
テスト環境では40回クリーンに動作したループが、本番の41回目の実行で同じ壊れたクエリを使って同一の SQL ツールを延々と呼び続け、その日の API 予算を使い果たした。請求アラートが鳴って、ようやく誰かが気づいた。モデルに問題があったわけでも、プロンプトが変わったわけでもない。エージェントが単に「完了」と判断しなかっただけだ。
エージェントをプロトタイプから24時間365日のワークロードへ移行したチームで、繰り返し見られるパターンがこれだ。AI エージェントループが本番で失敗するのは、モデルが急に劣化したからではなく、実行レイヤーに終了規律、検証済みのツールコントラクト、コンテキストの上限管理、そして耐久性のある状態管理が欠けているからだ。エージェントループは確率的なシステムであり、順番に一つひとつ意思決定を行っている。特定のガードレールがなければ、稀な障害は、十分に長く動かし続ければ必ず起きるものになる。マネージドエージェントプラットフォーム(Vertex AI Agent Builder、Bedrock Agents、Azure AI Foundry)にはこうしたガードレールが一部組み込まれているが、このガイドは自己ホストを選びループを自分で管理している開発者向けだ。
リスクは現実のものだ。Gartner は アジェンティック AI プロジェクトの40%以上が2027年末までにキャンセルされると予測しているとし、コスト増大と価値の不明確さを原因として挙げている。以下では、ループが本番で壊れる6つの具体的なパターン、それぞれのメカニズム、そして修正するためのハーネスパターンを、LangGraph と n8n の詳細も含めて解説する。24時間365日で実際に運用するために必要なことも説明する。
短いバージョン
- 無限ループ: エージェントが完了を判断しない。ハードなステップ上限(LangGraph の
recursion_limit、デフォルト25)と、同一のツール+引数の呼び出し繰り返しを検出して終了させる「進行なし検出」を組み合わせて使う。 - コンテキストオーバーフロー: ループが蓄積した履歴でコンテキストウィンドウを埋め尽くし、呼び出しが切り捨てられたり失敗したりする。固定間隔で履歴を要約し、作業コンテキストを有界に保つ。
- サイレントツール失敗: ツールが空文字列を返し、モデルがそれを有効な「何もしない」操作と解釈し、エージェントが何もせずに「成功」する。モデルがツールの結果を受け取る前にすべて検証する。
- 推論劣化: ハードリミット以下でもコンテキストが増えると品質が低下する。ループの途中で圧縮するが、その際に固定された安全指示は必ず保護する。
- 再起動時の状態喪失: クラッシュするとゼロから再開することになる。本番では SQLite ではなく Postgres(LangGraph
PostgresSaver)にチェックポイントを保存する。 - リトライストーム: 10のエージェントがそれぞれ10回リトライすると、障害中のサービスに100リクエストが飛ぶ。指数バックオフとジッターに加え、グローバルサーキットブレーカーを追加する。
このガイドが扱わないこと
これはハーネスガイドであり、ループの内側にあるモデルではなく、ループを取り巻くエンジニアリングに焦点を当てている。以下のトピックは意図的に対象外としている:
- マルチエージェント連携の障害 (エージェント間の古い読み取りや孤立した状態):別の問題であり、それ自体の解説が必要だ。
- エージェントセキュリティ (プロンプトインジェクション、ツールポイズニング):独自の脅威モデルを持つ別の障害カテゴリだ。
- モデルの選択とファインチューニング。 このガイドでは、すでにモデルを選択済みで、その周辺のシステムをデバッグしていることを前提としている。
- マネージドエージェントサービス、上記で触れたとおり。ここで紹介するパターンは自己ホストのパスを対象としている。
無限ループ:エージェントが完了を判断しないとき

エージェントがハードなステップ上限も進行の停止を検出する手段も持たない場合、永遠にループし続ける。修正策は2つに分かれる。ハードな上限をコストのセーフティネットとして維持しつつ、各ツール呼び出しと引数をハッシュ化して同一の呼び出しが繰り返された際に終了させる「進行なし検出」を追加することだ。LangGraph では、この上限が recursion_limitであり、デフォルトは25ステップだ。これを超えるとグラフが GraphRecursionError.
