
NVIDIA가 DLSS 4로 열여섯 픽셀 중 열다섯 픽셀 을 AI로 생성하는 모습을 공개했을 때, 상당수의 관객은 발전을 보지 못했다. 그들이 본 것은 "가짜 프레임"과 "AI 슬롭"이었다. 그럴듯해 보이다가 어느 순간 무너지는 생성된 디테일, 그리고 잘못 놓인 폴리곤을 디버깅하듯 디버깅할 수 없는 결과물 말이다. 한 커뮤니티 설문에 대한 PCGuide 보도에 따르면 응답의 54%가 DLSS 5의 외관에 대해 단순히 "아니오"였으며, 비판의 상당 부분은 얼굴 표현과 "AI 슬롭" 반응에 집중되었다. 그 반응은 진지하게 받아들일 가치가 있으며, 뒤에서 다시 다루겠다.
그러나 그 모든 논쟁의 더 큰 문제는 "뉴럴 렌더링"이라는 말이 최소 다섯 가지 서로 다른 것을 가리키는 데 쓰인다는 점이다. 업스케일링, AI 생성 프레임, 사진을 통한 장면 재구성, 소셜 미디어에서 본 NeRF와 Gaussian Splatting 데모, 그리고 단일 네트워크로 이미지 전체를 렌더링하는 연구 시스템이 그것이다. 사람들은 서로 다른 계층을 가리키면서 같은 단어를 쓰기 때문에 엇갈린 논쟁을 한다. NVIDIA의 젠슨 황은 이 변화를 "그래픽의 GPT 순간"이라고 불렀다. 그것이 주장이다. 유용한 질문은 그 아래에서 무슨 일이 벌어지고 있느냐다.
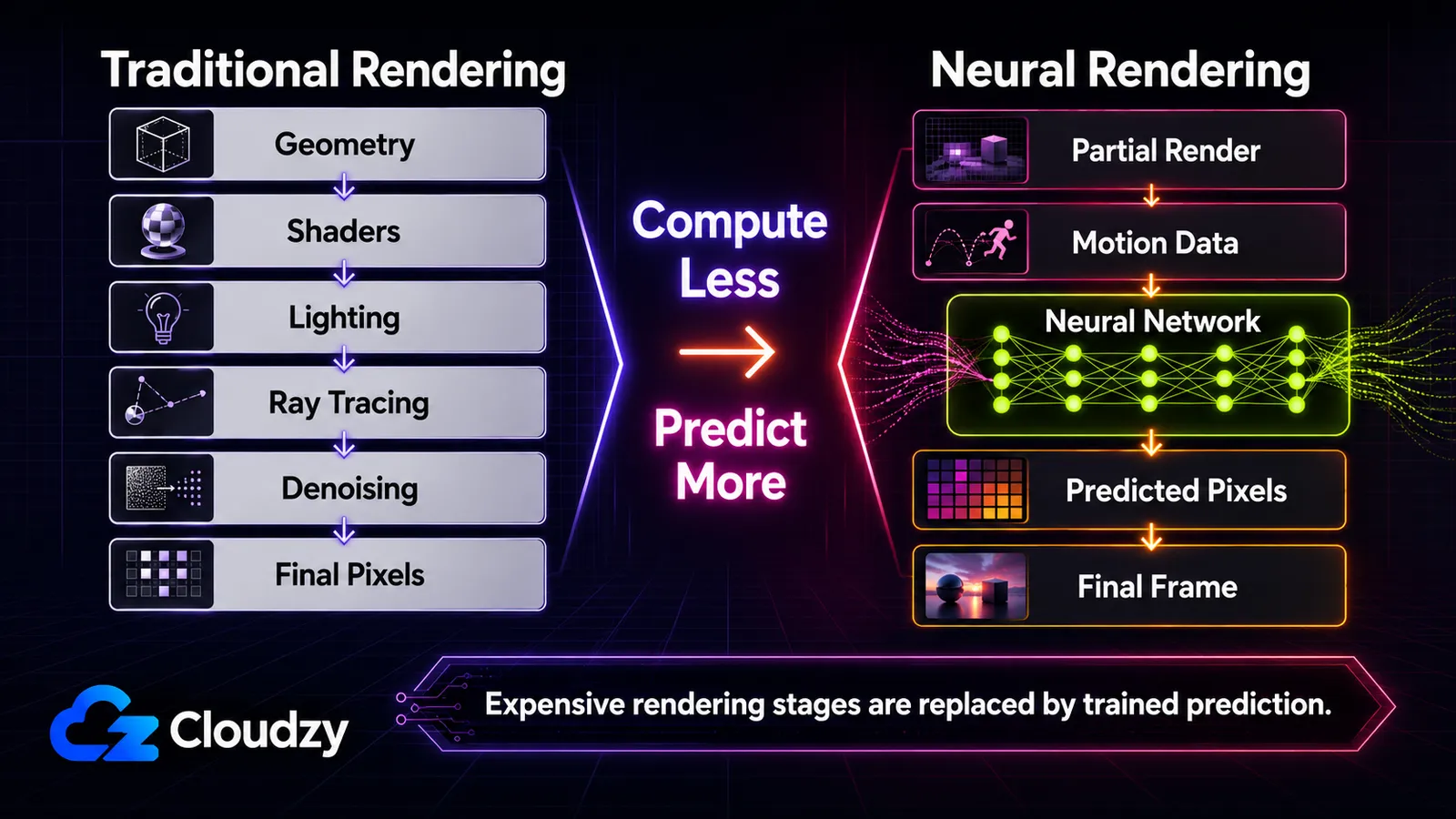
전체를 이해 가능하게 만드는 핵심 줄기는 이것이다. GPU는 이미지를 계산하는 대신 점점 더 예측하고 있다. 전통적으로 GPU는 지오메트리, 조명, 재질을 시뮬레이션해 모든 픽셀을 계산한다(래스터화, 그리고 더 최근에는 그 위에 얹은 레이 트레이싱). 뉴럴 렌더링은 무엇이 계산되는지 와 무엇이 학습된 네트워크에 의해 예측 되는지를 바꾼다. 그 하나의 구분이 이 글의 척추다. 끝까지 읽고 나면 어떤 기법이든 스펙트럼 위에 놓을 수 있고, 어느 것이 실시간으로 어떤 하드웨어에서 작동하는지 알며, 오늘 게임에 실제로 들어간 것과 연구 논문이나 GTC 데모에 불과한 것을 구분할 수 있게 된다. 이것은 지도이지 사용법 안내가 아니다. 개별 기법의 깊은 메커니즘은 그 자체로 별도의 글감이다.
