
GPU VPS를 선택하는 일은 숫자로 가득한 사양표를 보고 있으면 막막하게 느껴질 수 있습니다. 코어 수는 2,560개에서 21,760개까지 다양한데, 이 차이가 실제로 무엇을 의미할까요?
CUDA 코어는 NVIDIA GPU 내부의 병렬 처리 유닛으로, 수천 개의 연산을 동시에 실행합니다. AI 학습부터 3D 렌더링까지 폭넓게 활용됩니다. 이 가이드에서는 CUDA 코어의 작동 원리, CPU 코어 및 Tensor 코어와의 차이, 그리고 불필요한 비용 없이 내 용도에 맞는 코어 수를 고르는 방법을 설명합니다.
CUDA 코어란 무엇인가요?

CUDA 코어는 NVIDIA GPU 내부에서 명령을 병렬로 실행하는 개별 처리 유닛입니다. CUDA 코어 기술의 본질은 무엇일까요? 같은 작업을 여러 조각으로 나눠 동시에 처리하는 작은 작업자들이라고 생각하면 됩니다.
NVIDIA는 2006년 GPU의 연산 능력을 그래픽 이외의 범용 컴퓨팅에도 활용하기 위해 CUDA(Compute Unified Device Architecture)를 도입했습니다. 공식 CUDA 문서 에서 상세한 기술 내용을 확인할 수 있습니다. 각 유닛은 부동소수점 수에 대한 기본 산술 연산을 수행하며, 반복적인 계산에 최적화되어 있습니다.
최신 세대 NVIDIA GPU는 하나의 칩에 수천 개의 유닛을 탑재합니다. 최신 세대 소비자용 GPU는 21,000개 이상의 코어를 갖추고 있으며, Hopper 아키텍처 기반의 데이터센터용 GPU는 최대 16,896개를 지원합니다. 이 유닛들은 Streaming Multiprocessors(SMs)를 통해 함께 동작합니다.
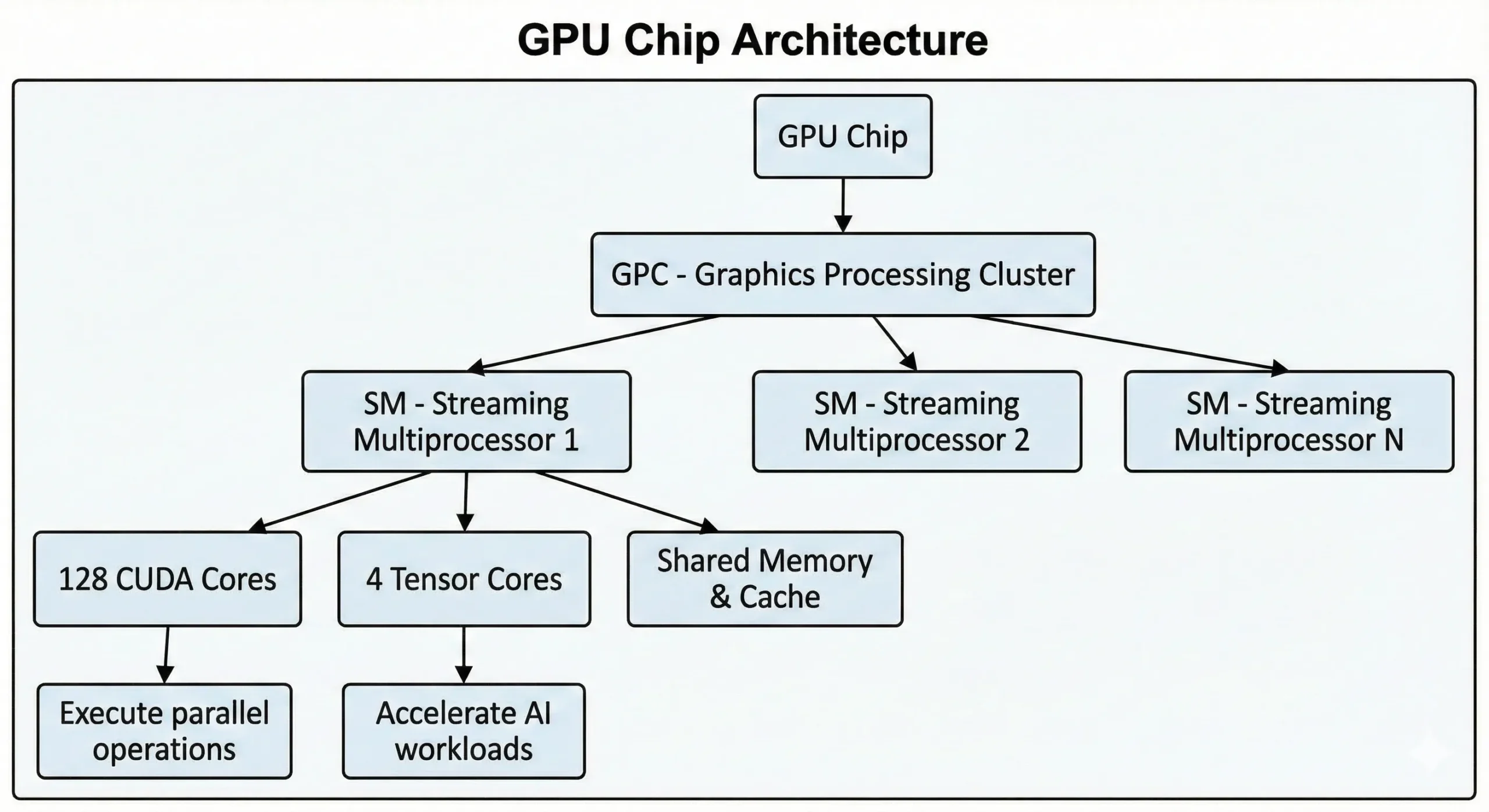
이 유닛들은 병렬 컴퓨팅 방식으로 SIMT(Single Instruction, Multiple Threads) 연산을 실행합니다. 하나의 명령이 여러 데이터 포인트에 동시에 적용됩니다. 신경망 학습이나 3D 씬 렌더링 시 수천 개의 유사한 연산이 발생하는데, 이를 동시 스트림으로 분산해 순차적이 아닌 병렬로 처리합니다.