を発生させる。 LangGraph のドキュメント 後(after) では、この上限を「停止条件に達する前の最大ステップ数」と説明しており、理解しておくべき落とし穴がある。recursion_limit はループ保護ではない。25ステップ分の無駄遣いと対応する API コストが発生してから初めて作動するセーフティネットだ。エージェント自身の学習済み終了ロジックが本来これより早く停止させるべきであり、そのロジックは独立して失敗する可能性がある。ある LangGraph の報告事例 では、text-to-SQL エージェントが、プロンプトに明確な停止条件があるにもかかわらず、recursion_limit に達するまでループし続けた事例がある。同じ失敗した SQL で同一のクエリツールを呼び続け、その issue は「計画外」としてクローズされた。私はこれを明確なシグナルと読んでいる:上限を停止条件として扱ってはいけない。それはシートベルトであって、ブレーキではない。
上限を引き上げるのは簡単で、グラフを呼び出す際に config を通じて渡す:
# The hard ceiling -- a backstop, not loop protection
graph.invoke(
{"messages": [("user", "Generate the quarterly report")]},
{"recursion_limit": 50},
)実際にスタックしたループを停止させるのは、進行なし検出だ。仕組みはシンプルで、各ステップでツール名と引数をハッシュ化し、最近のハッシュの短いウィンドウを保持して、重複が見つかった時点で終了させる。
import hashlib
def step_signature(tool_name: str, tool_args: dict) -> str:
payload = f"{tool_name}:{sorted(tool_args.items())}"
return hashlib.sha256(payload.encode()).hexdigest()
# Inside your loop: terminate if the same tool+args repeats within the window
seen = recent_signatures[-WINDOW:]
sig = step_signature(tool_name, tool_args)
if sig in seen:
raise StopReason("no_progress: repeated tool call detected")
recent_signatures.append(sig)これにより、技術的には「動いている」(ツールを呼び出し、トークンを生成している)が、同じ失敗した操作を繰り返しているエージェントを検出できる。この障害モードは、MAST タキソノミー(IBM Research および UC Berkeley)が 終了条件の未認識 (FM-1.5)と呼ぶもので、タスク完全失敗と関連付けられている障害モードの一つだ。
ステップ上限は暴走コストを防ぐ。進行なし検出は、技術的には「進行している」が繰り返しているループを停止させる。本番ではその両方が必要だ。
コンテキストウィンドウオーバーフロー:ループが自身のコンテキストをゴミで埋め尽くすとき
