
Один из ключевых — если не самый важный — аспектов машинного обучения: получение точных и надёжных предсказаний. Один из перспективных подходов к этой задаче, завоевавший широкое признание, — бэггинг (Bootstrap Aggregating). В этой статье мы разберём, что такое бэггинг в машинном обучении, сравним бэггинг и бустинг, рассмотрим пример классификатора на основе бэггинга, объясним, как работает этот метод, и оценим его преимущества и недостатки.
Что такое бэггинг в машинном обучении?
Это единственные два актуальных изображения из популярных статей; одно или оба можно использовать (одно здесь, другое в другом месте), если Design сделает их версии в стиле Cloudzy.
Что такое бэггинг?
Представьте, что вы пытаетесь угадать вес предмета, спрашивая оценки у нескольких человек. Каждый ответит по-разному, но если усреднить все оценки, результат окажется точнее любого отдельного ответа. В этом и суть бэггинга: объединить предсказания нескольких моделей, чтобы получить более точный и устойчивый результат.
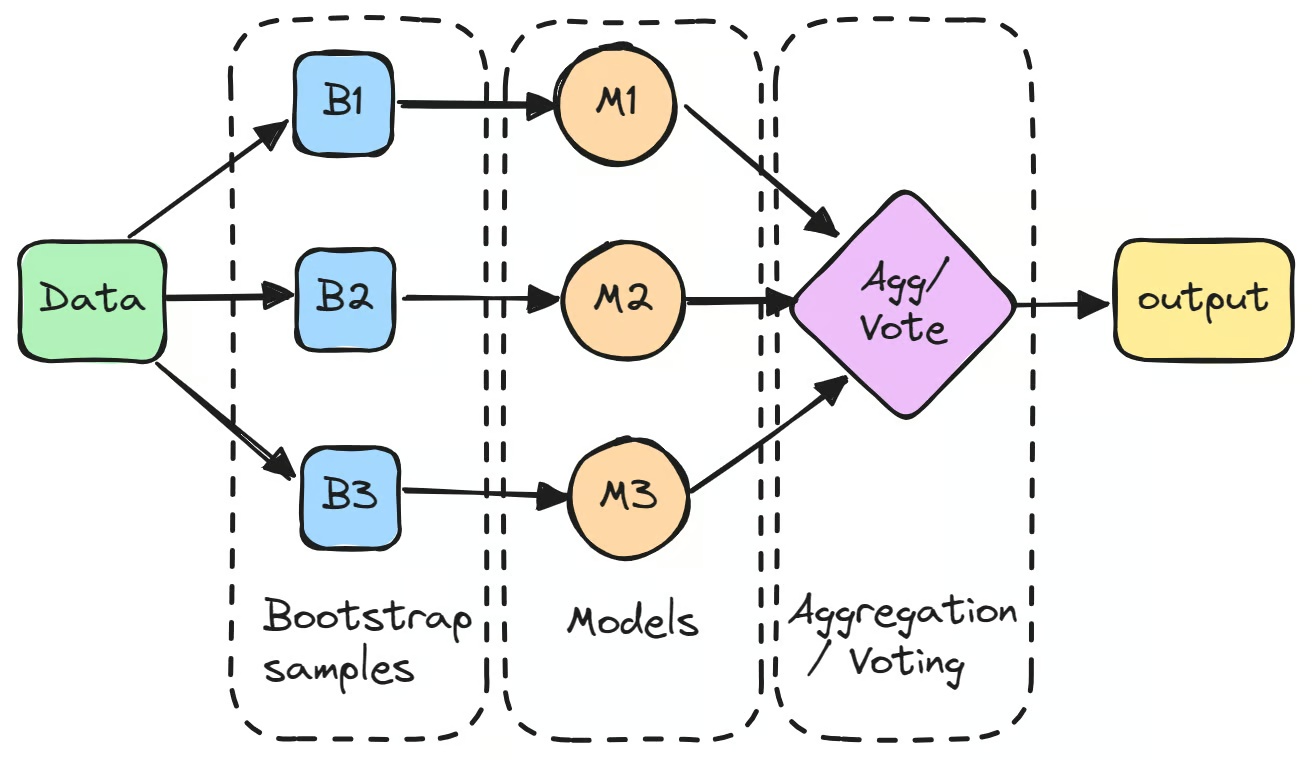
Процесс начинается с формирования нескольких подвыборок из исходного датасета методом бутстрэпинга — случайной выборки с возвращением. На каждой подвыборке обучается отдельная модель независимо от остальных.
