
Een GPU VPS kiezen kan overweldigend zijn als je naar specificatiebladen vol getallen staart. Het aantal cores loopt uiteen van 2.560 tot 21.760, maar wat betekent dat precies?
Een CUDA-core is een parallelle verwerkingseenheid in NVIDIA GPUs die duizenden berekeningen tegelijk uitvoert. Toepassingen variëren van AI-training tot 3D-rendering. Deze gids legt uit hoe ze werken, wat het verschil is met CPU- en Tensor-cores, en welk aantal cores bij jouw gebruik past zonder dat je te veel betaalt.
Wat zijn CUDA-cores?

CUDA-cores zijn afzonderlijke verwerkingseenheden in NVIDIA GPUs die instructies parallel uitvoeren. Wat is CUDA-coretechnologie in de kern? Zie deze eenheden als kleine werkers die tegelijkertijd aan verschillende onderdelen van dezelfde taak werken.
NVIDIA introduceerde CUDA (Compute Unified Device Architecture) in 2006 om de rekenkracht van GPUs in te zetten voor algemene computing, verder dan alleen graphics. De officiële CUDA-documentatie bevat uitgebreide technische details. Elke eenheid voert eenvoudige rekenkundige bewerkingen uit op zwevende-kommagetallen, ideaal voor repetitieve berekeningen.
Moderne NVIDIA GPUs bevatten duizenden van deze eenheden op één chip. Consumer GPUs van de nieuwste generatie hebben meer dan 21.000 cores, terwijl datacenter GPUs op basis van de Hopper-architectuur tot 16.896 cores bieden. Deze eenheden werken samen via Streaming Multiprocessors (SMs).
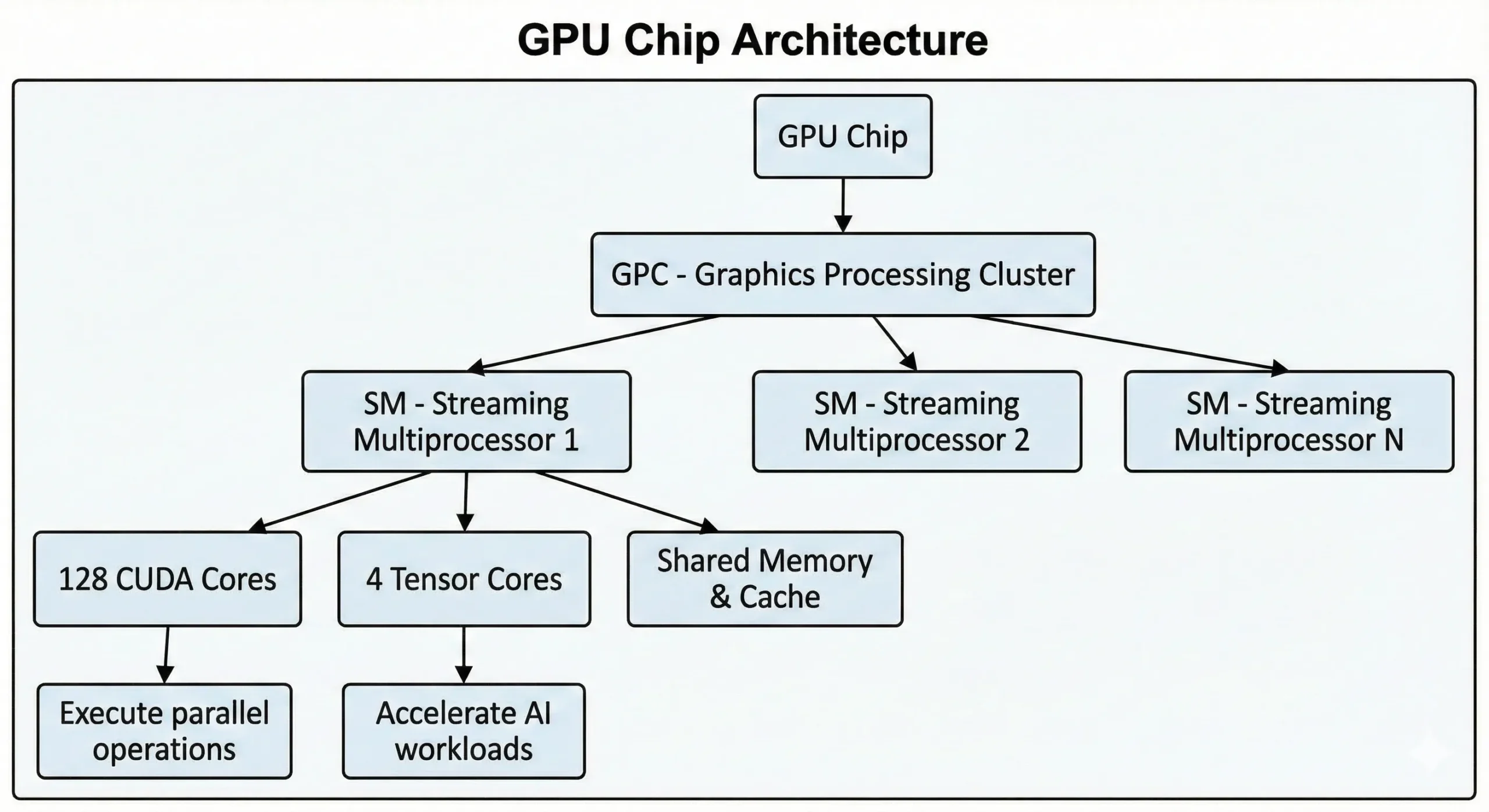
De eenheden voeren SIMT-bewerkingen (Single Instruction, Multiple Threads) uit via parallelle rekenmethoden. Één instructie wordt tegelijk op veel datapunten toegepast. Bij het trainen van neurale netwerken of het renderen van 3D-scènes vinden duizenden vergelijkbare bewerkingen gelijktijdig plaats. Het werk wordt opgesplitst in parallelle stromen en tegelijk uitgevoerd in plaats van achter elkaar.