長時間動作するループは、すべてのツール出力、中間的な思考、生成したメッセージを蓄積し、各ターンにそのすべてをコンテキストウィンドウに詰め込む。最終的にウィンドウが埋まり、呼び出しはサイレントに切り捨てられるか完全に失敗する。修正策は、固定間隔でのコンテキスト要約だ。N ステップごとに蓄積された履歴を要約にまとめ、作業コンテキストを有界に保つ。
1時間稼働中のリサーチエージェントを想像してほしい。ステップ60の時点で、取得したすべてのページの全文、すべての検索結果、すべての推論トレースを抱えている。その生の履歴はステップ61には何の役にも立たないが、ウィンドウを食い続け、モデルはもはや必要のないトークンに注意バジェットを使い続ける。ウィンドウが埋まると、プロバイダーは一方の端から切り捨て、エージェントは最初に与えられた指示を静かに失う。
トリガーはチューニングの判断であり、有用な参照点がある。Mem0 が実際の本番システムの解説で述べているように、 Hermes エージェントのコンプレッサーは「デフォルトでモデルのコンテキストウィンドウの50%の時点で起動する」とあり、ターン間で膨らむセッション向けに85%の二次セーフティネットも設けられている。50%は合理的な出発点だ。単一の大きなツール出力が次の圧縮前に上限を突破できないよう、十分に早く圧縮する。
注意: Overflow と推論の劣化は別々の問題であり、次のセクションでは後者を取り上げます。Overflow は明確な上限であり、tokens が尽きる状態です。劣化は緩やかなもので、モデルのパフォーマンスが徐々に低下していきます。 前に モデルが悪化する。両方に対処する必要があり、上記のトリガー閾値はハードな壁を防ぐ。
コンテキストの有界管理はハーネスの責務であり、モデルの機能ではない。サイレントな切り捨てをウィンドウに強制される前に、間隔を決めて要約する。
サイレントツール呼び出し失敗:エージェントが「何もせずに成功」するとき
ツール呼び出しが空文字列またはソフトな「結果なし」メッセージを返し、モデルがそれを有効な結果と解釈し、エージェントはそのステップが成功したかのように処理を続ける。実際には何もしていない。修正策は、すべてのツールの返り値に検証ゲートを設けることだ。モデルが受け取る前に、スキーマチェックまたはサニティチェックを行い、空の「成功」ではなく、ループが処理しなければならない本物の失敗を表面化させる。
これは厄介だ。何もクラッシュしないからだ。本番エージェントにおける 本番エージェントにおけるサイレント障害モード が直接指摘しているように、モデルは汎用的な空文字列を有効な「何もしない」操作と解釈し、障害を認識しないまま実行を続ける。接続が切れてゼロ行を返したデータベースクエリは、正当に何も見つからなかったクエリと、モデルには見分けがつかない。そのため、エージェントは「一致するレコードなし」と報告して処理を進め、実行の3分の1が静かに壊れていたことに一週間後に気づく。
検証ゲートはツールとモデルの間に置く:
def gate_tool_result(tool_name: str, result):
# Reject empties and soft errors before the model can rationalize them
if result is None or (isinstance(result, str) and not result.strip()):
raise ToolFailure(f"{tool_name} returned empty -- treat as failure, not no-op")
if isinstance(result, str) and result.lower().startswith(("error", "exception")):
