
Quand NVIDIA a montré DLSS 4 en train de générer quinze pixels sur seize avec l'AI, une grande partie du public n'a pas vu de progrès. Elle a vu des "fausses images" et de la "bouillie AI" : du détail généré qui semble correct jusqu'à ce qu'il ne le soit plus, et que vous ne pouvez pas déboguer comme vous déboguez un polygone mal placé. Un rapport de PCGuide sur un sondage communautaire a révélé que 54 % des réponses étaient un simple "Non" concernant DLSS 5 son rendu, une grande partie des critiques visant les traits du visage et la réaction de "bouillie AI". Cette réaction mérite d'être prise au sérieux, et nous y reviendrons.
Mais le problème plus profond dans chacun de ces débats, c'est que le "rendu neuronal" désigne au moins cinq choses différentes : la mise à l'échelle, les images générées par AI, la reconstruction de scène à partir de photos, les démos NeRF et Gaussian Splatting que vous avez vues sur les réseaux sociaux, et les systèmes de recherche qui rendent une image entière avec un seul réseau. Les gens se parlent sans se comprendre parce que chacun pointe une couche différente en employant le même mot. Jensen Huang, de NVIDIA, a qualifié ce changement de "moment GPT pour le graphisme". Voilà l'affirmation. La vraie question est de savoir ce qui se passe en dessous.
Voici le fil conducteur qui rend tout cela lisible : le GPU prédit de plus en plus l'image au lieu de la calculer. Traditionnellement, le GPU calcule chaque pixel en simulant la géométrie, l'éclairage et les matériaux (rastérisation, et plus récemment le ray tracing par-dessus). Le rendu neuronal change ce qui est calculé par rapport à ce qui est prédit par un réseau entraîné. Cette seule distinction est la colonne vertébrale de cet article. À la fin, vous saurez placer n'importe quelle technique sur un spectre, savoir lesquelles fonctionnent en temps réel et sur quel matériel, et distinguer ce qui équipe un jeu aujourd'hui de ce qui relève d'un article de recherche ou d'une démo GTC. C'est une carte, pas un mode d'emploi. Les mécanismes profonds de chaque technique mériteraient leur propre article.
La version courte
- Le rendu neuronal est un spectre, pas un synonyme de DLSS. Il couvre la recherche en reconstruction de scène (NeRF, Gaussian Splatting), des composants temps réel intégrés au pipeline de rendu (DLSS, Ray Reconstruction, cache de radiance neuronal) et des méthodes génératives qui inventent du détail que l'image n'a jamais eu.
- Le fil conducteur, c'est "prédire au lieu de calculer". Chaque technique remplace une étape de calcul coûteuse du pipeline par un réseau qui prédit le résultat sur lequel il a été entraîné.
- La plupart de ce qui est livré aujourd'hui est hybride. La mise à l'échelle, la génération d'images et le débruitage AI fonctionnent désormais dans les jeux en temps réel, tandis que la compression de textures neuronale et les shaders neuronaux émergent via les kits de développement. Les moteurs entièrement neuronaux qui dessinent toute l'image avec un réseau en sont encore au stade de la recherche.
- Cela devient multi-fournisseurs, pas seulement une affaire NVIDIA. Les travaux de Microsoft sur le ML au niveau shader dans DirectX ont commencé avec les Cooperative Vectors dans Shader Model 6.9 et évoluent vers une prise en charge plus large de l'algèbre linéaire dans Shader Model 6.10, offrant aux moteurs une voie pour cibler des charges de travail de shaders de type neuronal au-delà de la pile d'un seul fournisseur.
Pourquoi "rendu neuronal" signifie cinq choses différentes
Le rendu neuronal est une classe de méthodes qui utilisent des réseaux de neurones pour prédire des parties d'une image (pixels, éclairage, matériaux, voire des images entières) que le GPU calculerait sinon de zéro. L' étude de Tewari et al. le définit comme la combinaison de l'infographie classique avec des modèles génératifs profonds pour un rendu photoréaliste. Le terme couvre un large spectre, et le "DLSS" n'en est qu'un point.
Si la conversation est confuse, c'est que le spectre comporte au moins trois couches distinctes, et que le public emploie un seul mot pour toutes.
La première couche est le rendu neuronal académique / de reconstruction : NeRF, 3D Gaussian Splatting et le rendu différentiable. Ils prennent des photographies ou des mesures d'une scène réelle et apprennent une représentation que l'on peut rendre sous de nouveaux angles de caméra. L' article original sur NeRF (Mildenhall et al., 2020) entraîne un petit réseau à associer une coordonnée 3D et une direction de vue à une couleur et une densité, puis rend de nouvelles vues en l'interrogeant. Cette couche est essentiellement hors ligne. Elle reconstruit des scènes ; elle n'alimente pas la boucle d'images de votre jeu.
La deuxième couche est le rendu neuronal de pipeline temps réel : des réseaux qui s'exécutent à l'intérieur ou aux côtés d'une image rastérisée normale. La mise à l'échelle DLSS, Ray Reconstruction et le cache de radiance neuronal vivent ici. Le pipeline rastérise et lance toujours des rayons ; un réseau gère une de ses étapes coûteuses. C'est la couche qui équipe les jeux aujourd'hui.
La troisième couche est le rendu neuronal génératif : le réseau produit un contenu d'image que l'image n'a jamais calculé du tout. Les images générées de DLSS 4 se situent à la lisière de cette couche, et DLSS 5 (que NVIDIA a annoncé pour l'automne 2026) s'y enfonce davantage en générant des détails d'éclairage et de matériaux plutôt qu'en interpolant seulement entre des images rendues.