Такие модели часто называют «слабыми обучающимися»: по отдельности они работают недостаточно хорошо из-за высокой дисперсии. Однако при агрегировании предсказаний — усреднении для задач регрессии или голосованием большинства для задач классификации — итоговый результат нередко превосходит любую из моделей в отдельности.
Классический пример бэггинг-классификатора — алгоритм Random Forest, который строит ансамбль деревьев решений для повышения качества предсказаний. Важно не путать бэггинг с бустингом в машинном обучении: бустинг обучает модели последовательно, чтобы снизить смещение, тогда как бэггинг обучает модели параллельно, чтобы снизить дисперсию.
Бэггинг и бустинг в машинном обучении преследуют одну цель — улучшить качество модели, но воздействуют на разные аспекты её поведения.
Чем полезен бэггинг?
Одно из главных преимуществ бэггинга в машинном обучении — снижение дисперсии, что помогает моделям лучше обобщаться на новых данных. Особенно хорошо бэггинг работает с алгоритмами, чувствительными к изменениям в обучающих данных, например с деревьями решений.
Предотвращая переобучение, он делает модель более стабильной и надёжной. Если сравнивать бэггинг и бустинг в машинном обучении: бэггинг снижает дисперсию, обучая несколько моделей параллельно, тогда как бустинг снижает смещение, обучая модели последовательно.
Пример применения бэггинга в машинном обучении — прогнозирование финансовых рисков. Несколько деревьев решений обучаются на разных подвыборках исторических рыночных данных, а агрегирование их предсказаний даёт более устойчивую прогнозную модель и снижает влияние ошибок отдельных моделей.
По сути, бэггинг в машинном обучении использует коллективный результат нескольких моделей, чтобы получать предсказания точнее и надёжнее, чем любая из них по отдельности.
Как работает бэггинг в машинном обучении: пошаговый разбор
Разберём процесс по шагам, чтобы понять, как бэггинг улучшает качество модели.
Формирование бутстрэп-выборок из датасета
Первый шаг бэггинга — создание нескольких новых подвыборок из исходного датасета методом бутстрэпинга. Данные выбираются случайно с возвращением: одни точки могут встречаться в подвыборке несколько раз, другие не попасть вовсе. Это гарантирует, что каждая модель обучается на слегка отличающейся версии данных.
Обучение отдельной модели на каждой выборке
На каждой бутстрэп-выборке обучается отдельная модель, как правило одного типа — например дерево решений. Такие модели называют «базовыми» или «слабыми обучающимися»: каждая обучается независимо на своей подвыборке. Пример бэггинг-классификатора — деревья решений в алгоритме Random Forest, которые составляют основу многих бэггинг-моделей. Каждая модель в отдельности может работать не очень хорошо, но вносит уникальный вклад, основанный на своих обучающих данных.
Агрегирование предсказаний
После обучения предсказания моделей агрегируются в итоговый результат.
- Для задач регрессии предсказания усредняются, что снижает дисперсию модели.
- Для задач классификации итоговое предсказание определяется голосованием большинства: выбирается класс, который предсказало наибольшее число моделей. Это даёт более стабильный результат по сравнению с одной моделью.
Итоговое предсказание
Объединяя предсказания нескольких моделей, бэггинг снижает влияние ошибок каждой из них и повышает общую точность. Именно агрегирование делает бэггинг такой эффективной техникой — особенно в задачах машинного обучения, где используются модели с высокой дисперсией, такие как деревья решений. Оно сглаживает расхождения в предсказаниях отдельных моделей и в итоге даёт более сильную финальную модель.
Бэггинг хорошо стабилизирует предсказания, но стоит учитывать несколько нюансов. Если базовые модели слишком сложные, переобучение всё равно возможно — несмотря на то что бэггинг в целом направлен на его снижение.
