
Hugging Face上で人気モデルのGGUFページを開くと、15個のファイルが並んでいる。Q4_0、Q4_K_S、Q4_K_M、Q5_K_M、Q6_K、Q8_0、さらにGPTQ、AWQ、EXL2用にそれぞれ6種類ほどのビット設定の個別フォルダがある。「4ビット」のファイルについて概算計算をしてみる。4ビット×80億パラメータ÷8=4GB。しかしファイルには4.6GBと書かれている。そして実際にロードすると、モデルはそれ以上のメモリを使う。
ファイル名はノイズではない。ビット幅、それらをロードするランタイム、必要とするハードウェアについての実在する、学習可能な情報を符号化している。これまで見てきたサイズ算定表は、70Bモデルにはおよそ40GB必要だと教えてくれる。有用ではあるが、フォーマット自体を解読したり、なぜ実行中のモデルがディスク上のファイルより多くのメモリを要求するのかを説明したりすることは決してない。
そこで計画はこうだ。GGUFの命名規則を解読し(名目上のビット幅ではなく真のビット幅で)、4つのフォーマットのうちどれが実際に自分のハードウェアで動かせるかを見極め、そしてどのファイルサイズにも表れない唯一のメモリコスト、KVキャッシュを考慮に入れる。読み終える頃には、モデルのリポジトリを読んで、ロード時の挙動を予測できるようになるはずだ。
要約
- GGUFの量子化レベルは実効ビット幅であり、名前に含まれる正確な数値ではない。Q4_K_Mは重みあたり約4.89ビットであり、これが「4ビット」の8Bファイルが単純な4ビット見積もりではなく約4.6GiBになる理由である。
- GGUFはllama.cppがCPU、GPU、あるいはハイブリッド構成で実行できるため、最も可搬性の高い選択肢である。GPTQ、AWQ、EXL2はよりGPUおよびランタイム固有であり、特にEXL2はNVIDIA/CUDAのワークフローに強く結びついている。
- KVキャッシュはモデルの重みとは別物であり、コンテキスト長とともに増大する。これが、きれいにロードされたモデルであっても、会話が長くなるとメモリ不足でクラッシュし得る理由である。
- 5ビット台より上では、品質低下は通常小さい。Q4付近では、多くのローカル用途でこのトレードオフは依然として実用的である。4ビットを下回ると、品質面のコストがはるかに顕著になる。Q4_K_Mは依然としてコミュニティで一般的な既定値であり、メモリに余裕がある場合はQ5_K_MやQ6_Kの方が安全である。
GGUFファイル名のQ4_K_Mとは何を意味するのか

GGUFの量子化名はQ[ビット数]_[K]_[S/M/L]というパターンに従う。数字は 目標となる 重みあたりのビット数を表す。Kは「K-quant」であることを意味し、重みの小さなブロックごとにスケーリング係数を保存する。末尾のS、M、Lはサイズ/品質階層(small、medium、large)を表す。K-quantは重みとともに各ブロックのスケールと最小値を保存するため、 実効的な 実効ビット幅は名前の数字より高くなる。Q4_K_Mは重みあたり約4.89ビットであり、4ではない。
この差こそが、「なぜ自分の4ビットファイルが4.6GBなのか」という疑問への答えのすべてである。単純な見積もりでは、すべての重みがちょうど4ビットで済むと仮定している。実際にはK-quantは、低ビット量子化を正確にするためのメタデータ、つまりランタイムが各重みを再構成できるようにするブロックごとのスケールと最小値に、ブロックあたり追加のビットを費やす。4.89ビットを80億の重みに掛け合わせると、約4.58GiBになり、これがファイルが実際に持つ重さである。