Ces trois couches se comportent différemment, fonctionnent à des vitesses différentes et nécessitent un matériel différent. Les confondre explique pourquoi deux personnes peuvent dire l'une "le rendu neuronal est surévalué" et l'autre "le rendu neuronal est l'avenir" en ayant toutes deux partiellement raison.
À retenir : le terme est antérieur à DLSS et n'en est pas un synonyme. DLSS est une application (temps réel, dans le pipeline) au sein d'un spectre bien plus large qui va de la reconstruction de scène hors ligne aux images entièrement générées.
Comment le rendu neuronal remplace des parties du pipeline en force brute
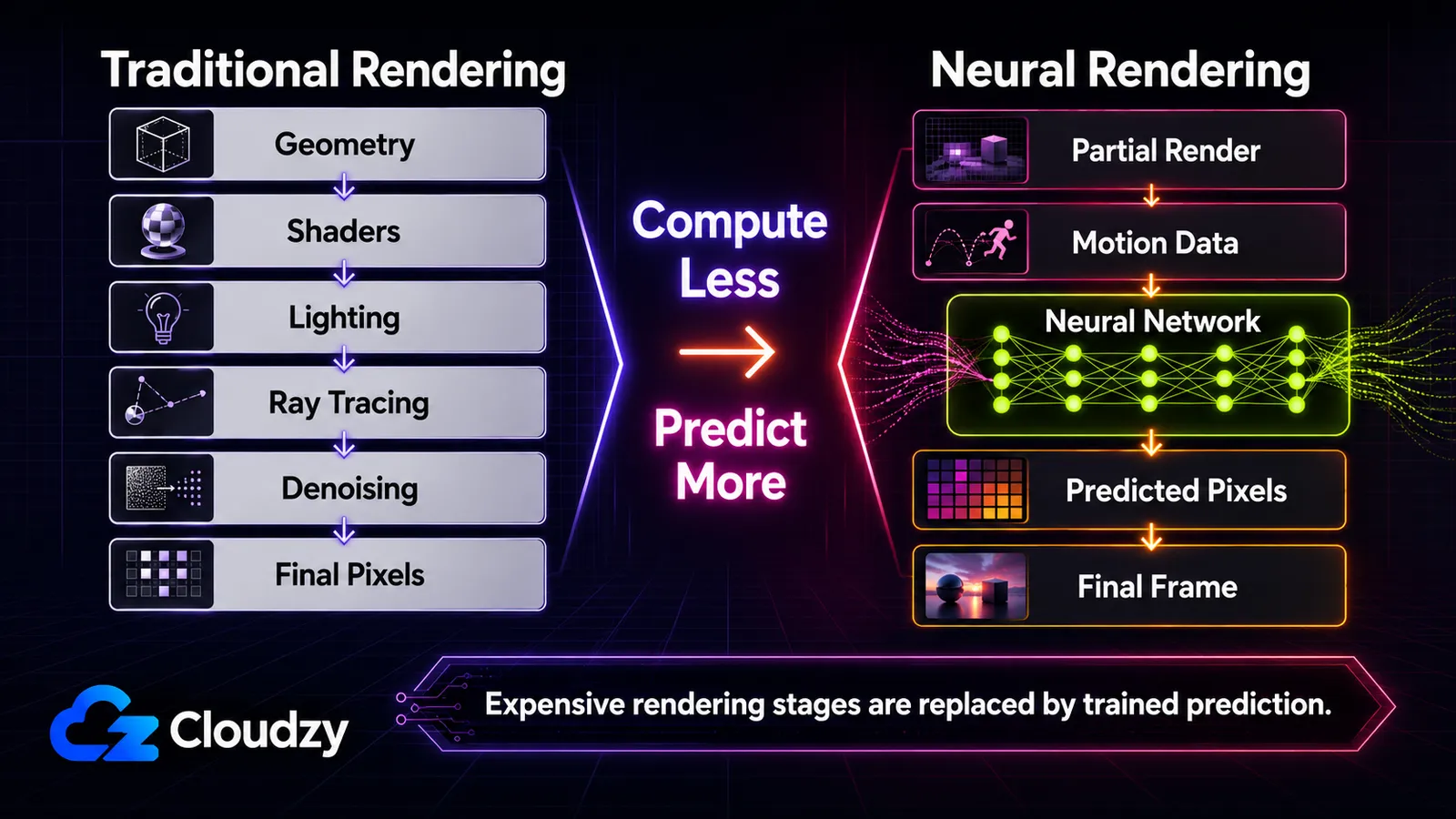
Avec la génération multi-images complète de DLSS 4, environ quinze pixels sur seize à l'écran sont produits par AI plutôt que rendus de façon traditionnelle (selon les chiffres DLSS 4 de NVIDIA). Ce nombre résume tout le changement en une seule statistique : le moteur calcule une fraction de l'image et prédit le reste.
Le rendu traditionnel gagne chaque pixel à la sueur. Le GPU rastérise la géométrie, exécute des shaders pour calculer l'éclairage et les matériaux, et (avec le ray tracing) simule la lumière qui rebondit dans la scène. Le ray tracing en particulier est brutalement coûteux, car une lumière réaliste exige de nombreux rebonds et de nombreux échantillons par pixel, et le bruit du sous-échantillonnage doit ensuite être nettoyé. À mesure que les scènes sont devenues plus ambitieuses, les étapes les plus coûteuses sont devenues les cibles évidentes : au lieu de les calculer, entraîner un réseau à prédire leur sortie.
