
En 2024, une équipe de Google Research et de Google DeepMind a montré qu'un modèle neuronal pouvait simuler DOOM jouable à plus de 20 images par seconde sans faire tourner le moteur de jeu d'origine en dessous. Il n'y avait aucune boucle de moteur classique stockant explicitement les coordonnées, les objets physiques, les variables de santé ou l'état de la carte de la manière habituelle. À la place, GameNGen a appris à déduire l'image suivante à partir des images récentes et des entrées du joueur, y compris des indices visuels comme la santé, les munitions, les ennemis, les portes et les murs. Le système, appelé GameNGen, est une version modifiée de Stable Diffusion (le même type de modèle qui génère des images à partir de texte), et il joue à DOOM en hallucinant chaque image suivante à partir des images précédentes et de la touche que vous venez d'appuyer.
C'est une chose fondamentalement différente de « l'IA à l'intérieur d'un moteur de jeu ». Quand un studio utilise l'IA pour générer des textures ou écrire des dialogues de NPC dans Unity, le moteur est toujours là à faire le vrai travail. GameNGen n'a aucun moteur. Le modèle is le jeu. Et c'est le début d'une véritable frontière que les gros titres ne cessent de mal comprendre. GameNGen est apparu via la piste de recherche ICLR, DIAMOND est arrivé via NeurIPS 2024, et des entreprises comme Google DeepMind, Microsoft Research, Decart et Skywork AI font désormais passer l'idée des articles aux démos, aux API et aux systèmes open source.
Voici ce que ces systèmes font réellement, comment fonctionne la prédiction d'image suivante, pourquoi la cohérence et la mémoire continuent de se dégrader sur une interaction plus longue, ce qu'ils coûtent à faire tourner, et s'ils s'apprêtent à remplacer Unity. La réponse courte à cette dernière question est non, du moins pas de la façon que le battage médiatique laisse entendre. La raison est architecturale : plus de puissance de calcul aide, mais cela ne crée pas en soi un état persistant, une logique déterministe ou une boucle de jeu déboguable.
La version courte
- Ces modèles prédisent des images ; ils ne simulent pas des règles. Un moteur de jeu calcule l'état suivant à partir d'une logique et de variables stockées. Un modèle de monde comme GameNGen ou Oasis devine l'image suivante à partir des images précédentes et de votre entrée. Il ne fait pas tourner une simulation de moteur de jeu traditionnelle avec un état d'objet explicite, du code physique et des variables inspectables ; il génère l'observation suivante au moyen d'un modèle appris.
- Leur cohérence reste limitée par la mémoire et le contexte, mais la limite n'est plus aussi simple que « tout échoue après quelques secondes ». GameNGen dispose d'un peu plus de 3 secondes d'historique direct des images, et peut pourtant rester visuellement stable sur des trajectoires plus longues grâce à des heuristiques apprises. Genie 2 montrait généralement des exemples de 10-20 secondes et pouvait parfois préserver des détails hors champ, tandis que Genie 3 pousse la cohérence jusqu'à quelques minutes en 720p/24fps. La faiblesse fondamentale demeure : ces systèmes ne fournissent pas encore l'état durable, inspectable et sauvegardable sur lequel reposent les jeux de production.
- Ils ne sont pas naturellement déterministes de la manière dont les jeux de production en ont besoin. Vous pouvez contraindre l'échantillonnage ou fixer des graines, mais cela ne vous donne toujours pas les mises à jour d'état propres et inspectables d'un moteur normal. Le multijoueur, l'équilibrage compétitif, les rejeux, la progression de compétence et la sauvegarde/le chargement dépendent tous de transitions d'état fiables. Un générateur d'images peut approximer ce comportement, mais un jeu de production aurait quand même besoin d'une couche de logique déterministe en dessous ou à côté de lui.
- DeepMind présente les modèles de monde comme une base pour entraîner et évaluer des agents d'IA dans des environnements simulés riches, tandis que Project Genie montre la même technologie dans un prototype de création de mondes destiné au grand public. Le plus récent Oasis 3 de Decart vise encore plus explicitement l'IA physique, la robotique et la simulation de véhicules autonomes. Cela recadre la question « est-ce que ça va remplacer Unity ? » : le marché le plus sérieux à court terme pourrait être l'entraînement d'agents et la simulation, et non des jeux grand public finis.
Ce que cet article n'aborde pas
Quelques sujets voisins se retrouvent mêlés à la même conversation et n'ont pas leur place ici :
- DLSS, FSR, l'upscaling et la génération d'images. Il s'agit là de l'IA qui remplace des étapes individuelles of a normal rendering pipeline; the engine is still running. That's a separate topic, neural rendering, and not what this article covers.
- La méthodologie détaillée d'apprentissage par renforcement utilisée pour rassembler les données d'entraînement. Je la décrirai à un niveau conceptuel ; les articles contiennent la recette complète.
- L'hébergement de serveurs de jeu et la configuration de l'infrastructure. Ceci est une explication du fonctionnement des modèles, pas un guide de déploiement.