CUDA 코어 vs CPU 코어: 무엇이 다른가?

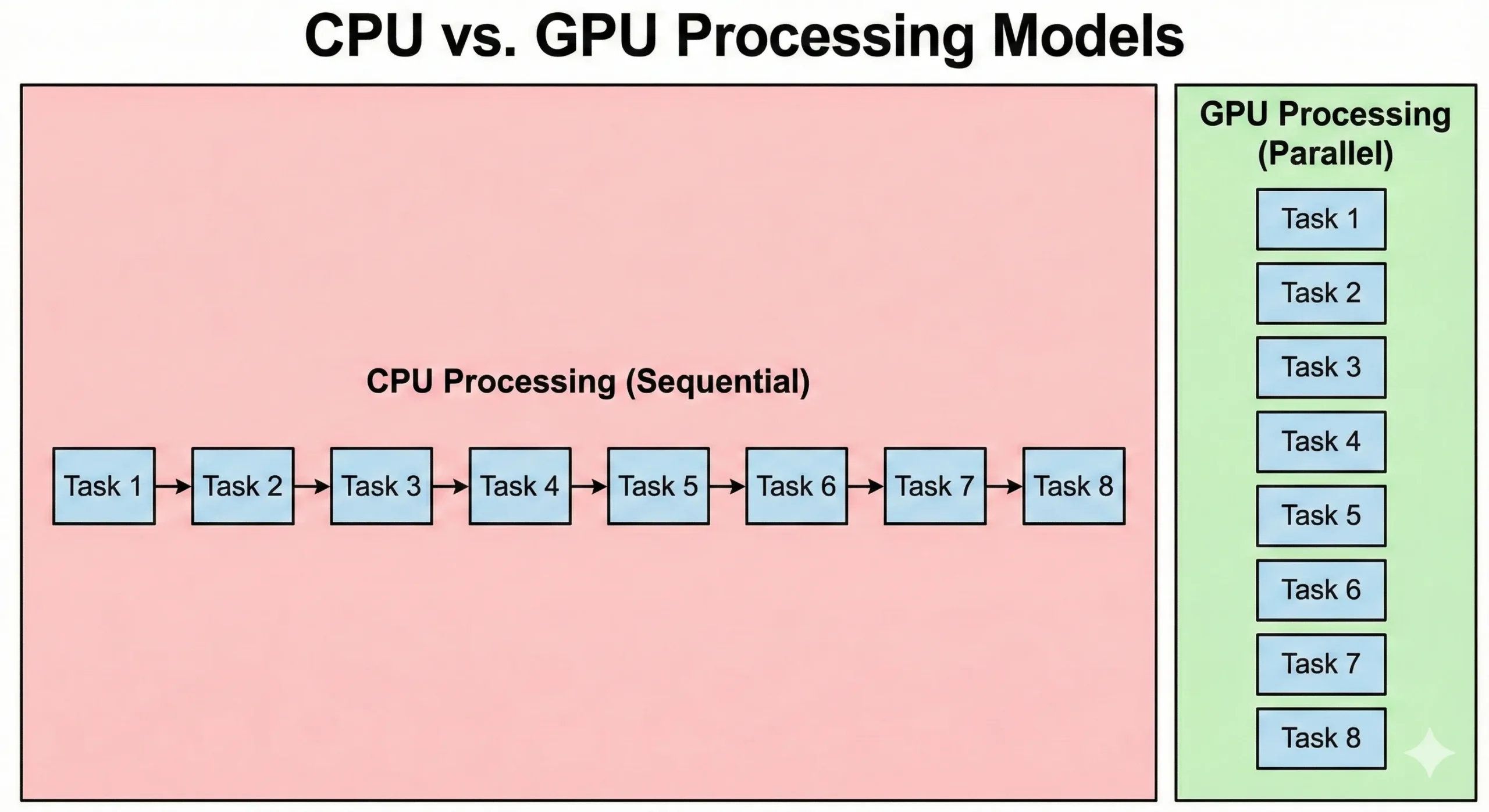
CPU와 GPU는 근본적으로 다른 방식으로 문제를 해결합니다. 최신 서버용 CPU는 높은 클럭 속도로 동작하는 8~128개 이상의 코어를 갖추고 있습니다. 이 프로세서들은 각 단계가 이전 결과에 의존하는 순차적 연산에 강하며, 복잡한 로직과 분기 처리에 뛰어납니다.