La progression a été régulière plutôt que soudaine :
- 2018, DLSS 1.0. La première étape commerciale : rendre en basse résolution, prédire l'image haute résolution. Faire passer la mise à l'échelle de "calculer plus de pixels" à "prédire plus de pixels".
- 2020, NeRF. Reconstruction de scène à partir d'images via un champ de radiance appris. Prédire de nouvelles vues au lieu de modéliser et de rendre la géométrie.
- 2021, cache de radiance neuronal. Prédire la lumière rebondie pendant le path tracing pour que le moteur puisse arrêter de tracer plus tôt.
- 2022, génération d'images DLSS 3. Générer des images intermédiaires entières au lieu de les rendre.
- 2023, 3D Gaussian Splatting. Une alternative à NeRF plus rapide et orientée temps réel pour les scènes reconstruites.
- 2025, DLSS 4 + RTX Kit. Génération multi-images plus une boîte à outils de composants neuronaux (compression de textures, cache de radiance, shaders neuronaux).
- 2025, DirectX Cooperative Vectors (préversion). Une API multi-fournisseurs pour les calculs matriciels dont ont besoin les shaders neuronaux (introduite en préversion dans le cadre de Shader Model 6.9).
- 2026, DLSS 4.5. Améliorations incrémentales de la qualité et de Ray Reconstruction (décrites par NVIDIA au Computex).
- Automne 2026, DLSS 5 (annoncé). La prochaine avancée vers le rendu neuronal génératif.
De haut en bas, chaque ligne est le même mouvement appliqué à une étape différente : prendre quelque chose que le pipeline calculait et faire qu'un réseau le prédise à la place.
Les six couches : ce que l'AI remplace à chaque étape du pipeline
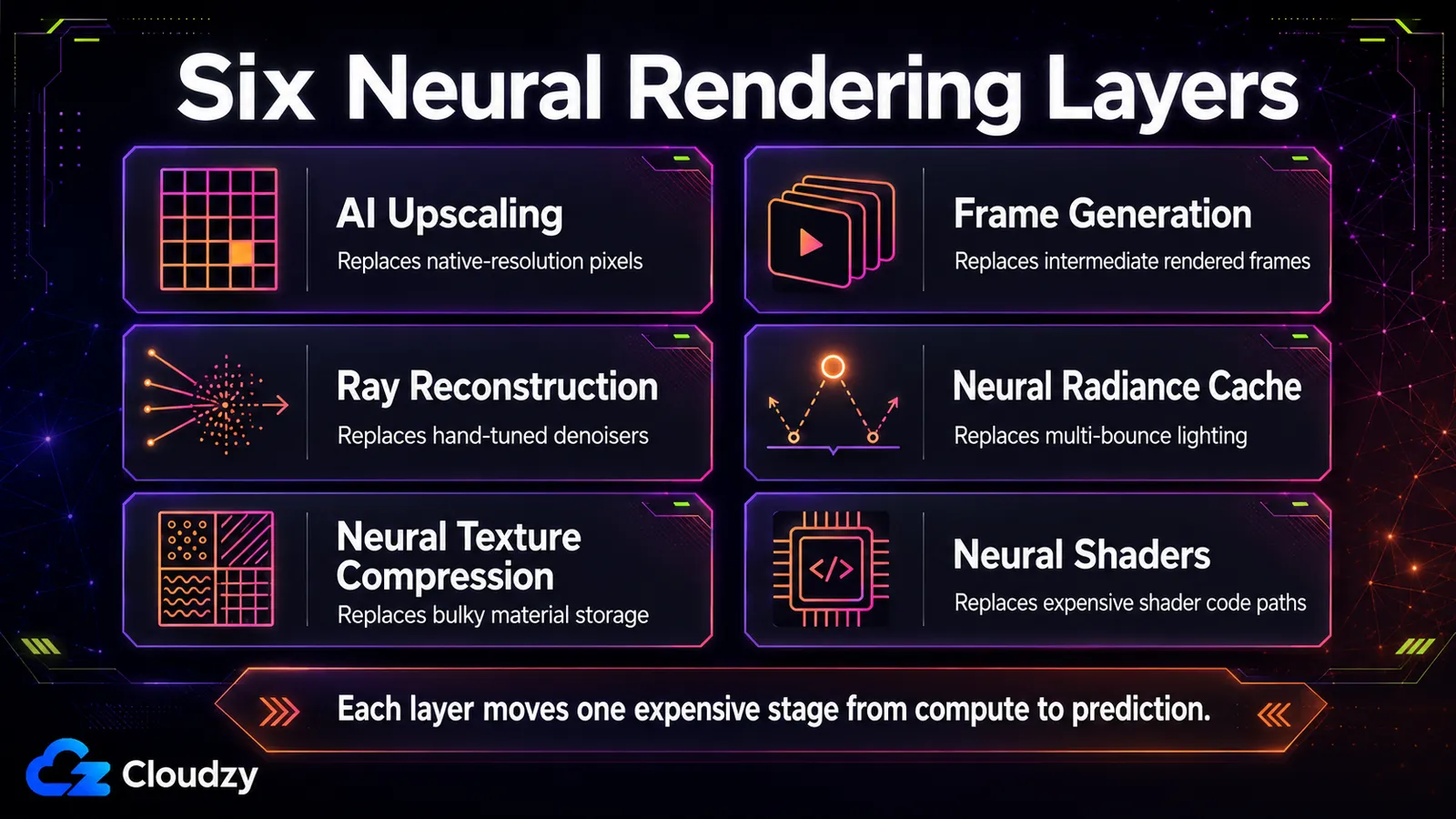
Six techniques portent l'essentiel du rendu neuronal temps réel d'aujourd'hui, et chacune remplace une étape de calcul précise : la mise à l'échelle (résolution), la génération d'images (nombre d'images), la reconstruction de rayons (débruitage), le cache de radiance neuronal (illumination globale), la compression de textures neuronale (stockage des matériaux) et les shaders neuronaux (calcul dans le shader). Savoir quelle étape chacune touche, c'est l'essentiel de la bataille.