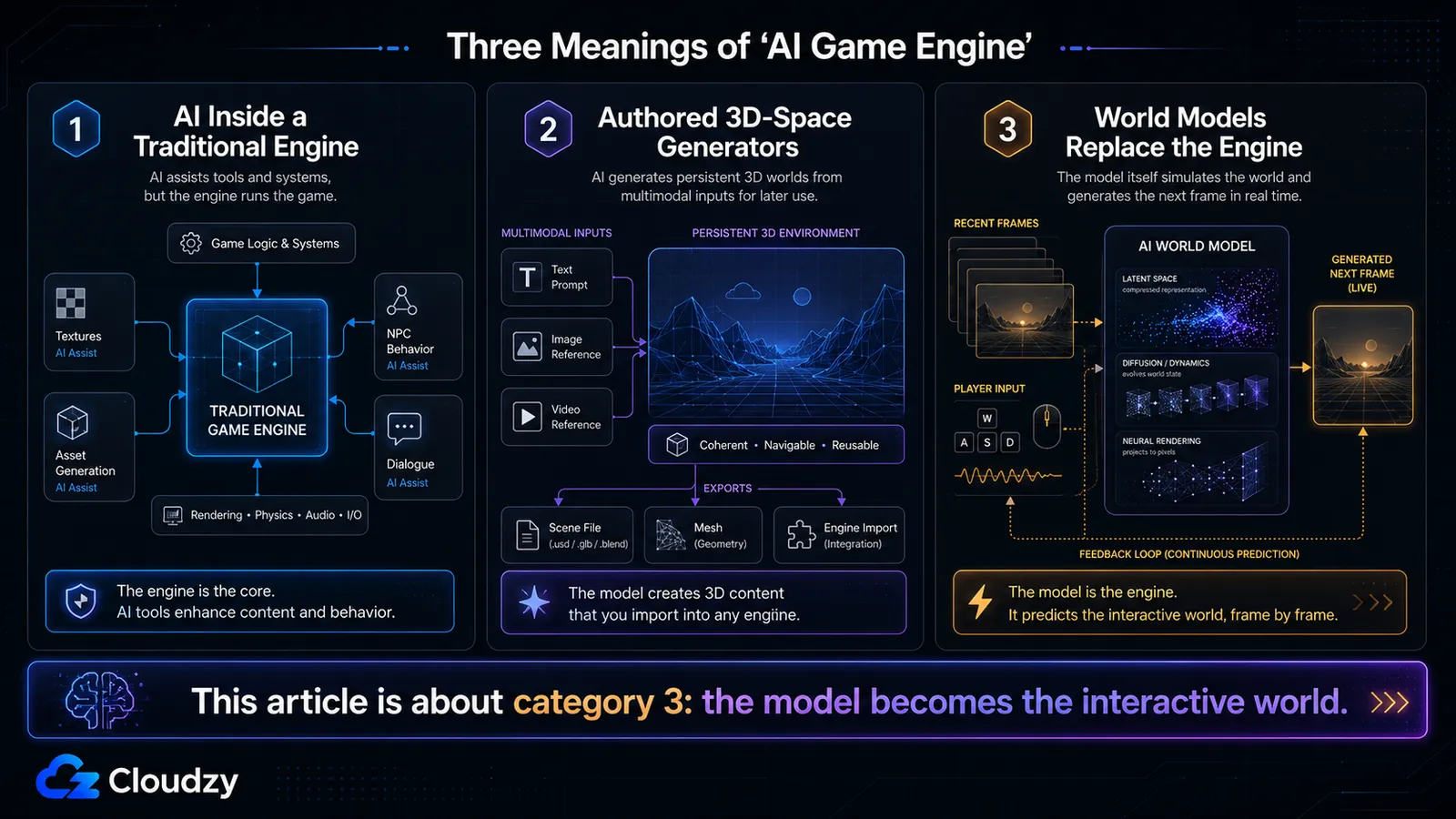
Ce que les gens entendent par « moteur de jeu IA » (et lequel il s'agit ici)
L'expression « moteur de jeu IA » se voit accolée à trois choses complètement différentes, et la plus grande partie de la confusion sur ce sujet vient du fait qu'on les amalgame. Cet article porte sur exactement l'une d'entre elles : un modèle qui prédit chaque image et remplace entièrement le moteur. Pas des outils d'IA greffés sur un moteur traditionnel, et pas un outil qui construit des environnements 3D que vous chargez ensuite dans un moteur.
Les trois sens, en termes simples :
- Des outils d'IA à l'intérieur d'un moteur traditionnel. Génération d'assets, synthèse de textures, arbres de comportement de NPC, écriture de dialogues : tout tourne à l'intérieur d'Unity ou d'Unreal. Le moteur affiche toujours les images, fait tourner la physique et tient l'état. L'IA est un assistant dans le pipeline de contenu. C'est de cela que parlent réellement la plupart des résultats de recherche pour « moteur de jeu IA », et ce n'est pas le sujet de cet article.
- Des générateurs d'espaces 3D créés par auteur. World Labs, cofondé par Fei-Fei Li, propose Marble, un outil qui crée des environnements 3D persistants et téléchargeables à partir de texte, d'images, de vidéos ou d'autres entrées. Surtout, Marble se rapproche d'un outil de création de contenu spatial : il génère des mondes 3D persistants que l'on peut parcourir, modifier, télécharger ou exporter vers des workflows en aval. Cela le rend différent de GameNGen, Oasis ou des systèmes de type Genie où l'expérience jouable elle-même est produite en direct par génération image par image.
- Des modèles de monde qui remplacent le moteur. GameNGen, Oasis, la famille Genie, DIAMOND, MineWorld, Matrix-Game. Ceux-ci génèrent directement des observations jouables au lieu de charger une scène normale créée par auteur dans Unity ou Unreal. Certains systèmes plus récents ajoutent des mécanismes de mémoire et de cohérence, mais ils n'exposent toujours pas le modèle d'état durable, inspectable et contrôlé par le développeur d'un moteur de jeu traditionnel. C'est le sujet ici.