요약
- 뉴럴 렌더링은 스펙트럼이지 DLSS의 동의어가 아니다. 이것은 장면 재구성 연구(NeRF, Gaussian Splatting), 렌더링 파이프라인 내부에 자리한 실시간 구성 요소(DLSS, Ray Reconstruction, 뉴럴 라디언스 캐시), 그리고 프레임이 한 번도 가진 적 없는 디테일을 만들어내는 생성 기법까지 아우른다.
- 핵심 줄기는 "계산하는 대신 예측한다"이다. 각 기법은 파이프라인의 비싼 계산 단계를, 학습된 결과를 예측하는 네트워크로 대체한다.
- 오늘 출시되는 것 대부분은 하이브리드다. 업스케일링, 프레임 생성, AI 디노이징은 이제 실시간 게임에서 작동하며, 뉴럴 텍스처 압축과 뉴럴 셰이더는 개발자 툴킷을 통해 등장하고 있다. 네트워크로 이미지 전체를 그리는 완전한 뉴럴 렌더러는 여전히 연구 단계다.
- 이것은 NVIDIA만의 이야기가 아니라 벤더를 가로지르는 흐름이 되고 있다. 셰이더 수준 ML에 대한 Microsoft의 DirectX 작업은 Shader Model 6.9의 Cooperative Vectors로 시작해 Shader Model 6.10의 더 폭넓은 선형대수 지원으로 나아가고 있으며, 이를 통해 엔진이 한 벤더의 스택을 넘어 뉴럴 방식의 셰이더 워크로드를 겨냥할 길을 열어준다.
왜 "뉴럴 렌더링"이 다섯 가지 서로 다른 것을 의미하는가
뉴럴 렌더링은 신경망을 사용해 GPU가 처음부터 계산했을 이미지의 일부(픽셀, 조명, 재질, 심지어 프레임 전체)를 예측하는 일군의 방법이다. Tewari 외 서베이 는 이를 사실적 출력을 위해 고전 컴퓨터 그래픽과 심층 생성 모델을 결합하는 것으로 정의한다. 이 용어는 넓은 스펙트럼을 아우르며, "DLSS"는 그 위의 한 점이다.
논의가 엉망인 이유는 스펙트럼에 적어도 세 개의 뚜렷한 계층이 있는데도 대중이 그 전부에 하나의 단어를 쓰기 때문이다.
첫 번째 계층은 학술 / 재구성 뉴럴 렌더링이다. NeRF, 3D Gaussian Splatting, 그리고 미분 가능 렌더링이 여기 속한다. 이들은 실제 장면의 사진이나 측정값을 받아, 새로운 카메라 각도에서 렌더링할 수 있는 표현을 학습한다. 원본 NeRF 논문 (Mildenhall 외, 2020)은 작은 네트워크를 학습시켜 3D 좌표와 시점 방향을 색상과 밀도로 매핑한 뒤, 그것을 질의해 새로운 시점을 렌더링한다. 이 계층은 대부분 오프라인이다. 장면을 재구성하지만 게임의 프레임 루프를 구동하지는 않는다.
두 번째 계층은 실시간 파이프라인 뉴럴 렌더링이다. 일반적인 래스터화 프레임 안에서, 혹은 그와 나란히 작동하는 네트워크다. DLSS 업스케일링, Ray Reconstruction, 뉴럴 라디언스 캐시가 여기 산다. 파이프라인은 여전히 래스터화하고 레이 트레이싱하며, 네트워크는 그중 비싼 한 단계를 맡는다. 이것이 오늘 게임에 들어가는 계층이다.
세 번째 계층은 생성 뉴럴 렌더링이다. 네트워크가 프레임이 전혀 계산한 적 없는 이미지 콘텐츠를 만들어낸다. DLSS 4의 생성 프레임이 이 가장자리에 있으며, DLSS 5(NVIDIA가 2026년 가을로 발표함)는 렌더링된 프레임 사이를 보간하는 데 그치지 않고 조명과 재질 디테일을 생성함으로써 이쪽으로 더 깊이 들어간다.
이 세 계층은 다르게 작동하고, 다른 속도로 돌아가며, 다른 하드웨어가 필요하다. 이들을 하나로 취급하는 것이 바로 두 사람이 각각 "뉴럴 렌더링은 과대평가됐다"와 "뉴럴 렌더링은 미래다"라고 말하면서 둘 다 부분적으로 옳을 수 있는 이유다.
절 요약: 이 용어는 DLSS보다 먼저 나왔고 그것의 동의어가 아니다. DLSS는 오프라인 장면 재구성부터 완전 생성 프레임까지 훨씬 넓은 스펙트럼 안의 한 응용(실시간, 파이프라인 내부)이다.
뉴럴 렌더링이 무차별 대입 파이프라인의 일부를 어떻게 대체하고 있는가
완전한 DLSS 4 멀티 프레임 생성에서는 화면의 열여섯 픽셀 중 약 열다섯 픽셀이 전통적으로 렌더링된 것이 아니라 AI로 만들어진다(NVIDIA의 DLSS 4 수치 기준). 그 숫자는 변화 전체를 하나의 통계로 압축한 것이다. 렌더러는 이미지의 일부만 계산하고 나머지는 예측한다.