Elles se répartissent selon l'endroit du pipeline où le réseau s'exécute. Certaines opèrent tout à la fin en post-traitement sur une image terminée ; certaines s'exécutent en milieu de pipeline aux côtés du ray tracing ; certaines vivent à l'intérieur du shader lui-même. Cet emplacement n'est pas un détail. Il détermine la vitesse à laquelle la technique peut fonctionner et le matériel qu'elle requiert. Le tableau recense ces six techniques ; les sous-sections ci-dessous expliquent le mécanisme qui ne tenait pas proprement dans chaque cellule.
| Technique | Ce qu'elle remplace | Viabilité en temps réel | Matériel requis | Multi-fournisseurs ? |
|---|---|---|---|---|
| Mise à l'échelle AI (super résolution) | Calcul des pixels en résolution native | Temps réel, faible surcharge | Cœurs Tensor / matriciels (RTX 20+, RDNA 4, Intel XMX) | Oui en tant que catégorie ; les implémentations restent propres à chaque fournisseur (DLSS, FSR / FSR Upscaling, XeSS) |
| Génération d'images | Rendu des images intermédiaires | Temps réel ; ajoute de la latence | RTX 40+ (DLSS 3), RTX 50 pour le multi-image | En partie ; propre au fournisseur |
| Reconstruction de rayons | La pile de débruiteurs réglés à la main | Temps réel | RTX 20+ | NVIDIA aujourd'hui |
| Cache de radiance neuronal | Calcul de la lumière indirecte à rebonds multiples | Temps réel (~2,6 ms rapportées) | Cœurs matriciels de classe RTX | NVIDIA aujourd'hui (RTX Kit) |
| Compression de textures neuronale | Stockage de matériaux compressé par blocs | Décodage en temps réel | Cœurs matriciels de classe RTX | SDK/outils NVIDIA aujourd'hui ; une prise en charge plus large du ML au niveau shader est en cours de normalisation séparément |
| Shaders neuronaux | Chemins de code de shaders calculés | Temps réel | GPU compatibles ML au niveau shader / matriciels | Émergent via la voie DirectX SM 6.9 / SM 6.10 |
Mise à l'échelle AI (super résolution)
La mise à l'échelle AI rend l'image à une résolution inférieure et prédit le résultat haute résolution, de sorte que le GPU dessine bien moins de pixels et qu'un réseau comble la structure. DLSS, FSR 4 d'AMD et XeSS d'Intel font tous cela par suréchantillonnage temporel : ils échantillonnent des pixels différents sur des images consécutives et combinent cet historique avec des vecteurs de mouvement pour reconstruire des détails qu'une seule image basse résolution ne contient pas.
C'est la couche la plus mature et la plus largement déployée, et c'est là que la réalité multi-fournisseurs est la plus claire. DLSS 4 a fait passer son outil de mise à l'échelle d'un réseau convolutionnel à un transformeur pour une meilleure stabilité des détails. FSR 4 est le premier outil de mise à l'échelle d'AMD basé sur le ML, fonctionnant sur RDNA 4 avec une inférence FP8 plutôt que sur les heuristiques écrites à la main des versions FSR antérieures. XeSS utilise les unités matricielles XMX d'Intel. Trois fournisseurs, la même idée sous-jacente : prédire les pixels que vous n'avez pas rendus.
Génération d'images et génération multi-images
La génération d'images prédit des images entières entre celles que le GPU rend réellement, en combinant des données de jeu telles que les vecteurs de mouvement avec l'estimation de flux optique et l'AI. DLSS 3 utilisait l'accélérateur de flux optique de la série RTX 40 pour insérer une image générée entre des images rendues ; la génération multi-images de DLSS 4 sur le matériel RTX série 50 peut générer jusqu'à trois images supplémentaires par image rendue de façon traditionnelle, et NVIDIA indique que DLSS 4 remplace l'étape matérielle de flux optique par un modèle AI plus efficace.
C'est la couche dont parle réellement l'argument des "fausses images", et la formulation compte ici. Une image générée est une interpolation plausible de la direction que prenait la scène : elle vous montre un contenu visuel utilisable. Mais elle est prédit, non rendue à partir de l'état réel du jeu, et elle ne véhicule ni nouvelle logique de jeu ni nouvelle entrée. Crucialement, la génération d'images s'exécute après qu'une image est rendue, ce qui ajoute de la latence au lieu de la supprimer ; Reflex 2 de NVIDIA existe précisément pour récupérer cette latence. Ainsi, "la génération d'images rend le jeu plus rapide" est une vérité partielle : elle augmente la fluidité perçue (plus d'images affichées) sans augmenter la fréquence à laquelle le jeu se met réellement à jour et répond. Cet écart entre ce que vous voyez et ce que le jeu sait constitue tout le débat, et pour le jeu compétitif, où la latence d'entrée décide des résultats, c'est un compromis qui mérite réflexion.