GPU는 접근 방식이 다릅니다. 낮은 클럭 속도로 동작하는 수천 개의 단순한 CUDA 코어를 탑재합니다. 속도 대신 병렬성으로 성능을 보완합니다. 16,000개가 함께 동작하면 전체 처리량이 일반 CPU의 처리 능력을 넘어섭니다.
CPU는 운영 체제 코드와 복잡한 애플리케이션 로직을 실행합니다. GPU는 처리량을 우선시하지만, 작업 시작과 동기화에 따른 오버헤드로 인해 지연 시간이 길어집니다. 병렬 그래픽 처리는 데이터를 빠르게 이동시키는 데 집중합니다. 시작하는 데 시간이 더 걸리지만, 대용량 데이터셋은 CPU보다 빠르게 처리합니다.
| 기능 | CPU 코어 | CUDA 코어 |
| 칩당 유닛 수 | 4-128+ 코어 | 2,560~21,760 코어 |
| 클록 속도 | 3.0-5.5 GHz | 1.4-2.5 GHz |
| 처리 방식 | 순차적, 복잡한 명령 | 병렬, 단순한 명령 |
| 적합한 용도 | 운영 체제, 단일 스레드 작업 | 행렬 연산, 병렬 데이터 처리 |
| 지연 시간 | 낮음 (마이크로초) | 높음 (실행 오버헤드 존재) |
| 아키텍처 | 범용 | 반복 연산에 특화 |
가상 GPU(vGPU)와 멀티 인스턴스 GPU(MIG) 기술은 리소스 파티셔닝과 스케줄링을 통해 여러 사용자에게 프로세서를 분배합니다. 이 구성을 통해 팀은 설정에 따라 시간 분할 공유 또는 전용 하드웨어 인스턴스 방식으로 하드웨어 활용률을 극대화할 수 있습니다.
신경망 학습에는 수십억 건의 행렬 곱셈이 수반됩니다. 10,000개의 유닛을 갖춘 GPU가 10,000개의 연산을 단순히 동시에 실행하는 것은 아닙니다. 대신 수천 개의 병렬 스레드를 '워프(warp)' 단위로 묶어 처리량을 극대화합니다. 이러한 대규모 병렬 처리 능력이 바로 이 유닛이 AI 개발자에게 필수 개념인 이유입니다.
CUDA 코어 vs 텐서 코어: 차이점 이해하기

NVIDIA GPU에는 서로 협력하는 두 가지 특수 유닛이 포함되어 있습니다. 바로 표준 CUDA 코어와 텐서 코어입니다. 이 둘은 경쟁 관계가 아니라, 각각 서로 다른 워크로드를 담당합니다.
표준 유닛은 범용 병렬 프로세서로, FP32 및 FP64 연산, 정수 연산, 좌표 변환을 처리합니다. 이 핵심 CUDA 기술은 GPU 컴퓨팅의 기반을 이루며, 물리 시뮬레이션부터 데이터 전처리까지 별도의 가속 없이 폭넓은 작업을 수행합니다.
텐서 코어는 행렬 곱셈과 AI 작업만을 위해 설계된 특수 유닛입니다. NVIDIA의 Volta 아키텍처(2017년)에서 처음 도입되었으며, FP16 및 TF32 정밀도 연산에 강점을 보입니다. 최신 세대는 더 빠른 AI 추론을 위해 FP8도 지원합니다.
| 기능 | CUDA 코어 | 텐서 코어 |
| 역할 | 범용 병렬 컴퓨팅 | AI를 위한 행렬 곱셈 |
| 정확도 | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| AI를 위한 속도 | 1배 기준 | CUDA 코어 대비 2~10배 빠름 |
| 사용 사례 | 데이터 전처리, 전통적인 ML | 딥러닝 학습 및 추론 |
| 이용 가능성 | 모든 NVIDIA GPU | RTX 20 시리즈 이상, 데이터센터 GPU |
최신 GPU는 두 유닛을 모두 탑재합니다. RTX 5090는 표준 유닛 21,760개와 5세대 텐서 코어 680개를 갖추고 있으며, H100는 표준 유닛 16,896개와 딥러닝 가속을 위한 4세대 텐서 코어 528개를 탑재하고 있습니다.
신경망 학습 시 텐서 코어는 모델의 순전파와 역전파 과정에서 핵심 연산을 담당합니다. 표준 유닛은 데이터 로딩, 전처리, 손실 계산, 옵티마이저 업데이트를 처리합니다. 두 유닛은 함께 작동하며, 텐서 코어가 연산 집약적인 작업을 가속합니다.