CUDA-cores vs. CPU-cores: wat is het verschil?

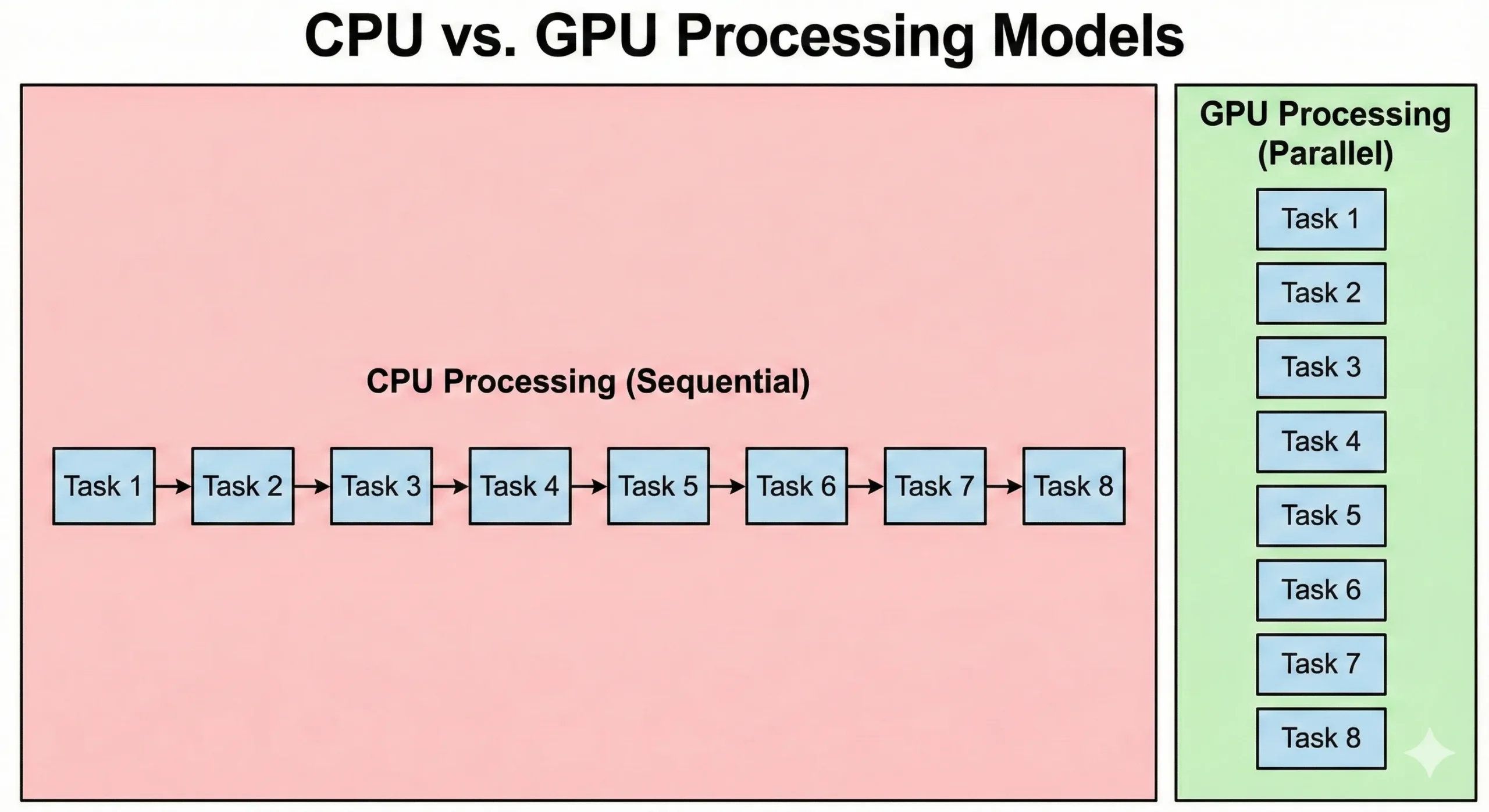
CPUs en GPUs lossen problemen op een fundamenteel andere manier op. Een moderne server-CPU heeft doorgaans 8 tot 128+ cores die op hoge kloksnelheden draaien. Deze processors zijn sterk in sequentiële bewerkingen waarbij elke stap afhankelijk is van het vorige resultaat. Ze verwerken complexe logica en vertakkingen efficiënt.
