
機械学習の最も重要な側面の1つは、正確で信頼性の高い予測を達成することです。この目標に向けた革新的なアプローチの1つが、機械学習におけるブートストラップ集約(より一般的にはバギングと呼ばれます)です。この記事では、機械学習におけるバギングについて説明し、機械学習におけるバギングとブースティングを比較し、バギング分類器の例を提供し、バギングの仕組みを説明し、機械学習におけるバギングの利点と欠点を探ります。
機械学習のバギングとは?
これら2つは人気のある記事で使用されている唯一の関連画像です。デザインチームがCloudzyバージョンを作成する場合、一方または両方を使用できます(1つはここに、もう1つは別の場所に)。
バギングとは
複数の人に物体の重さを推定してもらうことを想像してください。個々の推定値は大きく異なるかもしれませんが、すべての推定値を平均することで、より信頼性の高い値に到達できます。これがバギングの本質です。複数のモデルの出力を組み合わせて、より正確で安定した予測を生成します。
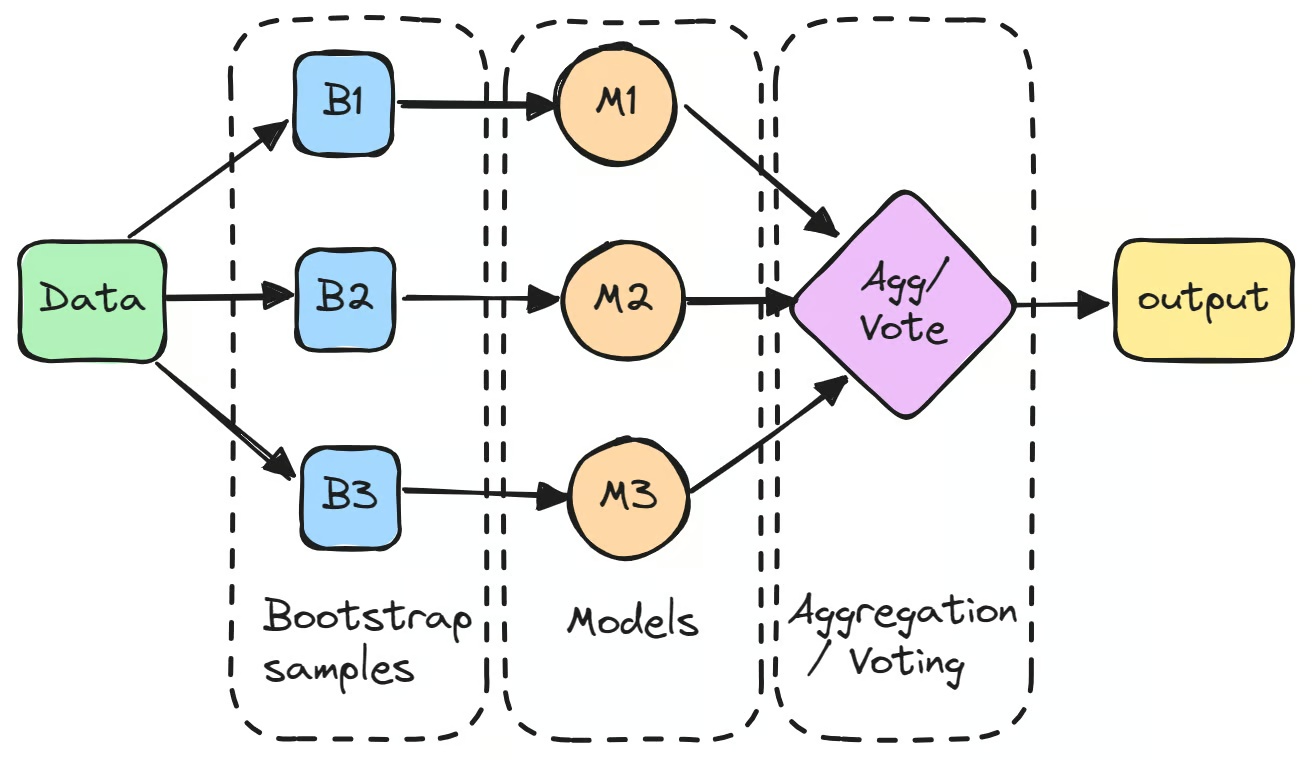
プロセスはブートストラップを通じて元のデータセットから複数のサブセットを作成することから始まります。これは放置復元抽出法で行われます。各サブセットは独立して別々のモデルを訓練するために使用されます。
個々のモデルは「弱学習器」と呼ばれることが多く、高分散のため単独ではあまり良いパフォーマンスを発揮しないかもしれません。しかし、それらの予測が集約されると(回帰タスクでは通常平均化、分類タスクでは多数決投票)、結合された結果は単一モデルのパフォーマンスを上回ることが多いです。
よく知られたバギング分類器の例はランダムフォレストアルゴリズムで、予測パフォーマンスを向上させるために決定木のアンサンブルを構成します。ただし、バギングは機械学習でのブースティングと混同してはいけません。ブースティングは偏差を減らすためモデルを順序立てて訓練する異なるアプローチを取りますが、バギングは分散を減らすため複数のモデルを並行して訓練することで機能します。
バギングとブースティングは両方ともモデルのパフォーマンスを向上させることを目指していますが、モデルの異なる側面を対象にしています。
バギングが役立つ理由
機械学習におけるバギングの主な利点の1つは、分散を減らす能力があることです。これはモデルが未知のデータに対してより良く汎化するのに役立ちます。バギングは決定木のようなトレーニングデータの変動に敏感なアルゴリズムを扱う場合に特に有効です。
過学習を防ぐことで、より安定した信頼性の高いモデルが実現します。機械学習でバギングとブースティングを比較すると、バギングは複数のモデルを並行して訓練することで分散を減らすことに焦点を当て、ブースティングはモデルを順序立てて訓練することで偏差を減らすことを目指します。
機械学習でのバギングの例は金融リスク予測で見られます。歴史的な市場データの異なるサブセットで複数の決定木を訓練します。これらの予測を集約することで、バギングはより堅牢な予測モデルを作成し、個々のモデルエラーの影響を減らします。