Une règle de décision rapide pour tout article que vous lisez : si le système produit un fichier que vous chargez dans Unity, c'est la catégorie 1 ou 2. Si le système is la chose à laquelle vous jouez, avec des images générées en direct, c'est la catégorie 3 : un modèle de monde.
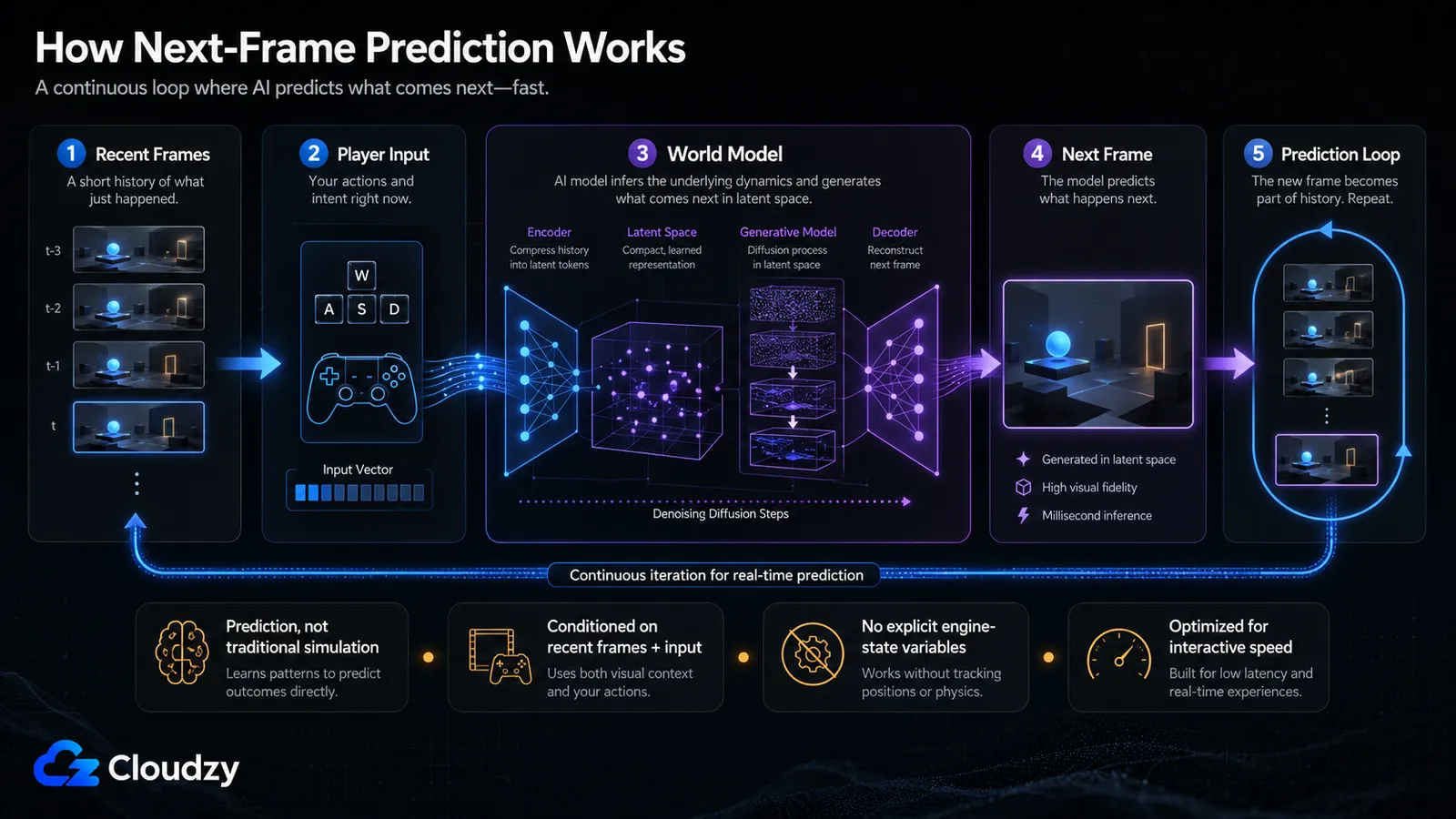
Comment un modèle génère un jeu sans moteur
Un modèle de monde apprend à quoi ressemble un jeu en mouvement, puis prédit l'image suivante conditionnée par les images récentes et l'entrée actuelle du joueur. Contrairement à un moteur traditionnel, il n'expose pas de variables propres comme « la porte est ouverte », « cet ennemi est mort » ou « le joueur est à la coordonnée X ». Dans les premiers systèmes de prédiction d'image, le modèle apprend surtout que certains états visuels tendent à suivre certaines entrées. Jouer revient simplement à faire tourner cette boucle de prédiction apprise assez vite pour que cela paraisse interactif.
GameNGen est l'exemple traité le plus net, parce que l' article expose chaque étape. Le pipeline se déroule en deux phases. D'abord, un agent d'apprentissage par renforcement joue des milliers de sessions de DOOM, et chaque session est enregistrée comme un flux d'images associées aux actions qui les ont produites. Ensuite, une version modifiée de Stable Diffusion v1.4 est entraînée sur ces données pour prédire l'image suivante à partir des images précédentes et de l'action du joueur. L'action est intégrée directement dans le conditionnement, et c'est l'astuce qui en fait un jeu et pas seulement un générateur de vidéo. Votre frappe au clavier fait partie de l'invite pour l'image suivante.