전통적 렌더링은 모든 픽셀을 일일이 얻어낸다. GPU는 지오메트리를 래스터화하고, 셰이더를 돌려 조명과 재질을 계산하며, (레이 트레이싱으로) 빛이 장면을 튕겨 다니는 것을 시뮬레이션한다. 특히 레이 트레이싱은 잔혹할 만큼 비싸다. 사실적인 빛은 많은 반사와 픽셀당 많은 샘플을 필요로 하고, 부족한 샘플링에서 나오는 노이즈는 나중에 정리해야 하기 때문이다. 장면이 더 야심차질수록 가장 비싼 단계들이 자명한 표적이 되었다. 그것들을 계산하는 대신, 그 출력을 예측하도록 네트워크를 학습시키는 것이다.
진전은 갑작스럽기보다 꾸준했다.
- 2018년, DLSS 1.0. 첫 상업적 단계. 저해상도로 렌더링하고 고해상도 이미지를 예측한다. 업스케일을 "더 많은 픽셀을 계산한다"에서 "더 많은 픽셀을 예측한다"로 옮긴 것이다.
- 2020년, NeRF. 학습된 라디언스 필드를 통한 이미지 기반 장면 재구성. 지오메트리를 모델링하고 렌더링하는 대신 새로운 시점을 예측한다.
- 2021년, Neural Radiance Cache. 패스 트레이싱 중 튕긴 빛을 예측해 렌더러가 추적을 일찍 멈출 수 있게 한다.
- 2022년, DLSS 3 Frame Generation. 중간 프레임을 렌더링하는 대신 통째로 생성한다.
- 2023년, 3D Gaussian Splatting. 재구성된 장면을 위한, NeRF보다 빠르고 실시간에 가까운 대안.
- 2025년, DLSS 4 + RTX Kit. 멀티 프레임 생성에 더해 뉴럴 구성 요소(텍스처 압축, 라디언스 캐시, 뉴럴 셰이더) 툴킷.
- 2025년, DirectX Cooperative Vectors(프리뷰). 뉴럴 셰이더에 필요한 행렬 연산을 위한 벤더 횡단 API(Shader Model 6.9의 일부로 프리뷰 도입).
- 2026년, DLSS 4.5. 점진적 품질 및 Ray Reconstruction 개선(NVIDIA가 Computex에서 설명).
- 2026년 가을, DLSS 5(발표됨). 생성 뉴럴 렌더링을 향한 다음 단계.
위에서 아래로 읽으면 각 행은 서로 다른 단계에 적용된 같은 수다. 파이프라인이 계산하던 무언가를 가져와 대신 네트워크가 예측하게 하는 것이다.
여섯 계층: 파이프라인의 각 단계에서 AI가 무엇을 대체하는가
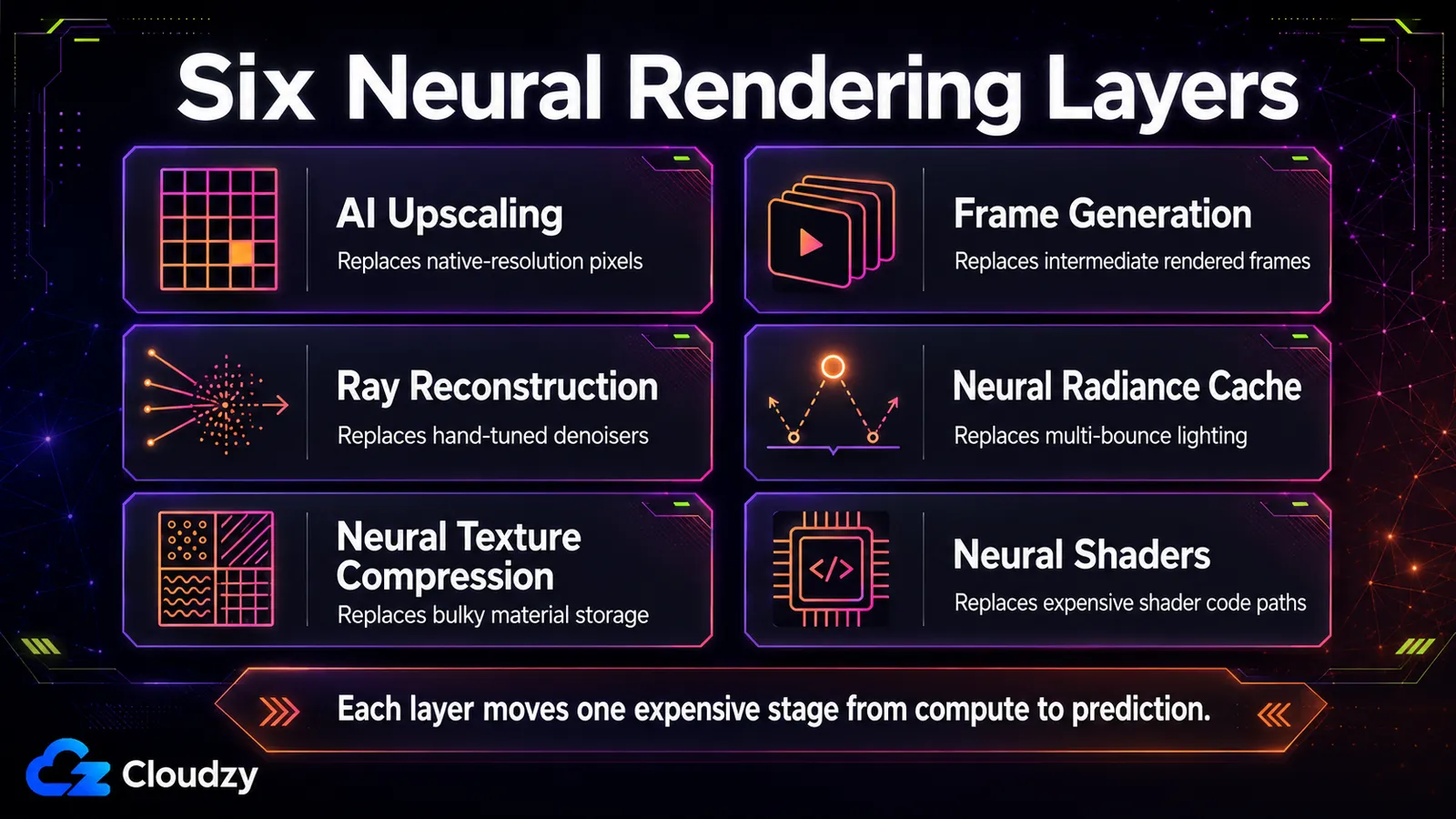
오늘날 실시간 뉴럴 렌더링의 대부분을 여섯 가지 기법이 짊어지며, 각각은 특정 계산 단계를 대체한다. 업스케일링(해상도), 프레임 생성(프레임 수), 레이 리컨스트럭션(디노이징), 뉴럴 라디언스 캐시(전역 조명), 뉴럴 텍스처 압축(재질 저장), 뉴럴 셰이더(셰이더 내 연산). 각각이 어느 단계를 건드리는지 아는 것이 싸움의 대부분이다.