本質的に、機械学習におけるバギングは複数のモデルの集合知を活用して、個々のモデルだけから得られるものよりも正確で信頼性の高い予測を提供します。
機械学習でのバギングの仕組み:ステップバイステップ
バギングがモデルのパフォーマンスをどのように向上させるかを完全に理解するために、プロセスをステップバイステップで見ていきましょう。
データセットから複数のブートストラップサンプルを取得する
機械学習でのバギングの最初のステップは、ブートストラップを使用して元のデータセットから複数の新しいサブセットを作成することです。このテクニックはデータをランダムに復元抽出で取得することを含みます。同じサブセット内に複数回表示されるデータポイントもあれば、全く表示されないものもあります。このプロセスは、各モデルがデータの少し異なったバージョンで訓練されることを確保するために行われます。
各サンプルで別々のモデルを訓練する
各ブートストラップサンプルは、その後、通常は決定木のような同じタイプの別々のモデルを訓練するために使用されます。「ベース学習器」または「弱学習器」と呼ばれるこれらのモデルは、それぞれのサブセットで独立して訓練されます。バギング分類器の例はランダムフォレストアルゴリズムで使用される決定木で、多くのバギングベースのモデルの基盤を形成します。個々のモデルは単独ではあまり良いパフォーマンスを発揮しないかもしれませんが、それぞれ特定のトレーニングデータに基づいた独特の洞察を提供します。
予測を集約する
モデルの訓練後、その予測は集約されて最終的な出力を形成します。
- 回帰タスクでは、予測が平均化されて、モデルの分散を減らします。
- 分類タスクでは、最終的な予測は多数決投票によって決定されます。最も多くのモデルが予測するクラスが選択されます。この方法は単一モデルの出力と比較して、より安定した予測を提供します。
最終予測
複数のモデルからの予測を組み合わせることで、バギングは任意の1つのモデルからのエラーの影響を減らし、全体的な精度を向上させます。この集約プロセスがバギングをこのような強力なテクニックにする理由です。特に決定木のような高分散モデルが使用される機械学習タスクでは効果的です。個々のモデルの予測における矛盾を効果的に平滑化し、より強力な最終モデルをもたらします。
バギングは予測の安定化に効果的ですが、覚えておくべきいくつかのことがあります。バギングの一般的な目的は分散を減らすことですが、ベースモデルが複雑すぎる場合、過学習のリスクがあります。
また計算コストが高いため、ベース学習器の数を調整したり、より効率的なアンサンブル方法を検討したりすることが役立ちます。そして MLとDLに適した正しいGPUを選択する は常に重要です。
より良い結果のために、ベース学習器の間でモデルの多様性を持つことを確認してください。また、クラスバランスの取れていないデータを扱う場合、バギングを適用する前にSMOTEなどのテクニックが少数派クラスでのパフォーマンス不足を避けるのに役立つ可能性があります。
バギングの応用
バギングの仕組みを理解したら、次は実際にどこで使われているかを見てみましょう。バギングは様々な業界で採用され、複雑なシナリオでの予測精度と安定性を向上させています。最も実用的な応用例を見ていきます。