La partie difficile, c'est la vitesse. Un modèle de diffusion normal exécute 20 à 50 étapes de débruitage pour transformer du bruit en image, ce qui est bien trop lent pour un jeu en temps réel. GameNGen réduit cela à 4 étapes de débruitage, ramenant l'inférence totale à environ 50 millisecondes par image : assez rapide pour 20 FPS sur un seul TPU à la résolution native de DOOM de 320×240. Des évaluateurs humains faisaient à peine mieux que le hasard pour distinguer de courts extraits de la simulation d'images réelles de DOOM.
La plupart des systèmes dans ce domaine relèvent de schémas architecturaux qui se recoupent :
- Les systèmes à base de diffusion (GameNGen, Oasis, DIAMOND, Genie 2) : partent du bruit et le débruitent de façon itérative jusqu'à l'image suivante. Ils peuvent produire une forte qualité visuelle à court horizon, mais ont besoin d'astuces de vitesse pour tourner de façon interactive.
- Les systèmes autorégressifs (MineWorld) : prédisent les images ou les tokens futurs de façon séquentielle, plus proche de la manière dont un modèle de langage prédit du texte. MineWorld échange du débit d'images contre un suivi d'action plus serré, se situant autour de 4-7 FPS.
- Les hybrides augmentés en mémoire et en contrôle (Matrix-Game 2.0/3.0 et systèmes plus récents) : combinent génération en temps réel, conditionnement par l'action, contrôle de caméra et mécanismes de mémoire explicites pour réduire la dérive à long horizon.
Un détail compte pour la section suivante. Pendant l'entraînement, GameNGen ajoute délibérément du bruit aux images passées sur lesquelles il se conditionne. Cela force le modèle à apprendre à corriger ses propres erreurs au lieu de les accumuler, une atténuation du problème de dérive. Cela aide. Cela ne le résout pas.
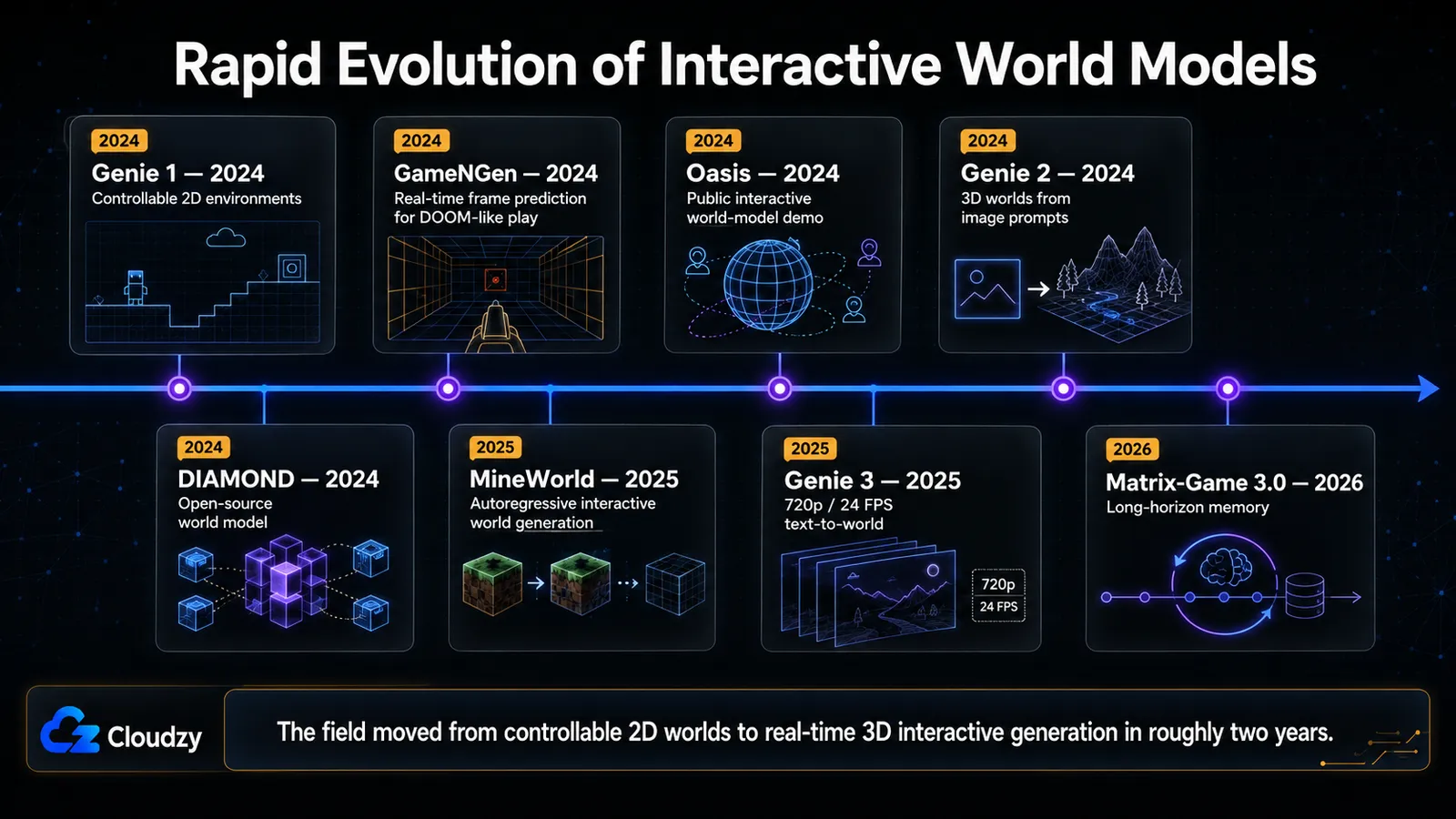
La lignée : de Genie 1 à Genie 3 en deux ans
La chose la plus frappante dans ce domaine, c'est la pente. En février 2024, Genie 1 générait des jeux de plateforme 2D contrôlables en 256×256. Dix-huit mois plus tard, Genie 3 générait des mondes 3D navigables à partir d'une invite textuelle en 720p et 24 FPS. Voilà la trajectoire qui mérite l'attention : non pas une démo isolée, mais le rythme du changement entre elles.