Метод также требователен к вычислительным ресурсам. Помочь может уменьшение числа базовых обучающихся или выбор более эффективных ансамблевых методов. выбор подходящего GPU для ML и DL всегда важно.
Старайтесь использовать разнообразные базовые модели — это улучшает итоговый результат. Если данные несбалансированы, перед применением бэггинга стоит воспользоваться такими техниками, как SMOTE, иначе модель будет плохо справляться с редкими классами.
Применение бэггинга
Разобравшись с тем, как работает бэггинг, посмотрим, где он применяется на практике. Метод нашёл применение в самых разных отраслях: он повышает точность и устойчивость предсказаний в сложных задачах. Рассмотрим наиболее значимые примеры.
- Классификация и регрессия: Бэггинг широко используется для повышения качества классификаторов и регрессоров за счёт снижения дисперсии и предотвращения переобучения. Например, случайные леса, основанные на бэггинге, хорошо справляются с задачами классификации изображений и прогностического моделирования.
- Обнаружение аномалий: В таких задачах, как выявление мошенничества и обнаружение сетевых вторжений, бэггинг-алгоритмы показывают высокую эффективность, точно выявляя выбросы и аномалии в данных.
- Оценка финансовых рисков: В банковской сфере методы бэггинга применяются для улучшения моделей кредитного скоринга — это повышает точность принятия решений по заявкам на кредит и оценки финансовых рисков.
- Медицинская диагностика: В здравоохранении бэггинг применяется для диагностики нейрокогнитивных расстройств, в частности болезни Альцгеймера, путём анализа данных МРТ. Это помогает в ранней постановке диагноза и планировании лечения.
- Обработка естественного языка (NLP): Бэггинг улучшает качество задач классификации текста и анализа тональности: объединяя предсказания нескольких моделей, он обеспечивает более точное понимание языка.
Преимущества и недостатки бэггинга
Как и любой метод машинного обучения, бэггинг имеет свои преимущества и недостатки. Понимание этих сторон поможет решить, когда и как его применять в ваших моделях.
Преимущества бэггинга:
- Снижение дисперсии и предотвращение переобучения: Одно из главных преимуществ бэггинга — снижение дисперсии, которое защищает модель от переобучения. Обучая несколько моделей на разных подмножествах данных, вы гарантируете, что итоговая модель не будет чрезмерно чувствительна к колебаниям в обучающей выборке. Результат — более обобщающая и устойчивая модель.
- Эффективность с высокодисперсными моделями: Бэггинг особенно хорошо работает с высокодисперсными моделями, например с деревьями решений. Такие модели склонны к переобучению, однако бэггинг сглаживает этот эффект за счёт усреднения или голосования по нескольким моделям. Предсказания становятся более надёжными и менее подверженными влиянию шума в данных.
- Повышение стабильности и качества модели: Объединяя несколько моделей, обученных на разных подмножествах данных, бэггинг, как правило, улучшает общее качество предсказаний. Он снижает чувствительность модели к небольшим изменениям в наборе данных, делая её более надёжной.
Недостатки бэггинга:
- Высокие вычислительные затраты: Бэггинг требует обучения нескольких моделей, что неизбежно увеличивает вычислительные затраты. Обучение множества моделей и агрегирование их предсказаний может занимать значительное время — особенно при работе с большими датасетами или сложными моделями, такими как деревья решений.
- Малая эффективность для моделей с низкой дисперсией: Бэггинг хорошо работает с моделями с высокой дисперсией, но практически не даёт преимуществ при применении к моделям с низкой дисперсией, например к линейной регрессии. В таких случаях отдельные модели уже имеют низкий уровень ошибок, и агрегирование предсказаний почти не улучшает результат.
- Снижение интерпретируемости: Объединение нескольких моделей снижает интерпретируемость итоговой модели. Например, в случае Random Forest процесс принятия решений опирается на множество деревьев решений, что затрудняет отслеживание логики конкретного предсказания.
Когда стоит использовать бэггинг?
Понимание того, когда применять бэггинг в задачах машинного обучения, напрямую влияет на качество результата. Этот метод хорошо работает в определённых ситуациях, но не является универсальным решением для каждой задачи.