raise ToolFailure(f"{tool_name} returned a soft error: {result[:120]}")
return result # validated -- safe to hand back to the model重要なのは具体的なチェックの内容ではなく、それはツールが正当に返すものによって異なる。重要なのは、検証されていない返り値は確率的なモデルに判断を委ねたということであり、モデルのデフォルトの動作は処理を続けることだ。
検証されていないツールの返り値は、サイレント障害の予備軍だ。呼び出しを信頼せず、出力を検証する。
長いコンテキストにおける推論劣化:エージェントが動けば動くほど悪化するとき
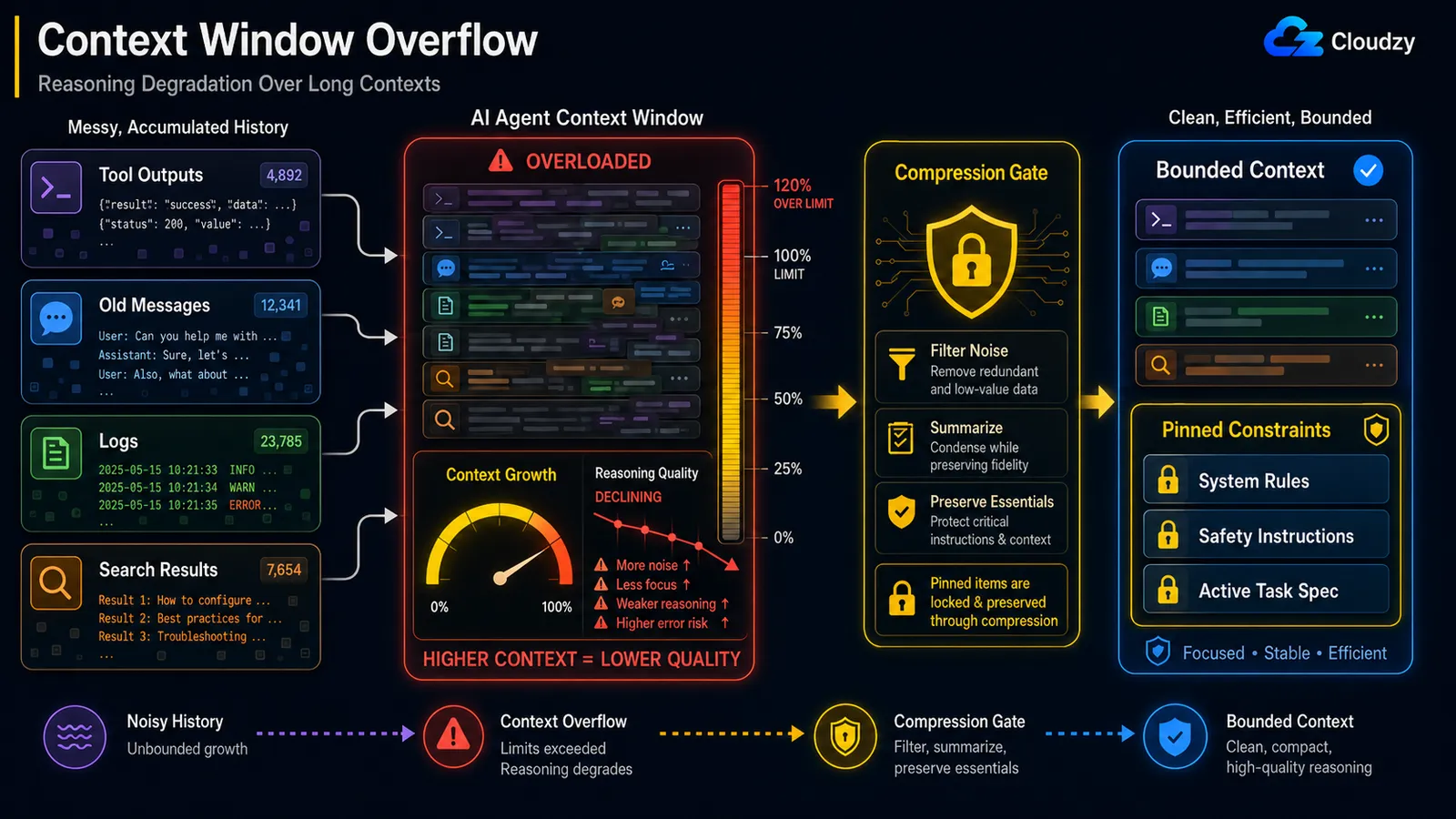
ハードなコンテキスト上限の手前でも、コンテキストが大きくなるにつれて推論品質は低下する。これが「lost in the middle」効果であり、モデルは長いコンテキストの最初と最後には確実に注目するが、中間を見落とす。修正策は、固定された制約を保護しながらループ途中で圧縮することだ。ノイズを圧縮し、重要な指示を守る。
このメカニズムには名前がある。Anthropic のエンジニアリングブログでは 「context rot」: と呼ばれており、「コンテキストウィンドウ内のトークン数が増えると、モデルがそのコンテキストから情報を正確に思い出す能力が低下する」とされている。 なぜなら、 「すべてのトークンが他のすべてのトークンに注目するため」 n個のトークンに対して n² のペアワイズ関係が生じ、コンテキストが長くなるほどモデルの注意は薄く引き伸ばされる。
この条件こそが、 「重要な指示を保護する」という条件が全てを決める。それを示すドキュメント化された事例がある。ある 報告されたケースでは、OpenClaw エージェントがコンテキスト圧縮中にユーザーの受信トレイを大量削除した。与えられていた安全指示(「指示があるまで操作しないこと」)が、履歴の圧縮時にアクティブなコンテキストから削除されたためだ。最後まで残るべきだった制約が、通常の履歴として扱われ、要約されてしまった。
そのため、「N ターンより古いものをすべて要約する」という素朴なアプローチは危険だ。圧縮では、絶対に削除してはいけないものを明確にする必要がある:
PINNED = {"system_constraints", "safety_instructions", "active_task_spec"}
def compress_history(messages):
pinned = [m for m in messages if m.tag in PINNED] # never summarized
transient = [m for m in messages if m.tag not in PINNED]
summary = summarize(transient) # lossy is fine here
return pinned + [summary] # constraints survive intactこれは前のセクションのオーバーフロー問題とは異なる。オーバーフローはスペースがなくなること、劣化はスペースが残っている状態でモデルが悪化することだ。ウィンドウの60%の状態でも、すでに推論が崩れている可能性がある。