Lue comme une seule progression, l'histoire se déroule ainsi. Genie 1 (DeepMind, ICML 2024) a prouvé qu'on pouvait apprendre des environnements interactifs à partir de vidéo non étiquetée. GameNGen (Google, ICLR 2025) a montré que la même idée pouvait faire tourner un vrai jeu nerveux (DOOM) en temps réel. Oasis (Decart, octobre 2024) l'a porté sur Minecraft et l'a rendu jouable publiquement. Genie 2 (DeepMind, décembre 2024) est passé aux mondes 3D générés à partir d'une seule image. DIAMOND (NeurIPS 2024) a rendu l'approche open source et exécutable sur un GPU grand public. GameGen-X et MineWorld (Microsoft, 2025) ont poussé l'écosystème ouvert plus loin. Genie 3 (août 2025 ; public sous le nom de Project Genie en janvier 2026) a atteint la 3D en temps réel à partir de texte. Matrix-Game 2.0 a poussé la génération en streaming temps réel et open source à 25 FPS, et Matrix-Game 3.0 s'est attaqué plus directement au problème de la mémoire avec une architecture de mémoire à long horizon.
This is, in a real sense, the other end of the neural-rendering trend. Neural rendering is AI replacing individual stages of the graphics pipeline (upscaling here, shading there) while the engine keeps running. World models are AI replacing the pipeline entirely. If you read the two together, neural rendering is the "AI eats the parts" story and this is the "AI eats the whole thing" story. Each is the other's logical next step.
Les spécifications des principaux systèmes figurent dans le tableau ci-dessous ; le propos du récit, c'est l'arc, pas les chiffres.
| Système | Développeur | Année | Approche | Résolution / FPS | Open source ? | Source |
|---|---|---|---|---|---|---|
| Genie 1 | Google DeepMind | 2024 | Action latente | 256×256 | No | arXiv |
| GameNGen | 2024 | Diffusion | 320×240 / 20 FPS | No | arXiv | |
| Oasis | Decart + Etched | 2024 | Diffusion (Forcing) | 360p / 20 FPS | Partiel (ckpt 500M) | Project |
| Oasis 3 | Decart | 2026 | Modèle de monde interactif accessible par API pour l'IA physique | Aperçu API en temps réel | No | Decart / TechCrunch |
| Genie 2 | Google DeepMind | 2024 | Diffusion latente autorégressive | S.O. | No | DeepMind |
| DIAMOND | Genève / Édimbourg / MSR | 2024 | Diffusion | Atari / CS:GO | Oui (MIT) | arXiv |
| GameGen-X | Universitaire | 2024 | Transformeur de diffusion | S.O. | Oui | arXiv |
| MineWorld | Microsoft Research | 2025 | Autorégressif | 4-7 FPS | Oui | arXiv |
| Genie 3 | Google DeepMind | 2025 | Modèle de monde temps réel à usage général | 720p / 24 FPS | No | DeepMind |
| Matrix-Game 2.0 | Skywork AI | 2025 | Diffusion autorégressive en quelques étapes | 25 FPS sur un seul H100 | Oui | Project |
| Matrix-Game 3.0 | Skywork AI | 2026 | Modèle de monde interactif augmenté en mémoire | Jusqu'à 40 FPS en 720p avec un modèle 5B | Oui | Project / arXiv |
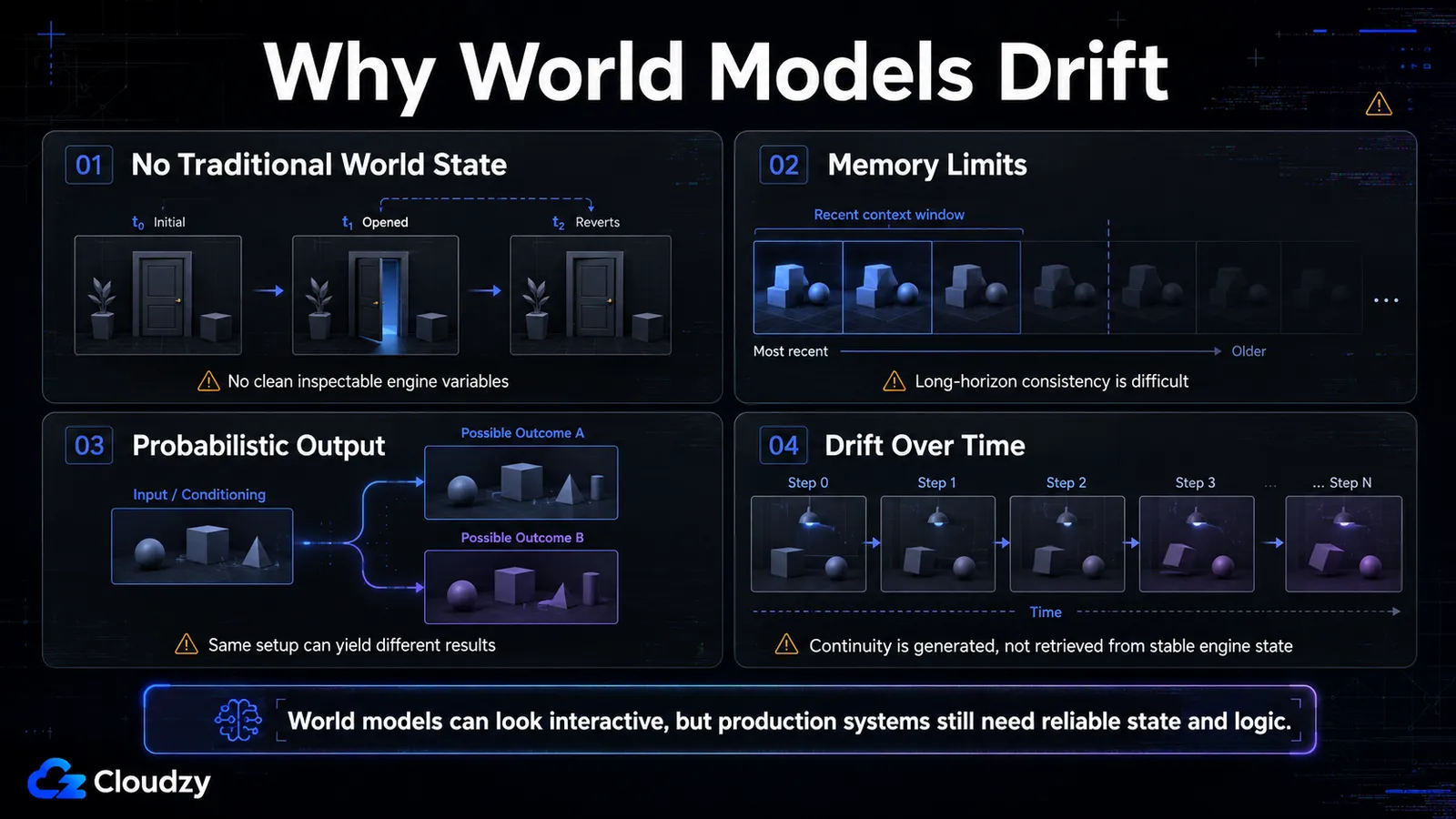
Pourquoi ces mondes s'effondrent
