
Vous ouvrez la page GGUF d'un modèle populaire sur Hugging Face et quinze fichiers vous font face : Q4_0, Q4_K_S, Q4_K_M, Q5_K_M, Q6_K, Q8_0, plus des dossiers séparés pour GPTQ, AWQ et EXL2 à une demi-douzaine de réglages de bits. Vous faites le calcul de coin de table pour le fichier « 4-bit » : 4 bits × 8 milliards de paramètres ÷ 8 = 4 Go. Mais le fichier indique 4,6 Go. Et une fois chargé, le modèle utilise encore plus de mémoire que ça.
Les noms de fichiers ne sont pas du bruit. Ils encodent une information réelle et exploitable sur la largeur de bits, le runtime qui les charge et le matériel dont ils ont besoin. Les tableaux de dimensionnement que vous avez lus vous disent qu'un modèle de 70B nécessite environ 40 Go, utile, mais ils ne décodent jamais le format lui-même ni n'expliquent pourquoi le modèle en cours d'exécution veut plus de mémoire que le fichier sur disque.
Voici donc le plan : décoder la convention de nommage GGUF (avec les vraies largeurs de bits, pas les nominales), déterminer lequel des quatre formats votre matériel peut réellement exécuter, et tenir compte de l'unique coût mémoire invisible dans chaque taille de fichier, le cache KV. À la fin, vous saurez lire un dépôt de modèle et prédire son comportement au chargement.
En bref
- Les niveaux de quantification GGUF correspondent à des largeurs de bits effectives, pas au chiffre exact du nom. Q4_K_M équivaut à environ 4,89 bits par poids, ce qui explique pourquoi un fichier « 4-bit » de 8B atterrit autour de 4,6 GiB au lieu de l'estimation naïve en 4 bits.
- GGUF est l'option la plus portable, car llama.cpp peut l'exécuter sur CPU, GPU ou en configuration hybride. GPTQ, AWQ et EXL2 sont plus spécifiques au GPU et au runtime, EXL2 étant particulièrement lié aux workflows NVIDIA/CUDA.
- Le cache KV est distinct des poids du modèle et croît avec la longueur du contexte. C'est la raison pour laquelle un modèle qui se charge parfaitement peut malgré tout planter avec une erreur de mémoire insuffisante une fois la conversation longue.
- Au-delà de la plage 5 bits, la perte de qualité est généralement faible. Autour de Q4, le compromis reste pratique pour de nombreux usages locaux. En dessous de 4 bits, le coût en qualité devient bien plus perceptible. Q4_K_M reste un choix par défaut courant dans la communauté, tandis que Q5_K_M et Q6_K sont plus sûrs quand vous avez de la mémoire à revendre.
Que signifie Q4_K_M dans un nom de fichier GGUF ?

Un nom de quantification GGUF suit le schéma Q[bits]_[K]_[S/M/L]. Le nombre correspond au nombre de bits cible par poids, K signifie qu'il s'agit d'un « K-quant » qui stocke des facteurs d'échelle par petit bloc de poids, et le S, M ou L final indique le palier de taille/qualité (small, medium, large). Comme les K-quants stockent une échelle et une valeur minimale pour chaque bloc en plus des poids, la largeur de bits effective est supérieure au chiffre affiché. Q4_K_M atterrit à environ 4,89 bits par poids, et non 4.
Cet écart répond entièrement à la question « pourquoi mon fichier 4-bit fait-il 4,6 Go ? ». L'estimation naïve suppose que chaque poids coûte exactement 4 bits. En réalité, les K-quants consacrent des bits supplémentaires par bloc aux métadonnées qui rendent la quantification à faible nombre de bits précise, l'échelle et le minimum par bloc qui permettent au runtime de reconstituer chaque poids. Multipliez 4,89 bits par 8 milliards de poids et vous obtenez près de 4,58 GiB, ce qui correspond au poids réel du fichier.