以下は測定された実効ビット幅とファイルサイズであり、 llama.cpp quantize documentation 参照モデルとしてLlama 3.1 8Bを用いて取得されたものである。あわせて、llama.cppの量子化評価論文で測定された各レベルのパープレキシティコストも示す(arXiv:2601.14277)、Llama-3.1-8B-Instructで測定されたものである。
| GGUFレベル | 実効BPW | ~ファイルサイズ(8B) | パープレキシティ対F16* |
|---|---|---|---|
| Q3_K_S | 3.64 | ~3.4 GiB | +22% |
| Q3_K_M | 3.95 | ~3.7 GiB | +8.7% |
| Q3_K_L | 4.30 | ~4.0 GiB | +6.7% |
| Q4_K_S | 4.67 | ~4.4 GiB | +4.1% |
| Q4_K_M | 4.89 | ~4.6 GiB | +3.3% |
| Q5_K_M | 5.70 | ~5.3 GiB | +1.1% |
| Q6_K | 6.56 | ~6.1 GiB | +0.4% |
| Q8_0 | 8.50 | ~8.0 GiB | +0.1% |
| F16 | 16.00 | ~15.0 GiB | ベースライン |
*このパープレキシティの数値はarXiv:2601.14277によるLlama-3.1-8B-Instruct固有のものである。BPW/ファイルサイズの列とパープレキシティの列は、別々に測定された2つの異なる出典に基づいているため、この表は単一のベンチマーク実行結果としてではなく、実用的な並列参照として読むべきである。タスクごとの劣化度合いは異なり、低ビット幅では数学的推論の方が常識的推論より影響を受けやすい傾向があるが、大まかな傾向は変わらない。5ビット以上は概ね安全であり、Q4は実用的な圧縮ゾーンであり、3ビットは品質低下がはるかに無視しづらくなる領域である。
実用的には、Q4_K_Mがほとんどの人が選ぶべき既定値であり、Q5_K_MとQ6_Kはメモリに余裕がある場合の品質重視の選択肢であり、Q3_K_S以下のものは、それ以上を本当に収められないハードウェアのための最後の手段である。
どの量子化フォーマットをダウンロードすべきか、GGUF、GPTQ、AWQ、それともEXL2か

GGUFは4つの中で最も可搬性が高い。llama.cppを通じてCPU、GPU、あるいは両者のハイブリッド構成で動作するため、自分のハードウェアが何をサポートしているか分からない場合に最も安全な選択となる。GPTQ、AWQ、EXL2はよりGPUおよびランタイム固有だ。実際にはNVIDIA/CUDA環境で最も一般的だが、GPTQとAWQのサポート状況はローダーやサービングスタックによって異なる。例えばvLLMは はハードウェアと実装によって量子化サポートを区別している。Mac、AMDカード、あるいはCPUのみの環境でローカル実行しているなら、GGUFが依然として最も安全な選択肢だ。NVIDIA GPUを持っていて、可能な限り速いトークン生成を求めるなら、残りの3つが選択肢に入ってくる。
| フォーマット | ハードウェア/ランタイム | 速度(相対) | 他フォーマットとのVRAM比較 | 最適 |
|---|---|---|---|---|
| GGUF Q4_K_M | 最も広範、CPU、GPU、またはllama.cpp経由のハイブリッド | 緩和 | 最も低い | あらゆるハードウェア、ローカル利用の既定値 |
| GPTQ 4ビット | 通常はCUDA/GPU優先、ランタイム依存 | 高速(ExLlama) | 中 | GPU優先、レガシーなツール群 |
| AWQ 4ビット | 通常はCUDA/GPU優先、ランタイム依存 | 速い | 最高 | vLLM/TGIサービング、高速ロード |
| EXL2 ~4.9 bpw | NVIDIA/CUDA優先 | 最速 | 低-中 | NVIDIA上での最高速度 |