이들은 다음 기준에 따라 나뉜다. 네트워크가 파이프라인의 어디에서 실행되는가. 어떤 것은 완성된 프레임에 대한 후처리로 맨 끝에서 작동하고, 어떤 것은 레이 트레이싱과 나란히 파이프라인 중간에서 돌며, 어떤 것은 셰이더 자체 안에 산다. 그 위치는 사소한 것이 아니다. 그것이 기법이 얼마나 빨리 돌 수 있는지, 어떤 하드웨어가 필요한지를 결정한다. 표는 그 여섯 기법을 정리하고, 아래 소절은 각 칸에 깔끔히 들어가지 않는 메커니즘을 설명한다.
| 기법 | 무엇을 대체하는가 | 실시간 실현성 | 필요 하드웨어 | 벤더 횡단? |
|---|---|---|---|---|
| AI 업스케일링(슈퍼 해상도) | 네이티브 해상도 픽셀 계산 | 실시간, 낮은 오버헤드 | 텐서 / 행렬 코어(RTX 20+, RDNA 4, Intel XMX) | 범주로서는 그렇다. 구현은 벤더별로 남아 있다(DLSS, FSR / FSR Upscaling, XeSS) |
| 프레임 생성 | 중간 프레임 렌더링 | 실시간. 지연을 더한다 | RTX 40+(DLSS 3), 멀티 프레임은 RTX 50 | 부분적. 벤더별 |
| 레이 리컨스트럭션 | 수작업 튜닝된 디노이저 스택 | 실시간 | RTX 20+ | 현재 NVIDIA |
| 뉴럴 라디언스 캐시 | 다중 반사 간접광 계산 | 실시간(약 2.6 ms 보고됨) | RTX급 행렬 코어 | 현재 NVIDIA(RTX Kit) |
| 뉴럴 텍스처 압축 | 블록 압축 재질 저장 | 실시간 디코드 | RTX급 행렬 코어 | 현재 NVIDIA SDK/툴링. 더 넓은 셰이더 수준 ML 지원은 별도로 표준화되는 중 |
| 뉴럴 셰이더 | 계산되던 셰이더 코드 경로 | 실시간 | 셰이더 수준 ML / 행렬 연산 가능 GPU | DirectX SM 6.9 / SM 6.10 경로를 통해 등장 중 |
AI 업스케일링(슈퍼 해상도)
AI 업스케일링은 프레임을 더 낮은 해상도로 렌더링하고 고해상도 결과를 예측하므로, GPU는 훨씬 적은 픽셀을 그리고 네트워크가 구조를 채운다. DLSS, AMD의 FSR 4, Intel의 XeSS 모두 이를 시간적(temporal) 업샘플링을 통해 한다. 연속 프레임에 걸쳐 서로 다른 픽셀을 샘플링하고, 그 히스토리를 모션 벡터와 결합해 단일 저해상도 프레임이 담지 못하는 디테일을 재구성한다.
이것은 가장 성숙하고 가장 널리 배포된 계층이며, 벤더 횡단 현실이 가장 분명한 곳이다. DLSS 4는 더 나은 디테일 안정성을 위해 업스케일러를 합성곱 네트워크에서 트랜스포머로 옮겼다. FSR 4는 AMD의 첫 ML 기반 업스케일러로, 이전 FSR 버전의 수작업 휴리스틱 대신 FP8 추론으로 RDNA 4에서 돈다. XeSS는 Intel의 XMX 행렬 유닛을 쓴다. 세 벤더, 동일한 근본 아이디어. 렌더링하지 않은 픽셀을 예측하는 것이다.
프레임 생성과 멀티 프레임 생성
프레임 생성은 모션 벡터 같은 게임 데이터를 옵티컬 플로우 추정 및 AI와 결합해, GPU가 실제로 렌더링하는 프레임들 사이에 프레임 전체를 예측한다. DLSS 3은 RTX 40 시리즈의 옵티컬 플로우 가속기를 사용해 렌더링된 프레임 사이에 생성 프레임 하나를 끼워 넣었다. RTX 50 시리즈 하드웨어의 DLSS 4 멀티 프레임 생성은 전통적으로 렌더링된 프레임마다 추가 프레임을 최대 세 개까지 생성할 수 있으며, NVIDIA는 DLSS 4가 하드웨어 옵티컬 플로우 단계를 더 효율적인 AI 모델로 대체한다고 말한다.
이것이 "가짜 프레임" 논쟁이 실제로 다루는 계층이며, 여기서 표현의 틀이 중요하다. 생성 프레임은 장면이 어디로 가고 있었는지에 대한 그럴듯한 보간이다. 즉 쓸 만한 시각적 콘텐츠를 보여준다. 그러나 그것은 예측되었을 뿐 게임의 실제 상태로부터 렌더링된 것이 아니며, 새로운 게임 로직이나 입력을 담지 않는다. 결정적으로 프레임 생성은 프레임이 렌더링된 후에(after) 실행되므로 지연을 없애는 것이 아니라 더한다. NVIDIA의 Reflex 2는 바로 그 지연을 되찾기 위해 존재한다. 그래서 "프레임 생성이 게임을 더 빠르게 만든다"는 절반의 진실이다. 게임이 실제로 갱신되고 반응하는 속도를 높이지 않은 채 체감 부드러움(표시되는 프레임 증가)만 높인다. 보이는 것과 게임이 아는 것 사이의 그 간극이 논쟁 전체이며, 입력 지연이 결과를 좌우하는 경쟁 플레이에서는 따져볼 가치가 있는 절충이다.