Ray Reconstruction (débruitage AI)
Ray Reconstruction remplace la pile de filtres de débruitage réglés à la main sur laquelle repose le rendu en ray tracing par un seul réseau de neurones entraîné à reconstruire une image propre à partir d'une entrée en ray tracing bruitée et sous-échantillonnée. Le path tracing ne peut se permettre que quelques échantillons de lumière par pixel en temps réel, ce qui laisse la sortie brute bruitée ; il faut bien la nettoyer avant que vous ne la voyiez.
L'approche traditionnelle était une chaîne de débruiteurs spécialisés, chacun réglé à la main pour un effet précis. Remplacer cela par un seul réseau entraîné tend à préserver des détails que les filtres réglés à la main estompaient, notamment sur les reflets et l'éclairage fin, et c'est un seul réseau à maintenir au lieu d'un pipeline fragile. C'est un exemple net du fil conducteur : l'étape de débruitage est passée de "calculer avec des heuristiques écrites à la main" à "prédire avec un modèle entraîné".
Cache de radiance neuronal (illumination globale)
Le cache de radiance neuronal (NRC) prédit comment la lumière rebondit dans une scène afin que le path tracer puisse cesser de tracer la plupart des rayons plus tôt au lieu de suivre chaque rebond jusqu'au bout. L'illumination globale (la lumière douce et indirecte qui rebondit sur les murs et les sols) est l'une des choses les plus coûteuses du graphisme temps réel, et le mécanisme qui fait fonctionner le NRC est rarement expliqué en termes simples, alors il vaut la peine de s'y attarder.
Voici le mécanisme. Un path tracer suit normalement chaque rayon lumineux à travers de nombreux rebonds, et c'est là que le coût explose. Le NRC entraîne un petit réseau pendant le rendu (et non à l'avance) pour prédire la lumière arrivant à un point après d'autres rebonds. Le path tracer trace donc un rayon sur un ou deux rebonds, puis demande au réseau "quel est le reste de la lumière ici ?" et met fin au chemin plus tôt ; l' article sur la mise en cache de radiance neuronale en temps réel (Müller et al., 2021) rapporte mettre fin de cette manière à la grande majorité des chemins. Voyez-le comme un cache qui ne stocke pas des réponses exactes déjà vues, mais apprend le motif de l'éclairage de la scène assez bien pour répondre à des requêtes qu'il n'a pas vues, et continue d'apprendre à mesure que la scène change. NVIDIA rapporte que le NRC fonctionne avec environ 2,6 ms de surcharge, ce qui le rend viable en temps réel plutôt qu'une curiosité de recherche.
Compression de textures neuronale
La compression de textures neuronale (NTC) compresse ensemble tous les canaux de texture d'un matériau avec un réseau, atteignant jusqu'à 8x d'économies de VRAM par rapport à la compression par blocs traditionnelle à qualité visuelle comparable (selon la documentation RTX Kit de NVIDIA). Un matériau moderne n'est pas une seule texture. C'est une pile (couleur, normales, rugosité, métallisation et plus), et ces canaux sont corrélés d'une manière que la compression par blocs, qui comprime chaque canal indépendamment, jette à la poubelle.
La NTC exploite cette corrélation. En apprenant la structure conjointe de tous les canaux d'un matériau à la fois, elle stocke le même matériau dans bien moins de mémoire et le décode à la volée au moment du rendu. La VRAM est une contrainte persistante à mesure que les jeux poussent le détail des textures, donc "faire tenir 8x plus de matériaux dans la même mémoire" est un gain direct et concret plutôt qu'un gadget visuel.
Shaders neuronaux et DirectX Cooperative Vectors
Les shaders neuronaux exécutent de petits réseaux de neurones à l'intérieur un shader programmable (les programmes par pixel/par sommet que le GPU exécute déjà) afin qu'un réseau puisse approximer un effet calculé coûteux là précisément où cet effet est nécessaire. Au lieu de greffer l'AI en passe séparée, le MLP s'exécute au sein du shader sur les unités matricielles du GPU (les Tensor Cores sur le matériel NVIDIA).
Les Tensor Cores gèrent les calculs matriciels sur lesquels ces réseaux s'appuient, distincts des cœurs généralistes qui gèrent le reste du travail. Ce qui fait passer les shaders neuronaux d'une fonctionnalité propre à un seul fournisseur à une capacité plus large de l'industrie, c'est la couche d'API qui les sous-tend. Microsoft a introduit DirectX Cooperative Vectors en préversion avec Shader Model 6.9 en 2025 pour exposer des opérations vectorielles/matricielles dans les shaders HLSL. En 2026, Shader Model 6.9 était passé en version finale, et Microsoft a indiqué que Cooperative Vector était abandonné au profit d'une conception d'algèbre linéaire plus large prévue pour Shader Model 6.10. Ce qu'il faut prudemment retenir, ce n'est pas que les Cooperative Vectors sont l'API définitive, mais que DirectX évolue vers une prise en charge multi-fournisseurs du ML au niveau shader.
À retenir : les six techniques se classent selon l'endroit où s'exécute le réseau : en post-traitement à la fin de l'image, en milieu de pipeline aux côtés du ray tracing, ou à l'intérieur du shader lui-même. Cet emplacement détermine si une technique peut fonctionner en temps réel et quel matériel elle requiert.