랜덤 포레스트나 그래디언트 부스팅 같은 전통적인 머신러닝 알고리즘은 텐서 코어가 가속하는 행렬 곱셈 패턴을 사용하지 않기 때문에 표준 유닛이 작업을 처리합니다. 반면 트랜스포머 모델이나 합성곱 신경망에서는 텐서 코어가 눈에 띄는 속도 향상을 제공합니다.
CUDA 코어는 어디에 활용되나요?

CUDA 코어는 동일한 연산을 대량으로 동시에 처리하는 작업에 최적화되어 있습니다. 행렬 연산이나 반복적인 수치 계산이 포함된 모든 작업은 이 아키텍처의 이점을 활용할 수 있습니다.
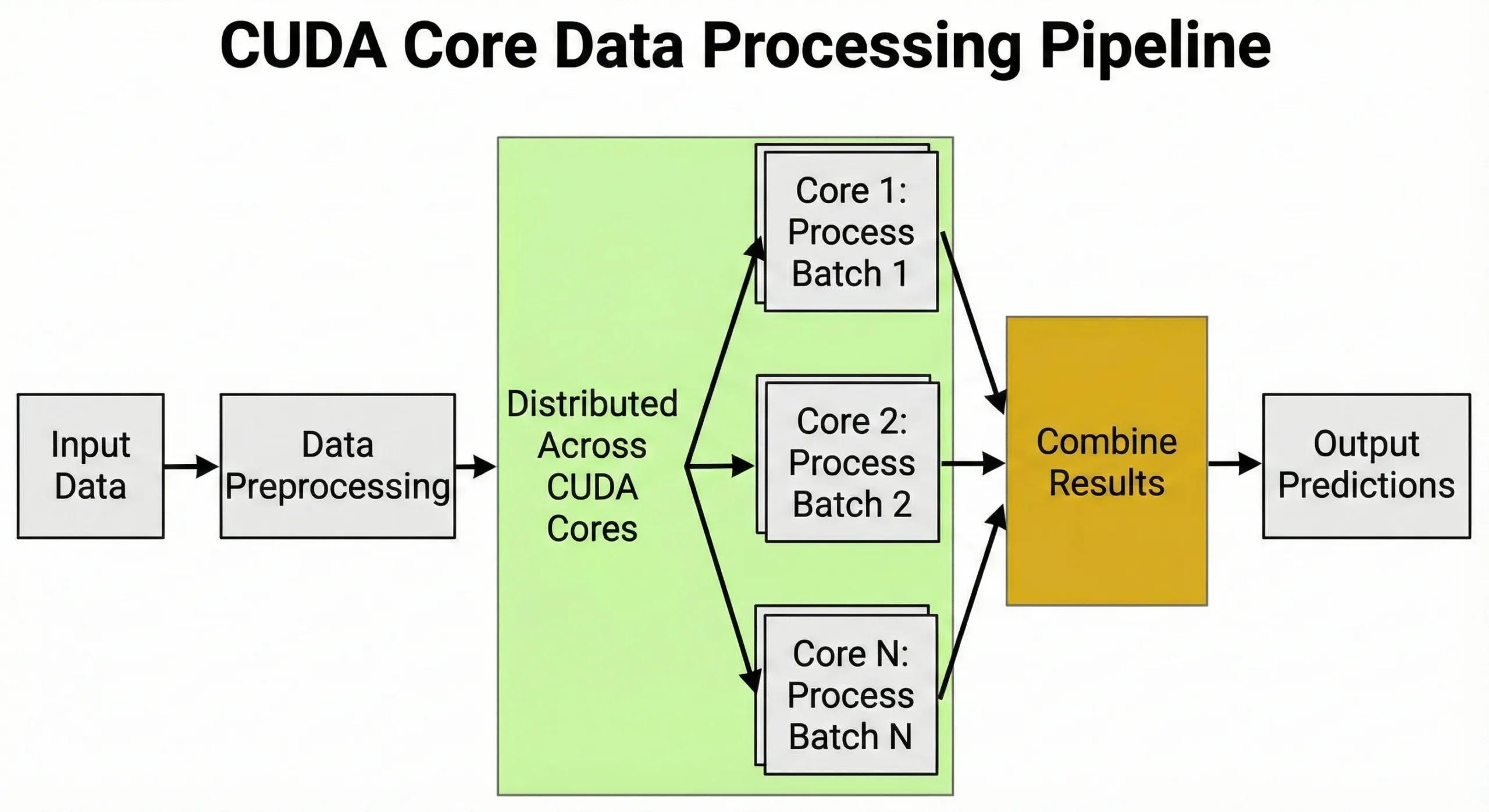
AI 및 머신러닝 애플리케이션
딥러닝은 학습과 추론 과정에서 행렬 곱셈에 의존합니다. 신경망을 학습할 때, 각 순전파 단계에서 가중치 행렬에 걸쳐 수백만 번의 곱셈-덧셈 연산이 필요합니다. 역전파 단계에서는 그보다 더 많은 연산이 추가됩니다.
GPU는 데이터 전처리를 담당하며, 이미지를 텐서로 변환하고 값을 정규화하며 증강 변환을 적용합니다. 수천 개의 작업을 동시에 처리할 수 있는 이 능력이 바로 GPU가 AI에서 중요한 이유입니다.