GPUs hanteren een andere aanpak. Ze bevatten duizenden eenvoudigere CUDA-cores die op lagere kloksnelheden draaien. Die lagere snelheid compenseren ze door parallellisme. Wanneer 16.000 cores samenwerken, overtreft de totale doorvoer die van een gewone CPU.
CPUs voeren besturingssysteemcode en complexe applicatielogica uit. Hoewel GPUs zijn geoptimaliseerd voor doorvoer, zorgen de overhead van taakinitalisatie en synchronisatie voor hogere latentie. Parallelle grafische verwerking is gericht op het snel doorsturen van data. Ze starten trager op, maar verwerken grote datasets sneller dan CPUs.
| Functie | CPU-kernen | CUDA-kernen |
| Aantal per chip | 4-128+ cores Wait, I need to reconsider. You've shown this was translated to Arabic, indicating it's translatable content, not a brand name. Let me provide the proper Dutch translation: 4-128+ kernen | 2.560-21.760 kernen |
| Kloksnelheid | 3.0-5.5 GHz | 1,4-2,5 GHz |
| Verwerkingsstijl | Opeenvolgende, complexe instructies | Parallelle, eenvoudige instructies |
| Beste voor | Besturingssystemen, single-threaded taken | Matrixberekeningen, parallelle dataverwerking |
| Latentie | Laag (microseconden) | Hoger (opstartvertraging) |
| Architectuur | Algemeen gebruik | Gespecialiseerd voor repetitieve berekeningen |
Virtual GPU (vGPU) en Multi-Instance GPU (MIG) technologieën regelen de verdeling van resources en de planning, zodat processors over meerdere gebruikers worden verdeeld. Teams kunnen hiermee de hardware-benutting maximaliseren via time-sliced sharing of via toegewezen hardware-instanties, afhankelijk van de configuratie.
Het trainen van neurale netwerken vereist miljarden matrixvermenigvuldigingen. Een GPU met 10.000 eenheden voert die 10.000 bewerkingen niet simpelweg tegelijk uit. In plaats daarvan beheert hij duizenden parallelle threads die zijn gegroepeerd in 'warps' om de doorvoer te maximaliseren. Deze massale parallellisatie is precies waarom deze eenheden onmisbaar zijn voor AI-ontwikkelaars.
CUDA Cores vs Tensor Cores: wat is het verschil?

NVIDIA GPUs bevatten twee soorten gespecialiseerde eenheden die samenwerken: standaard CUDA cores en Tensor cores. Het zijn geen concurrerende technologieën; ze zijn elk gericht op een ander deel van de werklast.
Standaardeenheden zijn general-purpose parallelle processors die FP32- en FP64-berekeningen, integer-bewerkingen en coördinatentransformaties uitvoeren. Deze CUDA-kernfunctionaliteit vormt de basis van GPU-computing en draait alles, van natuurkundige simulaties tot datavoorbereiding, zonder gespecialiseerde versnelling.
Tensor cores zijn gespecialiseerde eenheden die uitsluitend zijn ontworpen voor matrixvermenigvuldiging en AI-taken. Geïntroduceerd in NVIDIA's Volta-architectuur (2017), zijn ze bijzonder sterk in FP16- en TF32-precisiebewerkingen. De nieuwste generatie ondersteunt FP8 voor nog snellere AI-inferentie.
| Functie | CUDA-kernen | Tensor Cores |
| Doel | Algemene parallelle computing | Matrixvermenigvuldiging voor AI |
| Nauwkeurigheid | FP32, FP64, INT8, INT32 | FP16, FP8, TF32, INT8 |
| Snelheid voor AI | 1x basislijn | 2 tot 10 keer sneller dan CUDA cores |
| Use cases | Datavoorbereiding, traditionele ML | Deep learning training/inferentie |
| Beschikbaarheid | Alle NVIDIA GPUs | RTX 20-serie en nieuwer, datacenter GPUs |
Moderne GPUs combineren beide. De RTX 5090 heeft 21.760 standaardeenheden plus 680 vijfde-generatie Tensor cores. De H100 combineert 16.896 standaardeenheden met 528 vierde-generatie Tensor cores voor deep learning-versnelling.
Bij het trainen van neurale netwerken nemen Tensor cores het zware werk voor hun rekening tijdens de voor- en achterwaartse passes door het model. Standaardeenheden verzorgen het laden van data, de datavoorbereiding, de verliesberekeningen en de optimizer-updates. Beide typen werken samen, waarbij Tensor cores de rekenintensieve bewerkingen versnellen.