この表に関する注意点として、速度とVRAMの順位は oobabookaベンチマークから来ている。これは2023/2024年ごろのハードウェアで実行されたものだ。 相対的な この相対的な順序は今も有効なものとして扱うべきだが、当初の絶対的な1秒あたりトークン数の数値を現在のものとして読むべきではない。EXL2は速度重視で作られており、AWQはVRAMを犠牲にして高速ロードを実現し、GGUFは軽量かつ可搬性を維持している。2026年のGPUはまったく異なる生のスループットを示すだろう。引き継がれるのは序列そのものである。
そこから導かれる判断基準はこうだ。NVIDIAカードを持っていて速度を最も重視するならEXL2。異なるハードウェア間で最も安全なローカル既定値を求めるならGGUF。AWQとGPTQは、特定のサービングスタック(vLLM、TGI)や既存のツール群がそちらへ導く場合に主に意味を持つ。
なぜローカルLLMはそのファイルよりも多くのメモリを使うのか
ファイルサイズはモデルの重みだけを表す。実行時には、KVキャッシュ(コンテキストウィンドウ内のすべてのトークンに対するアテンション状態)、アクティベーション(順伝播の中間計算)、そしてフレームワークとドライバーのオーバーヘッドにもコストがかかる。これら重み以外の部分は、シングルユーザー構成であれば通常、重みに対して10〜20%を上乗せするが、KVキャッシュだけでもコンテキストが長くなれば他のすべてを圧倒しかねない。4.6GBのファイルが動作するには、4.6GBをはるかに超えるメモリが必要になることがある。
ランタイムメモリは、互いに積み重なった4つの構成要素として考えるとよい。
- モデルの重み。 ダウンロードしたファイルそのもの。ロード前に見えるのはこの部分だけである。
- KVキャッシュ。 コンテキストウィンドウに対するアテンション状態。短いコンテキストでは小さいが、長いコンテキストでは巨大になる。これが次のセクションのテーマである。人々を驚かせる部分だからだ。
- アクティベーション。 順伝播のためのワーキングメモリ。シングルストリームのローカル推論(バッチサイズ1)では小さく、典型的には数百メガバイト程度である。
- フレームワークのオーバーヘッド。 ランタイム自体のフットプリントに加え、GPUドライバーのコンテキストも含まれる。軽量なローカルランタイムであれば、モデルの重みやKVキャッシュに比べて小さく済むことがあるが、より重いサービングフレームワークははるかに多くを確保することがある。オペレーティングシステム自体のメモリ予約はこれとは別枠であり、さらに独立している。
重みとフレームワークのオーバーヘッドは予測可能である。KVキャッシュこそが、「収まる」はずのモデルをクラッシュさせるモデルに変える変数であり、だからこそ実際の計算をきちんと追う価値がある。
KVキャッシュはどれだけのメモリを使うのか
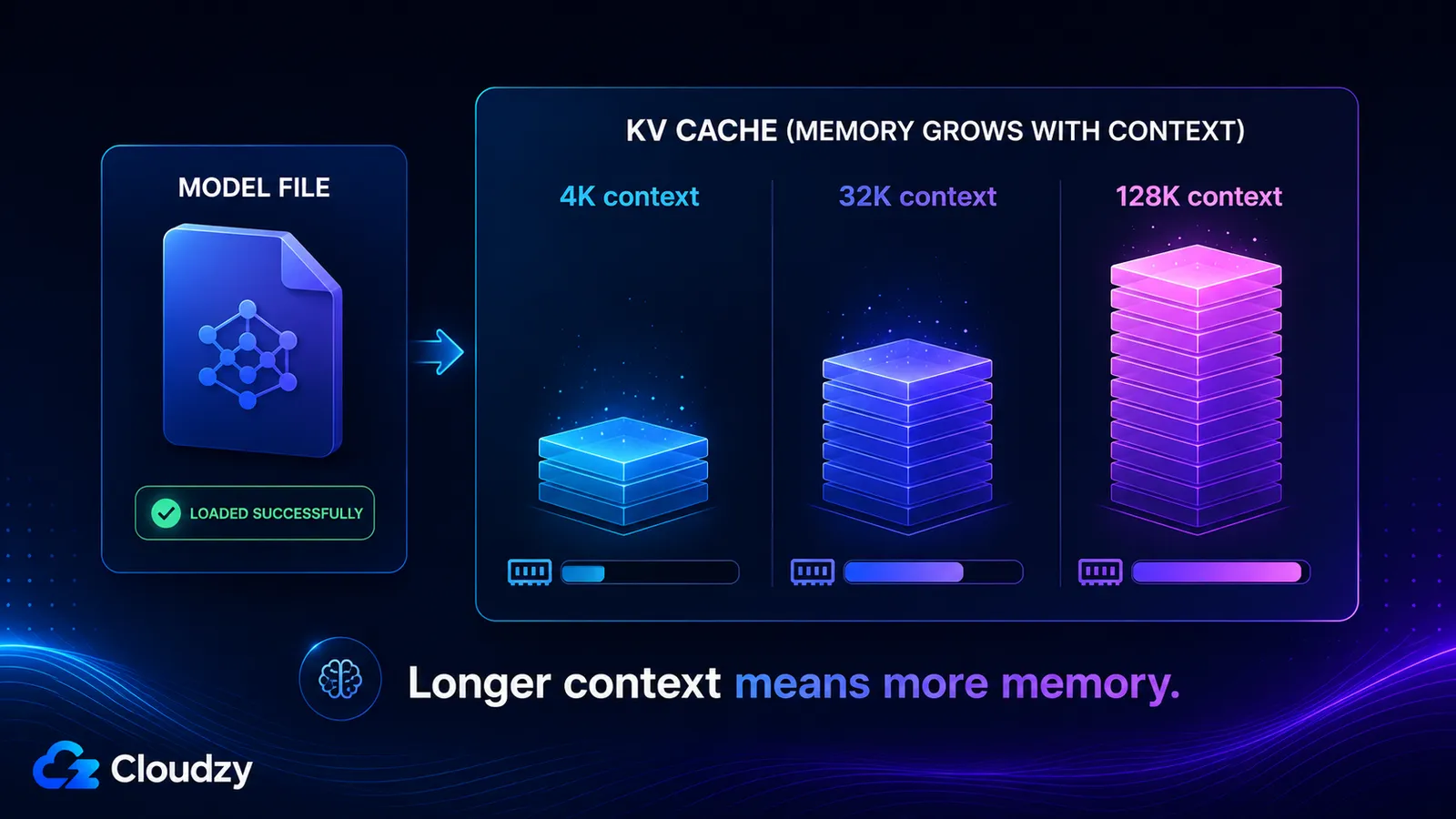
KVキャッシュはコンテキストウィンドウ内のすべてのトークンについてキーとバリューのベクトルを保存するため、コンテキスト長にほぼ比例して増大し、モデルの重みとは完全に切り離されている。そのサイズは、モデルのレイヤー数、KVヘッド数、ヘッド次元、コンテキスト長、そしてキャッシュの精度によって決まる。長いコンテキストを有効にすると、問題なくロードされたはずのモデルが一度も警告しなかった数十ギガバイトが追加されることがある。
この公式は頭の中に入れておけるほど短い。
KV cache bytes = 2 × layers × kv_heads × head_dim × context_tokens × bytes_per_element