학습 과정에서 GPU는 학습률 스케줄, 그래디언트 계산, 옵티마이저 상태 업데이트를 관리합니다.
추천 시스템이나 챗봇을 운영하는 AI 추론 작업에서 GPU는 요청을 동시에 처리하며 수백 개의 예측을 병렬로 실행합니다. 아래 가이드에서 AI에 최적화된 GPU 2025 추천 다양한 모델 크기에 맞는 구성을 확인할 수 있습니다.
RTX 6000 Pro의 16,896개 코어는 Tensor 코어와 결합하여 70억 파라미터 모델을 수개월이 아닌 몇 주 만에 학습시킵니다. 수천 명의 사용자를 응대하는 챗봇의 실시간 추론도 이와 같은 수준의 병렬 처리 능력을 필요로 합니다.
과학 연산 및 연구
연구자들은 분자 동역학 시뮬레이션, 기후 모델링, 유전체 분석에 GPU를 활용합니다. 각 계산이 독립적으로 이루어지기 때문에 병렬 실행에 이상적입니다. 금융 기관에서도 수백만 가지 시나리오를 동시에 실행하는 몬테카를로 시뮬레이션에 GPU를 사용합니다.
3D 렌더링 및 영상 제작
레이 트레이싱은 각 픽셀을 통해 독립적인 광선을 추적하여 3D 장면에서 빛의 반사를 계산합니다. 전용 RT 코어가 광선 탐색을 담당하는 동안, 일반 코어는 텍스처 샘플링과 조명 처리를 맡습니다. 이 역할 분담이 수백만 개의 광선이 오가는 장면의 렌더링 속도를 결정합니다.
NVENC는 H.264 및 H.265 인코딩을 처리하며, Ada Lovelace와 Hopper 같은 최신 아키텍처는 AV1 하드웨어 지원을 추가했습니다. CUDA는 이펙트, 필터, 스케일링, 노이즈 제거, 색상 변환, 파이프라인 연결을 담당합니다. 덕분에 인코딩 엔진이 병렬 프로세서와 함께 작동하여 영상 제작 속도를 높입니다.
Blender나 Maya에서의 3D 렌더링은 수십억 개의 서피스 셰이더 계산을 사용 가능한 코어에 분산합니다. 파티클 시스템도 수천 개의 파티클 상호작용을 동시에 시뮬레이션하므로 GPU의 혜택을 받습니다. 이러한 기능들은 고품질 디지털 콘텐츠 제작의 핵심입니다.
CUDA 코어가 GPU 성능에 미치는 영향

코어 수는 동시 처리 능력의 대략적인 지표일 뿐, CUDA 코어를 평가할 때는 숫자 이상을 봐야 합니다. 클럭 속도, 메모리 대역폭, 아키텍처 효율성, 소프트웨어 최적화 모두 중요한 역할을 합니다.
코어 수가 동일하게 10,000개라도, 2.0 GHz로 동작하는 GPU와 1.5 GHz로 동작하는 GPU는 다른 성능을 냅니다. 클럭 속도가 높을수록 각 코어가 초당 더 많은 연산을 처리합니다. 최신 아키텍처는 명령어 스케줄링 개선을 통해 사이클당 더 많은 작업을 처리합니다.
GPU가 충분히 활용되고 있는지 확인하되, nvidia-smi 사용률은 거친 지표임을 기억하세요. 커널이 활성 상태인 시간의 비율을 측정할 뿐, 실제로 몇 개의 코어가 작동 중인지는 알 수 없습니다.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheader출력 예시: 85%, 92% (활성 시간 85%, 메모리 컨트롤러 활동 92%)
GPU 사용률이 60~70% 수준이라면, CPU 데이터 로딩이나 작은 배치 크기 같은 업스트림 병목이 원인일 가능성이 높습니다. 그러나 사용률 100%도 커널이 메모리 바운드이거나 단일 스레드로 동작하고 있다면 오해를 불러일으킬 수 있습니다. 코어 포화도를 정확히 파악하려면 Nsight Systems 같은 프로파일러로 "SM Efficiency" 또는 "SM Active" 지표를 추적하세요.
연산 능력이 최대치에 도달하기 전에 메모리 대역폭이 먼저 병목이 되는 경우가 많습니다. GPU가 메모리에서 데이터를 공급받는 속도보다 빠르게 처리한다면, 코어는 유휴 상태로 남게 됩니다. H100 SXM5 모델은 16,896개의 코어를 구동하기 위해 3.35 TB/s의 대역폭을 사용합니다. 반면 PCIe 버전은 이 수치가 2 TB/s로 낮아집니다.