注意: 古い検索結果を失う圧縮よりも、安全制約を失う圧縮の方がはるかに深刻なバグだ。制約、タスク仕様、そして「X をしてはいけない」という指示には固定タグを付け、要約器から完全に除外する。
安全指示を削除する圧縮は、圧縮しないよりも悪い。圧縮する際は固定された制約を必ず保護する。
再起動時の状態喪失:クラッシュがゼロからのやり直しを意味するとき
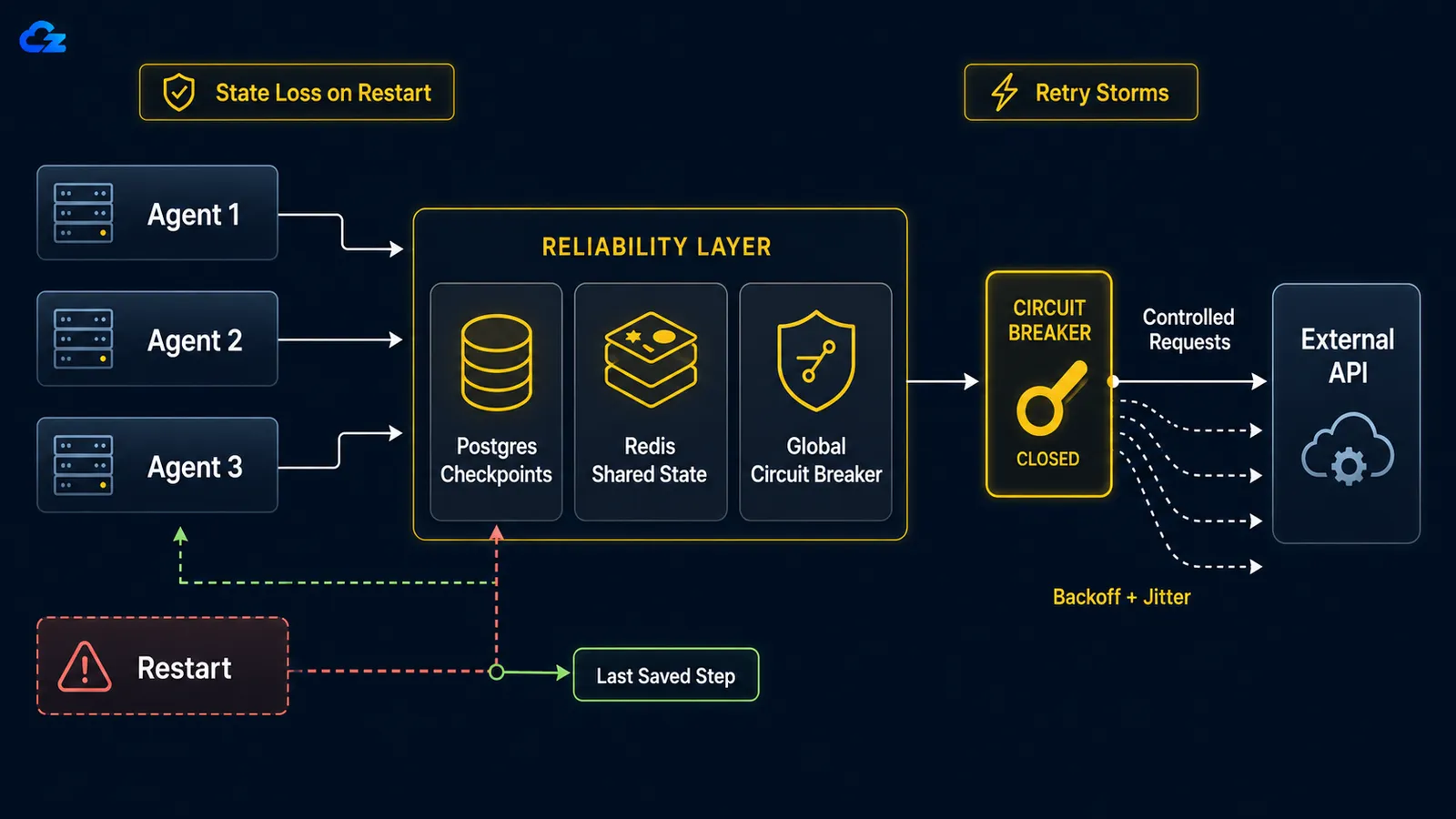
長時間動作するエージェントが、再起動、OOM キル、またはネットワーク接続切断のいずれかでクラッシュした場合、デフォルトではチェックポイントからの再開機能はない。ループはゼロから再スタートし、完了済みの作業をやり直すだけでなく、最悪の場合、既に実行した操作(同じメールを2回送信したり、有料の API 呼び出しを再実行したり)を繰り返す。修正策はチェックポイントだ。各ステップ後にループの状態を永続化し、再起動時にゼロからではなく停止した場所からリハイドレートできるようにする。
LangGraph では、チェックポイントバックエンドの選択が開発と本番の分岐点となる。 LangGraph のパーシステンスドキュメント では SqliteSaver は「実験やローカルワークフローに理想的」、 PostgresSaver は「本番での使用に理想的」と説明されており、LangSmith 自体も後者で動いている。コードでは両者が意図的に並行して記述されており、違いが一目でわかる:
# Development -- single file, no server, do not ship this
from langgraph.checkpoint.sqlite import SqliteSaver
# Production -- survives the box it runs on
from langgraph.checkpoint.postgres import PostgresSaverよく引っかかる2つのポイントがある。まず、チェックポイントパッケージは LangGraph のコアとは別途インストールする必要がある(langgraph-checkpoint-sqlite と langgraph-checkpoint-postgres は独自の依存関係)。そのため、新しい環境には Postgres セーバーが含まれておらず、インシデント発生時に初めて気づくことになる。次に、すべてのチェックポイント操作には config 内に thread_id が必要だ。この ID が特定の実行と保存済み状態を紐付け、正しい thread_id なしで再起動するとリハイドレートされない。
プロのヒント: LangGraph のチェックポイントパッケージは別途インストールが必要だ。
langgraph-checkpoint-postgresは基本的なlanggraphパッケージには含まれていないため、インシデントで痛い目を見る前に、本番の requirements ファイルに固定しておくこと。
n8n にも同様の開発・本番分割があるが、名前が異なる。組み込みのメモリオプションも Simple Memory(または Buffer Window Memory)と呼ばれ、本番では再起動を跨いで状態を保持できる Postgres Chat Memory ノード を使う。組み込みメモリは会話を実行中のプロセスに保持し、テストには問題ないが、24時間365日のワークロードではリスクになる。実際に n8n エージェントを本番運用しているユーザーが、インプロセスメモリが膨れてインスタンスごとダウンさせた経験から Postgres バックエンドに移行したという報告がある。n8n を使っていて再起動を跨いでエージェントが何かを記憶する必要があるなら、最初から Postgres Chat Memory に接続すること。