Когда модель склонна к переобучению
Одна из ключевых областей применения бэггинга — ситуации, когда модель склонна к переобучению, особенно если речь идёт о моделях с высокой дисперсией, таких как деревья решений. Подобные модели могут показывать хорошие результаты на обучающих данных, но плохо обобщаются на новых данных, поскольку слишком точно подстраиваются под паттерны обучающей выборки.
Бэггинг помогает решить эту проблему: несколько моделей обучаются на разных подвыборках данных, а их предсказания усредняются или объединяются голосованием. Это снижает вероятность переобучения и делает модель более устойчивой к новым данным.
Когда нужно повысить стабильность и точность
Если вы хотите улучшить стабильность и точность модели без существенной потери интерпретируемости, бэггинг — хороший выбор. Агрегирование предсказаний нескольких моделей делает итоговый результат более надёжным, что особенно важно при работе с зашумлёнными данными.
Будь то задачи классификации или регрессии, бэггинг помогает получать более стабильные результаты: точность растёт, а эффективность не страдает.
Когда доступны достаточные вычислительные ресурсы
Важный фактор при выборе бэггинга — наличие вычислительных ресурсов. Поскольку метод предполагает одновременное обучение нескольких моделей, вычислительные затраты могут быть весьма значительными — особенно при работе с большими датасетами или сложными моделями.
Если ресурсы позволяют, преимущества бэггинга с лихвой перекрывают его стоимость. Если же ресурсы ограничены, стоит рассмотреть альтернативные методы или уменьшить количество моделей в ансамбле.
Когда модели имеют высокую дисперсию
Бэггинг особенно полезен при работе с моделями, которые чувствительны к изменениям в обучающих данных и имеют высокую дисперсию. Деревья решений, например, часто используются с бэггингом в форме Random Forest именно потому, что их результаты сильно варьируются в зависимости от обучающей выборки.
Обучая несколько моделей на разных подвыборках и объединяя их предсказания, бэггинг сглаживает дисперсию и делает модель более стабильной.
Когда нужен надёжный классификатор
Если вы решаете задачи классификации и вам нужен надёжный классификатор, бэггинг может заметно повысить стабильность предсказаний. Например, Random Forest — классический пример бэггинг-классификатора — обеспечивает более точные предсказания за счёт агрегирования результатов множества отдельных деревьев решений.
Этот подход хорошо работает в случаях, когда отдельные модели слабы сами по себе, но их совокупный результат оказывается значительно сильнее.
Если вы ищете подходящую платформу для эффективного применения методов бэггинга, такие инструменты, как Databricks и Snowflake предоставляют единую аналитическую платформу, которая хорошо подходит для работы с большими наборами данных и запуска ансамблевых методов, таких как бэггинг.
Если вам нужен менее технический подход к машинному обучению, no-code инструменты для AI могут стать хорошим вариантом. Они не ориентированы напрямую на продвинутые техники вроде бэггинга, но многие no-code платформы позволяют экспериментировать с ансамблевыми методами обучения, включая бэггинг, без глубоких знаний программирования.
Это даёт возможность применять более сложные техники и при этом получать точные предсказания, сосредоточившись на производительности модели, а не на коде под капотом.
Заключение
Бэггинг в машинном обучении - мощная техника, которая улучшает качество модели за счёт снижения дисперсии и повышения стабильности. Агрегируя предсказания нескольких моделей, обученных на разных подвыборках данных, бэггинг помогает получать более точные и надёжные результаты. Особенно он эффективен для моделей с высокой дисперсией, таких как деревья решений: он снижает переобучение и улучшает обобщающую способность модели на новых данных.
При всех своих преимуществах - снижении переобучения и повышении точности - бэггинг сопряжён с определёнными компромиссами. Он увеличивает вычислительные затраты из-за обучения нескольких моделей и может снижать интерпретируемость. Несмотря на эти недостатки, способность бэггинга повышать качество делает его ценным инструментом в ансамблевом обучении наряду с другими методами, такими как бустинг и стекинг.
Использовали ли вы бэггинг в своих проектах по машинному обучению? Расскажите о своём опыте и результатах!