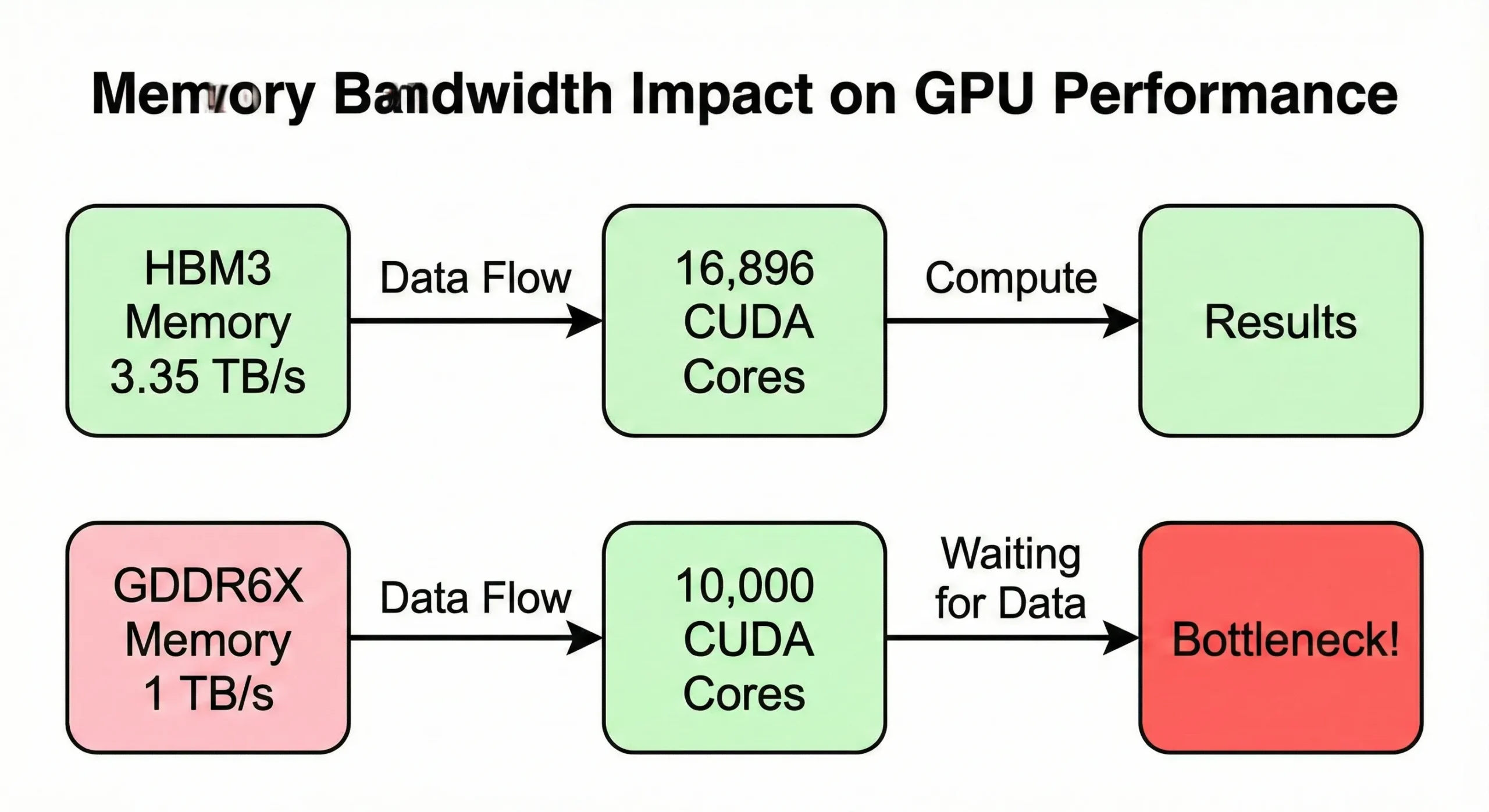
비슷한 코어 수를 가졌지만 대역폭이 낮은(약 1 TB/s) 소비자용 GPU는 메모리 집약적 작업에서 실제 성능이 떨어집니다.
VRAM 용량은 처리할 수 있는 작업의 규모를 결정합니다. FP16 가중치를 사용하는 70B 모델의 경우에도 전체 학습에는 더 많은 메모리가 필요합니다. 그래디언트와 옵티마이저 상태도 고려해야 합니다. 오프로드 전략을 사용하지 않으면 이 상태들이 메모리 사용량을 최대 3배까지 늘립니다.
A100 80GB는 고처리량 추론과 파인튜닝에 적합합니다. 한편 24GB RTX 4090는 7B 모델용으로 자주 언급되지만, INT4 같은 현대적인 양자화 기법을 활용하면 30B 이상의 파라미터 모델도 실행할 수 있습니다. 다만 VRAM가 부족해지면 CPU-GPU 간 데이터 전송이 발생해 처리량이 급격히 저하됩니다.
소프트웨어 최적화에 따라 코드가 모든 유닛을 실제로 활용하는지 여부가 결정됩니다. 잘못 작성된 커널은 가용 리소스의 일부만 사용할 수 있습니다. 딥러닝용 cuDNN, 데이터 사이언스용 RAPIDS 같은 라이브러리는 활용률을 극대화하도록 정밀하게 튜닝되어 있습니다.
CUDA 코어 수가 많다고 성능이 좋은 것은 아닙니다

코어 수가 가장 많은 GPU를 선택하는 것이 합리적으로 보일 수 있지만, 유닛이 다른 시스템 구성 요소보다 앞서거나 작업이 코어 수에 따라 확장되지 않는다면 비용이 낭비될 뿐입니다.