- 分類と回帰 バギングは分散を低減し、過学習を防ぐことで、分類器と回帰器のパフォーマンスを向上させるために広く使われています。例えば、バギングを利用するランダムフォレストは、画像分類や予測モデリングなどのタスクで効果的です。
- 異常検知 詐欺検出やネットワーク侵入検出などの分野では、バギングアルゴリズムが優れたパフォーマンスを発揮し、 データ内の外れ値と異常を効果的に検出します.
- 金融リスク評価 銀行ではバギング技術を用いてクレジットスコアリングモデルを強化し、ローン承認プロセスと金融リスク評価の精度を向上させています。
- 医療診断 医療分野では、バギングはMRIデータセットを分析してアルツハイマー病などの神経認知障害を検出するために応用され、 早期診断と治療計画を支援しています.
- 自然言語処理(NLP) バギングは複数モデルからの予測を集約することで、テキスト分類とセンチメント分析などのタスクに貢献し、より堅牢な言語理解をもたらします。
バギングの利点と欠点
機械学習の他の手法と同様に、バギングにも利点と欠点があります。これらを理解することで、モデルにバギングをいつどのように適用するかを判断できます。
バッギングの利点:
- 分散と過学習を低減 バギングの最大の利点の一つは、分散を低減して過学習を防ぐ能力です。複数のモデルをデータの異なるサブセットで学習させることで、モデルが訓練データの変動に過度に敏感になることを防ぎ、より汎用的で安定したモデルを実現できます。
- 高分散モデルとの相性が良い バギングは決定木のような高分散モデルで特に効果的です。これらのモデルはデータに過学習しやすく高い分散を持ちますが、バギングは複数モデルの平均化または投票によってこの問題を軽減します。予測の信頼性が高まり、データノイズの影響を受けにくくなります。
- モデルの安定性とパフォーマンスを向上 異なるデータサブセットで学習させた複数モデルを組み合わせることで、バギングはしばしば全体的なパフォーマンスの向上につながります。予測精度を高めながら、データセット内のわずかな変化に対するモデルの敏感性を低減し、結果としてより信頼性の高いモデルを実現します。
バッギングの欠点:
- 計算コストの増加 バギングは複数モデルの学習が必要であるため、計算コストが自然に増加します。特に大規模なデータセットや決定木のような複雑なモデルを使う場合、多数のモデルからの予測を学習して集約するのに時間がかかります。
- 低分散モデルには効果的でない バギングは高分散モデルで非常に効果的ですが、線形回帰のような低分散モデルに適用してもあまり効果がありません。こうしたモデルは既に低いエラー率を持っているため、複数の予測を集約してもほとんど改善されません。
- 解釈可能性の喪失 複数モデルの組み合わせにより、バギングは最終的なモデルの解釈性を低下させることがあります。例えば、ランダムフォレストでは意思決定プロセスが複数の決定木に基づいているため、特定の予測がどのような根拠に基づいているのかを追跡するのが難しくなります。
バギングはいつ使うべき?