Voici les largeurs de bits effectives et les tailles de fichiers mesurées, tirées de llama.cpp quantize documentation pour Llama 3.1 8B comme modèle de référence, ainsi que le coût en perplexité de chaque niveau mesuré dans l'étude d'évaluation de la quantification llama.cpp (arXiv:2601.14277) sur Llama-3.1-8B-Instruct :
| Niveau GGUF | BPW effectif | ~Taille du fichier (8B) | Perplexité vs F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3,4 GiB | +22% |
| Q3_K_M | 3.95 | ~3,7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4,0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4,4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4,6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5,3 GiB | +1.1% |
| Q6_K | 6.56 | ~6,1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8,0 GiB | +0.1% |
| F16 | 16.00 | ~15,0 GiB | référence |
*Les chiffres de perplexité sont spécifiques à Llama-3.1-8B-Instruct, tirés d'arXiv:2601.14277. La colonne BPW/taille de fichier et la colonne perplexité proviennent de deux sources différentes, mesurées séparément, lisez donc ce tableau comme une référence pratique côte à côte plutôt que comme le résultat d'un seul benchmark. La dégradation varie selon la tâche, le raisonnement mathématique souffre généralement plus que le raisonnement de bon sens à faible largeur de bits, mais la tendance générale se vérifie : 5 bits et plus sont généralement plus sûrs, Q4 est la zone de compression pratique, et 3 bits est le seuil où la perte de qualité devient bien plus difficile à ignorer.
En pratique : Q4_K_M est le choix par défaut que la plupart des gens devraient privilégier, Q5_K_M et Q6_K sont les options orientées qualité quand vous avez de la mémoire à revendre, et tout ce qui est au niveau ou en dessous de Q3_K_S est un dernier recours pour un matériel qui ne peut vraiment pas contenir plus.
Quel format de quantification devriez-vous télécharger : GGUF, GPTQ, AWQ ou EXL2 ?

GGUF est le plus portable des quatre : il s'exécute sur CPU, GPU, ou en combinaison des deux via llama.cpp, c'est donc le choix le plus sûr quand vous n'êtes pas certain de ce que votre matériel peut supporter. GPTQ, AWQ et EXL2 sont plus spécifiques au GPU et au runtime. En pratique, ils sont les plus courants sur des configurations NVIDIA/CUDA, mais la prise en charge de GPTQ et AWQ peut varier selon le loader et la pile de service ; vLLM, par exemple, distingue la prise en charge de la quantification selon le matériel et l'implémentation. Si vous exécutez localement sur un Mac, une carte AMD, ou une machine avec seulement un CPU, GGUF reste la réponse la plus sûre. Si vous avez un GPU NVIDIA et voulez les tokens les plus rapides possibles, les trois autres entrent en jeu.
| Format | Matériel/runtime | Vitesse (relative) | VRAM vs concurrents | Idéal pour |
|---|---|---|---|---|
| GGUF Q4_K_M | Le plus large, CPU, GPU, ou hybride via llama.cpp | Modéré | Le plus bas | N'importe quel matériel ; choix local par défaut |
| GPTQ 4-bit | Généralement CUDA/GPU en priorité ; dépend du runtime | Rapide (ExLlama) | Moyen | GPU en priorité, outillage historique |
| AWQ 4-bit | Généralement CUDA/GPU en priorité ; dépend du runtime | Rapide | Le plus élevé | Service via vLLM/TGI, chargement rapide |
| EXL2 ~4,9 bpw | NVIDIA/CUDA en priorité | Le plus rapide | Faible à moyen | Vitesse maximale sur NVIDIA |
Une réserve sur ce tableau : les classements de vitesse et de VRAM proviennent benchmark oobabooga, réalisé sur du matériel de l'ère 2023/2024. Considérez le relatif comme durable. EXL2 est conçu pour la vitesse, AWQ échange du VRAM contre un chargement rapide, GGUF reste léger et portable, mais ne lisez pas les chiffres absolus originaux de tokens par seconde comme étant d'actualité. Un GPU 2026 affichera un débit brut très différent ; c'est la hiérarchie relative qui perdure.
Voici donc la règle de décision qui en découle : si vous avez une carte NVIDIA et que la vitesse prime, EXL2 ; si vous voulez le choix local par défaut le plus sûr sur différents matériels, GGUF. AWQ et GPTQ comptent surtout quand une pile de service spécifique (vLLM, TGI) ou un outillage existant vous y pousse.
Pourquoi un LLM local utilise-t-il plus de mémoire que son fichier ?
La taille du fichier ne représente que les poids du modèle. À l'exécution, vous payez aussi le cache KV (l'état d'attention pour chaque token de votre fenêtre de contexte), les activations (le calcul intermédiaire d'une passe avant) et le surcoût du framework et du pilote. Ensemble, les éléments hors poids ajoutent en général 10 à 20 % en plus des poids pour une configuration mono-utilisateur, et le cache KV à lui seul peut éclipser tout le reste une fois le contexte long. Un fichier de 4,6 Go peut nécessiter bien plus de 4,6 Go de mémoire pour fonctionner.
