadas y las instrucciones de seguridad.