SQLite チェックポイントは開発時の便宜だ。本番の再起動を生き残るには Postgres(LangGraph)または Postgres バックエンドのストア(n8n)が必要だ。
リトライストーム:自分のエージェントが落ちたサービスに DDoS するとき
ダウンストリームのサービスがダウンすると、単純な実行ごとのリトライがエージェントフリートを自己引き起こしのサービス妨害に変える。修正策は2つに分かれる。各エージェントで指数バックオフとジッターを使ってリトライを時間的に分散させること、そして失敗閾値を超えた後にトリップして、明らかにダウンしているサービスへのフリート全体の殺到を止めるグローバルサーキットブレーカーだ。
数字は容赦ない。ある リトライパターンの解説 が述べているように、10の並列エージェントがそれぞれ10回リトライすると、すでにダウンしているサービスに100リクエストが送られる。各エージェントのバックオフは実行ごとであって、グローバルではないからだ。エージェントごとのバックオフだけでは解決しない。それぞれが丁寧にバックオフする10のエージェントでも、全員が同時にスタートすれば同期してリトライする。ジッターはランダムに待機時間を変えることで同期を壊し、サーキットブレーカーは1つの障害状態を全エージェントで共有することでフリートを制御する。
バックオフの半分は Python では解決済みの問題で、 tenacity ライブラリが指数+ジッターをクリーンに処理する:
from tenacity import retry, stop_after_attempt, wait_random_exponential
@retry(wait=wait_random_exponential(multiplier=1, max=60), stop=stop_after_attempt(5))
def call_flaky_service(payload):
return downstream.post(payload)サーキットブレーカーは グローバルである必要がある。各エージェントに独立して持たせるのではなく、すべてのエージェントで共有する。障害が閾値を超えるとオープンになり、各エージェントは呼び出しではなくフェイルファストし、クールダウン後にサービスが復旧しているかテストするため1件だけプローブを通す。各エージェントのプロセス内に存在するブレーカーは何も守らない。共有されるものがないため、落ちたサービスはそれでも100件全部のリクエストを受け取る。
実行ごとのバックオフでは、10のエージェントが一斉に落ちたサービスを叩き続ける。サーキットブレーカーはフリートを止めるためにグローバルでなければならない。
6つの障害の概要
インフラの話をする前に、全カタログを一か所でまとめて見てほしい。障害、それを引き起こすメカニズム、ハーネスの修正策、そして各フレームワークで関連するパラメーターの場所だ。
| 障害モード | メカニズム | ハーネスの修正策 | フレームワークパラメーター |
|---|---|---|---|
| 無限ループ | ステップ上限も進行チェックもない | ハードな上限+進行なし検出 | LangGraph recursion_limit (25)/ n8n Max Iterations |