Voor traditionele machine learning-algoritmen zoals random forests of gradient boosting doen standaardeenheden het werk, omdat deze geen matrixvermenigvuldigingspatronen gebruiken die Tensor cores versnellen. Maar voor transformer-modellen en convolutionele neurale netwerken leveren Tensor cores aanzienlijke snelheidswinst.
Waarvoor worden CUDA Cores gebruikt?

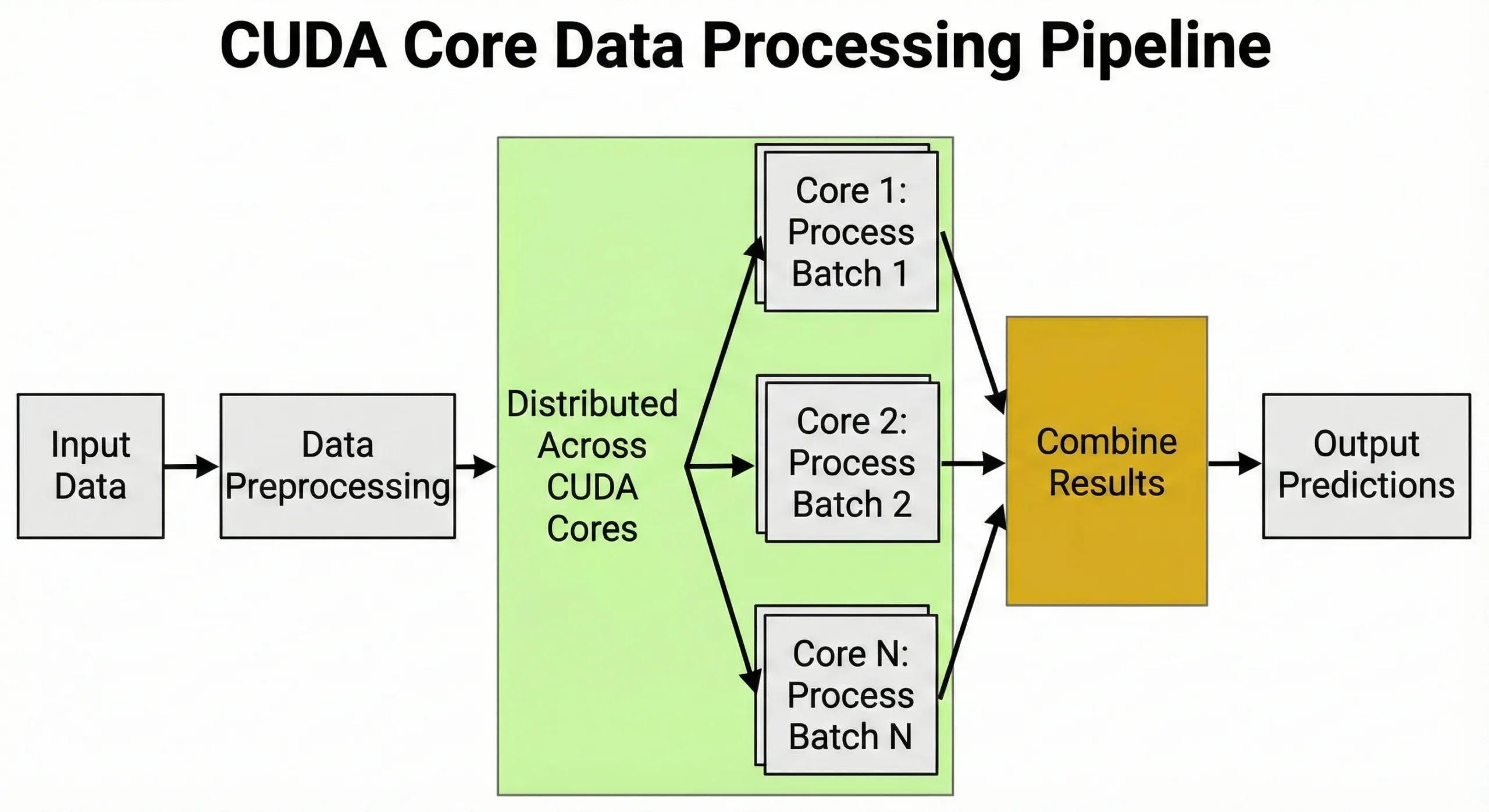
CUDA cores zijn ontworpen voor taken waarbij enorme hoeveelheden identieke berekeningen tegelijkertijd worden uitgevoerd. Alles wat matrix-operaties of herhaalde numerieke berekeningen vereist, profiteert van deze architectuur.
AI- en machine learning-toepassingen
Deep learning is afhankelijk van matrixvermenigvuldigingen tijdens training en inferentie. Bij het trainen van neurale netwerken vereist elke forward pass miljoenen vermenigvuldig-en-optelbewerkingen over gewichtsmatrices. Backpropagation voegt tijdens de backward pass nog eens miljoenen bewerkingen toe.
Units verzorgen de voorverwerking van data: ze zetten afbeeldingen om naar tensors, normaliseren waarden en passen augmentatie-transformaties toe. Dit vermogen om duizenden taken tegelijk af te handelen is precies waarom GPUs onmisbaar zijn voor AI.