Imaginez la mémoire d'exécution comme quatre composants empilés les uns sur les autres :
- Poids du modèle. Le fichier que vous avez téléchargé. C'est le seul élément visible avant le chargement.
- Cache KV. L'état d'attention pour la fenêtre de contexte. Petit à contexte court, énorme à contexte long. C'est la prochaine section, car c'est celle qui surprend le plus les gens.
- Activations. La mémoire de travail d'une passe avant. Pour une inférence locale à flux unique (taille de lot 1), c'est faible, typiquement quelques centaines de mégaoctets.
- Surcoût du framework. L'empreinte propre du runtime plus le contexte du pilote GPU. Pour un runtime local léger, cela peut être faible comparé aux poids du modèle et au cache KV ; des frameworks de service plus lourds peuvent en réserver bien plus. La réservation de mémoire propre à votre système d'exploitation se situe en dehors de tout cela, et reste distincte.
Les poids et le surcoût du framework sont prévisibles. Le cache KV est la variable qui transforme un modèle qui « tient » en un modèle qui plante, il vaut donc la peine de faire le calcul réel.
Combien de mémoire le cache KV utilise-t-il ?
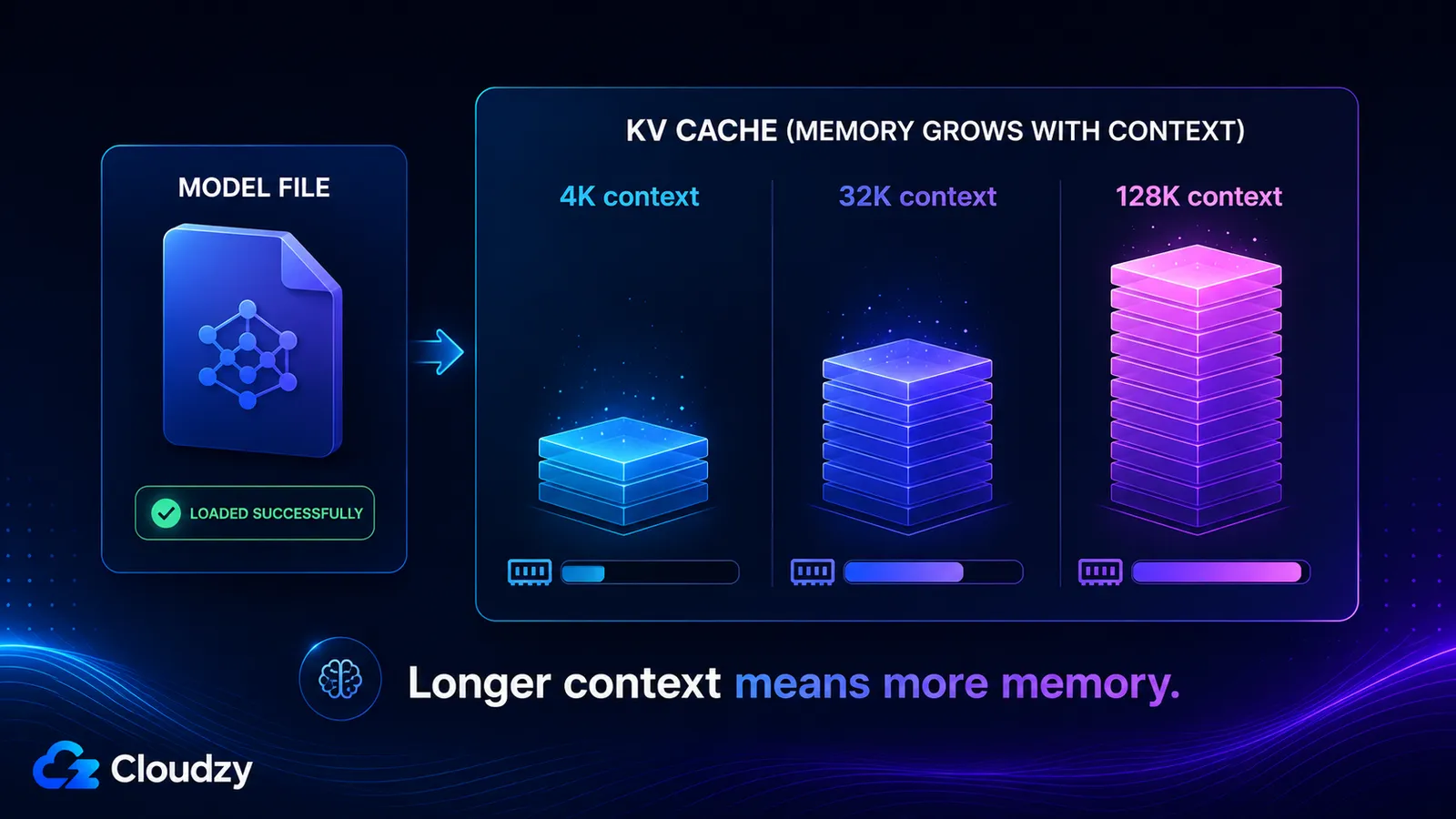
Le cache KV stocke les vecteurs clé et valeur pour chaque token de votre fenêtre de contexte, il croît donc à peu près linéairement avec la longueur du contexte et est complètement distinct des poids du modèle. Sa taille est déterminée par le nombre de couches du modèle, son nombre de têtes KV, la dimension des têtes, la longueur du contexte et la précision du cache. Activez un long contexte et vous pouvez ajouter des dizaines de gigaoctets dont un modèle qui se chargeait pourtant sans problème ne vous avait jamais averti.