Ces systèmes se cassent encore de quatre façons importantes, mais le mode de défaillance n'est pas seulement « pas assez de puissance de calcul ». Plus de GPU peuvent améliorer la résolution, la latence et l'échelle du modèle, mais une cohérence de qualité production exige une meilleure mémoire, un meilleur suivi d'état et une meilleure architecture de contrôle. Un modèle qui prédit des images plausibles n'est pas la même chose qu'un moteur doté de règles explicites, de variables inspectables, de mises à jour d'état déterministes et d'une sémantique de sauvegarde/chargement. Chaque limite ci-dessous correspond à ce que le modèle ne peut structurellement pas faire, et non à ce qu'il n'est pas encore devenu assez bon pour faire.
Aucun état de monde persistant
Ces systèmes n'exposent pas de variables à la manière d'un moteur traditionnel. Un moteur normal stocke le monde sous forme de données : ce coffre est ouvert, cet ennemi est mort, le joueur est à la coordonnée (412, 88). Dans les premiers systèmes de prédiction d'image, il n'y a aucun état de moteur durable en ce sens propre au développement de jeux. Le modèle s'appuie surtout sur le contexte visuel récent et des a priori appris, de sorte que les objets peuvent changer, disparaître ou réapparaître de façon incorrecte une fois sortis du champ. Des systèmes plus récents ajoutent des mécanismes de mémoire et de cohérence explicites, mais ils n'exposent toujours pas le genre d'état de monde propre et déboguable qu'un moteur traditionnel donne aux développeurs.
Dans les systèmes de prédiction d'image plus faibles ou anciens, un coffre que vous avez ouvert peut réapparaître fermé, un monstre que vous avez tué peut revenir, et une structure que vous avez construite peut se dissoudre une fois sortie du cadre. Les joueurs ont décrit la démo Oasis d'origine comme ayant une « logique de rêve » : vous vous retournez, et vous risquez de ne pas revenir exactement au même endroit. Des systèmes plus récents tentent de réduire ce problème avec des mécanismes de mémoire et de cohérence plus solides, mais l'écart demeure : ils n'exposent toujours pas une couche d'état de jeu traditionnelle et inspectable.
Le plafond de la fenêtre de contexte
La cohérence est bornée par la conception de la mémoire du modèle, et pas seulement par la qualité visuelle brute. GameNGen utilise un court historique direct des images mais rapporte tout de même des sessions de jeu stables de plusieurs minutes grâce à une correction apprise. Genie 2 a introduit des exemples visibles de mémoire à long horizon et maintenait la cohérence jusqu'à une minute, la plupart des exemples durant 10-20 secondes. Genie 3 pousse l'interaction continue à quelques minutes, et Matrix-Game 3.0 s'attaque directement au problème avec une mémoire à long horizon. Le problème non résolu n'est pas « le modèle peut-il durer plus de quelques secondes ? ». C'est de savoir s'il peut préserver un état de monde fiable, inspectable et sauvegardable sur la durée et la complexité d'un vrai jeu.