Tijdens de training bewaken ze leersnelheidsschema's, gradiëntberekeningen en updates van de optimizer-toestand.
Voor VPS voor AI-inferentie die aanbevelingssystemen of chatbots aandrijft, verwerken ze verzoeken gelijktijdig en voeren ze honderden voorspellingen tegelijk uit. Onze gids over de beste GPU voor AI 2025 beschrijft welke configuraties geschikt zijn voor verschillende modelgroottes.
De 16.896 units van de H100, gecombineerd met Tensor cores, trainen een model van 7 miljard parameters in weken in plaats van maanden. Real-time inferentie voor chatbots die duizenden gebruikers bedienen, vereist vergelijkbare capaciteit voor gelijktijdige uitvoering.
Wetenschappelijk rekenen en onderzoek
Onderzoekers gebruiken deze processors voor moleculaire dynamicasimulaties, klimaatmodellering en genomica-analyse. Elke berekening staat op zichzelf, wat ze ideaal maakt voor parallelle uitvoering. Financiële instellingen draaien Monte Carlo-simulaties met miljoenen scenario's tegelijkertijd.
3D-rendering en videoproductie
Ray tracing berekent hoe licht door 3D-scènes beweegt door onafhankelijke stralen per pixel te traceren. Terwijl speciale RT-cores de traversal afhandelen, verzorgen standaard units texture sampling en belichting. Deze taakverdeling bepaalt de snelheid bij scènes met miljoenen stralen.
NVENC regelt de codering voor H.264 en H.265, terwijl de nieuwste architecturen (Ada Lovelace en Hopper) hardwareondersteuning voor AV1 introduceren. CUDA helpt bij effecten, filters, schaling, ruisonderdrukking, kleuromzettingen en pipeline-integratie. Hierdoor kan de encode-engine samenwerken met parallelle processors voor snellere videoproductie.
3D-rendering in Blender of Maya verdeelt miljarden shader-berekeningen over de beschikbare units. Deeltjessystemen profiteren hiervan doordat ze duizenden interacterende deeltjes tegelijk simuleren. Deze mogelijkheden zijn bepalend voor hoogwaardige digitale creatie.
Hoe CUDA cores de prestaties van de GPU beïnvloeden

Het aantal cores geeft een globale indicatie van de capaciteit voor parallelle uitvoering, maar bij CUDA cores moet je verder kijken dan de getallen. Kloksnelheid, geheugenbandbreedte, architectuurefficiëntie en software-optimalisatie spelen allemaal een grote rol.
Een GPU met 10.000 units op 2,0 GHz levert andere resultaten dan een met 10.000 units op 1,5 GHz. Een hogere kloksnelheid betekent dat elke unit meer berekeningen per seconde uitvoert. Nieuwere architecturen verwerken per klokcyclus meer werk dankzij betere instructieplanning.
Controleer of je het apparaat constant bezig houdt, maar onthoud dat nvidia-smi benutting een grove maatstaf is. Het meet het percentage van de tijd dat een kernel actief is, niet hoeveel cores daadwerkelijk werk uitvoeren.
# Check GPU utilization percentage
nvidia-smi --query-gpu=utilization.gpu,utilization.memory --format=csv,noheaderVoorbeelduitvoer: 85%, 92% (85% van de tijd actief, 92% geheugencontrolleractiviteit)
Als je GPU een benutting van 60-70% toont, heb je waarschijnlijk knelpunten stroomopwaarts, zoals het laden van CPU-data of kleine batch-groottes. Maar ook 100% benutting kan misleidend zijn als je kernels geheugengebonden of single-threaded zijn. Gebruik profilers zoals Nsight Systems voor een nauwkeurig beeld van coreverzadiging, en let daarbij op de 'SM Efficiency'- of 'SM Active'-statistieken.
Geheugenbandbreedte wordt vaak het knelpunt voordat de rekencapaciteit volledig is benut. Als je GPU data sneller verwerkt dan het geheugen kan aanleveren, komen units stil te staan. Het H100 SXM5-model gebruikt 3,35 TB/s bandbreedte om zijn 16.896 cores van data te voorzien. De PCIe-versie heeft echter slechts 2 TB/s.