Ce qui fonctionne en temps réel, et sur quel matériel
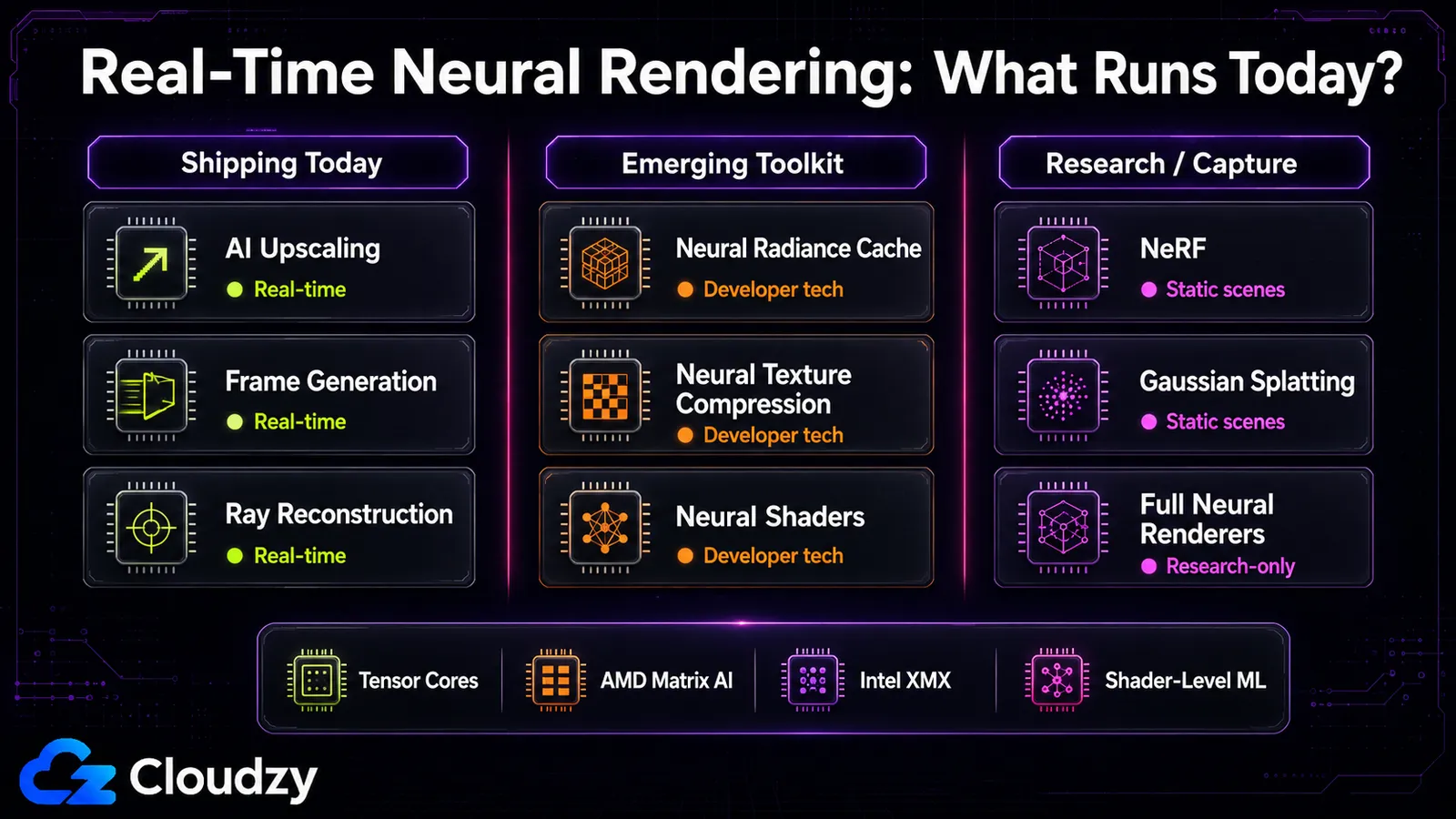
La frontière du temps réel est plus nette que ne le suggère le battage : la mise à l'échelle AI fonctionne généralement avec peu de surcharge, le NRC ajoute environ 2,6 ms, et le 3D Gaussian Splatting approche le temps réel pour les scènes statiques. Le NeRF original et les moteurs entièrement neuronaux comme RenderFormer relèvent fermement de la seule recherche, mettant beaucoup trop de temps par image pour un usage interactif. "Le rendu neuronal est en temps réel" est vrai pour la couche dans le pipeline et faux pour les couches de reconstruction et de moteur complet.
Ce partage suit exactement le spectre. Certains composants dans le pipeline, en particulier la mise à l'échelle, la génération d'images et Ray Reconstruction, fonctionnent déjà dans des jeux commercialisés. D'autres, comme le NRC, la NTC et les shaders neuronaux, se décrivent mieux comme des technologies pour développeurs et des fonctionnalités de boîte à outils émergentes plutôt que comme des fonctionnalités de production courantes. La couche de reconstruction est mitigée : le NeRF original est lent, mais le 3D Gaussian Splatting était une poussée délibérée vers le temps réel et y parvient pour les scènes statiques. La couche du moteur entièrement neuronal (un seul réseau produisant toute l'image) est là où vit la recherche, et les temps par image sont loin d'être interactifs.