Ray Reconstruction(AI 디노이징)
Ray Reconstruction은 레이 트레이싱 렌더링이 의존하는 수작업 튜닝된 디노이징 필터 스택을, 노이즈가 많고 샘플이 부족한 레이 트레이싱 입력으로부터 깨끗한 이미지를 재구성하도록 학습된 단일 신경망으로 대체한다. 패스 트레이싱은 실시간에서 픽셀당 몇 개의 빛 샘플만 감당할 수 있어 원시 출력에 노이즈가 남으며, 보기 전에 무언가가 그것을 정리해야 한다.
전통적 접근은 각각 특정 효과를 위해 손으로 튜닝한 전문 디노이저들의 사슬이었다. 그것을 학습된 네트워크 하나로 바꾸면 수작업 필터가 뭉개던 디테일, 특히 반사와 미세 조명을 보존하는 경향이 있고, 깨지기 쉬운 디노이저 파이프라인 대신 유지할 네트워크가 하나뿐이다. 이것은 핵심 줄기의 깔끔한 예다. 디노이즈 단계가 "수작업 휴리스틱으로 계산"에서 "학습된 모델로 예측"으로 옮겨간 것이다.
Neural Radiance Cache(전역 조명)
뉴럴 라디언스 캐시(NRC)는 빛이 장면을 어떻게 튕겨 다니는지 예측해, 패스 트레이서가 모든 반사를 끝까지 따라가는 대신 대부분의 광선 추적을 일찍 멈출 수 있게 한다. 전역 조명(벽과 바닥에서 튕기는 부드럽고 간접적인 빛)은 실시간 그래픽에서 가장 비싼 것 중 하나이며, NRC를 작동하게 하는 메커니즘은 쉬운 말로 설명되는 일이 드물어 천천히 짚어볼 가치가 있다.
메커니즘은 이렇다. 패스 트레이서는 보통 각 광선을 여러 반사에 걸쳐 따라가는데, 바로 거기서 비용이 폭발한다. NRC는 작은 네트워크를 렌더링 중에(during) (미리가 아니라) 학습시켜, 추가 반사 이후 한 지점에 도달하는 빛을 예측한다. 그래서 패스 트레이서는 광선을 한두 번 반사까지 추적한 뒤 네트워크에 "여기 나머지 빛은 무엇인가?"라고 묻고 경로를 일찍 종료한다. 실시간 뉴럴 라디언스 캐싱 논문 (Müller 외, 2021)은 이런 식으로 대다수 경로를 종료한다고 보고한다. 이것을 전에 본 정확한 답을 저장하는 캐시가 아니라, 장면 조명의 패턴 을 충분히 학습해 보지 못한 질의에도 답하고 장면이 바뀌면 계속 재학습하는 캐시로 생각하라. NVIDIA는 NRC가 약 2.6 ms의 오버헤드로 돈다고 보고하며, 이것이 그것을 연구용 호기심이 아니라 실시간 실현 가능한 것으로 만든다.
뉴럴 텍스처 압축
뉴럴 텍스처 압축(NTC)은 한 재질의 모든 텍스처 채널을 네트워크로 함께 압축해, 비슷한 시각 품질에서 전통적 블록 압축 대비 최대 8배의 VRAM 절감에 이른다(NVIDIA의 RTX Kit 문서 기준). 현대의 재질은 텍스처 하나가 아니다. 그것은 텍스처들의 묶음(색상, 노멀, 거칠기, 금속성 등)이며, 이 채널들은 각 채널을 독립적으로 짜내는 블록 압축이 버리는 방식으로 서로 상관되어 있다.
NTC는 그 상관을 활용한다. 한 재질의 모든 채널에 걸친 결합 구조를 한 번에 학습함으로써, 같은 재질을 훨씬 적은 메모리에 저장하고 렌더 타임에 즉석에서 디코드한다. 게임이 텍스처 디테일을 밀어붙일수록 VRAM은 지속적인 제약이므로, "같은 메모리에 8배 더 많은 재질을 담는다"는 시각적 눈속임이 아니라 직접적이고 실용적인 이득이다.
뉴럴 셰이더와 DirectX Cooperative Vectors
뉴럴 셰이더는 작은 신경망을 프로그래머블 셰이더(GPU가 이미 실행하는 픽셀별/정점별 프로그램) 안의 실행해, 비싼 계산 효과가 필요한 바로 그 자리에서 네트워크가 그것을 근사할 수 있게 한다. AI를 별도 패스로 덧붙이는 대신, MLP가 GPU의 행렬 유닛(NVIDIA 하드웨어의 Tensor Cores)에서 셰이더의 일부로 돈다.
Tensor Cores는 이 네트워크들이 도는 행렬 연산을 처리한다. 이는 나머지 작업을 처리하는 범용 코어와 구별된다. 뉴럴 셰이더를 단일 벤더 기능에서 더 넓은 산업 역량으로 바꾸는 것은 그 아래의 API 계층이다. Microsoft는 DirectX Cooperative Vectors를 2025년 Shader Model 6.9와 함께 프리뷰로 도입해 HLSL 셰이더 안에서 벡터/행렬 연산을 노출했다. 2026년에는 Shader Model 6.9가 정식으로 넘어갔고, Microsoft는 Cooperative Vector가 Shader Model 6.10에 계획된 더 넓은 선형대수 설계를 위해 폐지되는 중이라고 밝혔다. 안전한 결론은 Cooperative Vectors가 최종 API라는 것이 아니라, DirectX가 벤더 횡단 셰이더 수준 ML 지원으로 나아가고 있다는 것이다.
절 요약: 여섯 기법은 네트워크가 어디에서 도는가로 정렬된다. 프레임 끝에서의 후처리, 레이 트레이싱과 나란한 파이프라인 중간, 또는 셰이더 자체 안. 그 위치가 기법이 실시간으로 돌 수 있는지와 어떤 하드웨어가 필요한지를 결정한다.