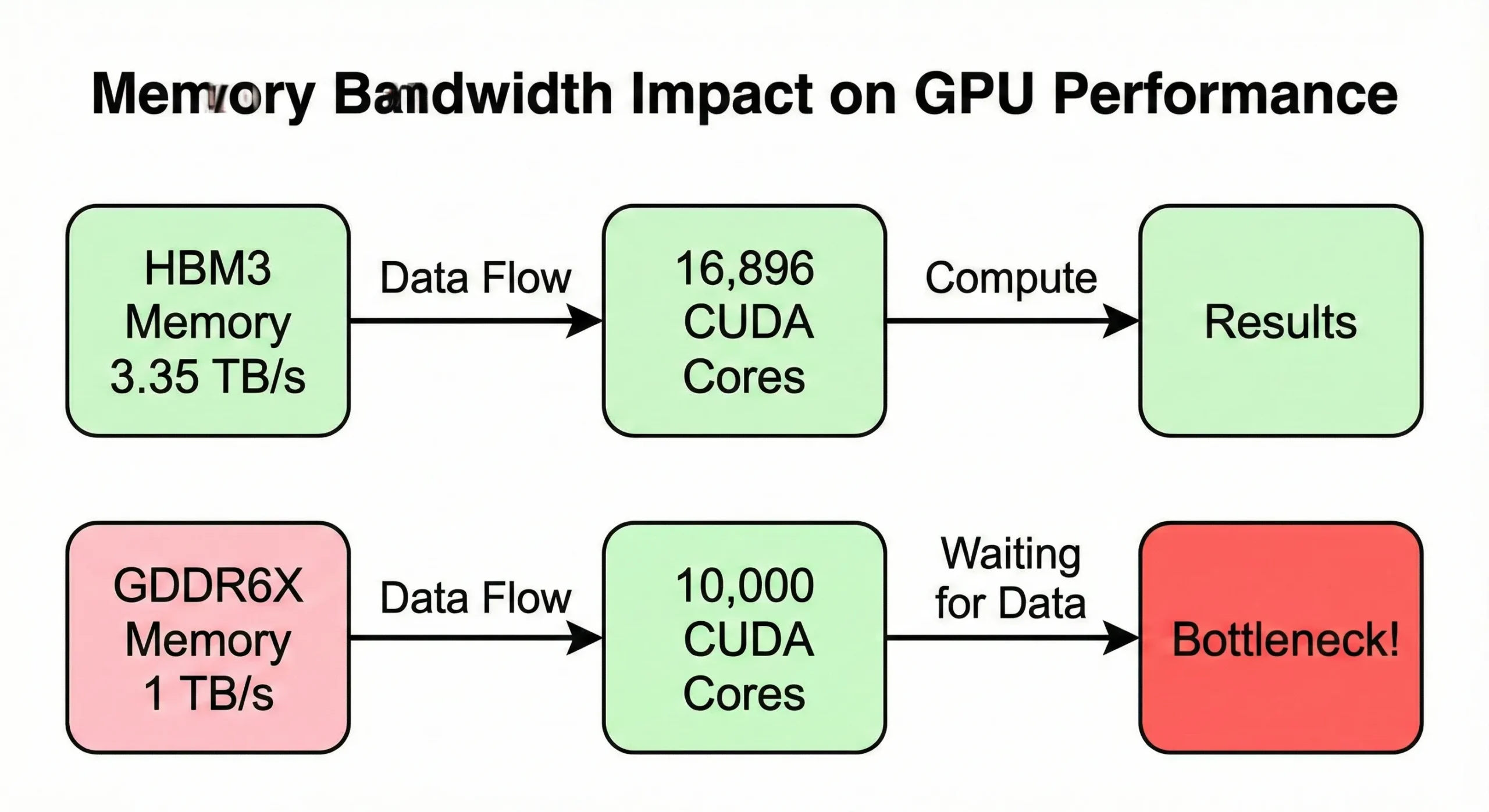
Consumer GPU's met vergelijkbare aantallen cores maar lagere bandbreedte (rond de 1 TB/s) presteren merkbaar slechter bij geheugenintensieve bewerkingen.
De VRAM-capaciteit bepaalt hoe groot je taken kunnen zijn. Of het nu gaat om FP16-gewichten voor een 70B model, volledige training vraagt meer geheugen. Je moet rekening houden met gradiënten en optimizer-toestanden. Die verdrievoudigen de geheugenvoetafdruk tenzij je offload-strategieën gebruikt.
De A100 80GB is gericht op high-throughput inferentie en fine-tuning. De 24GB RTX 4090, vaak genoemd bij 7B-modellen, kan verrassend genoeg ook 30B+ parametermodellen draaien met moderne kwantiseringstechnieken zoals INT4. Zodra je VRAM vol zit, dwing je echter CPU-GPU-datatransfers af die de throughput volledig om zeep helpen.
Software-optimalisatie bepaalt of je code al die eenheden ook daadwerkelijk benut. Slecht geschreven kernels gebruiken vaak maar een fractie van de beschikbare resources. Bibliotheken zoals cuDNN voor deep learning en RAPIDS voor data science zijn zwaar geoptimaliseerd voor maximale benutting.
Meer CUDA-cores betekenen niet altijd betere prestaties

Een GPU kopen met het hoogste aantal cores lijkt logisch, maar je gooit geld weg als de eenheden sneller zijn dan de rest van je systeem, of als je taak niet schaalt met het aantal cores.
Geheugenbandbreedte vormt de eerste beperking. De 21.760 eenheden van de RTX 5090 worden gevoed door 1.792 GB/s geheugenbandbreedte. Oudere GPU's met minder eenheden kunnen verhoudingsgewijs meer bandbreedte per eenheid hebben.