Stochastique, pas déterministe
La sortie est probabiliste par défaut. Lancez deux fois la même configuration et vous pouvez obtenir des images différentes, à moins que le système ne soit fortement contraint. Pour un outil artistique, cela peut être utile ; pour beaucoup de jeux de production, c'est un problème. Le multijoueur, l'équilibrage compétitif, les rejeux, la progression de compétence et la sauvegarde/le chargement dépendent tous de transitions d'état fiables. Un modèle de monde peut être rendu plus reproductible, mais un jeu de production aurait quand même besoin d'une couche de logique déterministe ou d'un système d'état pour garantir le comportement qu'attendent les joueurs et les développeurs.
Est-ce un jeu, ou de la prédiction vidéo avec un clavier ?
La critique la plus tranchée, c'est que ces systèmes ne simulent pas des mondes au sens traditionnel du moteur de jeu ; ils génèrent des continuations visuelles plausibles et vous laissent les piloter. Un moteur de jeu encode des règles ; un modèle de monde encode de la plausibilité. Un commentateur dans le fil Hacker News de GameNGen l'a qualifié de « la compression vidéo la moins efficace au monde », et comme provocation cela touche juste : le modèle a en pratique mémorisé une distribution sur des séquences de jeu et interpole à travers elle en réponse à vos entrées. Il existe un test net pour cela, dans l'encadré ci-dessous.
Le signe révélateur de la « dérive à l'arrêt ». Si un modèle de monde calculait vraiment un monde, un joueur immobile devrait produire une image stable : rien ne change, donc rien ne devrait changer. Dans les systèmes de prédiction d'image plus faibles ou anciens, même rester immobile peut révéler une dérive : de petits détails se déplacent parce que le modèle prédit l'image plausible suivante plutôt que d'afficher à partir d'un état de monde fixe et inspectable. C'est cela le signe révélateur. La scène peut paraître stable un moment, mais le système génère encore la continuité au lieu de la lire depuis un moteur classique.
Point clé : les limites de déterminisme et de persistance sont des problèmes architecturaux, pas des soucis que la seule montée en échelle brute résoudra d'elle-même. Tout système qui a besoin d'un monde fiable, reproductible et sauvegardable a encore besoin d'une couche de logique déterministe, d'un système de mémoire/d'état explicite ou d'une conception de moteur hybride que les approches actuelles de génération d'images ne fournissent pas à elles seules.
Ce que ça coûte réellement à faire tourner
La génération en temps réel coûte cher, et les chiffres en gros titres cachent beaucoup de choses. Le « TPU unique » de GameNGen semble bon marché jusqu'à ce que vous vous souveniez qu'il simule DOOM en 320×240, et non un jeu moderne en haute résolution. La démo Oasis d'origine tournait en temps réel sur une infrastructure de classe H100, et le plus récent Oasis 3 de Decart rend l'économie plus concrète. Decart positionne Oasis 3 comme un modèle de monde interactif accessible par API pour l'IA physique, et TechCrunch a rapporté le tarif d'accès en aperçu à 0,02 $ la seconde, soit 1,20 $ pour une session de 60 secondes. C'est utile pour les tests, la simulation et les workflows de recherche, mais cela reste un modèle de coût très différent de la distribution d'un client de jeu normal.
Pour donner l'échelle : la génération de mondes en temps réel reste coûteuse, mais le tableau matériel évolue vite. Certains systèmes de recherche ouverts rapportent désormais une génération en temps réel ou quasi temps réel sur des GPU uniques de classe H100, tandis que les systèmes de pointe destinés au grand public restent hébergés dans le cloud et souvent non divulgués. Le point ferme n'est pas « un seul GPU ne pourra jamais le faire » ; c'est que la génération de mondes de qualité production, à faible latence et en haute résolution reste un sérieux problème d'infrastructure.
Le contre-argument, c'est que le plancher baisse vite, et que le niveau open source est réel. DIAMOND s'est entraîné en environ 12 jours sur un seul RTX 4090 et, selon sa page de projet officielle, peut se jouer à environ 10 FPS sur un RTX 3090. MineWorld et Matrix-Game sont exécutables publiquement. Ainsi, même si les démos les plus impressionnantes dépendent encore d'une infrastructure spécialisée et coûteuse, un développeur curieux peut déjà mener de vraies expériences avec des modèles de monde sur du matériel accessible. Les deux choses sont vraies en même temps : l'interaction de qualité de pointe est coûteuse, et le point d'entrée pour l'expérimentation est déjà réel.
Alors, l'IA va-t-elle remplacer Unity et Unreal ?
Pas à court terme, et la raison en est les limites ci-dessus, pas un manque d'investissement. Le marché a pris la chose au sérieux. Google a déployé Project Genie auprès des abonnés américains de Google AI Ultra le 29 janvier 2026, et le lendemain plusieurs actions du secteur du jeu ont fortement chuté : The Verge a rapporté Unity en baisse de 24,22 %, Roblox en baisse de 13,17 % et Take-Two en baisse de 7,93 % à la clôture de vendredi. L'inquiétude s'est aussi manifestée à l'intérieur de l'industrie : l'enquête 2026 de la GDC a révélé que 52 % des professionnels du jeu voyaient l'IA générative comme ayant un impact négatif sur les jeux, contre 30 % l'année précédente. Mais les mouvements de bourse et l'inquiétude des sondages sont des réactions à une démo. C'est l'architecture qui fixe le calendrier réel.