무엇이 실시간으로, 어떤 하드웨어에서 도는가
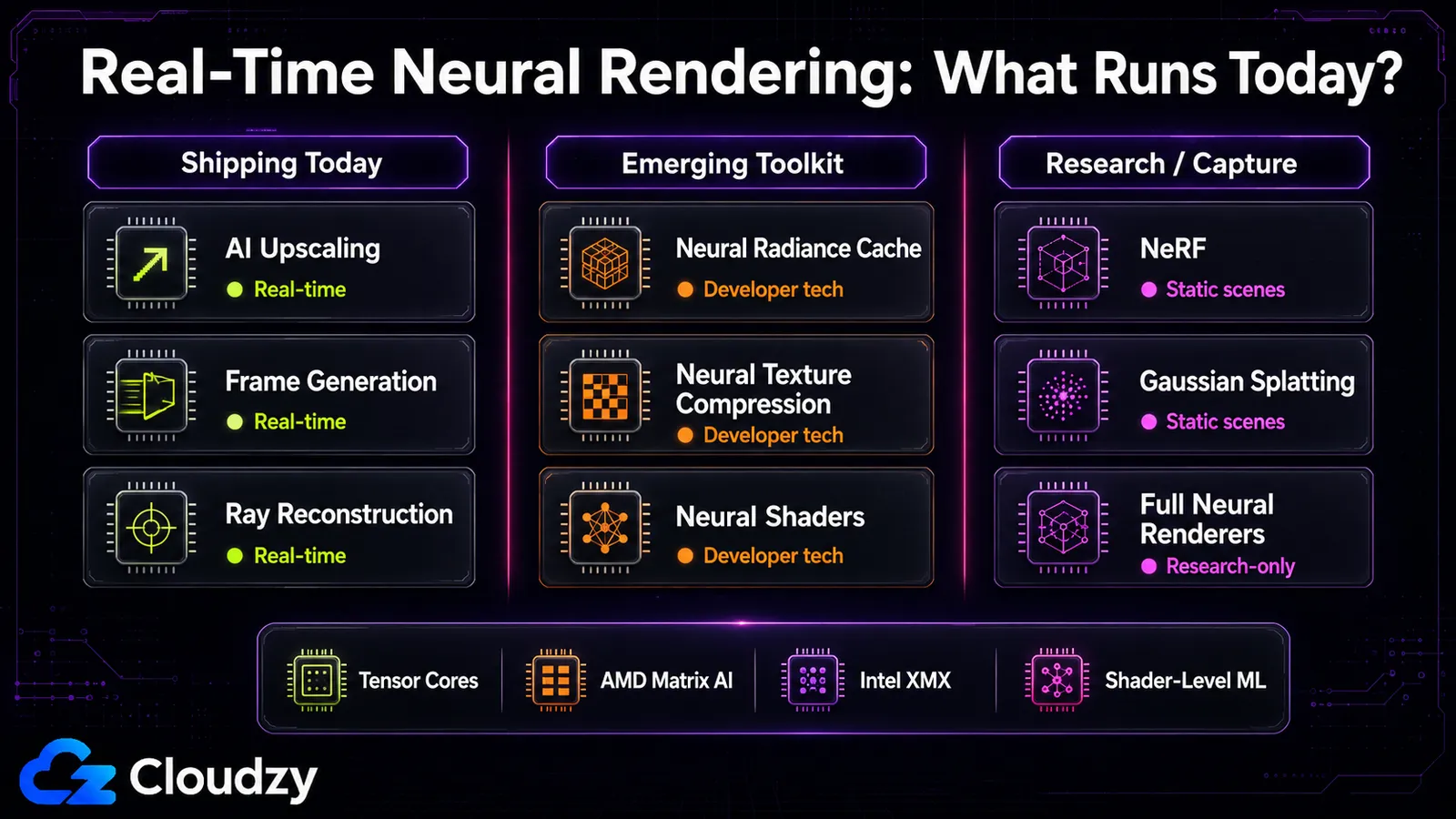
실시간의 경계선은 과대광고가 시사하는 것보다 더 선명하다. AI 업스케일링은 보통 낮은 오버헤드로 돌고, NRC는 약 2.6 ms를 더하며, 3D Gaussian Splatting은 정적 장면에서 실시간에 근접한다. 원본 NeRF와 RenderFormer 같은 완전한 뉴럴 렌더러는 확실히 연구 전용으로, 대화형 사용에는 프레임당 시간이 너무 오래 걸린다. "뉴럴 렌더링은 실시간이다"는 파이프라인 내부 계층에는 참이고 재구성 및 완전 렌더러 계층에는 거짓이다.
그 갈림은 스펙트럼을 정확히 따른다. 일부 파이프라인 내부 구성 요소, 특히 업스케일링, 프레임 생성, Ray Reconstruction은 이미 출시된 게임에서 돈다. NRC, NTC, 뉴럴 셰이더 같은 다른 것들은 흔한 양산 기능이라기보다 개발자 기술과 떠오르는 툴킷 기능으로 묘사하는 편이 낫다. 재구성 계층은 뒤섞여 있다. 원본 NeRF는 느리지만 3D Gaussian Splatting은 실시간을 향한 의도적 추진이었고 정적 장면에서는 거기에 도달한다. 완전 뉴럴 렌더러 계층(단일 네트워크가 이미지 전체를 생성)은 연구가 사는 곳이며 프레임 시간은 대화형과는 거리가 멀다.
하드웨어가 답의 나머지 절반이며, 바로 여기서 벤더 횡단 이야기가 안착한다. 여기 모든 기법은 현대 GPU가 AI 추론을 위해 탑재하는 행렬 연산 유닛에서 돈다.
- NVIDIA 는 20 시리즈 이후 모든 RTX 카드에 Tensor Cores를 두고 있으며, 그래서 이 기법들 대부분이 거기서 데뷔했다.