| コンテキストオーバーフロー | ウィンドウが埋まるまで履歴が増加する | 間隔ベースの要約 | アプリレベル(ウィンドウの〜50%で圧縮) |
| サイレントツール失敗 | 空またはソフトな返り値が有効な「何もしない」として読まれる | すべてのツール結果に検証ゲートを設ける | アプリレベルのツールラッパー |
| 推論劣化 | コンテキストが増えると注意が薄れる(「context rot」) | 固定された制約を保護しながらループ途中で圧縮する | アプリレベル、制約対応 |
| 再起動時の状態喪失 | チェックポイントなし、ループがゼロから再起動 | 永続チェックポイント | LangGraph PostgresSaver / n8n Postgres Chat Memory |
| リトライストーム | 実行ごとのリトライが落ちたサービスにカスケードする | バックオフ+ジッター+グローバルサーキットブレーカー | tenacity +共有ブレーカー状態 |
CrewAI、AutoGen、Dify、または手書きの Python ループを使っている読者へ:フレームワーク固有のパラメーターは変わるが、6つのパターンは変わらない。重複排除、間隔要約、スキーマ検証、制約対応の圧縮、チェックポイント、グローバルサーキットブレーカーはフレームワーク非依存の概念だ。ここで示した LangGraph と n8n の詳細は具体的な出発点であって、パターンが適用される範囲の境界ではない。
本番エージェントデプロイのサイジング
上記のパターンはすべて、プロセスマネージャー、データベース、および再起動動作を自分で管理していることを前提としている。クラッシュしたループが再起動しなければ、チェックポイントは意味をなさない。グローバルサーキットブレーカーは共有状態を保持する場所が必要だ。その制御こそが自己ホストがもたらすものであり、マネージドのブラックボックスには与えてくれないものだ。最後の決定は、これを24時間365日動かすサーバーのサイジングになる。
ほとんどのシングルエージェントデプロイ(1エージェント、外部 API への LLM 呼び出し、基本的な Postgres チェックポイント)には小さなインスタンスで十分だ: 2 GB RAM, 1 vCPU, and 60 GB of NVMe storage程度。重い計算はモデルプロバイダー側で行われ、自分のサーバーはオーケストレーション、チェックポイント、状態保持を担い、推論は行わない。Postgres チェックポイントと Redis によるセッションリハイドレーションを伴うステートフルかつマルチステップなエージェントを動かす場合、またはホストを共有する並行ワークフローを実行する場合は、約 4 GB RAM, 2 vCPU, and 120 GB NVMe にステップアップする。
自己管理の VPS を選ぶ理由は、修正策がそもそも機能する理由と同じだ。root が必要だからだ。チェックポイント用の自前の Postgres、セッション状態用の自前の Redis、そして systemd or pm2のような本物のプロセスマネージャー。これによりループがダウンしたとき、スーパーバイザーが再起動させ、ゼロからやり直しではなく最後のチェックポイントからリハイドレートできる。その回復ストーリー全体が、プロセスのライフサイクルを所有することに依存している。