À lire la trajectoire telle qu'elle est, et ceci est ma lecture, pas une prévision établie, les 1-3 prochaines années maintiendront probablement les modèles de monde dans les prototypes de recherche, l'infrastructure de simulation, l'entraînement en robotique/IA physique et des démos étroites destinées au grand public, plutôt que dans des jeux commerciaux complets. Le chemin plausible sur 3-7 ans est hybride, pas un remplacement : un modèle de monde gérant la génération visuelle posé au-dessus d'une machine à états déterministe légère qui détient la logique de jeu réelle. C'est de l'augmentation. La trajectoire est assez raide (DOOM en 320p à du 720p-depuis-texte en environ un an) pour que des prédictions à long terme assurées soient imprudentes, alors je n'en ferai pas.
Le détail qui recadre toute la question : DeepMind relie les modèles de monde à l'entraînement d'agents et à la recherche sur l'AGI, tandis que Project Genie montre la même technologie comme un prototype de création de mondes destiné au grand public. L'Oasis 3 de Decart vise encore plus explicitement la robotique, les véhicules autonomes et la simulation d'IA physique. Les jeux grand public comptent dans l'histoire, mais l'attraction commerciale à court terme pourrait venir d'abord de la simulation, de l'entraînement et du prototypage.
Foire aux questions
Quelle est la différence entre un modèle de monde et un moteur de jeu ?
Un moteur de jeu encode des règles explicites et stocke l'état du jeu sous forme de données : il est déterministe, inspectable et déboguable. Un modèle de monde comme GameNGen prédit des images suivantes plausibles à partir des images récentes et de votre entrée, sans l'état, les règles et les variables d'objet de type moteur que les développeurs inspectent et contrôlent normalement. Le moteur calcule le monde ; le modèle de monde le devine. C'est pourquoi l'un est reproductible et l'autre non.
Comment fonctionne GameNGen ?
GameNGen fait tourner DOOM en trois grandes étapes. D'abord, un agent d'apprentissage par renforcement joue des milliers de sessions de DOOM, enregistrées comme des images associées à des actions. Ensuite, une version modifiée de Stable Diffusion v1.4 apprend à prédire l'image suivante conditionnée par les images passées et l'entrée du joueur. Enfin, l'inférence est réduite à 4 étapes de débruitage, produisant environ 20 FPS sur un seul TPU en 320×240.
Pourquoi le monde dans Oasis change-t-il sans cesse quand on se retourne ?
Dans la démo Oasis d'origine de type Minecraft, le monde pouvait changer quand vous vous retourniez parce que le système ne préservait pas un état de monde traditionnel de type moteur. Il générait la vue suivante à partir du contexte visuel récent et d'a priori appris, de sorte que les objets hors champ pouvaient revenir sous une forme altérée. Des systèmes plus récents ajoutent des mécanismes de mémoire et de cohérence plus solides, mais cette « logique de rêve » d'origine est précisément ce qui rendait la limite facile à remarquer.
Combien de temps un monde de jeu généré par IA peut-il rester cohérent avant de dériver ?
Cela dépend du modèle. Les premiers systèmes dérivent souvent en quelques secondes à quelques dizaines de secondes, mais les systèmes plus récents étendent cet horizon. GameNGen dispose d'un peu plus de 3 secondes de contexte direct et peut pourtant rester stable sur un jeu plus long grâce à des heuristiques apprises. Genie 2 montrait surtout des exemples de 10-20 secondes et jusqu'à une minute dans certains cas. Genie 3 porte l'affirmation à quelques minutes en 720p/24fps, et Matrix-Game 3.0 rapporte une cohérence de mémoire d'une minute. Le problème non résolu, ce ne sont pas les courts extraits ; c'est un état de monde durable, inspectable et sauvegardable.
L'IA va-t-elle remplacer des moteurs de jeu comme Unity ou Unreal ?
Pas à court terme. Les obstacles sont architecturaux plus que purement un problème d'échelle : les jeux de production ont besoin d'un état persistant, d'une logique fiable, d'un comportement déterministe et d'une sémantique de sauvegarde/chargement. La montée en échelle aide la qualité et la cohérence, mais elle ne crée pas en soi une boucle de jeu traditionnelle. Le chemin plausible est hybride : un modèle de monde générant les visuels au-dessus d'un moteur déterministe pour la logique de jeu, ce qui est de l'augmentation plutôt qu'un remplacement. DeepMind présente les modèles de monde comme importants pour l'entraînement d'agents et la recherche sur l'AGI, tandis que Project Genie rend aussi la technologie visible comme un prototype de création de mondes destiné au grand public. L'Oasis 3 de Decart est l'exemple le plus net d'un modèle visant explicitement la robotique, les véhicules autonomes et la simulation d'IA physique.
Peut-on jouer à l'un de ces jeux générés par IA dès maintenant ?
Oui, à plusieurs. L'Oasis d'origine de Decart avait une démo web publique de type Minecraft, et son plus récent Oasis 3 Preview est désormais accessible par API pour des expériences de modèle de monde en temps réel. Le Project Genie de Google est aussi devenu disponible pour les abonnés de Google AI Ultra aux États-Unis en janvier 2026. Pour le niveau open source, DIAMOND et MineWorld peuvent être téléchargés et exécutés sur des GPU grand public, DIAMOND étant rapporté à environ 10 FPS sur un RTX 3090.