La formule est assez courte pour être retenue :
Octets du cache KV = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
Le 2 initial correspond aux deux tenseurs stockés par token, un pour les clés, un pour les valeurs. bytes_per_element vaut 2 pour un cache FP16. Le reste, ce sont des constantes d'architecture que vous pouvez lire sur une fiche de modèle.
Calculons pour Llama 3.1 8B, qui a 32 couches, 8 têtes KV, et une dimension de tête de 128. Pour un contexte de 4 096 tokens, taille de lot 1, cache FP16 :
2 × 32 × 8 × 128 × 4096 × 2 octets ≈ 536 Mo
Augmentez le contexte et le chiffre augmente avec lui, car tous les termes sauf context_tokens sont fixes :
- Contexte 4K : ~536 Mo
- Contexte 32K : ~4,3 Go
- Contexte 128K : ~17 Go
Ces deux derniers chiffres expliquent pourquoi un modèle peut annoncer une fenêtre de contexte de 128K, se charger sans problème, puis épuiser la mémoire dès que vous utilisez réellement cette fenêtre. Le cache KV à pleine capacité de contexte est plus volumineux que les poids quantifiés eux-mêmes.
Voici ce qui rend les modèles modernes à long contexte possibles : Llama 3.1 8B utilise Grouped Query Attention (GQA)Il possède 32 têtes de requête mais seulement 8 têtes KV, le cache stocke les vecteurs clé/valeur pour 8 têtes, pas 32. Appliquez la même formule avec 32 têtes KV (l'ancien design Multi-Head Attention, où les têtes KV égalent les têtes de requête) et chaque chiffre ci-dessus est multiplié par 4. Les 17 Go à 128K deviennent 68 Go. GQA est la raison architecturale pour laquelle le calcul reste viable à mesure que les fenêtres de contexte se sont agrandies.
La taille du fichier n'est pas votre budget mémoire. Quand les poids ou le cache KV ne tiennent plus dans le chemin mémoire rapide et que le runtime doit basculer vers la RAM système via PCIe, le débit ne se dégrade pas en douceur. Il s'effondre dès que vous déplacez des données via PCIe à chaque token. Budgétisez la mémoire de sorte que les poids et le cache KV à votre longueur de contexte réelle tiennent tous les deux, pas seulement les poids.
Comment choisir une quantification pour votre GPU ou votre Mac ?
Partez de votre matériel et de votre runtime. Les possesseurs de GPU NVIDIA ont le plus large éventail de choix et devraient soupeser EXL2 pour la vitesse brute ou GGUF pour la portabilité. Si vous êtes sur AMD, Apple Silicon, un matériel uniquement CPU, ou une configuration mixte, GGUF via llama.cpp est généralement le point de départ le plus sûr. À partir de là, choisissez le niveau de quantification le plus élevé qui tienne une fois que vous avez budgétisé le cache KV à la longueur de contexte que vous utilisez réellement, pas au maximum du modèle.
Un piège d'Apple Silicon à connaître : le GPU n'obtient pas la totalité de votre mémoire unifiée (voir notre article compagnon sur ce qu'est réellement la mémoire unifiée , pour une vue d'ensemble complète du fonctionnement de ce pool partagé). La communauté du self-hosting a documenté une limite d'environ 75 % de la mémoire unifiée totale disponible pour le GPU (ce n'est pas officiellement confirmé par Apple et peut évoluer avec les mises à jour de macOS). Un « Mac 64 Go » offre donc en réalité environ 48 Go pour le modèle et son cache KV, planifiez en fonction du chiffre le plus bas.