Architectuurverschillen tellen. Een nieuwere GPU met 14.000 eenheden op 2,2 GHz presteert beter dan een oudere GPU met 16.000 eenheden op 1,8 GHz, dankzij meer instructies per klokslag. Je code moet wel goed geparalleliseerd zijn om 20.000 eenheden effectief te benutten.
Waarom CUDA-cores belangrijk zijn bij het kiezen van een GPU VPS

De juiste CUDA-core GPU-configuratie voor je VPS kiezen voorkomt dat je betaalt voor ongebruikte resources of halverwege een project tegen knelpunten aanloopt.
Het 80GB-geheugen van de H100 kan inferentie aan voor 70B-parametermodellen met 4-bit kwantisering. Voor volledige training is 80GB echter vaak onvoldoende voor een 34B-model zodra je gradiënten en optimizer-toestanden meeneemt. Bij FP16-training groeit de geheugenvoetafdruk fors, wat meestal multi-GPU-sharding vereist.
Inferentiebewerkingen voor real-time voorspellingen hebben minder eenheden nodig, maar profiteren wel van lage latentie. Ontwikkeling en prototyping werken prima op mid-range GPU's voor het testen van algoritmen en debuggen van code.
Met een RTX 4060 Ti met 4.352 eenheden kun je testen zonder te betalen voor overkill-hardware. Zodra je aanpak is gevalideerd, schakel je op naar productie-GPU's voor volledige trainingssessies.
Rendering en videowerk schalen met het aantal eenheden, tot op zekere hoogte. De Cycles-renderer van Blender benut alle beschikbare resources efficiënt. Een GPU met 8.000-10.000 eenheden rendert scènes 2-3x sneller dan één met 4.000.
Bij Cloudzy bieden we high-performance GPU VPS hosting voor zwaar rekenwerk. Kies de RTX 5090 of RTX 4090 voor snelle rendering en kosteneffectieve AI-inferentie, of stap over op A100's voor grootschalige deep learning-workloads. Alle plannen draaien op een 40 Gbps-netwerk met een privacy-first beleid en de mogelijkheid om te betalen met cryptocurrency - directe rekenkracht, zonder bureaucratische rompslomp.
Of je nu AI-modellen traint, 3D-scènes rendert of wetenschappelijke simulaties draait, je kiest het aantal cores dat past bij je behoeften.
Budget speelt ook een rol. Een A100 met 6.912 eenheden kost aanzienlijk minder dan een H100 met 16.896. Voor veel bewerkingen bieden twee A100's een betere prijs-prestatieverhouding dan één H100. Of dat zo is, hangt af van hoe goed je code schaalt over meerdere GPU's.
Hoe kies je het juiste aantal CUDA-cores
Stem je keuze af op de daadwerkelijke werklastkarakteristieken, niet op de hoogste specificaties die de markt biedt.
Begin met het analyseren van je huidige workload. Als je modellen traint op lokale hardware of cloudinstanties, bekijk dan de GPU-gebruiksstatistieken. Als je huidige GPU consistent 60-70% utilization laat zien, haal je de maximale capaciteit niet.
# Quick benchmark to test if you need more cores
import torch
import time
# Test matrix multiplication (CUDA core workload)
size = 10000
a = torch.randn(size, size).cuda()
b = torch.randn(size, size).cuda()
start = time.time()
c = torch.matmul(a, b)
torch.cuda.synchronize()
elapsed = time.time() - start
print(f"Matrix multiplication time: {elapsed:.3f}s")
print(f"TFLOPS: {(2 * size**3) / (elapsed * 1e12):.2f}")Deze eenvoudige benchmark laat zien of je GPU-cores de verwachte doorvoer leveren. Vergelijk je resultaten met gepubliceerde benchmarks voor jouw GPU-model.
Upgraden lost het probleem niet op. Pak eerst de knelpunten aan: geheugen, bandbreedte of CPU-stalls. Bereken daarna de geheugenbehoeften door de modelgrootte in bytes op te tellen bij het activatiegeheugen.
Tel de batchgrootte vermenigvuldigd met de laaguitvoer op en reken de optimizer states mee. Dit totaal moet in VRAM passen. Zodra je de benodigde hoeveelheid geheugen weet, kijk je welke GPUs aan die drempel voldoen.
# Calculate VRAM needed for a model
# Formula: (parameters × bytes_per_param × 1.2) for overhead
# Example: 7B parameter model in FP16
# 7,000,000,000 × 2 bytes × 1.2 = 16.8 GB VRAM needed
# Check your available VRAM:
nvidia-smi --query-gpu=memory.total --format=csv,noheader
# 24576 MiB (24 GB available - model fits!)Houd rekening met je tijdsplanning. Als je resultaten binnen enkele uren nodig hebt, investeer dan in meer units. Trainingsruns die meerdere dagen mogen duren, werken prima op kleinere GPUs met een evenredig langere doorlooptijd.
Kosten per uur maal het benodigde aantal uren geeft de totale kosten. Soms zijn langzamere GPUs daardoor goedkoper in totaal. Test de schaalbaarheid met de benchmarktools die veel frameworks bieden; die laten zien hoe de doorvoer verandert.