自社のマーケットプレイスで n8n をワンクリックアプリとして提供しているため、そのセットアップが私たちにとっては最短経路だ。本番パスが必要とする Postgres バックエンド設定で Cloudzy VPS 上に n8n をデプロイ でき、自前の Redis とプロセスマネージャーを追加するための root アクセスも持てる。上で説明した自己ホスト型のフットプリントと同じで、データベースと再起動動作を所有し、チェックポイントと自動回復が実際に機能する環境だ。
ハーネスパターンの信頼性は、それが動くサーバーの信頼性に左右される。プロセスが再起動しなければ、チェックポイントは意味をなさない。
よくある質問
LangGraph エージェントが永遠にループするのを止めるには?
2つのメカニズムを組み合わせて使う。 recursion_limit をハードなステップ上限として設定し(デフォルトは25)、暴走したループが無制限にコストを使わないようにする。さらに、各ツール呼び出しと引数をハッシュ化して、同じ呼び出しが最近のウィンドウ内で繰り返されたら終了させる進行なし検出を追加する。上限だけでは無駄が発生してから作動するセーフティネットにすぎず、本当のループ保護ではない。進行なし検出こそが、スタックしたループを実際に止めるものだ。
LangGraph の本番での recursion_limit に正解はあるか?
普遍的な数値はない。エージェントが正当に必要とする最大ステップ数にマージンを加えた値に設定し、コストのセーフティネットとして厳密に扱うこと。上限を引き上げても、ループしているエージェントは収束しない。エージェントが高い上限に達しているなら、修正策は上限を上げることではなく進行なし検出だ。
n8n の AI エージェントが Max Iterations に繰り返し達するのはなぜか?
Max Iterations の上限に達するということは、エージェントが収束していないことを意味する。上限以内のステップで停止できずにいる。タスクが正当により多くのステップを必要とするなら上限を引き上げる。そうでなければ、エージェントがスタックしているシグナルとして扱う。特定の落とし穴に注意が必要だ: GitHub issue #22771 によると、「エラー時:続行」が設定されている状態でイテレーション上限に達した場合、実行が Error 出力ではなく Success 出力にルーティングされる可能性があり、上限に達して失敗した実行がワークフロー上では成功に見えることがある。
再起動を跨いでエージェントの状態を永続化するには?
LangGraph では、ローカル開発向けの PostgresSaver ではなく SqliteSaverチェックポイントを使う。n8n では、インプロセスの組み込みメモリではなく Postgres Chat Memory ノードを使う。どちらも永続データベースが必要で、LangGraph ではすべてのチェックポイント操作に thread_id が必要だ。これが特定の実行と保存済み状態を紐付ける。
長いエージェント実行で推論劣化が起きる原因は?
ハードなトークン上限に達する前でも、コンテキストが大きくなると推論品質が低下する。これが「lost in the middle」効果であり、モデルは長いコンテキストの最初と最後には注目するが、中間を見落とす。Anthropic のエンジニアリングブログでは、根本的なメカニズムを「context rot」と呼んでいる。すべてのトークンが他のすべてのトークンに注目するため n² のペアワイズ関係が生じ、コンテキストが長くなるほどモデルの注意は薄く引き伸ばされる。修正策は、固定された制約と安全指示を保護しながら古い履歴を要約する、ループ途中での圧縮だ。