메모리 대역폭이 첫 번째 제약이 됩니다. RTX 5090의 21,760개 유닛은 1,792 GB/s의 메모리 대역폭으로 공급됩니다. 유닛 수가 적은 구형 GPU는 유닛당 대역폭이 오히려 더 높을 수 있습니다.
아키텍처 차이도 중요합니다. 2.2 GHz에서 14,000개 유닛을 갖춘 최신 GPU는 클록당 명령어 처리 효율이 높아, 1.8 GHz에서 16,000개 유닛을 갖춘 구형 모델보다 성능이 뛰어납니다. 20,000개 유닛을 효과적으로 활용하려면 코드의 병렬화 설계가 제대로 갖춰져야 합니다.
GPU VPS를 선택할 때 CUDA 코어가 중요한 이유

VPS에 맞는 CUDA 코어 GPU 구성을 선택해야 불필요한 리소스 낭비나 프로젝트 중간의 병목 현상을 피할 수 있습니다.
H100의 80GB 메모리는 4비트 양자화를 사용한 70B 파라미터 모델 추론을 처리할 수 있습니다. 하지만 전체 학습의 경우, 그래디언트와 옵티마이저 상태를 고려하면 34B 모델에도 80GB가 부족한 경우가 많습니다. FP16 학습에서는 메모리 사용량이 크게 늘어나 다중 GPU 샤딩이 필요한 경우가 많습니다.
실시간 예측을 제공하는 추론 작업은 유닛 수가 적어도 되지만 낮은 레이턴시가 중요합니다. 알고리즘 테스트와 코드 디버깅 같은 개발 및 프로토타이핑 작업에는 중급 GPU로 충분합니다.
4,352개 유닛의 RTX 4060 Ti로 과도한 하드웨어 비용 없이 테스트할 수 있습니다. 접근 방식이 검증되면 프로덕션용 GPU로 확장해 전체 학습을 진행하세요.
렌더링과 영상 작업은 일정 수준까지 유닛 수에 비례해 성능이 향상됩니다. Blender의 Cycles 렌더러는 모든 가용 리소스를 효율적으로 활용합니다. 8,000~10,000개 유닛을 갖춘 GPU는 4,000개짜리 대비 2~3배 빠르게 씬을 렌더링합니다.
Cloudzy에서는 고성능 GPU VPS 무거운 작업을 위한 호스팅을 제공합니다. 빠른 렌더링과 비용 효율적인 AI 추론에는 RTX 5090 또는 RTX 4090를, 대규모 딥러닝 워크로드에는 A100로 확장하세요. 모든 플랜은 40 Gbps 네트워크에서 운영되며, 프라이버시 우선 정책과 암호화폐 결제 옵션을 제공합니다. 복잡한 절차 없이 필요한 성능을 바로 활용할 수 있습니다.
AI 모델 학습, 3D 씬 렌더링, 과학 시뮬레이션 등 어떤 작업이든 필요에 맞는 코어 수를 직접 선택하세요.
비용도 중요한 기준입니다. 6,912개 유닛의 A100는 16,896개 유닛의 H100보다 가격이 훨씬 낮습니다. 많은 작업에서 A100 두 대가 H100 한 대보다 가격 대비 성능이 더 높습니다. 손익 분기점은 코드가 여러 GPU에 걸쳐 확장되는지 여부에 달려 있습니다.
CUDA 코어 수를 올바르게 선택하는 방법
시장에서 가장 높은 사양을 쫓기보다, 실제 워크로드 특성에 맞는 요구사항을 파악하세요.
먼저 현재 작업을 프로파일링하세요. 로컬 하드웨어나 클라우드 인스턴스에서 모델을 학습하고 있다면, GPU 사용률 지표를 확인하세요. GPU 사용률이 꾸준히 60~70%라면, 아직 최대 용량에 도달한 것이 아닙니다.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")이 간단한 벤치마크로 GPU 코어가 예상 처리량을 내고 있는지 확인할 수 있습니다. 결과를 해당 GPU 모델의 공식 벤치마크와 비교해보세요.
업그레이드는 해결책이 아닙니다. 먼저 메모리, 대역폭, CPU 병목 현상을 해결해야 합니다. 그 다음 모델 크기(바이트)에 활성화 메모리를 더해 필요한 메모리 요구량을 계산하세요.
배치 크기와 레이어 출력값을 곱한 뒤 옵티마이저 상태도 포함하세요. 이 합계가 VRAM에 맞아야 합니다. 필요한 메모리를 파악한 후, 해당 기준을 충족하는 GPU를 찾으세요.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)일정도 고려하세요. 결과를 몇 시간 안에 얻어야 한다면 더 많은 유닛에 비용을 지불하세요. 며칠이 걸려도 괜찮은 학습 작업이라면 소형 GPU로도 충분히 처리할 수 있으며, 완료 시간이 그만큼 길어질 뿐입니다.