- AMD의 ML 기반 FSR Upscaling은 현재 ML 경로를 위해 RDNA 4 / Radeon RX 9000 시리즈 GPU를 겨냥한다. 이전 하드웨어에서는 AMD의 SDK가 분석적 FSR 3.1.5 경로로 폴백한다. 구체적인 AMD 발표를 인용하지 않는 한, 더 넓은 구형 GPU 지원은 보장된 FSR 4 기능이 아니라 변동하는 로드맵 항목으로 취급하라.
- Intel 은 XeSS를 위해 Arc GPU에서 XMX 행렬 엔진을 쓴다.
DLSS 자체는 세대별로 기능이 게이팅된다. 업스케일링은 RTX 20 시리즈까지 거슬러 작동하고, 원본 프레임 생성은 RTX 40 시리즈가 필요하며, 멀티 프레임 생성은 RTX 50 시리즈 전용이다. 특정 카드가 무엇을 할 수 있는지 따지려 한다면, 마케팅 등급이 아니라 그 세대 게이팅이 실용적인 답이다.
오늘 쓸 수 있는 것 대 다가오는 것: 업스케일링, 프레임 생성, Ray Reconstruction은 오늘 게임에서 사용 가능하다. RTX Kit 구성 요소 즉 NRC, NTC, 뉴럴 셰이더 같은 것들은 개발자 기술 및 툴링으로 제공되지만, 그것들 전부가 이미 출시 게임에서 흔하다고 암시해서는 안 된다. Gaussian Splatting은 장면 캡처를 위한 쓸 만한 오픈 툴링을 갖추고 있다. 아직 여기 없는 것: 단일 네트워크로 프레임 전체를 그리는 완전한 뉴럴 렌더러, 성숙한 벤더 횡단 뉴럴 셰이더(AMD 지원은 초기 단계), 그리고 DLSS 5의 생성 기능(2026년 가을로 발표됨). 재구성 쪽을 실험하고 싶다면(NeRF나 추론 워크로드를 직접 돌리는 것), 그것은 GPU 컴퓨트 작업이지 게임이 대신 해주는 것이 아니다.
뉴럴 렌더링이 아닌 것: 다섯 가지 오해

대부분의 뉴럴 렌더링 논쟁은 그 주장이 스펙트럼의 어느 계층에 관한 것인지 짚어내면 한결 쉬워진다. 다섯 가지 오해가 거듭 등장한다.
1. "DLSS 업스케일링이 뉴럴 렌더링이다." DLSS는 an 뉴럴 렌더링의 응용, 즉 파이프라인 내부 실시간 계층이지 분야 전체가 아니다. 이 용어는 DLSS보다 먼저 나왔고 NeRF, Gaussian Splatting, 그리고 생성 기법을 포함한다. 둘을 동일시하는 것은 "데이터베이스"를 당신이 마침 쓰는 한 제품의 동의어라고 부르는 것과 같다.
2. "프레임 생성이 게임을 더 빠르게 만든다." 그것은 당신이 보는 프레임 수를 높여 움직임을 더 부드럽게 보이게 하지만, 렌더링 후에 돌고 지연을 더한다. 게임이 당신의 입력에 갱신되고 반응하는 속도는 증가하지 않는다. 경쟁 플레이에는 그 지연이 실질적 절충이고, 시각적 부드러움에는 진짜 이득이다. "더 빠르다"는 그 둘을 뒤섞는다.
3. "DLSS 5는 3D를 인식한다 / 3D 장면을 읽는다." 이것은 가장 바로잡을 가치가 있는데, 기술 보도가 계속 잘못 묘사하기 때문이다. NVIDIA의 설명에 따르면 DLSS 5는 각 프레임의 색상 데이터와 모션 벡터를 입력으로 받고, 학습된 모델을 사용해 캐릭터, 머리카락, 천, 피부, 조명 조건 같은 장면 의미를 추론한다. 그것은 게임의 콘텐츠에 기반하지만, NVIDIA는 그것을 게임의 전체 3D 장면 파일을 직접 읽는 것으로 묘사하지 않는다. "3D 안내(3D-guided)"란 추론이 지오메트리와 일관된다는(표면이 어떻게 움직이고 관계 맺는지를 존중한다는) 뜻이지, 네트워크가 장면 지오메트리를 직접 읽는다는 뜻이 아니다. 이 구분은 그 기법이 무엇을 알 수 있고 알 수 없는지를 한정하기 때문에 중요하다.
4. "NeRF는 이제 실시간이다." 어느 기법을 말하느냐에 달렸는데, 이것이 바로 스펙트럼 문제다. 원본 NeRF는 실시간이 아니다. 3D Gaussian Splatting은 정적 장면에서 실시간에 근접한다. 단일 네트워크로 프레임 전체를 렌더링하는 연구 시스템(RenderFormer 및 유사한 것들)은 전혀 실시간이 아니다. "NeRF"는 속도가 천차만별인 대여섯 가지 방법을 아우르는 포괄어가 되어버렸다.
5. "뉴럴 렌더링이 곧 래스터화를 대체할 것이다." 오늘날 시스템은 하이브리드다. 뉴럴 구성 요소는 안의 래스터화-레이 트레이싱 파이프라인 안에 있지 그것을 대신하는 것이 아니다. 고전 파이프라인을 단일 생성 렌더러로 완전히 대체하는 것은 먼 지평의 연구 목표이지 가까운 시일의 제품 방향이 아니다. "미래는 완전히 뉴럴이다"는 시점이 박힌 예측이 아니라 진행 방향으로 받아들여라.
절 요약: 거의 모든 뉴럴 렌더링 의견 충돌의 단일 근본 원인은 사람들이 스펙트럼의 서로 다른 계층에 같은 단어를 쓰는 것이다. 먼저 그 주장을 스펙트럼 위에 놓으면 논쟁의 대부분이 사라진다.