Cet article traite de la lecture du format et de la prédiction de son comportement à l'exécution : décoder le nom de quantification, choisir le format que votre matériel supporte, et budgétiser le cache KV séparément des poids. Faire correspondre un modèle précis à une quantité de mémoire précise, la table de correspondance taille-mémoire, est une question connexe mais distincte que nous traiterons dans un futur article compagnon.
Lisez le dépôt
Vous pouvez désormais regarder la page d'un modèle et la lire au lieu de deviner. Décodez le nom de quantification pour obtenir sa largeur de bits effective, reconnaissez que GGUF est le format local le plus large tandis que GPTQ, AWQ et EXL2 sont plus spécifiques au runtime, et souvenez-vous que la taille du fichier n'est qu'un plancher, le cache KV s'empile par-dessus et croît avec votre contexte. Ouvrez les fichiers du modèle voulu, choisissez le format que votre matériel peut exécuter, sélectionnez le niveau de quantification le plus élevé qui tienne une fois que vous avez laissé de la marge pour le cache KV à votre longueur de contexte réelle, et vous éviterez le plantage par manque de mémoire qui a lancé toute cette question.
Foire aux questions
Que signifie Q4_K_M ?
Q4_K_M est un niveau de quantification GGUF : environ 4 bits par poids (Q4), utilisant la mise à l'échelle par bloc des K-quants (K), au palier de taille/qualité moyen (M). Sa largeur de bits effective effective est d'environ 4,89 bits par poids, pas exactement 4, car les K-quants stockent une échelle et une valeur minimale pour chaque bloc de poids. C'est pourquoi un fichier de modèle 8B « 4-bit » pèse environ 4,6 Go plutôt que 3,5 Go.
La quantification réduit-elle la qualité des LLM ?
Oui, mais le coût dépend fortement de la mesure dans laquelle vous poussez la compression. Sur Llama-3.1-8B-Instruct mesuré dans arXiv:2601.14277, la perplexité n'augmente que d'environ 0,4 % à Q6_K et reste proche de 1 % sur toute la bande Q5. Descendez à Q4 et l'augmentation reste modeste (quelques pour cent) ; en dessous de Q3_K_M, elle grimpe fortement, atteignant +22 % à Q3_K_S. Pour la plupart des usages, Q4_K_M et au-dessus est pratiquement sans perte ; la pénalité forte se situe à 3 bits et en dessous.
Quelle est la différence entre GGUF, GPTQ, AWQ et EXL2 ?
GGUF (exécuté par llama.cpp) est le format portable, il fonctionne sur CPU, GPU, ou en configuration hybride, sur un large éventail de matériels. GPTQ, AWQ et EXL2 sont plus spécifiques au GPU et au runtime. En 4-bit, les quatre peuvent se retrouver dans une bande de qualité étroite, si bien que la différence pratique se joue sur le matériel, le support du loader, la vitesse et l'usage de VRAM : EXL2 est le choix axé vitesse pour NVIDIA/CUDA, AWQ est courant dans les piles de service, GPTQ convient à l'outillage GPU et aux dépôts de modèles plus anciens, et GGUF reste l'option locale la plus portable.
Pourquoi mon LLM local utilise-t-il plus de mémoire que le fichier ?
La taille du fichier ne représente que les poids du modèle. À l'exécution, vous payez aussi le cache KV (l'état d'attention pour chaque token de la fenêtre de contexte), les activations, et le surcoût du framework plus du pilote. Le cache KV est habituellement le coupable quand l'écart est important, car il croît avec la longueur du contexte et est alloué séparément des poids, un modèle dont le fichier fait quelques gigaoctets peut nécessiter bien plus de mémoire une fois un long contexte défini.
Comment la longueur du contexte affecte-t-elle l'utilisation de la mémoire ?
Le cache KV croît à peu près linéairement avec la longueur du contexte, doubler votre contexte double donc approximativement le cache. Pour Llama 3.1 8B, le cache fait environ 536 Mo à 4K tokens, ~4,3 Go à 32K, et ~17 Go à 128K (FP16, flux unique). Cette croissance est entièrement distincte des poids du modèle, ce qui explique pourquoi déclarer une longue fenêtre de contexte peut pousser un modèle vers une erreur de mémoire insuffisante, même s'il s'était chargé sans problème.