시간당 비용에 필요한 시간을 곱하면 총비용이 나옵니다. 경우에 따라 느린 GPU가 전체 비용 면에서 더 저렴할 수 있습니다. 많은 프레임워크에서 처리량 변화를 보여주는 벤치마킹 도구를 제공하므로, 이를 활용해 확장 효율성을 테스트하세요.
유닛을 두 배로 늘렸는데 속도가 1.5배밖에 향상되지 않는다면, 추가 비용만큼의 가치가 없습니다. 가격 대비 성능 비율이 가장 높은 최적점을 찾으세요.
| 워크로드 유형 | 권장 코어 | 예시 GPU | 참고 |
| 모델 개발 및 디버깅 | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | 빠른 반복 개발, 낮은 비용 |
| 소규모 AI 학습 (파라미터 7B 미만) | 6,000-10,000 | RTX 4090, L40S | 개인 및 소형 기업에 적합 |
| 대규모 AI 학습 (파라미터 7B~70B) | 14,000+ | A100, H100 | 데이터센터용 GPU 필요 |
| 실시간 추론 (고처리량) | 10,000-16,000 | RTX 5080, L40 | 비용과 성능의 균형 |
| 3D 렌더링 및 동영상 인코딩 | 8,000-12,000 | RTX 4080, RTX 4090 | 복잡도에 따라 확장 |
| 과학 계산 및 HPC | 10,000+ | A100, H100 | FP64 지원이 필요합니다 |
주요 VPS GPU 모델과 CUDA 코어 수

GPU 등급에 따라 대상 사용자가 다릅니다. GPUaaS란 무엇일까요? Cloudzy 같은 공급업체가 물리적 하드웨어를 직접 구매하거나 유지관리할 필요 없이, 강력한 NVIDIA GPU에 온디맨드로 접근할 수 있게 해주는 GPU-as-a-Service입니다.
| GPU 모델 | CUDA 코어 | VRAM | 메모리 대역폭 | 아키텍처 | 추천 용도 |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1,792 GB/s | Blackwell | 플래그십 워크스테이션, 8K 렌더링 |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | 에이다 러브레이스 | 고성능 AI, 4K 렌더링 |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3,350 GB/초 | Hopper | 대규모 AI 학습 |
| H100 PCIe | 14,592 | 80GB HBM2e | 2,000GB/초 | Hopper | 엔터프라이즈 AI, 비용 효율적인 데이터센터 |
| A100 | 6,912 | 40/80GB HBM2e | 1,555–2,039 GB/s | Ampere | 중급 AI, 검증된 안정성 |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | 에이다 러브레이스 | 게임 및 중급 AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | 에이다 러브레이스 | 멀티 워크로드 데이터센터 |
일반 소비자용 RTX 카드(4070, 4080, 4090, 5080, 5090)는 크리에이터와 게이머를 위한 제품이지만, AI 개발에도 충분히 활용할 수 있습니다. 데이터센터 카드보다 저렴한 가격에 뛰어난 단일 GPU 성능을 제공합니다.
소비자용 GPU(VPS)는 비용에 민감한 사용자를 위해 많은 공급업체가 제공합니다. 데이터센터용 카드(A100, H100, L40)는 안정성, ECC 메모리, 다중 GPU 확장에 최적화되어 있습니다. 24시간 365일 운영을 처리하고 고급 기능을 지원합니다.
멀티 인스턴스 GPU(MIG) 기능을 사용하면 하나의 GPU를 여러 개의 독립된 인스턴스로 분할할 수 있습니다. GPU는 더 새로운 옵션들이 등장했음에도 균형 잡힌 사양 덕분에 여전히 널리 사용되고 있습니다.
NVIDIA 코어 수, 메모리 용량, 가격의 균형을 고려하면 대부분의 프로덕션 AI 작업에 가장 무난한 선택입니다. H100는 유닛 수가 2.4배 많지만 비용도 상당히 높습니다.
결론
병렬 처리 엔진은 현대 AI, 렌더링, 과학 연산의 핵심입니다. 작동 방식과 메모리, 클럭 속도, 소프트웨어와의 상호작용을 이해하면 GPU VPS 구성을 선택하는 데 도움이 됩니다.
코어 수를 늘리면 작업이 효과적으로 병렬화되고 메모리 대역폭 같은 구성 요소가 이를 뒷받침할 때 실질적인 성능 향상을 얻을 수 있습니다. 하지만 병목이 다른 곳에 있다면, 무작정 높은 코어 수를 쫓는 건 돈 낭비일 뿐입니다.
실제 운영 환경을 먼저 프로파일링하고, 어디에 시간이 소요되는지 파악한 다음, 불필요한 용량을 과도하게 구매하지 않도록 GPU 사양을 해당 요구사항에 맞춰 선택하세요.
대부분의 AI 개발 작업에서는 6,000~10,000 유닛이 비용과 성능 사이의 최적 균형점입니다. 대형 모델 학습이나 고처리량 추론을 운영하는 프로덕션 환경에서는 H100와 같이 14,000 유닛 이상의 GPU가 적합합니다.
렌더링과 영상 작업은 약 16,000 유닛까지 효율적으로 확장되며, 그 이상에서는 메모리 대역폭이 병목 지점이 됩니다.