이것이 향하는 곳
궤적은 위의 모든 것과 일관된다. 오늘은 하이브리드 파이프라인, 더 많은 단계가 계산에서 예측으로 이동, 벤더 횡단 뉴럴 셰이더가 이를 출시할 수 있는 주체를 넓힘, 그리고 완전 뉴럴 렌더러 프런티어는 여전히 수년 후. 다음 소비자 단계는 2026년 가을로 발표된 DLSS 5로, 렌더링된 프레임 사이를 보간하는 데 그치지 않고 게임이 한 번도 계산하지 않은 조명과 재질 디테일을 생성함으로써 생성 뉴럴 렌더링으로 들어간다. NVIDIA는 그 기술을 RTX 50 시리즈 맥락에서 보여주었지만, 최종 소비자 하드웨어 요구 사항은 NVIDIA가 명확한 호환성 목록을 발표할 때까지 미확정으로 취급해야 한다.
앞날 전망에는 두 측면이 있다. 가까운 쪽에서 가장 중요한 수는 어떤 단일 기법이 아니다. 표준화다. Microsoft의 DirectX 경로는 Cooperative Vectors에서 더 넓은 셰이더 수준 선형대수로 옮겨가고 있으며, 이는 엔진이 한 GPU 브랜드에 걸지 않고 뉴럴 방식 워크로드를 겨냥하게 해줄 수 있다. 먼 쪽에서는 NVIDIA 연구자들이 때때로 가설적 "DLSS 10"으로 띄워지는 먼 미래의 종착점을 묘사했는데, 거기서는 렌더러가 완전히 뉴럴이고 고전 파이프라인은 사라진다(Digital Foundry 라운드테이블에서 간접적으로 전해진 것이니 로드맵이 아니라 표명된 방향으로 취급하라). 사다리의 종착점은 세계를 그리는 것이 아니라 일관된 세계를 생성하는 시스템이다.
그래도 회의는 유지할 가치가 있다. 생성된 디테일은 예술적 의도에서 벗어날 수 있고, 네트워크는 디버깅할 전통적 대응물이 없는, 그럴듯하지만 틀린 비주얼을 환각할 수 있다. 이는 GDC 2026에서 제기된 QA 문제이자, "AI 슬롭" 반응 상당 부분의 실체다. 그래픽이 향하는 곳을 위해 만든다는 것이 현재 출력이 완성됐다고 가장하는 것을 뜻하지는 않는다. 그것은 어느 단계가 다음으로 계산에서 예측으로 이동하는지 지켜보고, 각각을 거기 붙은 단어가 아니라 그것이 이미지에 무엇을 하는지로 판단하는 것을 뜻한다.
자주 묻는 질문
DLSS는 뉴럴 렌더링인가?
그렇다, 다만 한 종류일 뿐이다. DLSS는 뉴럴 렌더링의 응용, 구체적으로 AI 업스케일링과 프레임 생성을 아우르는 실시간 파이프라인 내부 계층이다. 더 넓은 용어는 DLSS보다 먼저 나왔고 NeRF와 Gaussian Splatting 같은 장면 재구성 방법과 새로운 이미지 디테일을 만들어내는 생성 방법도 포함한다. 그러므로 모든 DLSS 기능은 뉴럴 렌더링이지만, 많은 뉴럴 렌더링은 DLSS가 아니다.
뉴럴 렌더링과 레이 트레이싱의 차이는 무엇인가?
레이 트레이싱은 시뮬레이션한다 광선이 장면을 어떻게 튕기는지 계산해 빛을. 뉴럴 렌더링은 그것들을 계산하는 대신 학습된 네트워크로부터 결과를 예측합니다 한다. 둘은 경쟁자가 아니다. 결합한다. 예컨대 Ray Reconstruction은 신경망을 사용해 노이즈가 많은 레이 트레이싱 출력을 디노이즈하고, 뉴럴 라디언스 캐시는 튕긴 빛을 예측해 레이 트레이서가 일찍 멈출 수 있게 한다. 뉴럴 기법은 레이 트레이싱을 실시간에서 감당할 만하게 만든다.
DLSS 프레임 생성은 지연을 더하는가?
그렇다. 프레임 생성은 프레임이 렌더링된 후에 돌며 렌더링된 프레임 사이에 예측 프레임을 끼워 넣으므로, 지연을 없애는 것이 아니라 더한다. NVIDIA의 Reflex 2는 바로 이를 보상하기 위해 존재한다. 그것은 게임이 입력에 갱신되고 반응하는 속도를 높이지 않으면서 체감 부드러움(표시되는 프레임 증가)을 높인다. 경쟁 플레이에는 절충이고, 싱글플레이어 부드러움에는 보통 순이득이다.
NeRF는 실시간인가?
어느 기법을 말하느냐에 달렸다. 원본 NeRF는 실시간이 아니다. 이후 방법인 3D Gaussian Splatting은 정적 장면에서 실시간에 근접한다. 단일 네트워크로 프레임 전체를 그리는 완전한 뉴럴 렌더러는 연구 전용이며 대화형 속도와는 거리가 멀다. "NeRF"는 성능이 매우 다른 여러 방법을 아우르는 데 느슨하게 쓰이는 일이 잦으며, 이것이 대부분 혼란의 원천이다.
뉴럴 렌더링이 래스터화를 대체할 것인가?
곧은 아니다. 오늘날 시스템은 하이브리드다. 뉴럴 구성 요소는 래스터화-레이 트레이싱 파이프라인을 대체하는 것이 아니라 그 안에서 돈다. 고전 파이프라인 전체를 단일 생성 렌더러로 대체하는 것은 먼 지평의 연구 목표이지 가까운 제품이 아니다. 현실적 방향은 시간이 지나며 더 많은 파이프라인 단계가 계산에서 예측으로 이동하는 것이며, 래스터화는 앞으로 수년간 여전히 실질적 일을 한다.
뉴럴 텍스처 압축이란 무엇인가?
뉴럴 텍스처 압축(NTC)은 한 재질의 모든 텍스처 채널(색상, 노멀, 거칠기 등)을 함께 압축하는 뉴럴 방법으로, 비슷한 시각 품질에서 전통적 블록 압축 대비 최대 8배의 VRAM 절감에 이른다(NVIDIA 기준). 이것은 각 채널을 따로 짜내는 블록 압축이 버리는 채널 간 상관을 학습함으로써 작동한다. 압축된 재질은 렌더 타임에 즉석에서 디코드된다.