Le matériel est l'autre moitié de la réponse, et c'est là que l'histoire multi-fournisseurs prend forme. Chaque technique ici fonctionne sur les unités de calcul matriciel que les GPU modernes embarquent pour l'inférence AI :
- NVIDIA dispose de Tensor Cores sur chaque carte RTX à partir de la série 20, c'est pourquoi la plupart de ces techniques y ont fait leurs débuts.
- AMD : le FSR Upscaling basé sur le ML cible actuellement les GPU RDNA 4 / Radeon RX série 9000 pour la voie ML ; sur le matériel antérieur, le SDK d'AMD bascule sur les voies analytiques FSR 3.1.5. Considérez une prise en charge plus large des GPU plus anciens comme un point de feuille de route mouvant, pas une fonctionnalité FSR 4 garantie, sauf si vous citez une annonce AMD précise.
- Intel utilise les moteurs matriciels XMX des GPU Arc pour XeSS.
DLSS lui-même est verrouillé par génération : la mise à l'échelle remonte jusqu'à la série RTX 20, la génération d'images originale exige la série RTX 40, et la génération multi-images est réservée à la série RTX 50. Si vous cherchez à raisonner sur ce qu'une carte donnée peut faire, ce verrouillage par génération est la réponse concrète, pas le palier marketing.
Ce que vous pouvez utiliser aujourd'hui contre ce qui arrive : la mise à l'échelle, la génération d'images et Ray Reconstruction sont disponibles dans les jeux aujourd'hui. Les composants RTX Kit tels que le NRC, la NTC et les shaders neuronaux sont disponibles comme technologies et outils pour développeurs, mais vous ne devriez pas laisser entendre qu'ils sont tous déjà courants dans les jeux commercialisés. Gaussian Splatting dispose d'outils ouverts utilisables pour la capture de scène. Ce qui n'est pas encore là : les moteurs entièrement neuronaux qui dessinent une image entière avec un seul réseau, les shaders neuronaux multi-fournisseurs matures (la prise en charge AMD est récente) et les fonctionnalités génératives de DLSS 5 (annoncées pour l'automne 2026). Si vous voulez expérimenter le côté reconstruction (exécuter vous-même NeRF ou des charges d'inférence), c'est un travail de calcul GPU , pas quelque chose que votre jeu fait à votre place.
Ce que le rendu neuronal n'est pas : cinq idées fausses

La plupart des débats sur le rendu neuronal deviennent plus simples une fois que vous identifiez à quelle couche du spectre l'affirmation se rapporte. Cinq idées fausses reviennent sans cesse.
1. "La mise à l'échelle DLSS, c'est le rendu neuronal." DLSS est an une application du rendu neuronal, la couche temps réel dans le pipeline, pas tout le domaine. Le terme est antérieur à DLSS et inclut NeRF, Gaussian Splatting et les méthodes génératives. Assimiler les deux revient à faire de "bases de données" un synonyme du seul produit que vous utilisez.
2. "La génération d'images rend les jeux plus rapides." Elle augmente le nombre d'images que vous voyez, ce qui rend le mouvement plus fluide, mais elle s'exécute après le rendu et ajoute de la latence. La fréquence à laquelle le jeu se met à jour et répond à votre entrée n'augmente pas. Pour le jeu compétitif, cette latence est un vrai compromis ; pour la fluidité visuelle, c'est un véritable gain. "Plus rapide" mélange les deux.
3. "DLSS 5 connaît la 3D / lit la scène 3D." C'est celle qu'il vaut le plus la peine de bien comprendre, car la couverture tech ne cesse de la dépeindre de travers. Selon la description de NVIDIA, DLSS 5 prend en entrée les données de couleur et les vecteurs de mouvement de chaque image, puis utilise son modèle entraîné pour inférer la sémantique de la scène : personnages, cheveux, tissus, peau et conditions d'éclairage. Il est ancré dans le contenu du jeu, mais NVIDIA ne le décrit pas comme lisant directement le fichier complet de la scène 3D du jeu. "Guidé par la 3D" signifie que l'inférence est cohérente avec la géométrie (elle respecte la manière dont les surfaces bougent et se relient), pas que le réseau lit directement la géométrie de la scène. La distinction compte car elle borne ce que la technique peut et ne peut pas savoir.
4. "NeRF est en temps réel maintenant." Cela dépend de la technique dont vous parlez, ce qui est exactement le problème du spectre. Le NeRF original n'est pas en temps réel. Le 3D Gaussian Splatting approche le temps réel pour les scènes statiques. Les systèmes de recherche qui rendent une image complète avec un seul réseau (RenderFormer et similaires) ne sont pas du tout en temps réel. "NeRF" est devenu un fourre-tout pour une demi-douzaine de méthodes aux vitesses radicalement différentes.
5. "Le rendu neuronal va bientôt remplacer la rastérisation." Les systèmes d'aujourd'hui sont hybrides : les composants neuronaux se trouvent à l'intérieur un pipeline de rastérisation et de ray tracing, pas à sa place. Remplacer entièrement le pipeline classique par un seul moteur génératif est un objectif de recherche à long terme, pas une orientation produit à court terme. Prenez "l'avenir est entièrement neuronal" comme une direction, pas comme une prédiction datée.
À retenir : la cause unique de presque tout désaccord sur le rendu neuronal, c'est que les gens emploient le même mot pour différentes couches du spectre. Situez d'abord l'affirmation sur le spectre, et la plus grande partie du débat disparaît.