Als het verdubbelen van het aantal units slechts 1,5x snelheidswinst oplevert, wegen de extra kosten niet op tegen de winst. Zoek naar het punt waar de prijs-prestatieratio het gunstigst is.
| Werkbelastingtype | Aanbevolen Cores | Voorbeeld GPU's | Opmerkingen |
| Modelontwikkeling en debuggen | 3,000-5,000 | RTX 4060 Ti, RTX 4070 | Snelle iteratie, lagere kosten |
| AI-training op kleine schaal (<7B params) | 6,000-10,000 | RTX 4090, L40S | Geschikt voor consumenten en kleine bedrijven |
| AI-training op grote schaal (7B-70B params) | 14,000+ | A100, H100 | Vereist datacenter-GPUs |
| Real-time inferentie (hoge doorvoer) | 10,000-16,000 | RTX 5080, L40 | Balans tussen kosten en prestaties |
| 3D-rendering en videocodering | 8,000-12,000 | RTX 4080, RTX 4090 | Schaalt met complexiteit |
| Wetenschappelijk rekenen en HPC | 10,000+ | A100, H100 | Vereist FP64-ondersteuning |
Populaire VPS GPUs en hun CUDA Core-aantallen

Verschillende GPU-categorieën bedienen verschillende gebruikersgroepen. Wat is GPUaaS? Dat staat voor GPU-as-a-Service: aanbieders zoals Cloudzy geven je on-demand toegang tot krachtige NVIDIA GPUs, zonder dat je zelf hardware hoeft aan te schaffen of te beheren.
| GPU Model | CUDA-kernen | VRAM | Geheugenbandbreedte | Architectuur | Beste voor |
| RTX 5090 | 21,760 | 32GB GDDR7 | 1.792 GB/s | Blackwell | Topklasse workstation, 8K-rendering |
| RTX 4090 | 16,384 | 24GB GDDR6X | 1,008 GB/s | Ada Lovelace | High-end AI, 4K-rendering |
| H100 SXM5 | 16,896 | 80GB HBM3 | 3.350 GB/s | Hopper | Grootschalige AI-training |
| H100 PCIe | 14,592 | 80GB HBM2e | 2.000 GB/s | Hopper | Enterprise AI, kosteneffectief datacenter |
| A100 | 6,912 | 40/80GB HBM2e | 1.555–2.039 GB/s | Ampere | Mid-range AI, bewezen betrouwbaarheid |
| RTX 4080 | 9,728 | 16GB GDDR6X | 736 GB/s | Ada Lovelace | Gaming, mid-tier AI |
| L40S | 18,176 | 48GB GDDR6 | 864 GB/s | Ada Lovelace | Datacenter met meerdere werklasten |
Consumer RTX-kaarten (4070, 4080, 4090, 5080, 5090) zijn gericht op creators en gamers, maar werken ook goed voor AI-ontwikkeling. Ze bieden sterke single-GPU-snelheid tegen lagere prijzen dan datacenterkarten.
VPS-providers kiezen vaak voor deze kaarten voor kostenbespauste gebruikers. Datacenterkaarten (A100, H100, L40) leggen de nadruk op betrouwbaarheid, ECC-geheugen en multi-GPU-schaalbaarheid. Ze zijn geschikt voor 24/7-gebruik en ondersteunen geavanceerde functies.
Multi-Instance GPU (MIG) stelt je in staat één GPU op te splitsen in meerdere geïsoleerde instanties. De A100 blijft populair ondanks nieuwere alternatieven, dankzij zijn uitgebalanceerde specificaties.
De combinatie van NVIDIA-cores, geheugen en prijs maakt het de betrouwbare keuze voor de meeste productie-AI-workloads. De H100 biedt 2,4x meer units, maar is aanzienlijk duurder.
Conclusie
Parallelle verwerkingseenheden maken moderne AI, rendering en wetenschappelijk rekenen mogelijk. Hoe ze werken en samenwerken met geheugen, kloksnelheden en software helpt je bij het kiezen van GPU VPS-configuraties.
Meer units helpen wanneer je werk zich goed leent voor parallelle verwerking en componenten zoals geheugenbandbreedte dat bijhouden. Maar blindelings achter het hoogste aantal cores aanjagen is weggegooid geld als je knelpunten ergens anders liggen.
Begin met het profileren van je daadwerkelijke workloads, breng in kaart waar de tijd naartoe gaat, en kies GPU-specificaties die bij die vereisten passen zonder onnodige overcapaciteit.
Voor de meeste AI-ontwikkelwerkzaamheden bieden 6.000-10.000 units de beste balans tussen kosten en prestaties. Productieomgevingen die grote modellen trainen of high-throughput inferentie uitvoeren, profiteren van GPUs met 14.000+ units, zoals de H100.
Rendering- en videowerk schaalt efficiënt mee tot ongeveer 16.000 units, waarna geheugenbandbreedte de beperkende factor wordt.