先頭の2は、トークンごとに保存される2つのテンソル、キー用とバリュー用を表す。bytes_per_elementはFP16キャッシュの場合2である。残りはモデルカードから読み取れるアーキテクチャ定数だ。
Llama 3.1 8Bで計算してみよう。このモデルは32レイヤー、8個のKVヘッド、ヘッド次元128を持つ。4,096トークンのコンテキスト、バッチサイズ1、FP16キャッシュの場合。
2 × 32 × 8 × 128 × 4096 × 2 bytes ≈ 536 MB
コンテキストを拡大すればこの数値もそれに応じて拡大する。context_tokens以外のすべての項が固定だからだ。
- 4Kコンテキスト: ~536 MB
- 32Kコンテキスト: ~4.3 GB
- 128Kコンテキスト: ~17 GB
この最後の2つの数値こそ、あるモデルが128Kのコンテキストウィンドウを謳い、問題なくロードされたのに、実際にそのウィンドウを使い始めた瞬間にメモリを使い果たしてしまう理由である。フルコンテキストにおけるKVキャッシュは、量子化された重み自体よりも大きくなる。
ここが、現代の長文脈対応モデルをそもそも可能にしている部分だ。Llama 3.1 8Bは Grouped Query Attention(GQA)を採用している。クエリヘッドは32個あるが、KVヘッドはわずか8個しかない。つまりキャッシュは32個ではなく8個のヘッド分のキー/バリューベクトルを保存する。同じ公式をKVヘッド32個(KVヘッドとクエリヘッドの数が等しい、より古いMulti-Head Attention設計)で計算すると、上記の数値はすべて4倍になる。128Kの時の17GBは68GBになる。GQAこそが、コンテキストウィンドウが拡大しても計算が破綻せずに済んでいるアーキテクチャ上の理由である。
ファイルサイズはあなたのメモリ予算ではない。重みやKVキャッシュが高速なメモリ経路に収まらなくなり、ランタイムがPCIe経由でシステムRAMにフォールバックせざるを得なくなると、スループットはなだらかには低下しない。トークンごとにPCIe経由でデータを移動させるようになった瞬間、崖から落ちるように急落する。重みだけでなく、実際に使うコンテキスト長でのKVキャッシュも含めて両方が収まるようにメモリを予算立てすべきだ。
自分のGPUやMacに合った量子化をどう選ぶか
まずは自分のハードウェアとランタイムから考える。NVIDIA GPUの所有者は最も選択肢が広く、生の速度を重視するならEXL2、可搬性を重視するならGGUFを検討すべきだ。AMD、Apple Silicon、CPUのみのハードウェア、あるいは混在構成の場合は、llama.cpp経由のGGUFが通常最も安全な出発点となる。そこから先は、実際に使うコンテキスト長(モデルの最大値ではなく)でのKVキャッシュ分の予算を確保した上で、収まる範囲で最も高い量子化レベルを選ぶとよい。
知っておく価値のあるApple Siliconの落とし穴が一つある。GPUはあなたのユニファイドメモリのすべてを取得できるわけではない(この共有プールの仕組みの全体像については、 「ユニファイドメモリとは実際何か」 という関連記事を参照してほしい)。セルフホスティングのコミュニティは GPUが利用できるユニファイドメモリ全体のおよそ75%という上限を 文書化している(これはAppleによって公式に確認されているわけではなく、macOSのアップデートで変わる可能性がある)。つまり「64GBのMac」は、モデルとそのKVキャッシュ用として現実的には約48GBであり、この小さい方の数字を基準に計画すべきだ。
この記事は、フォーマットを読み解き、そのランタイムの挙動を予測することがテーマである。量子化名を解読し、自分のハードウェアがサポートするフォーマットを選び、KVキャッシュを重みとは別に予算立てすることだ。特定のモデルを特定のメモリ量に対応付けること、つまりサイズとメモリの対応表については、関連はするが別の話題であり、今後の姉妹記事で扱う予定である。