機械学習プロジェクトでバギングを適用するタイミングを知ることが、最適な結果を実現するカギになります。この手法は特定の状況で効果的ですが、すべての問題に対して常に最適な選択肢とは限りません。
モデルが過学習に陥りやすい場合
バギングの主な用途の1つは、モデルが過学習に陥りやすい場合、特に決定木のような高分散モデルの場合です。これらのモデルは訓練データでは良好な性能を示すことがありますが、訓練データの特定のパターンに過度に適合するため、未知データへの一般化に失敗することがよくあります。
バギングはこの問題に対して、データのさまざまなサブセットで複数のモデルを訓練し、平均またはボーティングにより、より安定した予測を生成することで対処します。これにより過学習の可能性が低減され、新しい未知データに対するモデルの対応力が向上します。
安定性と精度を向上させたい場合
解釈可能性を大きく損なわずにモデルの安定性と精度を向上させたい場合、バギングは優れた選択肢です。複数のモデルからの予測を集約することで、最終結果がより強力になります。これは特にノイズの多いデータを扱うタスクで有用です。
分類問題であれ回帰タスクであれ、バギングはより一貫性のある結果を生成するのに役立ち、効率を保ちながら精度を向上させます。
十分な計算リソースがある場合
バギングを使用するかどうかを判断する際のもう1つの重要な要因は、計算リソースの可用性です。バギングは複数のモデルを同時に訓練する必要があるため、特に大規模なデータセットや複雑なモデルの場合、計算コストが大きくなる可能性があります。
必要な計算能力にアクセスできる場合、バギングのメリットはコストを大きく上回ります。ただし、リソースが限られている場合は、代替手法を検討するか、アンサンブル内のモデル数を制限することをお勧めします。
高分散モデルを扱う場合
バギングは、訓練データの変動に敏感で高分散を持つモデルを扱う場合に特に有用です。例えば、決定木は訓練データに基づいて性能が大きく変わることが多いため、ランダムフォレストの形でバギングと共に使用されることがよくあります。
異なるデータサブセットで複数のモデルを訓練し、それらの予測を組み合わせることで、バギングは分散を平滑化し、より信頼性の高いモデルをもたらします。
堅牢な分類器が必要な場合
分類問題に取り組んでおり、堅牢な分類器が必要な場合、バギングは予測の安定性を大幅に向上させることができます。例えば、バギング分類器の例であるランダムフォレストは、多くの個別決定木の結果を集約することで、より正確な予測を提供できます。
このアプローチは、個別のモデルは弱いかもしれませんが、それらの組み合わせた力が強力な全体モデルをもたらす場合に効果的です。
さらに、バギング手法を効率的に実装するための適切なプラットフォームを探している場合、以下のようなツールがあります。 Databricks と Snowflake は、大規模なデータセットを管理し、バギングのようなアンサンブル手法を実行するのに非常に有用な統合分析プラットフォームを提供します。
機械学習に対して、より技術的でないアプローチを探している場合、 ノーコードAIツール も選択肢になるかもしれません。バギングのような高度な手法に直接焦点を当ててはいませんが、多くのノーコードプラットフォームはユーザーが広範なコーディングスキルなしでバギングを含むアンサンブル学習手法を試験できるようにします。
これにより、より高度な手法を適用しながら、コードの基礎ではなくモデル性能に焦点を当てて、正確な予測を実現できます。
まとめ
機械学習におけるバギングは、分散を削減し安定性を向上させることでモデル性能を高める強力な手法です。異なるデータサブセットで訓練された複数のモデルの予測を集約することで、バギングはより正確で信頼性の高い結果をもたらすのに役立ちます。特に決定木のような高分散モデルの場合に効果的であり、過学習を防ぎ、未知データへのモデルの一般化を確保するのに役立ちます。
バギングは過学習の削減と精度の向上など大きなメリットがありますが、いくつかのトレードオフがあります。複数のモデルを訓練することによる計算コストの増加と、解釈可能性の低下です。これらの欠点にもかかわらず、性能を向上させる能力により、ブースティングやスタッキングなどの他の手法と並んで、アンサンブル学習における価値のある手法となります。
機械学習プロジェクトでバギングを使用したことがありますか。ぜひ、あなたの経験とそれがどのように機能したかを教えてください。