Où tout cela mène
La trajectoire est cohérente avec tout ce qui précède : des pipelines hybrides aujourd'hui, davantage d'étapes passant du calcul à la prédiction, des shaders neuronaux multi-fournisseurs élargissant le cercle de ceux qui peuvent livrer cela, et la frontière du moteur entièrement neuronal encore à des années. La prochaine étape grand public est DLSS 5, annoncé pour l'automne 2026, qui s'engage dans le rendu neuronal génératif en produisant des détails d'éclairage et de matériaux que le jeu n'a jamais calculés, plutôt qu'en interpolant seulement entre des images rendues. NVIDIA a montré la technologie dans des contextes de série RTX 50, mais ses exigences matérielles finales côté grand public doivent être considérées comme non confirmées jusqu'à ce que NVIDIA publie une liste de compatibilité claire.
La perspective a deux faces. Du côté proche, le mouvement qui compte le plus n'est aucune technique isolée. C'est la normalisation. La voie DirectX de Microsoft passe des Cooperative Vectors à une algèbre linéaire plus large au niveau shader, ce qui pourrait permettre aux moteurs de cibler des charges de type neuronal sans miser sur une seule marque de GPU. Du côté lointain, des chercheurs de NVIDIA ont décrit un point d'arrivée d'un futur lointain, parfois évoqué comme un hypothétique "DLSS 10", où le moteur est entièrement neuronal et le pipeline classique disparu (rapporté de seconde main lors d'une table ronde de Digital Foundry ; à prendre comme une direction énoncée, pas une feuille de route). Le bout de l'échelle est un système qui génère un monde cohérent plutôt qu'il n'en dessine un.
Il vaut toutefois la peine de garder son scepticisme. Le détail généré peut s'écarter de l'intention artistique, et un réseau peut halluciner des visuels plausibles mais faux qui n'ont aucun équivalent traditionnel à déboguer : un problème de QA signalé au GDC 2026, et la substance derrière une bonne part de la réaction de "bouillie AI". Construire pour la direction que prend le graphisme ne signifie pas prétendre que le résultat actuel est abouti. Cela signifie observer quelles étapes passent ensuite du calcul à la prédiction, et juger chacune sur ce qu'elle fait à l'image plutôt que sur le mot qui lui est accolé.
Foire aux questions
DLSS est-il du rendu neuronal ?
Oui, mais ce n'en est qu'un type. DLSS est une application du rendu neuronal : précisément la couche temps réel dans le pipeline, couvrant la mise à l'échelle AI et la génération d'images. Le terme plus large est antérieur à DLSS et inclut aussi des méthodes de reconstruction de scène comme NeRF et Gaussian Splatting et des méthodes génératives qui inventent du nouveau détail d'image. Donc toute fonctionnalité DLSS est du rendu neuronal, mais une grande partie du rendu neuronal n'est pas DLSS.
Quelle est la différence entre le rendu neuronal et le ray tracing ?
Le ray tracing simule la lumière en calculant comment les rayons rebondissent dans une scène ; le rendu neuronal prédit les résultats à partir d'un réseau entraîné au lieu de les calculer. Ce ne sont pas des rivaux. Ils se combinent. Ray Reconstruction, par exemple, utilise un réseau de neurones pour débruiter la sortie bruitée en ray tracing, et le cache de radiance neuronal prédit la lumière rebondie pour que le traceur de rayons puisse s'arrêter tôt. Les techniques neuronales rendent le ray tracing abordable en temps réel.
La génération d'images DLSS ajoute-t-elle de la latence ?
Oui. La génération d'images s'exécute après le rendu d'une image et insère des images prédites entre les images rendues, ce qui ajoute de la latence au lieu de la supprimer : Reflex 2 de NVIDIA existe précisément pour compenser. Elle augmente la fluidité perçue (plus d'images affichées) sans augmenter la vitesse à laquelle le jeu se met à jour et répond à l'entrée. Pour le jeu compétitif, c'est un compromis ; pour la fluidité en solo, c'est généralement un gain net.
NeRF est-il en temps réel ?
Cela dépend de la technique dont vous parlez. Le NeRF original n'est pas en temps réel. Le 3D Gaussian Splatting, une méthode ultérieure, approche le temps réel pour les scènes statiques. Les moteurs entièrement neuronaux qui dessinent une image entière avec un seul réseau relèvent de la seule recherche et sont loin des vitesses interactives. "NeRF" est souvent employé vaguement pour couvrir plusieurs méthodes aux performances très différentes, ce qui est la source de la plupart des confusions.
Le rendu neuronal remplacera-t-il la rastérisation ?
Pas de sitôt. Les systèmes d'aujourd'hui sont hybrides : les composants neuronaux s'exécutent à l'intérieur d'un pipeline de rastérisation et de ray tracing, pas à sa place. Remplacer entièrement le pipeline classique par un seul moteur génératif est un objectif de recherche à long terme, pas un produit à court terme. La direction réaliste est que davantage d'étapes du pipeline passent du calculé au prédit au fil du temps, la rastérisation faisant encore un vrai travail pendant des années.
Qu'est-ce que la compression de textures neuronale ?
La compression de textures neuronale (NTC) est une méthode neuronale qui compresse ensemble tous les canaux de texture d'un matériau (couleur, normales, rugosité et le reste), atteignant jusqu'à 8x d'économies de VRAM par rapport à la compression par blocs traditionnelle à qualité visuelle comparable, selon NVIDIA. Elle fonctionne en apprenant les corrélations entre canaux que la compression par blocs, qui comprime chaque canal séparément, met au rebut. Le matériau compressé est décodé à la volée au moment du rendu.