リポジトリを読む
これでもう、モデルのページを推測ではなく実際に読み解けるようになったはずだ。量子化名を実効ビット幅に解読し、GGUFが最も広範なローカルフォーマットであり、GPTQ、AWQ、EXL2はよりランタイム固有であることを理解し、ファイルサイズはあくまで最低ラインであり、その上にKVキャッシュが積み重なりコンテキストとともに増大することを忘れないでほしい。欲しいモデルのファイルを開き、自分のハードウェアで動かせるフォーマットを選び、実際のコンテキスト長でのKVキャッシュ分の余裕を残した上で収まる最も高い量子化レベルを選べば、この一連の疑問の出発点となったメモリ不足によるクラッシュを避けられるはずだ。
よくある質問
Q4_K_Mとは何を意味するのか
Q4_K_Mは一つのGGUF量子化レベルである。重みあたりおよそ4ビット(Q4)、K-quantによるブロック単位のスケーリング(K)を用い、中程度のサイズ/品質階層(M)に位置する。その 実効的な 実効ビット幅は重みあたり約4.89ビットであり、ちょうど4ではない。これはK-quantが重みの各ブロックについてスケールと最小値を保存するためである。だからこそ、「4ビット」の8Bモデルファイルは3.5GBではなく約4.6GBになるのだ。
量子化はLLMの品質を低下させるのか
はい、ただしそのコストは、どこまで追い込むかによって大きく変わる。arXiv:2601.14277で測定されたLlama-3.1-8B-Instructでは、Q6_Kでのパープレキシティ上昇はわずか約0.4%であり、Q5帯を通じても1%近くにとどまる。Q4まで下げても上昇はまだ控えめ(数パーセント程度)だが、Q3_K_Mを下回ると急激に上昇し、Q3_K_Sでは+22%に達する。ほとんどの用途では、Q4_K_M以上は事実上ロスレスであり、急激な劣化は3ビット以下の領域に存在する。
GGUF、GPTQ、AWQ、EXL2の違いは何か
GGUF(llama.cppで実行される)は可搬性のあるフォーマットであり、CPU、GPU、あるいは幅広いハードウェアにまたがるハイブリッド構成で動作する。GPTQ、AWQ、EXL2はよりGPUおよびランタイム固有だ。4ビットでは、この4つすべてが狭い品質帯に収まることが多いため、実際的な違いはハードウェア、ローダーのサポート状況、速度、VRAM使用量にある。EXL2は速度重視のNVIDIA/CUDA向けの選択肢であり、AWQはサービングスタックでよく使われ、GPTQは古めのGPUツール群やモデルリポジトリに適しており、GGUFは最も可搬性の高いローカル選択肢であり続ける。
なぜ自分のローカルLLMはファイルよりも多くのメモリを使うのか
ファイルサイズはモデルの重みだけを表す。実行時には、KVキャッシュ(コンテキストウィンドウ内のすべてのトークンに対するアテンション状態)、アクティベーション、そしてフレームワークとドライバーのオーバーヘッドにもコストがかかる。ギャップが大きい場合、通常の原因はKVキャッシュにある。コンテキスト長とともに増大し、重みとは別に確保されるため、ファイルが数ギガバイト程度のモデルでも、長いコンテキストを設定した途端にはるかに多くのメモリを必要とすることがある。
コンテキスト長はメモリ使用量にどう影響するか
KVキャッシュはコンテキスト長にほぼ比例して増大するため、コンテキストを2倍にすると、キャッシュもおおよそ2倍になる。Llama 3.1 8Bの場合、キャッシュは4Kトークンで約536MB、32Kで約4.3GB、128Kで約17GB(FP16、シングルストリーム)である。この増大はモデルの重みとは完全に独立しているため、長いコンテキストウィンドウを宣言することで、問題なくロードされたはずのモデルがメモリ不足に陥ることがある。


